Värdet på data är tidskänsligt. Realtidsbearbetning gör datadrivna beslut korrekta och genomförbara på sekunder eller minuter istället för timmar eller dagar. Change data capture (CDC) hänvisar till processen att identifiera och fånga ändringar som gjorts i data i en databas och sedan leverera dessa ändringar i realtid till ett nedströms system. Att fånga varje förändring från transaktioner i en källdatabas och flytta dem till målet i realtid håller systemen synkroniserade och hjälper till med användningsfall för realtidsanalys och databasmigreringar utan driftstopp. Följande är några fördelar med CDC:
- Det eliminerar behovet av bulkladdningsuppdatering och obekväma batchfönster genom att möjliggöra inkrementell laddning eller realtidsströmning av dataändringar till ditt mållager.
- Det säkerställer att data i flera system förblir synkroniserade. Detta är särskilt viktigt om du fattar tidskänsliga beslut i en datamiljö med hög hastighet.
Kafka Connect är en öppen källkodskomponent i Apache Kafka som fungerar som en centraliserad datahubb för enkel dataintegration mellan databaser, nyckel-värdelager, sökindex och filsystem. De AWS Glue Schema Registry låter dig upptäcka, styra och utveckla dataströmsscheman centralt. Kafka Connect och Schema Registry integreras för att fånga schemainformation från anslutningar. Kafka Connect tillhandahåller en mekanism för att konvertera data från de interna datatyperna som används av Kafka Connect till datatyper representerade som Avro, Protobuf eller JSON Schema. AvroConverter, ProtobufConverter och JsonSchemaConverter registrerar automatiskt scheman som genereras av Kafka-anslutningar (källa) som producerar data till Kafka. Anslutningar (sink) som förbrukar data från Kafka får schemainformation utöver data för varje meddelande. Detta gör det möjligt för sink-anslutare att känna till strukturen på datan för att tillhandahålla funktioner som att underhålla ett databastabellschema i en datakatalog.
Inlägget visar hur man bygger en end-to-end CDC med hjälp av Amazon MSK Connect, en AWS-hanterad tjänst för att distribuera och köra Kafka Connect-applikationer och AWS Glue Schema Registry, som låter dig upptäcka, kontrollera och utveckla dataströmsscheman centralt.
Lösningsöversikt
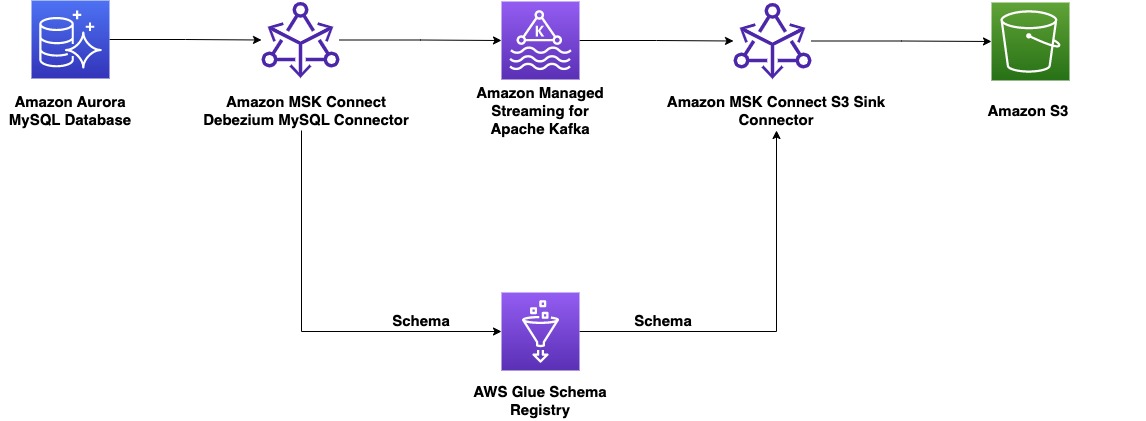
På producentsidan väljer vi för detta exempel en MySQL-kompatibel Amazon-Aurora databas som datakälla, och vi har en Debezium MySQL-kontakt för att utföra CDC. Debezium-anslutningen övervakar kontinuerligt databaserna och skickar ändringar på radnivå till ett Kafka-ämne. Anslutningen hämtar schemat från databasen för att serialisera posterna till en binär form. Om schemat inte redan finns i registret kommer schemat att registreras. Om schemat finns men serializern använder en ny version, kontrollerar schemaregistret kompatibilitetsläge av schemat innan du uppdaterar schemat. I denna lösning använder vi bakåtkompatibilitetsläge. Schemaregistret returnerar ett fel om en ny version av schemat inte är bakåtkompatibel, och vi kan konfigurera Kafka Connect att skicka inkompatibla meddelanden till dödbokstavskön.
