Med Amazon EMR 6.15 sjösatte vi AWS Lake Formation baserade finkorniga åtkomstkontroller (FGAC) på Open Table Formats (OTF), inklusive Apache Hudi, Apache Iceberg och Delta lake. Detta gör att du kan förenkla säkerhet och styrning över transaktionsdatasjöar genom att tillhandahålla åtkomstkontroller på tabell-, kolumn- och radnivåbehörigheter med dina Apache Spark-jobb. Många stora företagsföretag försöker använda sin transaktionsdatasjö för att få insikter och förbättra beslutsfattandet. Du kan bygga en sjöhusarkitektur med Amazon EMR integrerad med Lake Formation för FGAC. Denna kombination av tjänster gör att du kan utföra dataanalys på din transaktionsdatasjö samtidigt som du säkerställer säker och kontrollerad åtkomst.
Amazon EMR-postserverkomponenten stöder datafiltreringsfunktioner på tabell-, kolumn-, rad-, cell- och kapslade attributnivåer. Det utökar stödet till formaten Hive, Apache Hudi, Apache Iceberg och Delta lake för både läsning (inklusive tidsresor och inkrementell fråga) och skrivoperationer (på DML-satser som INSERT). Dessutom, med version 6.15, introducerar Amazon EMR åtkomstkontrollskydd för sitt applikationswebbgränssnitt, såsom on-cluster Spark History Server, Yarn Timeline Server och Yarn Resource Manager UI.
I det här inlägget visar vi hur man implementerar FGAC på Apache Hudi tabeller med Amazon EMR integrerad med Lake Formation.
Användningsfall för transaktionsdatasjö
Amazon EMR-kunder använder ofta Open Table Formats för att stödja deras ACID-transaktions- och tidsresorsbehov i en datasjö. Genom att bevara historiska versioner ger datasjötidsresor fördelar som granskning och efterlevnad, dataåterställning och återställning, reproducerbar analys och datautforskning vid olika tidpunkter.
Ett annat populärt användningsfall för transaktionsdatasjö är inkrementell fråga. Inkrementell fråga hänvisar till en frågestrategi som fokuserar på att endast bearbeta och analysera nya eller uppdaterade data i en datasjö sedan den senaste frågan. Nyckelidén bakom inkrementella frågor är att använda metadata eller ändra spårningsmekanismer för att identifiera nya eller modifierade data sedan den senaste frågan. Genom att identifiera dessa ändringar kan frågemotorn optimera frågan för att endast bearbeta relevant data, vilket avsevärt minskar bearbetningstiden och resurskraven.
Lösningsöversikt
I det här inlägget visar vi hur man implementerar FGAC på Apache Hudi-tabeller med Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) integrerad med Lake Formation. Apache Hudi är ett ramverk för transaktionsdatasjöar med öppen källkod som avsevärt förenklar inkrementell databehandling och utveckling av datapipelines. Denna nya FGAC-funktion stöder alla OTF. Förutom att demonstrera med Hudi här, kommer vi att följa upp med andra OTF-tabeller med andra bloggar. Vi använder bärbara datorer in Amazon SageMaker Studio att läsa och skriva Hudi-data via olika användaråtkomstbehörigheter genom ett EMR-kluster. Detta återspeglar verkliga scenarier för dataåtkomst – till exempel om en ingenjörsanvändare behöver fullständig dataåtkomst för att felsöka på en dataplattform, medan dataanalytiker kanske bara behöver komma åt en delmängd av denna data som inte innehåller personlig identifierbar information (PII ). Integrering med Lake Formation via Amazon EMR runtime roll ger dig ytterligare möjlighet att förbättra din datasäkerhetsställning och förenklar datakontrollhanteringen för Amazon EMR-arbetsbelastningar. Denna lösning säkerställer en säker och kontrollerad miljö för dataåtkomst, som möter de olika behoven och säkerhetskraven för olika användare och roller i en organisation.
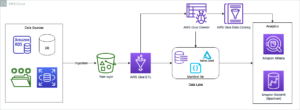
Följande diagram illustrerar lösningsarkitekturen.
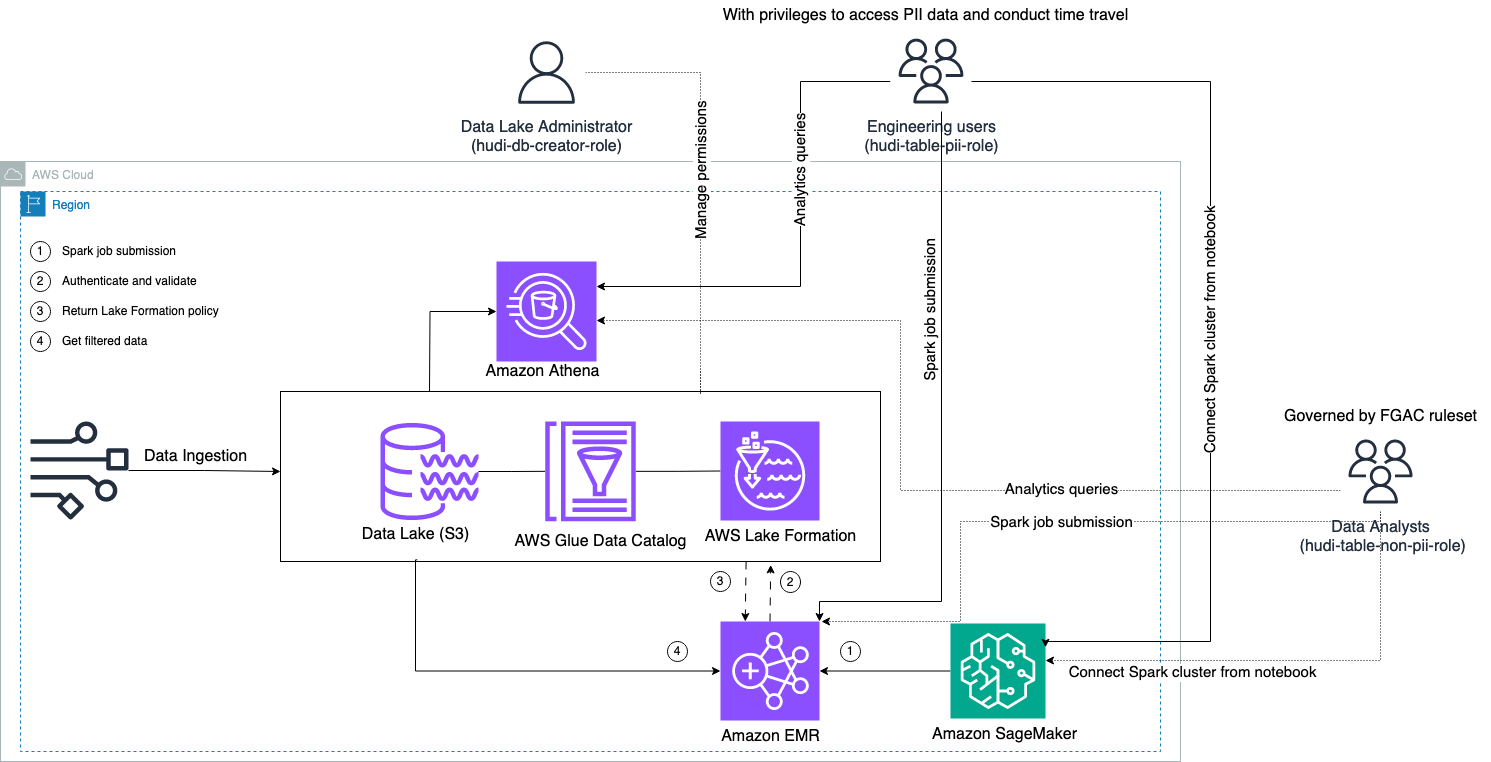
Vi genomför en dataintagsprocess för att infoga (uppdatera och infoga) en Hudi-datauppsättning till en Amazon enkel lagringstjänst (Amazon S3) bucket, och bevara eller uppdatera tabellschemat i AWS-lim Datakatalog. Med noll datarörelse kan vi fråga Hudi-tabellen som styrs av Lake Formation via olika AWS-tjänster, som t.ex. Amazonas Athena, Amazon EMR och Amazon SageMaker.
När användare skickar in ett Spark-jobb via EMR-klusterslutpunkter (EMR Steps, Livy, EMR Studio och SageMaker), validerar Lake Formation sina privilegier och instruerar EMR-klustret att filtrera bort känslig data som PII-data.
Denna lösning har tre olika typer av användare med olika behörighetsnivåer för att komma åt Hudi-data:
- hudi-db-skapare-roll – Detta används av datasjöadministratören som har behörighet att utföra DDL-operationer som att skapa, ändra och ta bort databasobjekt. De kan definiera datafiltreringsregler på Lake Formation för dataåtkomstkontroll på rad- och kolumnnivå. Dessa FGAC-regler säkerställer att datasjön är säker och uppfyller de datasekretessbestämmelser som krävs.
- hudi-table-pii-roll – Det här används av ingenjörsanvändare. De tekniska användarna kan utföra tidsresor och inkrementella frågor på både Copy-on-Write (CoW) och Merge-on-Read (MoR). De har också behörighet att komma åt PII-data baserat på eventuella tidsstämplar.
