
September 20, 2023
Grundläggande modeller (FM) markerar början på en ny era maskininlärning (ML) och artificiell intelligens (AI), vilket leder till snabbare utveckling av AI som kan anpassas till ett brett utbud av nedströmsuppgifter och finjusteras för en rad applikationer.
Med den ökande betydelsen av att bearbeta data där arbete utförs, möjliggör servering av AI-modeller på företagskanten nästan realtidsförutsägelser, samtidigt som de följer datasuveränitet och integritetskrav. Genom att kombinera IBM watsonx data- och AI-plattformskapacitet för FM:er med edge computing, kan företag köra AI-arbetsbelastningar för FM-finjustering och slutledning vid den operativa kanten. Detta gör det möjligt för företag att skala AI-distributioner vid kanten, vilket minskar tiden och kostnaderna att implementera med snabbare svarstider.
Se till att kolla in alla avbetalningar i den här serien av blogginlägg om edge computing:
Vad är grundmodeller?
Grundläggande modeller (FM), som tränas på en bred uppsättning omärkta data i stor skala, driver toppmoderna tillämpningar för artificiell intelligens (AI). De kan anpassas till ett brett utbud av nedströmsuppgifter och finjusteras för en mängd olika applikationer. Moderna AI-modeller, som utför specifika uppgifter i en enda domän, ger vika för FM:er eftersom de lär sig mer allmänt och fungerar över domäner och problem. Som namnet antyder kan en FM vara grunden för många tillämpningar av AI-modellen.
FM:er tar itu med två viktiga utmaningar som har hindrat företag från att skala in AI. För det första producerar företag en enorm mängd omärkt data, varav endast en bråkdel är märkt för AI-modellutbildning. För det andra är denna märknings- och anteckningsuppgift extremt mänskligt intensiv, och kräver ofta flera hundra timmar av en ämnesexperts (SME) tid. Detta gör det oöverkomligt att skala över användningsfall eftersom det skulle kräva arméer av små och medelstora företag och dataexperter. Genom att inta enorma mängder omärkt data och använda självövervakade tekniker för modellträning, har FM:er tagit bort dessa flaskhalsar och öppnat vägen för storskalig adoption av AI i hela företaget. Dessa enorma mängder data som finns i alla företag väntar på att släppas lös för att skapa insikter.
