S prihodom generativne umetne inteligence lahko današnji osnovni modeli (FM), kot sta velika jezikovna modela (LLM) Claude 2 in Llama 2, izvajajo vrsto generativnih nalog, kot so odgovarjanje na vprašanja, povzemanje in ustvarjanje vsebine na besedilnih podatkih. Vendar podatki iz resničnega sveta obstajajo v več modalitetah, kot so besedilo, slike, video in zvok. Vzemite na primer PowerPoint diapozitiv. Vsebuje lahko informacije v obliki besedila ali vdelane v grafe, tabele in slike.
V tej objavi predstavljamo rešitev, ki uporablja multimodalne FM-je, kot je Multimodalne vgradnje Amazon Titan model in LLaVA 1.5 in vključno s storitvami AWS Amazon Bedrock in Amazon SageMaker za izvajanje podobnih generativnih nalog na multimodalnih podatkih.
Pregled rešitev
Rešitev ponuja izvedbo za odgovarjanje na vprašanja z uporabo informacij v besedilu in vizualnih elementih diapozitivov. Zasnova temelji na konceptu Retrieval Augmented Generation (RAG). Tradicionalno je bil RAG povezan z besedilnimi podatki, ki jih lahko obdelujejo LLM. V tej objavi razširimo RAG, da vključuje tudi slike. To zagotavlja zmogljivo zmožnost iskanja za ekstrahiranje kontekstualno ustrezne vsebine iz vizualnih elementov, kot so tabele in grafi, skupaj z besedilom.
Obstajajo različni načini za oblikovanje rešitve RAG, ki vključuje slike. Tukaj smo predstavili en pristop in bomo nadaljevali z alternativnim pristopom v drugi objavi te tridelne serije.
Ta rešitev vključuje naslednje komponente:
- Model Amazon Titan Multimodal Embeddings – Ta FM se uporablja za ustvarjanje vdelav za vsebino v diapozitivih, uporabljenih v tej objavi. Kot multimodalni model lahko ta model Titan obdeluje besedilo, slike ali kombinacijo kot vhod in ustvarja vdelave. Model Titan Multimodal Embeddings ustvarja vektorje (vdelave) 1,024 dimenzij in je dostopen prek Amazon Bedrock.
- Velik pomočnik za jezik in vid (LLaVA) – LLaVA je odprtokodni multimodalni model za vizualno in jezikovno razumevanje in se uporablja za interpretacijo podatkov v diapozitivih, vključno z vizualnimi elementi, kot so grafi in tabele. Uporabljamo različico s 7 milijardami parametrov LLaVA 1.5-7b v tej rešitvi.
- Amazon SageMaker – Model LLaVA je razporejen na končni točki SageMaker z uporabo storitev gostovanja SageMaker, dobljeno končno točko pa uporabljamo za izvajanje sklepanja glede na model LLaVA. Uporabljamo tudi prenosne računalnike SageMaker za orkestracijo in predstavitev te rešitve od konca do konca.
- Amazon OpenSearch brez strežnika – OpenSearch Serverless je brezstrežniška konfiguracija na zahtevo za Storitev Amazon OpenSearch. OpenSearch Serverless uporabljamo kot vektorsko bazo podatkov za shranjevanje vdelav, ustvarjenih z modelom Titan Multimodal Embeddings. Indeks, ustvarjen v zbirki OpenSearch Serverless, služi kot vektorska shramba za našo rešitev RAG.
- Amazon OpenSearch Ingestion (OSI) – OSI je popolnoma upravljan zbiralnik podatkov brez strežnika, ki dostavlja podatke v domene OpenSearch Service in zbirke OpenSearch Serverless. V tej objavi uporabljamo cevovod OSI za dostavo podatkov v vektorsko shrambo OpenSearch Serverless.
Arhitektura rešitev
Zasnova rešitve je sestavljena iz dveh delov: zaužitja in interakcije z uporabnikom. Med zaužitjem obdelamo vhodni niz diapozitivov tako, da vsak diapozitiv pretvorimo v sliko, ustvarimo vdelave za te slike in nato zapolnimo shrambo vektorskih podatkov. Ti koraki so dokončani pred koraki interakcije uporabnika.
V fazi interakcije z uporabnikom se vprašanje uporabnika pretvori v vdelave in izvede se iskanje podobnosti v vektorski bazi podatkov, da se najde diapozitiv, ki bi lahko vseboval odgovore na uporabniško vprašanje. Nato ponudimo ta diapozitiv (v obliki slikovne datoteke) modelu LLaVA in uporabniško vprašanje kot poziv za ustvarjanje odgovora na poizvedbo. Vsa koda za to objavo je na voljo v GitHub počitek.
Naslednji diagram ponazarja arhitekturo zaužitja.
