In 2021 in 2020, smo vam povedali o novih funkcijah v Amazon RedShift ki omogočajo lažjo, hitrejšo in stroškovno učinkovitejšo analizo vseh vaših podatkov ter iskanje bogatih in močnih vpogledov. Leta 2022 z veseljem poročamo, da je ekipa Amazon Redshift trdo delala. Delali smo nazaj glede na zahteve strank in napovedali številne nove funkcije, da bi olajšali, hitreje in stroškovno učinkoviteje analizirali vse vaše podatke. Ta objava pokriva nekatere od teh novih funkcij.
Pri AWS je naša strategija za podatke in analitiko zagotoviti sodobna podatkovna arhitektura ki vam pomaga, da se osvobodite podatkovnih silosov; imeti namensko izdelane podatke, analitiko, strojno učenje (ML) in storitve umetne inteligence za uporabo pravega orodja za pravo delo; in imajo odprte, nadzorovane, varne in v celoti upravljane storitve, da je analitika na voljo vsem. Znotraj sodobne podatkovne arhitekture AWS ostaja Amazon Redshift kot skladišče podatkov v oblaku ključna komponenta, ki vam omogoča izvajanje kompleksne analitike SQL v velikem obsegu in zmogljivosti na terabajtih do petabajtih strukturiranih in nestrukturiranih podatkov ter omogoča široko dostopnost vpogledov prek priljubljene poslovne inteligence ( BI) in analitična orodja. Še naprej delamo nazaj glede na zahteve strank in leta 2022 smo uvedli več kot 40 funkcij v Amazon Redshift, da strankam pomagamo pri najboljših primerih uporabe skladiščenja podatkov, vključno z:
- Samopostrežna analitika
- Enostaven vnos podatkov
- Izmenjava podatkov in sodelovanje
- Znanost o podatkih in strojno učenje
- Varna in zanesljiva analitika
- Najboljša analiza cenovne uspešnosti
Potopimo se globlje in razpravljajmo o novih funkcijah Amazon Redshift na teh področjih.
Samopostrežna analitika