På konsumentsidan använder vi en Amazon enkel lagringstjänst (Amazon S3) handfatskontakt för att deserialisera skivan och lagra ändringar till Amazon S3. Vi bygger och distribuerar Debezium-kontakten och Amazon S3-vasken med MSK Connect.
Exempel schema
För det här inlägget använder vi följande schema som den första versionen av tabellen:
Förutsättningar
Innan vi konfigurerar MSK-producent- och konsumentanslutningarna måste vi först konfigurera en datakälla, MSK-kluster och ett nytt schemaregister. Vi tillhandahåller en AWS molnformation mall för att generera de stödresurser som behövs för lösningen:
- En MySQL-kompatibel Aurora-databas som datakälla. För att utföra CDC aktiverar vi binär inloggning i DB-klusterparametergrupp.
- Ett MSK-kluster. För att förenkla nätverksanslutningen använder vi samma VPC för Aurora-databasen och MSK-klustret.
- Två schemaregister för att hantera scheman för meddelandenyckel och meddelandevärde.
- En S3 hink som datasänka.
- MSK Connect-plugin-program och arbetarkonfiguration som behövs för denna demo.
- en Amazon Elastic Compute Cloud (Amazon EC2)-instans för att köra databaskommandon.
För att ställa in resurser i ditt AWS-konto, slutför följande steg i en AWS-region som stöder Amazon MSK, MSK Connect och AWS Glue Schema Registry:
- Välja Starta stack:
- Välja Nästa.
- För Stapla namn, ange lämpligt namn.
- För Databaslösenord, ange lösenordet du vill ha för databasanvändaren.
- Behåll andra värden som standard.
- Välja Nästa.
- Välj på nästa sida Nästa.
- Granska detaljerna på den sista sidan och välj Jag erkänner att AWS CloudFormation kan skapa IAM-resurser.
- Välja Skapa stack.
Anpassad plugin för käll- och destinationsanslutningen
En anpassad plugin är en uppsättning JAR-filer som innehåller implementeringen av en eller flera kontakter, transformeringar eller omvandlare. Amazon MSK kommer att installera plugin-programmet på arbetarna i MSK Connect-klustret där kontakten körs. Som en del av denna demo använder vi öppen källkod för källkontakten Debezium MySQL-kontakt JAR, och för destinationsanslutningen använder vi Confluent-gemenskapen licensierad Amazon S3 diskbänkskontakt JAR. Båda plugins läggs även till med bibliotek för Avro Serializers och Deserializers av AWS Glue Schema Registry. Dessa anpassade plugins är redan skapade som en del av CloudFormation-mallen som distribuerades i föregående steg.
Använd AWS Glue Schema Registry med Debezium-kontakten på MSK Connect som MSK-producent
Vi distribuerar först källkontakten med Debezium MySQL-plugin för att strömma data från en Amazon Aurora MySQL-kompatibel utgåva databas till Amazon MSK. Slutför följande steg:
- På Amazon MSK-konsolen, i navigeringsfönstret, under MSK Connectväljer kontakter.
- Välja Skapa anslutning.
- Välja Använd befintligt anpassat plugin och välj sedan den anpassade plugin med namnet som börjar
msk-blog-debezium-source-plugin. - Välja Nästa.
- Ange ett lämpligt namn som
debezium-mysql-connectoroch en valfri beskrivning. - För Apache Kafka-klusterväljer MSK-kluster och välj klustret som skapats av CloudFormation-mallen.
- In Anslutningskonfiguration, ta bort standardvärdena och använd följande konfigurationsnyckel-värdepar och med lämpliga värden:
- namn – Namnet som används för kontakten.
- database.hostsname – CloudFormation-utgången för Databasslutpunkt.
- databas.användare och databas.lösenord – Parametrarna som skickas i CloudFormation-mallen.
- database.history.kafka.bootstrap.servrar – CloudFormation-utgången för Kafka Bootstrap.
- key.converter.region och value.converter.region – Din region.
