Amazonas Athena är en interaktiv frågetjänst som gör det enkelt att analysera data i Amazon enkel lagringstjänst (Amazon S3) och datakällor som finns i AWS, lokala eller andra molnsystem som använder SQL eller Python. Athena är byggt på Trino- och Presto-motorer med öppen källkod, och Apache Spark-ramverk, utan att provisionering eller konfigurering krävs. Athena är serverlöst, så det finns ingen infrastruktur att hantera, och du betalar bara för de frågor du kör.
Apache isberg är ett öppet tabellformat för mycket stora analytiska datamängder. Den hanterar stora samlingar av filer som tabeller, och den stöder moderna analytiska datasjöoperationer som infogning, uppdatering, radering och tidsresor på rekordnivå. Athena stöder läs-, tidsresor, skriv- och DDL-frågor för Apache Iceberg-bord som använder Apache Parquet-formatet för data och AWS limdatakatalog för deras metastore.
Funktionsteknik är en process för att identifiera och transformera rådata (bilder, textfiler, videor och så vidare), återfylla saknad data och lägga till ett eller flera meningsfulla dataelement för att tillhandahålla sammanhang så att en maskininlärningsmodell (ML) kan lära av det. Datamärkning krävs för olika användningsfall, inklusive prognoser, datorseende, naturlig språkbehandling och taligenkänning.
Kombinerat med funktionerna hos Athena, levererar Apache Iceberg ett förenklat arbetsflöde för datavetare att skapa nya datafunktioner utan att behöva kopiera eller återskapa hela datamängden. Du kan skapa funktioner med standard SQL på Athena utan att använda någon annan tjänst för funktionsutveckling. Dataforskare kan minska tiden som ägnas åt att förbereda och kopiera datamängder och istället fokusera på datafunktionsteknik, experiment och analysera data i stor skala.
I det här inlägget granskar vi fördelarna med att använda Athena med Apache Icebergs öppna tabellformat och hur det förenklar vanliga funktionstekniska uppgifter för datavetare. Vi visar hur Athena kan konvertera en befintlig tabell i Apache Iceberg-format, sedan lägga till kolumner, ta bort kolumner och ändra data i tabellen utan att återskapa eller kopiera datamängden, och använda dessa funktioner för att skapa nya funktioner på Apache Iceberg-tabeller.
Lösningsöversikt
Dataforskare är i allmänhet vana vid att arbeta med stora datamängder. Datauppsättningar lagras vanligtvis i antingen JSON, CSV, ORC eller Apache parkett format, eller liknande läsoptimerade format för snabb läsprestanda. Dataforskare skapar ofta nya datafunktioner och fyller på sådana datafunktioner med aggregerade och kompletterande data. Historiskt sett har denna uppgift åstadkommits genom att skapa en vy ovanpå tabellen med underliggande data i Apache Parquet-format, där sådana kolumner och data lades till under körning eller genom att skapa en ny tabell med ytterligare kolumner. Även om det här arbetsflödet är väl lämpat för många användningsfall är det ineffektivt för stora datamängder, eftersom data skulle behöva genereras vid körning eller datauppsättningar skulle behöva kopieras och transformeras.
Athena har introducerat ACID-transaktion (Atomicitet, Konsistens, Isolering, Hållbarhet). funktioner som lägger till INSERT, UPDATE, DELETE, MERGE och tidsresor som bygger på Apache Iceberg-bord. Dessa funktioner gör det möjligt för datavetare att skapa nya datafunktioner och släppa befintliga datafunktioner på befintliga datauppsättningar utan att behöva oroa sig för att kopiera eller transformera datauppsättningen eller abstrahera den med en vy. Dataforskare kan fokusera på funktionsteknik och undvika att kopiera och transformera datamängderna.
Athena Iceberg UPDATE-operationen skriver Apache Iceberg position raderingsfiler och nyligen uppdaterade rader som datafiler i samma transaktion. Du kan göra postkorrigeringar via en enda UPDATE-sats.
