Medan OpenAI ChatGPT suger upp allt syre ur den 24-timmarsnyhetscykeln, har Google tyst avslöjat en ny AI-modell som kan generera videor när de ges video, bild och textinmatning. Den nya Google Dreamix AI-videoredigeraren för nu genererad video närmare verkligheten.
Enligt forskningen publicerad på GitHub, redigerar Dreamix videon baserat på en video och en textuppmaning. Den resulterande videon behåller sin trohet mot färg, hållning, objektstorlek och kameraposition, vilket resulterar i en tidsmässigt konsekvent video. För tillfället kan Dreamix inte generera videor från bara en uppmaning, men den kan ta befintligt material och modifiera videon med hjälp av textuppmaningar.
Google använder videodiffusionsmodeller för Dreamix, ett tillvägagångssätt som framgångsrikt har tillämpats för det mesta av videobildredigering vi ser i bild-AI:er som DALL-E2 eller öppen källkod Stable Diffusion.
Tillvägagångssättet innebär att kraftigt reducera ingångsvideon, lägga till artificiellt brus och sedan bearbeta det i en videodiffusionsmodell, som sedan använder en textprompt för att generera en ny video från den som behåller vissa egenskaper hos den ursprungliga videon och återskapar andra enligt till textinmatningen.
Videospridningsmodellen erbjuder en lovande framtid som kan inleda en ny era för att arbeta med videor.

Till exempel, i videon nedan, förvandlar Dreamix den ätande apan (vänster) till en dansande björn (höger) med uppmaningen "En björn som dansar och hoppar till livlig musik, rör sig hela kroppen."
I ett annat exempel nedan använder Dreamix ett enda foto som mall (som i bild-till-video) och ett objekt animeras sedan från det i en video via en prompt. Kamerarörelser är också möjliga i den nya scenen eller en efterföljande time-lapse-inspelning.
I ett annat exempel förvandlar Dreamix orangutangen i en vattenpöl (vänster) till en orangutang med orange hår som badar i ett vackert badrum.
"Medan diffusionsmodeller har använts framgångsrikt för bildredigering, har väldigt få verk gjort det för videoredigering. Vi presenterar den första diffusionsbaserade metoden som kan utföra textbaserad rörelse- och utseenderedigering av allmänna videor.”
Enligt Googles forskningsartikel använder Dreamix en videodiffusionsmodell för att vid slutledningstidpunkten kombinera lågupplöst spatiotemporal information från originalvideon med ny högupplöst information som den syntetiserade för att passa in i den vägledande textprompten."
Google sa att det tog det här tillvägagångssättet eftersom "att erhålla högtrohet till originalvideon kräver att man behåller en del av dess högupplösta information, vi lägger till ett preliminärt steg för att finjustera modellen på originalvideon, vilket avsevärt ökar troheten."
Nedan finns en videoöversikt över hur Dreamix fungerar.
