Predstavitev
Retrieval Augmented Generation ali RAG je mehanizem, ki pomaga, da veliki jezikovni modeli (LLM), kot je GPT, postanejo bolj uporabni in poznavalci s črpanjem informacij iz shrambe uporabnih podatkov, podobno kot pridobivanje knjige iz knjižnice. Evo, kako RAG naredi čarovnijo s preprostimi poteki dela AI:
- Baza znanja (vnos): Predstavljajte si to kot veliko knjižnico, polno uporabnih stvari – pogostih vprašanj, priročnikov, dokumentov itd. Ko se pojavi vprašanje, sistem tukaj išče odgovore.
- Sprožilec/poizvedba (vnos): To je izhodišče. Običajno gre za vprašanje ali zahtevo uporabnika, ki sistemu pove: "Hej, nekaj moraš narediti!"
- Naloga/dejanje (izhod): Ko sistem dobi sprožilec, začne delovati. Če je vprašanje, izkoplje odgovor. Če gre za zahtevo, da se nekaj naredi, se to naredi.
Zdaj pa razdelimo mehanizem RAG na preproste korake:
- Pridobivanje: Prvič, ko pride vprašanje ali zahteva, RAG pobrska po zbirki znanja in poišče ustrezne informacije.
- Povečanje: Nato vzame te podatke in jih pomeša z izvirnim vprašanjem ali zahtevo. To je kot dodajanje več podrobnosti osnovni zahtevi, da zagotovite, da jo sistem v celoti razume.
- Generation: Nazadnje, z vsemi temi bogatimi informacijami pri roki, jih vnese v velik jezikovni model, ki nato oblikuje dobro obveščen odgovor ali izvede zahtevano dejanje.
Torej, na kratko, RAG je kot imeti pametnega pomočnika, ki najprej poišče uporabne informacije, jih združi z vprašanjem, ki ga imamo pri roki, nato pa izda dobro zaokrožen odgovor ali po potrebi izvede nalogo. Na ta način z RAG vaš sistem AI ne bo samo streljal v temi; ima trdno bazo informacij za delo, zaradi česar je bolj zanesljiv in koristen.
Kakšno težavo rešujejo?
Premostitev vrzeli v znanju
Generativna umetna inteligenca, ki jo poganjajo LLM-ji, je vešča ustvarjanja besedilnih odgovorov na podlagi ogromne količine podatkov, na katerih je bila usposobljena. Čeprav to usposabljanje omogoča ustvarjanje berljivega in podrobnega besedila, je statična narava podatkov o usposabljanju kritična omejitev. Informacije v modelu sčasoma postanejo zastarele in v dinamičnem scenariju, kot je korporativni chatbot, lahko odsotnost podatkov v realnem času ali podatkov, specifičnih za organizacijo, povzroči nepravilne ali zavajajoče odzive. Ta scenarij je škodljiv, saj spodkopava uporabnikovo zaupanje v tehnologijo in predstavlja velik izziv, zlasti v aplikacijah, ki so osredotočene na stranke ali kritične.
Rešitev RAG
RAG priskoči na pomoč z združitvijo generativnih zmožnosti LLM s ciljnim iskanjem informacij v realnem času, ne da bi spremenil osnovni model. Ta fuzija omogoča sistemu umetne inteligence, da zagotovi odzive, ki niso samo kontekstualno primerni, ampak tudi temeljijo na najnovejših podatkih. Na primer, v scenariju športne lige, medtem ko bi LLM lahko zagotavljal splošne informacije o športu ali ekipah, RAG omogoča AI, da zagotavlja posodobitve v realnem času o nedavnih tekmah ali poškodbah igralcev z dostopom do zunanjih virov podatkov, kot so baze podatkov, viri novic ali celo lastna skladišča podatkov lige.