Med lanseringen av Athena engine version 3 förbättras kapaciteten för Apache Iceberg-bord med stöd för operationer som t.ex. SKAPA TABELL SOM SELECT (CTAS) och MERGE-kommandon som effektiviserar livscykelhanteringen av dina Iceberg-data. CTAS gör det snabbt och effektivt att skapa tabeller från andra format som Apache Paquet och SLÅS SAMMAN TILL villkorliga uppdateringar, tar bort eller infogar rader i en isbergstabell. En enskild sats kan kombinera uppdatering, radering och infoga åtgärder.
Förutsättningar
Skapa en Athena-arbetsgrupp med Athena-motorversion 3 för att använda CTAS- och MERGE-kommandon med ett Apache Iceberg-bord. För att uppgradera din befintliga Athena-motor till version 3 i din Athena-arbetsgrupp, följ instruktionerna i Uppgradera till Athena-motorversion 3 för att öka frågeprestanda och få tillgång till fler analysfunktioner eller hänvisa till Ändra motorversionen i Athena-konsolen.
dataset
För demonstration använder vi ett Apache Parquet-bord som innehåller flera miljoner poster med slumpmässigt distribuerade fiktiva försäljningsdata från de senaste åren lagrade i en S3-hink. Download datauppsättningen, packa upp den till din lokala dator och ladda upp den till din S3-hink. I det här inlägget laddade vi upp vår datauppsättning till s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
Följande tabell visar layouten för tabellen customer_orders.
| Kolumnnamn | Data typ | Beskrivning |
| ordernyckel | sträng | Ordernummer för beställningen |
| custkey | sträng | Kundens identifikationsnummer |
| orderstatus | sträng | Status för beställningen |
| totalbelopp | sträng | Totalpriset för beställningen |
| orderdatum | sträng | Datum för beställningen |
