
Bild av rawpixel.com on Freepik
Oavsett vilken verksamhet du är i, är det viktigare än någonsin att veta hur man analyserar data i den datadrivna eran. Dataanalys skulle göra det möjligt för företag att förbli konkurrenskraftiga och ge möjlighet att fatta bättre beslut.
Vikten av dataanalys driver varje individ att veta hur man utför dataanalys. Men ibland tar det för lång tid att genomföra dataanalys. Det är därför vi kunde lita på ChatGPT för att skapa en komplett rapport från vår datafil.
Den här artikeln kommer att utforska fem enkla steg för att skapa kompletta analytiska rapporter från din CSV-fil. Dessa fem steg inkluderar:
Steg 1: Importera CSV-filen
Steg 2: Datasammanfattning och förbearbetning
Steg 3: Dataanalys
Steg 4: Datavisualisering
Steg 5: Rapportgenerering
Som en förutsättning förutsätter denna artikel att läsaren har prenumererat på ChatGPT Plus. Med det i åtanke, låt oss börja.
Det första steget är att förbereda CSV-filen som du vill analysera och skapa en rapport. Den här filen kan komma från vilken pålitlig källa som helst, men den här artikeln skulle använda datauppsättningen Telecom Churn från Kaggle.
Se till att data är strukturerad, organiserad och har en tydlig rubrik. Om du har ett visst mål som du vill analysera, glöm inte att inkludera den datan i filen. I vårt exempel skulle vi försöka utföra en analys för churn-kolumnen.
Med data redo, anslut dem till ChatGPT och låt modellen göra sitt jobb.
Nästa steg är att hämta datasammanfattningen från vår CSV-fil och förbehandla dem. Ange följande prompt medan du laddar upp data.
Provide the data summary to this file and perform appropriate data processing for the dataset.Ovanstående uppmaning ger följande resultat:
Här är sammanfattningen av din datauppsättning:
Antal rader: 3333
Antal kolumner: 11
Kolumnnamn:
Churn
AccountWeeks
Kontraktsförnyelse
DataPlan
Dataanvändning
CustServCalls
DayMins
Dagsamtal
Månadsavgift
Överskottsavgift
RoamMins
Datatyper:
Heltal: Churn, AccountWeeks, ContractRenewal, DataPlan, CustServCalls, DayCalls
Flytande: DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins
Saknade värden: Det saknas inga värden i någon av kolumnerna.
ChatGPT kunde tydligt läsa data väl och kunde tillhandahålla den givna datamängden. Nästa resultat är dataförbehandlingen från ChatGPT.
Eftersom det inte finns några saknade värden i datamängden kommer huvudfokus för datarensning och förbearbetning att ligga på:
- Kontrollerar om det finns några extremvärden eller anomalier i data.
- Normalisering eller standardisering av data vid behov, särskilt för kolumner med kontinuerliga numeriska värden.
- Konvertering av kategoridata till ett format som lämpar sig för analys, om det behövs.
Låt oss fortsätta med dessa steg.
