Detta är ett gemensamt inlägg skrivet av AWS och Voxel51. Voxel51 är företaget bakom FiftyOne, verktygslådan med öppen källkod för att bygga högkvalitativa datauppsättningar och datorseendemodeller.
Ett detaljhandelsföretag bygger en mobilapp för att hjälpa kunder att köpa kläder. För att skapa den här appen behöver de en datauppsättning av hög kvalitet som innehåller klädbilder, märkta med olika kategorier. I det här inlägget visar vi hur man återanvänder en befintlig datauppsättning via datarensning, förbearbetning och förmärkning med en nollbildsklassificeringsmodell i Femtioett, och justera dessa etiketter med Amazon SageMaker Ground Sannhet.
Du kan använda Ground Truth och FiftyOne för att påskynda ditt datamärkningsprojekt. Vi illustrerar hur man sömlöst använder de två applikationerna tillsammans för att skapa högkvalitativa märkta datamängder. För vårt exempelanvändningsfall arbetar vi med Fashion200K dataset, släppt på ICCV 2017.
Lösningsöversikt
Ground Truth är en helt självbetjänad och hanterad datamärkningstjänst som ger datavetare, maskininlärningsingenjörer (ML) och forskare möjlighet att bygga datauppsättningar av hög kvalitet. Femtioett by voxel51 är en verktygslåda med öppen källkod för att kurera, visualisera och utvärdera datauppsättningar för datorvision så att du kan träna och analysera bättre modeller genom att påskynda dina användningsfall.
I följande avsnitt visar vi hur du gör följande:
- Visualisera datasetet i FiftyOne
- Rengör datasetet med filtrering och bilddeduplicering i FiftyOne
- Företikett de rensade data med noll-shot-klassificering i FiftyOne
- Märk den mindre kurerade datamängden med Ground Truth
- Injicera märkta resultat från Ground Truth i FiftyOne och granska märkta resultat i FiftyOne
Använda fallöversikt
Anta att du äger ett detaljhandelsföretag och vill bygga en mobilapplikation för att ge personliga rekommendationer för att hjälpa användare att bestämma vad de ska ha på sig. Dina potentiella användare letar efter ett program som talar om för dem vilka klädesplagg i deras garderob som fungerar bra tillsammans. Du ser en möjlighet här: om du kan identifiera bra outfits kan du använda detta för att rekommendera nya klädesplagg som kompletterar de kläder som en kund redan äger.
Du vill göra det så enkelt som möjligt för slutanvändaren. Helst behöver någon som använder din applikation bara ta bilder av kläderna i sin garderob, och dina ML-modeller gör sin magi bakom kulisserna. Du kan träna en modell för allmänt bruk eller finjustera en modell till varje användares unika stil med någon form av feedback.
Först måste du dock identifiera vilken typ av kläder användaren fångar. Är det en skjorta? Ett par byxor? Eller något annat? När allt kommer omkring vill du förmodligen inte rekommendera en outfit som har flera klänningar eller flera hattar.
För att möta denna första utmaning vill du skapa en träningsdatauppsättning som består av bilder av olika klädesplagg med olika mönster och stilar. För att prototypa med en begränsad budget vill du bootstrap med en befintlig datauppsättning.
För att illustrera och vägleda dig genom processen i det här inlägget använder vi Fashion200K-datauppsättningen som släpptes på ICCV 2017. Det är en etablerad och väl citerad datauppsättning, men den är inte direkt lämpad för ditt användningsfall.
Även om klädesplagg är märkta med kategorier (och underkategorier) och innehåller en mängd användbara taggar som är extraherade från de ursprungliga produktbeskrivningarna, är data inte systematiskt märkta med mönster- eller stilinformation. Ditt mål är att förvandla denna befintliga datauppsättning till en robust träningsdatauppsättning för dina klädklassificeringsmodeller. Du måste rensa data, utöka märkningsschemat med stiletiketter. Och du vill göra det snabbt och med så lite utgifter som möjligt.
Ladda ner data lokalt
Ladda först ner zip-filen women.tar och mappen etiketter (med alla dess undermappar) genom att följa instruktionerna i Fashion200K dataset GitHub repository. När du har packat upp dem båda, skapa en överordnad katalog fashion200k och flytta etiketterna och kvinnomapparna till denna. Lyckligtvis har dessa bilder redan beskurits till gränsrutorna för objektdetektering, så vi kan fokusera på klassificering snarare än att oroa oss för objektdetektering.
Trots "200K" i dess namn innehåller kvinnokatalogen vi extraherade 338,339 200 bilder. För att generera den officiella Fashion300,000K-datauppsättningen genomsökte datasetets författare mer än XNUMX XNUMX produkter online, och endast produkter med beskrivningar som innehåller mer än fyra ord kom igenom. För våra ändamål, där produktbeskrivningen inte är nödvändig, kan vi använda alla genomsökta bilder.
Låt oss titta på hur dessa uppgifter är organiserade: i kvinnornas mappen är bilderna ordnade efter artikeltyp på toppnivå (kjolar, toppar, byxor, jackor och klänningar) och artikeltyps underkategori (blusar, t-shirts, långärmade) blast).
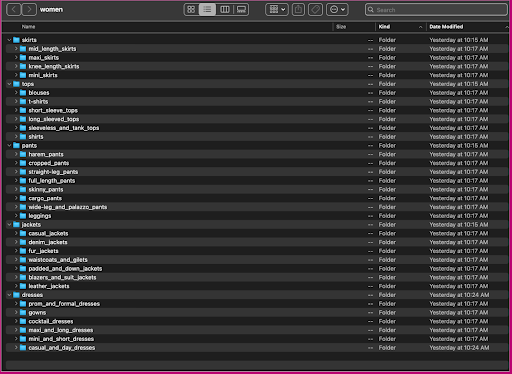
Inom underkategorikatalogerna finns det en underkatalog för varje produktlista. Var och en av dessa innehåller ett varierande antal bilder. Underkategorin cropped_pants innehåller till exempel följande produktlistor och tillhörande bilder.
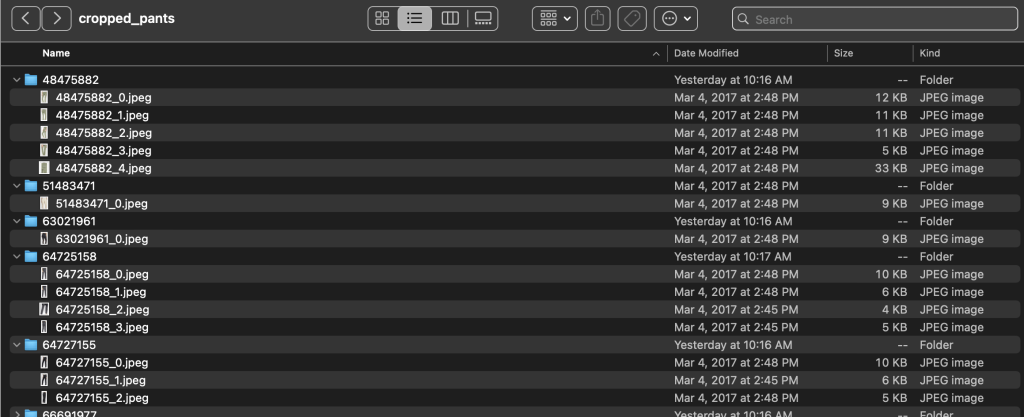
Etikettmappen innehåller en textfil för varje artikeltyp på toppnivå, för både tåg- och testdelningar. Inom var och en av dessa textfiler finns en separat rad för varje bild, som anger den relativa filsökvägen, en poäng och taggar från produktbeskrivningen.
