AWS Glue Studio je grafični vmesnik, ki olajša ustvarjanje, izvajanje in spremljanje opravil ekstrahiranja, preoblikovanja in nalaganja (ETL) v AWS lepilo. Omogoča vam vizualno sestavljanje delovnih tokov preoblikovanja podatkov z uporabo vozlišč, ki predstavljajo različne korake za obdelavo podatkov, ki se pozneje samodejno pretvorijo v kodo za izvajanje.
AWS Glue Studio pred kratkim izdal Še 10 vizualnih transformacij, ki omogočajo ustvarjanje naprednejših delovnih mest na vizualni način brez spretnosti kodiranja. V tej objavi razpravljamo o možnih primerih uporabe, ki odražajo običajne potrebe ETL.
Nove transformacije, ki bodo prikazane v tej objavi, so: združevanje, razdelitev niza, matrika v stolpce, dodajanje trenutnega časovnega žiga, zasukanje vrstic v stolpce, razveljavitev zasuka stolpcev v vrstice, iskanje, razstrelitev matrike ali preslikava v stolpce, izpeljani stolpec in obdelava samodejnega uravnavanja .
Pregled rešitev
V tem primeru uporabe imamo nekaj datotek JSON z operacijami delniških opcij. Pred shranjevanjem podatkov želimo narediti nekaj transformacij, da jih bomo lažje analizirali, poleg tega pa želimo ustvariti ločen povzetek nabora podatkov.
V tem naboru podatkov vsaka vrstica predstavlja trgovanje opcijskih pogodb. Opcije so finančni instrumenti, ki zagotavljajo pravico – vendar ne obveznosti – do nakupa ali prodaje delnic po fiksni ceni (imenovani cena stavke) pred določenim datumom poteka.
Vhodni podatki
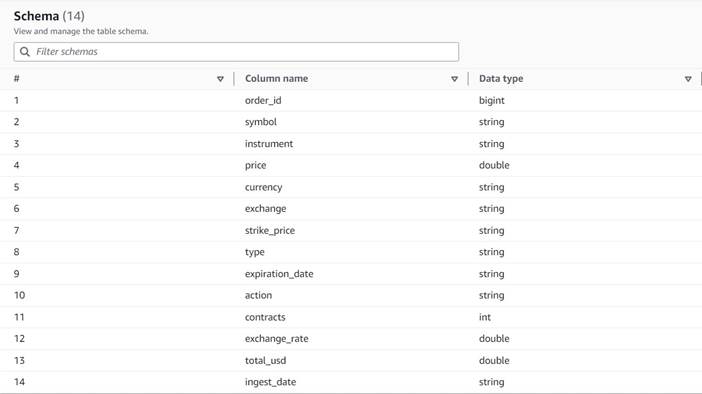
Podatki sledijo naslednji shemi:
- Številka naročila – Edinstven ID
- Simbol – Koda, ki običajno temelji na nekaj črkah za identifikacijo korporacije, ki izda osnovne delnice
- instrument – Ime, ki označuje določeno možnost, ki se kupuje ali prodaja
- valuta – Koda valute ISO, v kateri je izražena cena
- Cena – Znesek, ki je bil plačan za nakup vsake opcijske pogodbe (na večini borz ena pogodba omogoča nakup ali prodajo 100 delniških delnic)
- Izmenjava – Koda borznega središča ali mesta, kjer se je trgovalo z opcijo
- prodaja – Seznam števila pogodb, ki so bile dodeljene za izpolnitev prodajnega naročila, ko je to prodajna trgovina
- Kupil – Seznam števila pogodb, ki so bile dodeljene za izpolnitev nakupnega naročila, ko gre za nakupno trgovanje
Sledi vzorec sintetičnih podatkov, ustvarjenih za to objavo:
Zahteve ETL
Ti podatki imajo številne edinstvene lastnosti, kot jih pogosto najdemo v starejših sistemih, zaradi katerih je težje uporabiti podatke.
Zahteve ETL so naslednje:
- Ime instrumenta vsebuje dragocene informacije, ki so namenjene razumevanju ljudi; želimo ga normalizirati v ločene stolpce za lažjo analizo.
- Atributi
boughtinsoldse med seboj izključujejo; lahko jih združimo v en sam stolpec s številkami pogodb in imamo še en stolpec, ki označuje, ali so bile pogodbe kupljene ali prodane v tem vrstnem redu. - Podatke o dodelitvah posameznih pogodb želimo obdržati, vendar kot posamezne vrstice, namesto da bi uporabnike silili, da se ukvarjajo z nizom številk. Lahko bi sešteli številke, vendar bi izgubili informacijo o tem, kako je bilo naročilo izpolnjeno (kar kaže na likvidnost trga). Namesto tega se odločimo za denormalizacijo tabele, tako da ima vsaka vrstica eno samo število pogodb, pri čemer naročila z več številkami razdelimo v ločene vrstice. V stisnjenem stolpčnem formatu je dodatna velikost nabora podatkov tega ponavljanja pogosto majhna, ko je uporabljeno stiskanje, zato je sprejemljivo, da je nabor podatkov lažji za poizvedovanje.