Podatki, ki ostanejo posodobljeni
Bistvo RAG je v njegovi zmožnosti razširitve LLM s svežimi podatki, specifičnimi za domeno. Nenehno posodabljanje repozitorija znanja v RAG je stroškovno učinkovit način za zagotovitev, da generativni AI ostaja aktualen. Poleg tega zagotavlja plast konteksta, ki ga generalizirani LLM nima, s čimer se izboljša kakovost odgovorov. Zmožnost prepoznavanja, popravka ali brisanja nepravilnih informacij v skladišču znanja RAG dodatno prispeva k njegovi privlačnosti, saj zagotavlja samopopravljalni mehanizem za natančnejše iskanje informacij.
Primeri delovnih tokov RAG
V razvijajočem se kraljestvu umetne inteligence Retrieval-Augmented Generation (RAG) močno vpliva na različne poslovne sektorje s tem, da znatno izboljša zmogljivosti velikih jezikovnih modelov (LLM). Oglejmo si nekaj primerov, da dobimo občutek, kako poteki dela RAG avtomatizirajo opravila –
- Pridobivanje in deljenje znanja interne ekipe:
- Scenarij: Multinacionalna korporacija z raznolikim portfeljem projektov se pogosto sooča z izzivi pri učinkoviti delitvi znanja in vpogledov v svoje ekipe. Da bi to ublažili, podjetje implementira platformo, razširjeno z RAG, za poenostavitev notranjega pridobivanja in deljenja znanja.
- Workflow:
- Pridobivanje:
- Primer poizvedbe: vodja projekta vpraša: "Ali smo v zadnjih treh letih delali na kakršnih koli projektih, povezanih z obnovljivo energijo?"
- Mehanizem RAG nemudoma preišče notranje zbirke podatkov, poročila o preteklih projektih in vsa druga relevantna skladišča, da bi pridobil informacije o sodelovanju podjetja pri projektih obnovljive energije v določenem obdobju.
- Povečanje:
- Pridobljeni podatki vključujejo naslove projektov, ključno osebje, končne rezultate in rezultate vsakega projekta.
- Prav tako lahko pridobi povezave do vseh ustreznih sporočil, predstavitev ali dokumentov, ki so bili interno v skupni rabi med potekom teh projektov.
- Generation:
- Primer odgovora: Sistem ustvari celovit odgovor:
»Da, v zadnjih treh letih smo sodelovali pri treh velikih projektih obnovljivih virov energije. Projekt 'Solar Innovations' je vodila Sarah Johnson iz ekipe za trajnostni razvoj in se je zaključil decembra 2021 z razvojem prototipa polnilne postaje na sončno energijo. Projekt »Wind Energy Efficiency«, ki ga je vodil Mark D'Souza, je bil namenjen povečanju učinkovitosti vetrnih turbin in je bil zaključen junija 2022. Nazadnje, »Renewable Energy Policy Advocacy« je bila medresorska pobuda, ki se je zaključila septembra 2022 in ustvarila predlog politike za spodbujanje sprejemanja obnovljivih virov energije v lokalnih skupnostih. Do pomembnih dokumentov, poročil in predstavitev lahko dostopate prek navedenih povezav.«
- Primer odgovora: Sistem ustvari celovit odgovor:
- Pridobivanje:
- Avtomatizirane marketinške akcije:
- Scenarij: Agencija za digitalno trženje izvaja RAG za avtomatizacijo ustvarjanja in uvajanja marketinških kampanj na podlagi tržnih trendov v realnem času in vedenja potrošnikov.
- Potek dela:
- Pridobivanje: vsakič, ko v sistem pride nova potencialna stranka, mehanizem RAG pridobi ustrezne podrobnosti o potencialni stranki in njihovi organizaciji ter sproži začetek poteka dela.
- Povečanje: Te podatke združuje s tržnimi cilji stranke, smernicami blagovne znamke in ciljno demografijo.
- Izvedba naloge: Sistem avtonomno oblikuje in uvaja prilagojeno marketinško kampanjo po različnih digitalnih kanalih, da izkoristi prepoznani trend, pri čemer spremlja uspešnost kampanje v realnem času za morebitne prilagoditve.
- Pravne raziskave in priprava primerov:
- Scenarij: Odvetniška družba integrira RAG za pospešitev pravnih raziskav in priprave primerov.