Eftersom vi omanvänder datamängden kombinerar vi alla tåg- och testbilder. Vi använder dessa för att generera en applikationsspecifik datauppsättning av hög kvalitet. När vi har slutfört den här processen kan vi slumpmässigt dela upp den resulterande datamängden i nya tåg- och testdelningar.
Injicera, visa och kurera en datauppsättning i FiftyOne
Om du inte redan har gjort det, installera FiftyOne med öppen källkod med hjälp av pip:
En bästa praxis är att göra det i en ny virtuell (venv eller conda) miljö. Importera sedan relevanta moduler. Importera basbiblioteket, fiftyone, FiftyOne Brain, som har inbyggda ML-metoder, FiftyOne Zoo, från vilken vi kommer att ladda en modell som kommer att generera nollbildsetiketter för oss, och ViewField, som låter oss effektivt filtrera data i vår datauppsättning:
Du vill också importera glob- och OS Python-modulerna, vilket hjälper oss att arbeta med sökvägar och mönstermatchning över kataloginnehåll:
Nu är vi redo att ladda datauppsättningen i FiftyOne. Först skapar vi en datauppsättning som heter fashion200k och gör den beständig, vilket gör att vi kan spara resultaten av beräkningsintensiva operationer, så vi behöver bara beräkna nämnda kvantiteter en gång.
Vi kan nu iterera genom alla underkategorikataloger och lägga till alla bilder i produktkatalogerna. Vi lägger till en FiftyOne-klassificeringsetikett till varje prov med fältnamnet artikeltyp, fyllt av bildens artikelkategori på översta nivån. Vi lägger också till både kategori- och underkategoriinformation som taggar:
Vid det här laget kan vi visualisera vår datauppsättning i FiftyOne-appen genom att starta en session:
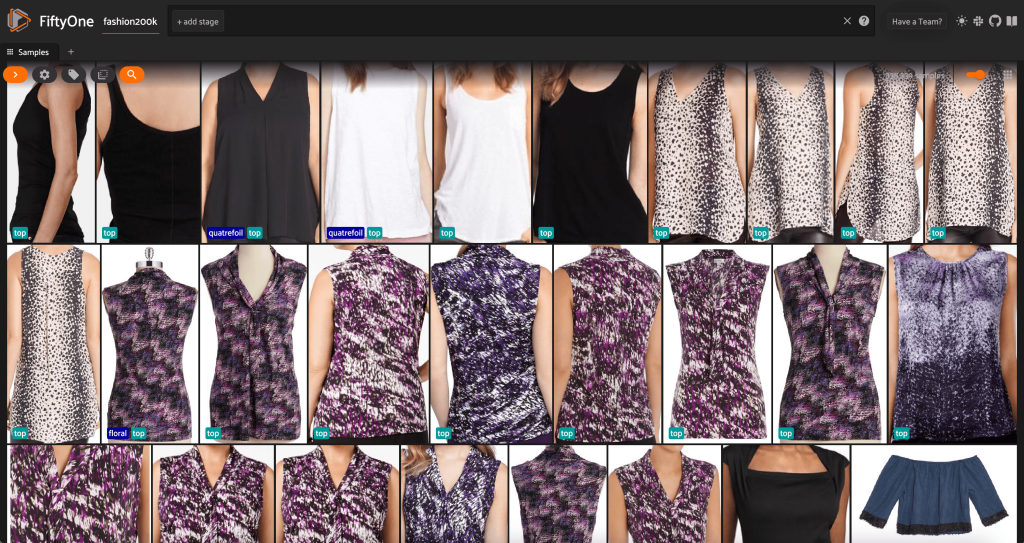
Vi kan också skriva ut en sammanfattning av datasetet i Python genom att köra print(dataset):
Vi kan också lägga till taggarna från labels katalog till proverna i vår datauppsättning:
När man tittar på uppgifterna blir några saker tydliga:
- Vissa av bilderna är ganska korniga, med låg upplösning. Detta beror sannolikt på att dessa bilder genererades genom att beskära initiala bilder i begränsningsrutor för objektdetektering.
- Vissa kläder bärs av en person, och vissa är fotograferade på egen hand. Dessa detaljer är inkapslade av
viewpointfast egendom. - Många av bilderna av samma produkt är väldigt lika, så åtminstone initialt, att inkludera mer än en bild per produkt kanske inte ger mycket prediktiv kraft. För det mesta, den första bilden av varje produkt (slutar på
_0.jpeg) är den renaste.
Till en början kanske vi vill träna vår klädstilsklassificeringsmodell på en kontrollerad delmängd av dessa bilder. För detta ändamål använder vi högupplösta bilder av våra produkter och begränsar vår syn till ett representativt prov per produkt.
Först filtrerar vi bort de lågupplösta bilderna. Vi använder compute_metadata() metod för att beräkna och lagra bildens bredd och höjd, i pixlar, för varje bild i datamängden. Vi använder sedan FiftyOne ViewField för att filtrera bort bilder baserat på minsta tillåtna bredd- och höjdvärden. Se följande kod:
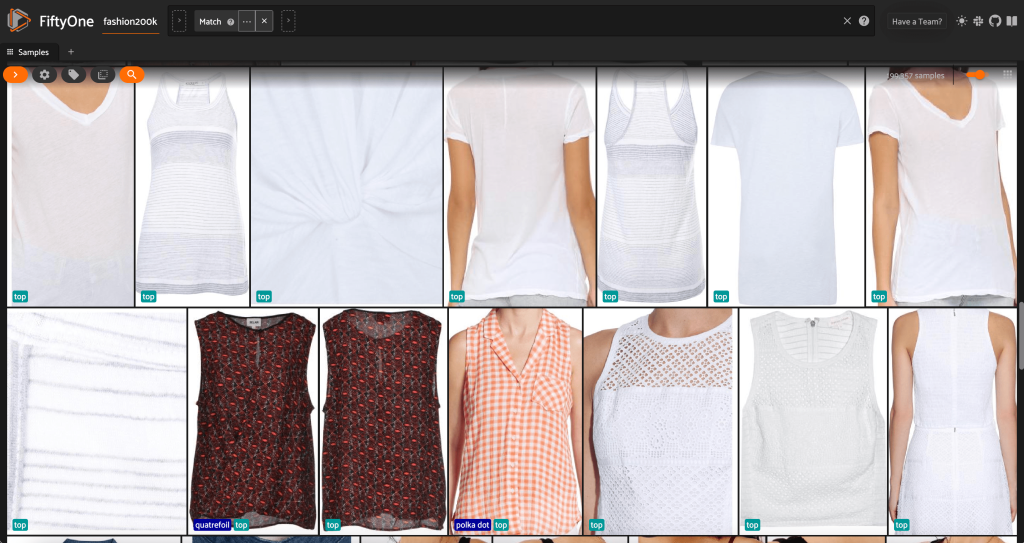
Denna högupplösta delmängd har knappt 200,000 XNUMX prover.
