Välkommen till datatiden. Den stora mängden data som samlas in dagligen fortsätter att växa, vilket kräver plattformar och lösningar för att utvecklas. Tjänster som t.ex Amazon enkel lagringstjänst (Amazon S3) erbjuder en skalbar lösning som anpassar sig men ändå är kostnadseffektiv för växande datauppsättningar. De Amazon Sustainability Data Initiative (ASDI) använder funktionerna hos Amazon S3 för att tillhandahålla en kostnadsfri lösning för dig att lagra och dela klimatvetenskapliga arbetsbelastningar över hela världen. Amazons Open Data Sponsorship Program tillåter organisationer att vara värd gratis på AWS.
Under det senaste decenniet har vi sett en ökning av ramverk för datavetenskap som kommer att förverkligas, tillsammans med massantagande av datavetenskapsgemenskapen. Ett sådant ramverk är dask, som är kraftfull för sin förmåga att tillhandahålla en orkestrering av arbetarnoder, vilket påskyndar komplex analys av stora datamängder.
I det här inlägget visar vi dig hur du distribuerar en anpassad AWS Cloud Development Kit (AWS CDK) lösning som utökar Dasks funktionalitet till att fungera interregionalt över Amazons globala nätverk. AWS CDK-lösningen distribuerar ett nätverk av Dask-arbetare över två AWS-regioner och ansluter till en klientregion. För mer information, se Vägledning för distribuerad datoranvändning med Cross Regional Dask på AWS och GitHub repo för öppen källkod.
Efter implementeringen kommer användaren att ha tillgång till en Jupyter-anteckningsbok, där de kan interagera med två datauppsättningar från ASDI på AWS: Coupled Model Intercomparison Project 6 (CMIP6) och ECMWF ERA5 omanalys. CMIP6 fokuserar på den sjätte fasen av globala kopplade ocean-atmosfärens allmänna cirkulationsmodellensemble; ERA5 är den femte generationen av ECMWF-atmosfäriska omanalyser av det globala klimatet, och den första omanalysen som produceras som en operativ tjänst.
Denna lösning inspirerades av arbete med en viktig AWS-kund, the UK Met Office. Met Office grundades 1854 och är den nationella meteorologiska tjänsten för Storbritannien. De ger väder- och klimatförutsägelser för att hjälpa dig att fatta bättre beslut för att förbli säker och frodas. Ett samarbete mellan Met Office och EUMETSAT, detaljerat i Datanära beräkning på ett Dask-kluster distribuerat mellan datacenter, belyser det växande behovet av att utveckla en hållbar, effektiv och skalbar datavetenskaplig lösning. Den här lösningen uppnår detta genom att föra datorer närmare data, snarare än att tvinga data att komma närmare beräkningsresurser, vilket lägger till kostnad, latens och energi.
Lösningsöversikt
Varje dag producerar UK Met Office upp till 300 TB väder- och klimatdata, varav en del publiceras till ASDI. Dessa datauppsättningar är distribuerade över hela världen och värd för offentligt bruk. Met Office skulle vilja göra det möjligt för konsumenter att få ut mer av sina data för att hjälpa till att informera kritiska beslut om att ta itu med frågor som bättre förberedelser för skogsbränder och översvämningar orsakade av klimatförändringar, och minska matosäkerheten genom bättre skördeanalys.
Traditionella lösningar som används idag, särskilt med klimatdata, är tidskrävande och ohållbara och replikerar datauppsättningar över regioner. Onödig dataöverföring på petabyte-skalan är kostsam, långsam och förbrukar energi.
Vi uppskattade att om denna praxis anammades av Met Office-användarna skulle motsvarande 40 hems dagliga strömförbrukning kunna sparas varje dag, och de kunde också minska överföringen av data mellan regioner.
Följande diagram illustrerar lösningsarkitekturen.