- Potek dela:
- Pridobivanje: Ob vnosu o novem primeru prikaže ustrezne pravne precedense, statute in nedavne sodbe.
- Povečanje: Te podatke povezuje s podrobnostmi primera.
- Generation: Sistem pripravi osnutek predhodnega primera, kar znatno skrajša čas, ki ga odvetniki porabijo za predhodne raziskave.
- Izboljšanje storitev za stranke:
- Scenarij: Telekomunikacijsko podjetje implementira klepetalnega robota, razširjenega z RAG, za obravnavanje poizvedb strank glede podrobnosti načrta, zaračunavanja in odpravljanja pogostih težav.
- Potek dela:
- Pridobivanje: Ko prejme poizvedbo o dovoljenih podatkih določenega načrta, se sistem sklicuje na najnovejše načrte in ponudbe iz svoje baze podatkov.
- Povečanje: Te pridobljene informacije združuje s podrobnostmi strankinega trenutnega načrta (iz profila stranke) in izvirno poizvedbo.
- Generation: Sistem generira prilagojen odgovor, ki pojasnjuje razlike v dovoljenih podatkih med strankinim trenutnim načrtom in načrtom, za katerega je zahteval poizvedbo.
- Upravljanje zalog in prerazporejanje:
- Scenarij: Podjetje za e-trgovino uporablja RAG-razširjeni sistem za upravljanje inventarja in samodejno prenaročanje izdelkov, ko ravni zalog padejo pod vnaprej določeno mejo.
- Workflow:
- Pridobivanje: Ko zaloga izdelka doseže nizko raven, sistem iz svoje baze podatkov preveri zgodovino prodaje, sezonska nihanja povpraševanja in trenutne tržne trende.
- Povečanje: S kombiniranjem pridobljenih podatkov s pogostostjo ponovnega naročanja izdelka, dobavnimi roki in podrobnostmi o dobavitelju določi optimalno količino za ponovno naročanje.
- Izvedba naloge: Sistem se nato poveže s programsko opremo podjetja za nabavo, da samodejno odda naročilo pri dobavitelju in tako zagotovi, da platformi za e-trgovino nikoli ne zmanjka priljubljenih izdelkov.
- Uvajanje zaposlenih in nastavitev IT:
- Scenarij: Večnacionalna korporacija uporablja sistem, ki ga poganja RAG, da poenostavi proces vključevanja novih zaposlenih in zagotovi, da so vse zahteve za IT nastavljene pred prvim delovnim dnem zaposlenega.
- Workflow:
- Pridobivanje: Po prejemu podrobnosti o novem najemu se sistem posvetuje s kadrovsko bazo podatkov, da določi vlogo, oddelek in lokacijo zaposlenega.
- Povečanje: Te informacije povezuje s politiko IT podjetja in določa programsko, strojno opremo in dovoljenja za dostop, ki jih bo potreboval novi zaposleni.
- Izvedba naloge: Sistem nato komunicira s sistemom za izdajo vstopnic oddelka za IT in samodejno generira vstopnice za postavitev nove delovne postaje, namestitev potrebne programske opreme in odobritev ustreznega dostopa do sistema. To zagotavlja, da je ob začetku dela novega zaposlenega njegova delovna postaja pripravljena in se lahko takoj potopi v svoje odgovornosti.
Ti primeri poudarjajo vsestranskost in praktične prednosti uporabe delovnih tokov RAG pri obravnavanju zapletenih poslovnih izzivov v realnem času na številnih področjih.
Povežite svoje podatke in aplikacije s pomočnikom Nanonets AI Assistant za klepet s podatki, uvajanje klepetalnih botov in agentov po meri ter ustvarjanje delovnih tokov RAG.
Kako zgraditi lastne delovne tokove RAG?