Stranke nam še naprej govorijo, da postajajo podatki in analitika vseprisotni in da vsi v njihovi organizaciji potrebujejo analitiko. Napovedali smo Amazon Redshift brez strežnika (v predogledu) v letu 2021, da bi olajšali izvajanje in prilagajanje analitike v nekaj sekundah, ne da bi bilo treba zagotoviti in upravljati infrastrukturo skladišča podatkov. Julija 2022 smo objavili splošna razpoložljivost Redshift Serverless, in od takrat ga je na tisoče strank, vključno s Peloton, Broadridge Financials in NextGen Healthcare, uporabilo za hitro in enostavno analizo svojih podatkov. Amazon Redshift Serverless samodejno zagotavlja in inteligentno prilagaja zmogljivost skladišča podatkov, da zagotovi visoko zmogljivost za vso vašo analitiko, vi pa plačate samo za računanje, uporabljeno v času trajanja delovnih obremenitev na osnovi na sekundo. Od GA smo dodali funkcije, kot je označevanje virov, poenostavljeno spremljanje in razpoložljivost v dodatnih regijah AWS za dodatno poenostavitev obračunavanja in razširitev dosega v več regijah po vsem svetu.
Leta 2021 smo predstavili Amazon Redshift Query Editor V2, ki je brezplačno spletno orodje za podatkovne analitike, podatkovne znanstvenike in razvijalce za raziskovanje, analiziranje in sodelovanje na podatkih v podatkovnih skladiščih in podatkovnih jezerih Amazon Redshift. Leta 2022 je urejevalnik poizvedb V2 dobil dodatne izboljšave, kot je npr podpora za prenosnike za izboljšano sodelovanje pri ustvarjanju, organiziranju in označevanju poizvedb; uporabniški dostop prek poverilnice ponudnika identitete (IdP). za enotno prijavo; in možnost hkratnega izvajanja več poizvedb za izboljšanje produktivnosti razvijalcev.
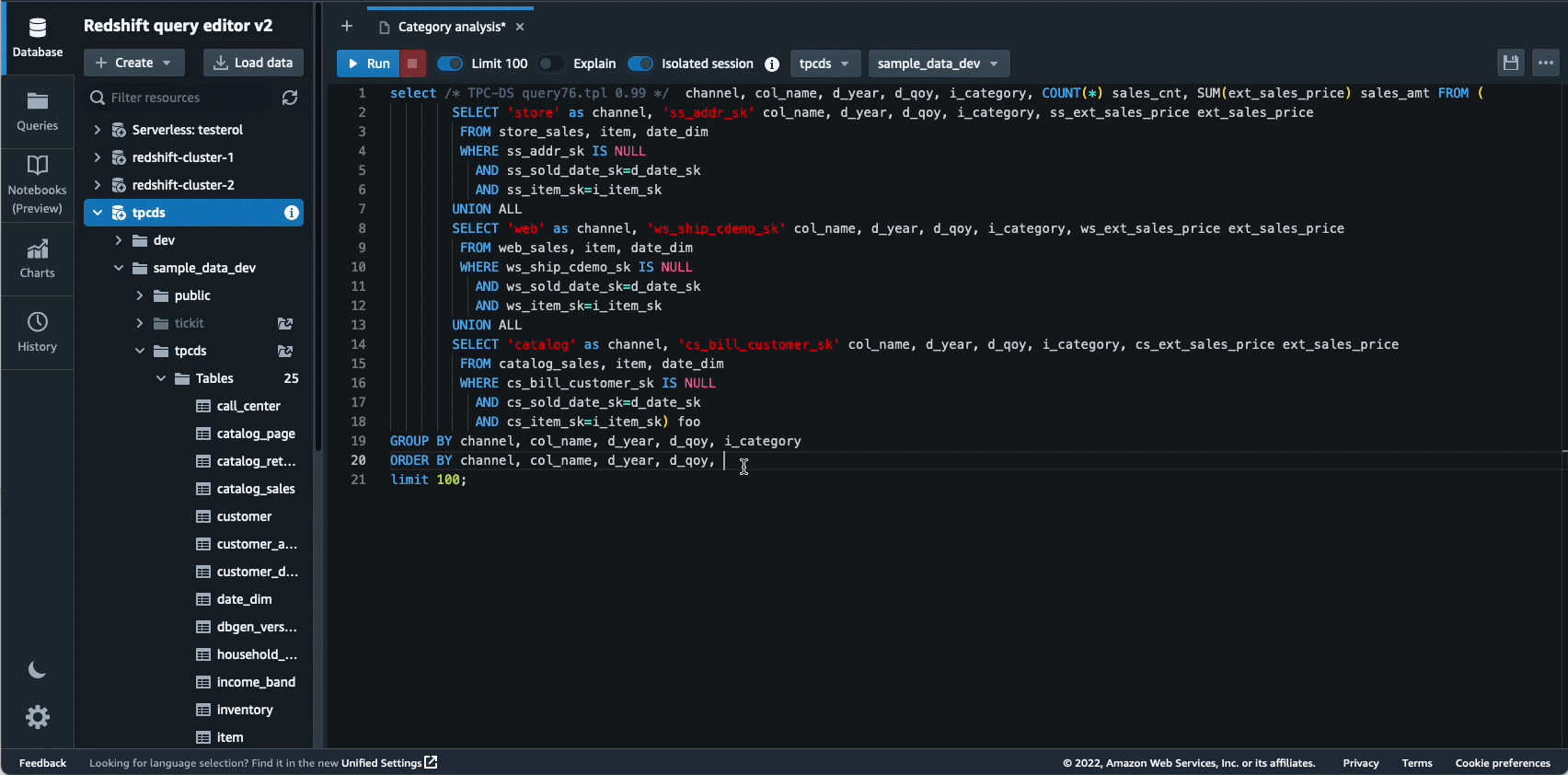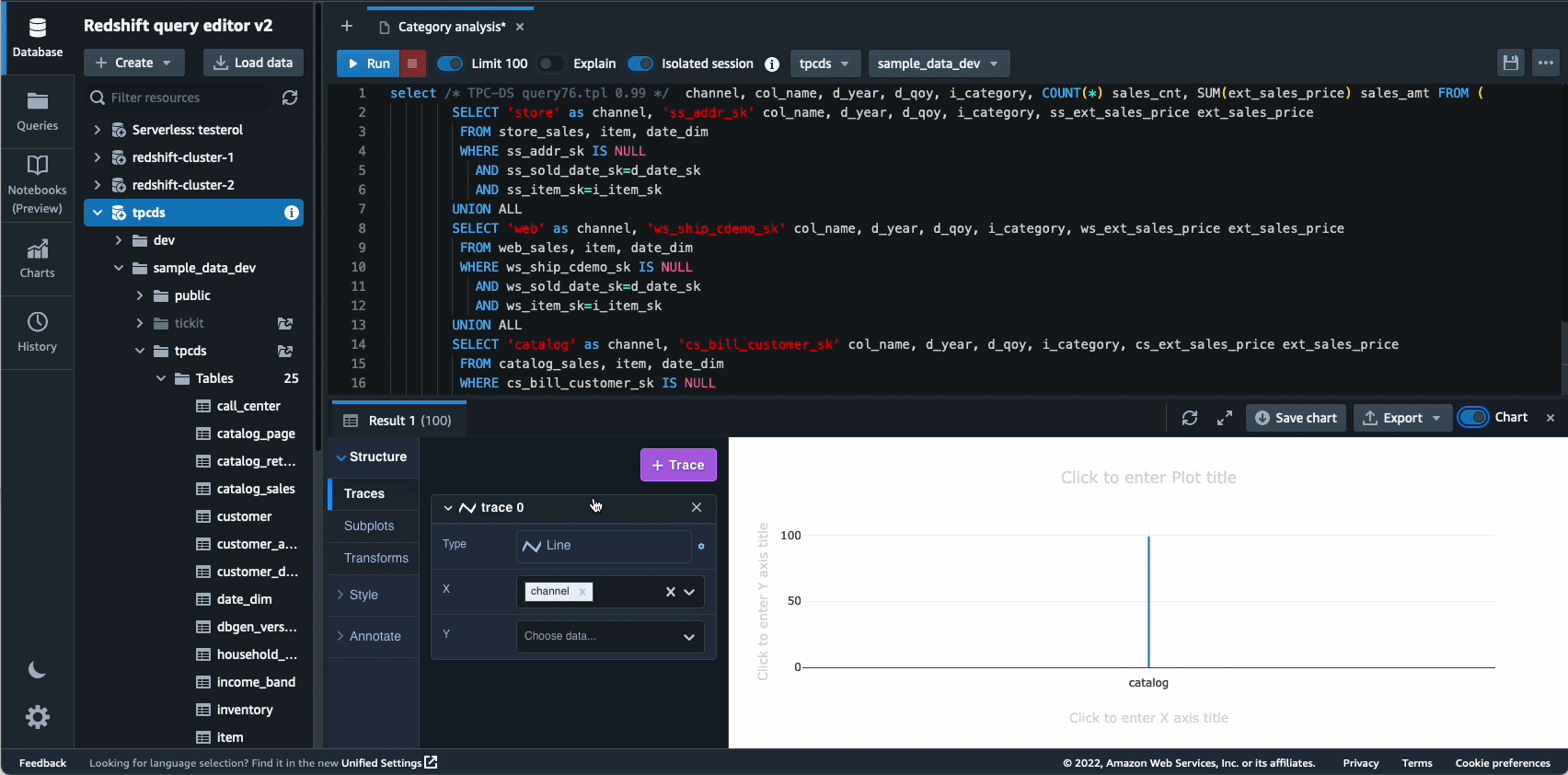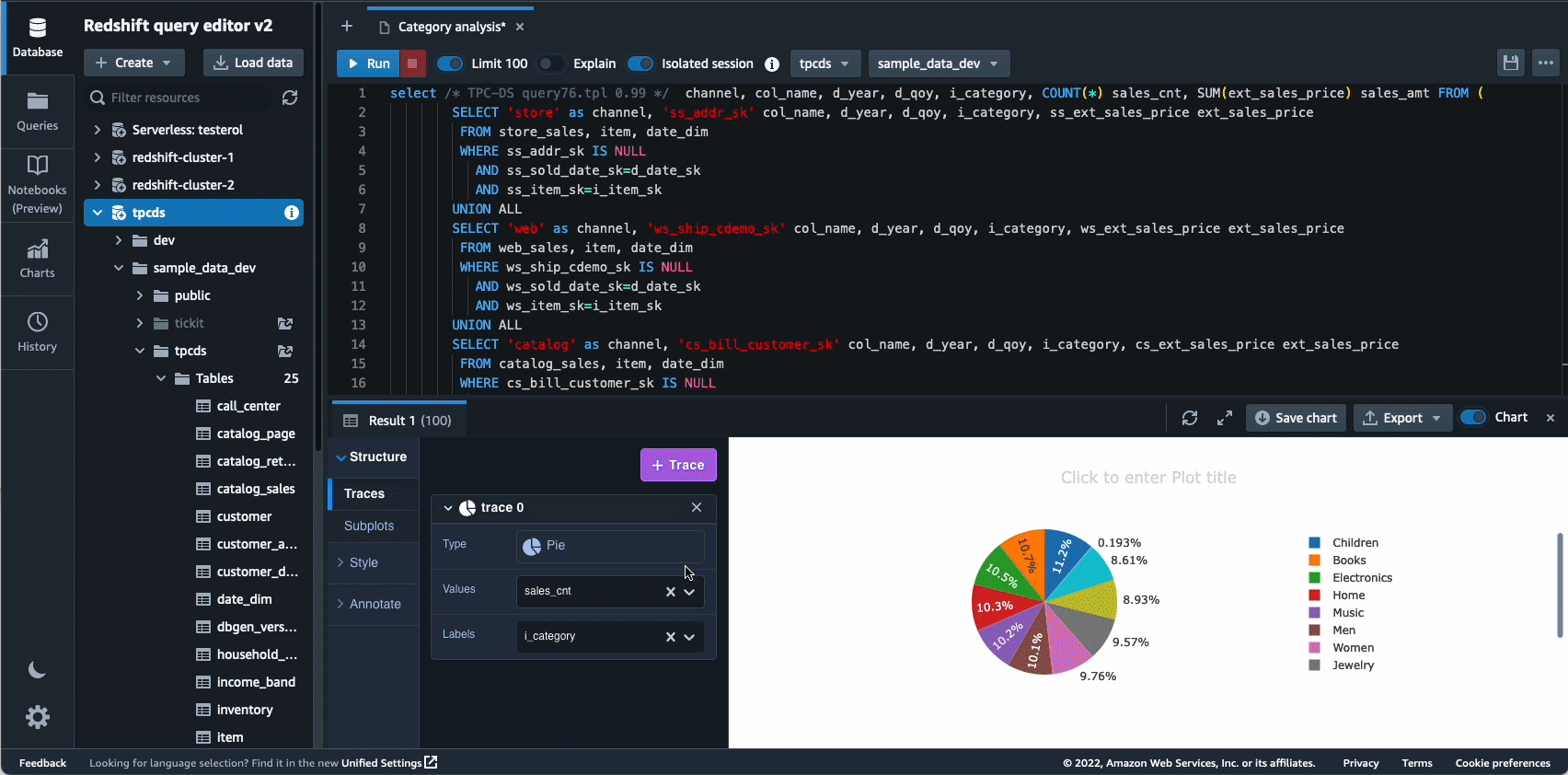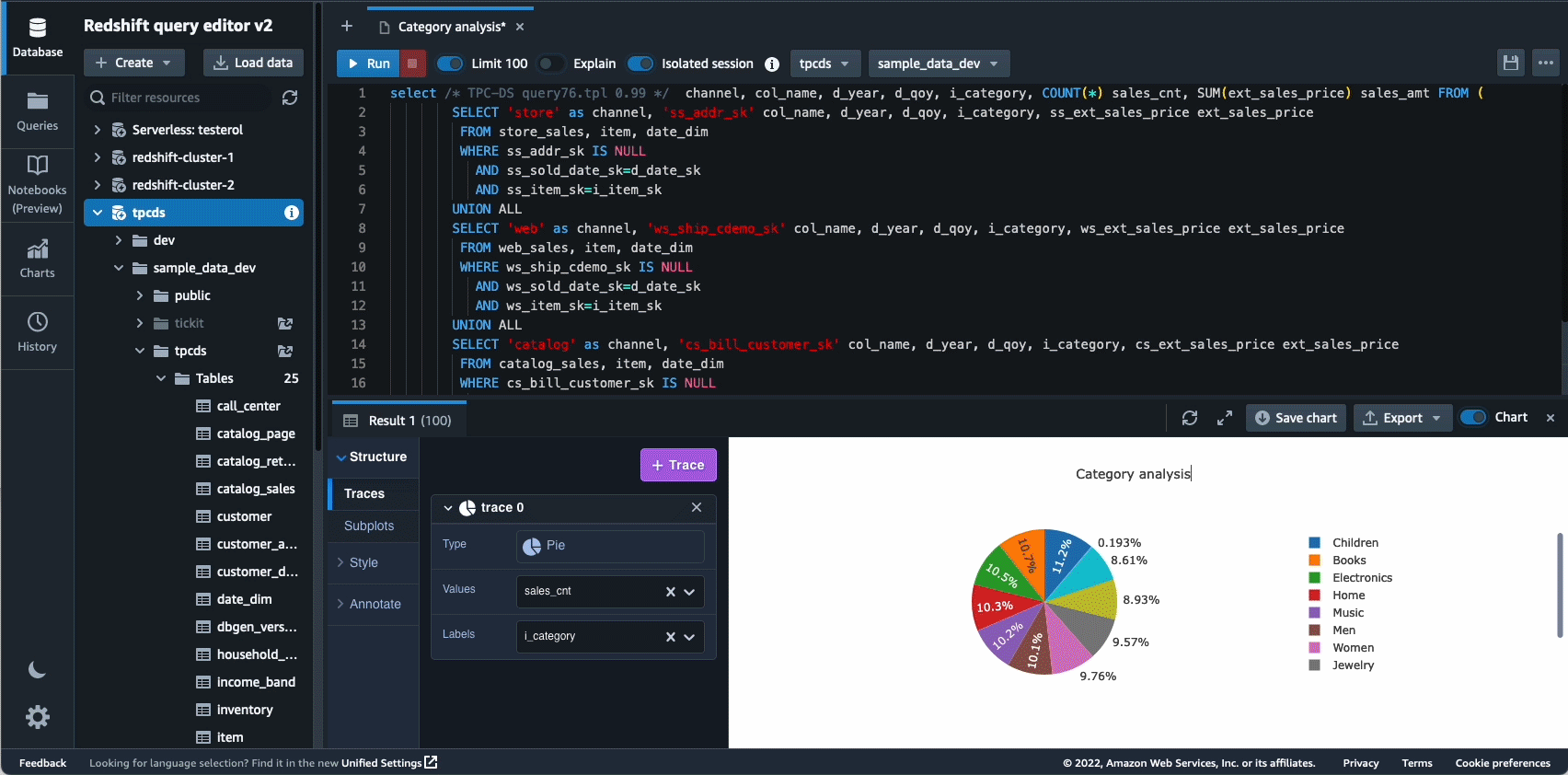
Avtonomija je še eno področje, kjer si aktivno prizadevamo za uporabo optimizacij, ki temeljijo na ML, in strankam ponuditi samoučeče in samooptimizirajoče podatkovno skladišče. Leta 2022 smo objavili splošno razpoložljivost za Avtomatizirani materializirani pogledi (AutoMVs) za izboljšanje zmogljivosti poizvedb (zmanjšanje skupnega časa izvajanja) brez napora uporabnika