| orderprioritet | sträng | Beställningens prioritet |
| kontorist | sträng | Namn på expediten som behandlade beställningen |
| fartygsprioritet | sträng | Prioritet på frakten |
| namn | sträng | Köparens namn |
| adress | sträng | Kundadress |
| nationsnyckel | sträng | Kundnationsnyckel |
| telefon | sträng | Kundens telefonnummer |
| acctbal | sträng | Kundkontosaldo |
| mktsegment | sträng | Kundmarknadssegment |
Utför funktionsteknik
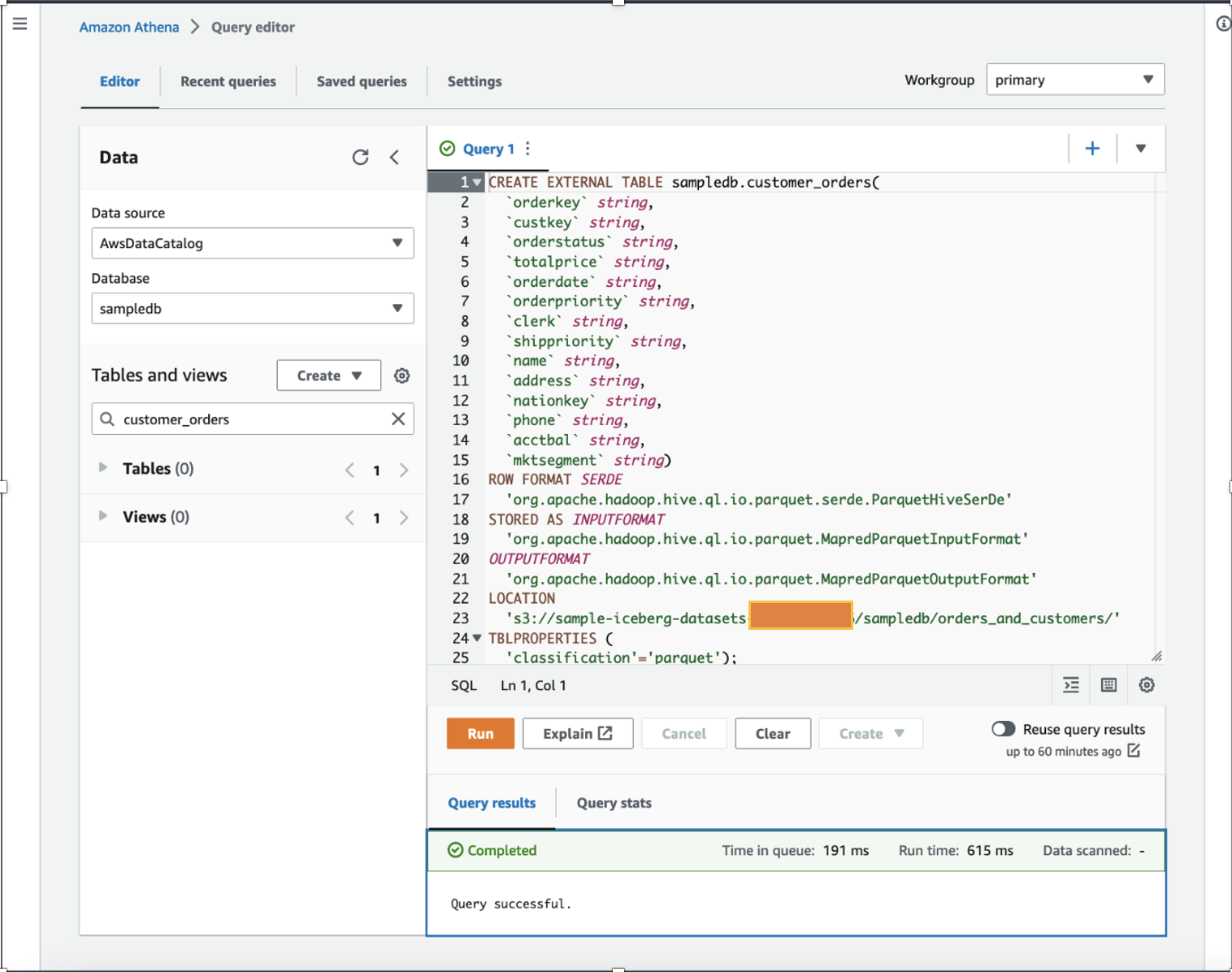
Som datavetare vill vi prestera funktionsteknik på kundorderdata genom att lägga till beräknade ett års totala inköp och ett års genomsnittliga inköp för varje kund i den befintliga datamängden. För demonstrationsändamål skapade vi customer_orders tabell i sampledb databas med Athena som visas i följande DDL-kommando. (Du kan använda vilken som helst av dina befintliga datauppsättningar och följa stegen som nämns i det här inlägget.) The customer_orders datauppsättning genererades och lagrades på S3-skopplatsen s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ i parkettformat. Detta bord är inte ett Apache Iceberg-bord.
![]()
Validera data i tabellen genom att köra en fråga:
![]()
Vi vill lägga till nya funktioner i den här tabellen för att få en djupare förståelse för kundförsäljning, vilket kan resultera i snabbare modellutbildning och mer värdefulla insikter. För att lägga till nya funktioner till datamängden, konvertera customer_orders Athena-bord till Apache Iceberg-bord på Athena. Utfärda en CTAS frågesats för att skapa en ny tabell med Apache Iceberg-format från customer_orders tabell. Medan du gör det läggs en ny funktion till för att få det totala inköpsbeloppet under det senaste året (max år för datasetet) av varje kund.