- Ustvariti želimo zbirno tabelo obsega za vsako vrsto opcije (call in put) za vsako delnico. To je pokazatelj razpoloženja trga za vsako delnico in trg na splošno (pohlep proti strahu).
- Da bi omogočili splošne trgovinske povzetke, želimo za vsako operacijo zagotoviti skupno vsoto in standardizirati valuto v ameriške dolarje z uporabo približne reference pretvorbe.
- Želimo dodati datum, ko so se te preobrazbe zgodile. To bi lahko bilo koristno na primer za sklic na to, kdaj je bila izvedena pretvorba valute.
Na podlagi teh zahtev bo opravilo ustvarilo dva rezultata:
- Datoteka CSV s povzetkom števila pogodb za vsak simbol in vrsto
- Kataloška tabela za vodenje zgodovine naročil po izvedbi navedenih transformacij
Predpogoji
Za ta primer uporabe boste potrebovali lastno vedro S3. Če želite ustvariti novo vedro, glejte Ustvarjanje vedra.
Ustvari sintetične podatke
Če želite slediti tej objavi (ali sami eksperimentirati s to vrsto podatkov), lahko sintetično ustvarite ta nabor podatkov. Naslednji skript Python je mogoče izvajati v okolju Python z nameščenim Boto3 in dostopom do njega Preprosta storitev shranjevanja Amazon (Amazon S3).
Če želite ustvariti podatke, izvedite naslednje korake:
- V AWS Glue Studio ustvarite novo opravilo z možnostjo Urejevalnik skriptov lupine Python.
- Poimenujte delo in na Podrobnosti o delovnem mestu zavihek izberite a primerno vlogo in ime za skript Python.
- v Podrobnosti o delovnem mestu razdelek, razširi Napredne lastnosti in se pomaknite navzdol do Parametri delovnega mesta.
- Vnesite parameter z imenom
--bucketin kot vrednost dodelite ime vedra, ki ga želite uporabiti za shranjevanje vzorčnih podatkov. - Vnesite naslednji skript v urejevalnik lupine AWS Glue:
- Zaženite opravilo in počakajte, da se na zavihku Izvajanja prikaže kot uspešno dokončano (trajalo bi le nekaj sekund).
Vsak zagon bo ustvaril datoteko JSON s 1,000 vrsticami pod navedenim vedro in predpono transformsblog/inputdata/. Posel lahko zaženete večkrat, če želite preizkusiti z več vhodnimi datotekami.
Vsaka vrstica v sintetičnih podatkih je podatkovna vrstica, ki predstavlja objekt JSON, kot je ta:
Ustvarite vizualno opravilo AWS Glue
Če želite ustvariti vizualno opravilo AWS Glue, dokončajte naslednje korake:
- Pojdite v AWS Glue Studio in ustvarite opravilo z možnostjo Vizualno s praznim platnom.
- Uredi
Untitled jobda ga poimenujete in dodelite vlogo, primerno za lepilo AWS o Podrobnosti o delovnem mestu tab. - Dodajte vir podatkov S3 (lahko ga poimenujete
JSON files source) in vnesite URL S3, pod katerim so shranjene datoteke (npr.s3://<your bucket name>/transformsblog/inputdata/), nato izberite JSON kot format podatkov. - Izberite Sklepaj shemo zato nastavi izhodno shemo na podlagi podatkov.
Iz tega izvornega vozlišča boste še naprej verižili transformacije. Ko dodajate vsako transformacijo, se prepričajte, da je izbrano vozlišče zadnje dodano, da bo dodeljeno kot nadrejeno, razen če je v navodilih navedeno drugače.
Če niste izbrali pravega nadrejenega elementa, ga lahko vedno uredite tako, da ga izberete in v konfiguracijskem podoknu izberete drugega nadrejenega elementa.
Za vsako dodano vozlišče boste dali posebno ime (tako da je namen vozlišča prikazan na grafu) in konfiguracijo na Transform tab.
Vsakič, ko pretvorba spremeni shemo (na primer doda nov stolpec), je treba izhodno shemo posodobiti, tako da je vidna nadaljnjim pretvorbam. Izhodno shemo lahko uredite ročno, vendar je bolj praktično in varneje, če to storite s predogledom podatkov.
Poleg tega lahko na ta način preverite, ali transformacija deluje tako daleč, kot je bilo pričakovano. Če želite to narediti, odprite Predogled podatkov z izbrano transformacijo in začnite sejo predogleda. Ko preverite, ali so preoblikovani podatki videti po pričakovanjih, pojdite na Izhodna shema zavihek in izberite Uporabi shemo predogleda podatkov za samodejno posodobitev sheme.
Ko dodate nove vrste transformacij, se lahko v predogledu prikaže sporočilo o manjkajoči odvisnosti. Ko se to zgodi, izberite Končaj sejo in začnite novo, tako da predogled pobere novo vrsto vozlišča.
Izvleček informacij o instrumentu
Začnimo z obravnavanjem informacij o imenu instrumenta, da ga normaliziramo v stolpce, ki so lažje dostopni v nastali izhodni tabeli.