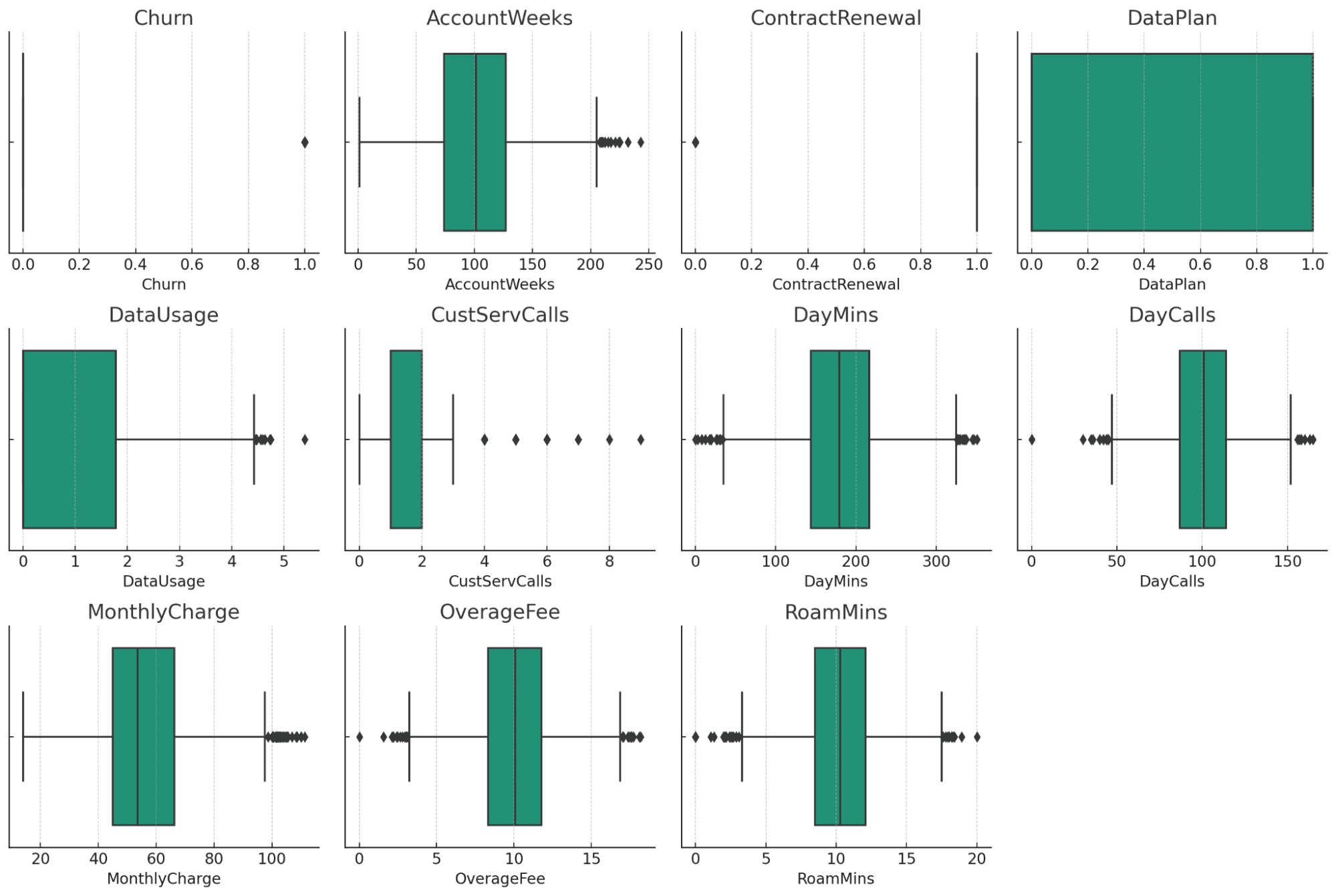
Boxplots ger en visuell översikt över potentiella extremvärden i varje numerisk kolumn i din datauppsättning. Här är några observationer:
- AccountWeeks, CustServCalls, DayCalls: Dessa kolumner visar en ganska normal fördelning med några extremvärden.
- DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins: Dessa kolumner visar också några extremvärden, men de verkar ligga inom ett rimligt intervall, med tanke på datas natur.
- Churn, ContractRenewal, DataPlan: Eftersom dessa kolumner är kategoriska/binära data, visar dessa kolumner inte traditionella extremvärden.
Med tanke på denna information kan nästa steg i datarensning och förbearbetning inkludera:
- Hantering av extremvärden: Vi kan bestämma om vi ska ta bort, begränsa eller på annat sätt hantera extremvärden baserat på dina specifika analytiska behov och domänkunskap.
- Datatransformation: Vid behov kan vi normalisera eller standardisera kolumner som DayMins, MonthlyCharge, etc., speciellt om du planerar att använda algoritmer som är känsliga för dataskalan.
- Kategorisk datakodning: Konvertera kategorisk data till ett format som är lämpligt för analys, om någon sådan transformation krävs.
Du kan låta ChatGPT utföra ytterligare steg för datarensning och förbearbetning eller låta den vara som den är. För det här exemplet skulle vi fortsätta till nästa steg.
