I dagens datadrivna affärsmiljö står organisationer inför utmaningen att effektivt förbereda och omvandla stora mängder data för analytiska och datavetenskapliga ändamål. Företag måste bygga datalager och datasjöar baserat på driftsdata. Detta drivs av behovet av att centralisera och integrera data som kommer från olika källor.
Samtidigt härrör driftdata ofta från applikationer som backas upp av äldre datalager. Att modernisera applikationer kräver en mikrotjänstarkitektur, vilket i sin tur kräver konsolidering av data från flera källor för att konstruera ett operativt datalager. Utan modernisering kan äldre applikationer medföra ökade underhållskostnader. Att modernisera applikationer innebär att den underliggande databasmotorn ändras till en modern dokumentbaserad databas som MongoDB.
Dessa två uppgifter (bygga datasjöar eller datalager och applikationsmodernisering) involverar datarörelse, som använder en extrahera, transformera och ladda (ETL) process. ETL-jobbet är en nyckelfunktion för att ha en välstrukturerad process för att lyckas.
AWS-lim är en serverlös dataintegrationstjänst som gör det enkelt att upptäcka, förbereda, flytta och integrera data från flera källor för analys, maskininlärning (ML) och applikationsutveckling. MongoDB Atlas är en integrerad svit av molndatabas- och datatjänster som kombinerar transaktionsbearbetning, relevansbaserad sökning, realtidsanalys och mobil-till-moln-datasynkronisering i en elegant och integrerad arkitektur.
Genom att använda AWS Glue med MongoDB Atlas kan organisationer effektivisera sina ETL-processer. Med sin fullt hanterade, skalbara och säkra databaslösning tillhandahåller MongoDB Atlas en flexibel och pålitlig miljö för lagring och hantering av driftsdata. Tillsammans är AWS Glue ETL och MongoDB Atlas en kraftfull lösning för organisationer som vill optimera hur de bygger datasjöar och datalager, och modernisera sina applikationer, för att förbättra verksamhetens prestanda, minska kostnaderna och driva tillväxt och framgång.
I det här inlägget visar vi hur man migrerar data från Amazon enkel lagringstjänst (Amazon S3) hinkar till MongoDB Atlas med AWS Glue ETL, och hur man extraherar data från MongoDB Atlas till en Amazon S3-baserad datasjö.
Lösningsöversikt
I det här inlägget utforskar vi följande användningsfall:
- Extrahera data från MongoDB – MongoDB är en populär databas som används av tusentals kunder för att lagra applikationsdata i stor skala. Företagskunder kan centralisera och integrera data som kommer från flera datalager genom att bygga datasjöar och datalager. Denna process innebär att extrahera data från de operativa datalagren. När data finns på ett ställe kan kunderna snabbt använda dem för affärsinformationsbehov eller för ML.
- Inför data i MongoDB – MongoDB fungerar också som en no-SQL-databas för att lagra applikationsdata och bygga operativa datalager. Modernisering av applikationer innebär ofta migrering av den operativa butiken till MongoDB. Kunder skulle behöva extrahera befintliga data från relationsdatabaser eller från platta filer. Mobil- och webbappar kräver ofta att dataingenjörer bygger datapipelines för att skapa en enda vy av data i Atlas samtidigt som de matar in data från flera silade källor. Under denna migrering skulle de behöva gå med i olika databaser för att skapa dokument. Denna komplexa sammanfogningsoperation skulle behöva betydande engångsräknekraft. Utvecklare skulle också behöva bygga detta snabbt för att migrera data.
AWS Glue är praktiskt i dessa fall med pay-as-you-go-modellen och dess förmåga att köra komplexa transformationer över enorma datamängder. Utvecklare kan använda AWS Glue Studio för att effektivt skapa sådana datapipelines.