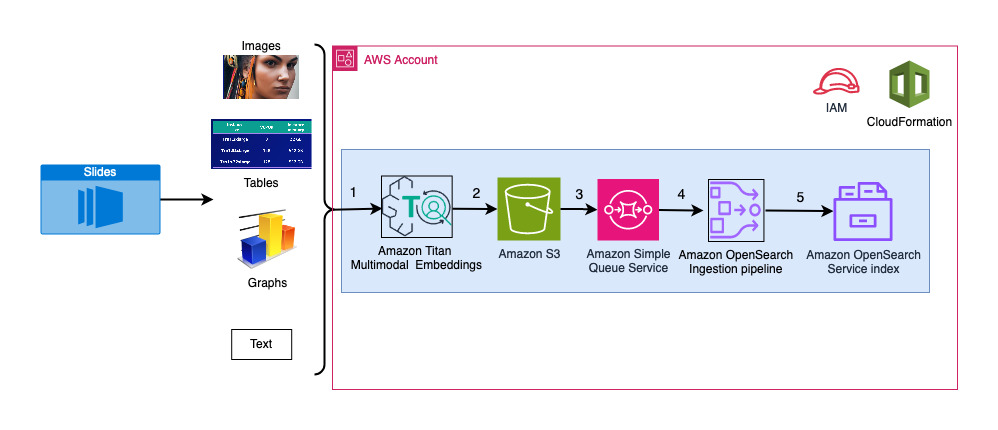
Koraki poteka dela so naslednji:
- Diapozitivi se pretvorijo v slikovne datoteke (ena na diapozitiv) v formatu JPG in se posredujejo modelu Titan Multimodal Embeddings za ustvarjanje vdelav. V tej objavi uporabljamo diapozitiv z naslovom Usposabljanje in uvajanje Stable Diffusion z uporabo AWS Trainium & AWS Inferentia z vrha AWS v Torontu junija 2023, da bi predstavili rešitev. Vzorčni komplet ima 31 diapozitivov, tako da ustvarimo 31 nizov vektorskih vdelav, od katerih ima vsak 1,024 dimenzij. Tem ustvarjenim vektorskim vdelavam dodamo dodatna metapodatkovna polja in ustvarimo datoteko JSON. Ta dodatna metapodatkovna polja je mogoče uporabiti za izvajanje obogatenih iskalnih poizvedb z uporabo zmogljivih zmožnosti iskanja OpenSearch.
- Ustvarjene vdelave so združene v eno datoteko JSON, ki se naloži v Preprosta storitev shranjevanja Amazon (Amazon S3).
- Via Obvestila o dogodkih Amazon S3, je dogodek postavljen v Storitev Amazon Simple Queue Service Čakalna vrsta (Amazon SQS).
- Ta dogodek v čakalni vrsti SQS deluje kot sprožilec za zagon cevovoda OSI, ki nato zaužije podatke (datoteko JSON) kot dokumente v indeks OpenSearch Serverless. Upoštevajte, da je indeks OpenSearch Serverless konfiguriran kot ponor za ta cevovod in je ustvarjen kot del zbirke OpenSearch Serverless.
Naslednji diagram ponazarja arhitekturo uporabniške interakcije.
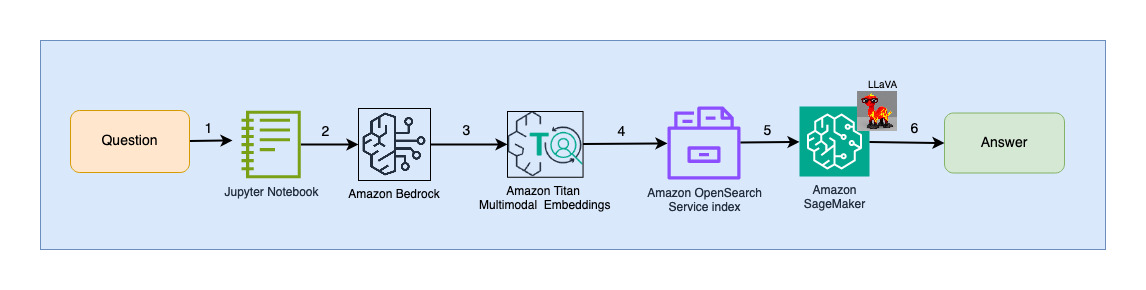
Koraki poteka dela so naslednji:
- Uporabnik pošlje vprašanje v zvezi z diapozitivom, ki je bil zaužit.
- Uporabniški vnos se pretvori v vdelave z uporabo modela Titan Multimodal Embeddings, do katerega dostopate prek Amazon Bedrock. Vektorsko iskanje OpenSearch se izvede z uporabo teh vdelav. Izvedemo iskanje k-najbližjega soseda (k=1), da pridobimo najbolj ustrezno vdelavo, ki se ujema z uporabniško poizvedbo. Nastavitev k=1 pridobi diapozitiv, ki najbolj ustreza vprašanju uporabnika.
- Metapodatki odgovora OpenSearch Serverless vsebujejo pot do slike, ki ustreza najustreznejšemu diapozitivu.
- Poziv se ustvari z združitvijo uporabniškega vprašanja in poti slike ter se posreduje LLaVA, ki gostuje na SageMakerju. Model LLaVA je sposoben razumeti uporabniško vprašanje in nanj odgovoriti s preučevanjem podatkov na sliki.
- Rezultat tega sklepanja se vrne uporabniku.
Ti koraki so podrobno obravnavani v naslednjih razdelkih. Glej Rezultati razdelek za posnetke zaslona in podrobnosti o izhodu.
Predpogoji
Če želite implementirati rešitev v tej objavi, bi morali imeti AWS račun in poznavanje FM, Amazon Bedrock, SageMaker in OpenSearch Service.
Ta rešitev uporablja model Titan Multimodal Embeddings. Prepričajte se, da je ta model omogočen za uporabo v Amazon Bedrock. Na konzoli Amazon Bedrock izberite Dostop do modela v navigacijskem podoknu. Če je Titan Multimodal Embeddings omogočen, bo status dostopa naveden Dostop odobren.