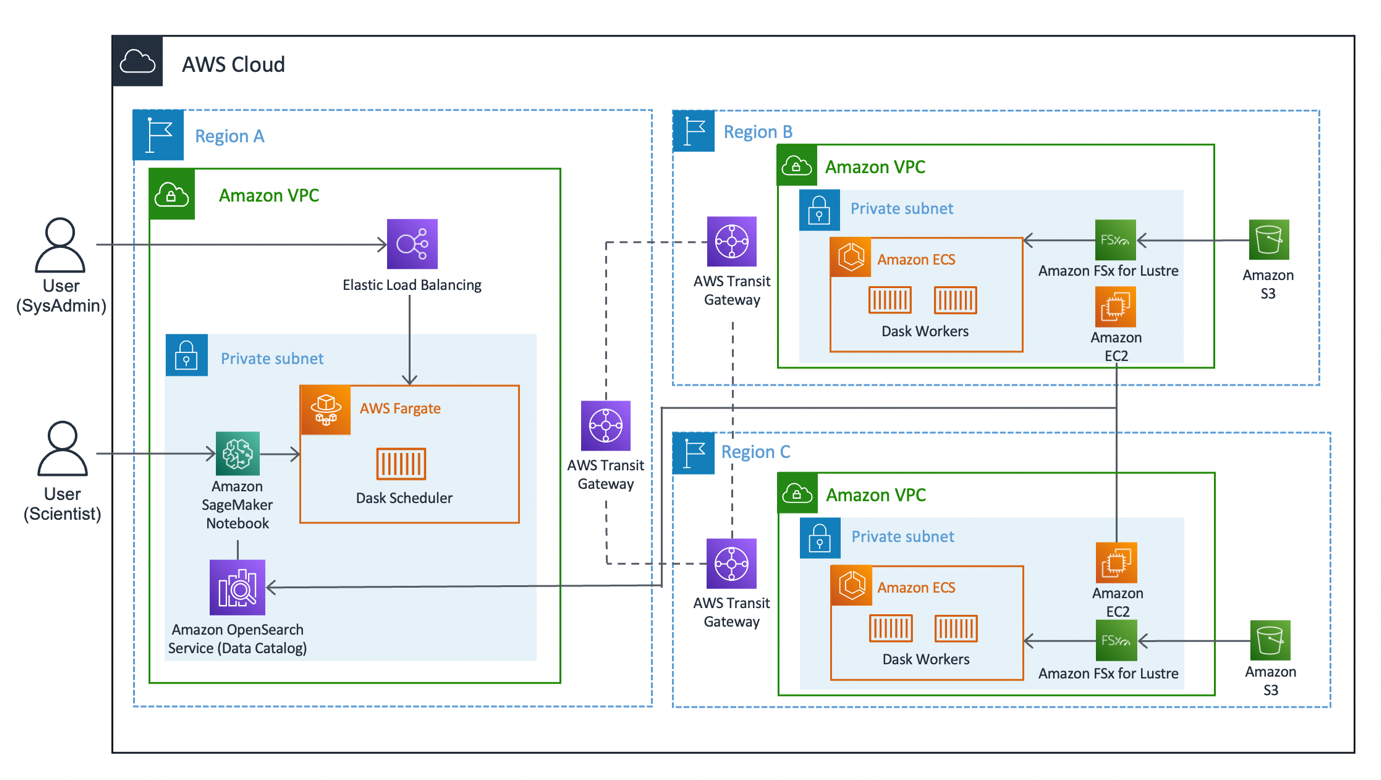
Lösningen kan delas in i tre huvudsegment: klient, arbetare och nätverk. Låt oss dyka in i var och en och se hur de går ihop.
Klient
Klienten representerar källregionen där datavetare ansluter. Denna region (Region A i diagrammet) innehåller en Amazon SageMaker anteckningsbok, En Amazon OpenSearch Service domän och en Schemaläggare för mörker som nyckelkomponenter. Systemadministratörer har tillgång till den inbyggda Dask-instrumentpanelen som exponeras via en Elastisk belastningsbalans.
Dataforskare har tillgång till Jupyter-anteckningsboken som finns på SageMaker. Den bärbara datorn kan ansluta och köra arbetsbelastningar på Dask-schemaläggaren. OpenSearch Service-domänen lagrar metadata på de datauppsättningar som är anslutna till regionerna. Notebook-användare kan fråga den här tjänsten för att hämta detaljer såsom rätt Region of Dask-arbetare utan att behöva känna till datas regionala plats i förväg.
Arbetare
Var och en av arbetarregionerna (region B och C i diagrammet) består av en Amazon Elastic Container Service (Amazon ECS) kluster av Skyddsarbetare, En Amazon FSx för Luster filsystem och ett fristående Amazon Elastic Compute Cloud (Amazon EC2) instans. FSx for Luster låter Dask-arbetare komma åt och bearbeta Amazon S3-data från ett högpresterande filsystem genom att länka dina filsystem till S3-buckets. Det ger fördröjningar på under millisekunder, upp till hundratals GB/s av genomströmning och miljontals IOPS. En nyckelfunktion hos Luster är att endast filsystemets metadata synkroniseras. Luster hanterar balansen mellan filer som ska laddas in och hållas varma, baserat på efterfrågan.
Arbetarkluster skalas baserat på CPU-användning, tillhandahåller ytterligare arbetare under längre perioder av efterfrågan och skalas ner när resurser blir lediga.
Varje natt klockan 0:00 UTC uppmanar ett datasynkroniseringsjobb Luster-filsystemet att synkronisera om med den bifogade S3-skopan och hämtar en uppdaterad metadatakatalog för hinken. Därefter skickar den fristående EC2-instansen dessa uppdateringar till OpenSearch Service respektive regionens index. OpenSearch Service tillhandahåller den nödvändiga informationen till kunden om vilken pool av arbetare som ska anlitas för en viss datauppsättning.
nätverks
Nätverk utgör kärnan i denna lösning, med hjälp av Amazons interna stamnätverk. Genom att använda AWS Transit Gateway, vi kan ansluta var och en av regionerna till varandra utan att behöva gå igenom det offentliga internet. Var och en av arbetarna kan ansluta dynamiskt till Dask-schemaläggaren, vilket gör att datavetare kan köra interregionala frågor genom Dask.
Förutsättningar
AWS CDK-paketet använder programmeringsspråket TypeScript. Följ stegen i Komma igång för AWS CDK för att ställa in din lokala miljö och starta upp ditt utvecklingskonto (du måste bootstrapa alla regioner som anges i GitHub repo).
För en framgångsrik implementering behöver du Docker installerad och körs på din lokala dator.
Distribuera AWS CDK-paketet
Att distribuera ett AWS CDK-paket är enkelt. När du har installerat förutsättningarna och startat upp ditt konto kan du fortsätta med att ladda ner kodbasen.
- ladda ner GitHub repository:
- Installera nodmoduler:
- Distribuera AWS CDK:
Stacken kan ta över en och en halv timme att distribuera.