s samodejnim ustvarjanjem in vzdrževanjem materializiranih pogledov. AutoMVs je v kombinaciji s samodejnim osveževanjem, inkrementalnim osveževanjem in samodejnim prepisovanjem poizvedb za materializirane poglede omogočil, da materializirani pogledi ne potrebujejo vzdrževanja, kar vam samodejno omogoča hitrejše delovanje. Poleg tega je avtomatska optimizacija tabele (ATO) zmožnost optimizacije sheme in samodejno upravljanje delovne obremenitve (samodejni WLM) za optimizacijo delovne obremenitve je dobil dodatne izboljšave za boljšo zmogljivost poizvedb.
Enostaven vnos podatkov
Stranke nam povedo, da imajo svoje podatke porazdeljene po več virih podatkov, kot so transakcijske baze podatkov, podatkovna skladišča, podatkovna jezera in sistemi velikih podatkov. Želijo prilagodljivost za integracijo teh podatkov s podatkovnimi cevovodi brez kode/nizko kodo, nič ETL ali analizo teh podatkov na mestu, ne da bi jih premaknili. Stranke nam sporočajo, da so njihovi trenutni podatkovni cevovodi zapleteni, ročni, togi in počasni, kar povzroča nepopolne, nedosledne in zastarele poglede podatkov, kar omejuje vpoglede. Stranke so nas prosile za boljšo pot naprej in z veseljem oznanjamo številne nove zmogljivosti za poenostavitev in avtomatizacijo podatkovnih cevovodov.
Integracija Amazon Aurora zero-ETL z Amazon Redshift (predogled) vam omogoča izvajanje analitike in strojnega učenja v skoraj realnem času na petabajtih transakcijskih podatkov. Ponuja rešitev brez kode za izdelavo transakcijskih podatkov iz več Amazonska Aurora baze podatkov, ki so na voljo v podatkovnih skladiščih Amazon Redshift v nekaj sekundah po zapisu v Auroro, s čimer se odpravi potreba po gradnji in vzdrževanju zapletenih podatkovnih cevovodov. S to funkcijo lahko stranke Aurore dostopajo tudi do zmogljivosti Amazon Redshift, kot so kompleksna analitika SQL, vgrajeno ML, deljenje podatkov in zvezni dostop do več podatkovnih shramb in podatkovnih jezer. Ta funkcija je zdaj na voljo v predogledu za Izdaja, združljiva z Amazon Aurora MySQL različico 3 (z združljivostjo z MySQL 8.0) in lahko zahtevajte dostop do predogleda.
