Vi lever i en tid av realtidsdata och insikter, drivna av dataströmningsapplikationer med låg latens. Idag förväntar alla sig en personlig upplevelse i alla applikationer, och organisationer förnyar ständigt för att öka hastigheten på affärsdrift och beslutsfattande. Mängden tidskänslig data som produceras ökar snabbt, med olika dataformat som introduceras i nya företag och kundanvändningsfall. Därför är det avgörande för organisationer att anamma en skalbar och pålitlig dataströmningsinfrastruktur med låg latens för att leverera affärsapplikationer i realtid och bättre kundupplevelser.
Det här är det första inlägget i en bloggserie som erbjuder vanliga arkitektoniska mönster för att bygga realtidsdataströmningsinfrastrukturer med Kinesis Data Streams för ett brett spektrum av användningsfall. Det syftar till att tillhandahålla ett ramverk för att skapa streamingapplikationer med låg latens på AWS-molnet med hjälp av Amazon Kinesis dataströmmar och AWS specialbyggda dataanalystjänster.
I det här inlägget kommer vi att granska de vanliga arkitekturmönstren för två användningsfall: tidsseriedataanalys och händelsedrivna mikrotjänster. I det efterföljande inlägget i vår serie kommer vi att utforska de arkitektoniska mönstren i att bygga strömmande pipelines för BI-instrumentpaneler i realtid, kontaktcenteragent, reskontradata, personliga rekommendationer i realtid, logganalys, IoT-data, Change Data Capture och verklig -tidsmarknadsföringsdata. Alla dessa arkitekturmönster är integrerade med Amazon Kinesis Data Streams.
Strömning i realtid med Kinesis Data Streams
Amazon Kinesis Data Streams är en molnbaserad, serverlös strömningsdatatjänst som gör det enkelt att fånga, bearbeta och lagra realtidsdata i vilken skala som helst. Med Kinesis Data Streams kan du samla in och bearbeta hundratals gigabyte data per sekund från hundratusentals källor, vilket gör att du enkelt kan skriva applikationer som behandlar information i realtid. Den insamlade informationen är tillgänglig på millisekunder för att möjliggöra användningsfall för analys i realtid, såsom instrumentpaneler i realtid, upptäckt av anomalier i realtid och dynamisk prissättning. Som standard lagras data i Kinesis Data Stream i 24 timmar med möjlighet att öka datalagringen till 365 dagar. Om kunder vill bearbeta samma data i realtid med flera applikationer kan de använda funktionen Enhanced Fan-Out (EFO). Före den här funktionen delade varje applikation som förbrukade data från strömmen utgången på 2 MB/sekund/shard. Genom att konfigurera strömkonsumenter för att använda utökad fan-out, får varje datakonsument dedikerad 2MB/sekund läskapacitet per shard för att ytterligare minska latensen i datahämtning.
För hög tillgänglighet och hållbarhet uppnår Kinesis Data Streams hög hållbarhet genom att synkront replikera den strömmade datan över tre tillgänglighetszoner i en AWS-region och ger dig möjlighet att behålla data i upp till 365 dagar. Av säkerhetsskäl tillhandahåller Kinesis Data Streams kryptering på serversidan så att du kan uppfylla strikta datahanteringskrav genom att kryptera din data i vila och Amazon Virtual Private Cloud (VPC) gränssnittsslutpunkter för att hålla trafiken mellan din Amazon VPC och Kinesis Data Streams privat.
Kinesis Data Streams har inbyggda integrationer med andra AWS-tjänster som t.ex AWS-lim och Amazon EventBridge att bygga streamingapplikationer i realtid på AWS. Se Amazon Kinesis Data Streams-integrationer för ytterligare information.
Modern dataströmningsarkitektur med Kinesis Dataströmmar
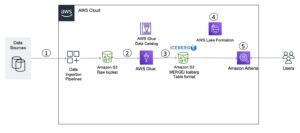
En modern strömmande dataarkitektur med Kinesis Data Streams kan utformas som en stack av fem logiska lager; varje lager är sammansatt av flera specialbyggda komponenter som uppfyller specifika krav, som illustreras i följande diagram:
Arkitekturen består av följande nyckelkomponenter:
- Strömmande källor – Din källa för strömmande data inkluderar datakällor som klickströmsdata, sensorer, sociala medier, Internet of Things (IoT)-enheter, loggfiler som genereras genom att använda dina webb- och mobilapplikationer och mobila enheter som genererar semistrukturerad och ostrukturerad data som kontinuerliga strömmar vid hög hastighet.