- hudi-table-icke-pii-roll – Det här används av dataanalytiker. Dataanalytikers rättigheter för dataåtkomst styrs av FGAC-auktoriserade regler som kontrolleras av datasjöadministratörer. De har inte synlighet på kolumner som innehåller PII-data som namn och adresser. Dessutom kan de inte komma åt rader med data som inte uppfyller vissa villkor. Till exempel kan användarna bara komma åt datarader som tillhör deras land.
Förutsättningar
Du kan ladda ner de tre anteckningsböckerna som används i det här inlägget från GitHub repo.
Innan du distribuerar lösningen, se till att du har följande:
Slutför följande steg för att ställa in dina behörigheter:
- Logga in på ditt AWS-konto med din admin IAM-användare.
Se till att du är ius-east-1Område.
- Skapa en S3 hink i
us-east-1Region (t.ex.emr-fgac-hudi-us-east-1-<ACCOUNT ID>).
Därefter aktiverar vi Lake Formation by ändra standardbehörighetsmodellen.
- Logga in på Lake Formation-konsolen som administratörsanvändare.
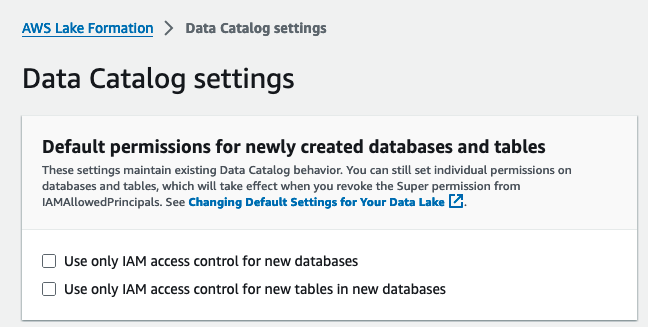
- Välja Datakataloginställningar under Administration i navigeringsfönstret.
- Enligt Standardbehörigheter för nyskapade databaser och tabeller, avmarkera Använd endast IAM-åtkomstkontroll för nya databaser och Använd endast IAM-åtkomstkontroll för nya tabeller i nya databaser.
- Välja Save.
Alternativt måste du återkalla IAMAllowedPrincipals på resurser (databaser och tabeller) som skapats om du startade Lake Formation med standardalternativet.
Slutligen skapar vi ett nyckelpar för Amazon EMR.
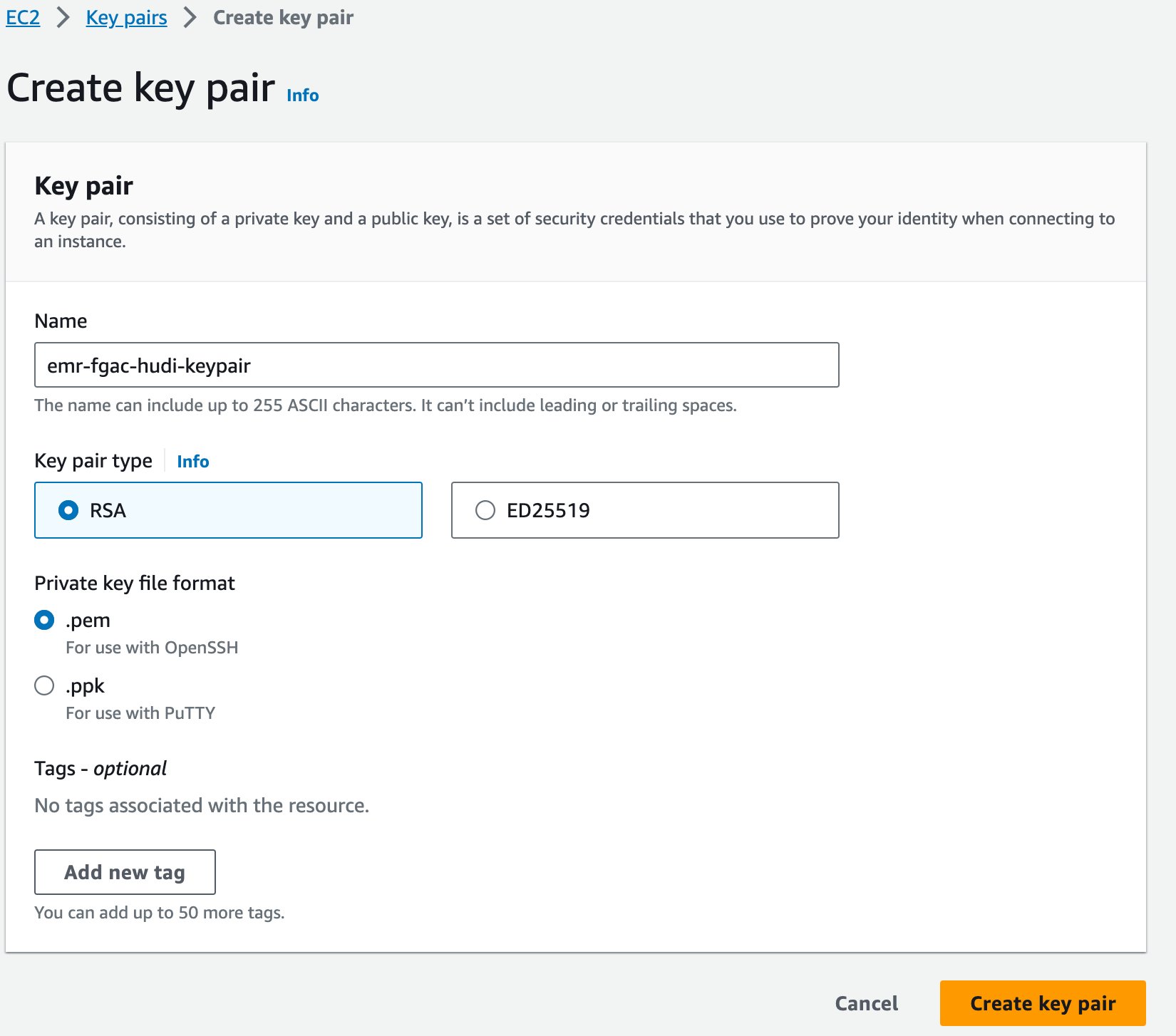
- Välj på Amazon EC2-konsolen Nyckelpar i navigeringsfönstret.
- Välja Skapa nyckelpar.
- För Namn , ange ett namn (till exempel
emr-fgac-hudi-keypair). - Välja Skapa nyckelpar.
Det genererade nyckelparet (för det här inlägget, emr-fgac-hudi-keypair.pem) sparas på din lokala dator.
Därefter skapar vi en AWS Cloud9 interaktiv utvecklingsmiljö (IDE).
- På AWS Cloud9-konsolen väljer du Miljöer i navigeringsfönstret.
- Välja Skapa miljö.
- För Namn ¸ ange ett namn (till exempel
emr-fgac-hudi-env). - Behåll övriga inställningar som standard.
- Välja Skapa.
- När IDE är klar, välj Öppen för att öppna den.
- I AWS Cloud9 IDE, på Fil meny, välj Ladda upp lokala filer.

- Ladda upp nyckelparsfilen (
emr-fgac-hudi-keypair.pem). - Välj plustecknet och välj Ny terminal.
- Mata in följande kommandorader i terminalen:
Observera att exempelkoden är ett bevis på konceptet endast i demonstrationssyfte. För produktionssystem, använd en betrodd certifikatutfärdare (CA) för att utfärda certifikat. Hänvisa till Tillhandahåller certifikat för kryptering av data under överföring med Amazon EMR-kryptering för mer information.
Distribuera lösningen via AWS CloudFormation
Vi tillhandahåller en AWS molnformation mall som automatiskt ställer in följande tjänster och komponenter:
- En S3 hink för datasjön. Den innehåller provuppsättningen TPC-DS.
- Ett EMR-kluster med säkerhetskonfiguration och offentlig DNS aktiverat.
- EMR runtime IAM-roller med Lake Formation finkorniga behörigheter:
- -hudi-db-creator-rolle – Den här rollen används för att skapa Apache Hudi-databas och tabeller.
- -hudi-table-pii-roll – Den här rollen ger behörighet att fråga alla kolumner i Hudi-tabeller, inklusive kolumner med PII.
- -hudi-table-non-pii-roll – Den här rollen ger behörighet att fråga Hudi-tabeller som har filtrerat bort PII-kolumner efter Lake Formation.
- SageMaker Studio exekveringsroller som gör att användarna kan anta sina motsvarande EMR runtime roller.
- Nätverksresurser som VPC, undernät och säkerhetsgrupper.
Utför följande steg för att distribuera resurserna:
- Välja Snabb skapa stack för att starta CloudFormation-stacken.
- För Stapla namn, ange ett stacknamn (t.ex.
rsv2-emr-hudi-blog). - För Ec2KeyPair, ange namnet på ditt nyckelpar.
- För IdleTimeout, ange en inaktiv timeout för EMR-klustret för att undvika att betala för klustret när det inte används.
- För InitS3Bucket, ange S3-bucket-namnet du skapade för att spara Amazon EMR-krypteringscertifikatet .zip-fil.
- För S3CertsZip, ange S3 URI för Amazon EMR-krypteringscertifikatets .zip-fil.
