
Slika ustvarjena z DALL-E3
Umetna inteligenca je bila popolna revolucija v tehnološkem svetu.
Njegova sposobnost, da posnema človeško inteligenco in opravlja naloge, ki so nekoč veljale izključno za človeško domeno, še vedno preseneča večino od nas.
Ne glede na to, kako dobri so bili ti pozni preskoki umetne inteligence, vedno obstaja prostor za izboljšave.
In ravno tu začne delovati hiter inženiring!
Vnesite to polje, ki lahko znatno izboljša produktivnost modelov AI.
Odkrijmo vse skupaj!
Hitro inženirstvo je hitro rastoča domena znotraj AI, ki se osredotoča na izboljšanje učinkovitosti in uspešnosti jezikovnih modelov. Gre za ustvarjanje popolnih pozivov za usmerjanje modelov AI, da ustvarijo želene rezultate.
Zamislite si to kot učenje, kako nekomu dati boljša navodila, da zagotovite, da razume in pravilno izvede nalogo.
Zakaj je hiter inženiring pomemben
- Izboljšana produktivnost: Z uporabo visokokakovostnih pozivov lahko modeli AI ustvarijo natančnejše in ustreznejše odgovore. To pomeni manj časa, porabljenega za popravke, in več časa za izkoriščanje zmogljivosti AI.
- Stroškovna učinkovitost: Usposabljanje modelov AI zahteva veliko virov. Hitro inženirstvo lahko zmanjša potrebo po ponovnem usposabljanju z optimizacijo delovanja modela z boljšimi pozivi.
- Vsestranskost: Dobro oblikovan poziv lahko naredi modele umetne inteligence bolj vsestranske in jim omogoči, da se spopadejo s širšim naborom nalog in izzivov.
Preden se poglobimo v najnaprednejše tehnike, se spomnimo dveh najbolj uporabnih (in osnovnih) tehnik hitrega inženiringa.
Zaporedno razmišljanje z "Razmišljajmo korak za korakom"
Danes je dobro znano, da se natančnost LLM modelov bistveno izboljša, če dodamo zaporedje besed »Razmišljajmo korak za korakom«.
Zakaj ... se lahko vprašate?
No, to je zato, ker prisilimo model, da vsako nalogo razdeli na več korakov, s čimer zagotovimo, da ima model dovolj časa za obdelavo vsakega od njih.
Na primer, lahko izzovem GPT3.5 z naslednjim pozivom:
Če ima Janez 5 hrušk, nato poje 2, kupi še 5 in nato 3 da prijatelju, koliko hrušk ima?
Model mi bo takoj odgovoril. Vendar, če dodam končni »Razmišljajmo korak za korakom«, prisilim model, da ustvari miselni proces z več koraki.
Nekaj pozicij
Medtem ko se poziv Zero-shot nanaša na prošnjo modelu, naj izvede nalogo brez zagotavljanja kakršnega koli konteksta ali predhodnega znanja, tehnika pozivanja nekaj posnetkov pomeni, da LLM predstavimo nekaj primerov želenega rezultata skupaj z določenim vprašanjem.
Na primer, če želimo pripraviti model, ki definira kateri koli izraz s poetičnim tonom, bo to morda zelo težko razložiti. Prav?
Vendar pa bi lahko uporabili naslednje nekajkratne pozive, da usmerimo model v želeno smer.
Vaša naloga je, da odgovorite v doslednem slogu, ki je usklajen z naslednjim slogom.
: Nauči me o odpornosti.
: Prožnost je kot drevo, ki se upogne z vetrom, vendar se nikoli ne zlomi.
To je sposobnost, da se odbiješ od stiske in greš naprej.
: Vaš vnos tukaj.
Če tega še niste preizkusili, lahko izzovete GPT.
Ker pa sem skoraj prepričan, da večina od vas že pozna te osnovne tehnike, vas bom poskušal izzvati z nekaterimi naprednimi tehnikami.
1. Nagovarjanje po verigi misli (CoT).
Predstavil Google leta 2022, ta metoda vključuje navodilo modelu, naj opravi več faz razmišljanja, preden zagotovi končni odgovor.
Se sliši znano, kajne? Če je tako, imate popolnoma prav.