Vad är stora språkmodeller?
Stora språkmodeller (LLM) är en klass av grundläggande modeller (FM) som består av lager av neurala nätverk som har tränats på dessa enorma mängder omärkt data. De använder självövervakade inlärningsalgoritmer för att utföra en mängd olika naturlig språkbearbetning (NLP) uppgifter på sätt som liknar hur människor använder språk (se figur 1).
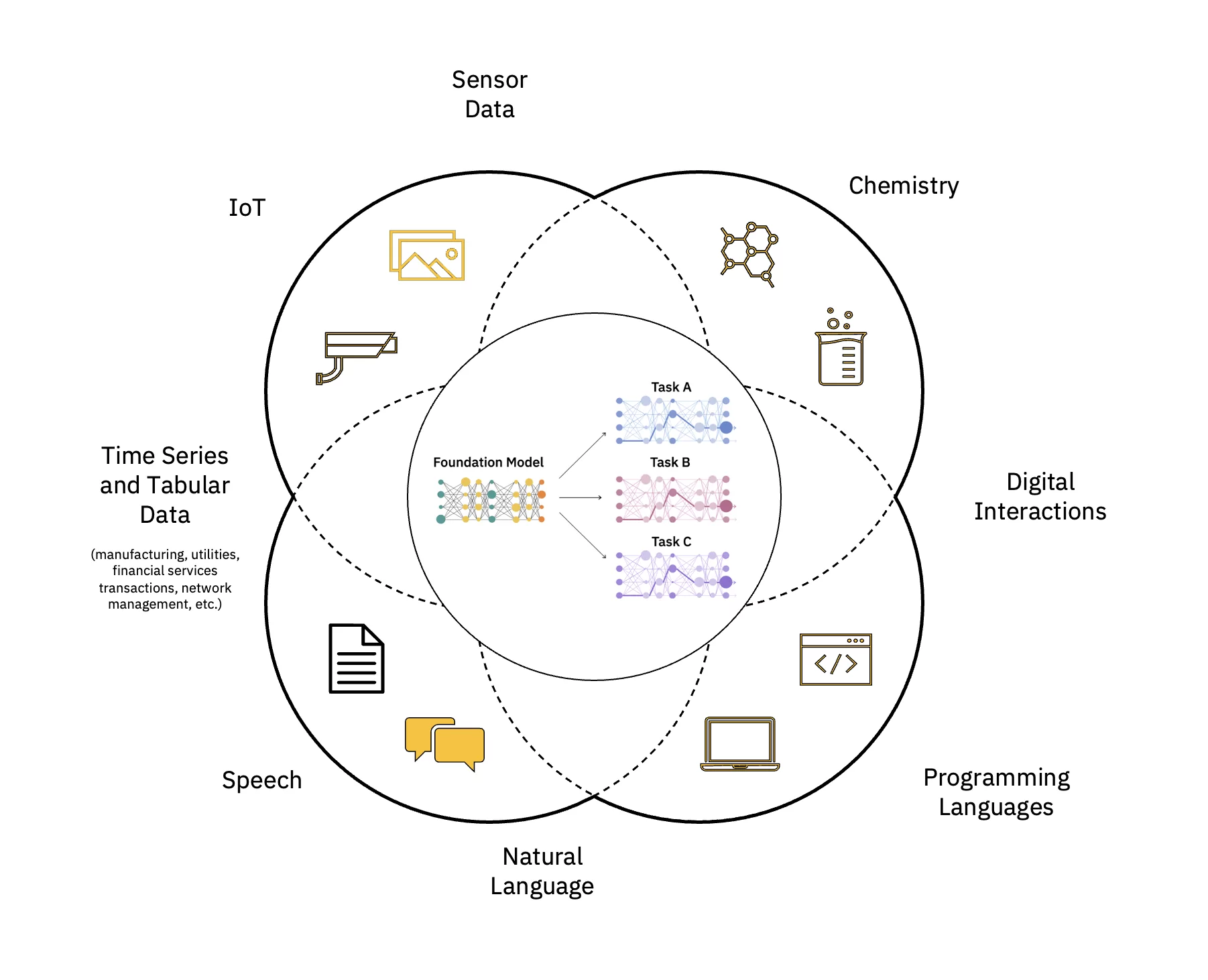
Skala och accelerera effekten av AI
Det finns flera steg för att bygga och distribuera en grundmodell (FM). Dessa inkluderar dataintag, dataurval, dataförbearbetning, FM-förträning, modellinställning till en eller flera nedströmsuppgifter, slutledningsservering och data- och AI-modellstyrning och livscykelhantering – allt detta kan beskrivas som FMOps.
För att hjälpa till med allt detta erbjuder IBM företag de nödvändiga verktygen och kapaciteterna för att utnyttja kraften i dessa FM:er via IBM watsonx, en företagsförberedd AI- och dataplattform designad för att multiplicera effekten av AI i ett företag. IBM watsonx består av följande:
- IBM watsonx.ai ger nytt generativ AI funktioner – drivna av FM:er och traditionell maskininlärning (ML) – till en kraftfull studio som spänner över AI-livscykeln.
- IBM watsonx.data är ett ändamålsenligt datalager byggt på en öppen sjöbyggnadsarkitektur för att skala AI-arbetsbelastningar för all din data, var som helst.
- IBM watsonx.governance är en heltäckande automatiserad AI-livscykelstyrningsverktygssats som är byggd för att möjliggöra ansvarsfulla, transparenta och förklarande AI-arbetsflöden.
En annan nyckelvektor är den ökande betydelsen av datoranvändning i företagskanten, såsom industriplatser, tillverkningsgolv, butiker, telekomsidor, etc. Mer specifikt möjliggör AI i företagskanten bearbetning av data där arbete utförs för nästan realtidsanalys. Företagsfördelen är där stora mängder företagsdata genereras och där AI kan ge värdefulla, snabba och handlingsbara affärsinsikter.