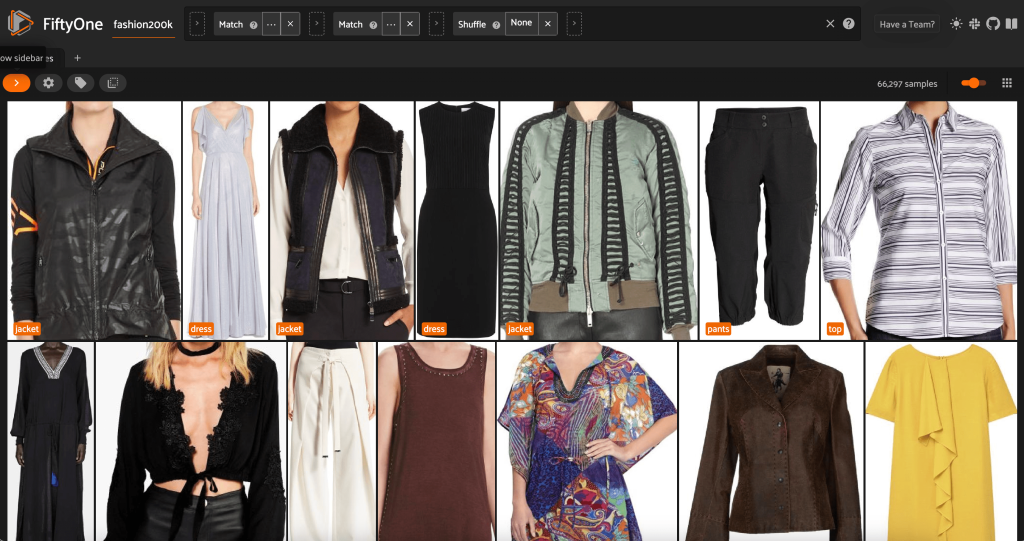
Från denna vy kan vi skapa en ny vy i vår datauppsättning som endast innehåller ett representativt urval (högst) för varje produkt. Vi använder ViewField återigen, mönstermatchning för filsökvägar som slutar med _0.jpeg:
Låt oss se en slumpmässigt blandad ordning av bilder i denna delmängd:
Ta bort överflödiga bilder i datamängden
Den här vyn innehåller 66,297 19 bilder, eller drygt XNUMX % av den ursprungliga datamängden. När vi tittar på utsikten ser vi dock att det finns många väldigt lika produkter. Att behålla alla dessa kopior kommer sannolikt bara att öka kostnaden för vår märkning och modellutbildning, utan att märkbart förbättra prestandan. Låt oss istället bli av med de nästan dubbletter för att skapa en mindre datauppsättning som fortfarande har samma kraft.
Eftersom dessa bilder inte är exakta dubbletter kan vi inte kontrollera pixelvis likhet. Lyckligtvis kan vi använda FiftyOne Brain för att hjälpa oss att rengöra vår datauppsättning. I synnerhet kommer vi att beräkna en inbäddning för varje bild – en vektor med lägre dimensioner som representerar bilden – och sedan leta efter bilder vars inbäddningsvektorer ligger nära varandra. Ju närmare vektorerna desto mer lika bilderna.
Vi använder en CLIP-modell för att generera en 512-dimensionell inbäddningsvektor för varje bild och lagrar dessa inbäddningar i fältinbäddningarna på proverna i vår datauppsättning:
Sedan beräknar vi närheten mellan inbäddningar med hjälp av cosinuslikhetoch hävdar att vilka två vektorer som helst vars likhet är större än något tröskelvärde sannolikt är nära dubbletter. Cosinuslikhetspoängen ligger i intervallet [0, 1], och om man tittar på data, verkar ett tröskelvärde på tröskel=0.5 vara ungefär rätt. Återigen, detta behöver inte vara perfekt. Några nästan duplicerade bilder kommer sannolikt inte att förstöra vår förutsägelsekraft, och att slänga några icke-duplicerade bilder påverkar inte modellens prestanda väsentligt.
Vi kan se de påstådda dubbletterna för att verifiera att de verkligen är överflödiga:
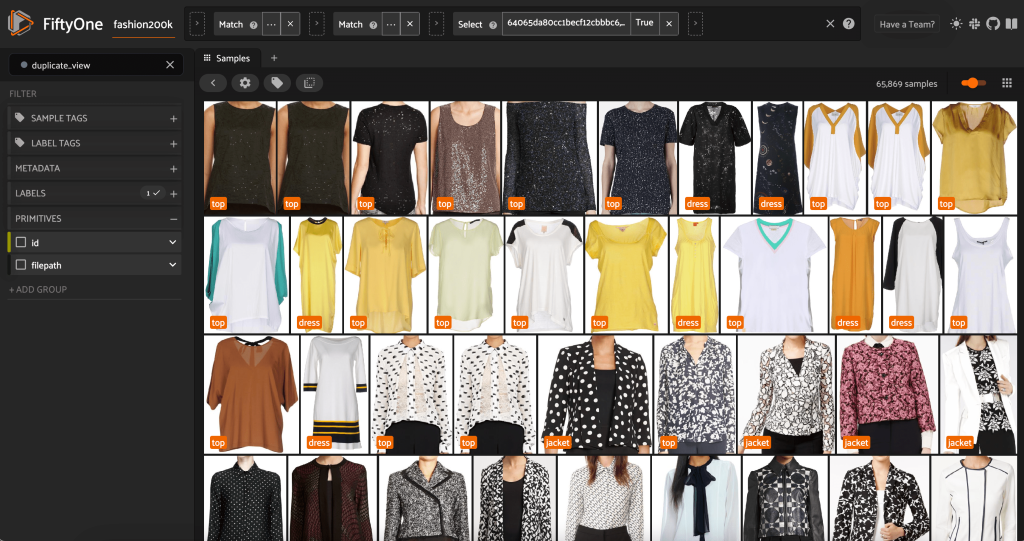
När vi är nöjda med resultatet och tror att dessa bilder verkligen är nära dubbletter kan vi välja ett prov från varje uppsättning liknande prover att behålla och ignorera de andra:
Nu har den här vyn 3,729 200 bilder. Genom att rensa data och identifiera en högkvalitativ delmängd av Fashion300,000K-datauppsättningen låter FiftyOne oss begränsa vårt fokus från mer än 4,000 98 bilder till strax under 90 XNUMX, vilket motsvarar en minskning med XNUMX %. Enbart att använda inbäddningar för att ta bort nästan dubblerade bilder minskade vårt totala antal bilder under övervägande med mer än XNUMX %, med liten om någon effekt på några modeller som ska tränas på dessa data.
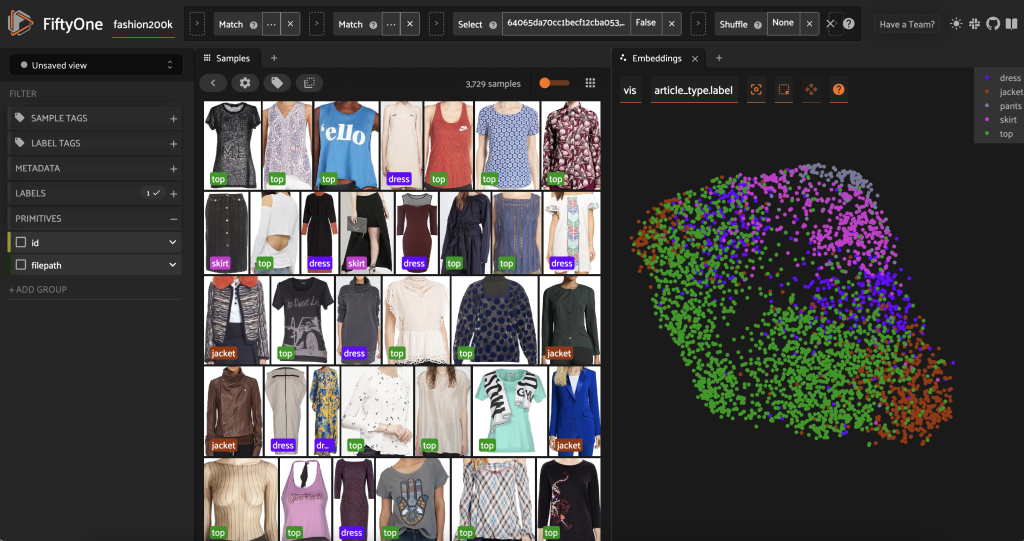
Innan vi pre-märker denna delmängd kan vi bättre förstå data genom att visualisera de inbäddningar vi redan har beräknat. Vi kan använda FiftyOne Brains inbyggda compute_visualization() metod, som använder tekniken för enhetlig manifold approximation (UMAP) för att projicera de 512-dimensionella inbäddningsvektorerna i tvådimensionellt utrymme så att vi kan visualisera dem:
Vi öppnar en ny Inbäddningspanel i FiftyOne-appen och färgläggning efter artikeltyp, och vi kan se att dessa inbäddningar ungefär kodar en föreställning om artikeltyp (bland annat!).