- Strömintag – Ströminmatningsskiktet ansvarar för att mata in data till strömlagringsskiktet. Det ger möjlighet att samla in data från tiotusentals datakällor och ta in i realtid. Du kan använda Kinesis SDK för inmatning av strömmande data via API:er Kinesis producentbibliotek för att bygga högpresterande och långvariga streamingproducenter, eller en Kinesis agent för att samla in en uppsättning filer och mata in dem i Kinesis Data Streams. Dessutom kan du använda många förbyggda integrationer som t.ex AWS Database Migration Service (AWS DMS), Amazon DynamoDBoch AWS IoT Core att mata in data utan kod. Du kan också mata in data från tredjepartsplattformar som Apache Spark och Apache Kafka Connect
- Streama lagring – Kinesis dataströmmar erbjuder två lägen för att stödja datagenomströmningen: On-Demand och Provisioned. On-Demand-läge, nu standardvalet, kan skalas elastiskt för att absorbera variabla genomströmningar, så att kunderna inte behöver oroa sig för kapacitetshantering och betala med datagenomströmning. On-Demand-läget skalar automatiskt upp 2x strömkapaciteten över dess historiska maximala dataintag för att ge tillräcklig kapacitet för oväntade toppar i dataintag. Alternativt kan kunder som vill ha granulär kontroll över strömresurser använda läget Provisioned och proaktivt skala upp och ner antalet Shards för att möta deras genomströmningskrav. Dessutom kan Kinesis Data Streams lagra strömmande data upp till 24 timmar som standard, men kan förlängas till 7 dagar eller 365 dagar beroende på användningsfall. Flera applikationer kan konsumera samma ström.
- Strömbehandling – Strömbehandlingslagret är ansvarigt för att omvandla data till ett förbrukningsbart tillstånd genom datavalidering, rensning, normalisering, transformation och anrikning. Streamingposterna läses i den ordning de produceras, vilket möjliggör realtidsanalys, byggande av händelsedrivna applikationer eller streaming ETL (extrahera, transformera och ladda). Du kan använda Amazon Managed Service för Apache Flink för komplex strömdatabehandling, AWS Lambda för tillståndslös strömdatabehandling, och AWS-lim & Amazon EMR för nästan realtidsberäkning. Du kan också bygga skräddarsydda konsumentapplikationer med Kinesis konsumentbibliotek, som kommer att ta hand om många komplexa uppgifter i samband med distribuerad datoranvändning.
- Destination - Destinationsskiktet är som en specialbyggd destination beroende på ditt användningsfall. Du kan strömma data direkt till Amazon RedShift för datalagring och Amazon EventBridge för att bygga händelsedrivna applikationer. Du kan också använda Amazon Kinesis Data Firehose för streaming-integration där du kan lätt streama bearbetning med AWS Lambda och sedan leverera bearbetad streaming till destinationer som Amazon S3 data lake, OpenSearch Service för operationell analys, ett Redshift-datalager, No-SQL-databaser som Amazon DynamoDB och relationsdatabaser som Amazon RDS att konsumera realtidsströmmar till affärsapplikationer. Destinationen kan vara en händelsedriven applikation för instrumentpaneler i realtid, automatiska beslut baserade på bearbetad strömmande data, realtidsändring och mer.
Realtidsanalysarkitektur för tidsserier
Tidsseriedata är en sekvens av datapunkter som registreras över ett tidsintervall för att mäta händelser som ändras över tiden. Exempel är aktiekurser över tid, klickströmmar på webbsidor och enhetsloggar över tid. Kunder kan använda tidsseriedata för att övervaka förändringar över tid, så att de kan upptäcka anomalier, identifiera mönster och analysera hur vissa variabler påverkas över tid. Tidsseriedata genereras vanligtvis från flera källor i stora volymer, och de måste samlas in på ett kostnadseffektivt sätt i nästan realtid.