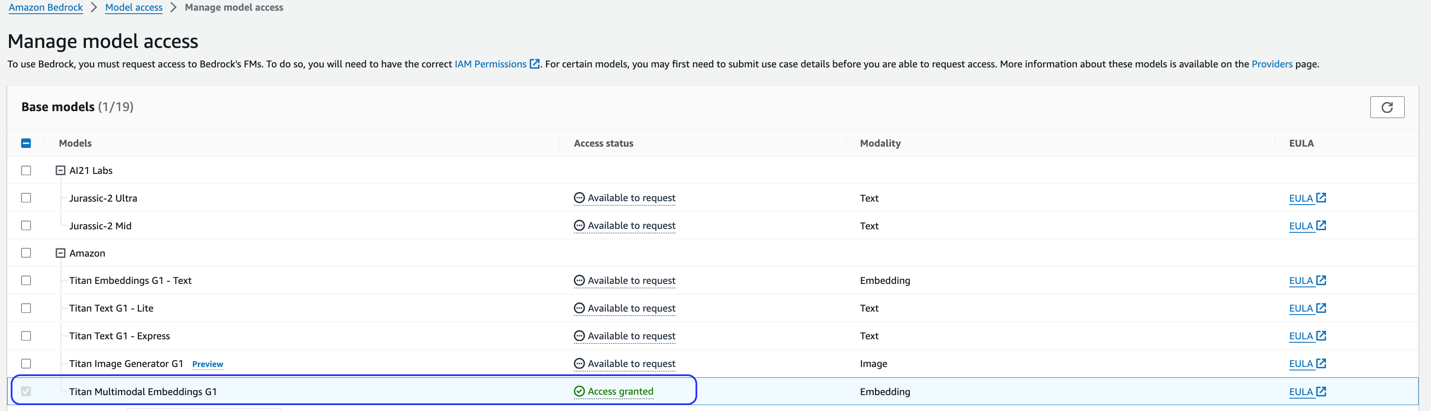
Če model ni na voljo, omogočite dostop do modela z izbiro Upravljanje dostopa do modela, izbiro Titan Multimodal Embeddings G1, in izbiro Zahtevajte dostop do modela. Model je takoj pripravljen za uporabo.
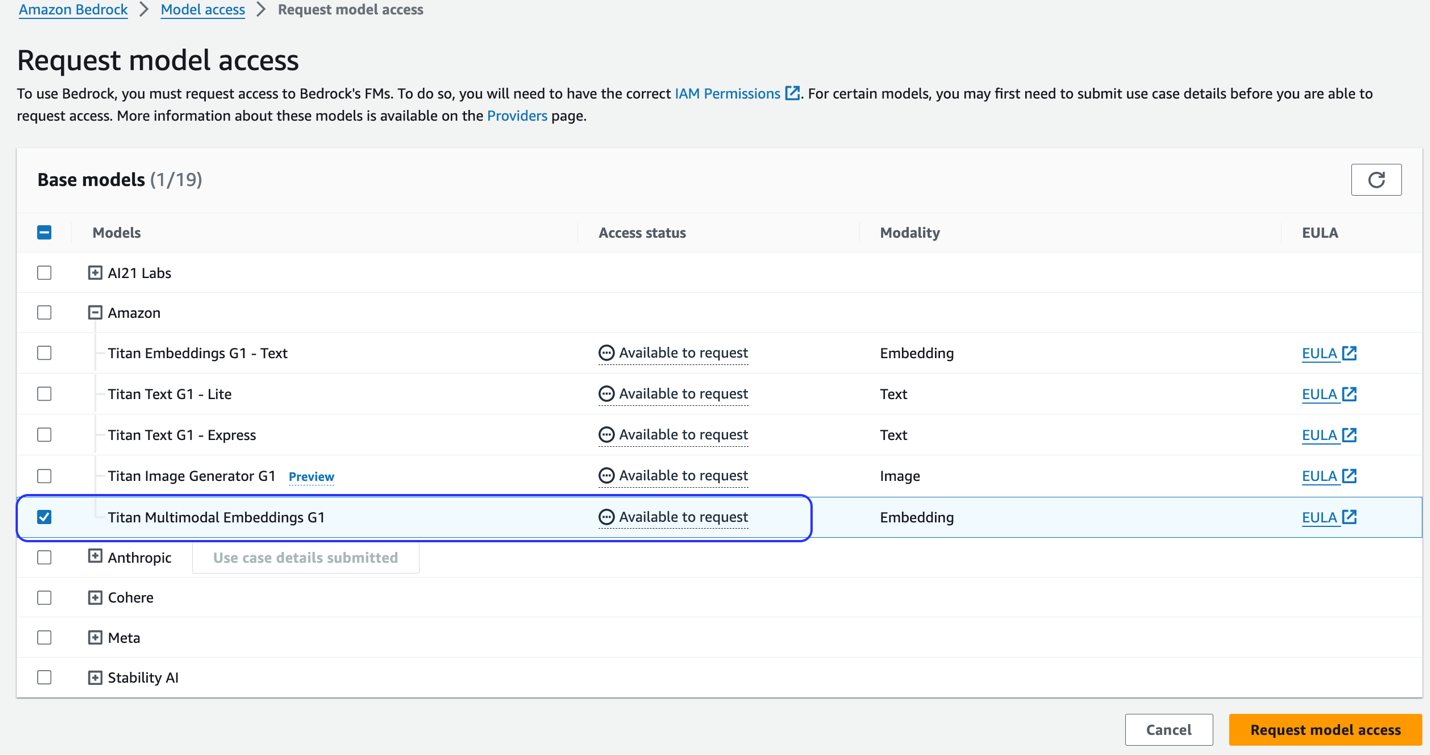
Za ustvarjanje sklada rešitev uporabite predlogo AWS CloudFormation
Uporabite eno od naslednjih možnosti Oblikovanje oblaka AWS predloge (odvisno od vaše regije) za zagon virov rešitve.
| Regija AWS | Link |
|---|---|
us-east-1 |
|
us-west-2 |
Ko je sklad uspešno ustvarjen, se pomaknite do sklada Izhodi na konzoli AWS CloudFormation in zabeležite vrednost za MultimodalCollectionEndpoint, ki ga uporabimo v naslednjih korakih.