Vissa av dessa inställningar är generiska och bör specificeras för alla anslutningar. Till exempel:
- connector.class är Java-klassen för kontakten
- tasks.max är det maximala antalet uppgifter som ska skapas för den här anslutningen
Vissa inställningar (database.*, transforms.*) är specifika för Debezium MySQL-anslutningen. Hänvisa till Debezium MySQL Source Connector Configuration Properties för mer information.
Vissa inställningar (key.converter.* och value.converter.*) är specifika för Schema Registry. Vi använder AWSKafkaAvroConverter från AWS Glue Schema Registry Library som formatomvandlare. Att konfigurera AWSKafkaAvroConverter, använder vi värdet för strängkonstantens egenskaper i AWSSchemaRegistryConstants klass:
key.converterochvalue.converterkontrollera formatet för data som kommer att skrivas till Kafka för källanslutningar eller läsas från Kafka för sänkanslutningar. Vi använderAWSKafkaAvroConverterför Avro-format.key.converter.registry.nameochvalue.converter.registry.namedefiniera vilket schemaregister som ska användas.key.converter.compatibilityochvalue.converter.compatibilitydefiniera kompatibilitetsmodellen.
Hänvisa till Använder Kafka Connect med AWS Glue Schema Registry för mer information.
- Därefter konfigurerar vi Anslutningskapacitet. Vi kan välja Förutsatt och lämna andra egenskaper som standard
- För Arbetarkonfiguration, välj den anpassade arbetarkonfigurationen med namnet som börjar
msk-gsr-blogskapad som en del av CloudFormation-mallen. - För Åtkomstbehörigheter, Använd AWS identitets- och åtkomsthantering (IAM)-roll genererad av CloudFormation-mallen
MSKConnectRole. - Välja Nästa.
- För Säkerhet, välj standardinställningarna.
- Välja Nästa.
- För Leverans av stockar, Välj Leverera till Amazon CloudWatch-loggar och bläddra efter logggruppen som skapats av CloudFormation-mallen (
msk-connector-logs). - Välja Nästa.
- Granska inställningarna och välj Skapa anslutning.
Efter några minuter ändras kontakten till körstatus.
Använd AWS Glue Schema Registry med Confluent S3 diskbänkskontakten som körs på MSK Connect som MSK-konsument
Vi distribuerar sink-kontakten med Confluent S3 sink-plugin för att strömma data från Amazon MSK till Amazon S3. Slutför följande steg:
-
- På Amazon MSK-konsolen, i navigeringsfönstret, under MSK Connectväljer kontakter.
- Välja Skapa anslutning.
- Välja Använd befintligt anpassat plugin och välj den anpassade plugin med namnet som börjar
msk-blog-S3sink-plugin. - Välja Nästa.
- Ange ett lämpligt namn som
s3-sink-connectoroch en valfri beskrivning. - För Apache Kafka-klusterväljer MSK-kluster och välj klustret som skapats av CloudFormation-mallen.
- In Anslutningskonfiguration, ta bort de angivna standardvärdena och använd följande konfigurationsnyckel-värdepar med lämpliga värden:
-
- namn – Samma namn som används för kontakten.
- s3.bucket.name – CloudFormation-utgången för Skopnamn.
- s3.region, key.converter.region och value.converter.region – Din region.
-
- Därefter konfigurerar vi Anslutningskapacitet. Vi kan välja Förutsatt och lämna andra egenskaper som standard
- För Arbetarkonfiguration, välj den anpassade arbetarkonfigurationen med namnet som börjar
msk-gsr-blogskapad som en del av CloudFormation-mallen. - För Åtkomstbehörigheter, använd IAM-rollen som genereras av CloudFormation-mallen
MSKConnectRole. - Välja Nästa.
- För Säkerhet, välj standardinställningarna.
- Välja Nästa.
- För Leverans av stockar, Välj Leverera till Amazon CloudWatch-loggar och bläddra efter logggruppen som skapats av CloudFormation-mallen
msk-connector-logs. - Välja Nästa.
- Granska inställningarna och välj Skapa anslutning.
Efter några minuter är kontakten igång.
Testa hela CDC-loggströmmen
Nu när både Debezium- och S3-sänkanslutningarna är igång, slutför följande steg för att testa end-to-end CDC:
- På Amazon EC2-konsolen, navigera till Säkerhetsgrupper sida.