Vanligtvis finns det tre primära mål som kunderna vill uppnå med att bearbeta tidsseriedata:
- Få insikter i realtid om systemets prestanda och upptäck avvikelser
- Förstå slutanvändarnas beteende för att spåra trender och fråga/bygga visualiseringar utifrån dessa insikter
- Ha en hållbar lagringslösning för att inta och lagra både arkivdata och data som ofta används.
Med Kinesis Data Streams kan kunder kontinuerligt fånga in terabyte av tidsseriedata från tusentals källor för rengöring, anrikning, lagring, analys och visualisering.
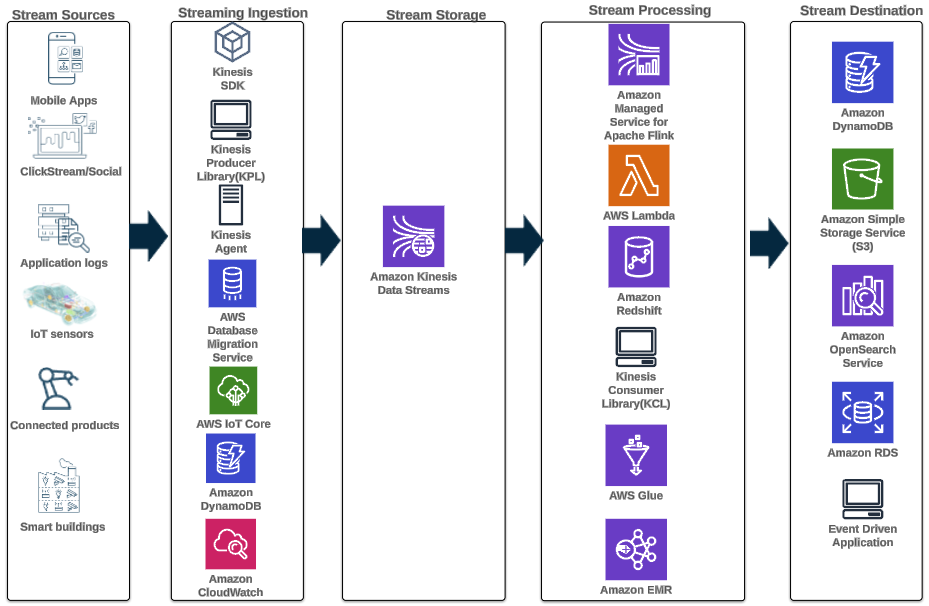
Följande arkitekturmönster illustrerar hur realtidsanalys kan uppnås för tidsseriedata med Kinesis Dataströmmar:
Arbetsflödesstegen är följande:
- Dataintag och lagring – Kinesis Data Streams kan kontinuerligt fånga och lagra terabyte med data från tusentals källor.
- Strömbehandling – En applikation skapad med Amazon Managed Service för Apache Flink kan läsa posterna från dataströmmen för att upptäcka och rensa eventuella fel i tidsseriedata och berika data med specifik metadata för att optimera operationsanalyser. Att använda en dataström i mitten ger fördelen av att använda tidsseriedata i andra processer och lösningar samtidigt. En lambdafunktion anropas sedan med dessa händelser, och kan utföra tidsserieberäkningar i minnet.
- Resmål – Efter rengöring och berikning kan den bearbetade tidsseriedata streamas till Amazon Timestream databas för instrumentpanel och analys i realtid, eller lagras i databaser som DynamoDB för slutanvändarfrågor. Rådata kan strömmas till Amazon S3 för arkivering.
- Visualisering och få insikter – Kunder kan fråga, visualisera och skapa varningar med hjälp av Amazon Managed Service för Grafana. Grafana stöder datakällor som är lagringsbackends för tidsseriedata. För att komma åt dina data från Timestream måste du installera Timestream-plugin för Grafana. Slutanvändare kan fråga data från DynamoDB-tabellen med Amazon API Gateway agerar som ombud.
Hänvisa till Nära realtidsbearbetning med Amazon Kinesis, Amazon Timestream och Grafana visar upp en serverlös strömningspipeline för att bearbeta och lagra enhetstelemetri IoT-data i en tidsserieoptimerad databutik som Amazon Timestream.