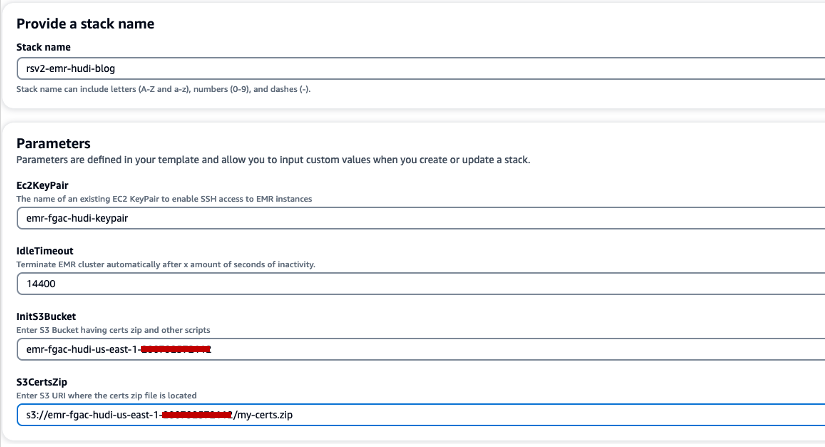
- Välja Jag erkänner att AWS CloudFormation kan skapa IAM-resurser med anpassade namn.
- Välja Skapa stack.
Implementeringen av CloudFormation-stacken tar cirka 10 minuter.
Konfigurera Lake Formation för Amazon EMR-integration
Slutför följande steg för att ställa in Lake Formation:
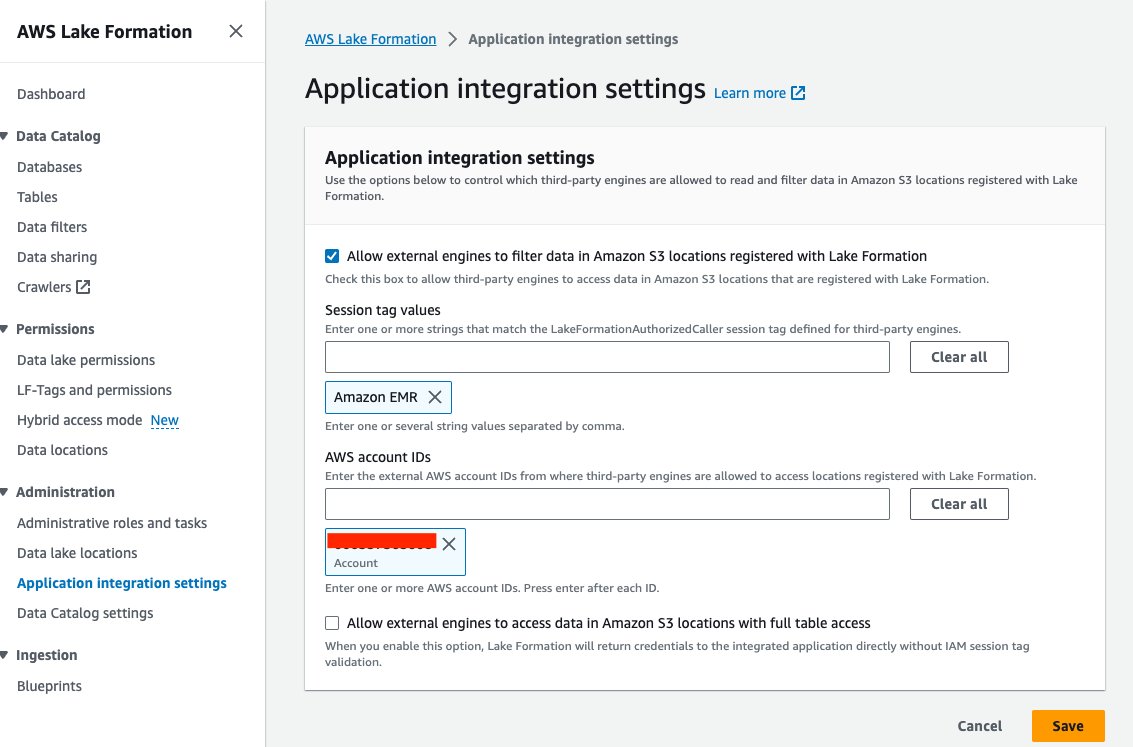
- Välj på Lake Formation-konsolen Inställningar för applikationsintegration under Administration i navigeringsfönstret.
- Välja Tillåt externa motorer att filtrera data på Amazon S3-platser som är registrerade hos Lake Formation.
- Välja Amazon EMR för Sessionstaggvärden.
- Ange ditt AWS-konto-ID för AWS-konto-ID.
- Välja Save.
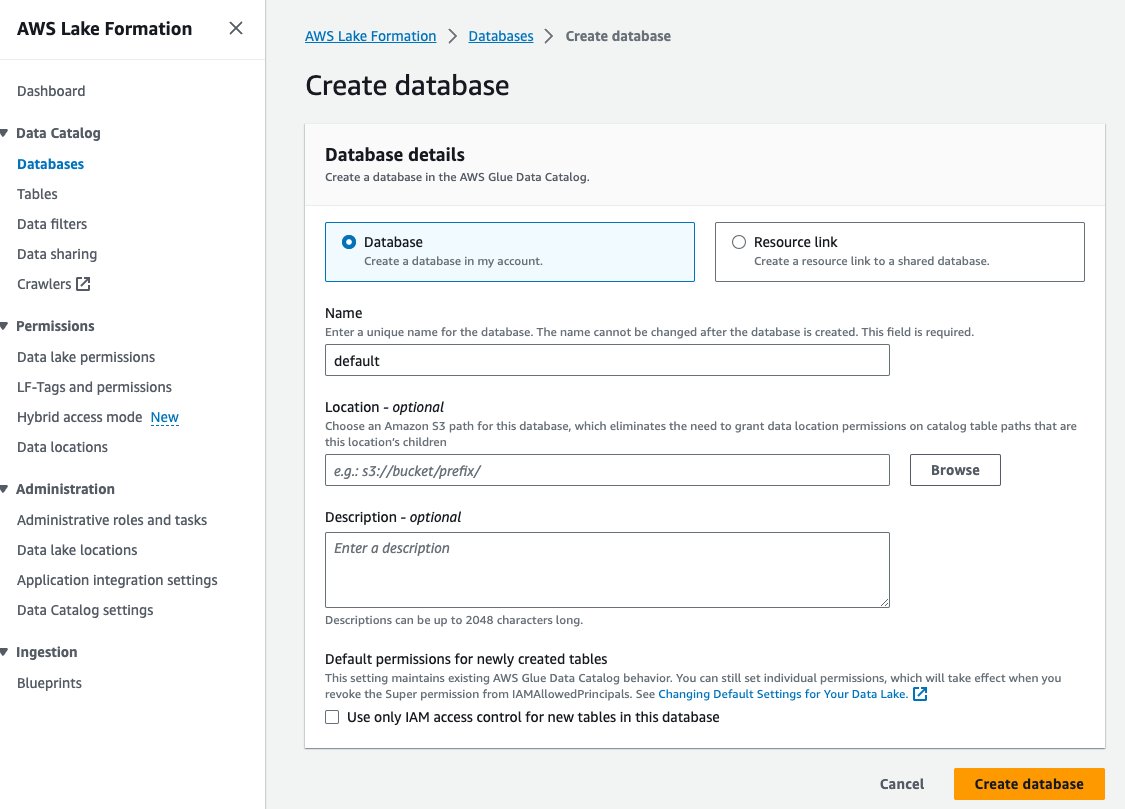
- Välja Databaser under Datakatalog i navigeringsfönstret.
- Välja Skapa databas.
- För Namn , ange standard.
- Välja Skapa databas.