Kodgenomgång
I det här avsnittet inspekterar vi några av nyckelfunktionerna i kodbasen. Om du vill inspektera hela kodbasen, se GitHub repository.
Konfigurera och anpassa din stack
I filen bin/variabler.ts, hittar du två variabla deklarationer: en för klienten och en för arbetare. Klientdeklarationen är en ordbok med hänvisning till en region och ett CIDR-intervall. Anpassning av dessa variabler kommer att ändra både region- och CIDR-intervallet för var klientresurserna ska distribueras.
Arbetarvariabeln kopierar samma funktionalitet; det är dock en lista med ordböcker för att kunna lägga till eller subtrahera datamängder som användaren vill inkludera. Dessutom innehåller varje ordbok de tillagda fälten för dataset och lustreFileSystemPath. Dataset används för att specificera den anslutande S3 URI som Luster ska ansluta till. De lustreFileSystemPath variabeln används som en mappning för hur användaren vill att datamängden ska mappas lokalt på arbetsfilsystemet. Se följande kod:
Publicera schemaläggarens IP dynamiskt
En utmaning som var inneboende i det här projektets tvärregionala karaktär var att upprätthålla en dynamisk koppling mellan Dask-arbetarna och schemaläggaren. Hur skulle vi kunna publicera en IP-adress, som kan ändras, över AWS-regioner? Vi kunde åstadkomma detta genom att använda AWS molnkarta och associera-vpc-med-värd-zon. Tjänsten sammandrag gör att AWS kan hantera detta DNS-namnområde privat. Se följande kod:
Jupyter notebook UI
Jupyter-anteckningsboken som finns på SageMaker ger forskare en färdig miljö för distribution för att enkelt kunna ansluta och experimentera med de laddade datamängderna. Vi använde en skript för livscykelkonfiguration för att tillhandahålla den bärbara datorn med en förkonfigurerad utvecklarmiljö och exempelkodbas. Se följande kod:
Dask arbetarnoder
När det kommer till Dask-arbetarna tillhandahålls större anpassningsbarhet, mer specifikt på instanstyp, trådar per behållare och skalningslarm. Som standard monterar arbetarna på instanstypen m5d.4xlarge till Luster-filsystemet vid lansering och delar upp dess arbetare och trådar dynamiskt till portar. Allt detta är valfritt anpassningsbart. Se följande kod:
prestanda
För att bedöma prestanda använder vi en provberäkning och plottning av lufttemperaturen vid 2 meter baserat på skillnaden mellan CMIP6-förutsägelse för en månad och ERA5 medellufttemperatur under 10 år. Vi sätter ett riktmärke för två arbetare i varje region och bedömer skillnaden i tidsförkortning när ytterligare arbetare tillkommit. I teorin, när lösningen skalas, borde det finnas en produktiv materialskillnad när det gäller att minska den totala tiden.
Följande tabell sammanfattar våra datauppsättningsdetaljer.
| dataset | variabler | Diskstorlek | Xarray Dataset Storlek | Region |
| ERA5 | 2011–2020 (120 netcdf-filer) | 53.5GB | 364.1 GB | us-öst-1 |
| CMIP6 | 1.13GB | 0.11 GB | us-west-2 |
Följande tabell visar de insamlade resultaten och visar tiden (i sekunder) för varje beräkning och förutsägelse i tre steg vid beräkning av CMIP6-förutsägelse, ERA5 och skillnad.
| . | . | Antal arbetare | |||
| Compute | Region | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
us-west-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
us-öst-1 | 1512 | 711 | 427 | 202 |
Skillnad (propogated pool) |
us-west-2 och us-east-1 | 1527 | 906 | 469 | 251 |
Följande graf visualiserar prestandan och skalan.
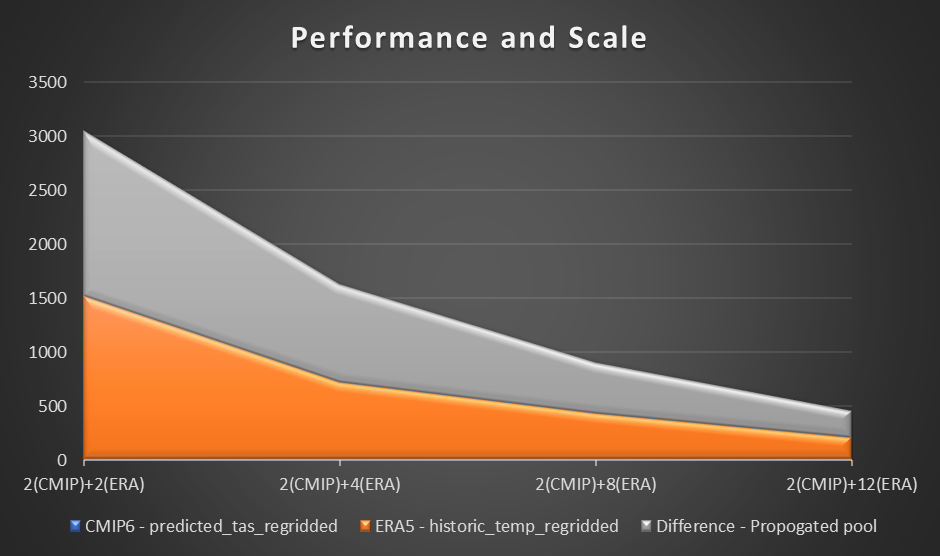
Från vårt experiment observerade vi en linjär förbättring av beräkningen för ERA5-datauppsättningen när antalet arbetare ökade. När antalet arbetare ökade halverades beräkningstiderna ibland.