Berika och spela upp data i realtid för mikrotjänster för evenemangssourcing
Mikrotjänster är ett arkitektoniskt och organisatoriskt tillvägagångssätt för mjukvaruutveckling där mjukvara är sammansatt av små oberoende tjänster som kommunicerar över väldefinierade API:er. När man bygger händelsedrivna mikrotjänster vill kunder uppnå 1. hög skalbarhet för att hantera volymen av inkommande händelser och 2. tillförlitlighet i händelsebearbetning och upprätthålla systemfunktionalitet inför fel.
Kunder använder mikrotjänstarkitekturmönster för att påskynda innovation och time-to-market för nya funktioner, eftersom det gör applikationer lättare att skala och snabbare att utveckla. Det är dock utmanande att berika och spela upp data i ett nätverksanrop till en annan mikrotjänst eftersom det kan påverka applikationens tillförlitlighet och göra det svårt att felsöka och spåra fel. För att lösa detta problem är event-sourcing ett effektivt designmönster som centraliserar historiska register över alla tillståndsförändringar för berikning och uppspelning, och frikopplar läsning från skrivarbetsbelastningar. Kunder kan använda Kinesis Data Streams som den centraliserade händelsebutiken för mikrotjänster för event-sourcing, eftersom KDS kan 1/ hantera gigabyte datagenomströmning per sekund per ström och strömma data på millisekunder, för att uppfylla kravet på hög skalbarhet och nära realtid latens, 2/ integrera med Flink och S3 för databerikning och uppnående samtidigt som den är helt frikopplad från mikrotjänsterna, och 3/ tillåter ett nytt försök och asynkron läsning vid ett senare tillfälle, eftersom KDS behåller dataposten under en standard på 24 timmar, och valfritt upp till 365 dagar.
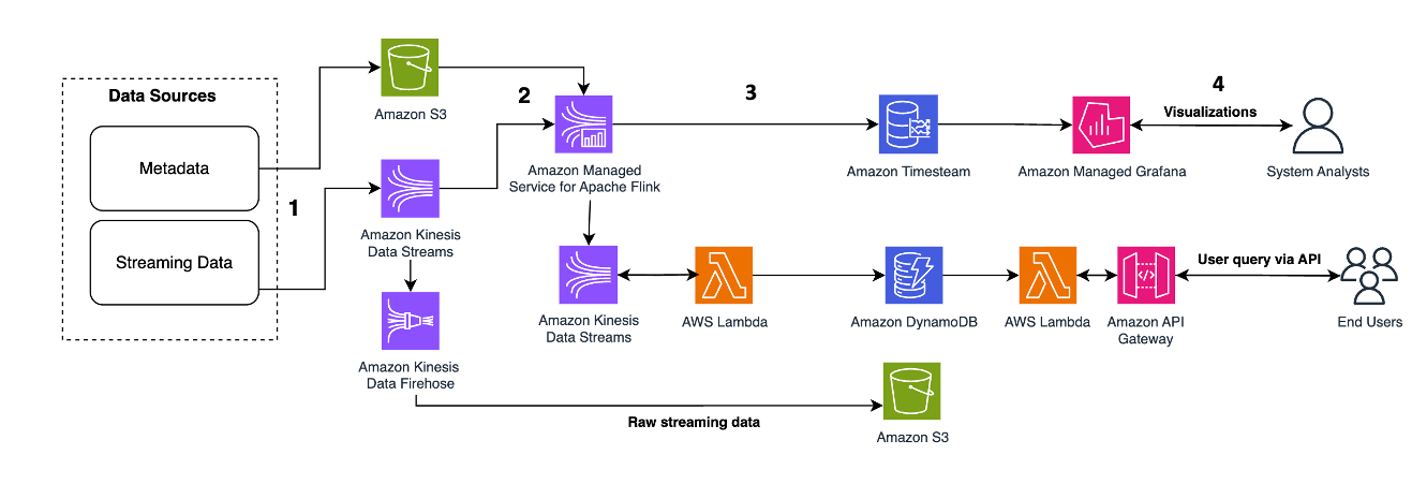
Följande arkitektoniska mönster är en generisk illustration av hur Kinesis Dataströmmar kan användas för Event-Sourcing Microservices:
Stegen i arbetsflödet är följande:
- Dataintag och lagring – Du kan aggregera indata från dina mikrotjänster till dina Kinesis Dataströmmar för lagring.
