
Model v modelu
V raziskovalni skupnosti strojnega učenja je veliko znanstvenikov prišlo do prepričanja, da lahko veliki jezikovni modeli izvajajo učenje v kontekstu zaradi tega, kako so usposobljeni, pravi Akyürek. GPT-3 ima na primer na stotine milijard parametrov in je bil usposobljen z branjem ogromnih kosov besedila na internetu, od člankov v Wikipediji do objav na Redditu. Torej, ko nekdo pokaže modelne primere nove naloge, je verjetno že videl nekaj zelo podobnega, ker je njegov nabor podatkov o usposabljanju vključeval besedilo z milijard spletnih mest. Ponavlja vzorce, ki jih je videl med treningom, namesto da bi se naučil izvajati nove naloge. Akyürek je domneval, da se učenci v kontekstu ne ujemajo le s prej videnimi vzorci, temveč se dejansko učijo izvajati nove naloge. On in drugi so eksperimentirali tako, da so tem modelom dajali pozive z uporabo sintetičnih podatkov, ki jih prej niso mogli videti nikjer, in ugotovili, da se modeli še vedno lahko učijo iz le nekaj primerov. Akyürek in njegovi kolegi so mislili, da imajo morda ti modeli nevronske mreže v sebi manjše modele strojnega učenja, ki jih lahko usposobijo za dokončanje nove naloge. "To bi lahko pojasnilo skoraj vse pojave učenja, ki smo jih videli pri teh velikih modelih," pravi. Da bi preizkusili to hipotezo, so raziskovalci uporabili model nevronske mreže, imenovan transformator, ki ima enako arhitekturo kot GPT-3, vendar je bil posebej usposobljen za učenje v kontekstu. Z raziskovanjem arhitekture tega transformatorja so teoretično dokazali, da lahko napiše linearni model znotraj svojih skritih stanj. Nevronska mreža je sestavljena iz številnih plasti med seboj povezanih vozlišč, ki obdelujejo podatke. Skrita stanja so plasti med vhodno in izhodno plastjo. Njihove matematične ocene kažejo, da je ta linearni model zapisan nekje v najzgodnejših slojih transformatorja. Transformator lahko nato posodobi linearni model z implementacijo preprostih učnih algoritmov. V bistvu model simulira in usposablja manjšo različico samega sebe.Preiskovanje skritih plasti
Raziskovalci so to hipotezo raziskali s poskusi sondiranja, kjer so pogledali v skrite plasti transformatorja, da bi poskušali pridobiti določeno količino. »V tem primeru smo poskušali obnoviti dejansko rešitev linearnega modela in lahko smo pokazali, da je parameter zapisan v skritih stanjih. To pomeni, da je linearni model nekje notri,« pravi. Na podlagi tega teoretičnega dela bodo raziskovalci morda lahko omogočili transformatorju, da izvede učenje v kontekstu, tako da bodo nevronski mreži dodali samo dve plasti. Akyürek opozarja, da je še veliko tehničnih podrobnosti, ki jih je treba dodelati, preden bi bilo to mogoče, vendar bi lahko inženirjem pomagalo ustvariti modele, ki lahko dokončajo nove naloge brez potrebe po ponovnem usposabljanju z novimi podatki. Akyürek načrtuje nadaljevanje raziskovanja učenja v kontekstu s funkcijami, ki so bolj zapletene od linearnih modelov, ki so jih proučevali v tem delu. Te poskuse bi lahko uporabili tudi na velikih jezikovnih modelih, da bi ugotovili, ali je njihovo vedenje opisano tudi s preprostimi učnimi algoritmi. Poleg tega se želi poglobiti v vrste podatkov pred usposabljanjem, ki lahko omogočijo učenje v kontekstu. »S tem delom si lahko ljudje zdaj predstavljajo, kako se lahko ti modeli učijo od primerkov. Zato upam, da spremeni poglede nekaterih ljudi na učenje v kontekstu,« pravi Akyürek. »Ti modeli niso tako neumni, kot si ljudje mislijo. Teh nalog si ne zapomnijo samo. Lahko se naučijo novih nalog in pokazali smo, kako je to mogoče.«- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.nanowerk.com/news2/robotics/newsid=62325.php
- 10
- 7
- 9
- a
- Sposobna
- O meni
- doseganje
- dejansko
- Poleg tega
- po
- Alberta
- algoritem
- algoritmi
- vsi
- že
- in
- kjerkoli
- Uporabi
- Arhitektura
- okoli
- članki
- umetni
- Umetna inteligenca
- Pomočnik
- Avtor
- Avtorji
- ker
- pred
- zadaj
- Verjemite
- Boljše
- med
- milijardah
- Bit
- Brain
- Building
- se imenuje
- lahko
- primeru
- nekatere
- Spremembe
- Koda
- sodelavci
- zbiranje
- kako
- skupnost
- dokončanje
- kompleksna
- sestavljajo
- računalnik
- Računalništvo
- računalništvo
- Konferenca
- konzorcij
- naprej
- bi
- ustvarjajo
- CSAIL
- radovedna
- datum
- Datum
- globlje
- Oddelek
- opisano
- Kljub
- Podrobnosti
- DIG
- Direktor
- dont
- By
- med
- elektrotehnike
- omogočajo
- Inženiring
- Inženirji
- Bistvo
- vrednotenja
- Primer
- Primeri
- zanimivo
- Pojasnite
- raziskovanje
- Raziskano
- Raziskovati
- Nekaj
- Všita
- Naprej
- je pokazala,
- iz
- funkcije
- ustvarjajo
- Daj
- Giving
- diplomiral
- pomoč
- skrita
- upam,
- Kako
- HTTPS
- velika
- Stotine
- izvajati
- izvajanja
- Pomembno
- in
- vključeno
- Podatki
- vhod
- primer
- Namesto
- Intelligence
- medsebojno povezani
- Facebook Global
- Internet
- preiskave
- IT
- sam
- pridružil
- znano
- Laboratorij
- jezik
- velika
- večja
- plasti
- vodi
- UČITE
- učenje
- Verjeten
- Pogledal
- več
- ogromen
- ujemanje
- matematični
- pomeni
- član
- MIT
- Model
- modeli
- več
- premikanje
- Mystery
- Nimate
- negativna
- mreža
- omrežij
- Nevronski
- nevronska mreža
- nevronske mreže
- Novo
- Naslednja
- vozlišča
- Odpre
- drugi
- Papir
- parameter
- parametri
- vzorci
- ljudje
- Ljudske
- opravlja
- mogoče
- pojav
- načrti
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Poezija
- pozitiven
- mogoče
- Prispevkov
- napovedati
- predstavljeni
- precej
- prej
- , ravnateljica
- Postopek
- Procesi
- Učitelj
- Programiranje
- dokazano
- Količina
- reading
- Obnovi
- ostajajo
- Raziskave
- raziskovalna skupnost
- raziskovalci
- Rezultati
- preusposabljanje
- Enako
- pravi
- Znanost
- Znanstvenik
- Znanstveniki
- videnje
- Zdi se,
- višji
- stavek
- sentiment
- več
- Prikaži
- pokazale
- Razstave
- Podoben
- Enostavno
- majhna
- manj
- So
- Rešitev
- Reševanje
- nekaj
- nekdo
- Nekaj
- nekje
- posebej
- Stanford
- Univerza Stanford
- Države
- Statistika
- Korak
- Še vedno
- študent
- študiral
- sintetična
- sintetični podatki
- Bodite
- Naloga
- Naloge
- tehnični
- Test
- O
- njihove
- Teoretični
- mislil
- do
- proti
- Vlak
- usposobljeni
- usposabljanje
- vlaki
- Vrste
- tipično
- razumevanje
- univerza
- Nadgradnja
- posodobljeno
- posodobitve
- posodabljanje
- različica
- ogledov
- spletne strani
- Kaj
- ali
- ki
- Wikipedia
- bo
- v
- brez
- delo
- telovaditi
- bi
- pisati
- pisni
- X
- zefirnet
Več od Nanowerk
Katere izzive je treba premagati, da bodo čipi DNK bolj uporabni kot mediji za shranjevanje
Izvorno vozlišče: 2845390
Časovni žig: Avgust 24, 2023