[Inbäddat innehåll]
Hur Dreamix Videodiffusionsmodeller fungerar
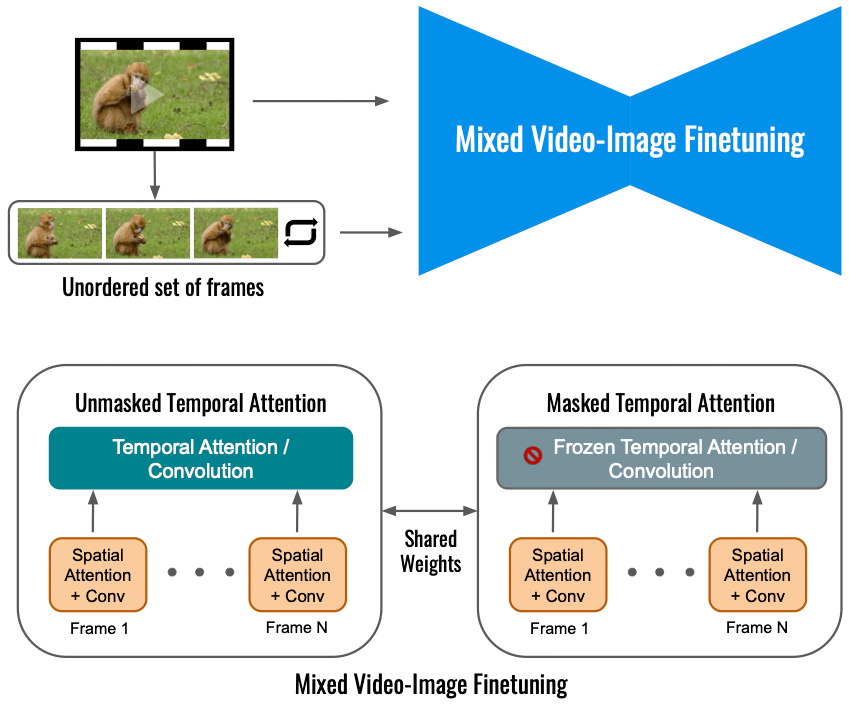
Enligt Google begränsar finjustering av videodiffusionsmodellen för Dreamix enbart på ingångsvideon omfattningen av rörelseförändringar. Istället använder vi ett blandat objektiv som förutom originalobjektivet (nedre till vänster) även finjusterar på den oordnade uppsättningen ramar. Detta görs genom att använda "maskerad tidsuppmärksamhet", vilket förhindrar att den tidsmässiga uppmärksamheten och faltningen finjusteras (nedre till höger). Detta gör det möjligt att lägga till rörelse till en statisk video.
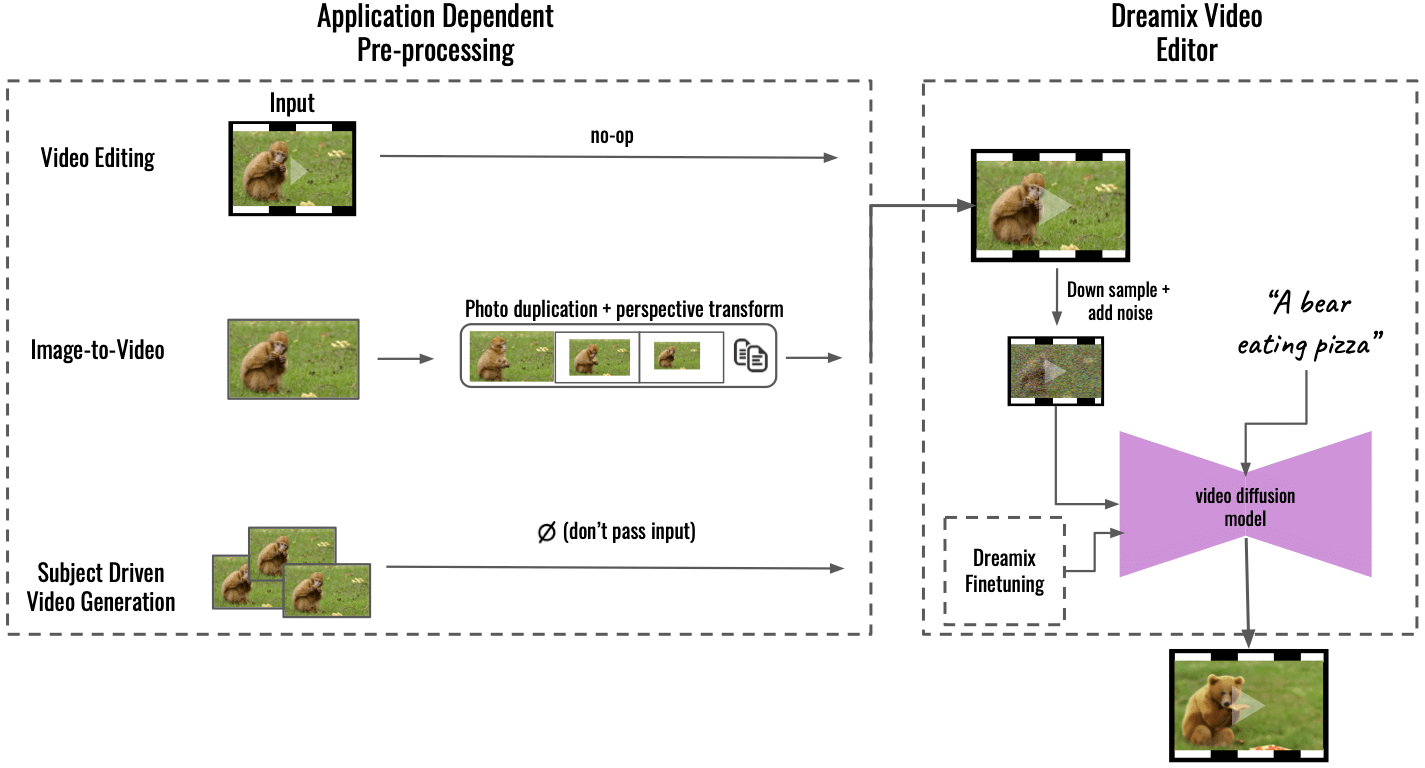
"Vår metod stöder flera applikationer genom applikationsberoende förbehandling (vänster), omvandling av inmatat innehåll till ett enhetligt videoformat. För bild-till-video dupliceras och transformeras ingångsbilden med hjälp av perspektivtransformationer, vilket syntetiserar en grov video med lite kamerarörelse. För ämnesdriven videogenerering utelämnas ingången – finjusteringen tar enbart hand om troheten. Denna grova video redigeras sedan med vår allmänna "Dreamix Video Editor" (höger): vi förstör videon genom att nedsampling följt av att lägga till brus. Vi tillämpar sedan den finjusterade textstyrda videodiffusionsmodellen, som uppskalar videon till den slutliga spatiotemporala upplösningen", skrev Dream på GitHub.
Du kan läsa forskningsartikeln nedan.
Google Dreamix- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Able
- Enligt
- AI
- AI -video
- AI-powered
- Alla
- tillåter
- ensam
- och
- Annan
- tillämpningar