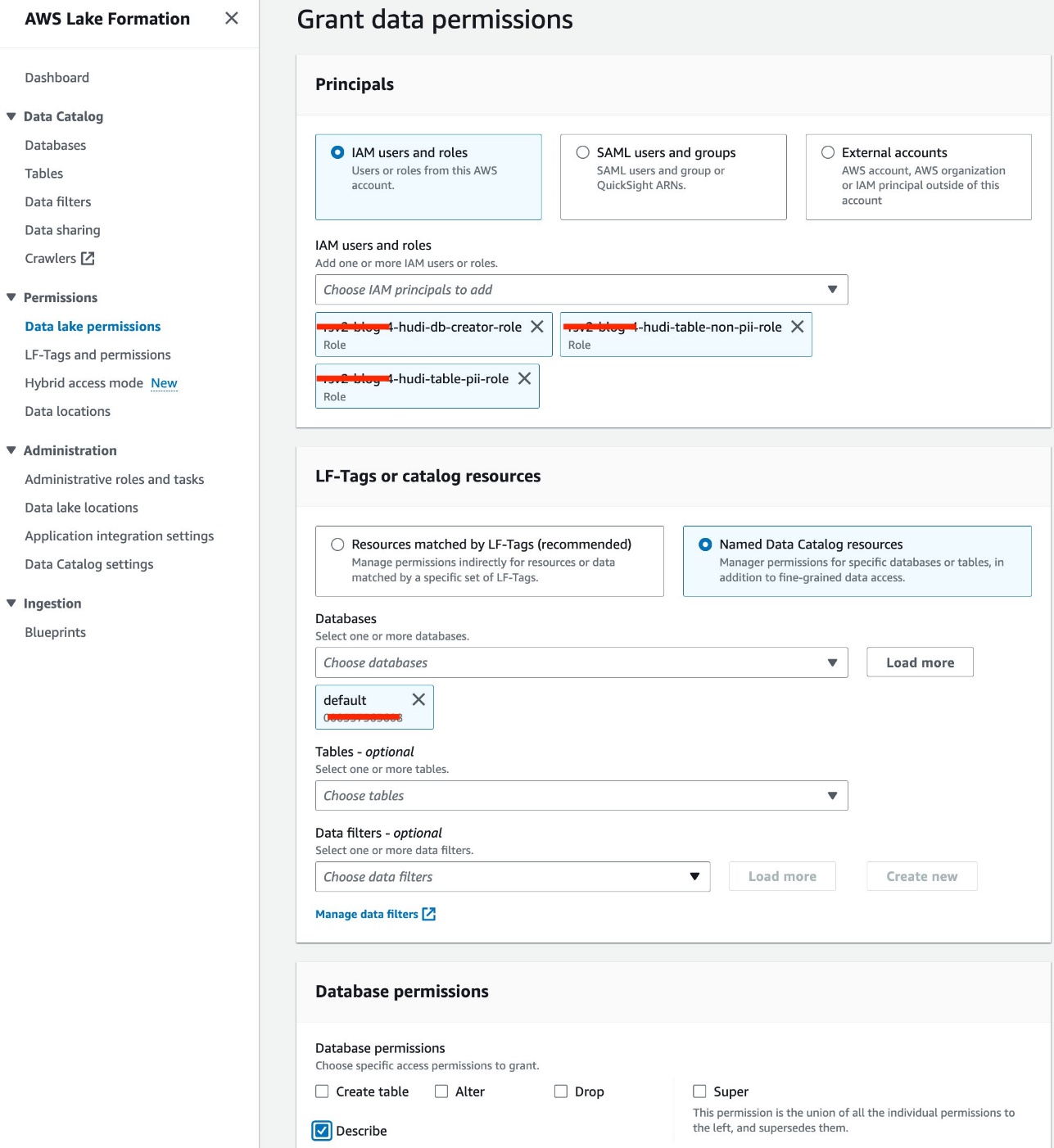
- Välja Data Lake-behörigheter under behörigheter i navigeringsfönstret.
- Välja Grant.
- Välja IAM-användare och roller.
- Välj dina IAM-roller.
- För Databaser, välj standard.
- För Databasbehörigheter, Välj Beskriv.
- Välja Grant.
Kopiera Hudi JAR-filen till Amazon EMR HDFS
Till använd Hudi med Jupyter-anteckningsböcker, måste du slutföra följande steg för EMR-klustret, vilket inkluderar att kopiera en Hudi JAR-fil från Amazon EMR lokala katalog till dess HDFS-lagring, så att du kan konfigurera en Spark-session för att använda Hudi:
- Auktorisera inkommande SSH-trafik (port 22).
- Kopiera värdet för Primär nod offentlig DNS (till exempel ec2-XXX-XXX-XXX-XXX.compute-1.amazonaws.com) från EMR-klustret Sammanfattning sektion.
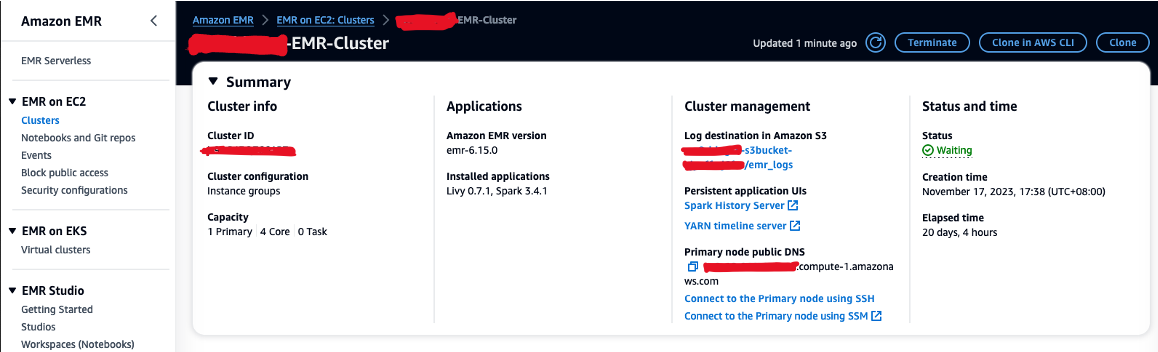
- Gå tillbaka till föregående AWS Cloud9-terminal som du använde för att skapa EC2-nyckelparet.
- Kör följande kommando till SSH till den primära EMR-noden. Byt ut platshållaren med ditt EMR DNS-värdnamn:
- Kör följande kommando för att kopiera Hudi JAR-filen till HDFS:
Skapa Hudi-databasen och tabellerna i Lake Formation
Nu är vi redo att skapa Hudi-databasen och tabellerna med FGAC aktiverad av EMR-runtime-rollen. De EMR runtime roll är en IAM-roll som du kan ange när du skickar ett jobb eller en fråga till ett EMR-kluster.
Ge tillstånd för att skapa databas
Låt oss först ge Lake Formation-databasskaparen tillstånd till<STACK-NAME>-hudi-db-creator-role:
- Logga in på ditt AWS-konto som administratör.
- Välj på Lake Formation-konsolen Administrativa roller och uppgifter under Administration i navigeringsfönstret.
- Bekräfta att din AWS-inloggningsanvändare har lagts till som datasjöadministratör.
- I Databas skapare avsnitt väljer Grant.
- För IAM-användare och rollerväljer
<STACK-NAME>-hudi-db-creator-role. - För Katalogbehörigheter, Välj Skapa databas.
- Välja Grant.
Registrera datasjöns plats
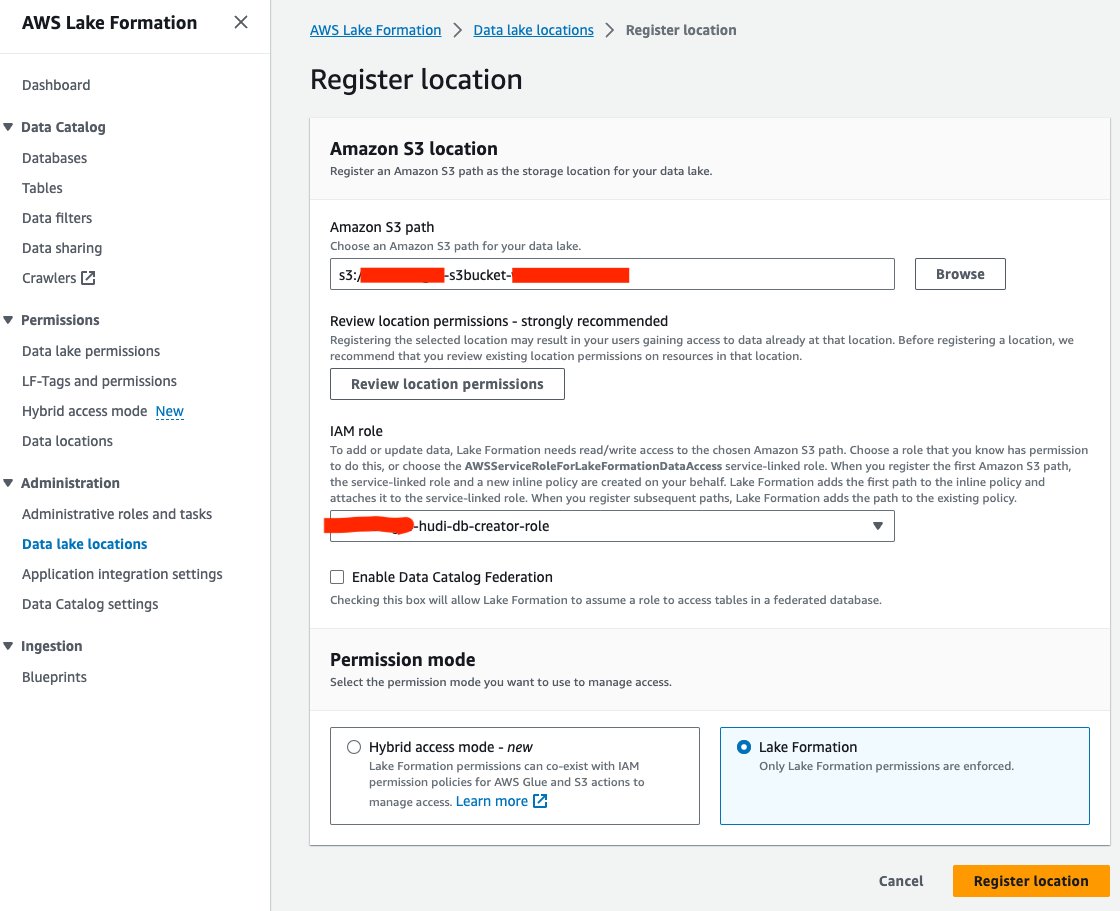
Låt oss sedan registrera S3-datasjöplatsen i Lake Formation:
- Välj på Lake Formation-konsolen Data sjö platser under Administration i navigeringsfönstret.
- Välja Registrera plats.