- Välj säkerhetsgrupp
ClientInstanceSecurityGroupOch välj Redigera inkommande regler. - Lägg till en inkommande regel som tillåter SSH-anslutning från ditt lokala nätverk.
- På Instanser sida, välj instansen
ClientInstanceOch välj Kontakta. - På EC2 Instance Connect fliken, välj Kontakta.
- Se till att din nuvarande arbetskatalog är det
/home/ec2-useroch den har filernacreate_table.sql,alter_table.sql,initial_insert.sqlochinsert_data_with_new_column.sql. - Skapa en tabell i din MySQL-databas genom att köra följande kommando (ange databasvärdnamnet från CloudFormations mallutgångar):
- När du uppmanas att ange ett lösenord, ange lösenordet från CloudFormations mallparametrar.
- Infoga några exempeldata i tabellen med följande kommando:
- När du uppmanas att ange ett lösenord, ange lösenordet från CloudFormations mallparametrar.
- Välj på AWS Lim-konsolen Schema register i navigeringsfönstret och välj sedan scheman.
- Navigera till
db1.sampledatabase.moviesversion 1 för att kontrollera det nya schemat som skapats för filmtabellen:
En separat S3-mapp skapas för varje partition av Kafka-ämnet, och data för ämnet skrivs i den mappen.
- På Amazon S3-konsolen, leta efter data skrivna i parkettformat i mappen för ditt Kafka-ämne.
Schema utveckling
Efter att det initiala schemat har definierats kan applikationer behöva utveckla det över tid. När detta händer är det avgörande för nedströmskonsumenterna att sömlöst kunna hantera data kodad med både det gamla och det nya schemat. Kompatibilitetslägen låter dig styra hur scheman kan eller inte kan utvecklas över tiden. Dessa lägen utgör kontraktet mellan applikationer som producerar och konsumerar data. För detaljerad information om olika kompatibilitetslägen tillgängliga i AWS Glue Schema Registry, se AWS Glue Schema Registry. I vårt exempel använder vi bakåtkombbarhet för att säkerställa att konsumenter kan läsa både nuvarande och tidigare schemaversioner. Slutför följande steg:
- Lägg till en ny kolumn i tabellen genom att köra följande kommando:
- Infoga ny data i tabellen genom att köra följande kommando:
- Välj på AWS Lim-konsolen Schema register i navigeringsfönstret och välj sedan scheman.
- Navigera till schemat
db1.sampledatabase.moviesversion 2 för att kontrollera den nya versionen av schemat som skapats för filmtabellsfilmerna inklusive landkolumnen som du lade till:
- På Amazon S3-konsolen, leta efter data skrivna i parkettformat i mappen för Kafka-ämnet.
Städa upp
För att förhindra oönskade debiteringar på ditt AWS-konto, ta bort AWS-resurserna som du använde i det här inlägget:
- På Amazon S3-konsolen navigerar du till S3-hinken som skapats av CloudFormation-mallen.
- Välj alla filer och mappar och välj Radera.
- Ange radera permanent enligt anvisningarna och välj Ta bort objekt.
- Ta bort stacken du skapade på AWS CloudFormation-konsolen.
- Vänta tills stackens status ändras till DELETE_COMPLETE.
Slutsats
Det här inlägget demonstrerade hur man använder Amazon MSK, MSK Connect och AWS Glue Schema Registry för att bygga en CDC-loggström och utveckla scheman för dataströmmar när affärsbehoven förändras. Du kan tillämpa detta arkitekturmönster på andra datakällor med olika Kafka-anslutningar. För mer information, se MSK Connect exempel.
Om författaren
 Kalyan Janaki är Senior Big Data & Analytics Specialist med Amazon Web Services. Han hjälper kunder att utforma och bygga mycket skalbara, prestanda och säkra molnbaserade lösningar på AWS.