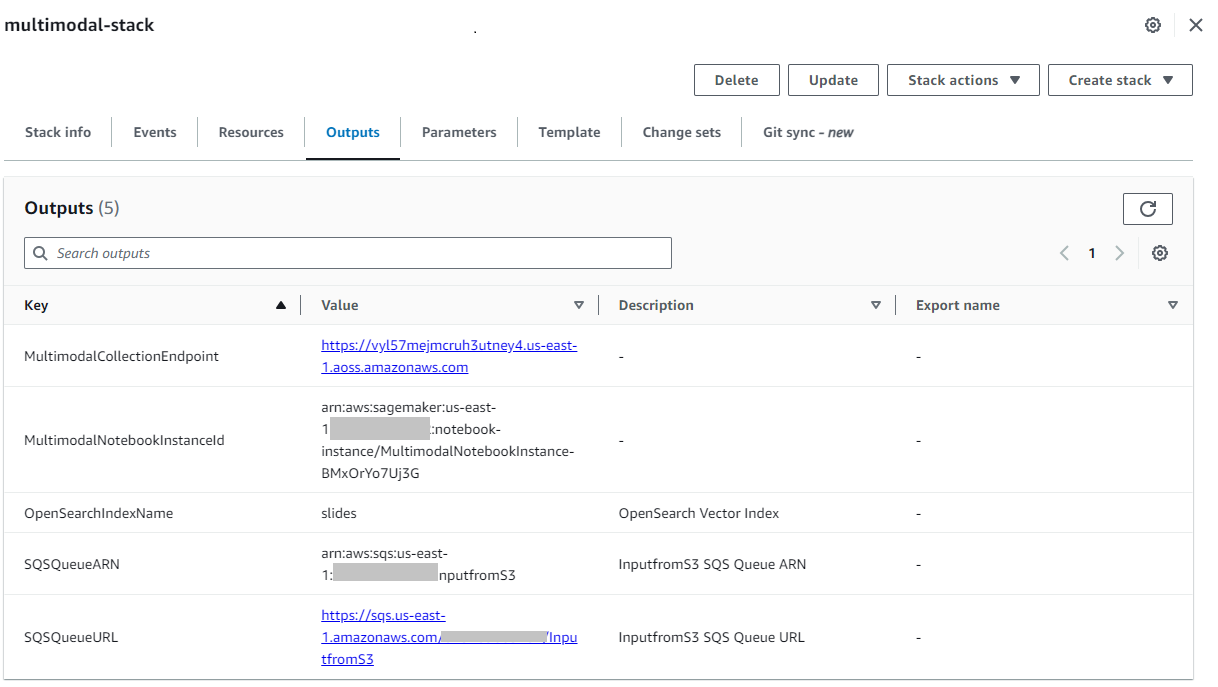
Predloga CloudFormation ustvari naslednje vire:
- Vloge IAM - Naslednji AWS upravljanje identitete in dostopa (IAM) so ustvarjene vloge. Posodobite te vloge, da jih uporabite dovoljenja z najmanjšimi pravicami.
SMExecutionRoles polnim dostopom Amazon S3, SageMaker, OpenSearch Service in Bedrock.OSPipelineExecutionRolez dostopom do posebnih dejanj Amazon SQS in OSI.
- Beležnica SageMaker – Vsa koda za to objavo se izvaja prek tega zvezka.
- Zbirka OpenSearch Brez strežnika – To je vektorska baza podatkov za shranjevanje in pridobivanje vdelav.
- cevovod OSI – To je cevovod za vnos podatkov v OpenSearch Serverless.
- Vedro S3 – Vsi podatki za to objavo so shranjeni v tem vedru.
- čakalna vrsta SQS – Dogodki za sprožitev izvajanja cevovoda OSI so postavljeni v to čakalno vrsto.
Predloga CloudFormation konfigurira cevovod OSI z obdelavo Amazon S3 in Amazon SQS kot virom in indeksom OpenSearch Serverless kot ponorom. Vsi predmeti, ustvarjeni v podanem vedru S3 in predponi (multimodal/osi-embeddings-json) bo sprožil obvestila SQS, ki jih cevovod OSI uporablja za vnos podatkov v OpenSearch Serverless.
Predloga CloudFormation prav tako ustvarja mreža, šifriranjein dostop do podatkov pravilniki, potrebni za zbirko OpenSearch Serverless. Posodobite te pravilnike, da uporabite dovoljenja z najmanjšimi pravicami.
Upoštevajte, da je ime predloge CloudFormation navedeno v zvezkih SageMaker. Če je ime privzete predloge spremenjeno, ga posodobite v globals.py
Preizkusite raztopino
Ko so predpogojni koraki končani in je sklad CloudFormation uspešno ustvarjen, ste zdaj pripravljeni na testiranje rešitve:
- Na konzoli SageMaker izberite Prenosniki v podoknu za krmarjenje.