Postopek gradnje poteka dela RAG
Postopek gradnje delovnega toka RAG (Retrieval Augmented Generation) je mogoče razčleniti na več ključnih korakov. Te korake je mogoče razvrstiti v tri glavne procese: zaužitje, iskanjein generacija, ter nekaj dodatnih priprav:
1. Priprava:
- Priprava baze znanja: Pripravite repozitorij podatkov ali bazo znanja tako, da vnesete podatke iz različnih virov – aplikacij, dokumentov, baz podatkov. Ti podatki morajo biti oblikovani tako, da omogočajo učinkovito iskanje, kar v bistvu pomeni, da morajo biti ti podatki oblikovani v poenoteno predstavitev objekta 'Dokument'.
2. Postopek zaužitja:
- Nastavitev vektorske baze podatkov: Uporabite vektorske baze podatkov kot baze znanja, ki uporabljajo različne algoritme indeksiranja za organiziranje visokodimenzionalnih vektorjev, kar omogoča hitro in robustno zmožnost poizvedovanja.
- Izvleček podatkov: Izvlecite podatke iz teh dokumentov.
- Razdelitev podatkov: Razčlenite dokumente na dele podatkovnih odsekov.
- Vdelava podatkov: Pretvorite te dele v vdelave z uporabo modela vdelav, kot je tisti, ki ga ponuja OpenAI.
- Razvijte mehanizem za vnos vaše uporabniške poizvedbe. To je lahko uporabniški vmesnik ali potek dela, ki temelji na API-ju.
3. Postopek pridobivanja:
- Vdelava poizvedbe: Pridobite vdelavo podatkov za uporabniško poizvedbo.
- Pridobivanje kosov: Izvedite hibridno iskanje, da poiščete najbolj ustrezne shranjene dele v vektorski podatkovni zbirki na podlagi vdelave poizvedbe.
- Vlečenje vsebine: Povlecite najbolj ustrezno vsebino iz svoje baze znanja v svoj poziv kot kontekst.
4. Postopek generiranja:
- Generiranje poziva: Združite pridobljene informacije z izvirno poizvedbo, da oblikujete poziv. Zdaj lahko izvedete –
- Generiranje odziva: Pošljite kombinirano pozivno besedilo LLM (Large Language Model), da ustvarite dobro informiran odgovor.
- Izvedba naloge: Pošljite kombinirano pozivno besedilo svojemu podatkovnemu agentu LLM, ki bo ugotovil pravilno nalogo, ki jo je treba izvesti na podlagi vaše poizvedbe, in jo izvedel. Ustvarite lahko na primer podatkovnega agenta za Gmail in ga nato pozovete, naj »pošlje promocijska e-poštna sporočila nedavnim potencialnim strankam Hubspot« in podatkovni agent bo –
- pridobite nedavne potencialne stranke iz Hubspota.
- uporabite svojo bazo znanja, da pridobite ustrezne informacije o potencialnih strankah. Vaša baza znanja lahko zajema podatke iz več virov podatkov – LinkedIn, Lead Enrichment API-ji itd.
- pripravite prilagojena promocijska e-poštna sporočila za vsako potencialno stranko.
- pošljite ta e-poštna sporočila s svojim ponudnikom e-pošte / upraviteljem e-poštnih kampanj.
5. Konfiguracija in optimizacija:
- Prilagajanje: Prilagodite delovni tok, da bo ustrezal posebnim zahtevam, kar lahko vključuje prilagoditev toka vnosa, kot je predprocesiranje, razčlenjevanje in izbira modela vdelave.
- Optimizacija: Izvedite optimizacijske strategije za izboljšanje kakovosti pridobivanja in zmanjšanje števila žetonov za obdelavo, kar bi lahko privedlo do optimizacije učinkovitosti in stroškov v obsegu.
Implementing One Yourself
Implementacija delovnega toka Retrieval Augmented Generation (RAG) je kompleksna naloga, ki vključuje številne korake in dobro razumevanje osnovnih algoritmov in sistemov. Spodaj so poudarjeni izzivi in koraki za njihovo premagovanje za tiste, ki želijo implementirati potek dela RAG:
Izzivi pri ustvarjanju lastnega delovnega procesa RAG:
- Novosti in pomanjkanje ustaljenih praks: RAG je razmeroma nova tehnologija, prvič predlagana leta 2020, razvijalci pa še vedno ugotavljajo najboljše prakse za implementacijo mehanizmov za iskanje informacij v generativni AI.