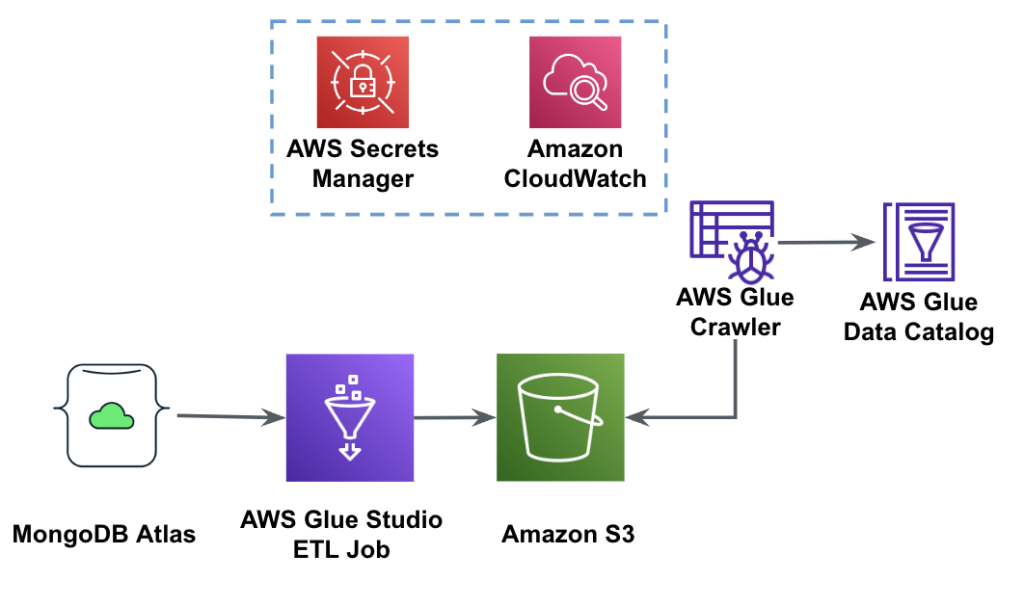
Följande diagram visar arbetsflödet för dataextraktion från MongoDB Atlas till en S3-hink med hjälp av AWS Glue Studio.
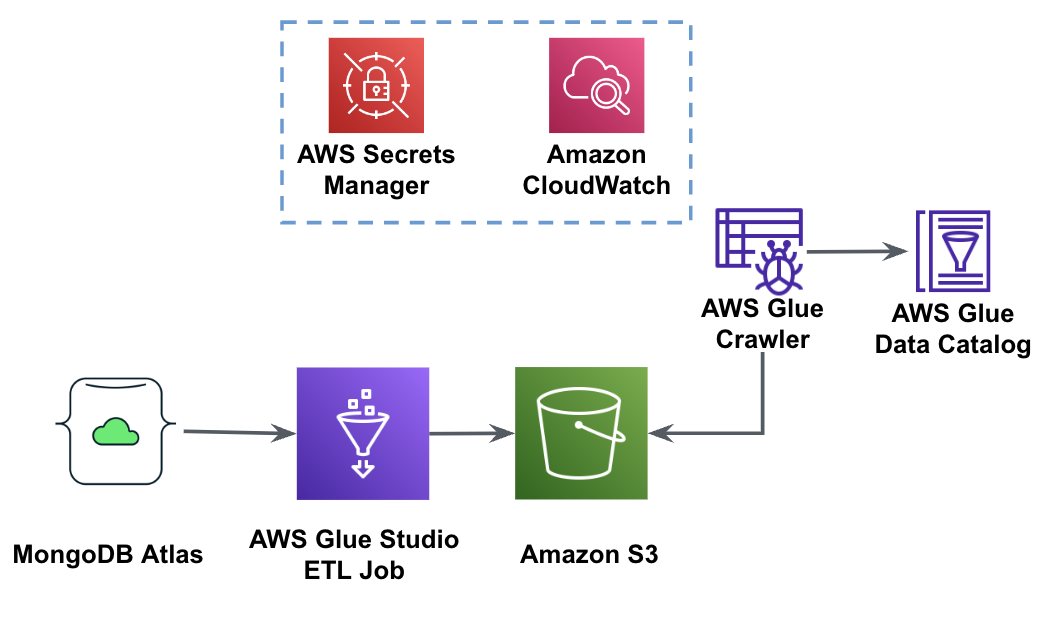
För att implementera den här arkitekturen behöver du ett MongoDB Atlas-kluster, en S3-hink och en AWS identitets- och åtkomsthantering (IAM) roll för AWS Glue. För att konfigurera dessa resurser, se de nödvändiga stegen i följande GitHub repo.