- För Amazon S3-väg, Välj Bläddra och välj datasjö S3-hinken. (
<STACK_NAME>s3bucket-XXXXXXX) skapad från CloudFormation-stacken. - För IAM-rollväljer
<STACK-NAME>-hudi-db-creator-role. - För Tillståndsläge, Välj Sjöformation.
- Välja Registrera plats.
Ge dataplatsbehörighet
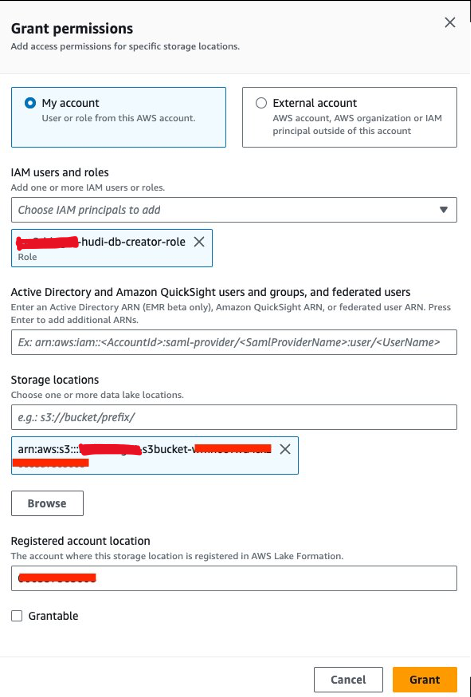
Därefter måste vi bevilja<STACK-NAME>-hudi-db-creator-roledataplatsbehörigheten:
- Välj på Lake Formation-konsolen Dataplatser under behörigheter i navigeringsfönstret.
- Välja Grant.
- För IAM-användare och rollerväljer
<STACK-NAME>-hudi-db-creator-role. - För Förvaringsplatser, skriv in S3-hinken (
<STACK_NAME>-s3bucket-XXXXXXX). - Välja Grant.
Anslut till EMR-klustret
Låt oss nu använda en Jupyter-anteckningsbok i SageMaker Studio för att ansluta till EMR-klustret med databasskaparen EMR-runtime-rollen:
- Välj på SageMaker-konsolen domäner i navigeringsfönstret.
- Välj domän
<STACK-NAME>-Studio-EMR-LF-Hudi. - På Starta menyn bredvid användarprofilen
<STACK-NAME>-hudi-db-creatorväljer Studio.
- Ladda ner anteckningsboken rsv2-hudi-db-creator-notebook.
- Välj uppladdningsikonen.
- Välj den nedladdade Jupyter-anteckningsboken och välj Öppen.
- Öppna den uppladdade anteckningsboken.
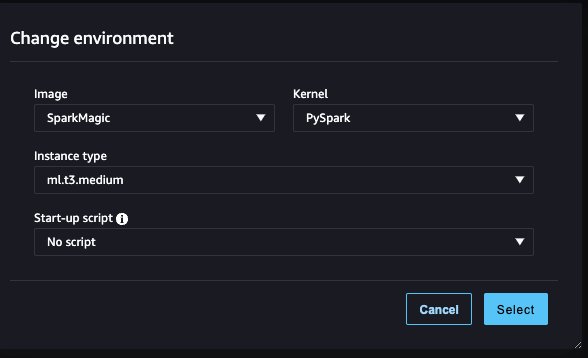
- För Bildväljer SparkMagic.
- För Kärnaväljer PySpark.
- Lämna de andra konfigurationerna som standard och välj Välja.
- Välja kluster för att ansluta till EMR-klustret.

- Välj EMR på EC2-kluster (
<STACK-NAME>-EMR-Cluster) skapad med CloudFormation-stacken. - Välja Kontakta.
- För EMR verkställande rollväljer
<STACK-NAME>-hudi-db-creator-role. - Välja Kontakta.
Skapa databas och tabeller
Nu kan du följa stegen i anteckningsboken för att skapa Hudi-databasen och tabellerna. De viktigaste stegen är följande:
- När du startar den bärbara datorn, konfigurera
“spark.sql.catalog.spark_catalog.lf.managed":"true"för att informera Spark om att spark_catalog skyddas av Lake Formation. - Skapa Hudi-tabeller med följande Spark SQL.
- Infoga data från källtabellen till Hudi-tabellerna.
- Infoga data igen i Hudi-tabellerna.
Fråga Hudi-tabellerna via Lake Formation med FGAC
När du har skapat Hudi-databasen och tabellerna är du redo att fråga tabellerna med hjälp av finkornig åtkomstkontroll med Lake Formation. Vi har skapat två typer av Hudi-tabeller: Copy-On-Write (COW) och Merge-On-Read (MOR). COW-tabellen lagrar data i ett kolumnformat (Parquet), och varje uppdatering skapar en ny version av filer under en skrivning. Detta innebär att Hudi för varje uppdatering skriver om hela filen, vilket kan vara mer resurskrävande men ger snabbare läsprestanda. MOR, å andra sidan, introduceras för fall där COW kanske inte är optimal, särskilt för skriv- eller förändringstunga arbetsbelastningar. I en MOR-tabell, varje gång det sker en uppdatering, skriver Hudi endast raden för den ändrade posten, vilket minskar kostnaden och möjliggör skrivningar med låg latens. Läsprestandan kan dock vara långsammare jämfört med COW-tabeller.
Ge tabellåtkomstbehörighet
Vi använder oss av IAM-rollen<STACK-NAME>-hudi-table-pii-roleför att fråga Hudi COW och MOR som innehåller PII-kolumner. Vi ger först åtkomst till bordet via Lake Formation:
- Välj på Lake Formation-konsolen Data Lake-behörigheter under behörigheter i navigeringsfönstret.
- Välja Grant.
- Välja
<STACK-NAME>-hudi-table-pii-roleför IAM-användare och roller. - Välj
rsv2_blog_hudi_db_1databas för Databaser. - För Bord, välj de fyra Hudi-tabellerna du skapade i Jupyter-anteckningsboken.
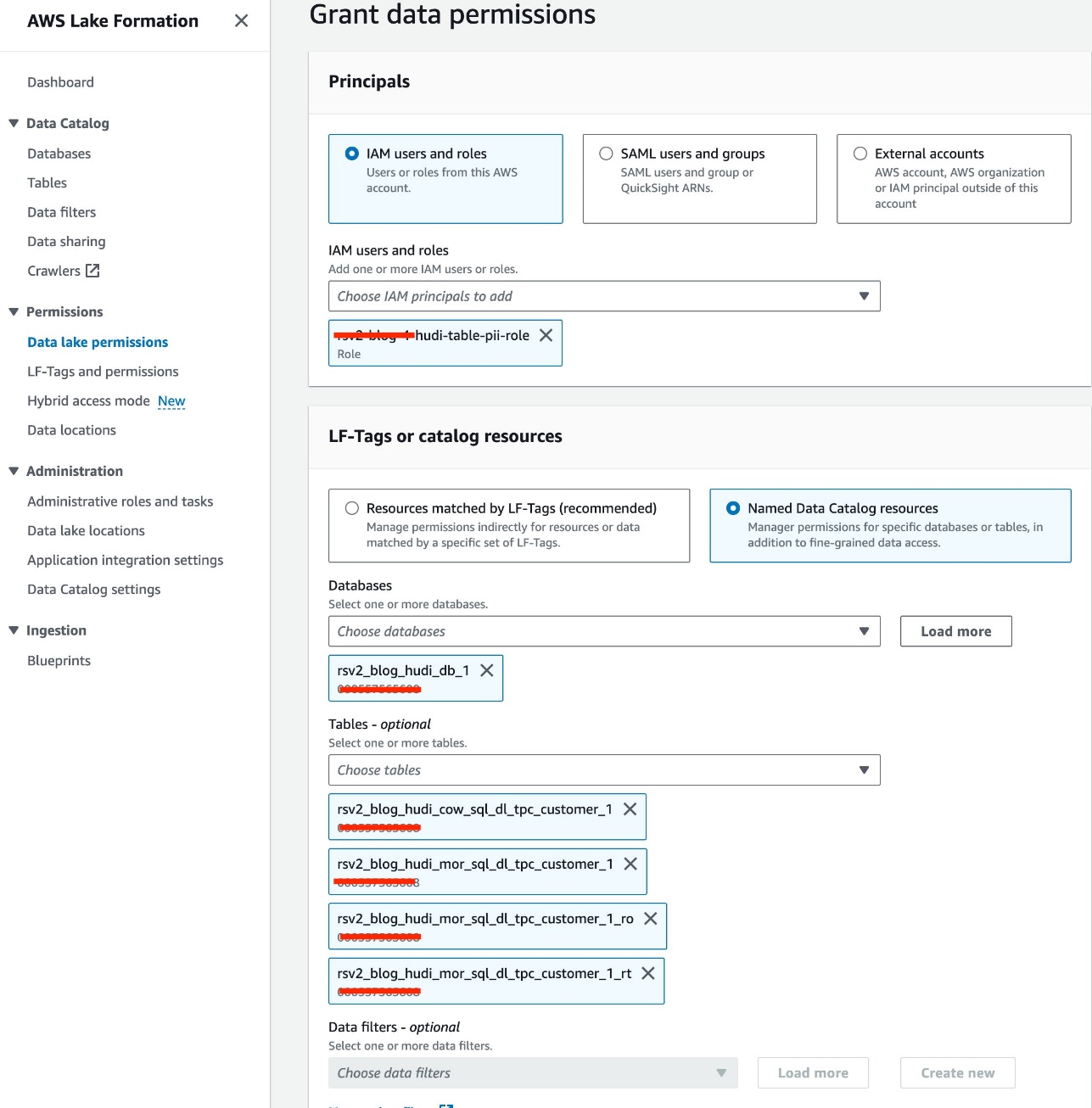
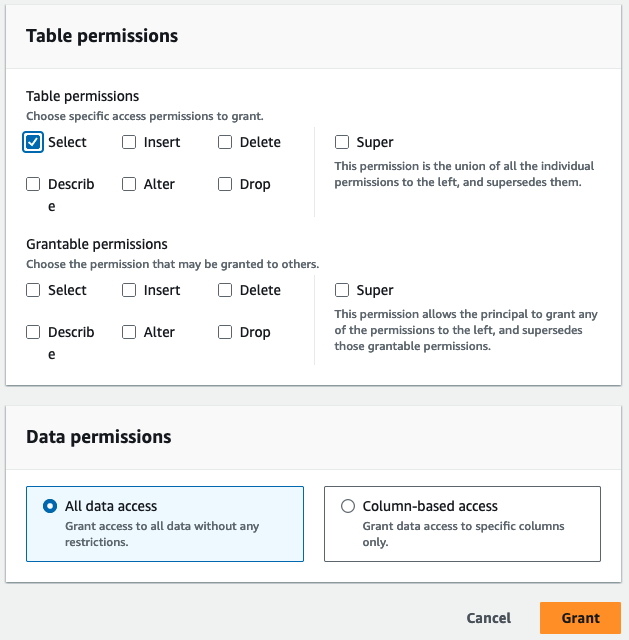
- För Tabellbehörigheter, Välj Välja.