- Izberite
MultimodalNotebookInstanceprimerek prenosnika in izberite Odprite JupyterLab.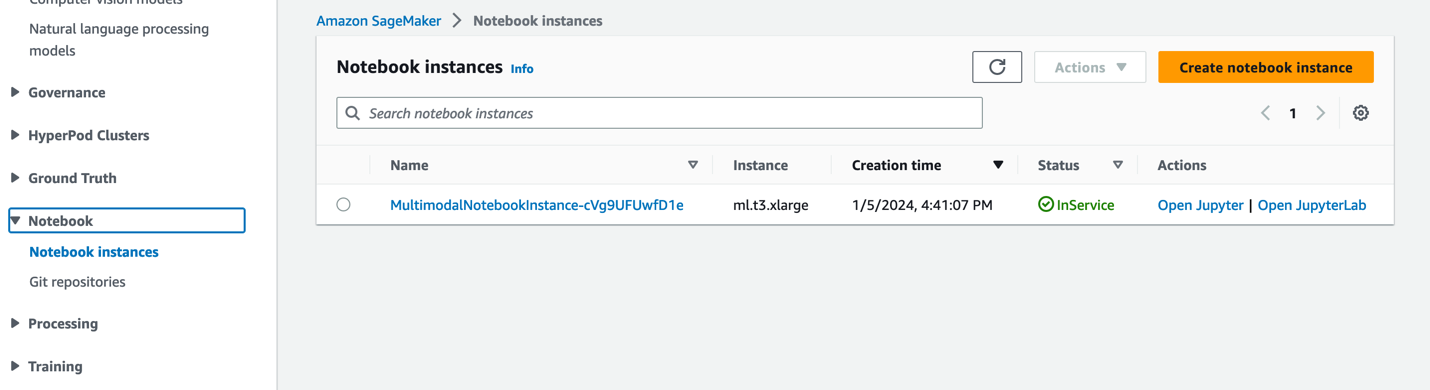
- In Brskalnik datotek, se pomaknite do mape zvezki, da si ogledate zvezke in podporne datoteke.
Zvezki so oštevilčeni v zaporedju, v katerem se izvajajo. Navodila in komentarji v vsakem zvezku opisujejo dejanja, ki jih izvaja ta zvezek. Te zvezke izvajamo enega za drugim.
- Izberite 0_deploy_llava.ipynb da ga odprete v JupyterLab.
- o Run izberite meni Zaženi vse celice za zagon kode v tem zvezku.
Ta prenosnik uvaja model LLaVA-v1.5-7B v končno točko SageMaker. V tem zvezku prenesemo model LLaVA-v1.5-7B iz HuggingFace Hub, zamenjamo skript inference.py z llava_inference.pyin ustvarite datoteko model.tar.gz za ta model. Datoteka model.tar.gz se naloži v Amazon S3 in uporabi za uvajanje modela na končni točki SageMaker. The llava_inference.py skript ima dodatno kodo, ki omogoča branje slikovne datoteke iz Amazon S3 in izvajanje sklepanja na njej.
- Izberite 1_data_prep.ipynb da ga odprete v JupyterLab.
- o Run izberite meni Zaženi vse celice za zagon kode v tem zvezku.
Ta prenosni računalnik prenese drsni krov, pretvori vsak diapozitiv v obliko datoteke JPG in jih naloži v vedro S3, ki se uporablja za to objavo.
- Izberite 2_data_ingestion.ipynb da ga odprete v JupyterLab.
- o Run izberite meni Zaženi vse celice za zagon kode v tem zvezku.
V tem zvezku naredimo naslednje:
- Ustvarimo indeks v zbirki OpenSearch Serverless. Ta indeks shranjuje podatke o vdelavah za komplet diapozitivov. Oglejte si naslednjo kodo:
- Za pretvorbo slik JPG, ustvarjenih v prejšnjem zvezku, v vektorske vdelave uporabljamo model Titan Multimodal Embeddings. Te vdelave in dodatni metapodatki (kot je pot S3 slikovne datoteke) so shranjeni v datoteki JSON in naloženi v Amazon S3. Upoštevajte, da je ustvarjena ena datoteka JSON, ki vsebuje dokumente za vse diapozitive (slike), pretvorjene v vdelave. Naslednji delček kode prikazuje, kako se slika (v obliki kodiranega niza Base64) pretvori v vdelave:
- To dejanje sproži cevovod OpenSearch Ingestion, ki obdela datoteko in jo vnese v indeks OpenSearch Serverless. Sledi vzorec ustvarjene datoteke JSON. (V primeru kode je prikazan vektor s štirimi dimenzijami. Model Titan Multimodal Embeddings ustvari 1,024 dimenzij.)
- Izberite 3_rag_inference.ipynb da ga odprete v JupyterLab.
- o Run izberite meni Zaženi vse celice za zagon kode v tem zvezku.
Ta prenosni računalnik izvaja rešitev RAG: uporabniško vprašanje pretvorimo v vdelave, poiščemo podobno sliko (diapozitiv) iz vektorske podatkovne baze in posredujemo pridobljeno sliko LLaVA, da ustvari odgovor na uporabniško vprašanje. Uporabljamo naslednjo predlogo poziva:
Naslednji delček kode zagotavlja potek dela RAG:
Rezultati
Sledi zbirka nekaterih uporabniških vprašanj in odgovorov, ki jih ustvari naša implementacija. The Vprašanje stolpec zajema vprašanje uporabnika in Odgovor je besedilni odgovor, ki ga ustvari LLaVA. Image je k-najbližje (k=1) ujemanje diapozitiva, ki ga vrne vektorsko iskanje brez strežnika OpenSearch. Ta diapozitiv interpretira LLaVA, da zagotovi odgovor.