Därefter skulle vi utföra dataanalys med ChatGPT. Dataanalysen beror på vad du vill uppnå. I vårt fall vill vi utföra dataanalys från Churn POV.
Vi använder följande uppmaning för att utföra dataanalysen med ChatGPT för ovanstående fall.
Please perform the data analysis based on the data above with respect to the churn data.
Dataanalysen kan ses i följande resultat.
För att utföra dataanalys med avseende på churn-data kommer vi att fokusera på att förstå hur olika faktorer relaterar till kundchurn. Churn, som är en binär variabel (0 för ingen churn, 1 för churn), analyseras vanligtvis genom klassificeringsmetoder och genom att undersöka samband med andra variabler. Här är planen:
- Korrelationsanalys: Till att börja med ska vi titta på hur varje numerisk funktion korrelerar med churn. Detta ger oss en första förståelse för vilka faktorer som kan vara närmare relaterade till churn.
- Statistiska tester: För kategoriska variabler som ContractRenewal och DataPlan kan vi använda statistiska tester för att se om det finns signifikanta skillnader i churn-hastigheter mellan olika kategorier.
- Visuell analys: Vi kommer att skapa några visualiseringar för att ytterligare utforska dessa relationer. Detta inkluderar att jämföra churnhastigheter mellan olika grupper och plotta nyckelvariabler mot churn.
- Sammanfattande statistik: Vi kommer att tillhandahålla sammanfattande statistik för olika grupper baserat på churn-status för att se om det finns märkbara skillnader i medelvärden eller fördelningar.
Låt oss börja med korrelationsanalysen och sedan gå vidare till nästa steg.
Korrelationsanalys med Churn
Korrelationen mellan olika variabler med churn är som följer (från starkaste negativa till starkaste positiva korrelation):
Negativ korrelation:
- ContractRenewal: Starkast negativ korrelation. Indikerar att kunder som inte förnyar sina kontrakt är mer benägna att churna.
- DataPlan: Kunder utan en dataplan är något mer benägna att churna.
- Dataanvändning: Högre dataanvändning minskar sannolikheten för churn något.
Positiv korrelation:
- AccountWeeks, DayCalls: Mycket svag positiv korrelation, vilket tyder på minimal påverkan på churn.
- RoamMins: En liten ökning av sannolikheten för churn med ökade roamingminuter.
- MonthlyCharge: Något högre churn rates med ökade månadsavgifter.
- OverageFee: Högre överageavgifter är måttligt korrelerade med ökad churn.
- DayMins: Högre dagliga minuter är måttligt korrelerade med ökad churn.
- CustServCalls: Stark positiv korrelation. Fler kundtjänstsamtal är förknippade med högre churn rates.
Baserat på dessa korrelationer verkar det som om faktorer som kontraktsförnyelse, kundtjänstsamtal, dagliga minuter och överskottsavgifter är närmare relaterade till churn. Vi kan utforska dessa faktorer ytterligare genom visuell analys och statistiska tester, särskilt för kategoriska variabler som ContractRenewal och DataPlan.