- Strömbehandling - Apache Flink Stateful Functions förenklar att bygga distribuerade tillståndsstyrda händelsedrivna applikationer. Den kan ta emot händelserna från en Kinesis-indataström och dirigera den resulterande strömmen till en utdataström. Du kan skapa ett tillståndsfullt funktionskluster med Apache Flink baserat på din applikations affärslogik.
- Tillståndsbild i Amazon S3 – Du kan lagra tillståndsbilden i Amazon S3 för spårning.
- Utgångsströmmar – Utdataströmmarna kan konsumeras genom Lambda-fjärrfunktioner via HTTP/gRPC-protokollet via API Gateway.
- Lambda fjärrfunktioner – Lambda-funktioner kan fungera som mikrotjänster för olika applikations- och affärslogik för att tjäna affärsapplikationer och mobilappar.
För att lära dig hur andra kunder byggde sina händelsebaserade mikrotjänster med Kinesis Data Streams, se följande:
Viktiga överväganden och bästa praxis
Följande är överväganden och bästa praxis att tänka på:
- Dataupptäckt bör vara ditt första steg i att bygga moderna dataströmningsapplikationer. Du måste definiera affärsvärdet och sedan identifiera dina strömmande datakällor och användarpersoner för att uppnå önskade affärsresultat.
- Välj ditt verktyg för inmatning av strömmande data baserat på din ångande datakälla. Du kan till exempel använda Kinesis SDK för inmatning av strömmande data via API:er Kinesis producentbibliotek för att bygga högpresterande och långvariga streamingproducenter, a Kinesis agent för att samla in en uppsättning filer och mata in dem i Kinesis Data Streams, AWS DMS för CDC-streaming användningsfall, och AWS IoT Core för inmatning av IoT-enhetsdata i Kinesis Dataströmmar. Du kan mata in strömmande data direkt i Amazon Redshift för att bygga streamingapplikationer med låg latens. Du kan också använda tredjepartsbibliotek som Apache Spark och Apache Kafka för att mata in strömmande data i Kinesis Data Streams.
- Du måste välja dina strömmande databehandlingstjänster baserat på ditt specifika användningsfall och affärskrav. Till exempel kan du använda Amazon Kinesis Managed Service för Apache Flink för avancerade streaming-användningsfall med flera streamingdestinationer och komplex stateful stream-bearbetning eller om du vill övervaka affärsmått i realtid (som varje timme). Lambda är bra för händelsebaserad och tillståndslös bearbetning. Du kan använda Amazon EMR för strömmande databehandling för att använda dina favorit ramverk för stordata med öppen källkod. AWS Glue är bra för strömmande databearbetning i nästan realtid för användningsfall som strömmande ETL.
- Kinesis Data Streams on-demand-lägesavgifter efter användning och skalar automatiskt upp resurskapaciteten, så det är bra för taggiga strömmande arbetsbelastningar och handsfree-underhåll. Provisionerat läge debiteras per kapacitet och kräver proaktiv kapacitetshantering, så det är bra för förutsägbara strömmande arbetsbelastningar.
- Du kan använda Kinesis delad kalkylator för att beräkna antalet shards som behövs för provisionerat läge. Du behöver inte oroa dig för skärvor med on-demand-läge.
- När du beviljar behörigheter bestämmer du vem som får vilka behörigheter till vilka Kinesis Data Streams-resurser. Du aktiverar specifika åtgärder som du vill tillåta på dessa resurser. Därför bör du bara ge de behörigheter som krävs för att utföra en uppgift. Du kan också kryptera data i vila genom att använda en KMS kundhanterad nyckel (CMK).
- Du kan uppdatera lagringsperioden via Kinesis Data Streams-konsolen eller genom att använda ÖkaStreamRetentionPeriod och Minska StreamRetentionPeriod operationer baserat på dina specifika användningsfall.