Multimodalni rezultati RAG
| Vprašanje | Odgovor | Image |
|---|---|---|
| Kakšna je zmogljivost Inf2 v primerjavi s primerljivimi primerki EC2? Potrebujem številke. | Glede na diapozitiv ponujajo primerki Inf2 podjetja AWS Inferentia2 do 4-krat večjo prepustnost in 10-krat nižjo zakasnitev v primerjavi s primerljivimi primerki EC2. |  |
| Kaj glede na vztrajnik AI/ML ponujajo storitve AWS AI/ML? | Storitve AWS AI/ML zagotavljajo boljše zmogljivosti $/perfer, nove zmogljivosti in naložbe v inovacije. | 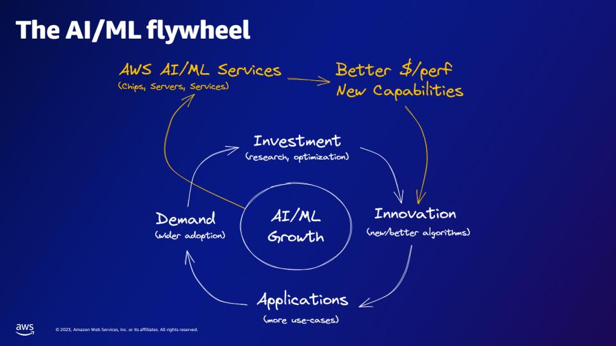 |
| Koliko več parametrov ima GPT-2 v primerjavi z GPT-3? Kakšna je številčna razlika med velikostjo parametra GPT-2 in GPT-3? | Glede na diapozitiv ima GPT-3 175 milijard parametrov, medtem ko ima GPT-2 1.5 milijarde parametrov. Številčna razlika med velikostjo parametra GPT-2 in GPT-3 je 173.5 milijarde. | 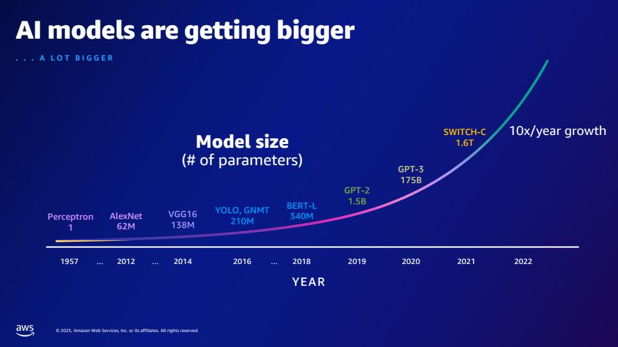 |
| Kaj so kvarki v fiziki delcev? | V diapozitivih nisem našel odgovora na to vprašanje. |  |
To rešitev lahko razširite na diapozitive. Preprosto posodobite spremenljivko SLIDE_DECK v globals.py z URL-jem do kompleta diapozitivov in zaženite korake za vnos, ki so opisani v prejšnjem razdelku.
Nasvet
Nadzorne plošče OpenSearch lahko uporabite za interakcijo z API-jem OpenSearch za izvajanje hitrih testov vašega indeksa in vnesenih podatkov. Naslednji posnetek zaslona prikazuje primer GET nadzorne plošče OpenSearch.
Čiščenje
Da se izognete prihodnjim stroškom, izbrišite vire, ki ste jih ustvarili. To lahko storite tako, da izbrišete sklad prek konzole CloudFormation.

Poleg tega izbrišite končno točko sklepanja SageMaker, ustvarjeno za sklepanje LLaVA. To lahko storite tako, da odkomentirate korak čiščenja 3_rag_inference.ipynb in zagon celice ali z brisanjem končne točke prek konzole SageMaker: izberite Sklepanje in Končne točke v podoknu za krmarjenje, nato izberite končno točko in jo izbrišite.
zaključek
Podjetja ves čas ustvarjajo nove vsebine, diapozitivi pa so običajen mehanizem, ki se uporablja za skupno rabo in razširjanje informacij znotraj organizacije in navzven s strankami ali na konferencah. Sčasoma lahko bogate informacije ostanejo zakopane in skrite v nebesedilnih modalitetah, kot so grafi in tabele v teh diapozitivih. To rešitev in moč večmodalnih FM-jev, kot sta model Titan Multimodal Embeddings in LLaVA, lahko uporabite za odkrivanje novih informacij ali odkrivanje novih pogledov na vsebino v diapozitivih.
Spodbujamo vas, da z raziskovanjem izveste več Amazon SageMaker JumpStart, Modeli Amazon Titan, Amazon Bedrock in OpenSearch Service ter izdelava rešitve z uporabo vzorčne izvedbe, podane v tej objavi.
Bodite pozorni na dve dodatni objavi kot del te serije. 2. del pokriva drug pristop, ki bi ga lahko uporabili za pogovor s svojim diapozitivom. Ta pristop ustvarja in shranjuje sklepe LLaVA ter te shranjene sklepe uporablja za odgovarjanje na poizvedbe uporabnikov. 3. del primerja oba pristopa.