- Välja Grant.
Fråga PII-kolumner
Nu är du redo att köra anteckningsboken för att fråga Hudi-tabellerna. Låt oss följa steg som liknar föregående avsnitt för att köra anteckningsboken i SageMaker Studio:
- På SageMaker-konsolen navigerar du till
<STACK-NAME>-Studio-EMR-LF-Hudidomän. - På Starta menyn bredvid
<STACK-NAME>-hudi-table-readeranvändarprofil, välj Studio. - Ladda upp den nedladdade anteckningsboken rsv2-hudi-table-pii-reader-notebook.
- Öppna den uppladdade anteckningsboken.
- Upprepa installationsstegen för notebook och anslut till samma EMR-kluster, men använd rollen
<STACK-NAME>-hudi-table-pii-role.
I det aktuella skedet måste FGAC-aktiverat EMR-kluster fråga Hudis commit-tidskolumn för att utföra inkrementella frågor och tidsresor. Den stöder inte Sparks "tidsstämpel från och med" syntax och Spark.read(). Vi arbetar aktivt med att införliva stöd för båda åtgärderna i framtida Amazon EMR-utgåvor med FGAC aktiverat.
Du kan nu följa stegen i anteckningsboken. Följande är några markerade steg:
- Kör en ögonblicksbildsfråga.
- Kör en inkrementell fråga.
- Kör en tidsresefråga.
- Kör MOR-läsoptimerade och realtidstabellfrågor.
Fråga Hudi-tabellerna med datafilter på kolumnnivå och radnivå
Vi använder oss av IAM-rollen<STACK-NAME>-hudi-table-non-pii-roleför att fråga Hudi-tabeller. Den här rollen får inte fråga efter kolumner som innehåller PII. Vi använder datafiltren Lake Formation på kolumnnivå och radnivå för att implementera finkornig åtkomstkontroll:
- Välj på Lake Formation-konsolen Datafilter under Datakatalog i navigeringsfönstret.
- Välja Skapa nytt filter.
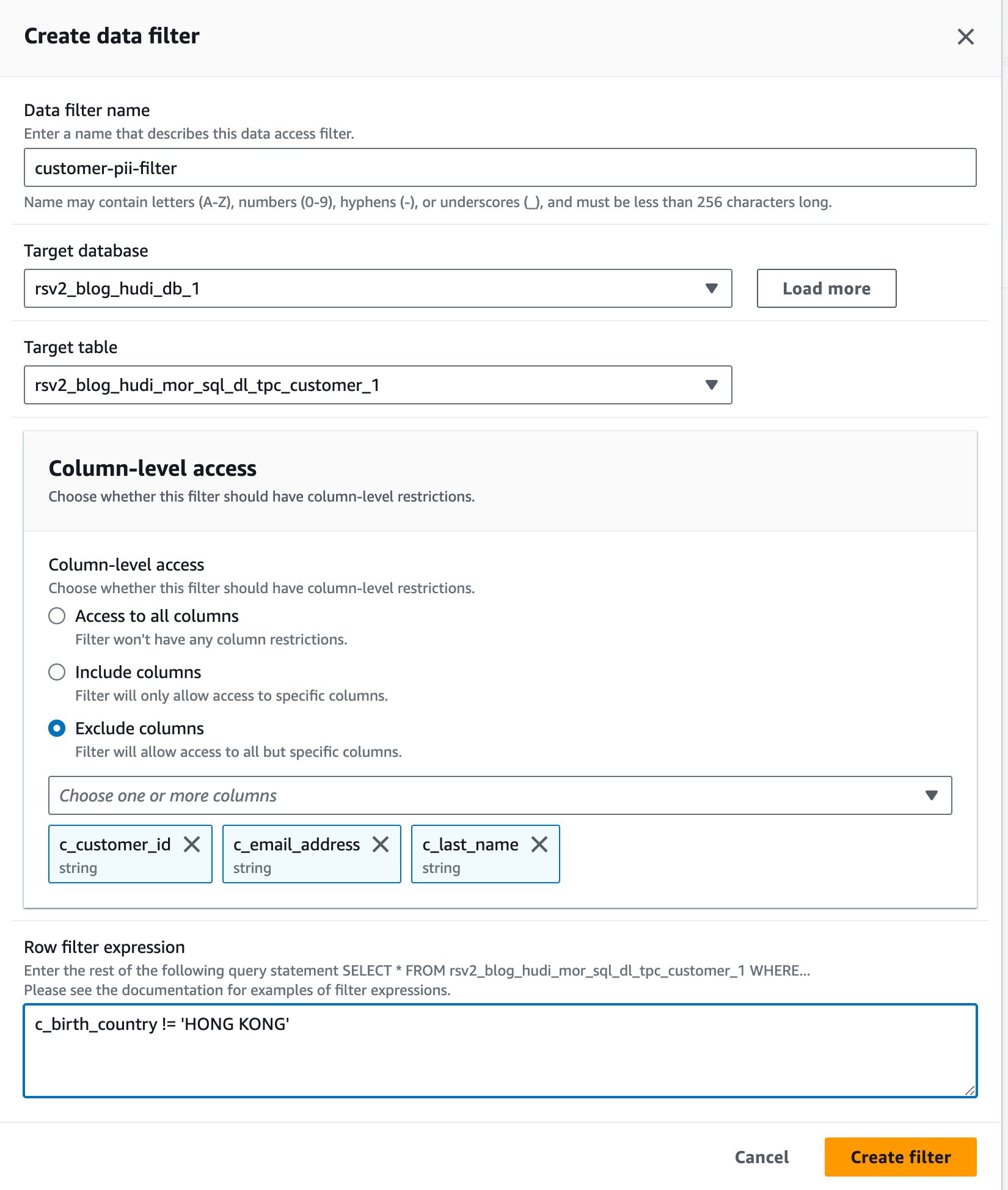
- För Datafilternamn, stiga på
customer-pii-filter. - Välja
rsv2_blog_hudi_db_1för Måldatabas. - Välja
rsv2_blog_hudi_mor_sql_dl_customer_1för Måltabell. - Välja Uteslut kolumner och välj
c_customer_id,c_email_addressochc_last_namekolumner. - ange
c_birth_country != 'HONG KONG'för Radfilteruttryck. - Välja Skapa filter.