To je kot združitev zaporednega razmišljanja in nekajkratnega spodbujanja.
Kako?
V bistvu pozivi CoT usmerjajo LLM k zaporedni obdelavi informacij. To pomeni, da ponazarjamo, kako rešiti prvo težavo z razmišljanjem v več korakih, nato pa modelu pošljemo našo pravo nalogo, pri čemer pričakujemo, da posnema primerljivo verigo misli, ko se odzove na dejansko poizvedbo, ki jo želimo rešiti.
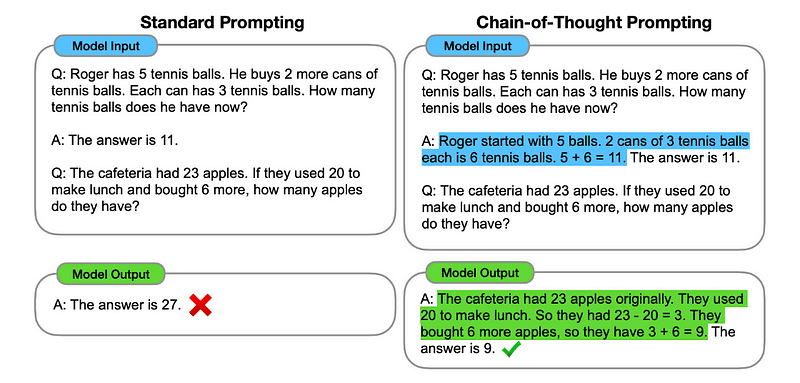
Slika vzeta iz papirja.
Tako bi lahko po prvem primeru zagotovili poziv s prvo težavo in zaporedno razlago, kako jo rešiti. Nato lahko pošljemo svoj vnos in vidimo, kako nastane čarovnija!
Če ima Janez 5 hrušk, nato poje 2, kupi še 5 in nato 3 da prijatelju, koliko hrušk ima? Razmišljajmo korak za korakom.
Gremo korak za korakom. Janez začne s 5 hruškami. Poje 2 hruški, torej mu ostane 5–2 = 3 hruške. Nato kupi še 5 hrušk. Torej ima zdaj 3 + 5 = 8 hrušk. Na koncu da prijatelju 3 hruške. Ostane mu torej 8–3 = 5 hrušk. Torej ima Janez po vseh teh korakih 5 hrušk.
Vaš vnos tukaj.
Vendar večina od vas zagotovo razmišlja ... Ali moram razmišljati o zaporedni poti za rešitev katere koli težave, kadar koli želim nekaj vprašati na ChatGPT?
No… nisi prvi! In to nas pripelje do …
2. Samodejna veriga misli (Auto-CoT)
V 2022, Zhang in sodelavci so predstavili metodo za izogibanje temu ročnemu postopku. Obstajata dva glavna razloga, zakaj se izogibati ročnim opravilom:
- Lahko je dolgočasno.
- Lahko prinese slabe rezultate – na primer, ko je naš mentalni proces napačen.
Predlagali so uporabo LLM-jev v kombinaciji s pozivom »Razmišljajmo korak za korakom«, da bi zaporedoma izdelali sklepne verige za vsako predstavitev.
To pomeni, da vprašate ChatGPT, kako zaporedno rešiti katero koli težavo, nato pa uporabite ta isti primer, da ga naučite, kako rešiti katero koli drugo težavo.
3. Samodoslednost
Samokonsistentnost je še ena zanimiva tehnika spodbujanja, katere namen je izboljšati verigo misli, ki spodbuja k bolj zapletenim težavam sklepanja.
Torej … kaj je glavna razlika?
Glavna ideja pod Self-Consistency je zavedanje, da lahko model usposobimo z napačnim primerom. Predstavljajte si, da prejšnji problem rešim z napačnim miselnim procesom:
Če ima Janez 5 hrušk, nato poje 2, kupi še 5 in nato 3 da prijatelju, koliko hrušk ima? Razmišljajmo korak za korakom.
Začnite s 5 hruškami. Janez poje 2 hruški. Nato da prijatelju 3 hruške. Ta dejanja je mogoče kombinirati: 2 (pojedeno) + 3 (dano) = skupno 5 prizadetih hrušk. Zdaj odštejte skupno število prizadetih hrušk od začetnih 5 hrušk: 5 (začetno) – 5 (prizadeto) = 0 preostalih hrušk.