Visuell analys
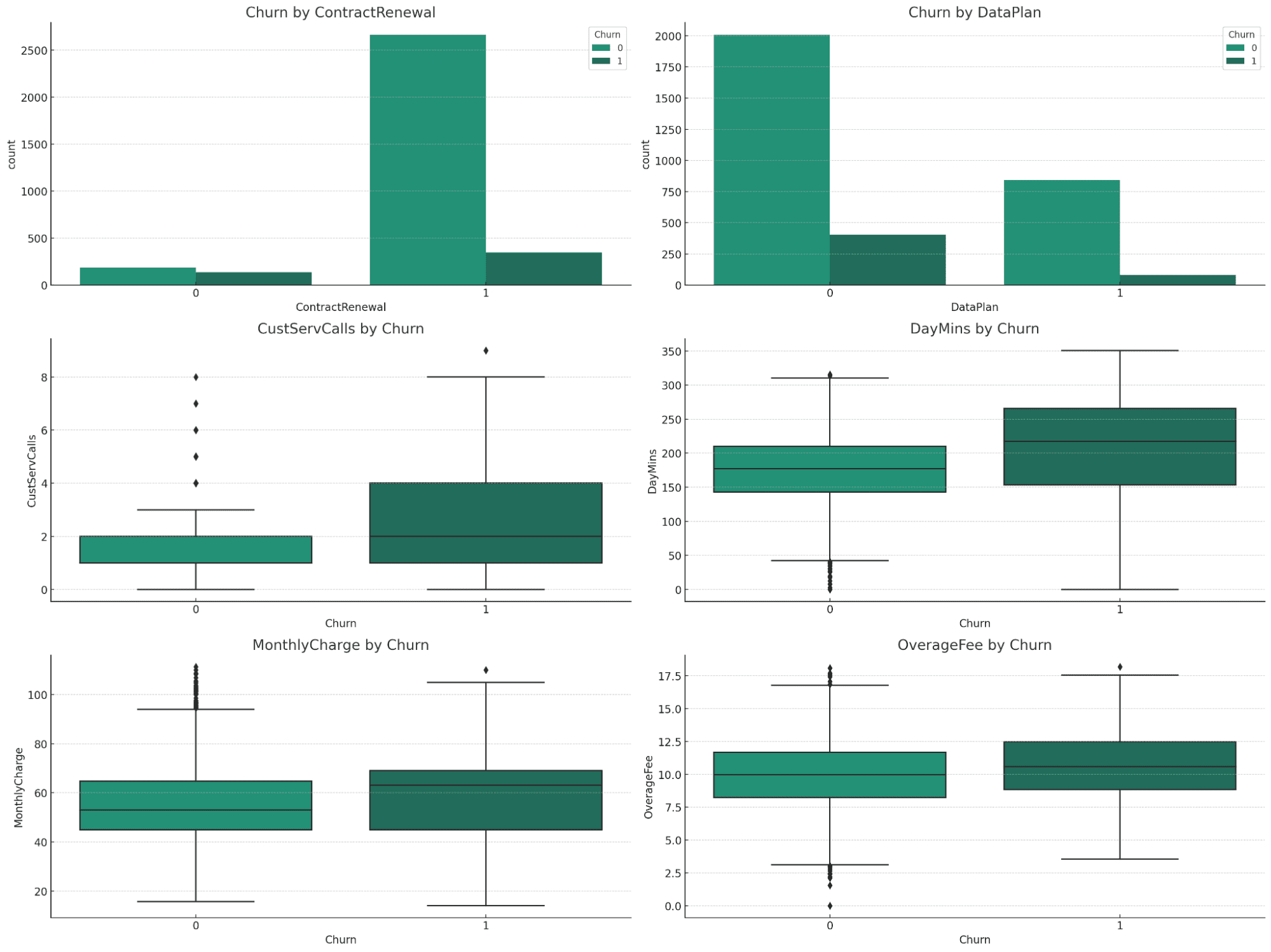
Visualiseringarna ger värdefulla insikter om förhållandet mellan olika variabler och churn:
Churn genom ContractRenewal och DataPlan:
- Kontraktsförnyelse: En betydande skillnad i churn rates är uppenbar. Kunder som inte förnyat sina kontrakt visar en högre churn.
- DataPlan: Det finns en märkbar skillnad i churn-frekvenser baserat på om kunder har en dataplan eller inte, med de utan en dataplan som visar högre churn.
Numeriska variabler (CustServCalls, DayMins, MonthlyCharge, OverageFee) av Churn:
- CustServCalls: Kunder med högre antal kundtjänstsamtal tenderar att churna mer.
- DayMins: Högre dagliga minuter är förknippade med en större sannolikhet för churn.
- MonthlyCharge: Högre månadsavgifter korrelerar med en ökad churn rate.
- OverageFee: Högre överageavgifter är också förknippade med ökad churn.
Slutsatser från analysen
- Kontraktsförnyelsestatus och närvaron av en dataplan är viktiga faktorer i kundförlusten.
- Hög användning (i termer av dagsminuter) och höga avgifter (månadsavgifter och överskottsavgifter) är förknippade med högre churn rates.