- Kinesis Data Streams stöder omhärdning. Rekommenderat API för denna funktion är UpdateShardCount, vilket gör att du kan ändra antalet skärvor i din ström för att anpassa dig till förändringar i dataflödeshastigheten genom strömmen. Omskärnings-API:erna (Split och Merge) används vanligtvis för att hantera heta skärvor.
Slutsats
Det här inlägget demonstrerade olika arkitektoniska mönster för att bygga streamingapplikationer med låg latens med Kinesis Data Streams. Du kan bygga dina egna steaming-applikationer med låg latens med Kinesis Data Streams med hjälp av informationen i det här inlägget.
För detaljerade arkitektoniska mönster, se följande resurser:
Om du vill bygga en datavision och strategi, kolla in AWS datadrivet allt (D2E) program.
Om författarna
 Raghavarao Sodabatathina är en Principal Solutions Architect på AWS, med fokus på Data Analytics, AI/ML och molnsäkerhet. Han engagerar sig med kunder för att skapa innovativa lösningar som tar itu med kundernas affärsproblem och för att påskynda införandet av AWS-tjänster. På sin fritid gillar Raghavarao att umgås med sin familj, läsa böcker och titta på film.
Raghavarao Sodabatathina är en Principal Solutions Architect på AWS, med fokus på Data Analytics, AI/ML och molnsäkerhet. Han engagerar sig med kunder för att skapa innovativa lösningar som tar itu med kundernas affärsproblem och för att påskynda införandet av AWS-tjänster. På sin fritid gillar Raghavarao att umgås med sin familj, läsa böcker och titta på film.
 Häng Zuo är Senior Product Manager på Amazon Kinesis Data Streams-teamet på Amazon Web Services. Han brinner för att utveckla intuitiva produktupplevelser som löser komplexa kundproblem och gör det möjligt för kunder att nå sina affärsmål.
Häng Zuo är Senior Product Manager på Amazon Kinesis Data Streams-teamet på Amazon Web Services. Han brinner för att utveckla intuitiva produktupplevelser som löser komplexa kundproblem och gör det möjligt för kunder att nå sina affärsmål.
 Shwetha Radhakrishnan är en Solutions Architect för AWS med fokus på Data Analytics. Hon har byggt lösningar som driver molnadoption och hjälper organisationer att fatta datadrivna beslut inom den offentliga sektorn. Utanför jobbet älskar hon att dansa, umgås med vänner och familj och att resa.
Shwetha Radhakrishnan är en Solutions Architect för AWS med fokus på Data Analytics. Hon har byggt lösningar som driver molnadoption och hjälper organisationer att fatta datadrivna beslut inom den offentliga sektorn. Utanför jobbet älskar hon att dansa, umgås med vänner och familj och att resa.
 Brittany Ly är lösningsarkitekt på AWS. Hon är fokuserad på att hjälpa företagskunder med deras molnanpassning och moderniseringsresa och har ett intresse för säkerhets- och analysområdet. Utanför jobbet älskar hon att umgås med sin hund och spela pickleball.