Nu är vi redo att förmärka denna data.
Genom att inspektera dessa mycket unika, högupplösta bilder kan vi skapa en anständig lista över stilar att använda som klasser i vår nollbildsklassificering för märkning. Vårt mål med att företikettera dessa bilder är inte att nödvändigtvis märka varje bild korrekt. Snarare är vårt mål att ge en bra utgångspunkt för mänskliga annotatorer så att vi kan minska tid och kostnader för märkning.
Vi kan sedan instansiera en nollbildsklassificeringsmodell för denna applikation. Vi använder en CLIP-modell, som är en generell modell som tränas på både bilder och naturligt språk. Vi instansierar en CLIP-modell med textuppmaningen "Kläder i stilen", så att givet en bild kommer modellen att mata ut den klass för vilken "Kläder i stilen [klass]" passar bäst. CLIP är inte utbildad på detaljhandels- eller modespecifika data, så detta kommer inte att vara perfekt, men det kan spara dig i kostnader för märkning och anteckningar.
Vi tillämpar sedan denna modell på vår reducerade delmängd och lagrar resultaten i en article_style fält:
Genom att starta FiftyOne-appen igen kan vi visualisera bilderna med dessa förutspådda stiletiketter. Vi sorterar efter förutsägelseförtroende så vi ser de mest säkra stilförutsägelserna först:
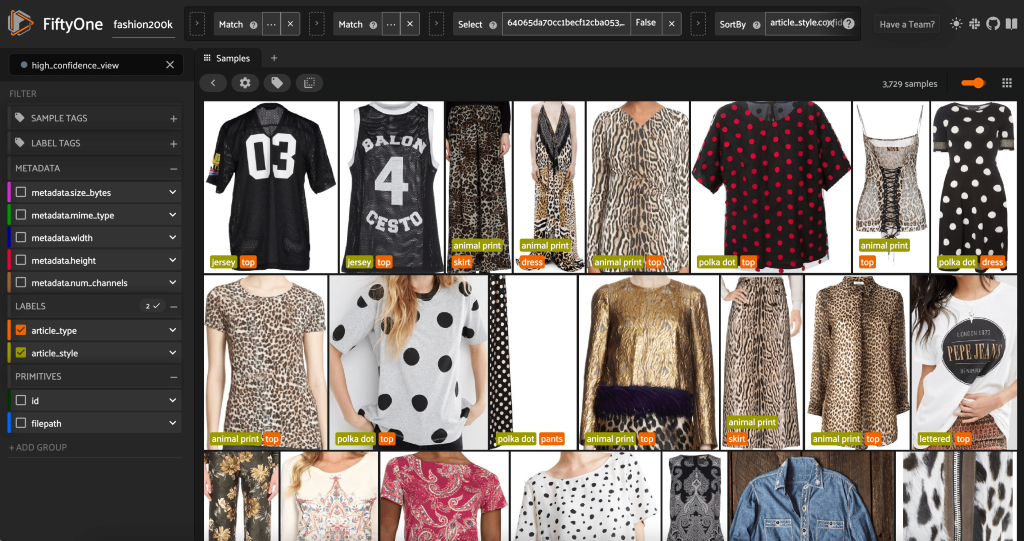
Vi kan se att de högsta förutsägelserna verkar vara för "jersey", "djurtryck", "prickiga" och "bokstäver". Detta är vettigt, eftersom dessa stilar är relativt distinkta. Det verkar också som, för det mesta, de förutspådda stiletiketterna är korrekta.
Vi kan också titta på stilförutsägelserna med lägst förtroende:
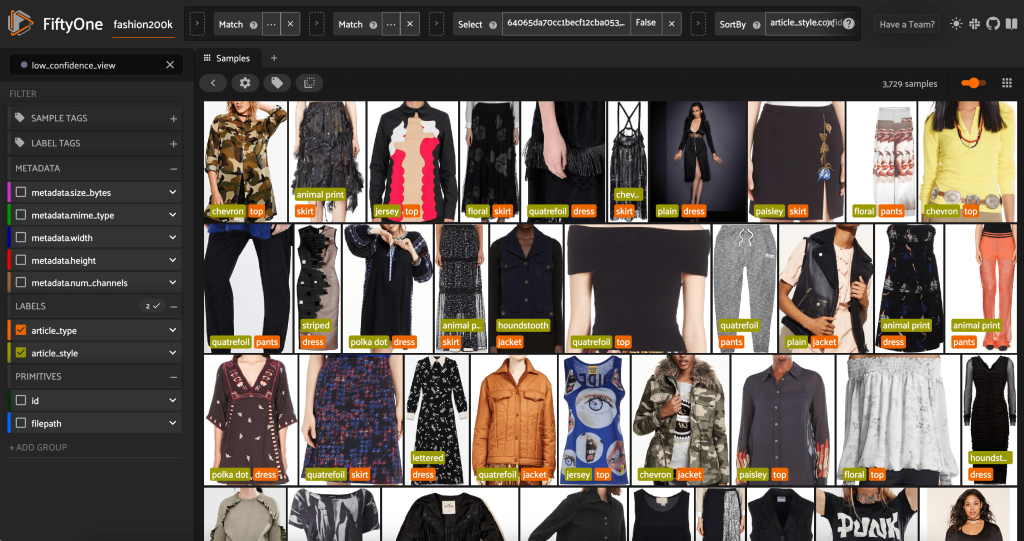
För vissa av dessa bilder finns lämplig stilkategori i den medföljande listan, och klädesplagget är felaktigt märkt. Den första bilden i rutnätet, till exempel, ska tydligt vara "kamouflage" och inte "chevron". I andra fall passar produkterna dock inte in i stilkategorierna. Klänningen på den andra bilden i andra raden är till exempel inte exakt "randig", men med samma märkningsalternativ kan en mänsklig kommentator också ha varit i konflikt. När vi bygger ut vår datauppsättning måste vi bestämma om vi ska ta bort kantfall som dessa, lägga till nya stilkategorier eller utöka datauppsättningen.
Exportera den slutliga datamängden från FiftyOne
Exportera den slutliga datamängden med följande kod:
Vi kan exportera en mindre datauppsättning, till exempel 16 bilder, till mappen 200kFashionDatasetExportResult-16Images. Vi skapar ett Ground Truth-justeringsjobb med det:
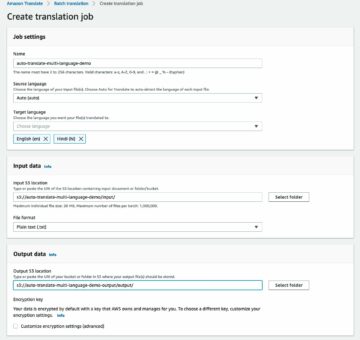
Ladda upp den reviderade datamängden, konvertera etikettformatet till Ground Truth, ladda upp till Amazon S3 och skapa en manifestfil för justeringsjobbet
Vi kan konvertera etiketterna i datamängden för att matcha utgångsmanifestschema av ett Ground Truth bounding box-jobb och ladda upp bilderna till ett Amazon enkel lagringstjänst (Amazon S3) hink för att lansera en Ground Truth justeringsjobb:
Ladda upp manifestfilen till Amazon S3 med följande kod:
Skapa korrigerade formaterade etiketter med Ground Truth
För att annotera dina data med stiletiketter med Ground Truth, slutför du de nödvändiga stegen för att starta ett märkningsjobb med begränsningsruta genom att följa proceduren som beskrivs i Komma igång med Ground Truth guide med datamängden i samma S3-hink.