- Cena: Implementacija RAG bo dražja kot uporaba samega Large Language Model (LLM). Vendar pa je ceneje kot pogosto prekvalificiranje LLM.
- Strukturiranje podatkov: Ključni izziv je določiti, kako najbolje modelirati strukturirane in nestrukturirane podatke v knjižnici znanja in vektorski bazi podatkov.
- Prirastno dovajanje podatkov: Razvoj procesov za postopno dovajanje podatkov v sistem RAG je ključnega pomena.
- Netočnosti pri ravnanju: Potrebna je uvedba postopkov za obravnavanje poročil o netočnostih in popravljanje ali brisanje teh virov informacij v sistemu RAG.
Povežite svoje podatke in aplikacije s pomočnikom Nanonets AI Assistant za klepet s podatki, uvajanje klepetalnih botov in agentov po meri ter ustvarjanje delovnih tokov RAG.
Kako začeti z ustvarjanjem lastnega poteka dela RAG:
Implementacija delovnega toka RAG zahteva mešanico tehničnega znanja, pravih orodij ter nenehnega učenja in optimizacije, da se zagotovi učinkovitost in učinkovitost pri doseganju vaših ciljev. Za tiste, ki želijo sami izvajati poteke dela RAG, smo pripravili seznam obsežnih praktičnih vodnikov, ki vas podrobno popeljejo skozi postopke implementacije –
Vsaka vadnica je opremljena z edinstvenim pristopom ali platformo za doseganje želene izvedbe na določenih temah.
Če se želite poglobiti v gradnjo lastnih delovnih tokov RAG, vam priporočamo, da si ogledate vse zgoraj navedene članke, da dobite celovit občutek, potreben za začetek vaše poti.
Implementirajte delovne tokove RAG z uporabo platform ML
Medtem ko privlačnost izdelave delovnega toka Retrieval Augmented Generation (RAG) od začetka ponuja določen občutek dosežka in prilagajanja, je to nedvomno zapleten podvig. Ker se zavedajo zapletenosti in izzivov, je več podjetij stopilo naprej in ponudilo specializirane platforme in storitve za poenostavitev tega procesa. Izkoriščanje teh platform ne more le prihraniti dragocenega časa in virov, ampak tudi zagotoviti, da implementacija temelji na najboljših praksah v industriji in je optimizirana za učinkovitost.
Za organizacije ali posameznike, ki morda nimajo pasovne širine ali strokovnega znanja za izdelavo sistema RAG iz nič, te platforme ML predstavljajo izvedljivo rešitev. Če se odločite za te platforme, lahko:
- Zaobidite tehnične zaplete: Izogibajte se zapletenim korakom procesov strukturiranja, vdelave in iskanja podatkov. Te platforme pogosto prihajajo z vnaprej zgrajenimi rešitvami in ogrodji, prilagojenimi za poteke dela RAG.
- Izkoristite strokovno znanje: Izkoristite strokovno znanje strokovnjakov, ki dobro razumejo sisteme RAG in so že obravnavali številne izzive, povezane z njihovim izvajanjem.
- Prilagodljivost: Te platforme so pogosto zasnovane z mislijo na razširljivost, kar zagotavlja, da se sistem lahko prilagaja brez popolne prenove, ko vaši podatki rastejo ali se vaše zahteve spreminjajo.
- Stroškovna učinkovitost: Čeprav so z uporabo platforme povezani stroški, se lahko dolgoročno izkaže za stroškovno učinkovitejše, zlasti če upoštevamo stroške odpravljanja težav, optimizacije in morebitnih ponovnih uvedb.
Oglejmo si platforme, ki ponujajo zmožnosti ustvarjanja poteka dela RAG.