Att betjäna AI-modeller i utkanten möjliggör förutsägelser i nästan realtid samtidigt som man följer datasuveränitet och integritetskrav. Detta minskar avsevärt den latens som ofta förknippas med insamling, överföring, transformation och bearbetning av inspektionsdata. Genom att arbeta på kanten kan vi skydda känslig företagsdata och minska kostnaderna för dataöverföring med snabbare svarstider.
Att skala AI-distributioner vid kanten är dock inte en lätt uppgift bland data (heterogenitet, volym och regulatoriska) och begränsade resurser (dator, nätverksanslutning, lagring och till och med IT-kunskaper) relaterade utmaningar. Dessa kan i stora drag beskrivas i två kategorier:
- Tid/kostnad att implementera: Varje distribution består av flera lager av hårdvara och mjukvara som måste installeras, konfigureras och testas innan distributionen. Idag kan en servicetekniker ta upp till en vecka eller två för installation på varje plats, kraftigt begränsar hur snabbt och kostnadseffektivt företag kan skala upp implementeringar i hela sin organisation.
- Dag 2 ledning: Det stora antalet distribuerade kanter och den geografiska platsen för varje distribution kan ofta göra det oöverkomligt dyrt att tillhandahålla lokal IT-support på varje plats för att övervaka, underhålla och uppdatera dessa distributioner.
Edge AI-distributioner
IBM utvecklade en edge-arkitektur som tar itu med dessa utmaningar genom att ta med en integrerad hårdvara/mjukvara (HW/SW) apparatmodell till edge AI-distributioner. Den består av flera nyckelparadigm som underlättar skalbarheten av AI-distributioner:
- Policybaserad, noll-touch-provisionering av hela programvarustacken.
- Kontinuerlig övervakning av kantsystemets hälsa
- Förmåga att hantera och driva program-/säkerhets-/konfigurationsuppdateringar till ett flertal kantplatser – allt från en central molnbaserad plats för dag-2-hantering.
