I dagens värld hanterar kunder enorma mängder data i sina Amazon enkel lagringstjänst (Amazon S3) datasjöar, som kräver invecklade datapipelines för att kontinuerligt förstå förändringarna i datalayouten och göra dem tillgängliga för konsumerande system. AWS-lim sökrobotar ger ett enkelt sätt att katalogisera data i AWS Glue Data Catalog som tar bort det tunga lyftet när det gäller schemahantering och dataklassificering. AWS Glue-sökrobotar extraherar dataschemat och partitionerna från Amazon S3 för att automatiskt fylla i datakatalogen och hålla metadata aktuell.
Men med data som växer exponentiellt över tiden, kan antalet partitioner i en given tabell växa avsevärt. Eftersom analystjänster som Amazonas Athena frågar en tabell som innehåller miljontals partitioner, ökar tiden som behövs för att hämta partitionen och kan göra att frågekörtiden ökar.
Idag har AWS Glue-crawler-stödet utökats för att automatiskt lägga till partitionsindex för nyupptäckta tabeller för att optimera frågebehandlingen på den partitionerade datamängden. Nu, när sökroboten skapar en ny datakatalogtabell under en sökrobotkörning, skapar den också ett partitionsindex som standard, med den största permutationen av alla partitionskolumner av numerisk och strängtyp som nycklar. Datakatalogen skapar sedan ett sökbart index baserat på dessa nycklar, vilket minskar tiden som krävs för att hämta och filtrera partitionsmetadata på tabeller med miljontals partitioner. Skapandet av partitionsindex gynnar analysarbetet som körs på Athena, Amazon EMR, Amazon Redshift Spectrum, och AWS Glue.
I det här inlägget beskriver vi hur man skapar partitionsindex med en AWS Glue-crawler och jämför förbättringen av frågeprestanda vid åtkomst till genomsökt data med och utan ett partitionsindex från Athena.
Lösningsöversikt
Vi använder en AWS molnformation mall för att skapa våra lösningsresurser. I följande steg visar vi hur man konfigurerar AWS Glue-sökroboten för att skapa ett partitionsindex med antingen AWS Glue-konsolen eller AWS-kommandoradsgränssnitt (AWS CLI). Sedan jämför vi förbättringarna av frågeprestanda med Athena.
Förutsättningar
För att följa med i detta inlägg måste du ha tillgång till en AWS identitets- och åtkomsthantering (IAM) administratörsroll för att skapa resurser med AWS CloudFormation.
Ställ in dina lösningsresurser
CloudFormation-mallen genererar följande resurser:
- IAM-roller och policyer
- En AWS Glue-databas för att hålla schemat
- En AWS Glue-sökrobot som pekar på en mycket uppdelad datauppsättning
- En Athena-arbetsgrupp och en hink för att lagra frågeresultat
Utför följande steg för att konfigurera lösningsresurserna:
- Logga in på AWS Management Console som IAM-administratör.
- Välja Starta stack för att distribuera CloudFormation-mallen:

- För Databas namn, behåll standard
blog_partition_index_crawlerdb.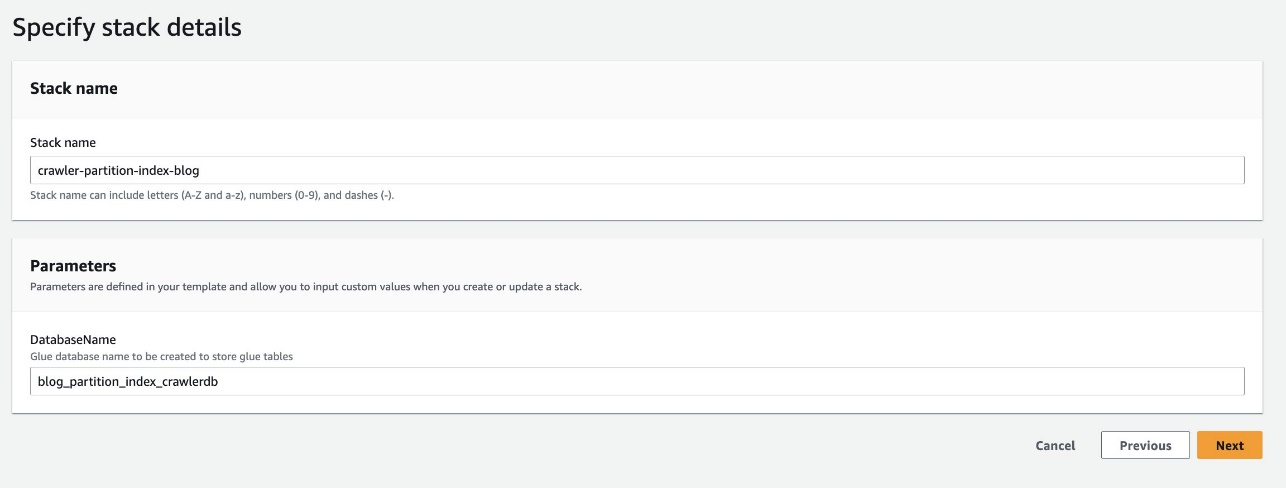
- Välja Nästa.