Följande bild visar arbetsflödet för dataladdning från en S3-skopa till MongoDB Atlas med hjälp av AWS Glue.
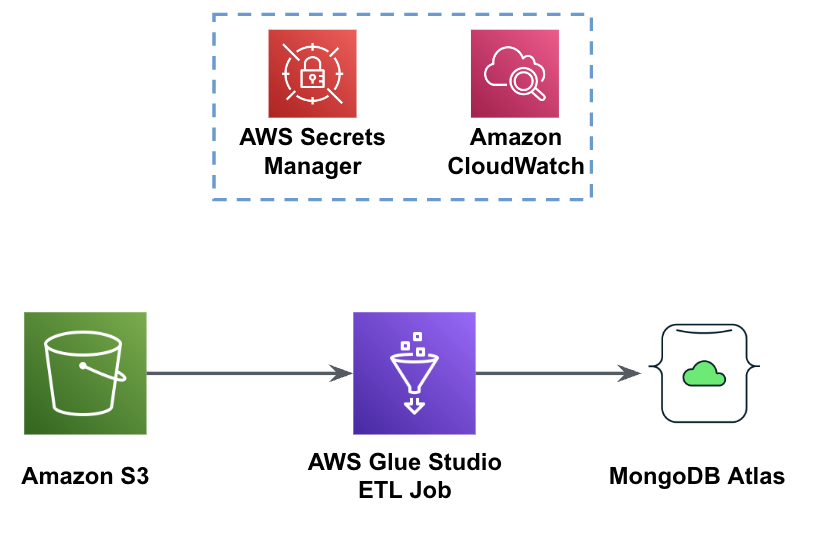
Samma förutsättningar behövs här: en S3-hink, IAM-roll och ett MongoDB Atlas-kluster.
Ladda data från Amazon S3 till MongoDB Atlas med AWS Glue
Följande steg beskriver hur man laddar data från S3-skopan till MongoDB Atlas med hjälp av ett AWS-limjobb. Extraktionsprocessen från MongoDB Atlas till Amazon S3 är väldigt lik, med undantag för skriptet som används. Vi nämner skillnaderna mellan de två processerna.
- Skapa ett gratis kluster i MongoDB Atlas.
- Ladda upp exempel på JSON-fil till din S3-skopa.
- Skapa ett nytt AWS Glue Studio-jobb med Spark script editor alternativ.

- Beroende på om du vill ladda eller extrahera data från MongoDB Atlas-klustret, skriv in ladda skript or extrahera skript i AWS Glue Studio manusredigerare.
Följande skärmdump visar ett kodavsnitt för att ladda data till MongoDB Atlas-klustret.

Koden använder AWS Secrets Manager för att hämta MongoDB Atlas-klusternamn, användarnamn och lösenord. Sedan skapar det en DynamicFrame för S3-hinken och filnamnet som skickas till skriptet som parametrar. Koden hämtar databasen och samlingsnamnen från jobbparametrarnas konfiguration. Slutligen skriver koden DynamicFrame till MongoDB Atlas-klustret med hjälp av de hämtade parametrarna.