Jupyter anteckningsbok
Som en del av lanseringen av lösningen distribuerar vi en förkonfigurerad Jupyter-dator för att hjälpa till att testa den tvärregionala Dask-lösningen. Anteckningsboken visar den borttagna oro över att behöva känna till den regionala platsen för datauppsättningar, istället för att söka efter en katalog genom en serie Jupyter-anteckningsböcker som körs i bakgrunden.
För att komma igång, följ instruktionerna i det här avsnittet.
Koden för anteckningsböckerna finns i lib/SagemakerCode med den primära anteckningsboken ux_notebook.ipynb. Den här anteckningsboken använder andra anteckningsböcker och utlöser hjälpskript. ux_notebook är utformad för att vara ingångspunkten för forskare, utan att behöva gå någon annanstans.
För att komma igång, öppna den här anteckningsboken i SageMaker efter att du har distribuerat AWS CDK. AWS CDK skapar en anteckningsboksinstans med alla filer i arkivet inlästa och säkerhetskopierade till en AWS CodeCommit förvaret.
För att köra programmet, öppna och kör den första cellen i ux_notebook. Denna cell kör get_variables notebook i bakgrunden, som ber dig att ange de data du vill välja. Vi tar med ett exempel; observera dock att frågor endast visas efter att föregående alternativ har valts. Detta är avsiktligt för att begränsa rullgardinsvalen och är valfritt konfigurerbart genom att redigera get_variables anteckningsbok.
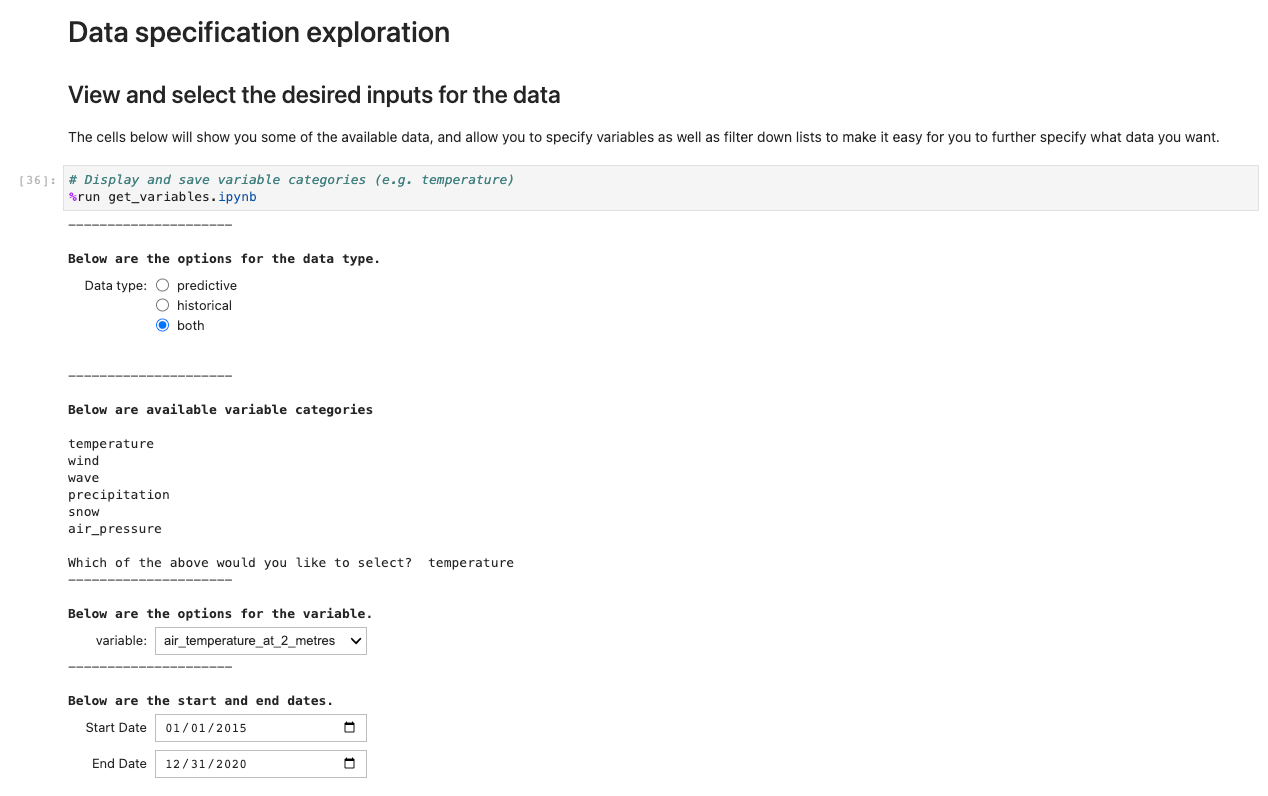
Den föregående koden lagrar variabler globalt så att andra bärbara datorer kan hämta och ladda ditt urval av val. För demonstration bör nästa cell mata ut sparavariablerna från tidigare.