Amazon Redshift zdaj podpira samodejno kopiranje iz Amazon S3 (predogled) za poenostavitev nalaganja podatkov iz Preprosta storitev shranjevanja Amazon (Amazon S3) v Amazon Redshift. Zdaj lahko nastavite pravila neprekinjenega vnosa datotek (opravila kopiranja), da sledite svojim potem Amazon S3 in samodejno nalagate nove datoteke brez potrebe po dodatnih orodjih ali rešitvah po meri. Naloge kopiranja je mogoče spremljati prek sistemskih tabel, ki samodejno sledijo predhodno naloženim datotekam in jih izključijo iz postopka vnosa, da preprečijo podvajanje podatkov. Ta funkcija je zdaj na voljo v predogledu; to funkcijo lahko preizkusite tako, da ustvarite novo gručo s predogledno skladbo.
Stranke nam še naprej govorijo, da potrebujejo takojšnjo analitiko v realnem času, in z veseljem oznanjamo, splošna razpoložljivost podpore za pretakanje v Amazon Redshift za Amazonski kinezi podatkovni tokovi in Amazonovo pretakanje za Apache Kafka (Amazon MSK). Ta funkcija odpravlja potrebo po pripravi pretočnih podatkov v Amazon S3, preden jih vnesete v Amazon Redshift, kar vam omogoča, da dosežete nizko zakasnitev, merjeno v sekundah, medtem ko v vaša podatkovna skladišča vnašate stotine megabajtov pretočnih podatkov na sekundo. Uporabite lahko SQL znotraj Amazon Redshift, da se povežete in neposredno vnesete podatke iz več podatkovnih tokov Kinesis ali tem MSK, ustvarite samodejno osvežujoče materializirane poglede pretakanja s transformacijami na vrhu tokov neposredno za dostop do pretočnih podatkov in združite podatke v realnem času z zgodovinskimi podatke za boljši vpogled. Adobe je na primer integriral pretakanje Amazon Redshift kot del svoje platforme Adobe Experience Platform za zajem in analizo v realnem času spleta in aplikacij, klikov in podatkov o sejah za različne aplikacije, kot so CRM in aplikacije za podporo strankam.