- tillämpas
- Ansök
- tillvägagångssätt
- konstgjord
- uppmärksamhet
- baserat
- Bear
- vackert
- därför att
- Där vi får lov att vara utan att konstant prestera,
- nedan
- kropp
- öka
- Botten
- Bringar
- rum
- kan inte
- vilken
- byta
- ChatGPT
- närmare
- färg
- kombinera
- konsekvent
- innehåll
- Skapa
- cykel
- Dans
- Diffusion
- drömmen
- redaktör
- inbäddade
- Era
- exempel
- befintliga
- få
- trohet
- slutlig
- Förnamn
- följt
- format
- från
- framtida
- Allmänt
- generera
- genereras
- generering
- gif
- GitHub
- ges
- Hår
- kraftigt
- hög upplösning
- Hur ser din drömresa ut
- Men
- HTTPS
- bild
- bilder
- in
- informationen
- ingång
- istället
- IT
- lanserar
- gränser
- upprätthåller
- Materialet
- max
- metod
- blandad
- modell
- modeller
- modifiera
- ögonblick
- mest
- rörelse
- rörelser
- rörliga
- multipel
- Musik
- Nya
- nyheter
- Brus
- objektet
- mål
- Erbjudanden
- öppen källkod
- OpenAI
- Orange
- ursprungliga
- Övrigt
- Översikt
- Syrgas
- Papper
- utföra
- perspektiv
- plato
- Platon Data Intelligence
- PlatonData
- poolen
- möjlig
- presentera
- förebyggande
- bearbetning
- lovande
- egenskaper
- publicerade
- tyst
- Läsa
- Verkligheten
- inspelning
- reducerande
- Kräver
- forskning
- Upplösning
- resulterande
- kvarhållande
- Nämnda
- scen
- in
- signifikant
- enda
- Storlek
- So
- några
- stabil
- Etapp
- senare
- Framgångsrikt
- sådana
- Stöder
- Ta
- mall
- Smakämnen
- tid
- till
- transformationer
- transformerad
- avtäckt
- användning
- via
- Video
- Video
- Vatten
- som
- arbetssätt
- fungerar
- Youtube
- zephyrnet