- Granska detaljerna på den sista sidan och välj Jag erkänner att AWS CloudFormation kan skapa IAM-resurser.
- Välja Skapa stack.
- När stacken är klar, på AWS CloudFormation-konsolen, navigera till Utgångarna fliken i stacken.
- Notera värden på
DatabaseNameochGlueCrawlerName.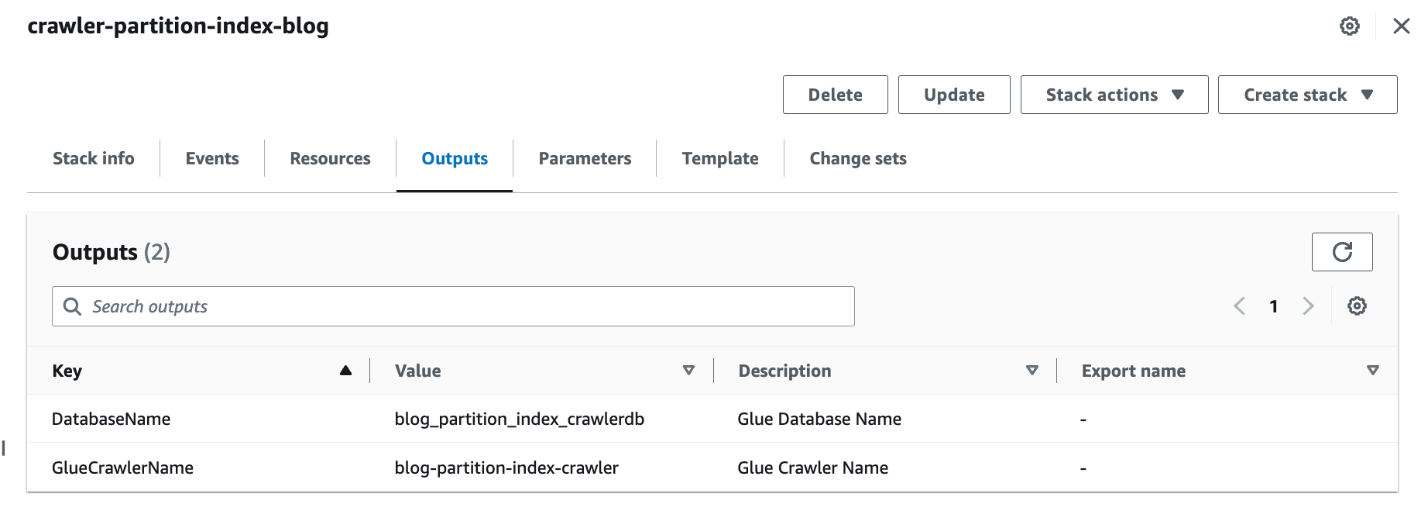
Vissa av resurserna som denna stack distribuerar medför kostnader när de används.
Redigera och kör AWS Glue-sökroboten
För att konfigurera och köra AWS Glue-crawler, slutför följande steg:
- Välj på AWS Lim-konsolen crawlers i navigeringsfönstret.
- Leta reda på
crawler blog-partition-index-crawlerOch välj Redigera.
- I Ställ in utdata och schemaläggning avsnitt, under Avancerade alternativ, Välj Skapa partitionsindex automatiskt.