Stranke so nam povedale, da želijo preprosto, takoj pripravljeno integracijo med orodji Amazon Redshift, BI in ETL (izvleček, transformacija in nalaganje) ter poslovnimi aplikacijami, kot sta Salesforce in Marketo. Z veseljem objavljamo splošno razpoložljivost Informatica Data Loader za Amazon Redshift, ki vam omogoča brezplačno uporabo Informatica Data Loader za hitro in veliko nalaganje podatkov v Amazon Redshift. Preprosto lahko izberete možnost Informatica Data Loader na konzoli Amazon Redshift. Ko ste v programu Informatica Data Loader, se lahko povežete z viri, kot sta Salesforce ali Marketo, izberete Amazon Redshift kot cilj in začnete nalagati svoje podatke.
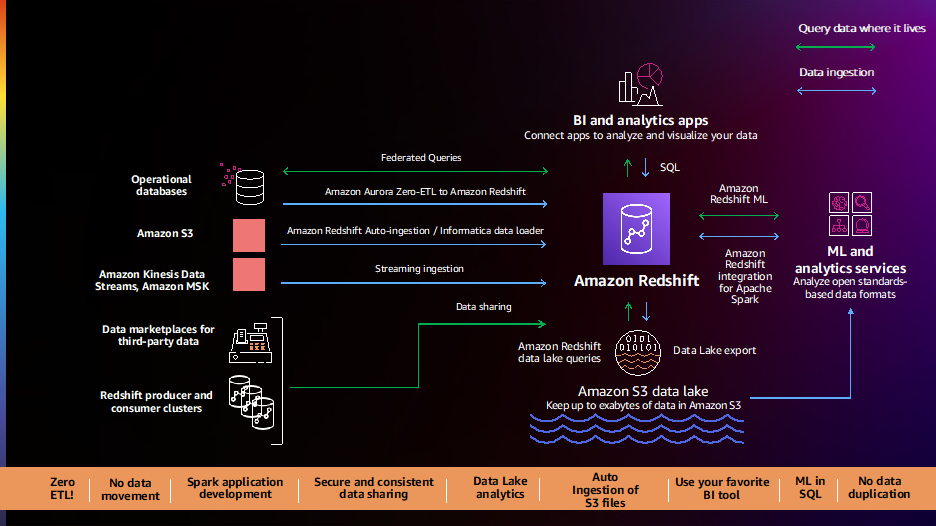
Izmenjava podatkov in sodelovanje
Stranke nam še naprej sporočajo, da želijo analizirati vse svoje podatke prvih in tretjih oseb ter dati bogate vpoglede, ki temeljijo na podatkih, na voljo svojim strankam, partnerjem in dobaviteljem. Leta 2021 smo lansirali nove funkcije, kot je npr Skupna raba podatkov in Integracija AWS Data Exchange, da boste lažje analizirali vse svoje podatke in jih delili znotraj in zunaj svojih organizacij.
Odličen primer stranke, ki uporablja izmenjavo podatkov, je Orion. Orion ponuja rešitve za podatke kot storitev (DaaS) v realnem času za stranke v industriji finančnih storitev, kot so ponudniki upravljanja premoženja, upravljanja sredstev in upravljanja naložb. Imajo več kot 2,500 podatkovnih virov, ki so predvsem baze podatkov SQL Server, nameščene tako v prostorih kot v AWS. Podatki se pretakajo prek povezovalnikov Kafka v Amazon Redshift. Imajo gručo proizvajalcev, ki prejme vse te podatke in nato uporablja skupno rabo podatkov za skupno rabo podatkov v realnem času za sodelovanje. To je arhitektura z več najemniki, ki služi več strankam. Glede na občutljivost njihovih podatkov je skupna raba podatkov način za zagotavljanje izolacije delovne obremenitve med gručami in tudi varno skupno rabo teh podatkov s končnimi uporabniki.
V letu 2022 smo nadaljevali z vlaganjem v to področje, da bi izboljšali zmogljivost, upravljanje in produktivnost razvijalcev z novimi funkcijami, ki omogočajo lažjo, enostavnejšo in hitrejšo skupno rabo podatkov in sodelovanje pri njih.
Ker stranke gradijo obsežne konfiguracije za skupno rabo podatkov, so zahtevale poenostavljeno upravljanje in varnost za podatke v skupni rabi, mi pa dodajamo centraliziran nadzor dostopa z AWS Lake Formation za skupno rabo podatkov Amazon Redshift, ki omogoča skupno rabo podatkov v živo v več skladiščih podatkov Amazon Redshift. S to funkcijo Amazon Redshift zdaj podpira poenostavljeno upravljanje skupne rabe podatkov Amazon Redshift z uporabo Oblikovanje jezera AWS kot eno samo steklo za centralno upravljanje podatkov ali dovoljenj za skupno rabo podatkov. Ogledate si lahko, spremenite in nadzirate dovoljenja, vključno z varnostjo na ravni vrstic in stolpcev v tabelah in pogledih v skupni rabi podatkov Amazon Redshift, z API-ji Lake Formation in Konzola za upravljanje AWS, in omogočite odkrivanje in uporabo skupnih podatkovnih zbirk Amazon Redshift v drugih podatkovnih skladiščih Amazon Redshift.
Znanost o podatkih in strojno učenje
Stranke nam še naprej sporočajo, da želijo, da jim njihovi podatkovni in analitični sistemi pomagajo odgovoriti na številna vprašanja, od tega, kaj se dogaja v njihovem podjetju (opisna analitika) do tega, zakaj se dogaja (diagnostična analitika) in kaj se bo zgodilo v prihodnosti. (prediktivna analitika). Amazon Redshift ponuja funkcije, kot so kompleksna analitika SQL, analitika podatkovnega jezera in Amazon Redshift ML za stranke, da analizirajo svoje podatke in odkrijejo močne vpoglede. Rdeči premik ML integrira Amazon Redshift z Amazon SageMaker, popolnoma upravljana storitev ML, ki vam omogoča ustvarjanje, usposabljanje in uvajanje modelov ML z uporabo znanih ukazov SQL.