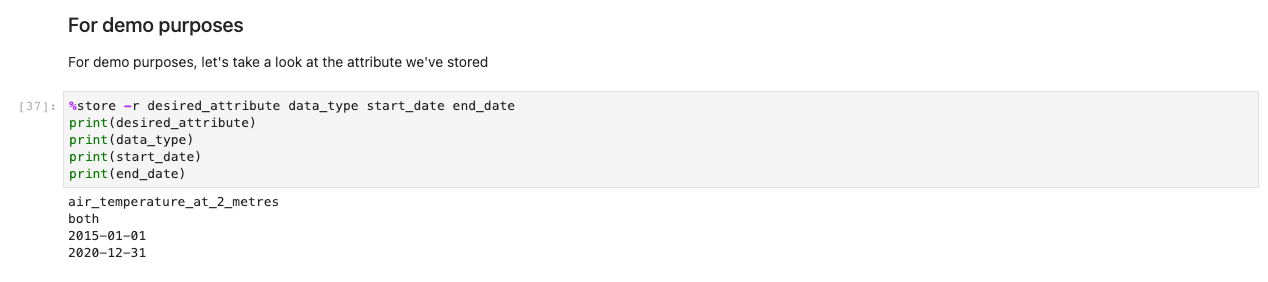
Därefter visas en uppmaning om ytterligare dataspecifikationer. Den här cellen förfinar informationen du är ute efter genom att presentera tabellernas ID i läsbart format. Användare väljer som om det vore ett formulär, men titlarna mappas till tabeller i bakgrunden som hjälper systemet att hämta lämpliga datauppsättningar.
När du har lagrat alla dina val och urvalsceller laddar du in data i regionerna genom att köra cellen i Skaffa data in sektion. Kommandot %%capture kommer att undertrycka onödiga utdata från get_data anteckningsbok. Observera att du kan ta bort detta för att inspektera utdata från de andra bärbara datorerna. Data hämtas sedan i backend.
Medan andra bärbara datorer körs i bakgrunden, är den enda kontaktpunkten för användaren ux_notebook. Detta är för att abstrahera den tråkiga processen att importera data till ett format som alla användare kan följa med lätthet.
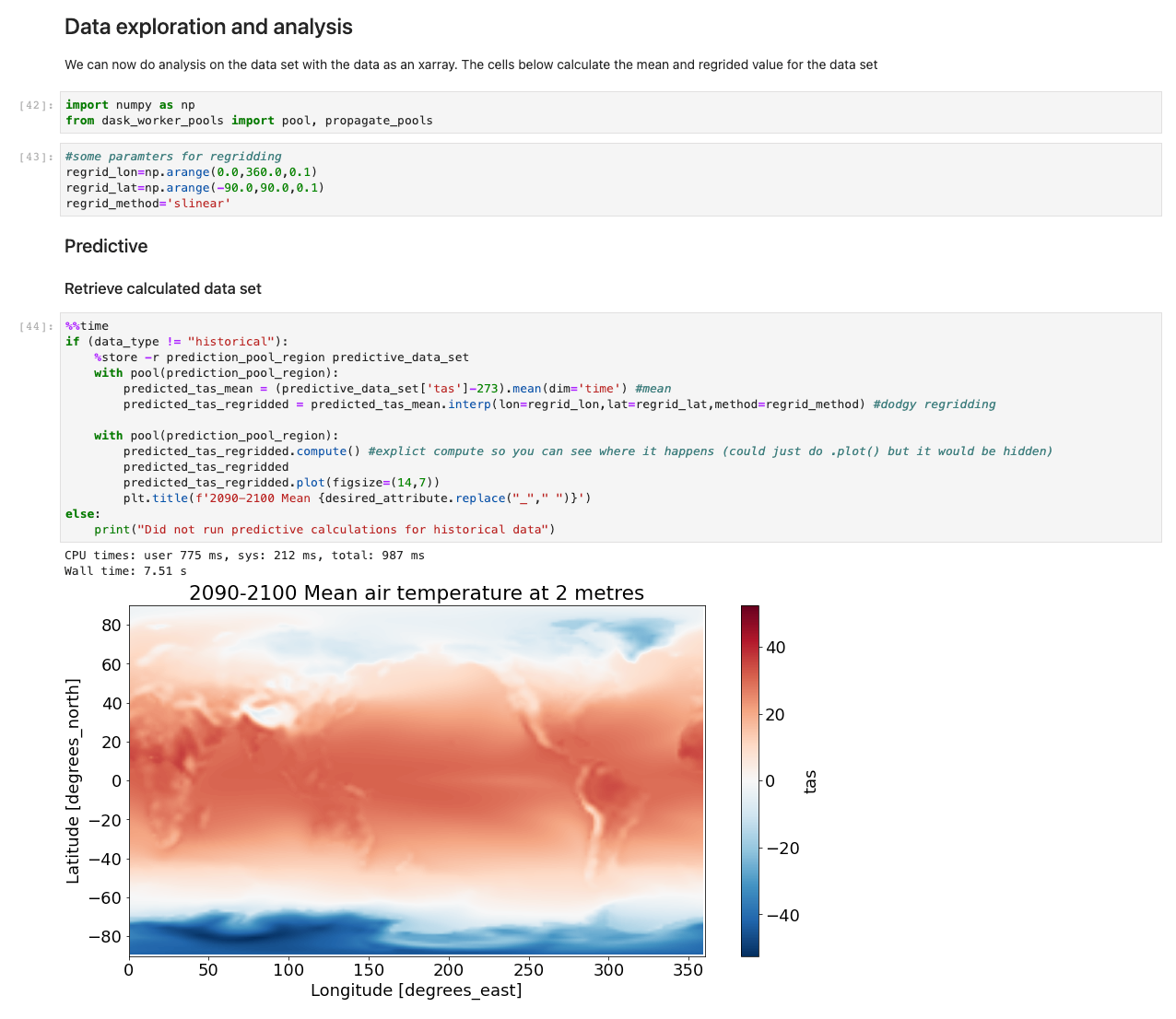
Med datan nu laddad kan vi börja interagera med den. Följande celler är exempel på beräkningar du kan köra på väderdata. Använder sig av röntgenbilder, vi importerar, beräknar och plottar sedan dessa datamängder.