En distribuerad hub-and-spoke-arkitektur kan användas för att skala företags-AI-distributioner vid kanten, där ett centralt moln eller företagsdatacenter fungerar som ett nav och edge-in-a-box-enheten fungerar som en eker på en kantplats. Denna nav- och ekermodell, som sträcker sig över hybridmoln- och kantmiljöer, illustrerar bäst den balans som krävs för att optimalt utnyttja resurser som behövs för FM-drift (se figur 2).
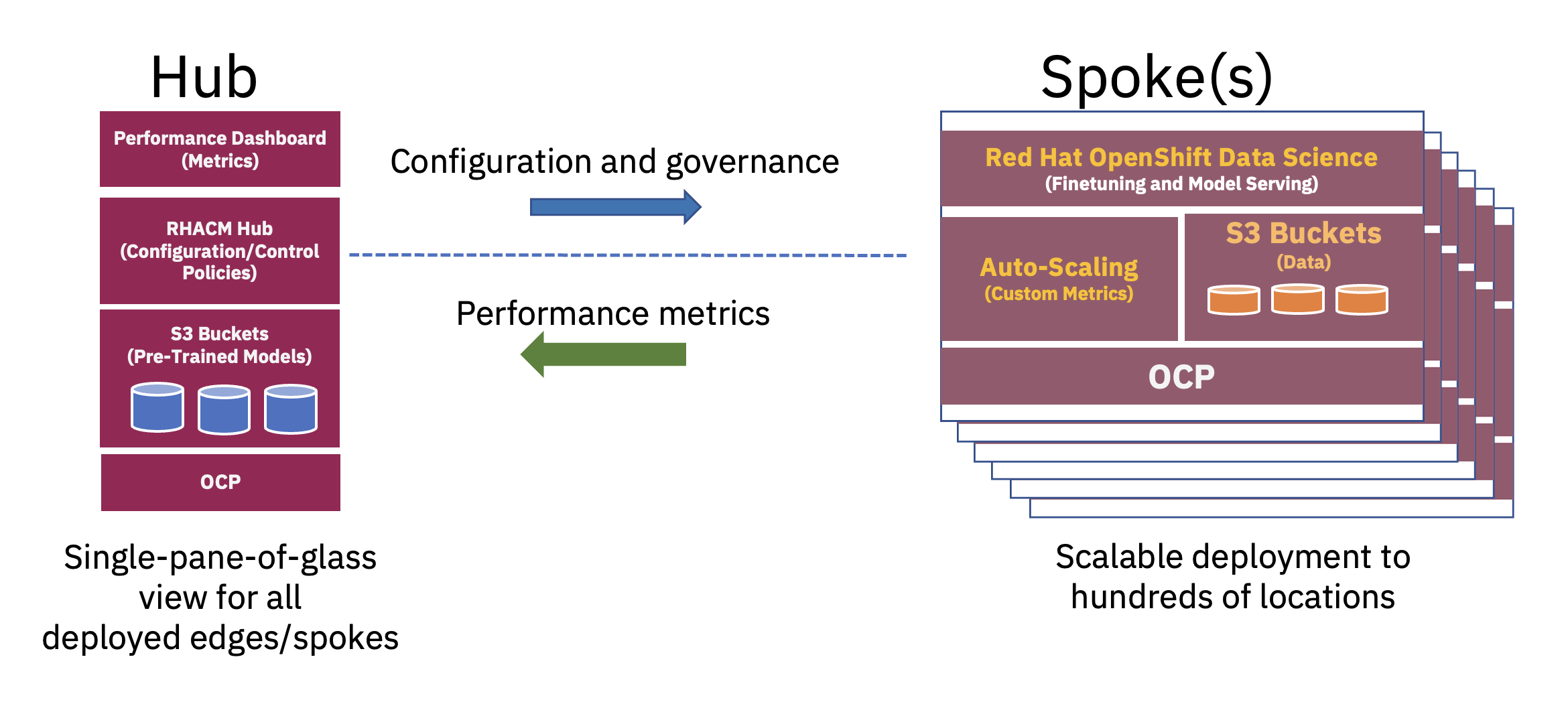
Förträning av dessa basmodeller för stora språk (LLM) och andra typer av grundmodeller som använder självövervakade tekniker på stora omärkta datauppsättningar kräver ofta betydande beräkningsresurser (GPU) och utförs bäst i ett nav. De praktiskt taget obegränsade beräkningsresurserna och stora datahögarna som ofta lagras i molnet möjliggör förträning av stora parametermodeller och kontinuerlig förbättring av noggrannheten hos dessa basmodeller.
Å andra sidan kan tuning av dessa bas-FM:er för nedströmsuppgifter – som bara kräver några tiotals eller hundratals märkta dataprover och slutledningsservering – utföras med endast ett fåtal GPU:er i företagskanten. Detta gör det möjligt för känslig märkt data (eller företagets kronjuveldata) för att säkert hålla sig inom företagets operativa miljö samtidigt som det minskar kostnaderna för dataöverföring.
Genom att använda en fullstack-metod för att distribuera applikationer till kanten kan en datavetare utföra finjustering, testning och driftsättning av modellerna. Detta kan åstadkommas i en enda miljö samtidigt som utvecklingslivscykeln för att servera nya AI-modeller för slutanvändarna krymper. Plattformar som Red Hat OpenShift Data Science (RHODS) och den nyligen tillkännagivna Red Hat OpenShift AI tillhandahåller verktyg för att snabbt utveckla och distribuera produktionsklara AI-modeller i distribuerat moln och kantmiljöer.
Slutligen, att servera den finjusterade AI-modellen på företagskanten minskar avsevärt latensen som ofta förknippas med förvärv, överföring, transformation och bearbetning av data. Att frikoppla förträningen i molnet från finjustering och slutledning på kanten sänker den totala driftskostnaden genom att minska den tid som krävs och kostnaderna för dataöverföring som är förknippade med en slutledningsuppgift (se figur 3).