- Skapa ett Ground Truth-märkningsjobb på SageMaker-konsolen.
- Ställ in Ange datasättplatsen att vara det manifest som vi skapade i de föregående stegen.
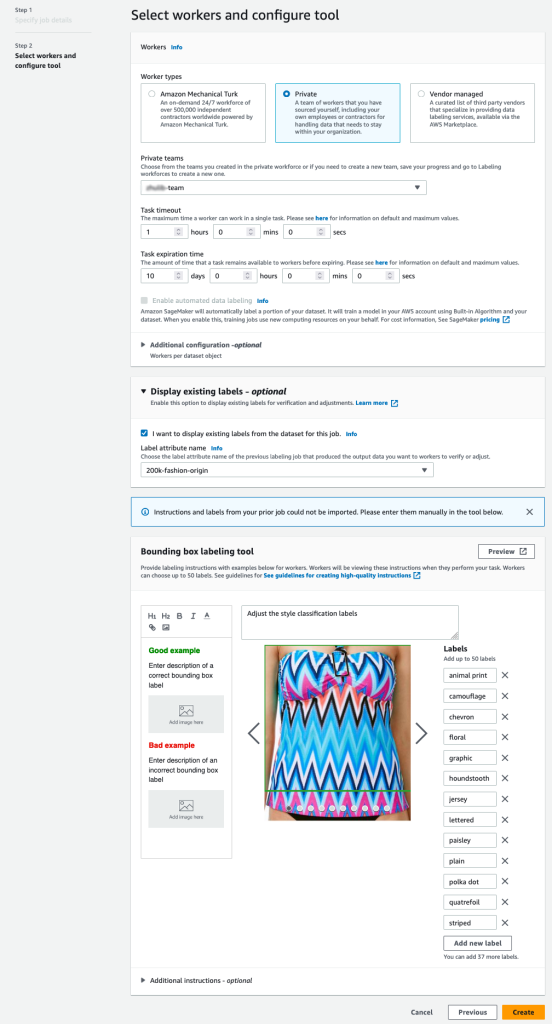
- Ange en S3-sökväg för Utdata dataset plats.
- För IAM-rollväljer Ange en anpassad IAM-roll ARN, ange sedan rollen ARN.
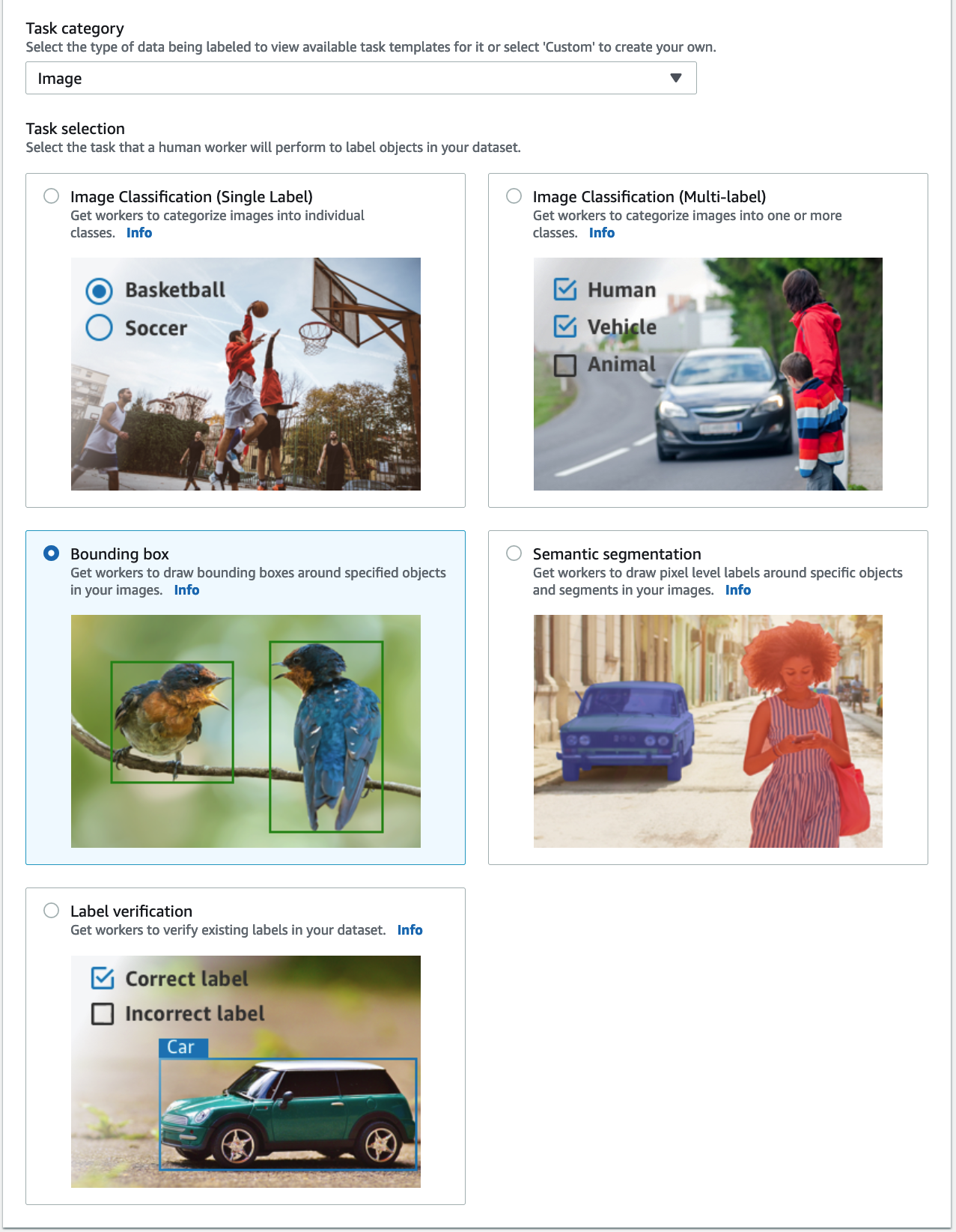
- För Uppgiftskategoriväljer Bild och välj Begränsande låda.
- Välja Nästa.
- I Arbetare väljer du vilken typ av arbetskraft du vill använda.
Du kan välja en arbetsstyrka genom Amazon Mekanisk Turk, tredjepartsleverantörer eller din egen privata arbetsstyrka. För mer information om dina arbetskraftsalternativ, se Skapa och hantera arbetskraft. - Bygga ut Visningsalternativ för befintliga etiketter och välj Jag vill visa befintliga etiketter från datamängden för det här jobbet.
- För Etikettattribut namn, välj det namn från ditt manifest som motsvarar etiketterna som du vill visa för justering.
Du kommer bara att se etikettattributnamn för etiketter som matchar uppgiftstypen du valde i de föregående stegen. - Ange etiketterna manuellt för Verktyg för märkning av avgränsningslådor.