Potem bo katera koli druga naloga, ki jo pošljem modelu, napačna.
Zato samokonsistentnost vključuje vzorčenje iz različnih poti razmišljanja, od katerih vsaka vsebuje verigo misli, in nato prepušča LLM-u, da izbere najboljšo in najbolj dosledno pot za rešitev problema.
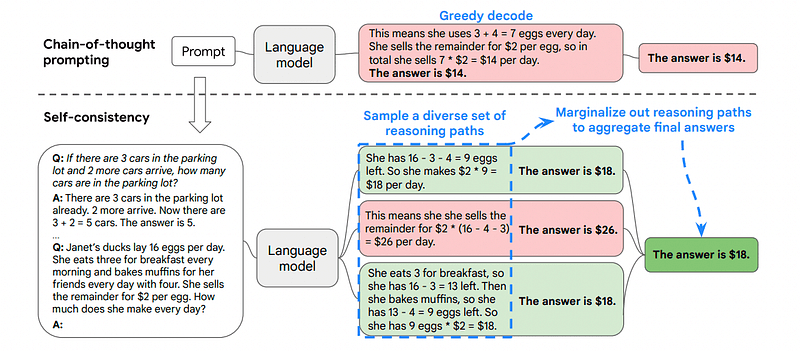
Slika vzeta iz papirja
V tem primeru in spet po prvem primeru lahko modelu pokažemo različne načine reševanja problema.
Če ima Janez 5 hrušk, nato poje 2, kupi še 5 in nato 3 da prijatelju, koliko hrušk ima?
Začnite s 5 hruškami. Janez poje 2 hruški, pri čemer mu ostane 5–2 = 3 hruške. Kupi še 5 hrušk, kar pomeni skupno 3 + 5 = 8 hrušk. Na koncu da prijatelju 3 hruške, tako da mu ostane 8–3 = 5 hrušk.
Če ima Janez 5 hrušk, nato poje 2, kupi še 5 in nato 3 da prijatelju, koliko hrušk ima?
Začnite s 5 hruškami. Nato kupi še 5 hrušk. Janez zdaj poje 2 hruški. Ta dejanja je mogoče kombinirati: 2 (pojedeno) + 5 (kupljeno) = skupaj 7 hrušk. Od skupne količine hrušk odštejte hruško, ki jo je Jon pojedel 7 (skupna količina) – 2 (pojedeno) = 5 preostalih hrušk.
Vaš vnos tukaj.
In tukaj je zadnja tehnika.
4. Spodbujanje splošnega znanja
Običajna praksa hitrega inženiringa je dopolnitev poizvedbe z dodatnim znanjem, preden se končni klic API pošlje GPT-3 ali GPT-4.
Glede na Jiacheng Liu in Co, lahko vsaki zahtevi vedno dodamo nekaj znanja, tako da LLM bolje pozna vprašanje.
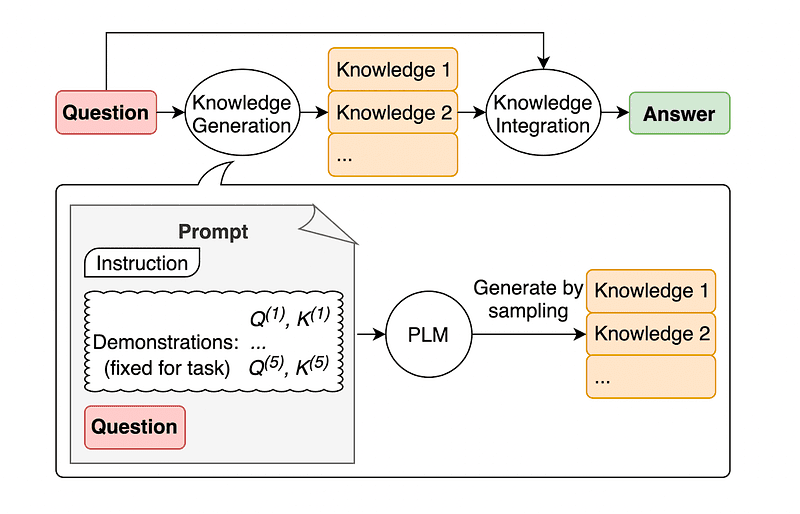
Slika vzeta iz papirja.