Stranke so nas prosile tudi za boljšo integracijo med Amazon Redshift in Apache Spark, zato z veseljem sporočamo Integracija Amazon Redshift za Apache Spark omogočiti enostaven dostop do podatkovnih skladišč za aplikacije, ki temeljijo na Spark. Zdaj razvijalci, ki uporabljajo analitiko AWS in storitve ML, kot je npr Amazonski EMR, AWS lepilo, SageMaker pa lahko brez truda zgradi aplikacije Apache Spark, ki berejo in pišejo v njihovih podatkovnih skladiščih Amazon Redshift. Amazon EMR in AWS Glue sta opremljena s priključkom Redshift-Spark, tako da se lahko preprosto povežete s svojim skladiščem podatkov iz aplikacij, ki temeljijo na Sparku. Uporabite lahko več zmožnosti potiskanja navzdol za operacije, kot so razvrščanje, združevanje, omejitev, združevanje in skalarne funkcije, tako da se samo ustrezni podatki premaknejo iz vašega podatkovnega skladišča Amazon Redshift v porabniško aplikacijo Spark. Svoje aplikacije lahko tudi naredite bolj varne z uporabo AWS upravljanje identitete in dostopa (IAM) poverilnice za povezavo z Amazon Redshift.
Varna in zanesljiva analitika
Stranke nam še naprej govorijo, da so njihova podatkovna skladišča kritični sistemi, ki potrebujejo visoko razpoložljivost, zanesljivost in varnost. Leta 2022 smo na tem področju predstavili številne nove funkcije.
Amazon Redshift zdaj podpira Razmestitve v več AZ (v predogledu) za gruče, ki temeljijo na instancah RA3, kar omogoča istočasno delovanje vašega podatkovnega skladišča v več območjih razpoložljivosti AWS in neprekinjeno delovanje v nepredvidenih scenarijih napak v celotnem območju razpoložljivosti. Podpora za več AZ je že na voljo za Redshift Serverless. Uvedba Amazon Redshift Multi-AZ vam omogoča obnovitev v primeru napak Availability Zone brez posredovanja uporabnika. Do podatkovnega skladišča Amazon Redshift Multi-AZ se dostopa kot do enega samega podatkovnega skladišča z eno končno točko in vam pomaga povečati zmogljivost s samodejno porazdelitvijo obdelave delovne obremenitve na več območij razpoložljivosti. Za ohranitev neprekinjenega poslovanja med nepredvidenimi izpadi niso potrebne spremembe aplikacije.
Leta 2022 smo uvedli funkcije, kot so nadzor dostopa na podlagi vlog, varnost na ravni vrstic in maskiranje podatkov (v predogledu), da vam olajšamo upravljanje dostopa in odločanje o tem, kdo ima dostop do katerih podatkov, vključno z zamegljevanjem osebnih podatkov (PII). ), kot so številke kreditnih kartic.
Lahko uporabite nadzor dostopa na podlagi vlog (RBAC) za nadzor dostopa končnega uporabnika do podatkov na široki ali razdrobljeni ravni glede na delovno vlogo in dovoljenja končnega uporabnika. Z RBAC lahko ustvarite vlogo z uporabo SQL, vlogi dodelite zbirko podrobnih dovoljenj in nato to vlogo dodelite končnim uporabnikom. Vlogam je mogoče dodeliti dovoljenja na ravni objekta, na ravni stolpca in na ravni sistema. Poleg tega RBAC uvaja vnaprej pripravljene sistemske vloge za skrbnike baze podatkov, operaterje, varnostne skrbnike ali prilagojene vloge.
Varnost na ravni vrstice (RLS) poenostavi načrtovanje in izvedbo natančnega dostopa do vrstic v tabelah. Z RLS lahko omejite dostop do podmnožice vrstic v tabeli na podlagi delovne vloge uporabnikov ali dovoljenj s SQL.
Podpora za Amazon Redshift dinamično maskiranje podatkov (DDM), ki je zdaj na voljo v predogledu, vam omogoča poenostavitev zaščite PII, kot so številke socialnega zavarovanja, številke kreditnih kartic in telefonske številke v vašem podatkovnem skladišču Amazon Redshift. Z dinamičnim maskiranjem podatkov nadzirate dostop do svojih podatkov prek preprostih politik maskiranja, ki temeljijo na SQL in določajo, kako Amazon Redshift vrne občutljive podatke uporabniku v času poizvedbe. Ustvarite lahko pravilnike maskiranja, da definirate konsistentne vrednosti maskiranih podatkov, ki ohranjajo format, in nepreklicne. Politiko maskiranja lahko uporabite za določen stolpec ali seznam stolpcev v tabeli. Prav tako imate prilagodljivost pri izbiri načina prikaza zamaskiranih podatkov. Podatke lahko na primer popolnoma skrijete, zamenjate delne dejanske vrednosti z nadomestnimi znaki ali določite svoj način maskiranja podatkov z izrazi SQL, Python ali AWS Lambda uporabniško definirane funkcije. Poleg tega lahko uporabite pravilnik pogojnega maskiranja na podlagi drugih stolpcev, ki selektivno ščiti podatke stolpca v tabeli na podlagi vrednosti v enem ali več različnih stolpcih.
Napovedali smo tudi izboljšave za revizijsko beleženje, domača integracija z Microsoft Azure Active Directoryin podporo za privzete vloge IAM v dodatnih regijah za dodatno poenostavitev upravljanja varnosti.