- Ett högre antal kundtjänstsamtal är en stark indikator på potentiell churn.
Nästa steg
Baserat på dessa insikter kan riktade strategier utvecklas för att minska churn, såsom att förbättra kundservice, revidera prisstrategier eller erbjuda incitament för förnyelse av kontrakt och prenumerationer på dataplaner.
Med en enda uppmaning kan vi se hur väl ChatGPT kan ge oss den fullständiga dataanalysen och komma med insikt från datan. Du kan justera analysens mål och börja därifrån.
Datavisualiseringen är en stödjande aktivitet för att förbättra dataanalysen och den övergripande rapporten. Genom att ha visualiseringen kan vi få en mer omfattande rapport för att förstå vår data.
Med hjälp av följande prompt kan vi utföra datavisualiseringen med ChatGPT.
Please perform data visualization from the data analysis to explain the data better.För att öka förståelsen för dataanalysresultaten kommer jag att skapa en serie visualiseringar som tydligt visar nyckelresultaten relaterade till kundförlust. Dessa visualiseringar kommer att inkludera:
- Stapeldiagram för kategoriska variabler:
- Jämför churn rates för kunder med och utan avtalsförnyelse.
- Jämför churn rates för kunder med och utan dataplan.
- Boxplots för numeriska nyckelvariabler:
- Kundtjänstsamtal vs Churn.
- Dagliga minuter vs Churn.
- Månatliga avgifter vs Churn.
- Överskottsavgifter vs Churn.
- Värmekarta över korrelation:
För att visualisera korrelationen av alla variabler med churn.
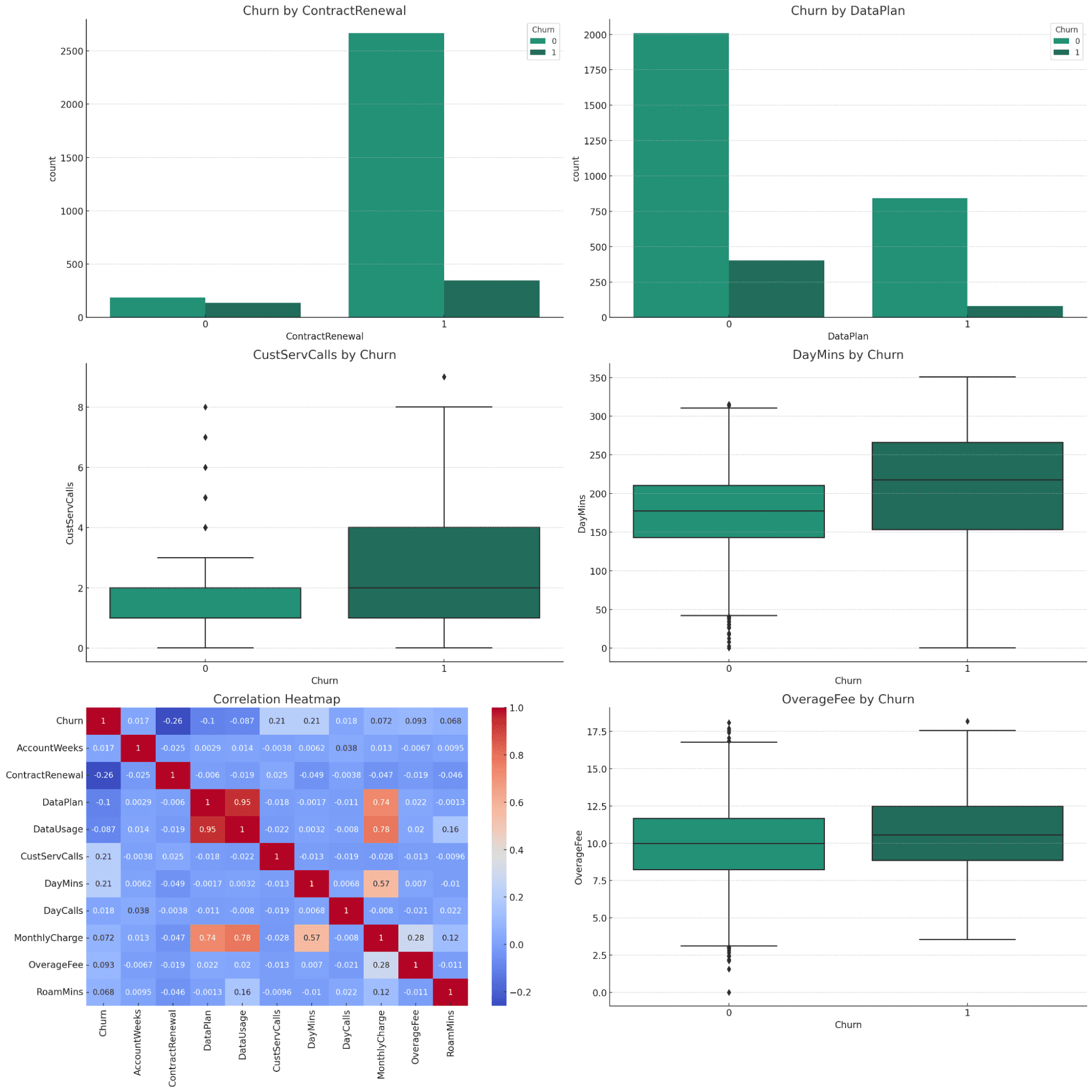
Visualiseringen skulle visa alla viktiga diagram som kapslar in hela datasetet. Vi kan be om mer detaljerade beskrivningar för varje tomt, som du kan prova självständigt.
Det sista steget är att generera rapporten baserat på de föregående stegen. Tyvärr kanske ChatGPT inte fångar all beskrivning och insikt från dataanalysen, men vi kan fortfarande ha den enkla versionen av rapporten.
Använd följande uppmaning för att skapa en PDF-rapport baserad på den tidigare analysen.
Please provide me with the pdf report from the first step to the last step.Du kommer att få PDF-länkresultatet med din tidigare analys täckt. Försök att upprepa stegen om du känner att resultatet är otillräckligt eller om det finns saker du vill ändra.
Dataanalys är en aktivitet som alla borde känna till eftersom det är en av de mest nödvändiga färdigheterna i den nuvarande eran. Det kan dock ta lång tid att lära sig att utföra dataanalys. Med ChatGPT kan vi minimera all aktivitetstid.
