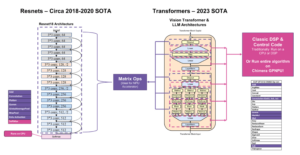
En teknisk artikel med titeln "Massive Data-Centric Parallelism in the Chiplet Era" publicerades av forskare vid Princeton University.
Sammanfattning:
"Traditionellt exekveras massivt parallella applikationer på distribuerade system, där beräkningsnoder är tillräckligt långt borta för att parallelliseringsscheman måste minimera kommunikation och synkronisering för att uppnå skalbarhet. Att kartlägga kommunikationsintensiva arbetsbelastningar till distribuerade system kräver komplicerad problempartitionering och förbearbetning av dataset. Med den nuvarande AI-drivna trenden att ha tusentals sammankopplade processorer per chip, finns det en möjlighet att ompröva dessa kommunikationsflaskhalsade arbetsbelastningar. Denna flaskhals uppstår ofta från datastrukturer, som orsakar oregelbundna minnesåtkomster och dålig cachelokalitet.
Nyligen genomförda arbeten har introducerat uppgiftsbaserade parallelliseringsscheman för att påskynda genomgång av grafer och andra glesa arbetsbelastningar. Datastrukturgenomgångar delas upp i uppgifter och distribueras över bearbetningsenheter (PU). Dalorex visade den högsta skalbarheten (upp till tusentals PU:er på ett enda chip) genom att ha hela datauppsättningen på chipet, spridd över PU:er och utföra uppgifterna på PU:n där data är lokal. Men det väckte också frågor om hur man kan skala till större datamängder när allt minne finns på chip, och till vilken kostnad.
För att möta dessa utmaningar föreslår vi en skalbar arkitektur som består av ett rutnät av DCRA-chiplets (Data-Centric Reconfigurable Array). Pakettidsomkonfiguration gör det möjligt att skapa chipprodukter som optimerar för olika målmått, såsom tid till lösning, energi eller kostnad, medan omkonfigurationer av programvara undviker nätverksmättnad när de skalas till miljontals PU:er över många chippaket. Vi utvärderar sex applikationer och fyra datauppsättningar, med flera konfigurationer och minnesteknologier, för att tillhandahålla en detaljerad analys av prestanda, kraft och kostnad för datalokalt exekvering i stor skala. Vår parallellisering av Breadth-First-Search med RMAT-26 över en miljon PU:er når 3323 GTEPS."
Hitta det tekniska papper här. Publicerad april 2023 (förtryck).
Orenes-Vera, Marcelo, Esin Tureci, David Wentzlaf och Margaret Martonosi. "Massiv datacentrerad parallellism i Chiplet-eran." arXiv förtryck arXiv: 2304.09389 (2023).
Relaterad
Minikonsortier som bildas runt chips
Kommersiella chiplet-marknadsplatser är fortfarande vid horisonten, men företag börjar tidigt med fler kommanditbolag.
Chipletsäkerhetsrisker underskattade
Storleken på säkerhetsutmaningarna för kommersiella chiplets är skrämmande.
Kapplöpet mot blandade gjuterichiplets
Utmaningarna med att montera chiplets från olika gjuterier har precis börjat dyka upp.
Designöverväganden och senaste framsteg inom chiplets (UC Berkeley/Peking University)
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Källa: https://semiengineering.com/data-centric-reconfigurable-array-dcra-chiplets-princeton/
- :är
- :var
- $UPP
- 2023
- a
- accelerera
- Uppnå
- tvärs
- adress
- framsteg
- Alla
- också
- an
- analys
- och
- tillämpningar
- April
- arkitektur
- ÄR
- runt
- array
- AS
- At
- Börjar
- men
- by
- cache
- Orsak
- utmaningar
- chip
- kommersiella
- Kommunikation
- Företag
- komplicerad
- sammansatt
- databehandling
- överväganden
- Pris
- Skapa
- Aktuella
- datum
- datauppsättningar
- David
- demonstreras
- detaljerad
- olika
- Avlägsen
- distribueras
- distribuerade system
- Tidig
- möjliggör
- energi
- tillräckligt
- Hela
- Era
- utvärdera
- exekvera
- utförande
- För
- fyra
- från
- få
- diagram
- Rutnät
- Har
- har
- högsta
- horisonten
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- in
- sammankopplade
- in
- introducerade
- IT
- bara
- större
- Begränsad
- lokal
- många
- kartläggning
- marknads
- massivt
- Minne
- Metrics
- miljon
- miljoner
- mer
- nät
- noder
- of
- on
- Möjlighet
- Optimera
- or
- Övriga
- vår
- paket
- Papper
- Parallell
- partnerskap
- peking
- prestanda
- plato
- Platon Data Intelligence
- PlatonData
- dålig
- kraft
- princeton
- Problem
- bearbetning
- processorer
- Produkter
- föreslå
- ge
- publicerade
- frågor
- Lopp
- insamlat
- når
- senaste
- Kräver
- forskare
- risker
- skalbarhet
- skalbar
- Skala
- skalning
- spridda
- system
- säkerhet
- säkerhetsrisker
- flera
- enda
- SEX
- Mjukvara
- delas
- starta
- Fortfarande
- struktur
- sådana
- synkronisering
- System
- Målet
- uppgifter
- Teknisk
- Tekniken
- den där
- Smakämnen
- Där.
- Dessa
- detta
- tusentals
- betitlad
- till
- mot
- Trend
- enheter
- universitet
- var
- we
- Vad
- som
- medan
- med
- fungerar
- zephyrnet