Najboljša analiza cenovne uspešnosti
Stranke nam še naprej govorijo, da potrebujejo hitra in stroškovno učinkovita podatkovna skladišča, ki zagotavljajo visoko zmogljivost v katerem koli obsegu, hkrati pa ohranjajo nizke stroške. Od 1. dne od Predstavitev Amazon Redshift leta 2012, smo izbrali pristop, ki temelji na podatkih, in uporabili telemetrijo voznega parka za izgradnjo storitve skladiščenja podatkov v oblaku, ki vam nudi najboljšo cenovno zmogljivost v katerem koli obsegu. Z leti smo se razvijali Arhitektura Amazon Redshift in predstavil funkcije, kot je Redshift Managed Storage (RMS) za ločevanje shranjevanja in računalništva, Amazonov rdeči premik spektra za poizvedbe podatkovnega jezera, avtomatska optimizacija tabele za optimizacijo fizične sheme, samodejno upravljanje delovne obremenitve za določanje prioritet delovnih obremenitev in dodelitev pravega računalništva in pomnilnika, spreminjanje velikosti gruče za navpično prilagajanje računalništva in shranjevanja ter skaliranje sočasnosti za dinamično povečevanje računalništva. Naš merila uspešnosti še naprej dokazuje vodilni položaj Amazon Redshift v cenovni uspešnosti.
Leta 2022 smo dodali nove funkcije, kot je splošna razpoložljivost skaliranje sočasnosti za pisalne operacije kot so COPY, INSERT, UPDATE in DELETE za podporo skoraj neomejenemu hkratnemu številu uporabnikov in poizvedb. Uvedli smo tudi izboljšave zmogljivosti za obdelavo podatkov na podlagi nizov z vektoriziranimi pregledi nad lahkimi, CPE-učinkovitimi stolpci nizov, kodiranih s slovarjem, kar omogoča mehanizmu baze podatkov, da deluje neposredno nad stisnjenimi podatki.
Dodali smo tudi podporo za operaterje SQL, kot je npr MERGE (en operater za vstavke ali posodobitve); CONNECY_BY (za hierarhične poizvedbe); ZDRUŽEVANJE SKUPOV, ROLLUP in CUBE (za večdimenzionalno poročanje); in povečali velikost podatkovnega tipa SUPER na 16 MB, da vam olajšajo selitev iz podedovanih podatkovnih skladišč na Amazon Redshift.
zaključek
Naše stranke nam še naprej govorijo, da podatki in analitika zanje ostajajo glavna prednostna naloga in da je potreba po stroškovno učinkovitem pridobivanju več poslovne vrednosti iz njihovih podatkov v teh časih bolj izrazita kot kadar koli v preteklosti. Amazon Redshift kot vaše skladišče podatkov v oblaku vam omogoča zagon kompleksne analitike SQL z obsegom in zmogljivostjo na terabajtih do petabajtih strukturiranih in nestrukturiranih podatkov ter omogoča široko dostopnost vpogledov prek priljubljenih orodij za poslovno inteligenco in analitičnih orodij.
Čeprav smo leta 40 uvedli več kot 2022 funkcij in se hitrost inovacij še naprej pospešuje, ostaja dan 1 in veselimo se vašega odgovora o tem, kako vam te funkcije pomagajo odkleniti večjo vrednost za vaše organizacije. Vabimo vas, da preizkusite te nove funkcije in stopite v stik z nami prek skupine za račun AWS, če imate dodatne pripombe.
O avtorju
 Manan Goel je vodja produktov na trgu za analitične storitve AWS, vključno z Amazon Redshift pri AWS. Ima več kot 25 let izkušenj in dobro pozna baze podatkov, skladiščenje podatkov, poslovno inteligenco in analitiko. Manan ima MBA z univerze Duke in diplomo iz elektronike in komunikacijskega inženirstva.
Manan Goel je vodja produktov na trgu za analitične storitve AWS, vključno z Amazon Redshift pri AWS. Ima več kot 25 let izkušenj in dobro pozna baze podatkov, skladiščenje podatkov, poslovno inteligenco in analitiko. Manan ima MBA z univerze Duke in diplomo iz elektronike in komunikacijskega inženirstva.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- sposobnost
- O meni
- pospeši
- dostop
- Dostop do podatkov
- dostopna
- dostopen
- Račun
- Doseči
- čez
- aktivna
- aktivno
- dodano
- Poleg tega
- Dodatne
- Poleg tega
- Adobe
- vsi
- omogoča
- že
- Amazon
- Amazonski EMR
- Analitiki
- analitika
- analizirati
- analiziranje
- in
- Objavi
- razglasitve
- Še ena
- odgovor
- Apache
- Apache Spark
- API-ji
- uporaba
- aplikacije
- Uporabi
- pristop
- Arhitektura
- OBMOČJE
- območja
- umetni
- Umetna inteligenca
- sredstvo
- upravljanje premoženja
- Revizija
- aurora
- Avtor
- avto
- avtomatizirati
- Samodejno
- samodejno
- razpoložljivost
- Na voljo
- AWS
- AWS lepilo
- Azure
- temeljijo
- Osnova
- postajajo
- pred
- počutje
- BEST
- Boljše
- med
- Big
- Big Podatki
- zaračunavanje
- Break
- široka
- Broadridge
- izgradnjo
- Building
- vgrajeno
- poslovni
- Poslovne aplikacije
- kontinuiteta poslovanja
- Poslovna inteligenca
- Zmogljivosti
- kapaciteta
- kartice
- primeru
- primeri
- Spremembe
- znaki
- Izberite
- izbiri
- stranke
- Cloud
- Grozd
- sodelovati
- sodelovanje
- zbirka
- Stolpec
- Stolpci
- združujejo
- kombinirani
- komentarji
- Communications
- združljivost
- popolnoma
- kompleksna
- komponenta
- Izračunajte
- sočasno
- Connect
- dosledno
- Konzole
- porabi
- naprej
- naprej
- se nadaljuje
- neprekinjeno
- nadzor
- stroškovno učinkovito