I den här artikeln har vi diskuterat hur man genererar en komplett analytisk rapport från CSV-filer i 5 steg. ChatGPT förser användare med end-to-end dataanalysaktivitet, från att importera filen till att producera rapporten.
Cornellius Yudha Wijaya är biträdande chef för datavetenskap och dataskribent. Medan han arbetar heltid på Allianz Indonesia älskar han att dela Python- och Data-tips via sociala medier och skrivande media.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps?utm_source=rss&utm_medium=rss&utm_campaign=from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps
- : har
- :är
- :inte
- $UPP
- 1
- 7
- a
- förmåga
- Able
- Om oss
- ovan
- Uppnå
- tvärs
- aktivitet
- Annat
- mot
- Syftet
- algoritmer
- Alla
- Allianz
- också
- an
- analys
- Analytisk
- analysera
- analyseras
- och
- vilken som helst
- lämpligt
- ÄR
- Artikeln
- AS
- be
- Assistent
- associerad
- antar
- At
- bifoga
- bar
- baserat
- BE
- Där vi får lov att vara utan att konstant prestera,
- Bättre
- mellan
- Box
- företag
- företag
- men
- by
- Samtal
- KAN
- lock
- fånga
- Vid
- kategorier
- vissa
- byta
- avgifter
- ChatGPT
- kontroll
- klassificering
- Rengöring
- klar
- klart
- nära
- Kolumn
- Kolonner
- komma
- jämförande
- konkurrenskraftig
- fullborda
- omfattande
- Genomför
- med tanke på
- fortsätta
- kontinuerlig
- kontrakt
- kontrakt
- konvertera
- omvandling
- korrelerade
- Korrelation
- korrelationer
- kunde
- omfattas
- skapa
- Aktuella
- kund
- Kundservice
- Kunder
- dagligen
- datum
- dataanalys
- databehandling
- datavetenskap
- datavisualisering
- data driven
- dag
- beslutar
- beslut
- minskar
- beroende
- beskrivning
- detaljerad
- utvecklade
- DID
- Skillnaden
- skillnader
- olika
- diskuteras
- fördelning
- Distributioner
- do
- domän
- donation
- inte
- enheter
- varje
- möjliggöra
- kodning
- början till slut
- förbättra
- Era
- speciellt
- etc
- NÅGONSIN
- Varje
- alla
- uppenbart
- Granskning
- exempel
- exekvera
- Förklara
- utforska
- faktorer
- ganska
- Leverans
- känna
- avgifter
- få
- Fil
- Filer
- resultat
- Förnamn
- fem
- Fokus
- efter
- följer
- För
- format
- från
- ytterligare
- generera
- skaffa sig
- Ge
- ges
- ger
- större
- Gruppens
- hantera
- Arbetsmiljö
- Har
- har
- he
- här.