Brittany Ly är lösningsarkitekt på AWS. Hon är fokuserad på att hjälpa företagskunder med deras molnanpassning och moderniseringsresa och har ett intresse för säkerhets- och analysområdet. Utanför jobbet älskar hon att umgås med sin hund och spela pickleball.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 100
- 24
- 7
- a
- förmåga
- Om oss
- accelerera
- tillgång
- Accessed
- Uppnå
- uppnås
- uppnår
- uppnå
- tvärs
- Agera
- verkande
- åtgärder
- anpassa
- Dessutom
- Annat
- Dessutom
- adress
- Antagande
- avancerat
- Fördel
- Efter
- ålder
- Recensioner
- aggregat
- AI / ML
- Syftet
- varningar
- Alla
- tillåter
- tillåta
- tillåter
- också
- amason
- Amazon Kinesis
- Amazon Timestream
- Amazon Web Services
- an
- analys
- analytics
- analysera
- och
- avvikelse av anomali
- Annan
- vilken som helst
- Apache
- Apache Kafka
- Apache Spark
- api
- API: er
- Ansökan
- tillämpningar
- tillvägagångssätt
- appar
- arkitektoniska
- arkitektur
- ÄR
- AS
- associerad
- At
- Automat
- automatiskt
- tillgänglighet
- tillgänglig
- AWS
- AWS-lim
- AWS Lambda
- baserat
- BE
- därför att
- varit
- beteende
- Där vi får lov att vara utan att konstant prestera,
- BÄST
- bästa praxis
- Bättre
- mellan
- Stor
- Stora data
- Blogg
- Böcker
- båda
- SLUTRESULTAT
- Byggnad
- byggt
- företag
- Business Applications
- företag
- men
- by
- beräkna
- Ring
- KAN
- Kapacitet
- fånga
- vilken
- Vid
- fall
- CDC
- Centrum
- centraliserad
- vissa
- utmanande
- byta
- Förändringar
- avgifter
- ta
- val
- Välja
- rena
- Rengöring
- cloud
- moln adoption
- Cloud Security
- kluster
- samla
- Samla
- Gemensam
- kommunicera
- fullständigt
- komplex
- komponenter
- sammansatt
- Compute
- databehandling
- aktuella
- konfigurering
- överväganden
- består
- Konsol
- ständigt
- konsumera
- konsumeras
- Konsumenten
- konsumenter
- kontakta
- kontaktcenter
- kontinuerlig
- kontinuerligt
- kontroll
- skapa
- skapas
- kritisk
- kund
- Kunder
- kundanpassad
- Dans
- instrumentpaneler
- datum
- dataanalys
- Data Analytics
- datarikning
- datasjö
- datahantering
- datapunkter
- databehandling
- datalagret
- data driven
- Databas
- databaser
- Dagar
- beslutar
- Beslutet
- Beslutsfattande
- beslut
- frikopplat
- dedicerad
- Standard
- definiera
- leverera
- demonstreras
- beroende
- Designa
- utformade
- önskas
- destination
- destinationer
- detaljerad
- detaljer
- upptäcka
- Detektering
- utveckla
- utveckla
- Utveckling
- anordning
- enheter
- olika
- svårt
- direkt
- Upptäckten
- distribueras
- distribuerad databehandling
- do
- Dog
- inte
- ner
- driv
- driven
- hållbarhet
- dynamisk
- varje
- lättare
- lätt
- lätt
- Effektiv
- omfamna
- möjliggöra
- kryptering
- endpoints
- ingriper
- förbättrad
- berika
- Företag
- företagskunder
- fel
- Eter (ETH)
- händelse
- händelser
- Varje
- alla
- exempel
- exempel
- förväntar
- erfarenhet
- Erfarenheter
- utforska
- förlänga
- extrahera
- Ansikte
- misslyckanden
- familj
- Mode
- snabbare
- Favoriten
- Leverans
- Funktioner
- fält
- Filer
- Förnamn
- fem
- flöda
- Fokus
- fokuserade
- fokusering
- efter
- följer
- För
- Ramverk
- ramar
- ofta
- vänner
- från
- fungera
- funktionalitet
- funktioner
- ytterligare
- Få
- nätbryggan
- generera
- genereras
- få
- GitHub
- ger
- Mål
- god
- bevilja
- beviljande
- hantera
- Hänga
- he
- hjälpa
- hjälpa
- här
- Hög
- högpresterande
- hans
- historiska
- HET
- timme
- ÖPPETTIDER
- Hur ser din drömresa ut
- Men
- html
- http
- HTTPS
- Hundratals
- identifiera
- if
- illustrerar
- Inverkan
- in
- I andra
- innefattar
- Inkommande
- Öka
- ökande
- oberoende
- påverkas
- informationen