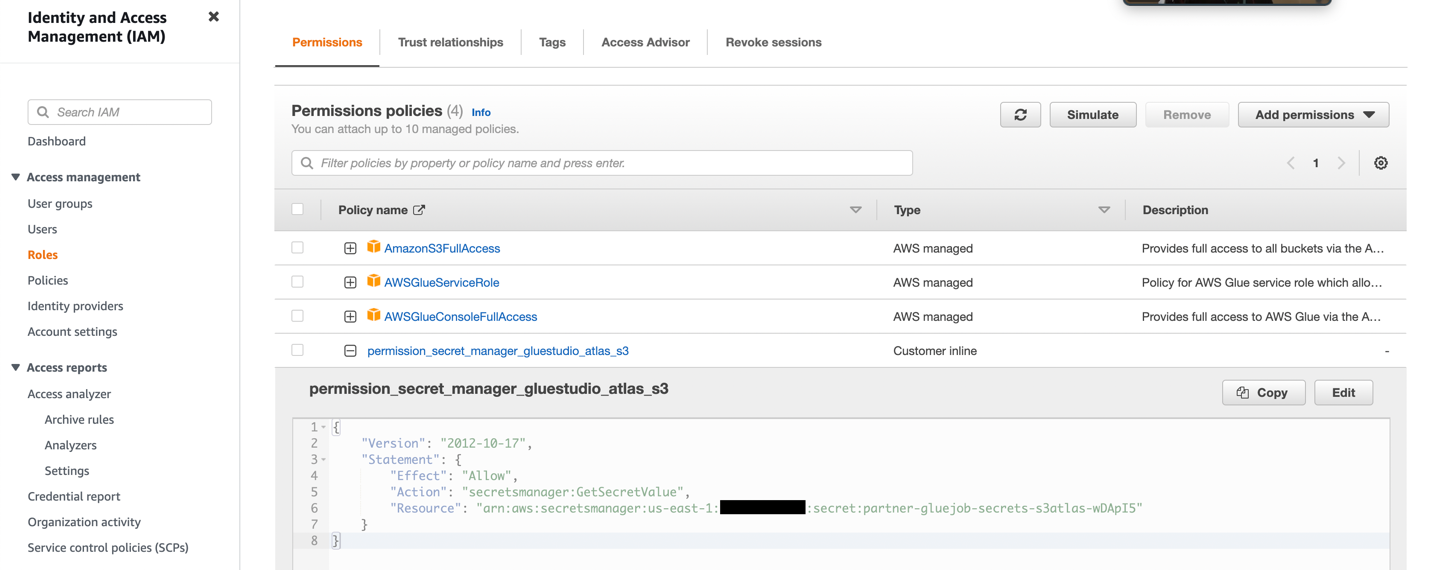
- Skapa en IAM-roll med behörigheterna som visas i följande skärmdump.
Mer information finns i Konfigurera en IAM-roll för ditt ETL-jobb.
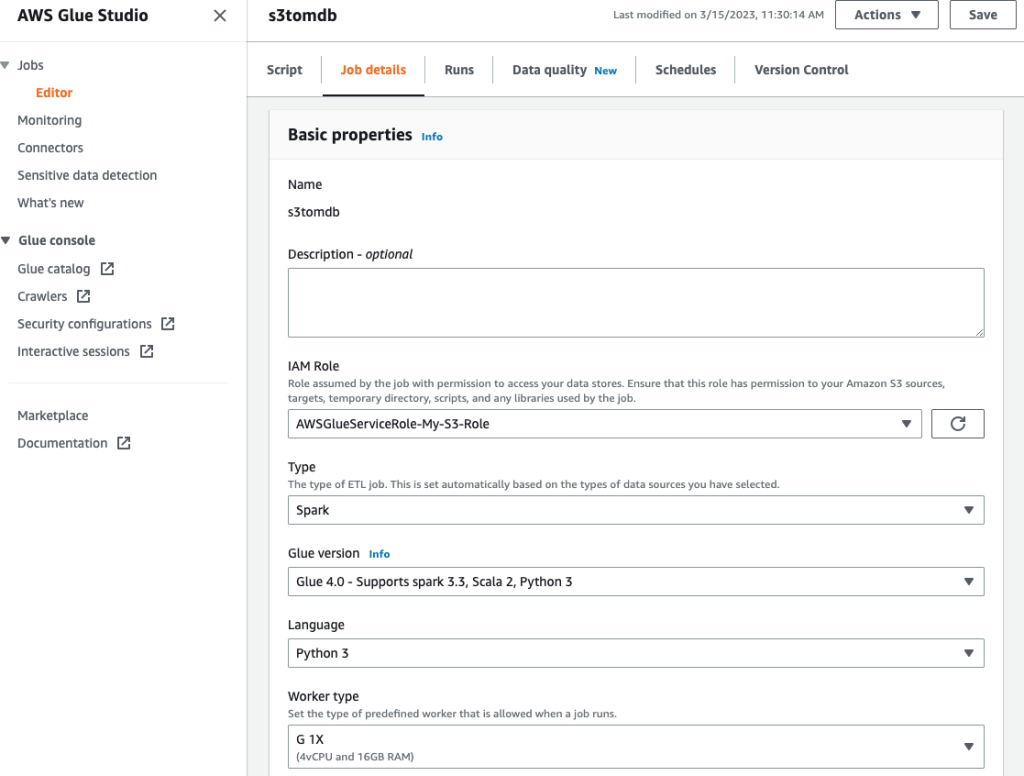
- Ge jobbet ett namn och ange IAM-rollen som skapades i föregående steg på Jobb detaljer fliken.