- Dodaj Razcepljena vrvica vozlišče in ga poimenujte
Split instrument, ki bo tokeniziral stolpec instrumenta z uporabo regularnega izraza presledka:s+(v tem primeru bi zadostoval en sam presledek, vendar je ta način bolj prilagodljiv in vizualno preglednejši). - Izvirne informacije o instrumentu želimo ohraniti takšne, kot so, zato vnesite novo ime stolpca za razdeljeno matriko:
instrument_arr.
- Dodajanje Niz v stolpce vozlišče in ga poimenujte
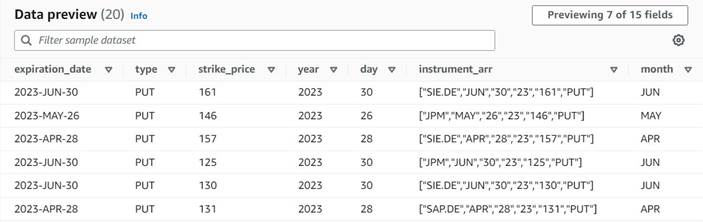
Instrument columnsza pretvorbo pravkar ustvarjenega stolpca matrike v nova polja, razen zasymbol, za katerega že imamo rubriko. - Izberite stolpec
instrument_arr, preskočite prvi žeton in mu recite, naj izvleče izhodne stolpcemonth, day, year, strike_price, typez uporabo indeksov2, 3, 4, 5, 6(presledki za vejicami so za berljivost, ne vplivajo na konfiguracijo).
Izvlečeno leto je izraženo le z dvema števkama; postavimo začasno vrzel in predpostavimo, da je v tem stoletju, če uporabljajo le dve števki.
- Dodaj Izpeljani stolpec vozlišče in ga poimenujte
Four digits year. - Vnesite
yearkot izpeljani stolpec, tako da ga preglasi, in vnesite naslednji izraz SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Za udobje izdelamo expiration_date polje, ki ga ima lahko uporabnik kot sklic na zadnji datum, ko je možnost uveljaviti.
- Dodaj Poveži stolpce vozlišče in ga poimenujte
Build expiration date. - Poimenujte nov stolpec
expiration_date, izberite stolpceyear,monthinday(v tem vrstnem redu) in vezaj kot presledek.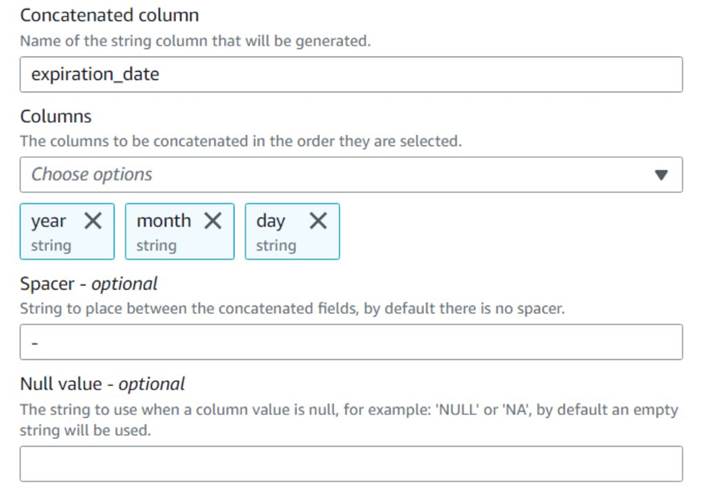
Dosedanji diagram bi moral izgledati kot naslednji primer.
![]()
Dosedanji predogled podatkov novih stolpcev bi moral izgledati kot naslednji posnetek zaslona.
Normalizirajte število pogodb
Vsaka od vrstic v podatkih označuje število pogodb vsake opcije, ki so bile kupljene ali prodane, in sklope, na katerih so bila naročila izpolnjena. Ne da bi izgubili informacije o posameznih serijah, želimo imeti vsako količino v posamezni vrstici z eno samo vrednostjo količine, medtem ko se ostale informacije ponovijo v vsaki proizvedeni vrstici.
Najprej združimo zneske v en stolpec.
- Dodajanje Prekliči vrtenje stolpcev v vrstice vozlišče in ga poimenujte
Unpivot actions. - Izberite stolpce
boughtinsoldza odmik in shranjevanje imen in vrednosti v poimenovanih stolpcihactionincontractsOz.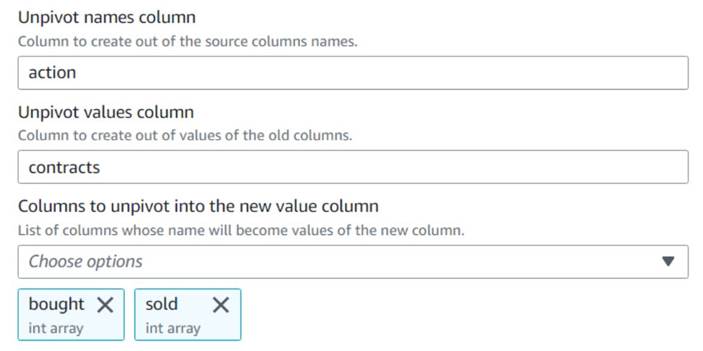
V predogledu opazite, da novi stolpeccontractsje po tej transformaciji še vedno niz števil.