- Hög
- högre
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- i
- if
- Inverkan
- vikt
- med Esport
- importera
- förbättra
- förbättra
- in
- incitament
- innefattar
- innefattar
- Öka
- ökat
- oberoende av
- pekar på
- Indikator
- individuellt
- Indonesien
- informationen
- inledande
- ingång
- insikt
- insikter
- in
- IT
- jpg
- KDnuggets
- Nyckel
- Vet
- Menande
- kunskap
- Efternamn
- inlärning
- Låt
- tycka om
- sannolikhet
- sannolikt
- LINK
- ll
- Lång
- länge sedan
- se
- älskar
- Huvudsida
- göra
- chef
- Materia
- me
- betyder
- Media
- metoder
- kanske
- emot
- minimum
- minimera
- minuter
- saknas
- modell
- månad
- mer
- mest
- flytta
- mycket
- namn
- Natur
- nödvändigt för
- behövs
- behov
- negativ
- Nästa
- Nej
- normala
- antal
- nummer
- observationer
- of
- erbjudanden
- erbjuda
- on
- ONE
- or
- Organiserad
- Övriga
- annat
- vår
- övergripande
- Översikt
- utföra
- utför
- Planen
- plato
- Platon Data Intelligence
- PlatonData
- plus
- positiv
- potentiell
- Förbered
- Närvaron
- föregående
- prissättning
- Fortsätt
- bearbetning
- producerande
- ge
- ger
- Python
- område
- Betygsätta
- rates
- Läsa
- Läsare
- redo
- rimlig
- minska
- relaterad
- relation
- Förhållanden
- förlita
- ta bort
- rapport
- Rapport
- Obligatorisk
- avseende
- resultera
- Resultat
- s
- Skala
- Vetenskap
- se
- verka
- verkar
- sett
- känslig
- Serier
- service
- Dela
- skall
- show
- visar
- signifikant
- Enkelt
- enda
- färdigheter
- Social hållbarhet
- sociala medier
- några
- ibland
- Källa
- specifik
- standardisera
- starta
- igång
- statistisk
- statistik
- status
- bo
- Steg
- Steg
- Fortfarande
- strategier
- stark
- starkaste
- strukturerade
- abonnemang
- sådana
- lämplig
- SAMMANFATTNING
- stödjande
- T
- Ta
- tar
- Målet
- riktade
- telecom
- villkor
- tester
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Där.
- Dessa
- de
- saker
- detta
- de
- Genom
- tid
- Tips
- till
- alltför
- traditionell
- Transformation
- trovärdig
- prova
- justera
- typiskt
- förstå
- förståelse
- tyvärr
- us
- Användning
- användning
- användare
- Värdefulla
- Värden
- variabel
- version
- mycket
- via
- visuell
- visualisering
- visualisera
- vs
- vill
- var
- we
- VÄL
- Vad
- om
- som
- medan
- VEM
- Hela
- varför
- kommer
- med
- inom
- utan
- Arbete
- arbetssätt
- skulle
- författare
- skrivning
- dig
- Din
- zephyrnet