- Du kan lämna resten av parametrarna som standard, som visas i följande skärmdumpar.
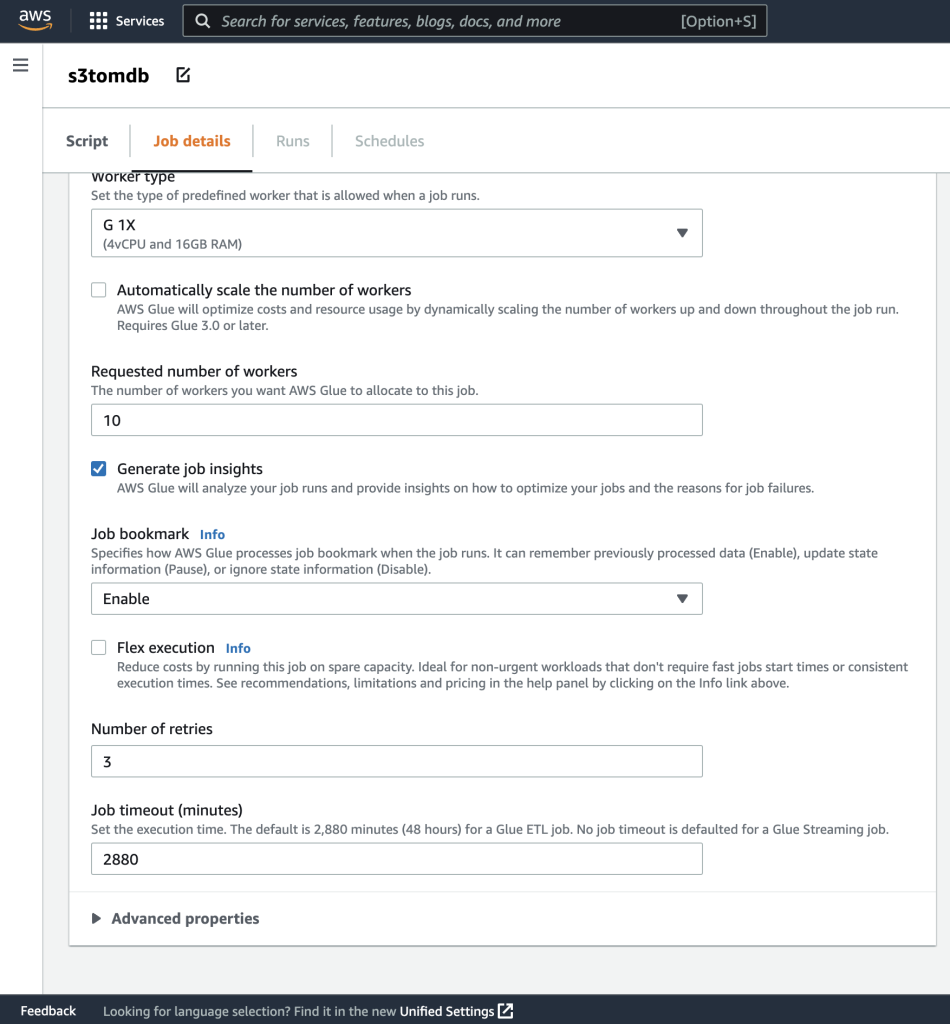
- Definiera sedan jobbparametrarna som skriptet använder och ange standardvärdena.