- Dodajanje Razčlenite niz ali preslikajte v vrstice vrstica z imenom
Explode contracts. - Izberite
contractsstolpec in vnesitecontractskot nov stolpec, da ga preglasimo (ni nam treba obdržati izvirne matrike).
Predogled zdaj kaže, da ima vsaka vrstica enega contracts znesek, ostala polja pa so enaka.
To tudi pomeni, da order_id ni več edinstven ključ. Za lastne primere uporabe se morate odločiti, kako modelirati podatke in ali jih želite denormalizirati ali ne.
Naslednji posnetek zaslona je primer, kako izgledajo novi stolpci po dosedanjih transformacijah.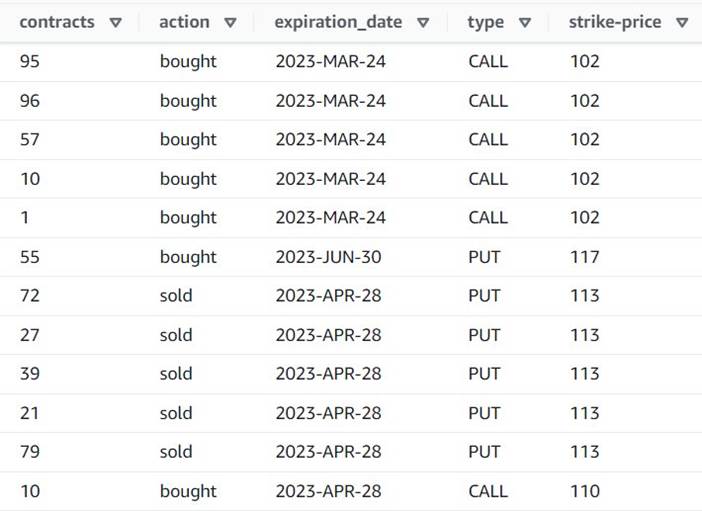
Ustvarite zbirno tabelo
Sedaj ustvarite zbirno tabelo s številom pogodb, s katerimi se trguje za vsako vrsto in vsak delniški simbol.
Za ponazoritev predpostavimo, da obdelane datoteke pripadajo enemu dnevu, tako da ta povzetek daje poslovnim uporabnikom informacije o tem, kakšen je tržni interes in razpoloženje tisti dan.
- Dodaj Izberite Polja vozlišče in izberite naslednje stolpce, ki jih želite obdržati za povzetek:
symbol,typeincontracts.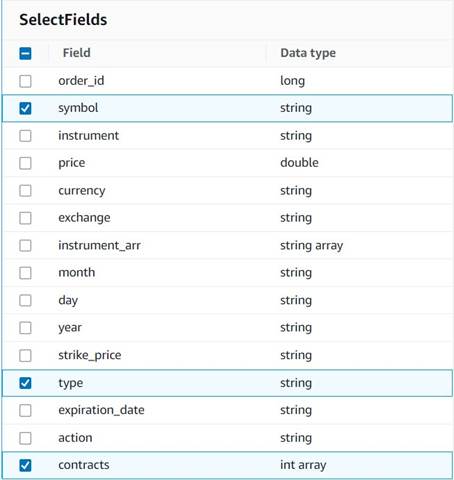
- Dodaj Vrti vrstice v stolpce vozlišče in ga poimenujte
Pivot summary. - Agregat na
contractsuporaba stolpcasumin izberite pretvorbotypestolpec.
Običajno bi ga shranili v zunanjo bazo podatkov ali datoteko za referenco; v tem primeru ga shranimo kot datoteko CSV na Amazon S3.
- Dodajanje Obdelava samodejnega uravnoteženja vozlišče in ga poimenujte
Single output file. - Čeprav se ta vrsta pretvorbe običajno uporablja za optimizacijo vzporednosti, jo tukaj uporabljamo za zmanjšanje izhoda na eno datoteko. Zato vstopite
1v konfiguraciji števila particij.
- Dodajte cilj S3 in ga poimenujte
CSV Contract summary. - Za format podatkov izberite CSV in vnesite pot S3, kjer lahko vloga službe shranjuje datoteke.
Zadnji del opravila bi zdaj moral izgledati kot naslednji primer.![]()
- Shranite in zaženite opravilo. Uporabi Teče zavihek, da preverite, kdaj se je uspešno končalo.
Pod to potjo boste našli datoteko, ki je CSV, čeprav nima te pripone. Verjetno boste morali razširitev dodati, ko jo prenesete, da jo odprete.
V orodju, ki lahko bere CSV, bi moral biti povzetek videti nekako tako kot naslednji primer.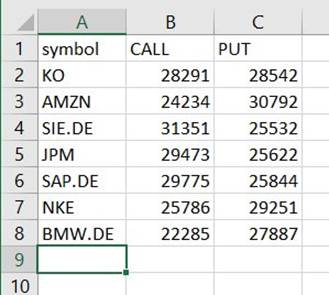
Očistite začasne stolpce
V pripravah na shranjevanje naročil v zgodovinsko tabelo za prihodnjo analizo počistimo nekaj začasnih stolpcev, ustvarjenih na poti.