Tako na primer, ko vprašamo ChatGPT, ali del golfa poskuša doseči več točk kot drugi, nas bo to potrdilo. Toda glavni cilj golfa je ravno nasproten. Zato lahko dodamo nekaj predhodnega znanja, ki pravi: "Zmaga igralec z nižjim rezultatom".

Torej.. kaj je smešnega, če modelu povemo točno odgovor?
V tem primeru se ta tehnika uporablja za izboljšanje načina interakcije LLM z nami.
Zato avtorji prispevka priporočajo, da LLM ustvari svoje lastno znanje, namesto da bi črpali dodatni kontekst iz zunanje baze podatkov. To samoustvarjeno znanje je nato vključeno v poziv za krepitev zdravega razmišljanja in zagotavljanje boljših rezultatov.
Tako je torej mogoče izboljšati LLM brez povečanja njegovega nabora podatkov o usposabljanju!
Hitro inženirstvo se je pokazalo kot ključna tehnika pri izboljšanju zmogljivosti LLM. S ponavljanjem in izboljšanjem pozivov lahko na bolj neposreden način komuniciramo z modeli AI in tako pridobimo natančnejše in kontekstualno relevantne rezultate, s čimer prihranimo čas in sredstva.
Za tehnološke navdušence, podatkovne znanstvenike in ustvarjalce vsebin je lahko razumevanje in obvladovanje hitrega inženiringa dragocena prednost pri izkoriščanju celotnega potenciala umetne inteligence.
S kombinacijo skrbno zasnovanih pozivov za vnos s temi naprednejšimi tehnikami vam bo nabor spretnosti inženiringa pozivov nedvomno dal prednost v prihodnjih letih.
Josep Ferrer je inženir analitike iz Barcelone. Diplomiral je iz fizike in trenutno dela na področju Data Science, ki se uporablja za mobilnost ljudi. Je ustvarjalec vsebin s krajšim delovnim časom, osredotočen na podatkovno znanost in tehnologijo. Lahko ga kontaktirate na LinkedIn, Twitter or srednje.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :ima
- : je
- :ne
- :kje
- $GOR
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- sposobnost
- O meni
- natančnost
- natančna
- dejavnosti
- dejanska
- dodajte
- dodajanje
- Dodatne
- napredno
- po
- spet
- AI
- AI modeli
- Cilje
- poravnano
- podobno
- vsi
- Dovoli
- skupaj
- že
- vedno
- am
- znesek
- an
- analitika
- in
- Še ena
- odgovor
- kaj
- API
- uporabna
- SE
- AS
- vprašati
- sprašuje
- sredstvo
- Avtorji
- Samodejno
- izogniti
- zaveda
- stran
- nazaj
- Slab
- Barcelona
- Osnovni
- BE
- ker
- bilo
- pred
- počutje
- BEST
- Boljše
- podstavek
- povečanje
- Dolgočasen
- tako
- Kupil
- Bounce
- Break
- odmori
- Prinaša
- širši
- vendar
- Kupi
- by
- klic
- CAN
- Zmogljivosti
- previdno
- primeru
- verige
- verige
- izziv
- izzivi
- ChatGPT
- Izberite
- sodelavci
- kombinirani
- združevanje
- kako
- prihaja
- prihajajo
- Skupno
- komunicirajo
- primerljiva
- dokončanje
- kompleksna
- šteje
- dosledno
- kontakt
- vsebina
- ustvarjalci vsebin
- ozadje
- Popravki
- pravilno
- bi
- ustvaril
- kreator
- Ustvarjalci
- Trenutno
- datum
- znanost o podatkih
- Baze podatkov
- Določa
- dostavo
- zasnovan
- želeno
- Razlika
- drugačen
- neposredna
- smer
- odkriti
- potapljanje
- do
- ne
- domena
- domen
- navzdol