O avtorjih
 Amit Arora je specialist za AI in ML pri Amazon Web Services, ki podjetjem pomaga pri uporabi storitev strojnega učenja v oblaku za hitro razširitev njihovih inovacij. Je tudi pomožni predavatelj v programu podatkovne znanosti in analitike MS na Univerzi Georgetown v Washingtonu DC.
Amit Arora je specialist za AI in ML pri Amazon Web Services, ki podjetjem pomaga pri uporabi storitev strojnega učenja v oblaku za hitro razširitev njihovih inovacij. Je tudi pomožni predavatelj v programu podatkovne znanosti in analitike MS na Univerzi Georgetown v Washingtonu DC.
 Manju Prasad je višji arhitekt rešitev v Strategic Accounts pri Amazon Web Services. Osredotoča se na zagotavljanje tehničnih smernic na različnih področjih, vključno z umetno inteligenco/ML, za stranko M&E, ki se nahaja na trgu. Preden se je pridružila AWS, je oblikovala in gradila rešitve za podjetja v sektorju finančnih storitev in tudi za startupe.
Manju Prasad je višji arhitekt rešitev v Strategic Accounts pri Amazon Web Services. Osredotoča se na zagotavljanje tehničnih smernic na različnih področjih, vključno z umetno inteligenco/ML, za stranko M&E, ki se nahaja na trgu. Preden se je pridružila AWS, je oblikovala in gradila rešitve za podjetja v sektorju finančnih storitev in tudi za startupe.
 Archana Inapudi je višji arhitekt rešitev pri AWS, ki podpira strateške stranke. Ima več kot desetletje izkušenj s pomočjo strankam pri oblikovanju in izdelavi analitike podatkov in rešitev za baze podatkov. Navdušena je nad uporabo tehnologije za zagotavljanje vrednosti strankam in doseganje poslovnih rezultatov.
Archana Inapudi je višji arhitekt rešitev pri AWS, ki podpira strateške stranke. Ima več kot desetletje izkušenj s pomočjo strankam pri oblikovanju in izdelavi analitike podatkov in rešitev za baze podatkov. Navdušena je nad uporabo tehnologije za zagotavljanje vrednosti strankam in doseganje poslovnih rezultatov.
 Antara Raisa je arhitekt rešitev AI in ML pri Amazon Web Services, ki podpira strateške stranke iz Dallasa v Teksasu. Prav tako ima predhodne izkušnje pri delu z velikimi podjetniškimi partnerji pri AWS, kjer je delala kot arhitektka partnerskih rešitev za uspeh digitalnih strank.
Antara Raisa je arhitekt rešitev AI in ML pri Amazon Web Services, ki podpira strateške stranke iz Dallasa v Teksasu. Prav tako ima predhodne izkušnje pri delu z velikimi podjetniškimi partnerji pri AWS, kjer je delala kot arhitektka partnerskih rešitev za uspeh digitalnih strank.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 10
- 100
- 13
- 15%
- 16
- 173
- 20
- 2023
- 26
- 29
- 31
- 8
- 9
- a
- Sposobna
- O meni
- dostop
- dostopna
- računi
- Doseči
- Ukrep
- dejavnosti
- aktov
- dodajte
- Dodatne
- dodatek
- prihod
- proti
- AI
- AI / ML
- vsi
- omogočajo
- skupaj
- Prav tako
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- analitika
- in
- Še ena
- odgovor
- odgovor
- odgovori
- kaj
- API
- Uporabi
- pristop
- pristopi
- Arhitektura
- SE
- AS
- vprašati
- Pomočnik
- povezan
- At
- audio
- Povečana
- Auth
- Na voljo
- izogniti
- AWS
- Oblikovanje oblaka AWS
- temeljijo
- BE
- bilo
- Boljše
- med
- Billion
- telo
- izgradnjo
- Building
- zgrajena
- poslovni
- by
- CAN
- Zmogljivosti
- zmožnost
- ujame
- celica
- spremenilo
- Stroški
- Izberite
- izbiri
- stranke
- Koda
- zbirka
- Zbirke
- zbiralec
- Stolpec
- kombinacija
- združevanje
- komentarji
- Skupno
- Podjetja
- primerljiva
- primerjate
- v primerjavi z letom
- dokončanje
- Končana
- deli
- Koncept
- konference
- konfiguracija
- konfigurirano
- vsebuje
- Konzole
- vsebujejo
- vseboval
- Vsebuje
- vsebina
- ustvarjanje vsebine
- pretvorbo
- pretvori
- pretvorbo
- Ustrezno
- bi
- prevleke
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- Oblikovanje
- Mandatno
- stranka
- Stranke, ki so
- Dallas
- Armaturna plošča
- nadzorne plošče
- datum
- Podatkovna analiza
- znanost o podatkih
- Baze podatkov
- desetletje
- paluba
- privzeto
- poda
- daje
- izkazati
- Odvisno
- razporedi
- razporejeni
- uvajanja
- razpolaga
- opisati
- Oblikovanje
- zasnovan
- Podatki
- podrobno
- Podrobnosti
- diagram
- DICT
- DID
- Razlika
- drugačen
- Difuzija
- digitalni
- Dimenzije