- Dodaj Spustite polja vozlišče z
Explode contractsvozlišče, izbrano kot nadrejeno (podatkovni cevovod razvejamo, da ustvarimo ločen izhod). - Izberite polja, ki jih želite izpustiti:
instrument_arr,month,dayinyear.
Ostale želimo obdržati, da se shranijo v zgodovinsko tabelo, ki jo bomo ustvarili pozneje.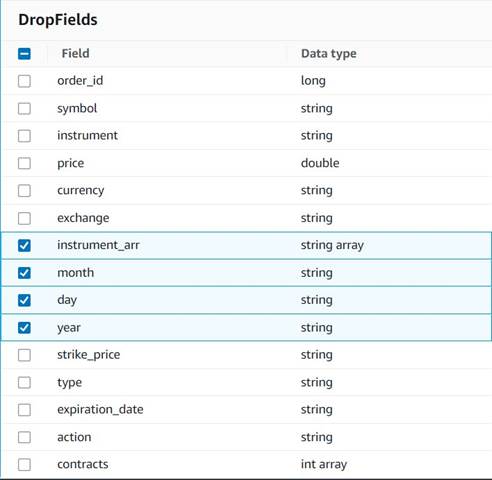
Standardizacija valut
Ti sintetični podatki vsebujejo izmišljene operacije na dveh valutah, toda v resničnem sistemu lahko dobite valute s trgov po vsem svetu. Koristno je standardizirati obravnavane valute v eno referenčno valuto, da jih je mogoče preprosto primerjati in združevati za poročanje in analizo.
Mi uporabljamo Amazonska Atena za simulacijo tabele s približnimi pretvorbami valut, ki se redno posodablja (tukaj predvidevamo, da naročila obdelujemo dovolj pravočasno, da je pretvorba razumen predstavnik za namene primerjave).
- Odprite konzolo Athena v isti regiji, kjer uporabljate AWS Glue.
- Zaženite naslednjo poizvedbo, da ustvarite tabelo tako, da nastavite lokacijo S3, kjer lahko vaši vlogi Athena in AWS Glue bereta in pišeta. Poleg tega boste morda želeli shraniti tabelo v drugo zbirko podatkov
default(če to storite, ustrezno posodobite kvalificirano ime tabele v navedenih primerih). - V tabelo vnesite nekaj vzorčnih konverzij:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Zdaj bi si lahko ogledali tabelo z naslednjo poizvedbo:
SELECT * FROM default.exchange_rates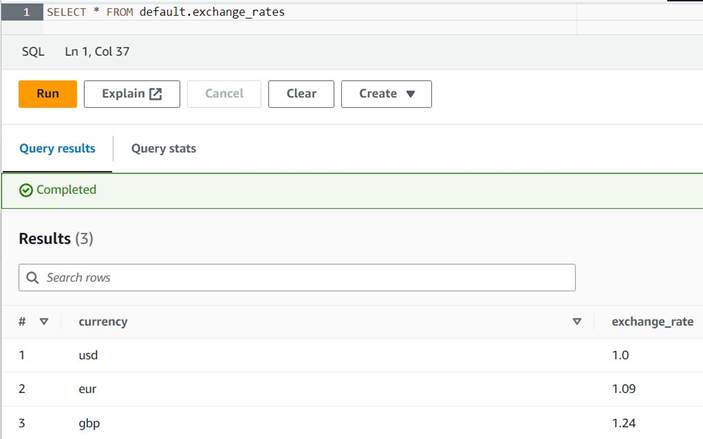
- Nazaj na vizualno opravilo AWS Glue dodajte a Iskanje vozlišče (kot otrok
Drop Fields) in ga poimenujteExchange rate. - Vnesite kakovostno ime tabele, ki ste jo pravkar ustvarili, z uporabo
currencykot ključ in izberiteexchange_ratepolje za uporabo.