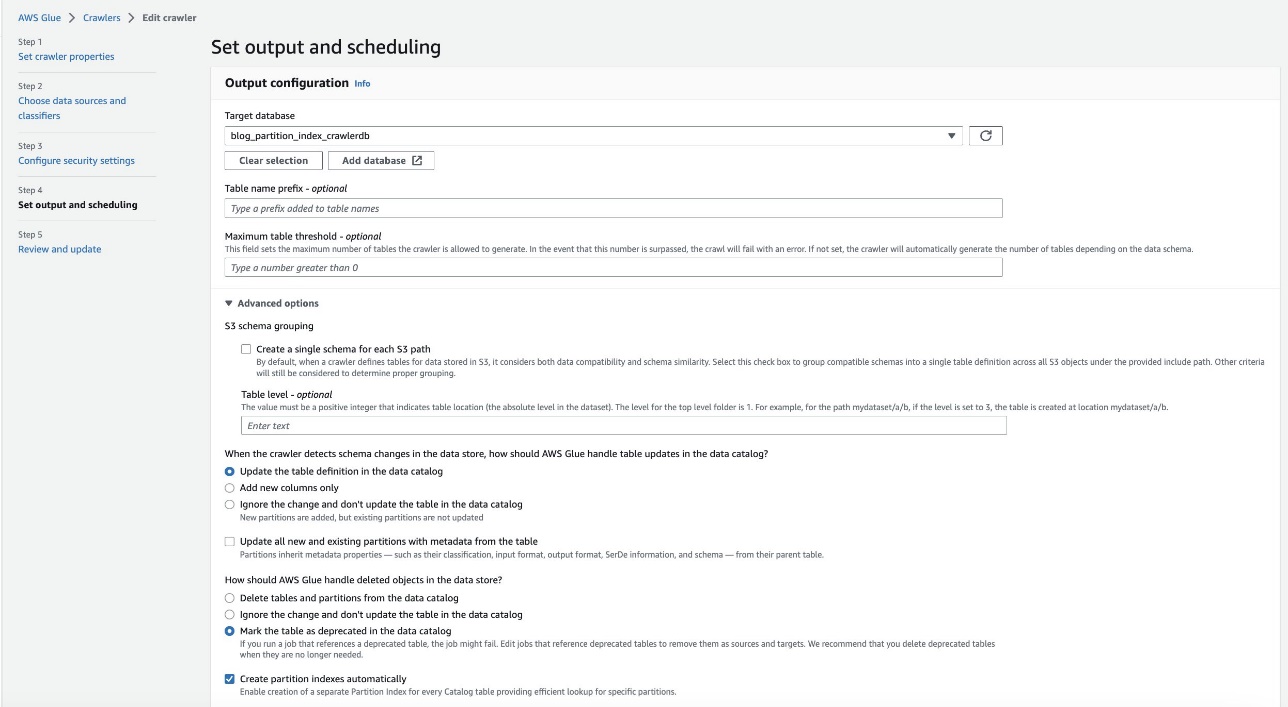
- Granska och uppdatera sökrobotinställningarna.
Alternativt kan du konfigurera din sökrobot med AWS CLI (ange din IAM-roll och region):
- Kör nu sökroboten och verifiera att sökrobotkörningen är klar.
Detta är mycket partitionerad datauppsättning och kommer att ta cirka 90 minuter att slutföra.
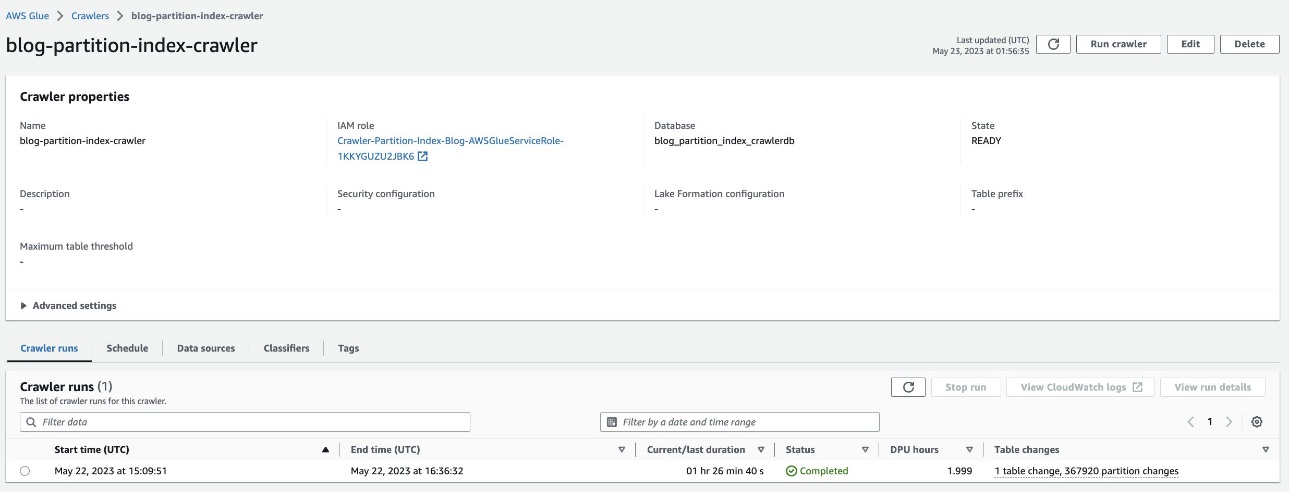
Verifiera den partitionerade tabellen
I AWS Glue-databasen blog_partition_index_crawlerdb, kontrollera att tabellen highly_partitioned_table skapas.