Vårt exempel illustrerar en plot av prediktiv data som hämtar data, kör beräkningen och plottar resultaten på under 7.5 sekunder – storleksordningar snabbare än ett typiskt tillvägagångssätt.
Under huven
Anteckningsböckerna get_catalog_input och get_variables använda biblioteket ipywidgets för att visa widgetar som rullgardinsmenyer och val av flera rutor. Dessa alternativ sparas globalt med kommandot %%store så att de kan nås från ux_notebook. Ett av alternativen frågar dig om du vill ha historisk data, prediktiv data eller båda. Denna variabel skickas till get_data anteckningsbok för att avgöra vilka efterföljande anteckningsböcker som ska köras.
Smakämnen get_data notebook hämtar först den delade OpenSearch Service-domänen som sparats till AWS Systems Manager Parameter Store. Den här domänen tillåter vår anteckningsbok att köra en fråga om att samla in information som kommer att indikera var de valda datamängderna lagras regionalt. Med dessa datauppsättningar lokaliserade regionalt kommer anteckningsboken att göra ett anslutningsförsök till Dask-schemaläggaren och skicka informationen som samlats in från OpenSearch Service. Dask-schemaläggaren kommer i sin tur att kunna kalla på arbetare i rätt regioner.
Hur man anpassar och fortsätter utvecklingen
Dessa anteckningsböcker är tänkta att vara ett exempel på hur du kan skapa ett sätt för användare att gränssnitta och interagera med data. Anteckningsboken i det här inlägget fungerar som en illustration för vad som är möjligt, och vi inbjuder dig att fortsätta bygga vidare på lösningen för att ytterligare förbättra användarens engagemang. Kärnan i denna lösning är backend-tekniken, men utan någon mekanism för att interagera med den backend kommer användarna inte att inse lösningens fulla potential.
Ta bort resurserna för att undvika framtida avgifter. Låt oss förstöra vår distribuerade lösning med följande kommando:
Slutsats
Det här inlägget visar utvidgningen av Dask inter-Regionalt på AWS och en möjlig integration med offentliga datauppsättningar på AWS. Lösningen byggdes som ett generiskt mönster och ytterligare datauppsättningar kan laddas in för att påskynda höga I/O-analyser på komplexa data.
Data förändrar varje område och varje verksamhet. Men med data som växer snabbare än de flesta företag kan hålla reda på, är det en utmaning att samla in data och få ut värdet av den datan. En modern datastrategi kan hjälpa dig att skapa bättre affärsresultat med data. AWS tillhandahåller den mest kompletta uppsättningen tjänster för hela dataresan för att hjälpa dig att låsa upp värde från din data och omvandla den till insikt.
För att lära dig mer om de olika sätten att använda din data i molnet, besök AWS Big Data-blogg. Vi inbjuder dig vidare att kommentera med dina tankar om detta inlägg, och om detta är en lösning du planerar att testa.
Om författarna
 Patrick O'Connor är en WWSO Prototyping Engineer baserad i London. Han är en kreativ problemlösare, anpassningsbar inom ett brett spektrum av teknologier, såsom IoT, serverlös teknik, 3D spatial tech och ML/AI, tillsammans med en obeveklig nyfikenhet på hur tekniken kan fortsätta att utveckla vardagliga tillvägagångssätt.
Patrick O'Connor är en WWSO Prototyping Engineer baserad i London. Han är en kreativ problemlösare, anpassningsbar inom ett brett spektrum av teknologier, såsom IoT, serverlös teknik, 3D spatial tech och ML/AI, tillsammans med en obeveklig nyfikenhet på hur tekniken kan fortsätta att utveckla vardagliga tillvägagångssätt.
 Chakra Nagarajan är en Principal Machine Learning Prototyping SA med 21 års erfarenhet av maskininlärning, big data och högpresterande datoranvändning. I sin nuvarande roll hjälper han kunder att lösa komplexa affärsproblem i verkligheten genom att bygga prototyper med end-to-end AI/ML-lösningar i moln och edge-enheter. Hans ML specialisering inkluderar datorseende, naturlig språkbehandling, tidsserieprognoser och personalisering.
Chakra Nagarajan är en Principal Machine Learning Prototyping SA med 21 års erfarenhet av maskininlärning, big data och högpresterande datoranvändning. I sin nuvarande roll hjälper han kunder att lösa komplexa affärsproblem i verkligheten genom att bygga prototyper med end-to-end AI/ML-lösningar i moln och edge-enheter. Hans ML specialisering inkluderar datorseende, naturlig språkbehandling, tidsserieprognoser och personalisering.
 Val Cohen är en senior WWSO Prototyping Engineer baserad i London. Val är en problemlösare till sin natur och tycker om att skriva kod för att automatisera processer, bygga kundbesatta verktyg och skapa infrastruktur för olika applikationer för sin globala kundbas. Val har erfarenhet av en mängd olika tekniker, såsom front-end webbutveckling, backend-arbete och AI/ML.