- Infrastruktur
- infrastruktur
- nyskapande
- Innovation
- innovativa
- ingång
- insikter
- installera
- integrera
- integrerade
- integrering
- integrationer
- intresse
- Gränssnitt
- Internet
- sakernas Internet
- in
- introducerade
- intuitiv
- åberopas
- iot
- IoT-enhet
- IT
- DESS
- resa
- jpg
- kafka
- Ha kvar
- Nyckel
- Kinesis dataströmmar
- sjö
- Latens
- senare
- lager
- skikt
- LÄRA SIG
- Ledger
- bibliotek
- Bibliotek
- ljus
- tycka om
- levande
- läsa in
- log
- Logiken
- logisk
- älskar
- bibehålla
- underhåll
- göra
- GÖR
- Framställning
- förvaltade
- ledning
- chef
- många
- Marknadsföring
- maximal
- mätning
- Media
- Möt
- Minne
- Sammanfoga
- metadata
- Metrics
- microservices
- Mitten
- migration
- millisekunder
- emot
- Mobil
- Mobila applikationer
- Mobil enheter
- mobil-appar
- Mode
- Modern Konst
- modernisering
- lägen
- modifiera
- Övervaka
- mer
- Filmer
- multipel
- måste
- nativ
- Nära
- Behöver
- behövs
- behov
- nät
- Nya
- Nya funktioner
- nu
- antal
- of
- erbjudanden
- Erbjudanden
- on
- On-Demand
- endast
- öppet
- öppen källkod
- drift
- operativa
- Verksamhet
- Optimera
- optimerad
- Alternativet
- or
- beställa
- organisatoriska
- organisationer
- Övriga
- vår
- ut
- utfall
- produktion
- utanför
- över
- egen
- del
- brinner
- Mönster
- mönster
- Betala
- för
- utföra
- prestanda
- behörigheter
- personlig
- Röret
- rörledning
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- plugin
- poäng
- Inlägg
- praxis
- Förutsägbar
- Priser
- prissättning
- primär
- Principal
- Innan
- privat
- Proaktiv
- Problem
- problem
- process
- bearbetade
- processer
- bearbetning
- producerad
- producent
- producenter
- Produkt
- produktchef
- Program
- protokoll
- ge
- ger
- ombud
- allmän
- område
- snabbt
- Betygsätta
- Raw
- rådata
- Läsa
- Läsning
- verklig
- realtid
- data i realtid
- motta
- erhåller
- Rekommendation
- rekommenderas
- post
- registreras
- register
- minska
- hänvisa
- region
- tillförlitlighet
- pålitlig
- avlägsen
- Obligatorisk
- krav
- Krav
- Kräver
- resurs
- Resurser
- ansvarig
- REST
- resulterande
- behålla
- behåller
- retentionstid
- översyn
- Rutt
- Samma
- skalbarhet
- skalbar
- Skala
- skalor
- Andra
- sektor
- säkerhet
- senior
- sensor
- Sekvens
- Serier
- tjänar
- Server
- service
- Tjänster
- in
- delas
- hon
- skall
- visa upp
- förenklar
- Small
- Snapshot
- So
- Social hållbarhet
- sociala medier
- Mjukvara
- mjukvaruutveckling
- lösning
- Lösningar
- LÖSA
- Källa
- Källor
- Gnista
- specifik
- fart
- spendera
- Spendera
- spikar
- delas
- stapel
- Ange
- Steg
- Steg
- lager
- förvaring
- lagra
- lagras
- Strategi
- ström
- strömmas
- streaming
- strömmar
- sträng
- senare
- sådana
- tillräcklig
- stödja
- Stöder
- system
- bord
- Ta
- uppgift
- uppgifter
- grupp
- tiotals
- den där
- Smakämnen
- den information
- Staten
- deras
- Dem
- sedan
- Där.
- därför
- Dessa
- de
- saker
- tredje part
- detta
- de
- tusentals
- tre
- Genom
- genomströmning
- tid
- Tidsföljder
- tidskänslig
- till
- i dag
- verktyg
- spåra
- spår
- Spårning
- trafik
- Förvandla
- Transformation
- omvandla
- Traveling
- Trender
- två
- typiskt
- Oväntat
- på
- Användning
- användning
- användningsfall
- Begagnade
- Användare
- med hjälp av
- utnyttja
- godkännande
- värde
- variabel
- olika
- Hastighet
- via
- Virtuell
- syn
- visualisering
- visualisera
- volym
- volymer
- vill
- Warehouse
- Lagring
- tittar
- we
- webb
- webbservice
- väldefinierad
- Vad
- när
- som
- medan
- VEM
- bred
- Brett utbud
- kommer
- med
- inom
- Arbete
- arbetsflöde
- oro
- skriva
- dig
- Din
- zephyrnet
- zoner