I följande CTAS-fråga namnges en ny kolumn one_year_sales_aggregate med standardvärdet som 0.0 av datatyp double läggs till och table_type är inställd på ICEBERG:
![]()
Utfärda följande fråga för att verifiera data i Apache Iceberg-tabellen med den nya kolumnen one_year_sales_aggregate värden som 0.0:
![]()
Vi vill fylla i värdena för den nya funktionen one_year_sales_aggregate i datasetet för att få det totala inköpsbeloppet för varje kund baserat på deras köp under det senaste året (max år för datasetet). Utfärda en MERGE-frågasats till Apache Iceberg-tabellen med Athena för att fylla i värden för one_year_sales_aggregate funktion:
![]()
Skicka följande fråga för att validera det uppdaterade värdet för varje kunds totala utgifter under det senaste året:
![]()
Vi bestämmer oss för att lägga till ytterligare en funktion på ett befintligt Apache Iceberg-bord för att beräkna och lagra det genomsnittliga köpbeloppet under det senaste året av varje kund. Utfärda en ALTER-frågesats för att lägga till en ny kolumn i en befintlig tabell för funktion one_year_sales_average:
![]()
Innan du fyller i värdena för den här nya funktionen kan du ställa in standardvärdet för funktionen one_year_sales_average till 0.0. Använd samma Apache Iceberg-tabell på Athena, utfärda en UPDATE-frågesats för att fylla i värdet för den nya funktionen som 0.0:
![]()
Skicka följande fråga för att verifiera att det uppdaterade värdet för genomsnittliga utgifter för varje kund under det senaste året är inställt på 0.0:
![]()
Nu vill vi fylla i värdena för den nya funktionen one_year_sales_average i datasetet för att få det genomsnittliga inköpsbeloppet för varje kund baserat på deras inköp under det senaste året (max år för datasetet). Utfärda en MERGE-frågasats till den befintliga Apache Iceberg-tabellen på Athena med hjälp av Athena-motorn för att fylla i värden för funktionen one_year_sales_average:
![]()
Skicka följande fråga för att verifiera de uppdaterade värdena för genomsnittliga utgifter för varje kund:
![]()
När ytterligare datafunktioner har lagts till i datasetet fortsätter datavetare i allmänhet att träna ML-modeller och dra slutsatser med Amazon Sagemaker eller motsvarande verktygsuppsättning.
Slutsats
I det här inlägget demonstrerade vi hur man utför funktionsteknik med Athena med Apache Iceberg. Vi demonstrerade också att använda CTAS-frågan för att skapa en Apache Iceberg-tabell på Athena från en befintlig datauppsättning i Apache Parquet-format, lägga till nya funktioner i en befintlig Apache Iceberg-tabell på Athena med hjälp av ALTER-frågan och använda UPDATE och MERGE frågesatser för att uppdatera funktionsvärden för befintliga kolumner.
Vi uppmuntrar dig att använda CTAS-frågor för att skapa tabeller snabbt och effektivt, och använda MERGE-frågesatsen för att synkronisera tabeller i ett steg för att förenkla dataförberedelser och uppdateringsuppgifter när du transformerar funktionerna med Athena med Apache Iceberg. Om du har kommentarer eller feedback, vänligen lämna dem i kommentarsektionen.
Om författarna
![]() Vivek Gautam är en Data Architect med specialisering på datasjöar på AWS Professional Services. Han arbetar med företagskunder som bygger dataprodukter, analysplattformar och lösningar på AWS. När vi inte bygger och designar moderna dataplattformar är Vivek en matentusiast som också gillar att utforska nya resmål och åka på vandringar.
Vivek Gautam är en Data Architect med specialisering på datasjöar på AWS Professional Services. Han arbetar med företagskunder som bygger dataprodukter, analysplattformar och lösningar på AWS. När vi inte bygger och designar moderna dataplattformar är Vivek en matentusiast som också gillar att utforska nya resmål och åka på vandringar.