- stroški
- prevleke
- ustvarjajo
- Ustvarjanje
- Mandatno
- kredit
- kreditne kartice
- krediti
- CRM
- Trenutna
- po meri
- stranka
- Pomoč strankam
- Stranke, ki so
- meri
- datum
- Izmenjava podatkov
- Data jezero
- obdelava podatkov
- izmenjavo podatkov
- podatkovno skladišče
- skladišča podatkov
- Podatkov usmerjenih
- Baze podatkov
- baze podatkov
- dan
- globlje
- poda
- izkazati
- razporedi
- uvajanje
- Oblikovanje
- Ugotovite,
- Razvojni
- Razvijalci
- drugačen
- neposredno
- odkriti
- odkril
- razpravlja
- porazdeljena
- distribucijo
- Duke
- vojvodska univerza
- med
- dinamično
- lažje
- enostavno
- urednik
- prizadevanje
- Elektronika
- odpravlja
- odstranjevanje
- omogočajo
- omogoča
- omogočanje
- Končna točka
- Motor
- Inženiring
- Eter (ETH)
- vsi
- razvil
- Primer
- Izmenjava
- razburjen
- Razširi
- izkušnje
- raziskuje
- izrazi
- ekstrakt
- Napaka
- seznanjeni
- FAST
- hitreje
- Feature
- Lastnosti
- file
- datoteke
- finančna
- finančne storitve
- financ
- Najdi
- FLET
- prilagodljivost
- Oblikovanje
- Naprej
- brezplačno
- iz
- v celoti
- funkcije
- nadalje
- Prihodnost
- splošno
- dobili
- gif
- Daj
- dana
- daje
- Giving
- steklo
- Pojdi na trg
- upravljanje
- odobri
- odobreno
- veliko
- se zgodi
- srečna
- Trdi
- ob
- zdravstveno varstvo
- sluha
- pomoč
- Pomaga
- Skrij
- visoka
- zgodovinski
- drži
- Kako
- Kako
- HTML
- HTTPS
- Stotine
- IAM
- identiteta
- Izvajanje
- izboljšanje
- izboljšalo
- Izboljšave
- in
- Vključno
- povečal
- Industrija
- Podatki
- Infrastruktura
- Inovacije
- Vložki
- vpogledi
- integrirati
- integrirana
- Integrira
- integracija
- Intelligence
- intervencije
- Uvedeno
- Predstavlja
- Invest
- naložbe
- povabi
- izolacija
- IT
- Job
- Delovna mesta
- pridružite
- julij
- kafka
- Imejte
- vzdrževanje
- Ključne
- Podatkovni tokovi Kinesis
- Jezero
- obsežne
- Latenca
- kosilo
- začela
- Vodja
- Vodstvo
- učenje
- Legacy
- Stopnja
- lahek
- LIMIT
- Seznam
- v živo
- podatki v živo
- obremenitev
- nakladač
- nalaganje
- Poglej
- nizka
- stroj
- strojno učenje
- je
- vzdrževati
- vzdrževanje
- Znamka
- Izdelava
- upravljanje
- upravlja
- upravljanje
- Navodilo
- Marketo
- Maska
- Povečajte
- Spomin
- selitev
- ML
- modeli
- sodobna
- spremenite
- spremljati
- spremljanje
- več
- premikanje
- več
- MySQL
- materni
- Nimate
- potrebna
- potrebe
- Novo
- Nove funkcije
- Številka
- številke
- Ponudbe
- ONE
- odprite
- deluje
- Delovanje
- operacije
- operater
- operaterji
- optimizacija
- Možnost
- Organizacija
- organizacije
- Ostalo
- Izpusti
- zunaj
- lastne
- Pace
- paket
- podokno
- del
- partnerji
- preteklosti
- Plačajte
- peloton
- performance
- Dovoljenja
- Osebno
- telefon
- fizično
- pii
- Kraj
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- zadovoljen
- politike
- politika
- Popular
- Prispevek
- močan
- Napovedna analiza
- preprečiti
- predogled
- prej
- Cena
- v prvi vrsti
- Prednost
- prednostna naloga
- Postopek
- obravnavati
- Proizvajalec
- Izdelek
- produktivnost
- zaščito
- zagotavljajo
- Ponudnik
- ponudniki
- zagotavlja
- zagotavljanje
- Python
- vprašanja
- hitro
- območje
- dosežejo
- Preberi
- pravo
- v realnem času
- podatki v realnem času
- prejme
- Obnovi
- zmanjša
- regije
- pomembno
- zanesljivost
- zanesljiv
- ostanki
- zamenjajte
- poročilo
- Poročanje
- Zahteve
- omejiti
- rezultat
- vrne
- pregleda
- prepisovanje
- Rich
- toga
- vloga
- vloge
- zavihamo
- pravila
- Run
- tek
- sagemaker
- prodajni center
- Lestvica
- luske
- skaliranje
- scenariji
- Znanost
- Znanstveniki
- drugi
- sekund
- zavarovanje
- Varno
- varnost
- občutljiva
- občutljivost
- Brez strežnika
- služi
- Storitev
- Storitve
- Zasedanje
- nastavite
- Kompleti
- več
- Delite s prijatelji, znanci, družino in partnerji :-)
- deli
- delitev
- Prikaži
- Enostavno
- poenostavljeno
- poenostavitev
- preprosto
- hkrati
- saj
- sam
- Sedenje
- Velikosti
- počasi
- So
- socialna
- Rešitev
- rešitve
- nekaj
- Viri
- Spark
- specifična
- SQL
- Stage
- shranjevanje
- trgovine
- Strategija
- pretočenih
- pretakanje
- tokovi
- strukturirano
- strukturirani in nestrukturirani podatki
- taka
- Super
- dobavitelji
- podpora
- Podpira
- sistem
- sistemi
- miza
- ciljna
- skupina
- O
- Prihodnost
- njihove
- tretjih oseb
- tisoče
- skozi
- čas
- krat
- do
- orodje
- orodja
- vrh
- Teme
- Skupaj za plačilo
- na dotik
- sledenje
- Vlak
- transakcijski
- Transform
- transformacije
- povsod
- nepredviden
- univerza
- neomejeno
- odklepanje
- Nadgradnja
- posodobitve
- us
- uporaba
- uporabnik
- Uporabniki
- Uporaben
- vrednost
- Vrednote
- različnih
- različica
- Poglej
- ogledov
- praktično
- Skladišče
- skladiščenje
- Wealth
- upravljanje premoženja
- web
- Web-Based
- Kaj
- Kaj je
- ki
- medtem
- WHO
- široka
- Širok spekter
- pogosto
- bo
- v
- brez
- delo
- delal
- deluje
- po vsem svetu
- pisati
- pisni
- leto
- let
- Vaša rutina za
- zefirnet
- cone