Val Cohen är en senior WWSO Prototyping Engineer baserad i London. Val är en problemlösare till sin natur och tycker om att skriva kod för att automatisera processer, bygga kundbesatta verktyg och skapa infrastruktur för olika applikationer för sin globala kundbas. Val har erfarenhet av en mängd olika tekniker, såsom front-end webbutveckling, backend-arbete och AI/ML.
 Niall Robinson är chef för produktterminer på UK Met Office. Han och hans team utforskar nya sätt som Met Office kan ge värde genom produktinnovation och strategiska partnerskap. Han har haft en varierad karriär, lett ett multidisciplinärt informatik-FoU-team, akademisk forskning inom datavetenskap och fältforskare tillsammans med expertis inom klimatmodeller.
Niall Robinson är chef för produktterminer på UK Met Office. Han och hans team utforskar nya sätt som Met Office kan ge värde genom produktinnovation och strategiska partnerskap. Han har haft en varierad karriär, lett ett multidisciplinärt informatik-FoU-team, akademisk forskning inom datavetenskap och fältforskare tillsammans med expertis inom klimatmodeller.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- : har
- :är
- :var
- $UPP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- förmåga
- Able
- Om oss
- ovan
- SAMMANDRAG
- sammandrag
- akademiska
- akademisk forskning
- accelerera
- accelererande
- tillgång
- Accessed
- rymma
- åstadkomma
- Konto
- uppnår
- tvärs
- anpassar sig
- lagt till
- tillsats
- Annat
- Dessutom
- adress
- adresse
- Lägger
- administratörer
- antagen
- Antagande
- Efter
- AI / ML
- LUFT
- Alla
- tillåta
- tillåter
- längs
- också
- amason
- Amazon EC2
- an
- analys
- och
- vilken som helst
- visas
- Ansökan
- tillämpningar
- tillvägagångssätt
- tillvägagångssätt
- lämpligt
- arkitektur
- ÄR
- AS
- At
- Atmosfär
- atmosfärs
- automatisera
- undvika
- AWS
- AWS kund
- Backbone
- dragen tillbaka
- backend
- bakgrund
- Balansera
- bas
- baserat
- BE
- blir
- varit
- innan
- Där vi får lov att vara utan att konstant prestera,
- nedan
- riktmärke
- Bättre
- mellan
- Stor
- Stora data
- Bootstrap
- båda
- Föra
- Brutet
- SLUTRESULTAT
- Byggnad
- byggt
- inbyggd
- företag
- men
- by
- beräkna
- Ring
- kallas
- anropande
- Samtal
- KAN
- kapacitet
- kapabel
- Karriär
- katalog
- CD
- Celler
- utmanar
- utmanande
- byta
- byte
- laddning
- avgifter
- val
- Cirkulation
- klient
- Klimat
- närmare
- cloud
- kluster
- CO
- koda
- kodbas
- samverkan
- Samla
- komma
- kommer
- kommande
- kommentar
- samfundet
- Företag
- fullborda
- komplex
- komponenter
- Består
- beräkning
- Compute
- dator
- Datorsyn
- databehandling
- konfiguration
- Kontakta
- anslutna
- Anslutning
- anslutning
- konsumenter
- konsumtion
- Behållare
- innehåller
- fortsätta
- fortsätter
- kopior
- Kärna
- korrekt
- Pris
- kostnadseffektiv
- kunde
- kopplad
- CPU
- skapa
- skapar
- Kreativ
- kritisk
- gröda
- Cross
- nyfikenhet
- Aktuella
- beställnings
- kund
- Kunder
- anpassningsbar
- skräddarsy
- dagligen
- instrumentbräda
- datum
- datavetenskap
- datstrategi
- datauppsättningar
- dag
- årtionde
- beslut
- Standard
- Efterfrågan
- demonstrerar
- distribuera
- utplacerade
- utplacering
- vecklas ut
- utformade
- förstöra
- detaljerad
- detaljer
- Bestämma
- utveckla
- Utvecklare
- Utveckling
- enheter
- Skillnaden
- inaktiverad
- Upptäckten
- Visa
- distribueras
- distribuerad databehandling
- dns
- Hamnarbetare
- domän
- ner
- dynamisk
- dynamiskt
- varje
- lätta
- lätt
- kant
- redigering
- effektiv
- annorstädes
- möjliggöra
- början till slut
- energi
- ingrepp
- ingenjör
- inträde
- Miljö
- Motsvarande
- Era
- beräknad
- Eter (ETH)
- Varje
- varje dag
- dagliga
- utvecklas
- exempel
- exempel
- erfarenhet
- experimentera
- expertis
- utforska
- export
- utsatta
- förlängning
- snabbare
- Leverans
- Funktioner
- fält
- Fält
- Fil
- Filer
- hitta
- Förnamn
- fokuserar
- följer
- efter
- livsmedelsproduktion
- För
- formen
- format
- former
- hittade
- Grundad
- Ramverk
- ramar
- Fri
- från
- förverkligande
- full
- funktionalitet
- ytterligare
- framtida
- Futures
- Allmänt
- generering
- skaffa sig
- få
- gå
- Välgörenhet
- globalt nätverk
- Globalt
- globen
- kommer
- diagram
- större
- Rutnät
- Väx
- Odling
- hade
- Hälften
- halveras
- Har
- he
- huvud
- hjälpa
- hjälper
- här
- Hög
- högpresterande
- höjdpunkter
- hans
- historisk
- värd
- värd
- timme
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- läsbar
- Hundratals
- Idle
- ids
- if
- illustrerar
- importera
- importera
- förbättra
- förbättring
- in
- innefattar
- innefattar
- ökat
- index
- indikerar
- underrätta
- informationen
- Infrastruktur
- inneboende
- Innovation
- ingång
- otrygghet
- insikt
- inspirerat
- installera
- exempel
- istället
- instruktioner
- integrering
- Avsiktlig
- interagera
- interagera
- Gränssnitt
- inre
- Internet
- in
- bjuda in
- iot
- IP
- IP-adress
- problem
- IT
- DESS
- Jobb
- resa
- jpg
- Jupyter Notebook
- Ha kvar
- Nyckel
- Vet
- språk
- Large
- Efternamn
- Latens
- lansera
- ledande
- LÄRA SIG
- inlärning
- Bibliotek
- livscykel
- tycka om
- länkning
- Lista
- läsa in
- lokal
- lokalt
- belägen
- läge
- london
- Maskinen
- maskininlärning
- större
- göra
- hantera
- chef
- förvaltar
- karta
- kartläggning
- Massa
- Massadoption
- Materialet
- Maj..