![]() Mikhail Vaynshteyn är en lösningsarkitekt med Amazon Web Services. Mikhail arbetar med kunder inom hälsovård och biovetenskap för att bygga lösningar som hjälper till att förbättra patienternas resultat. Mikhail är specialiserad på dataanalystjänster.
Mikhail Vaynshteyn är en lösningsarkitekt med Amazon Web Services. Mikhail arbetar med kunder inom hälsovård och biovetenskap för att bygga lösningar som hjälper till att förbättra patienternas resultat. Mikhail är specialiserad på dataanalystjänster.
![]() Naresh Gautam är en dataanalys- och AI/ML-ledare på AWS med 20 års erfarenhet, som tycker om att hjälpa kunder att bygga högt tillgänglig, högpresterande och kostnadseffektiv dataanalys och AI/ML-lösningar för att ge kunderna datadrivet beslutsfattande . På fritiden tycker han om att meditera och laga mat.
Naresh Gautam är en dataanalys- och AI/ML-ledare på AWS med 20 års erfarenhet, som tycker om att hjälpa kunder att bygga högt tillgänglig, högpresterande och kostnadseffektiv dataanalys och AI/ML-lösningar för att ge kunderna datadrivet beslutsfattande . På fritiden tycker han om att meditera och laga mat.
![]() Harsha Tadiparthi är specialist Principal Solutions Architect, Analytics på AWS. Han tycker om att lösa komplexa kundproblem i databaser och analyser och leverera framgångsrika resultat. Utanför jobbet älskar han att umgås med sin familj, titta på film och resa när det är möjligt.
Harsha Tadiparthi är specialist Principal Solutions Architect, Analytics på AWS. Han tycker om att lösa komplexa kundproblem i databaser och analyser och leverera framgångsrika resultat. Utanför jobbet älskar han att umgås med sin familj, titta på film och resa när det är möjligt.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- : har
- :är
- :inte
- :var
- $UPP
- 10
- 100
- 12
- 17
- 20
- 20 år
- 23
- 27
- 7
- a
- Om Oss
- accelerera
- tillgång
- åstadkommit
- Konto
- åtgärder
- lägga till
- lagt till
- tillsats
- Annat
- adress
- AI / ML
- också
- Även
- amason
- Amazonas Athena
- Amazon SageMaker
- Amazon Web Services
- mängd
- an
- Analytisk
- Analytisk
- analytics
- analysera
- analys
- och
- Annan
- vilken som helst
- Apache
- Apache Spark
- ÄR
- AS
- At
- tillgänglig
- genomsnitt
- undvika
- AWS
- AWS professionella tjänster
- baserat
- BE
- därför att
- varit
- Fördelarna
- SLUTRESULTAT
- Byggnad
- byggt
- by
- beräknat
- KAN
- kapacitet
- fall
- klassificering
- cloud
- samlingar
- Kolumn
- Kolonner
- kombinera
- kommentarer
- Gemensam
- komplex
- Compute
- dator
- Datorsyn
- konfiguration
- innehåller
- sammanhang
- konvertera
- kokning
- kopiering
- Korrigeringar
- kostnadseffektiv
- skapa
- skapas
- Skapa
- kund
- Kunder
- datum
- Data Analytics
- datasjö
- datavetenskap
- datavetare
- data driven
- Databas
- databaser
- datauppsättningar
- Datum
- beslutar
- Beslutsfattande
- djupare
- Standard
- leverera
- levererar
- demonstrera
- demonstreras
- design
- destinationer
- distribueras
- gör
- dubbla
- Drop
- hållbarhet
- varje
- lätt
- effektiv
- effektivt
- ansträngning
- antingen
- element
- ge
- möjliggöra
- uppmuntra
- Motor
- Teknik