Raziskovalci so podrli najmanjši božični rekord na svetu (z videom)
Izvorno vozlišče: 1850116
Časovni žig: December 22, 2022
Raziskovalci dokazujejo, da sta kvantna prepletenost in topologija neločljivo povezani
Izvorno vozlišče: 3057881
Časovni žig: Jan 12, 2024

Odkrivanje čarovnije v "čarobnem kotu" superprevodnosti
Izvorno vozlišče: 1959509
Časovni žig: Februar 15, 2023
Dvo/kvazi-dvodimenzionalne heterostrukture na osnovi perovskita: konstrukcija, lastnosti in aplikacije
Izvorno vozlišče: 1938788
Časovni žig: Februar 3, 2023

Inovativno izboljšanje svetlobe v nanometrskih strukturah bi lahko pomagalo pri odkrivanju raka
Izvorno vozlišče: 2793993
Časovni žig: Julij 28, 2023

Edinstvene lastnosti kovinskih nanoklastrov za aplikacije od katalize do biomedicine
Izvorno vozlišče: 2726825
Časovni žig: Junij 16, 2023
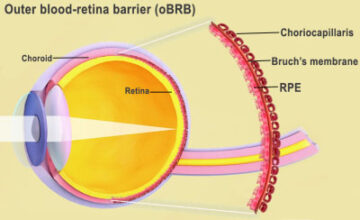
Raziskovalci uporabljajo 3D biotiskanje za ustvarjanje očesnega tkiva
Izvorno vozlišče: 1790814
Časovni žig: December 22, 2022

Nanokatalizator na svetlobo za pridobivanje vodika z uporabo sončne svetlobe
Izvorno vozlišče: 3053672
Časovni žig: Jan 10, 2024
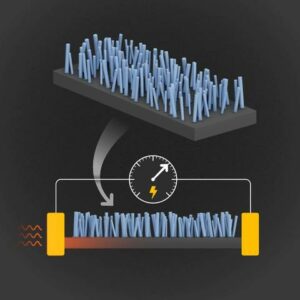
Raziskovalci prikazujejo nov način za pretvorbo toplote v elektriko
Izvorno vozlišče: 2662990
Časovni žig: Maj 19, 2023