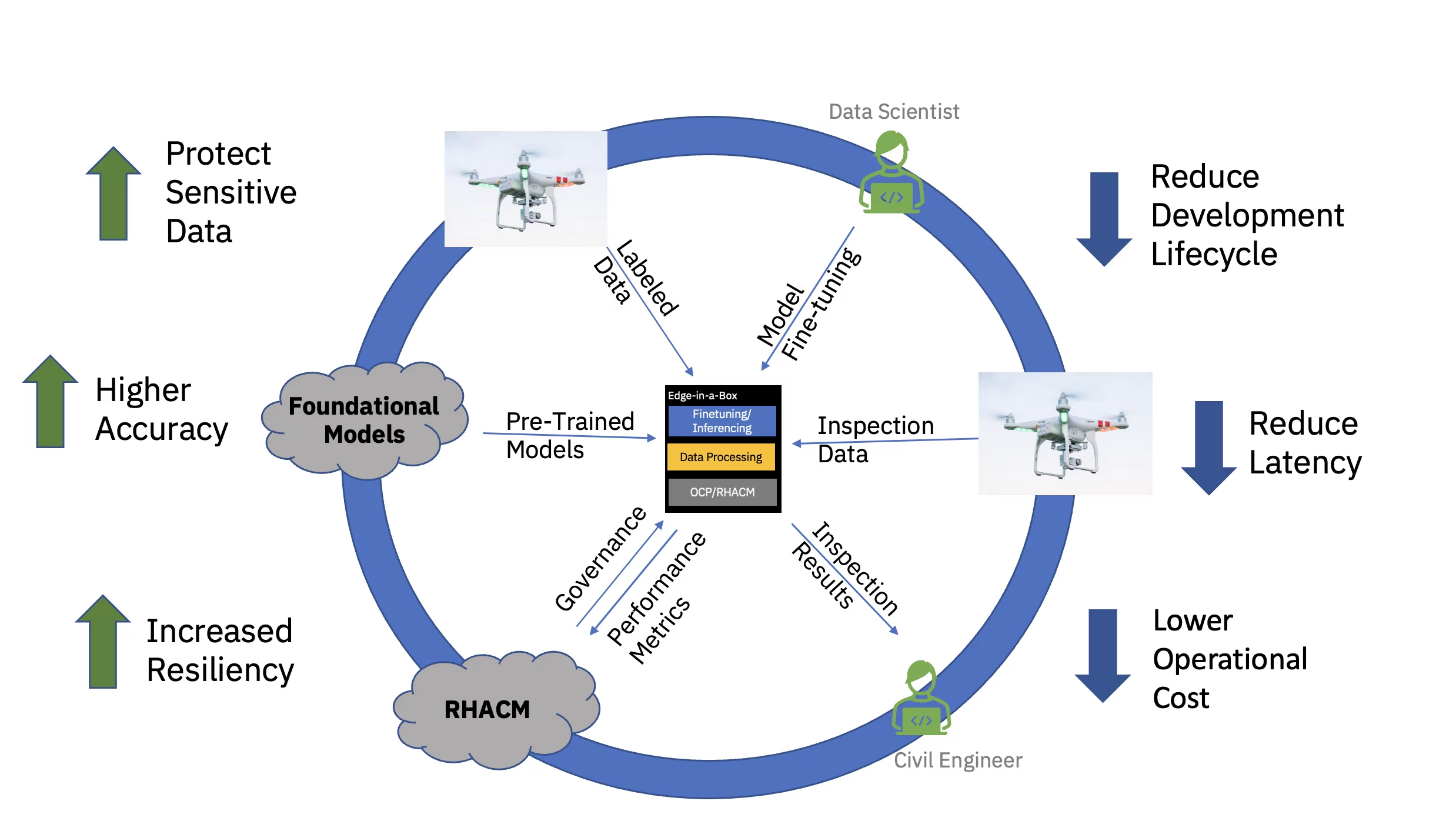
För att demonstrera detta värdeförslag från början till slut finjusterades en exemplarisk vision-transformatorbaserad grundmodell för civil infrastruktur (förutbildad med offentliga och anpassade branschspecifika datauppsättningar) och distribuerades för slutledning på en kant med tre noder (ekrade) klunga. Programvaran inkluderade Red Hat OpenShift Container Platform och Red Hat OpenShift Data Science. Detta kantkluster var också kopplat till en instans av Red Hat Advanced Cluster Management for Kubernetes (RHACM) nav som kördes i molnet.