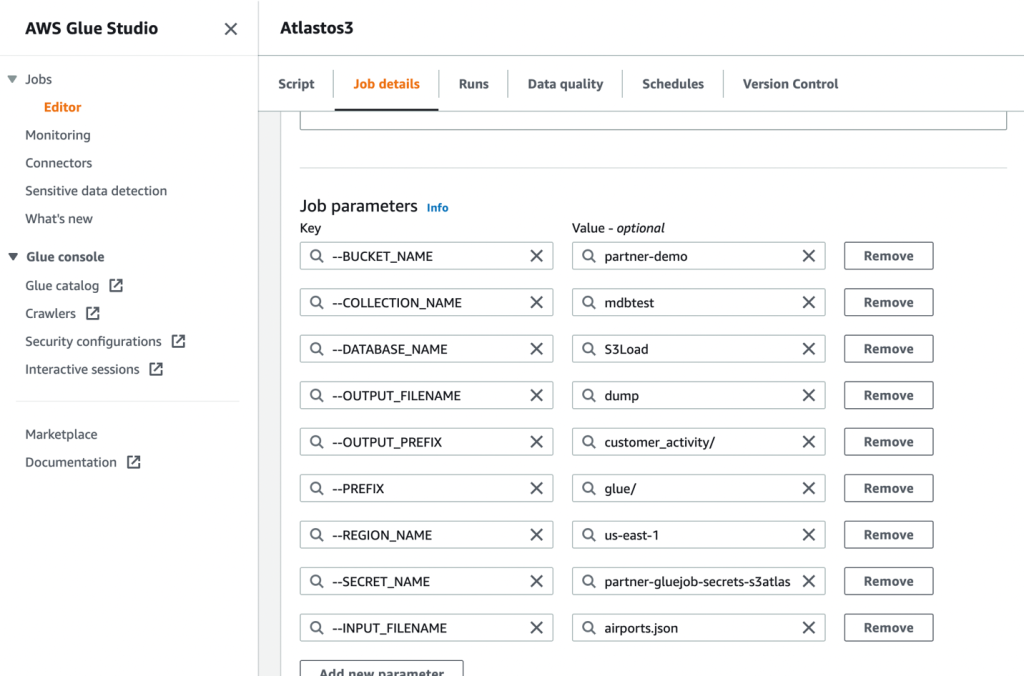
- Spara jobbet och kör det.
- För att bekräfta en lyckad körning, observera innehållet i MongoDB Atlas-databassamlingen om data laddas, eller S3-hinken om du utförde ett extrakt.



Följande skärmdump visar resultaten av en lyckad dataladdning från en Amazon S3-hink till MongoDB Atlas-klustret. Datan är nu tillgänglig för frågor i MongoDB Atlas UI.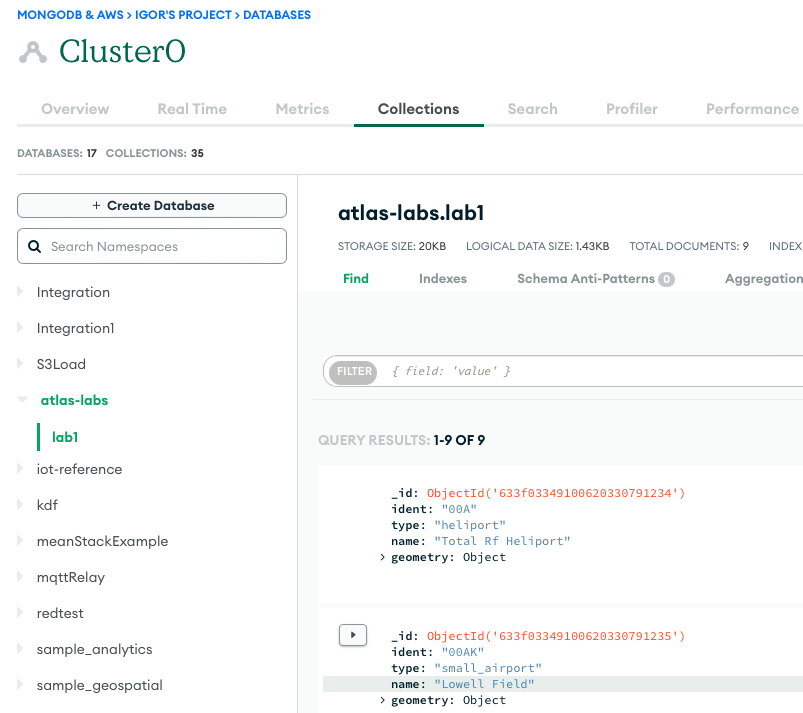
- För att felsöka dina körningar, granska amazoncloudwatch loggar med hjälp av länken på jobbets Körning fliken.