Ker je polje enako poimenovano tako v podatkih kot v iskalni tabeli, lahko samo vnesemo imecurrencyin ni treba definirati preslikave.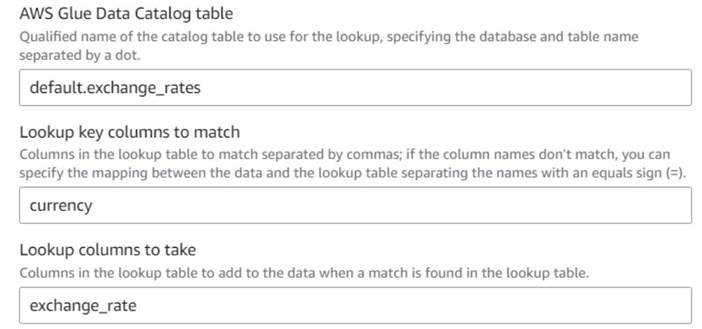
V času tega pisanja pretvorba iskanja ni podprta v predogledu podatkov in prikazala bo napako, da tabela ne obstaja. To je samo za predogled podatkov in ne preprečuje pravilnega izvajanja opravila. Nekaj preostalih korakov objave ne zahteva, da posodobite shemo. Če morate zagnati predogled podatkov na drugih vozliščih, lahko vozlišče za iskanje začasno odstranite in ga nato postavite nazaj. - Dodaj Izpeljani stolpec vozlišče in ga poimenujte
Total in usd. - Poimenujte izpeljani stolpec
total_usdin uporabite naslednji izraz SQL:round(contracts * price * exchange_rate, 2)
- Dodaj Dodajte trenutni časovni žig vozlišče in poimenujte stolpec
ingest_date. - Uporabite obliko
%Y-%m-%dza vaš časovni žig (za namene predstavitve uporabljamo le datum; če želite, ga lahko naredite natančnejšega).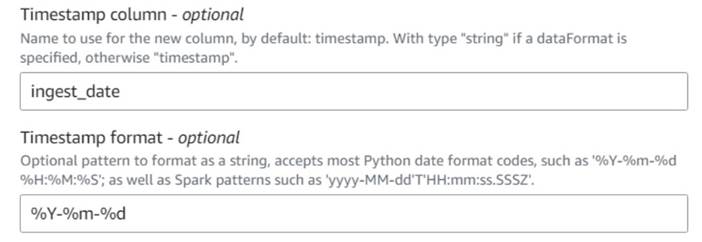
Shranite tabelo zgodovinskih naročil
Če želite shraniti tabelo zgodovinskih naročil, izvedite naslednje korake:
- Dodajte ciljno vozlišče S3 in ga poimenujte
Orders table. - Konfigurirajte format Parquet s hitrim stiskanjem in zagotovite ciljno pot S3, pod katero boste shranili rezultate (ločeno od povzetka).
- Izberite Ustvarite tabelo v podatkovnem katalogu in pri naslednjih zagonih posodobite shemo in dodajte nove particije.
- Vnesite ciljno bazo podatkov in ime za novo tabelo, na primer:
option_orders.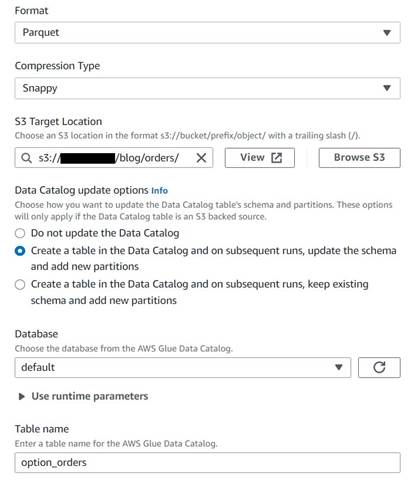
Zadnji del diagrama bi moral biti zdaj podoben naslednjemu, z dvema vejama za dva ločena izhoda.![]()
Ko uspešno zaženete opravilo, lahko z orodjem, kot je Athena, pregledate podatke, ki jih je opravilo ustvarilo s poizvedovanjem po novi tabeli. Mizo najdete na seznamu Athena in izberite Predogled tabele ali samo zaženite poizvedbo SELECT (posodobitev imena tabele na ime in katalog, ki ste ju uporabili):
SELECT * FROM default.option_orders limit 10
Vsebina vaše tabele bi morala biti podobna naslednjemu posnetku zaslona.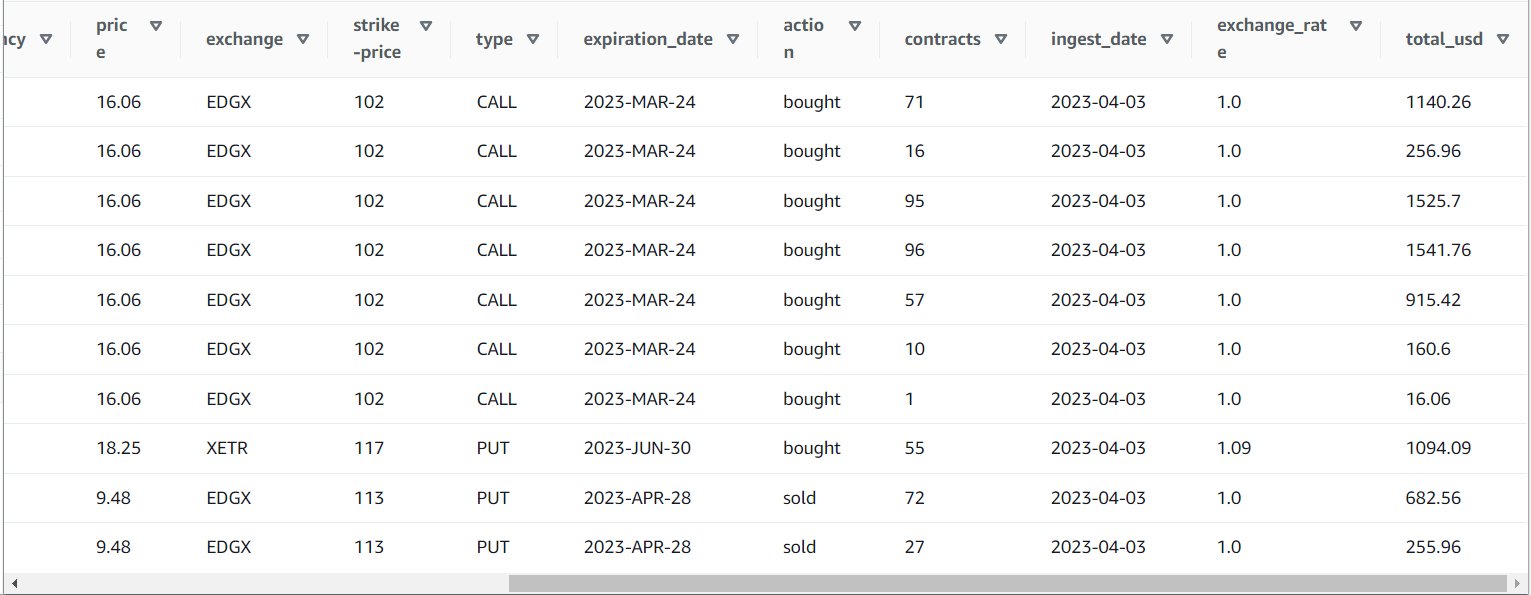
Čiščenje
Če tega primera ne želite obdržati, izbrišite dve opravili, ki ste jih ustvarili, dve tabeli v Atheni in poti S3, kjer so bile shranjene vhodne in izhodne datoteke.
zaključek
V tej objavi smo pokazali, kako vam lahko nove transformacije v AWS Glue Studio pomagajo narediti naprednejšo transformacijo z minimalno konfiguracijo. To pomeni, da lahko implementirate več primerov uporabe ETL, ne da bi morali pisati in vzdrževati kodo. Nove transformacije so že na voljo v AWS Glue Studio, tako da jih lahko že danes uporabite v svojih vizualnih opravilih.
O avtorju
![]() Gonzalo Herreros je višji arhitekt za velike podatke v skupini AWS Glue.
Gonzalo Herreros je višji arhitekt za velike podatke v skupini AWS Glue.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoAiStream. Podatkovna inteligenca Web3. Razširjeno znanje. Dostopite tukaj.