Zero-touch provisionering
Policybaserad, noll-touch provisionering gjordes med Red Hat Advanced Cluster Management for Kubernetes (RHACM) via policyer och placeringstaggar, som binder specifika kantkluster till en uppsättning programvarukomponenter och konfigurationer. Dessa programvarukomponenter – som sträcker sig över hela stacken och täcker dator, lagring, nätverk och AI-arbetsbelastningen – installerades med olika OpenShift-operatörer, tillhandahållande av erforderliga applikationstjänster och S3 Bucket (lagring).
Den förutbildade grundmodellen (FM) för civil infrastruktur finjusterades via en Jupyter Notebook inom Red Hat OpenShift Data Science (RHODS) med hjälp av märkta data för att klassificera sex typer av defekter som hittats på betongbroar. Inferensservering av denna finjusterade FM demonstrerades också med hjälp av en Triton-server. Dessutom gjordes övervakning av tillståndet för detta kantsystem möjlig genom att aggregera observerbarhetsmått från hårdvaru- och mjukvarukomponenterna via Prometheus till den centrala RHACM-instrumentbrädan i molnet. Civila infrastrukturföretag kan distribuera dessa FM:er vid sina kantplatser och använda drönarbilder för att upptäcka defekter i nästan realtid – vilket påskyndar tiden till insikt och minskar kostnaderna för att flytta stora volymer högupplöst data till och från molnet.
Sammanfattning
Kombinera IBM watsonx data- och AI-plattformsfunktioner för grundmodeller (FM) med en edge-in-a-box-apparat gör att företag kan köra AI-arbetsbelastningar för FM-finjustering och slutledning vid den operativa kanten. Denna apparat kan hantera komplexa användningsfall direkt, och den bygger nav-och-eker-ramverket för centraliserad hantering, automatisering och självbetjäning. Edge FM-distributioner kan reduceras från veckor till timmar med upprepad framgång, högre motståndskraft och säkerhet.
Se till att kolla in alla avbetalningar i den här serien av blogginlägg om edge computing:
Mer från Cloud




- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.ibm.com/blog/foundational-models-at-the-edge/
- : har
- :är
- :inte
- :var
- $UPP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Om oss
- accelerera
- tillgång
- åstadkommit
- noggrannhet
- förvärv
- tvärs
- handlingar
- anpassat
- Dessutom
- adress
- adresser
- Antagande
- avancerat
- framsteg
- reklam
- AI
- AI-antagande
- AI-modeller
- AI-plattform
- Stöd
- algoritmer
- Alla
- tillåter
- tillåter
- också
- Mitt i
- mängd
- mängder
- amp
- an
- analys
- analytics
- och
- meddelade
- vilken som helst
- var som helst
- Ansökan
- tillämpningar
- tillvägagångssätt
- arkitektur
- ÄR
- array
- Artikeln
- konstgjord
- artificiell intelligens
- Konstgjord intelligens (AI)
- AS
- associerad
- At
- Författaren
- Automatiserad
- Automation
- tillgänglig
- Avenue
- tillbaka
- Balansera
- Bank
- Banker
- bas
- BE
- därför att
- blir
- passande
- varit
- Börjar
- Där vi får lov att vara utan att konstant prestera,
- tro
- BÄST
- binda
- Blogg
- Blogginlägg
- bloggar
- båda
- Box
- broar
- Föra
- Bringar
- bred