Kalyan Janaki är Senior Big Data & Analytics Specialist med Amazon Web Services. Han hjälper kunder att utforma och bygga mycket skalbara, prestanda och säkra molnbaserade lösningar på AWS.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :är
- $UPP
- 1
- 10
- 11
- 7
- 8
- a
- Able
- Om oss
- tillgång
- Konto
- exakt
- bekräfta
- lagt till
- Dessutom
- Alla
- tillåta
- tillåter
- redan
- amason
- Amazon EC2
- Amazon Web Services
- analytics
- och
- Apache
- Apache Kafka
- tillämpningar
- Ansök
- lämpligt
- arkitektur
- ÄR
- AS
- aurora
- automatiskt
- tillgänglig
- AWS
- AWS molnformation
- AWS-lim
- BE
- innan
- Fördelarna
- mellan
- Stor
- Stora data
- Bootstrap
- SLUTRESULTAT
- företag
- by
- KAN
- kapacitet
- fånga
- Fångande
- fall
- katalog
- CDC
- centraliserad
- byta
- Förändringar
- avgifter
- ta
- Kontroller
- Välja
- klass
- kluster
- Kolumn
- samfundet
- kompatibilitet
- kompatibel
- fullborda
- komponent
- Compute
- konfiguration
- Konfluenta
- Kontakta
- anslutning
- Konsol
- konstant
- konsumera
- Konsumenten
- konsumenter
- kontinuerligt
- kontrakt
- kontroll
- land
- skapa
- skapas
- kritisk
- Aktuella
- beställnings
- Kunder
- datum
- dataintegration
- data driven
- Databas
- databaser
- Dagar
- beslut
- Standard
- defaults
- definierade
- leverera
- demo
- demonstreras
- demonstrerar
- distribuera
- utplacerade
- beskrivning
- destination
- detaljerad
- detaljer
- olika
- Upptäck
- inte
- Drop
- varje
- eliminerar
- möjliggör
- början till slut
- säkerställa
- säkerställer
- ange
- Miljö
- fel
- speciellt
- Eter (ETH)
- Varje
- utvecklas
- exempel
- befintliga
- finns
- få
- Fält
- Fil
- Filer
- slutlig
- Förnamn
- efter
- För
- formen
- format
- från
- generera
- genereras
- Grupp
- Gruppens
- hantera
- Arbetsmiljö
- händer
- Har
- hjälpa
- hjälper
- höggradigt
- historia
- värd
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- Nav
- IAM
- identifiera
- Identitet
- genomförande
- med Esport
- in
- Inklusive
- index
- informationen
- inledande
- installera
- exempel
- istället
- integrera
- integrering
- inre
- IT
- java
- jpg
- json
- kafka
- Nyckel
- Vet
- Lämna
- bibliotek
- Licensierade
- tycka om
- läsa in
- läser in
- lokal
- Lång
- gjord
- GÖR
- Framställning
- förvaltade
- Master
- max
- maximal
- mekanism
- meddelande
- meddelanden
- kanske
- minuter
- modell
- lägen
- monitorer
- mer
- Filmer
- rörliga
- multipel
- MySQL
- namn
- Navigera
- Navigering
- Behöver
- behövs
- behov
- nät
- Nya
- Nästa
- antal
- of
- Gamla
- on
- ONE
- öppen källkod
- Övriga
- produktion
- sida
- par
- panelen
- parameter
- parametrar
- del
- Godkänd
- Lösenord
- Mönster
- utföra
- permanent
- plocka
- plato
- Platon Data Intelligence
- PlatonData
- plugin
- insticksmoduler
- Inlägg
- förhindra
- föregående
- process
- bearbetning
- producera
- producent
- egenskaper
- ge
- förutsatt
- ger
- Läsa
- verklig
- realtid
- motta
- post
- register
- hänvisar
- region
- registrera
- registrerat
- register
- Repository
- representerade
- Resurser
- återgår
- Roll
- Regel
- Körning
- rinnande
- Samma
- skalbar
- sömlöst
- Sök
- sekunder
- säkra
- säkerhet
- senior
- känslig
- separat
- service
- Tjänster
- in
- inställningar
- skall
- Enkelt
- förenkla
- lösning
- Lösningar
- några
- Källa
- Källor
- specialist
- specifik
- specificerade
- stapel
- Starta
- status
- Steg
- Steg
- förvaring
- lagra
- lagrar
- ström
- streaming
- strömmar
- struktur
- lämplig
- Stödjande
- Stöder
- synkronisera.
- system
- System
- bord
- Målet
- uppgifter
- mall
- testa
- den där
- Smakämnen
- källan
- Dem
- Dessa
- tid
- tidskänslig
- Titel
- till
- ämne
- Transaktioner
- SVÄNG
- typer
- under
- oönskade
- uppdatering
- användning
- Användare
- värde
- Värden
- version
- webb
- webbservice
- som
- kommer
- fönster
- med
- arbetstagaren
- arbetare
- arbetssätt
- fungerar
- skriven
- Din
- zephyrnet