Som standard bestämmer sökroboten ett index baserat på den största permutationen av partitionskolumner med giltiga kolumntyper i samma ordning av partitionskolumner, som antingen är numeriska eller strängar. För tabellen skapad av sökroboten (highly_partitioned_table), har vi partitionskolumner year (sträng), month (sträng), day (sträng), och hour (sträng).
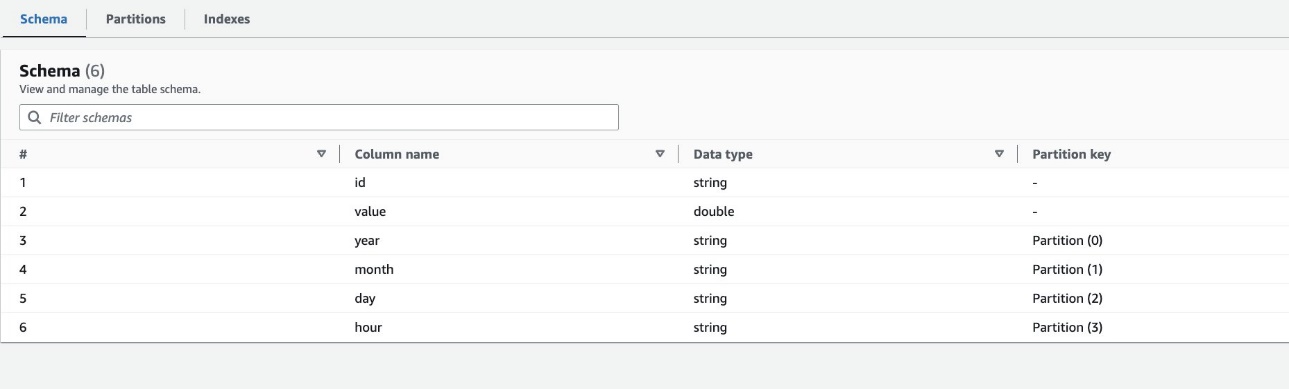
Baserat på denna definition skapade sökroboten ett index på permutationen av år, månad, dag och timme. Sökroboten skapade indexen med prefix crawler_ på valfritt partitionsindex skapat som standard.
Verifiera detsamma genom att navigera till tabellen highly_partitioned_table på AWS Glue-konsolen och välja Index fliken.