- Motorer
- förbättrad
- Företag
- företagskunder
- entusiast
- Hela
- Motsvarande
- Eter (ETH)
- befintliga
- erfarenhet
- utforska
- extern
- falsk
- familj
- SNABB
- snabbare
- Leverans
- Funktioner
- återkoppling
- Filer
- Fokus
- följer
- efter
- livsmedelsproduktion
- För
- format
- ramar
- Fri
- från
- allmänhet
- genereras
- skaffa sig
- Go
- Grupp
- Hadoop
- Har
- he
- hälso-och sjukvård
- hjälpa
- hjälpa
- högpresterande
- höggradigt
- vandringar
- hans
- historiskt
- Bikupa
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- Identifiering
- identifiera
- if
- bilder
- förbättra
- in
- Inklusive
- Öka
- ineffektiv
- Infrastruktur
- Insert
- insikter
- istället
- instruktioner
- interaktiva
- in
- introducerade
- isolering
- fråga
- IT
- jpg
- json
- märkning
- sjö
- språk
- Large
- Efternamn
- Layout
- ledare
- LÄRA SIG
- inlärning
- Lämna
- livet
- Life Sciences
- livscykel
- BEGRÄNSA
- lokal
- läge
- älskar
- Maskinen
- maskininlärning
- göra
- GÖR
- hantera
- ledning
- förvaltar
- många
- marknad
- matchas
- max
- meningsfull
- Meditation
- nämnts
- Sammanfoga
- miljon
- saknas
- ML
- modell
- modeller
- Modern Konst
- modifiera
- mer
- Filmer
- namn
- Som heter
- nation
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Behöver
- behöver
- Nya
- ny funktion
- Nya funktioner
- nytt
- Nej
- antal
- of
- Ofta
- on
- ONE
- endast
- öppet
- öppen källkod
- drift
- Verksamhet
- or
- ordrar
- Övriga
- vår
- utfall
- utanför
- Tidigare
- Betala
- utföra
- prestanda
- telefon
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- snälla du
- placera
- möjlig
- Inlägg
- förbereda
- pris
- Principal
- problem
- process
- bearbetade
- bearbetning
- Produkter
- professionell
- ge
- inköp
- inköp
- syfte
- Python
- sökfrågor
- snabbt
- Raw
- rådata
- Läsa
- erkännande
- post
- register
- minska
- frigöra
- Obligatorisk
- resultera
- översyn
- RAD
- Körning
- rinnande
- sagemaker
- försäljning
- Samma
- Skala
- Vetenskap
- VETENSKAPER
- Forskare
- vetenskapsmän
- §
- Server
- service
- Tjänster
- in
- flera
- visas
- Visar
- liknande
- Enkelt
- förenklade
- förenkla
- enda
- So
- Lösningar
- Lösa
- Källor
- Gnista
- specialist
- specialiserat
- tal
- Taligenkänning
- spendera
- spent
- SQL
- standard
- .
- uttalanden
- Steg
- Steg
- förvaring
- lagra
- lagras
- effektivisera
- Sträng
- framgångsrik
- sådana
- stödja
- Stöder
- System
- bord
- uppgift
- uppgifter
- den där
- Smakämnen
- Sammanfogningen
- deras
- Dem
- sedan
- Där.
- Dessa
- detta
- tid
- tidsresor
- till
- topp
- Totalt
- Tåg
- Utbildning
- transaktion
- transaktion
- transformerad
- omvandla
- färdas
- Typ
- underliggande
- förståelse
- Uppdatering
- uppdaterad
- Uppdateringar
- uppgradera
- uppladdad
- användning
- med hjälp av
- vanligen
- BEKRÄFTA
- Värdefulla
- värde
- Värden
- olika
- verifiera
- version
- mycket
- via
- Video
- utsikt
- syn
- vill
- var
- Kolla på
- we
- webb
- webbservice
- były
- när
- närhelst
- som
- medan
- VEM
- med
- utan
- Arbete
- arbetsflöde
- arbetsgrupp
- arbetssätt
- fungerar
- skulle
- skriva
- år
- år
- dig
- Din
- zephyrnet
- Postnummer