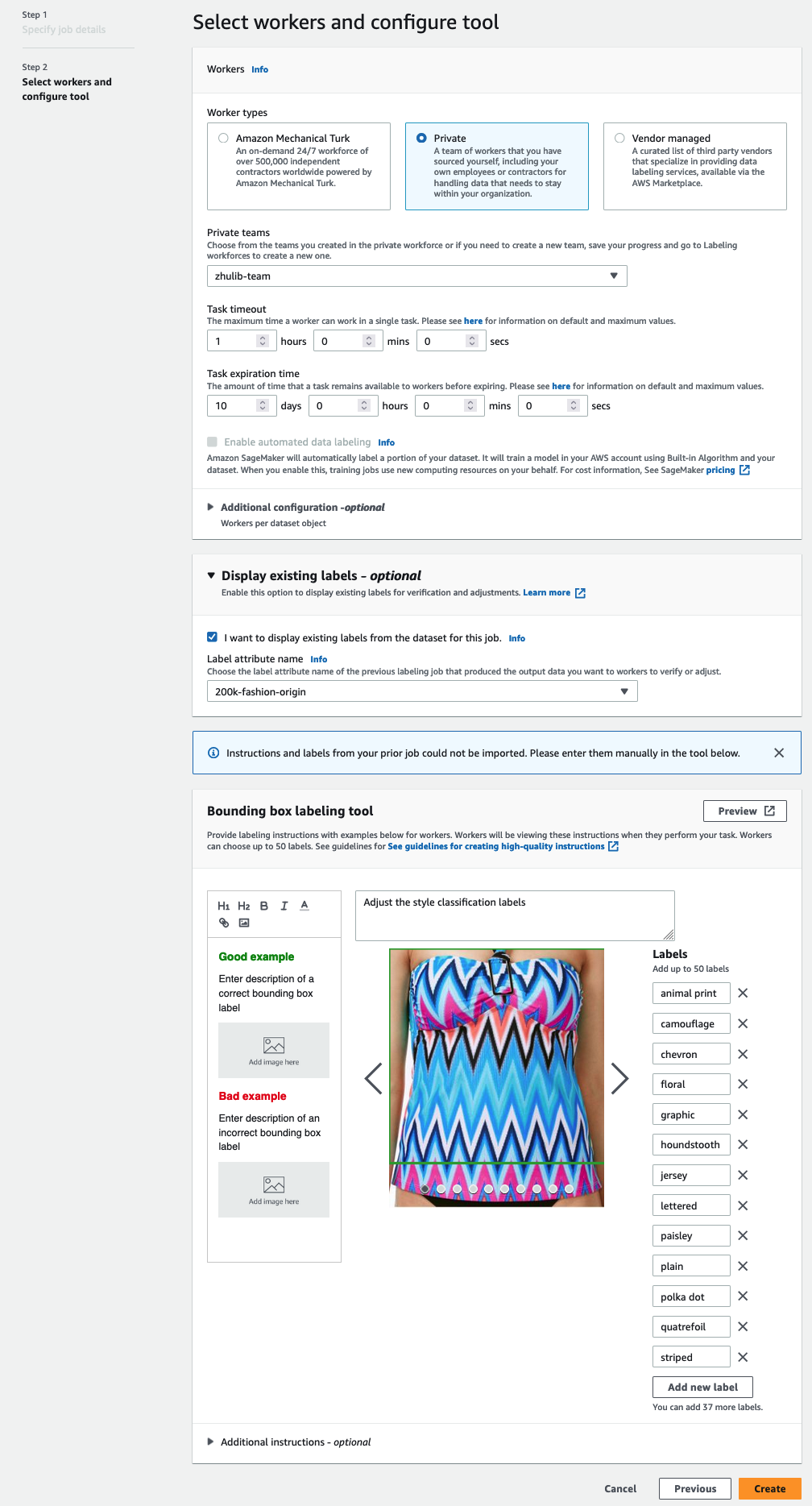 Etiketterna måste innehålla samma etiketter som används i den offentliga datamängden. Du kan lägga till nya etiketter. Följande skärmdump visar hur du kan välja arbetare och konfigurera verktyget för ditt etikettjobb.
Etiketterna måste innehålla samma etiketter som används i den offentliga datamängden. Du kan lägga till nya etiketter. Följande skärmdump visar hur du kan välja arbetare och konfigurera verktyget för ditt etikettjobb.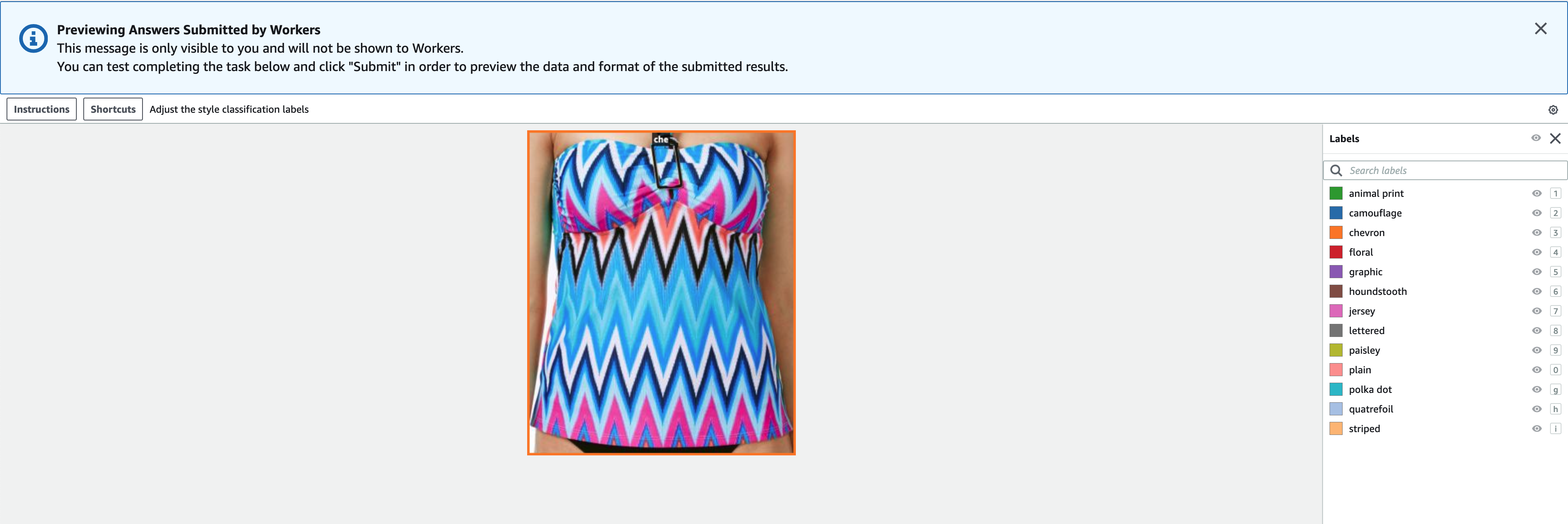
- Välja Förhandsvisning för att förhandsgranska bilden och originalanteckningarna.
Vi har nu skapat ett märkningsjobb i Ground Truth. När vårt jobb är klart kan vi ladda nygenererade märkta data i FiftyOne. Ground Truth producerar utdata i ett Ground Truth-utdatamanifest. För mer information om utdatamanifestfilen, se Bounding Box Job Output. Följande kod visar ett exempel på detta utdatamanifestformat:
Granska märkta resultat från Ground Truth i FiftyOne
När jobbet är klart laddar du ned utdatamanifestet för etikettjobbet från Amazon S3.