- vsak
- Edge
- učinkovitost
- učinkovitosti
- pojavile
- inženir
- Inženiring
- okrepi
- izboljšanje
- dovolj
- zagotovitev
- Ljubitelji
- točno
- Primer
- Primeri
- izvršiti
- pričakovati
- Pojasnite
- Razlaga
- seznanjeni
- Nekaj
- Polje
- končna
- končno
- prva
- osredotočena
- Osredotoča
- po
- za
- silijo
- Naprej
- prijatelj
- iz
- polno
- smešno
- splošno
- ustvarjajo
- dobili
- Daj
- dana
- daje
- Go
- Cilj
- golf
- dobro
- vodi
- Trdi
- Dovoljenje
- Imajo
- ob
- he
- tukaj
- visoka kvaliteta
- več
- ga
- njegov
- Kako
- Kako
- Vendar
- HTTPS
- človeškega
- človeško inteligenco
- i
- Ideja
- if
- slika
- izboljšanje
- izboljšalo
- Izboljšanje
- izboljšanju
- in
- narašča
- Podatki
- začetna
- vhod
- primer
- Navodila
- integrirana
- Intelligence
- interaktivni
- Zanimivo
- v
- Uvedeno
- vključuje
- IT
- ITS
- John
- Jon
- samo
- KDnuggets
- Imejte
- brcati
- Udarcev
- Vedite
- znanje
- ve
- jezik
- Zadnja
- Pozen
- Interesenti
- Leap
- učenje
- odhodu
- levo
- manj
- Naj
- najem
- vzvod
- kot
- nižje
- magic
- Glavne
- Znamka
- Izdelava
- Način
- Navodilo
- več
- Mastering
- Matter
- me
- pomeni
- duševne
- združitev
- Metoda
- morda
- mobilnost
- Model
- modeli
- več
- Najbolj
- premikanje
- več
- morajo
- Nimate
- nikoli
- št
- zdaj
- pridobi
- of
- on
- enkrat
- Nasprotno
- optimizacijo
- or
- Ostalo
- drugi
- naši
- ven
- izhod
- izhodi
- zunaj
- lastne
- Papir
- del
- pot
- popolna
- opravlja
- performance
- Fizika
- ključno
- platon
- Platonova podatkovna inteligenca
- PlatoData
- predvajalnik
- Točka
- potencial
- praksa
- Ravno
- predstaviti
- precej
- prejšnja
- problem
- Težave
- Postopek
- proizvodnjo
- produktivnost
- zagotavljajo
- zagotavljanje
- vlečenje
- vprašanje
- precej
- območje
- precej
- pravo
- Razlogi
- Priporočamo
- zmanjša
- nanaša
- pomembno
- zahteva
- odpornost
- virov intenzivno
- viri
- odziva
- Odgovor
- odgovorov
- Rezultati
- preusposabljanje
- Revolucija
- Pravica
- soba
- s
- Enako
- shranjevanje
- Znanost
- Znanost in tehnologija
- Znanstveniki
- rezultat
- glej
- pošljite
- pošiljanja
- Zaporedje
- nastavite
- več
- Prikaži
- bistveno
- spretnost
- So
- Izključno
- SOLVE
- Reševanje
- nekaj
- nekdo
- Nekaj
- specifična
- porabljen
- postopka
- Začetek
- začne
- usmerjanje
- Korak
- Koraki
- Še vedno
- slog
- Preverite
- reševanje
- sprejeti
- Naloga
- Naloge
- tech
- tehnika
- tehnike
- Tehnologija
- pove
- Izraz
- kot
- da
- O
- Njih
- POTEM
- Tukaj.
- zato
- te
- jih
- mislim
- Razmišljanje
- ta
- mislil
- skozi
- Tako
- čas
- do
- TONE
- Skupaj za plačilo
- POPOLNOMA
- Vlak
- usposabljanje
- Drevo
- Poskušal
- poskusite
- poskuša
- dva
- Končni
- pod
- opravi
- razumeli
- razumevanje
- nedvomno
- us
- uporaba
- Rabljeni
- uporabo
- POTRDI
- dragocene
- različnih
- vsestranski
- zelo
- želeli
- način..
- načini
- we
- dobro znana
- so bili
- kdaj
- ki
- zakaj
- bo
- veter
- z
- v
- brez
- beseda
- deluje
- svet
- Napačen
- let
- še
- donos
- jo
- Vaša rutina za
- zefirnet