- brett
- Byggnad
- bygger
- byggt
- företag
- by
- KAN
- kapacitet
- kapital
- Fångande
- kol
- kortet
- Kort
- fall
- KATT
- kategorier
- Orsak
- Centrum
- centrala
- Centralbanken
- centralbankens digitala valutor
- centraliserad
- kedja
- utmaningar
- byta
- byte
- ta
- val
- cirklar
- CIS
- civila
- klass
- klassificera
- klar
- klienter
- nära
- cloud
- kluster
- färg
- färgstarka
- kombinera
- konkurrenskraftig
- komplex
- Komplexiteten
- Efterlevnad
- komponenter
- Compute
- databehandling
- konfiguration
- konfigurerad
- anslutna
- Anslutningar
- består
- Behållare
- fortsätta
- kontroll
- Pris
- Kostar
- kunde
- beläggning
- kryptovaluta
- CSS
- valutor
- beställnings
- kund
- kundupplevelse
- Kunder
- instrumentbräda
- datum
- Data Center
- Dataplattform
- datavetenskap
- datavetare
- datauppsättningar
- Datum
- dedicerad
- Standard
- definitioner
- leverera
- demonstrera
- demonstreras
- distribuera
- utplacerade
- utplacera
- utplacering
- distributioner
- beskriven
- beskrivning
- utformade
- utveckla
- utvecklade
- Utveckling
- digital
- digitala valutor
- digitalisering
- Störningar
- störande
- störande
- distribueras
- distrikt
- domän
- domäner
- gjort
- driv
- drivande
- drönare
- varje
- lätt
- ekosystemet
- kant
- kanten beräkning
- UPPHÖJA
- förhöjd
- möjliggöra
- möjliggör
- änden
- början till slut
- ingenjör
- Teknik
- ange
- Företag
- företag
- inkommande
- Miljö
- miljöer
- Era
- speciellt
- etc
- Eter (ETH)
- Även
- händelser
- Varje
- utvecklats
- Granskning
- exempel
- exekvera
- existerar
- Utgång
- dyra
- erfarenhet
- experter
- Förklarbar AI
- förklara
- sträcker
- extremt
- faktorer
- SNABB
- snabbare
- få
- fält
- Figur
- finansiella
- Finansiella institut
- finansiering
- Förnamn
- golv
- följer
- efter
- typsnitt
- För
- förgrunden
- hittade
- fundament
- fraktion
- Ramverk
- från
- full
- Full stack
- Vidare
- allmänhet
- genereras
- Generatorn
- geografisk
- Geopolitik
- Ge
- Välgörenhet
- världshandel
- styrning
- GPU
- GPUs
- Rutnät
- sidan
- hantera
- hårdvara
- har
- Har
- Hälsa
- höjd
- hjälpa
- hjälpa
- hjälper
- högupplöst
- högre
- höggradigt
- historia
- värd
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- Nav
- Människa
- Hundratals
- Hybrid
- hybrid moln
- IBM
- IBM Cloud
- ICO
- IKON
- illustrerar
- bild
- Inverkan
- vikt
- förbättring
- in
- innefattar
- ingår
- ökande
- alltmer
- index
- industriell
- industrier
- industrin
- branschspecifika
- inflation
- Böjning
- Böjpunkt
- påverkas
- Infrastruktur
- Initiativ
- Innovation
- innovativa
- ingångar
- insikter
- exempel
- institutioner
- integrerade
- Intelligens
- inneboende
- införa
- IT
- IT-support
- Journeys
- jpg
- hoppa
- Jupyter Notebook
- bara
- bara en
- hålls
- Nyckel
- Kubernetes
- märkning
- språk
- Large
- till stor del
- Latens
- senaste
- skikt
- ledande
- LÄRA SIG
- inlärning
- Hävstång
- livscykel
- tycka om
- gränslös
- linux
- lokal
- locale
- läge
- platser
- Lång
- se
- Maskinen
- maskininlärning
- gjord
- bibehålla
- göra
- GÖR
- hantera
- ledning
- Produktion