Följande skärmdump visar att jobbet kördes framgångsrikt, med ytterligare detaljer som länkar till CloudWatch-loggarna.

Slutsats
I det här inlägget beskrev vi hur man extraherar och matar in data till MongoDB Atlas med hjälp av AWS Glue.
Med AWS Glue ETL-jobb kan vi nu överföra data från MongoDB Atlas till AWS Glue-kompatibla källor och vice versa. Du kan också utöka lösningen till att bygga analyser med AWS AI- och ML-tjänster.
För att lära dig mer, se GitHub repository för steg-för-steg-instruktioner och exempelkod. Du kan införskaffa MongoDB Atlas på AWS Marketplace.
Om författarna

Igor Alekseev är Senior Partner Solution Architect på AWS inom data- och analysdomän. I sin roll arbetar Igor med strategiska partners som hjälper dem att bygga komplexa, AWS-optimerade arkitekturer. Innan han började på AWS implementerade han som data-/lösningsarkitekt många projekt inom Big Data-domänen, inklusive flera datasjöar i Hadoop-ekosystemet. Som dataingenjör var han involverad i att tillämpa AI/ML för att upptäcka bedrägerier och kontorsautomation.
 Babu Srinivasan är Senior Partner Solutions Architect på MongoDB. I sin nuvarande roll arbetar han med AWS för att bygga de tekniska integrationerna och referensarkitekturerna för AWS- och MongoDB-lösningarna. Han har mer än två decennier av erfarenhet av databas- och molnteknologier. Han brinner för att tillhandahålla tekniska lösningar till kunder som arbetar med flera globala systemintegratörer (GSI) över flera geografiska områden.
Babu Srinivasan är Senior Partner Solutions Architect på MongoDB. I sin nuvarande roll arbetar han med AWS för att bygga de tekniska integrationerna och referensarkitekturerna för AWS- och MongoDB-lösningarna. Han har mer än två decennier av erfarenhet av databas- och molnteknologier. Han brinner för att tillhandahålla tekniska lösningar till kunder som arbetar med flera globala systemintegratörer (GSI) över flera geografiska områden.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- : har
- :är
- 100
- 11
- a
- förmåga
- Om oss
- tillgång
- tvärs
- Annat
- AI
- AI / ML
- också
- amason
- mängder
- an
- analytics
- och
- Ansökan
- Application Development
- tillämpningar
- Tillämpa
- appar
- arkitektur
- ÄR
- AS
- At
- atlas
- Automation
- tillgänglig
- AWS
- AWS-lim
- AWS Marketplace
- dragen tillbaka
- baserat
- Där vi får lov att vara utan att konstant prestera,
- mellan
- Stor
- Stora data
- SLUTRESULTAT
- Byggnad
- företag
- business intelligence
- affärsprestation
- företag
- by
- Ring
- KAN
- fall
- utmanar
- byte
- cloud
- kluster
- koda
- samling
- kombinerar
- kommer
- kommande
- komplex
- Compute
- konfiguration
- Bekräfta
- konsolidering
- konstruera
- innehåll
- fortsatte
- Kostar
- skapa
- skapas
- skapar
- skapande
- Aktuella
- Kunder
- datum
- dataingenjör
- dataintegration
- datasjö
- datavetenskap
- datalager
- data driven
- Databas
- databaser
- datauppsättningar
- årtionden
- Standard
- demonstrera
- beskriva
- beskriven
- detaljer
- Detektering
- utvecklare
- Utveckling
- skillnader
- olika
- Upptäck
- disparat
- dokument
- domän
- driv
- driven
- under
- ekosystemet
- redaktör
- effektivt
- Motor
- ingenjör
- Ingenjörer
- ange
- Företag
- företagskunder
- Miljö
- Eter (ETH)
- undantag
- befintliga
- erfarenhet
- utforska
- förlänga
- extrahera
- extraktion
- Ansikte
- Figur
- Fil
- Filer
- Slutligen
- platta
- flexibel
- efter
- För
- bedrägeri
- spårning av bedrägerier
- Fri
- från
- fullständigt
- funktionalitet
- geografier
- Välgörenhet
- Tillväxt
- Hadoop
- praktisk
- har
- he
- hjälpa
- här.