- Kovanje prihodnosti z Adryenn Ashley. Dostopite tukaj.
- Kupujte in prodajajte delnice podjetij pred IPO s PREIPO®. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :ima
- : je
- :ne
- :kje
- $GOR
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- Sposobna
- O meni
- sprejemljiv
- dostop
- ustrezno
- dodajte
- dodano
- dodajanje
- napredno
- po
- vsi
- dodeljenih
- dodelitve
- omogočajo
- omogoča
- skupaj
- že
- Prav tako
- vedno
- Amazon
- znesek
- zneski
- an
- Analiza
- analizirati
- in
- Še ena
- kaj
- uporabna
- približno
- april
- SE
- Argument
- Array
- AS
- dodeljena
- At
- lastnosti
- samodejno
- Na voljo
- AWS
- AWS lepilo
- nazaj
- temeljijo
- BE
- pred
- počutje
- Big
- Big Podatki
- prazno
- BMW
- tako
- Kupil
- veje
- izgradnjo
- poslovni
- vendar
- nakup
- by
- klic
- CAN
- primeru
- primeri
- Katalog
- center
- Stoletje
- Spremembe
- lastnosti
- preveriti
- otrok
- Izberite
- izbiri
- bolj jasno
- Koda
- Kodiranje
- Stolpec
- Stolpci
- Skupno
- v primerjavi z letom
- Primerjava
- dokončanje
- Končana
- konfiguracija
- Konzole
- Konsolidirati
- Vsebuje
- vsebina
- Naročilo
- pogodbe
- udobje
- Pretvorba
- konverzije
- pretvorbo
- pretvori
- KORPORACIJA
- bi
- ustvarjajo
- ustvaril
- Ustvarjanje
- plačila
- valuta
- Trenutna
- DAG
- datum
- Baze podatkov
- Datum
- Termini
- Datum čas
- dan
- ponudba
- deliti
- odloča
- privzeto
- opredeljen
- Dokazano
- Odvisnost
- Izpeljano
- Kljub
- Podrobnosti
- drugačen
- števk
- razpravlja
- do
- Ne
- tem
- dolarjev
- dont
- podvojila
- navzdol
- Drop
- padla
- vsak
- lažje
- enostavno
- lahka
- urednik
- omogočajo
- dovolj
- Vnesite
- okolje
- Napaka
- Eter (ETH)
- EUR
- Primer
- Primeri
- Razen
- Izmenjava
- Izmenjave
- Ekskluzivno
- obstajajo
- Razširi
- Pričakuje
- poskus
- potekel
- izražena
- razširitev
- zunanja
- dodatna
- ekstrakt
- daleč
- strah
- Nekaj
- izmišljeno
- Polje
- Področja
- file
- datoteke
- izpolnite
- napolnjena
- finančna
- Finančni instrumenti
- Najdi
- prva
- Všita
- prilagodljiv
- sledi
- po
- sledi
- za
- format
- je pokazala,
- iz
- Prihodnost
- britanski funt
- splošno
- splošno
- ustvarjajo
- ustvarila
- dobili
- Daj
- daje
- Go
- graf
- Pohlep
- Ravnanje
- se zgodi
- Imajo
- ob
- pomoč
- tukaj
- zgodovinski
- zgodovina
- Kako
- Kako
- HTML
- http
- HTTPS
- Ljudje
- i
- identificira
- identificirati
- if
- vpliv
- izvajati
- uvoz
- in
- indekse
- naveden
- označuje
- označuje
- indikacija
- individualna
- Podatki
- vhod
- primer
- Namesto
- Navodila
- instrument
- instrumenti
- obresti
- vmesnik
- v
- ISO
- IT
- ITS
- Job
- Delovna mesta
- jpg
- json
- samo
- Imejte
- Ključne
- Otrok
- Zadnja
- pozneje
- kot
- LIMIT
- vrstica
- likvidnostno
- Seznam
- obremenitev
- kraj aktivnosti
- več
- Poglej
- izgleda kot
- POGLEDI
- iskanje
- izgubiti
- izgube
- je
- vzdrževati
- Znamka
- IZDELA
- ročno
- map
- kartiranje
- Tržna
- tržne občutke
- Prisotnost
- Maj ..