- många
- märkning
- massiv
- Master
- Materia
- max-bredd
- mekanismer
- metoder
- Metrics
- min
- minimerande
- minuter
- ML
- Mobil
- modell
- modeller
- Modern Konst
- modernisering
- modernisera
- Övervaka
- övervakning
- mer
- rörelse
- rörliga
- namn
- Navigering
- Nära
- nödvändigt för
- Behöver
- behövs
- behov
- nät
- Nya
- Nästa
- nlp
- anteckningsbok
- inget
- nu
- antal
- talrik
- of
- erbjuda
- Ofta
- on
- ONE
- endast
- öppet
- öppnade
- operativa
- Verksamhet
- operatörer
- optimerad
- or
- organisation
- Övriga
- vår
- ut
- övergripande
- paket
- sida
- parameter
- betalning
- betalningsmetoder
- betalningar
- utföra
- utfört
- PHP
- placering
- plattform
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- plugin
- Punkt
- Strategier
- policy
- placera
- möjlig
- Inlägg
- inlägg
- potentiell
- kraft
- den mäktigaste
- Förutsägelser
- Innan
- privatpolicy
- privat
- problem
- bearbetning
- producera
- professionell
- förslag
- ge
- allmän
- Tryck
- område
- snabbt
- Läsning
- realtid
- nyligen
- post
- inspelning
- Red
- Red Hat
- minska
- Minskad
- minskar
- reducerande
- föreskrifter
- Tillsynsmyndigheter
- regulatorer
- relaterad
- avlägsnas
- repeterbar
- kräver
- Obligatorisk
- Krav
- erforderlig
- forskning
- Resurser
- respons
- ansvarig
- mottaglig
- detaljhandeln
- Rise
- robotar
- Körning
- rinnande
- på ett säkert sätt
- Samma
- skalbarhet
- Skala
- skala ai
- skalning
- Vetenskap
- Forskare
- screen
- skript
- Andra
- säkert
- säkerhet
- se
- se
- Val
- Självbetjäning
- känslig
- SEO
- September
- Serier
- server
- service
- Tjänster
- portion
- session
- sessioner
- in
- flera
- Dela
- show
- signifikant
- signifikant
- liknande
- eftersom
- Singapore
- enda
- enda miljö
- webbplats
- Områden
- SEX
- färdigheter
- Small
- EMS
- SMF
- Mjukvara
- mjukvarukomponenter
- lösning
- suveränitet
- Utrymme
- spänning
- specifik
- specifikt
- Sponsrade
- stapel
- starta
- state-of-the-art
- bo
- Steg
- förvaring
- lagra
- lagras
- lagrar
- Storm
- studio
- ämne
- framgång
- sådana
- Föreslår
- leverera
- leveranskedjan
- stödja
- säker
- system
- Ta
- tagen
- uppgift
- uppgifter
- tekniker
- Teknologi
- Telco
- Temenos
- tiotals
- Terraform
- testade
- Testning
- den där
- Smakämnen
- deras
- tema
- Där.
- Dessa
- de
- detta
- Genom
- tid
- tid
- gånger
- Titel
- till
- i dag
- tillsammans
- toolkit
- verktyg
- topp
- handla
- traditionell
- Tåg
- tränad
- Utbildning
- överföring
- Förvandla
- Transformation
- transformationer
- transparent
- Triton
- två
- Typ
- typer
- avfyrade
- Uppdatering
- Uppdateringar
- URL
- us
- användning
- Begagnade
- användare
- med hjälp av
- utnyttja
- utnyttjas
- Värdefulla
- värde
- värdeerbjudande
- mängd
- olika
- Omfattande
- via
- utsikt
- praktiskt taget
- volym
- volymer
- W
- väntar
- plånbok
- var
- Våg
- Sätt..
- sätt
- we
- vecka
- veckor
- Vad
- Vad är
- när
- som
- medan
- VEM
- varför
- bred
- Brett utbud
- med
- inom
- kvinna
- Wordpress
- Arbete
- arbetsflöden
- arbetssätt
- skulle
- skriven
- Din
- zephyrnet