Läs utdatamanifestfilen:
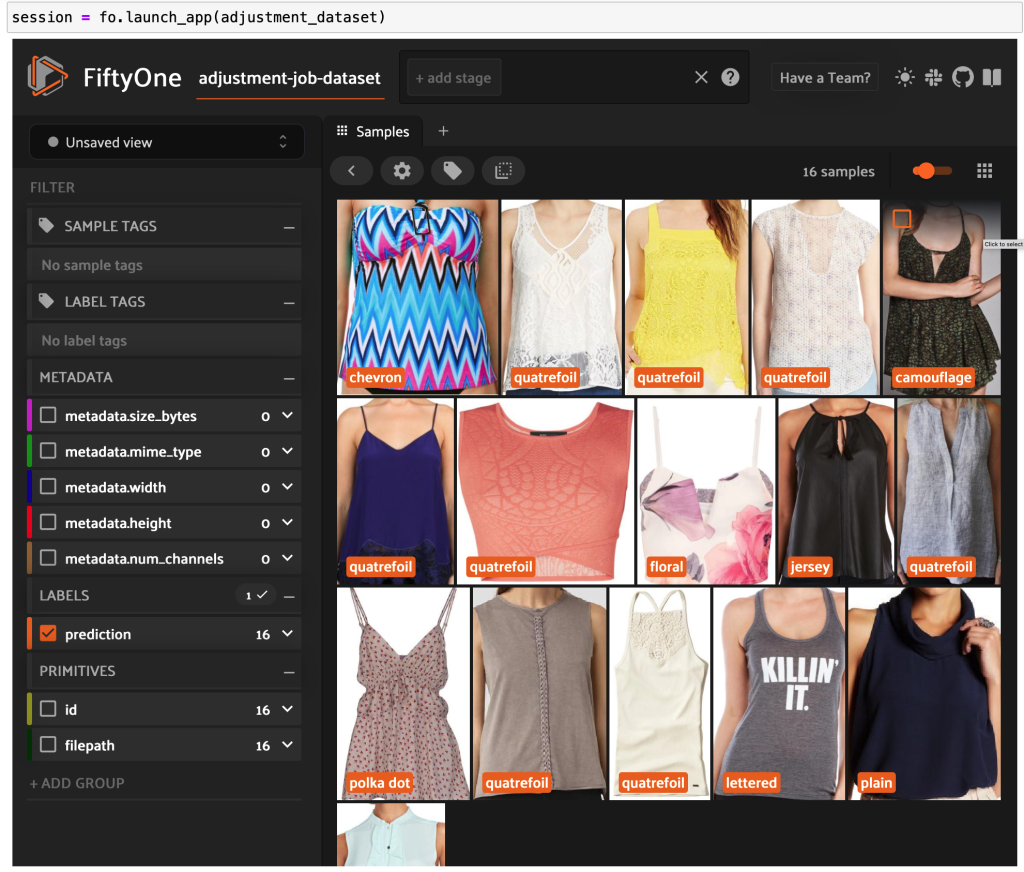
Skapa en FiftyOne-datauppsättning och konvertera manifestraderna till exempel i datasetet:
Du kan nu se märkt data av hög kvalitet från Ground Truth i FiftyOne.
Slutsats
I det här inlägget visade vi hur man bygger högkvalitativa datamängder genom att kombinera kraften i Femtioett by voxel51, en verktygslåda med öppen källkod som låter dig hantera, spåra, visualisera och kurera din datauppsättning, och Ground Truth, en datamärkningstjänst som låter dig effektivt och korrekt märka de datauppsättningar som krävs för att träna ML-system genom att ge tillgång till flera byggda -i uppgiftsmallar och tillgång till en mångsidig arbetsstyrka genom Mechanical Turk, tredjepartsleverantörer eller din egen privata arbetsstyrka.
Vi uppmuntrar dig att testa den här nya funktionen genom att installera en FiftyOne-instans och använda Ground Truth-konsolen för att komma igång. För att lära dig mer om Ground Truth, se Etikettdata, Vanliga frågor om Amazon SageMaker-datamärkning, Och den AWS-maskininlärningsblogg.
Anslut till Machine Learning & AI community om du har några frågor eller feedback!
Gå med i FiftyOne-communityt!
Gå med i de tusentals ingenjörer och datavetare som redan använder FiftyOne för att lösa några av de mest utmanande problemen inom datorseende idag!
Om författarna
Shalendra Chhabra är för närvarande chef för produkthantering för Amazon SageMaker Human-in-the-Loop (HIL) Services. Tidigare inkuberade och ledde Shalendra Language and Conversational Intelligence för Microsoft Teams Meetings, var EIR på Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing på Diskutera.io, Head of Product and Marketing på Clipboard (uppköpt av Salesforce), och Lead Product Manager på Swype (uppköpt av Nuance). Totalt har Shalendra hjälpt till att bygga, skicka och marknadsföra produkter som har berört mer än en miljard liv.
Jacob Marks är en maskininlärningsingenjör och utvecklarevangelist på Voxel51, där han hjälper till att skapa transparens och klarhet i världens data. Innan han gick med i Voxel51 grundade Jacob en startup för att hjälpa nya musiker att ansluta och dela kreativt innehåll med fans. Innan dess arbetade han på Google X, Samsung Research och Wolfram Research. I ett tidigare liv var Jacob en teoretisk fysiker och avslutade sin doktorsexamen vid Stanford, där han undersökte materiens kvantfaser. På fritiden tycker Jacob om att klättra, springa och läsa science fiction-romaner.
Jason Corso är en av grundarna och VD:n för Voxel51, där han styr strategin för att bidra till att skapa transparens och klarhet i världens data genom toppmodern flexibel mjukvara. Han är också professor i robotik, elektroteknik och datavetenskap vid University of Michigan, där han fokuserar på spjutspetsproblem i skärningspunkten mellan datorseende, naturligt språk och fysiska plattformar. På fritiden tycker Jason om att spendera tid med sin familj, läsa, vara i naturen, spela brädspel och alla möjliga kreativa aktiviteter.
Brian Moore är medgrundare och CTO för Voxel51, där han leder teknisk strategi och vision. Han har en doktorsexamen i elektroteknik från University of Michigan, där hans forskning var inriktad på effektiva algoritmer för storskaliga maskininlärningsproblem, med särskild tonvikt på datorseendetillämpningar. På fritiden tycker han om badminton, golf, vandring och att leka med sina tvillingar Yorkshireterrier.