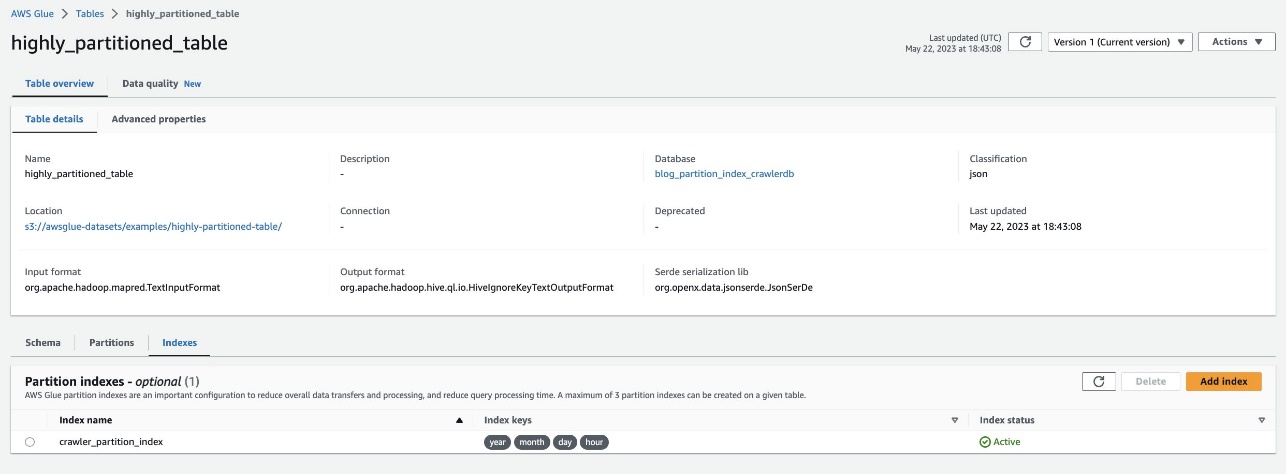
Sökroboten kunde genomsöka S3-datakällan och fylla i partitionsindexen för tabellen.
Jämför förbättringarna av frågeprestanda med Athena
Först frågar vi tabellen i Athena utan att använda partitionsindexet. För att verifiera tabellerna med Athena, utför följande steg:
- Välj på Athena-konsolen
crawler-primary-workgroupsom Athena-arbetsgruppen och välj Erkänna.
- Kör följande fråga:
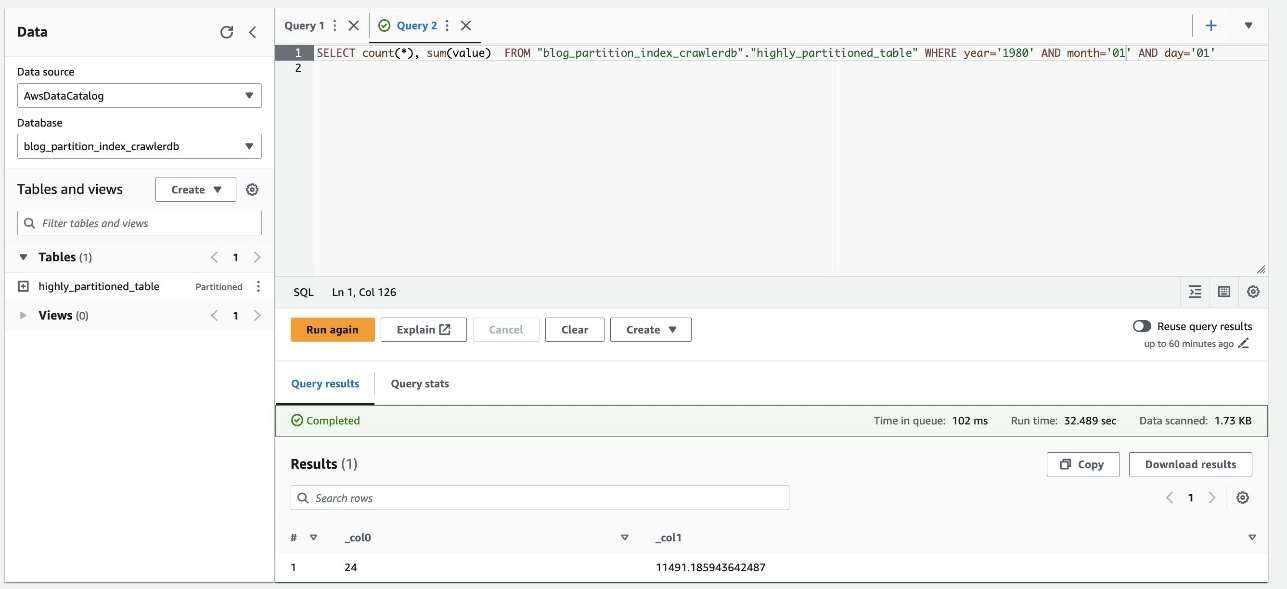
Följande skärmdump visar att frågan tog cirka 32 sekunder utan att filtrering var aktiverad med hjälp av partitionsindex.