- betyda
- mekanism
- metadata
- miljoner
- ML
- modell
- Modern Konst
- Moduler
- Månad
- månad
- månadsdata
- mer
- mest
- MONTERA
- tvärvetenskaplig
- namn
- nationell
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Natur
- nödvändigt för
- Behöver
- behöver
- nät
- Nya
- Nästa
- natt
- nod
- noder
- anteckningsbok
- bärbara datorer
- nu
- antal
- nummer
- of
- erbjudanden
- Office
- on
- ONE
- endast
- öppet
- öppna uppgifter
- öppen källkod
- öppen källkod
- operativa
- Alternativet
- Tillbehör
- or
- orkestrering
- organisationer
- Övriga
- vår
- ut
- utfall
- produktion
- över
- övergripande
- paket
- parameter
- del
- särskilt
- särskilt
- partnerskap
- Godkänd
- Förbi
- Mönster
- prestanda
- perioder
- personalisering
- petabyte
- fas
- Planen
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poolen
- portar
- möjlig
- Inlägg
- potentiell
- kraft
- den mäktigaste
- praktiken
- förutsägelse
- Förutsägelser
- förutsättningar
- föregående
- primär
- Principal
- privat
- Problem
- problem
- process
- processer
- bearbetning
- producerad
- Produkt
- Produkt innovation
- produktiv
- Program
- Programmering
- projektet
- prototyper
- prototyping
- ge
- förutsatt
- ger
- tillhandahållande
- allmän
- publicera
- publicerade
- Drar
- sökfrågor
- frågor
- R&D
- område
- snarare
- färdiga
- verkliga världen
- inser
- minska
- reducerande
- reduktion
- region
- regionala
- regioner
- obeveklig
- resterna
- ta bort
- avlägsnas
- Repository
- representerar
- forskning
- Resurser
- att
- Resultat
- Roll
- Körning
- rinnande
- SA
- säker
- sagemaker
- Samma
- Save
- skalbar
- Skala
- skalor
- skalning
- Vetenskap
- Forskare
- vetenskapsmän
- skript
- sekunder
- §
- se
- sett
- segment
- vald
- Val
- senior
- Serier
- Server
- serverar
- service
- Tjänster
- in
- Dela
- delas
- skall
- show
- visa upp
- Visar
- Enkelt
- helt enkelt
- 6:e
- långsam
- So
- lösning
- Lösningar
- LÖSA
- några
- Källa
- rumsliga
- specifikt
- specifikationer
- specificerade
- sponsorskap
- stapel
- stadier
- fristående
- starta
- igång
- bo
- Steg
- förvaring
- lagra
- lagras
- lagrar
- okomplicerad
- Strategisk
- strategiska partnerskap
- Strategi
- senare
- Senare
- framgångsrik
- sådana
- yta
- uppstår
- Hållbarhet
- hållbart
- system
- System
- bord
- Ta
- grupp
- tech
- Tekniken
- Teknologi
- testa
- än
- den där
- Smakämnen
- den information
- källan
- Storbritannien
- världen
- deras
- sedan
- Där.
- vari
- Dessa
- de
- detta
- de
- tre
- Frodas
- Genom
- genomströmning
- tid
- Tidsföljder
- gånger
- titlar
- till
- i dag
- tillsammans
- verktyg
- spår
- Spårning
- överföring
- omvandla
- transitering
- trigg
- SVÄNG
- två
- Typ
- skrivmaskin
- typisk
- Uk
- under
- låsa
- ohållbar
- TIDSENLIG
- Uppdateringar
- på
- URI
- Användning
- användning
- Begagnade
- Användare
- användare
- med hjälp av
- UTC
- Använda
- VAL
- värde
- mängd
- olika
- via
- syn
- Besök
- volym
- vill
- vill
- varm
- var
- Sätt..
- sätt
- we
- Väder
- webb
- Webbutveckling
- były
- om
- som
- bred
- Brett utbud
- kommer
- önskemål
- med
- utan
- Arbete
- arbetstagaren
- arbetare
- världen
- oro
- skulle
- skrivning
- år
- ännu
- Avkastning
- dig
- Din
- zephyrnet