Zhuling Bai är en mjukvaruutvecklingsingenjör på Amazon Web Services. Hon arbetar med att utveckla storskaliga distribuerade system för att lösa problem med maskininlärning.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Om oss
- accelerera
- accelererande
- accelerator
- tillgång
- exakt
- exakt
- förvärvade
- aktiviteter
- lägga till
- tillsats
- adress
- justerat
- Justering
- Efter
- igen
- AI
- alexa
- algoritmer
- Alla
- tillåter
- ensam
- redan
- också
- amason
- amazon alexa
- Amazon SageMaker
- Amazon SageMaker Ground Sannhet
- Amazon Web Services
- bland
- an
- analysera
- och
- djur
- vilken som helst
- app
- Ansökan
- tillämpningar
- Ansök
- lämpligt
- ÄR
- anordnad
- Artikeln
- artiklar
- AS
- associerad
- At
- Författarna
- bort
- AWS
- bas
- baserat
- BE
- därför att
- blir
- varit
- innan
- bakom
- bakom kulisserna
- Där vi får lov att vara utan att konstant prestera,
- tro
- BÄST
- Bättre
- mellan
- Miljarder
- ombord
- Brädspel
- BEN
- Bootstrap
- båda
- Box
- boxar
- Hjärna
- Ha sönder
- föra
- fört
- budget
- SLUTRESULTAT
- Byggnad
- inbyggd
- men
- Köp
- by
- KAN
- Fångande
- Vid
- fall
- kategorier
- Kategori
- VD
- utmanar
- utmanande
- ta
- Välja
- klarhet
- klass
- klasser
- klassificering
- Rengöring
- klar
- klart
- klient
- Klättring
- Stänga
- närmare
- kläder
- Kläder
- Medgrundare
- koda
- kombinera
- kombinera
- företag
- Komplement
- fullborda
- fullborda
- Compute
- dator
- Datavetenskap
- Datorsyn
- Datorseende applikationer
- förtroende
- säker
- Kontakta
- övervägande
- Bestående
- Konsol
- innehåller
- innehåll
- innehåll
- kontrolleras
- konversera
- konvertera
- kopior
- Kärna
- Korrigerad
- motsvarar
- Pris
- Kostar
- skapa
- skapas
- Kreativ
- referenser
- CTO
- kurerad
- organisera
- För närvarande
- beställnings
- kund
- Kunder
- Klipp
- allra senaste
- datum
- datauppsättningar
- beslutar
- demonstrera
- Denim
- djup
- beskrivning
- detaljer
- Detektering
- Utvecklare
- utveckla
- Utveckling
- olika
- direkt
- kataloger
- Visa
- distinkt
- distribueras
- distribuerade system
- flera
- do
- inte
- Dog
- gör
- gjort
- inte
- DOT
- ner
- ladda ner
- dubbletter
- e
- varje
- lätt
- kant
- effekt
- effektiv
- effektivt
- elektroteknik
- inbäddning
- smärgel
- vikt
- sysselsätter
- bemyndigar
- inkapslad
- uppmuntra
- änden
- ingenjör
- Teknik
- Ingenjörer
- ange
- Miljö
- jämlikhet
- väsentlig
- etablerade
- Eter (ETH)
- utvärdering
- Evangelist
- exakt
- exempel
- befintliga
- export
- ganska
- familj
- fans
- återkoppling
- få
- Fiktion
- fält
- Fält
- Fil
- Filer
- filtrera
- filtrering
- slutlig
- Förnamn
- passa
- flexibel
- Fokus
- fokuserade
- fokuserar
- efter
- För
- formen
- format
- Lyckligtvis
- Grundad
- fyra
- Fri
- från
- fullständigt
- funktionalitet
- Games
- generell mening
- generera
- genereras
- skaffa sig
- GitHub
- Ge
- ges
- Målet
- golf
- god
- större
- Rutnät
- Marken
- Grupp
- styra
- lyckligt
- Har
- he
- huvud
- höjd
- hjälpa
- hjälpte
- hjälp
- hjälper
- här.
- hög kvalitet
- hög upplösning
- högsta
- höggradigt
- vandring
- hans
- innehar
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- humant
- i
- IAM
- ID
- identifiera
- identifiera
- ids
- if
- bild
- bilder
- Inverkan
- importera
- förbättra
- in
- I andra
- Inklusive
- felaktigt
- inkuberades
- informationen
- inledande
- initialt
- installera
- installera
- exempel
- istället
- instruktioner
- Intelligens
- skärning
- in
- IT
- DESS
- Jersey
- Jobb
- sammanfogning
- gemensam
- json
- bara
- Ha kvar
- hålla
- etikett
- märkning
- Etiketter
- språk
- storskalig
- lansera
- lansera
- leda
- Leads
- LÄRA SIG
- inlärning
- t minst
- Led
- vänster
- Lets
- Bibliotek
- livet
- tycka om
- sannolikt
- BEGRÄNSA
- Begränsad
- linje
- rader
- Lista
- lista
- Annonser
- liten
- Bor
- läsa in
- se
- du letar
- Lot
- Låg
- Maskinen
- maskininlärning
- gjord
- magi
- göra
- GÖR
- hantera
- förvaltade
- ledning
- chef
- många
- karta
- marknad
- Marknadsföring
- Match
- matchande
- väsentligt
- Materia
- Maj..
- mekanisk
- Media
- möten
- meta
- metadata
- metod
- metoder
- Michigan
- Microsoft
- Microsoft-team
- kanske
- minsta
- ML
- Mobil
- Mobil app
- modell
- modeller
- Moduler
- mer
- mest
- flytta
- mycket
- multipel
- musiker
- måste
- namn
- Som heter
- namn
- Natural
- Naturligt språk
- Natur
- Nära
- nödvändigtvis
- nödvändigt för
- Behöver
- behov
- Nya
- märkbart
- Begrepp
- nu
- Nyans
- antal
- objektet
- Objektdetektion
- objekt
- of
- tjänsteman
- on
- gång
- ONE
- nätet
- endast
- öppet
- öppen källkod
- Verksamhet
- Möjlighet
- Tillbehör
- or
- Organiserad
- ursprungliga
- OS
- Övriga
- Övrigt
- vår
- ut
- skisse
- produktion
- över
- egen
- äger
- förpackningar
- parade
- del
- särskilt
- Tidigare
- bana
- Mönster
- mönster
- perfekt
- prestanda
- personen
- personlig
- Materiens faser
- fysisk
- plocka
- Bilder
- PLÄD
- Enkel
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- i
- Punkt
- befolkad
- möjlig
- Inlägg
- kraft
- praktiken
- förutsagda
- förutsägelse
- Förutsägelser
- Förhandsvisning
- föregående
- tidigare
- Skriva ut
- Innan
- privat
- förmodligen
- problem
- process
- Produkt
- produktledning
- produktchef
- Produkter
- Professor
- projektet
- egenskapen
- blivande
- Prototypen
- ge
- förutsatt
- tillhandahålla
- allmän
- stansen
- syfte
- Python
- Quantum
- frågor
- snabbt
- område
- snarare
- Läsning
- redo
- rekommenderar
- rekommendationer
- minska
- Minskad
- reduktion
- relativt
- frigörs
- relevanta
- ta bort
- representativ
- representerar
- Obligatorisk
- forskning
- forskare
- Upplösning
- begränsa
- resultera
- resulterande
- Resultat
- detaljhandeln
- avkastning
- översyn
- Befria
- robotik
- robusta
- Roll
- ungefär
- RAD
- ruin
- rinnande
- sagemaker
- Nämnda
- Salesforce
- Samma
- Samsung
- Save
- scener
- Vetenskap
- Science Fiction
- vetenskapsmän
- göra
- sömlöst
- Andra
- §
- sektioner
- se
- verka
- verkar
- vald
- känsla
- separat
- service
- Tjänster
- session
- in
- Dela
- hon
- skall
- show
- Visar
- SIM
- liknande
- Enkelt
- mindre
- So
- Mjukvara
- mjukvaruutveckling
- LÖSA
- några
- någon
- något
- Utrymme
- spendera
- Spendera
- delas
- Delar upp
- stanford
- starta
- igång
- Starta
- start
- startaccelerator
- state-of-the-art
- Steg
- Fortfarande
- förvaring
- lagra
- Strategi
- stil
- stilar
- SAMMANFATTNING
- Som stöds
- System
- Ta
- uppgift
- lag
- Teknisk
- Techstars
- berättar
- mallar
- testa
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- teoretiska
- Där.
- Dessa
- de
- saker
- tror
- tredje part
- detta
- tusentals
- tröskelvärde
- Genom
- Kasta
- tid
- till
- tillsammans
- verktyg
- toolkit
- topp
- toppnivå
- Överdelar
- Totalt
- rörd
- spår
- Tåg
- tränad
- Utbildning
- Förvandla
- Öppenhet
- sann
- sanningen
- SVÄNG
- två
- Typ
- typer
- under
- förstå
- unika
- universitet
- University of Michigan
- Uppdatering
- us
- användning
- användningsfall
- Begagnade
- Användare
- användare
- med hjälp av
- Värden
- mängd
- olika
- försäljare
- verifiera
- mycket
- via
- utsikt
- Virtuell
- syn
- vill
- var
- we
- webb
- webbservice
- VÄL
- były
- Vad
- när
- om
- som
- wikipedia
- kommer
- med
- inom
- utan
- Kvinnor
- ord
- Arbete
- arbetade
- arbetare
- arbetskraft
- fungerar
- Världens
- oro
- skulle
- skriva
- X
- dig
- Din
- zephyrnet
- Postnummer
- ZOO