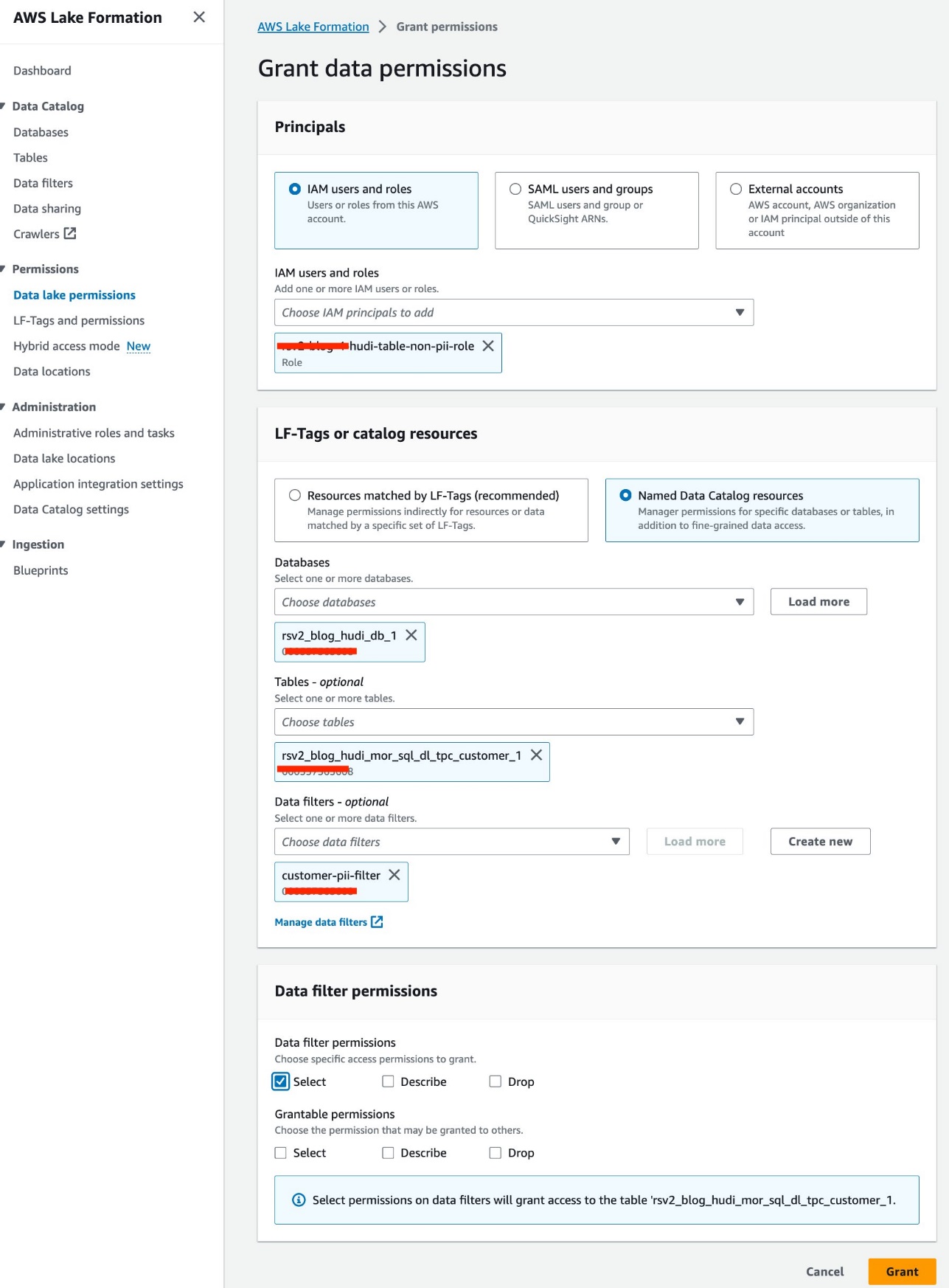
- Välja Data Lake-behörigheter under behörigheter i navigeringsfönstret.
- Välja Grant.
- Välja
<STACK-NAME>-hudi-table-non-pii-roleför IAM-användare och roller. - Välja
rsv2_blog_hudi_db_1för Databaser. - Välja
rsv2_blog_hudi_mor_sql_dl_tpc_customer_1för Bord. - Välja
customer-pii-filterför Datafilter. - För Datafilterbehörigheter, Välj Välja.
- Välja Grant.
Låt oss följa liknande steg för att köra anteckningsboken i SageMaker Studio:
- På SageMaker-konsolen, navigera till domänen
Studio-EMR-LF-Hudi. - På Starta meny för
hudi-table-readeranvändarprofil, välj Studio. - Ladda upp den nedladdade anteckningsboken rsv2-hudi-table-non-pii-reader-notebook Och välj Öppen.
- Upprepa installationsstegen för notebook och anslut till samma EMR-kluster, men välj rollen
<STACK-NAME>-hudi-table-non-pii-role.
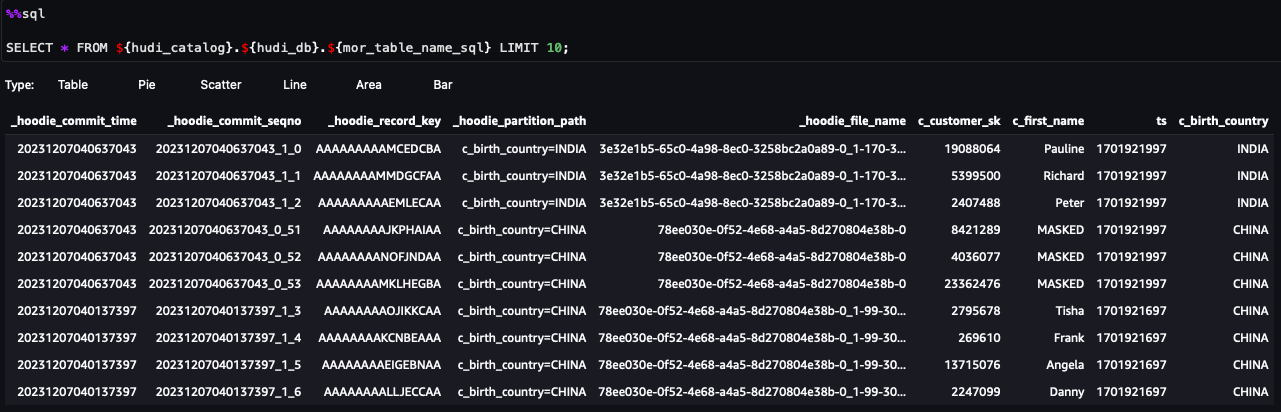
Du kan nu följa stegen i anteckningsboken. Från frågeresultaten kan du se att FGAC via datafiltret Lake Formation har tillämpats. Rollen kan inte se PII-kolumnernac_customer_id,c_last_nameochc_email_address. Också raderna frånHONG KONGhar filtrerats.
Städa upp
När du är klar med att experimentera med lösningen rekommenderar vi att du rengör resurser med följande steg för att undvika oväntade kostnader:
- Stäng av SageMaker Studio-apparna för användarprofilerna.
EMR-klustret kommer att raderas automatiskt efter inaktiv timeout-värdet.
- Radera Amazon Elastic File System (Amazon EFS) volym skapad för domänen.
- Töm S3-hinkarna skapad av CloudFormation-stacken.
- Ta bort stacken på AWS CloudFormation-konsolen.
Slutsats
I det här inlägget använde vi Apachi Hudi, en typ av OTF-tabeller, för att demonstrera denna nya funktion för att upprätthålla finkornig åtkomstkontroll på Amazon EMR. Du kan definiera granulära behörigheter i Lake Formation för OTF-tabeller och tillämpa dem via Spark SQL-frågor på EMR-kluster. Du kan också använda transaktionsdatasjöfunktioner som att köra ögonblicksbildsfrågor, inkrementella frågor, tidsresor och DML-frågor. Observera att denna nya funktion täcker alla OTF-bord.
Den här funktionen lanseras från och med Amazon EMR release 6.15 totalt Regioner där Amazon EMR är tillgängligt. Med Amazon EMR-integrationen med Lake Formation kan du med säkerhet hantera och bearbeta big data, låsa upp insikter och underlätta informerat beslutsfattande samtidigt som du upprätthåller datasäkerhet och styrning.
För att lära dig mer, se Aktivera Lake Formation med Amazon EMR och kontakta gärna dina AWS Solutions Architects, som kan vara till hjälp vid din dataresa.
Om författaren
 Raymond Lai är en senior lösningsarkitekt som är specialiserad på att tillgodose behoven hos stora företagskunder. Hans expertis ligger i att hjälpa kunder med att migrera intrikata företagssystem och databaser till AWS, konstruera företagsdatalager och datasjöplattformar. Raymond utmärker sig i att identifiera och designa lösningar för AI/ML-användningsfall, och han har ett särskilt fokus på AWS Serverless-lösningar och Event Driven Architecture-design.
Raymond Lai är en senior lösningsarkitekt som är specialiserad på att tillgodose behoven hos stora företagskunder. Hans expertis ligger i att hjälpa kunder med att migrera intrikata företagssystem och databaser till AWS, konstruera företagsdatalager och datasjöplattformar. Raymond utmärker sig i att identifiera och designa lösningar för AI/ML-användningsfall, och han har ett särskilt fokus på AWS Serverless-lösningar och Event Driven Architecture-design.
 Bin Wang, PhD, är Senior Analytic Specialist Solutions Architect på AWS, med över 12 års erfarenhet inom ML-branschen, med särskilt fokus på reklam. Han har expertis inom naturlig språkbehandling (NLP), rekommendatorsystem, olika ML-algoritmer och ML-operationer. Han brinner djupt för att tillämpa ML/DL och big data-tekniker för att lösa verkliga problem.
Bin Wang, PhD, är Senior Analytic Specialist Solutions Architect på AWS, med över 12 års erfarenhet inom ML-branschen, med särskilt fokus på reklam. Han har expertis inom naturlig språkbehandling (NLP), rekommendatorsystem, olika ML-algoritmer och ML-operationer. Han brinner djupt för att tillämpa ML/DL och big data-tekniker för att lösa verkliga problem.
 Aditya Shah är en mjukvaruutvecklingsingenjör på AWS. Han är intresserad av databaser och datalagermotorer och har arbetat med prestandaoptimeringar, säkerhetsefterlevnad och ACID-efterlevnad för motorer som Apache Hive och Apache Spark.
Aditya Shah är en mjukvaruutvecklingsingenjör på AWS. Han är intresserad av databaser och datalagermotorer och har arbetat med prestandaoptimeringar, säkerhetsefterlevnad och ACID-efterlevnad för motorer som Apache Hive och Apache Spark.