- Nu aktiverar vi partitionsindexet på Athena-frågan:
- Kör följande fråga igen och notera körtiden:
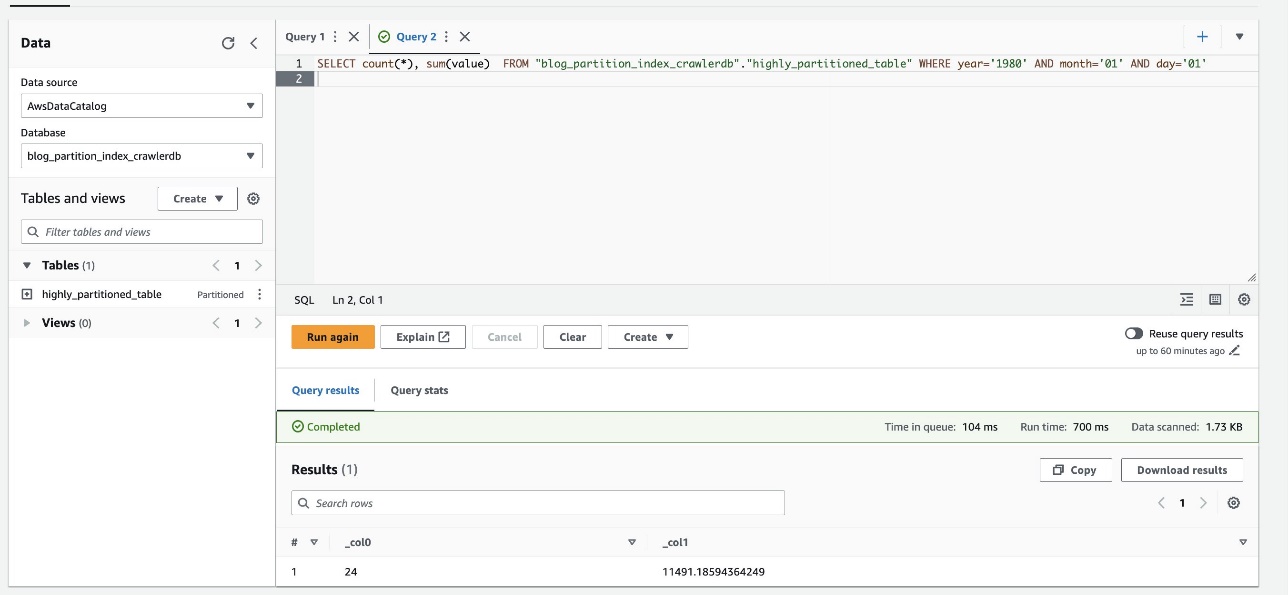
Följande skärmdump visar att frågan tog bara 700 millisekunder, vilket är mycket snabbare med filtrering aktiverad med hjälp av partitionsindex.
Städa upp
För att undvika oönskade avgifter på ditt AWS-konto kan du ta bort AWS-resurserna:
- Logga in på CloudFormation-konsolen som IAM-administratören som användes för att skapa CloudFormation-stacken.
- Ta bort CloudFormation-stacken du skapade.
Slutsats
I det här inlägget förklarade vi hur man konfigurerar en AWS-crawler för att skapa partitionsindex och jämförde frågeprestandan vid åtkomst till data med index från Athena.
Om inga partitionsindex finns i tabellen, laddar AWS Glue alla partitioner i tabellen och filtrerar sedan de laddade partitionerna, vilket resulterar i ineffektiv hämtning av metadata. Analystjänster som Redshift Spectrum, Amazon EMR och AWS Glue ETL Spark DataFrames kan nu använda index för att hämta partitioner, vilket resulterar i betydande frågeprestanda.
För mer information om partitionsindex och frågeprestanda över olika analytiska motorer, se Förbättra Amazon Athena-frågeprestanda med hjälp av AWS Glue Data Catalog-partitionsindex och Förbättra frågeprestanda med hjälp av AWS Glue-partitionsindex.
Särskilt tack till alla som bidrog till lanseringen av denna sökrobotfunktion: Yuhang Chen, Kyle Duong och Mita Gavade.
Om författarna
 Srividya Parthasarathy är Senior Big Data Architect på AWS Lake Formation-teamet. Hon tycker om att bygga datanätlösningar och dela dem med samhället.
Srividya Parthasarathy är Senior Big Data Architect på AWS Lake Formation-teamet. Hon tycker om att bygga datanätlösningar och dela dem med samhället.