- dimenzije
- odkriti
- razpravljali
- zaslon
- do
- Dokumenti
- ne
- domen
- prenesi
- prenosov
- med
- e
- vsak
- elementi
- vgrajeni
- vdelava
- omogočajo
- omogočena
- kodiran
- spodbujanje
- konec
- Končna točka
- Motor
- zagotovitev
- Podjetje
- podjetniške stranke
- Napaka
- Eter (ETH)
- Event
- dogodki
- Preučevanje
- Primer
- Razen
- izjema
- obstaja
- izkušnje
- Raziskovati
- razširiti
- zunaj
- ekstrakt
- Poznavanje
- Področja
- file
- datoteke
- finančna
- finančne storitve
- Najdi
- Osredotoča
- sledi
- po
- sledi
- za
- obrazec
- format
- Fundacija
- štiri
- brezplačno
- iz
- polno
- v celoti
- Prihodnost
- ustvarjajo
- ustvarila
- ustvarja
- generacija
- generativno
- Generativna AI
- Georgetown
- dobili
- GitHub
- dogaja
- grafi
- Navodila
- Imajo
- he
- pomoč
- pomoč
- tukaj
- skrita
- več
- Hits
- gostitelj
- gostila
- gostovanje
- Gostitelji
- Kako
- Vendar
- HTML
- http
- HTTPS
- Hub
- HuggingFace
- i
- IAM
- identiteta
- if
- ponazarja
- slika
- slike
- takoj
- izvajati
- Izvajanje
- izvedbe
- in
- vključujejo
- vključuje
- Vključno
- Indeks
- indeksi
- Podatki
- Inovacije
- novosti
- vhod
- primer
- primerov
- Navodila
- interakcijo
- interakcije
- interno
- v
- naložbe
- IT
- pridružil
- jpg
- json
- junij
- jezik
- velika
- Latenca
- kosilo
- UČITE
- učenje
- predavatelj
- kot
- LINK
- Llama
- lokalna
- nižje
- stroj
- strojno učenje
- Znamka
- upravljanje
- upravlja
- več
- Stave
- ujemanje
- Mehanizem
- Meni
- metapodatki
- Metoda
- ML
- modalitete
- Model
- modeli
- več
- Najbolj
- MS
- več
- Ime
- materni
- Krmarjenje
- ostalo
- Nimate
- Novo
- Noben
- Upoštevajte
- prenosnik
- zvezki
- Obvestila
- zdaj
- oštevilčen
- številke
- predmeti
- of
- ponudba
- on
- Na zahtevo
- ONE
- samo
- odprite
- open source
- or
- Organizacija
- OS
- naši
- ven
- rezultatov
- izhod
- več
- podokno
- parameter
- parametri
- del
- delec
- partner
- partnerji
- deli
- opravil
- strastno
- pot
- za
- opravlja
- performance
- opravljeno
- Dovoljenja
- perspektive
- faza
- Fizika
- slike
- plinovod
- platon
- Platonova podatkovna inteligenca
- PlatoData
- politike
- Prispevek
- Prispevkov
- potencialno
- moč
- močan
- Predictor
- predstaviti
- predstavljeni
- prejšnja
- Predhodna
- Postopek
- obdelani
- Procesi
- obravnavati
- Program
- Lastnosti
- zagotavljajo
- če
- zagotavlja
- zagotavljanje
- dal
- Quarks
- poizvedbe
- poizvedba
- vprašanje
- vprašanja
- Hitri
- krpa
- območje
- hitro
- reading
- pripravljen
- resnični svet
- prejetih
- referenčno
- okolica
- povezane
- pomembno
- ostajajo
- zamenjajte
- zahteva
- obvezna
- viri
- Odzove
- Odgovor
- odgovorov
- povzroči
- rezultat
- Rezultati
- iskanje
- vrnitev
- Rich
- vloge
- Run
- tek
- sagemaker
- Sklep SageMaker
- Enako
- pravijo,
- Lestvica
- Znanost
- galerija
- script
- Iskalnik
- drugi
- Oddelek
- oddelki
- sektor
- glej
- izberite
- izbiranje
- višji
- Zaporedje
- Serija
- Brez strežnika
- služi
- Storitev
- Storitve
- Zasedanje
- Kompleti
- nastavitev
- nastavitve
- Delite s prijatelji, znanci, družino in partnerji :-)
- je
- shouldnt
- pokazale
- Razstave
- Podoben
- Enostavno
- preprosto
- sam
- Velikosti
- Slide
- Diapozitivi
- delček
- So
- Rešitev
- rešitve
- nekaj
- vir
- specialist
- specifična
- določeno
- stabilna
- sveženj
- zagon
- Država
- Status
- Korak
- Koraki
- shranjevanje
- trgovina
- shranjeni
- trgovine
- Strateško
- String
- kasneje
- uspeh
- Uspešno
- taka
- Vrh
- Podpora
- Preverite
- miza
- Bodite
- Pogovor
- Naloge
- tehnični
- Tehnologija
- Predloga
- predloge
- Test
- testi
- texas
- besedilo
- besedilno
- da
- O
- informacije
- njihove
- POTEM
- te
- ta
- tisti,
- pretočnost
- čas
- titan
- z naslovom
- do
- današnje
- skupaj
- toronto
- tradicionalno
- prečkanje
- sprožijo
- sproži
- Res
- poskusite
- OBRAT
- dva
- tip
- odkrijte
- razumeli
- razumevanje
- univerza
- Nadgradnja
- naložili
- URL
- uporaba
- Rabljeni
- uporabnik
- uporablja
- uporabo
- vrednost
- spremenljivka
- raznolikost
- različica
- preko
- Video
- Poglej
- Vizija
- vizualna
- washington
- načini
- we
- web
- spletne storitve
- Dobro
- Kaj
- Kaj je
- ki
- medtem
- bo
- z
- v
- delal
- potek dela
- deluje
- jo
- Vaša rutina za
- zefirnet