 Melodi Yang är Senior Big Data Solution Architect för Amazon EMR på AWS. Hon är en erfaren analysledare som arbetar med AWS-kunder för att ge bästa praxisvägledning och tekniska råd för att hjälpa dem att lyckas med datatransformation. Hennes intresseområden är ramverk med öppen källkod och automation, datateknik och DataOps.
Melodi Yang är Senior Big Data Solution Architect för Amazon EMR på AWS. Hon är en erfaren analysledare som arbetar med AWS-kunder för att ge bästa praxisvägledning och tekniska råd för att hjälpa dem att lyckas med datatransformation. Hennes intresseområden är ramverk med öppen källkod och automation, datateknik och DataOps.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/enforce-fine-grained-access-control-on-open-table-formats-via-amazon-emr-integrated-with-aws-lake-formation/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 11
- 12
- 130
- 15%
- 16
- 17
- 20
- 22
- 400
- 7
- 8
- 9
- a
- Om oss
- tillgång
- Konto
- bekräfta
- åtgärder
- aktivt
- lagt till
- Dessutom
- adresser
- administration
- administratörer
- reklam
- rådgivning
- Efter
- igen
- AI / ML
- algoritmer
- Alla
- tillåter
- tillåts
- tillåter
- vid sidan av
- också
- amason
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- an
- analys
- analytiker
- Analytisk
- analytics
- analys
- och
- vilken som helst
- Apache
- Apache Spark
- Ansökan
- tillämpas
- Ansök
- Tillämpa
- arkitekter
- arkitektur
- ÄR
- områden
- runt
- AS
- bistå
- Bistånd
- bistå
- utgå ifrån
- At
- revision
- myndighet
- tillstånd
- automatiskt
- Automation
- tillgänglig
- undvika
- AWS
- AWS Cloud9
- AWS molnformation
- AWS Lake Formation
- tillbaka
- baserat
- BE
- varit
- bakom
- Där vi får lov att vara utan att konstant prestera,
- Fördelarna
- förutom
- BÄST
- Stor
- Stora data
- bloggar
- skryt
- båda
- SLUTRESULTAT
- men
- by
- CA
- KAN
- kapabel
- bära
- bär
- Vid
- fall
- katalog
- catering
- vissa
- certifikat
- certifikat
- certifiering
- byta
- ändrats
- Förändringar
- Kina
- Välja
- Rengöring
- Cloud9
- kluster
- koda
- Kolumn
- Kolonner
- COM
- kombination
- förbinda
- Företag
- jämfört
- fullborda
- Efterlevnad
- komponent
- komponenter
- Compute
- dator
- begrepp
- villkor
- Genomför
- självsäkert
- konfiguration
- Kontakta
- Konsol
- konstruera
- kontakta
- innehålla
- innehåller
- kontroll
- kontrolleras
- kontroller
- kopiering
- Motsvarande
- Pris
- Kostar
- land
- omfattar
- skapa
- skapas
- skapar
- Skapa
- skaparen
- Aktuella
- beställnings
- Kunder
- datum
- datatillgång
- dataanalys
- datasjö
- Dataplattform
- dataintegritet
- databehandling
- datasäkerhet
- datalagret
- Databas
- databaser
- Beslutsfattande
- djupt
- Standard
- definiera
- Delta
- demonstrera
- demonstrera
- distribuera
- utplacering
- Designa
- design
- detaljer
- Utveckling
- olika
- distinkt
- flera
- dns
- do
- gör
- inte
- domän
- gjort
- inte
- ner
- ladda ner
- driven
- under
- varje
- annars
- möjliggöra
- aktiverad
- möjliggör
- kryptering
- änden
- endpoints
- förstärka
- Motor
- ingenjör
- Teknik
- Motorer
- säkerställa
- säkerställer
- säkerställa
- ange
- Företag
- företagskunder
- Hela
- Miljö
- Eter (ETH)
- händelse
- Varje
- exempel
- utförande
- finns
- erfarenhet
- erfaren
- expertis
- utforskning
- sträcker
- extern
- underlättande
- snabbare
- Leverans
- Funktioner
- känna
- Fil
- Filer
- filtrera
- filtrering
- filter
- Förnamn
- Fokus
- fokuserar
- följer
- efter
- följer
- För
- format
- bildning
- fyra
- Ramverk
- ramar
- Fri
- från
- Uppfylla
- full
- funktionalitet
- ytterligare
- framtida
- Få
- genereras
- styrning
- regleras
- bevilja
- kraftigt
- Grupp
- Gruppens
- vägleda
- sidan
- Har
- he
- här
- här.
- Markerad
- hans
- historisk
- historia
- Bikupa
- Hong
- Hong Kong
- Huset
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- IAM
- IKON
- ID
- Tanken
- identifiera
- identifiera
- Idle
- if
- illustrerar
- genomföra
- förbättra
- in
- innefattar
- Inklusive
- införlivande
- steg
- indien
- industrin
- underrätta
- informationen
- informeras
- ingång
- insikter
- integrerade
- Integrera
- integrering
- interaktiva
- intresserad
- intressen
- Gränssnitt
- inre
- in
- invecklad
- introducerade
- Introducerar
- fråga
- IT
- DESS
- Jobb
- Lediga jobb
- resa
- jpg
- Jupyter Notebook
- Nyckel
- Kong
- sjö
- språk
- Large
- Efternamn
- lansera
- lanserades
- ledare
- LÄRA SIG
- nivåer
- ligger
- tycka om
- BEGRÄNSA
- rader
- lokal
- läge
- platser
- logga in
- större
- göra
- hantera
- förvaltade
- ledning
- chef
- många
- Maj..
- betyder
- mekanismer
- möte
- Meny
- metadata
- kanske
- migrerande
- minuter
- ML
- ML-algoritmer
- modifierad
- mer
- rörelse
- namn
- namn
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Navigera
- Navigering
- Behöver
- behov
- Nya
- ny funktion
- nytt
- Nästa
- nlp
- nod
- Notera
- anteckningsbok
- bärbara datorer
- nu
- objekt
- of
- Ofta
- on
- ONE
- endast
- öppet
- öppen källkod
- openssl
- Verksamhet
- optimala
- Optimera
- Alternativet
- Tillbehör
- or
- beställa
- organisation
- Övriga
- ut
- över
- par
- panelen
- särskilt
- särskilt
- brinner
- betalar
- prestanda
- utför
- tillstånd
- behörigheter
- Personligen
- phd
- pii
- platshållare
- plattform
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- snälla du
- plus
- poäng
- Populära
- besitter
- Inlägg
- praktiken
- konservering
- föregående
- primär
- privatpolicy
- privilegium
- privilegier
- problem
- process
- bearbetning
- Produktion
- Profil
- Profiler
- bevis
- bevis på koncept
- skyddad
- skydd
- ge
- ger
- tillhandahålla
- allmän
- syfte
- sökfrågor
- Läsa
- Läsning
- redo
- verkliga världen
- realtid
- rekommenderar
- post
- återvinning
- minskar
- reducerande
- hänvisa
- hänvisar
- Reflekterar
- region
- registrera
- registrerat
- föreskrifter
- frigöra
- meddelanden
- relevanta
- ersätta
- Obligatorisk
- Krav
- resurs
- Resursintensiv
- Resurser
- resultera
- Resultat
- rättigheter
- Roll
- roller
- RAD
- rsa
- regler
- Körning
- rinnande
- sagemaker
- Samma
- Save
- §
- säkra
- Säkrad
- säkerhet
- se
- Seek
- välj
- senior
- känslig
- server
- Server
- Tjänster
- session
- in
- uppsättningar
- inställningar
- inställning
- hon
- signera
- signifikant
- liknande
- Enkelt
- förenklar
- förenkla
- eftersom
- Snapshot
- So
- Mjukvara
- mjukvaruutveckling
- lösning
- Lösningar
- LÖSA
- några
- Källa
- Gnista
- specialist
- specialiserat
- SQL
- stapel
- Etapp
- starta
- igång
- Starta
- uttalanden
- Steg
- förvaring
- lagrar
- Strategi
- Sträng
- studio
- skicka
- subnät
- framgång
- sådana
- SAMMANFATTNING
- stödja
- Stöder
- säker
- syntax
- System
- bord
- MÄRKA
- tar
- Teknisk
- tekniker
- mall
- terminal
- den där
- Smakämnen
- källan
- deras
- Dem
- sedan
- Där.
- Dessa
- de
- detta
- tre
- Genom
- tid
- tidsresor
- tidslinje
- till
- Spårning
- transaktion
- transaktion
- Transformation
- transitering
- färdas
- sann
- betrodd
- Ts
- två
- Typ
- typer
- ui
- under
- Oväntat
- okänd
- upplåsning
- Uppdatering
- uppdaterad
- upprätthållande
- uppladdad
- URI
- användning
- användningsfall
- Begagnade
- Användare
- användare
- med hjälp av
- validerar
- värde
- olika
- version
- via
- synlighet
- volym
- Warehouse
- Lagring
- we
- webb
- webbservice
- när
- medan
- som
- medan
- VEM
- kommer
- med
- inom
- arbetade
- arbetssätt
- skriva
- år
- dig
- Din
- zephyrnet
- noll-
- Postnummer