 Sandeep Adwankar är Senior Technical Product Manager på AWS. Baserad i California Bay Area arbetar han med kunder över hela världen för att översätta affärsmässiga och tekniska krav till produkter som gör det möjligt för kunder att förbättra hur de hanterar, säkrar och får tillgång till data.
Sandeep Adwankar är Senior Technical Product Manager på AWS. Baserad i California Bay Area arbetar han med kunder över hela världen för att översätta affärsmässiga och tekniska krav till produkter som gör det möjligt för kunder att förbättra hur de hanterar, säkrar och får tillgång till data.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- : har
- :är
- :var
- $UPP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Able
- tillgång
- åtkomst
- Konto
- bekräfta
- tvärs
- lägga till
- administration
- igen
- Alla
- längs
- också
- amason
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- mängder
- an
- Analytisk
- analytics
- och
- vilken som helst
- cirka
- ÄR
- OMRÅDE
- runt
- AS
- At
- automatiskt
- tillgänglig
- undvika
- AWS
- AWS molnformation
- AWS-lim
- AWS Lake Formation
- baserat
- bukt
- därför att
- varit
- Fördelarna
- Stor
- Stora data
- Byggnad
- företag
- by
- kalifornien
- KAN
- katalog
- Orsak
- Förändringar
- avgifter
- chen
- Välja
- välja
- klassificering
- Kolumn
- Kolonner
- kommer
- samfundet
- jämföra
- jämfört
- fullborda
- Konsol
- kontinuerligt
- bidrog
- Kostar
- sökrobot
- skapa
- skapas
- skapar
- Skapa
- skapande
- Aktuella
- Kunder
- datum
- datatillgång
- datasjö
- Databas
- dag
- Standard
- demonstrera
- distribuera
- vecklas ut
- beskriva
- detaljer
- bestämd
- upptäckt
- ner
- under
- effektivt
- antingen
- möjliggöra
- aktiverad
- Motorer
- Eter (ETH)
- alla
- expanderade
- förklarade
- exponentiellt
- extrahera
- extrahera data
- snabbare
- Leverans
- filtrera
- filtrering
- filter
- slutlig
- följer
- efter
- För
- bildning
- från
- genererar
- ges
- globen
- Väx
- Odling
- Har
- he
- tung
- tunga lyft
- höggradigt
- hålla
- timme
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- IAM
- Identitet
- förbättra
- förbättring
- förbättringar
- in
- Öka
- Ökar
- index
- index
- ineffektiv
- informationen
- in
- IT
- jpg
- Ha kvar
- hålla
- nycklar
- sjö
- största
- lansera
- Layout
- lyft
- tycka om
- linje
- laster
- göra
- hantera
- ledning
- chef
- maska
- metadata
- kanske
- miljoner
- minuter
- Månad
- mer
- mycket
- måste
- Navigera
- navigerande
- Navigering
- behövs
- Nya
- nytt
- Nej
- nu
- antal
- of
- on
- endast
- Optimera
- or
- beställa
- vår
- produktion
- över
- sida
- panelen
- bana
- prestanda
- plato
- Platon Data Intelligence
- PlatonData
- Inlägg
- presentera
- bearbetning
- Produkt
- produktchef
- Produkter
- ge
- reducerande
- region
- Obligatorisk
- Krav
- Kräver
- Resurser
- resulterande
- Resultat
- Roll
- roller
- Körning
- rinnande
- Samma
- sekunder
- §
- säkra
- senior
- Tjänster
- in
- inställningar
- delning
- hon
- Visar
- signifikant
- signifikant
- Enkelt
- lösning
- Lösningar
- Källa
- Gnista
- Spektrum
- stapel
- Steg
- förvaring
- lagra
- okomplicerad
- Sträng
- Framgångsrikt
- stödja
- System
- bord
- Ta
- grupp
- Teknisk
- mall
- tack
- den där
- Smakämnen
- deras
- Dem
- sedan
- Dessa
- de
- detta
- tid
- till
- dagens
- tog
- Översätt
- sann
- Typ
- typer
- under
- förstå
- oönskade
- Uppdatering
- användning
- Begagnade
- med hjälp av
- utnyttja
- värde
- Värden
- olika
- Omfattande
- verifiera
- version
- var
- Sätt..
- we
- webb
- webbservice
- när
- som
- VEM
- kommer
- med
- utan
- arbetsgrupp
- fungerar
- världen
- jaml
- år
- dig
- Din
- zephyrnet