- hans
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- stor
- IAM
- Identitet
- if
- genomföra
- genomföras
- förbättra
- in
- Inklusive
- ökande
- ingång
- instruktioner
- integrera
- integrerade
- integrering
- integrationer
- Intelligens
- in
- engagera
- involverade
- IT
- DESS
- Jobb
- Lediga jobb
- delta
- sammanfogning
- json
- Nyckel
- sjö
- Large
- LÄRA SIG
- inlärning
- Lämna
- Legacy
- tycka om
- LINK
- länkar
- läsa in
- läser in
- du letar
- Maskinen
- maskininlärning
- underhåll
- GÖR
- förvaltade
- hantera
- många
- marknadsplats
- Maj..
- migrera
- migration
- ML
- Mobil
- modell
- Modern Konst
- modernisering
- modernisera
- MongoDB
- mer
- flytta
- rörelse
- multipel
- namn
- namn
- Behöver
- behövs
- behov
- Nya
- nu
- observera
- of
- Office
- Ofta
- on
- ONE
- drift
- operativa
- Optimera
- Alternativet
- or
- beställa
- organisationer
- ut
- parametrar
- partnern
- partner
- Godkänd
- brinner
- Lösenord
- prestanda
- utför
- behörigheter
- Plats
- plato
- Platon Data Intelligence
- PlatonData
- Populära
- Inlägg
- kraft
- den mäktigaste
- Förbered
- förbereda
- förutsättningar
- föregående
- Innan
- process
- processer
- bearbetning
- projekt
- ger
- tillhandahålla
- syfte
- sökfrågor
- snabbt
- realtid
- minska
- pålitlig
- kräver
- Kräver
- Resurser
- REST
- Resultat
- översyn
- Roll
- Körning
- Samma
- skalbar
- Skala
- Vetenskap
- skärmdumpar
- Sök
- säkra
- senior
- Server
- serverar
- service
- Tjänster
- flera
- visas
- Visar
- signifikant
- liknande
- Enkelt
- enda
- lösning
- Lösningar
- Källor
- Steg
- Steg
- förvaring
- lagra
- lagrar
- okomplicerad
- Strategisk
- strategiska partners
- effektivisera
- studio
- lyckas
- framgång
- framgångsrik
- Framgångsrikt
- sådana
- svit
- leverera
- synkronisering
- system
- uppgifter
- Teknisk
- Tekniken
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Dessa
- de
- detta
- tusentals
- tid
- till
- dagens
- tillsammans
- transaktion
- överföring
- Förvandla
- transformationer
- omvandla
- SVÄNG
- två
- ui
- underliggande
- användning
- Begagnade
- Användare
- med hjälp av
- Värden
- mycket
- utsikt
- vill
- var
- we
- webb
- były
- när
- om
- som
- medan
- kommer
- med
- utan
- arbetsflöde
- arbetssätt
- skulle
- dig
- Din
- zephyrnet