- pomeni
- Spoji
- Sporočilo
- morda
- minimalna
- manjka
- Model
- monitor
- več
- Najbolj
- več
- vzajemno
- Ime
- Imenovan
- Imena
- Nimate
- potrebe
- Novo
- št
- Vozel
- vozlišča
- Običajno
- zdaj
- Številka
- številke
- predmet
- of
- pogosto
- on
- ONE
- samo
- odprite
- Delovanje
- operacije
- Optimizirajte
- Možnost
- možnosti
- or
- Da
- naročila
- izvirno
- Ostalo
- drugače
- izhod
- več
- Splošni
- preglasijo
- lastne
- plačana
- podokno
- parameter
- del
- pot
- Izbiramo
- plinovod
- pivot
- Kraj
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Prispevek
- potencial
- Praktično
- natančna
- preprečiti
- predogled
- Cena
- verjetno
- Postopek
- obravnavati
- proizvodnjo
- Proizvedeno
- zagotavljajo
- če
- zagotavlja
- nakup
- Namen
- namene
- dal
- Python
- kvalificirano
- dvigniti
- naključno
- Preberi
- pravo
- razumno
- zmanjša
- odražajo
- okolica
- Preostalih
- odstrani
- podvojeno
- Poročanje
- predstavljajo
- predstavnik
- predstavlja
- predstavlja
- zahteva
- Zahteve
- zahteva
- oziroma
- REST
- rezultat
- Rezultati
- pregleda
- vloga
- vloge
- ROW
- Run
- tek
- varnejši
- Enako
- sap
- Shrani
- shranjevanje
- pomaknite
- sekund
- izbran
- izbiranje
- prodaja
- višji
- sentiment
- ločena
- Zasedanje
- Kompleti
- nastavitev
- Delnice
- Shell
- shouldnt
- Prikaži
- Razstave
- Podoben
- Enostavno
- sam
- Velikosti
- spretnosti
- majhna
- So
- doslej
- prodaja
- nekaj
- Nekaj
- vir
- Vesolje
- prostori
- specifična
- določeno
- po delih
- Spreadsheet
- SQL
- Začetek
- Koraki
- Še vedno
- zaloge
- shranjevanje
- trgovina
- shranjeni
- String
- studio
- kasneje
- Uspešno
- primerna
- POVZETEK
- Podprti
- Simbol
- sintetična
- sintetični podatki
- sintetično
- sistem
- sistemi
- miza
- Bodite
- ciljna
- skupina
- povej
- začasna
- deset
- Test
- kot
- da
- O
- Graf
- informacije
- svet
- Njih
- POTEM
- zato
- te
- jih
- ta
- tisti,
- čas
- krat
- Časovni žig
- do
- danes
- žeton
- tokenizirati
- vzel
- orodje
- Skupaj za plačilo
- trgovini
- s katerimi se trguje
- Transform
- Preoblikovanje
- transformacije
- preoblikovati
- dva
- tip
- pod
- osnovni
- razumeli
- edinstven
- dokler
- Nadgradnja
- posodobljeno
- posodabljanje
- URL
- us
- Ameriških dolarjev
- ameriški dolar
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- Uporabniki
- uporabo
- dragocene
- Dragocene informacije
- vrednost
- Vrednote
- Kraj
- preverjeno
- preverjanje
- Poglej
- vidna
- Obseg
- vs
- Počakaj
- želeli
- je
- način..
- we
- so bili
- Kaj
- kdaj
- ki
- medtem
- bo
- z
- brez
- delovnih tokov
- deluje
- svet
- bi
- pisati
- pisanje
- leto
- jo
- Vaša rutina za
- zefirnet