Nanoneti
Nanonets ponuja varne pomočnike AI, klepetalne robote in poteke dela RAG, ki jih poganjajo podatki vašega podjetja. Omogoča sinhronizacijo podatkov v realnem času med različnimi viri podatkov, kar ekipam olajša celovito iskanje informacij. Platforma omogoča ustvarjanje chatbotov skupaj z uvajanjem kompleksnih delovnih tokov prek naravnega jezika, ki ga poganjajo veliki jezikovni modeli (LLM). Zagotavlja tudi podatkovne konektorje za branje in pisanje podatkov v vaših aplikacijah ter možnost uporabe agentov LLM za neposredno izvajanje dejanj v zunanjih aplikacijah.
Stran izdelka Nanonets AI Assistant
AWS Generative AI
AWS ponuja različne storitve in orodja pod svojim okriljem Generative AI za zadovoljitev različnih poslovnih potreb. Omogoča dostop do širokega nabora vodilnih modelov temeljev različnih ponudnikov prek Amazon Bedrock. Uporabniki lahko prilagodijo te temeljne modele s svojimi podatki, da ustvarijo bolj prilagojene in drugačne izkušnje. AWS poudarja varnost in zasebnost ter zagotavlja zaščito podatkov pri prilagajanju temeljnih modelov. Izpostavlja tudi stroškovno učinkovito infrastrukturo za skaliranje generativne umetne inteligence z možnostmi, kot so AWS Trainium, AWS Inferentia in grafični procesorji NVIDIA za doseganje najboljše cenovne zmogljivosti. Poleg tega AWS olajša gradnjo, usposabljanje in uvajanje temeljnih modelov na Amazon SageMaker, s čimer razširi moč temeljnih modelov na uporabnikove posebne primere uporabe.
Stran izdelka AWS Generative AI
Generativni AI v Google Cloudu
Generative AI Google Cloud ponuja robusten nabor orodij za razvoj modelov AI, izboljšanje iskanja in omogočanje pogovorov, ki jih poganja AI. Odlikuje ga analiza občutkov, obdelava jezika, govorne tehnologije in avtomatizirano upravljanje dokumentov. Poleg tega lahko ustvari poteke dela RAG in agente LLM, ki z večjezičnim pristopom izpolnjujejo različne poslovne zahteve, zaradi česar je celovita rešitev za različne potrebe podjetij.
Oracle Generative AI
Oraclov Generative AI (OCI Generative AI) je prilagojen podjetjem in ponuja vrhunske modele v kombinaciji z odličnim upravljanjem podatkov, infrastrukturo AI in poslovnimi aplikacijami. Omogoča izboljšanje modelov z uporabo uporabnikovih lastnih podatkov, ne da bi jih delil z velikimi ponudniki jezikovnih modelov ali drugimi strankami, s čimer zagotavlja varnost in zasebnost. Platforma omogoča uvajanje modelov v namenske gruče AI za predvidljivo delovanje in cene. OCI Generative AI ponuja različne primere uporabe, kot so povzemanje besedila, ustvarjanje kopij, ustvarjanje chatbota, slogovno pretvorbo, klasifikacijo besedila in iskanje podatkov, s čimer obravnava širok spekter potreb podjetij. Obdeluje uporabniški vnos, ki lahko vključuje naravni jezik, primere vnosa/izhoda in navodila, za generiranje, povzemanje, preoblikovanje, ekstrahiranje informacij ali razvrščanje besedila na podlagi zahtev uporabnika, pri čemer pošlje nazaj odgovor v podani obliki.
cloudera
Na področju generativne umetne inteligence se Cloudera kaže kot zaupanja vreden zaveznik podjetij. Njihova jezerska hiša odprtih podatkov, dostopna v javnih in zasebnih oblakih, je temelj. Ponujajo nabor podatkovnih storitev, ki pomagajo pri celotnem življenjskem ciklu podatkov, od roba do umetne inteligence. Njihove zmogljivosti segajo do pretakanja podatkov v realnem času, shranjevanja in analize podatkov v odprtih jezerih ter uvajanja in spremljanja modelov strojnega učenja prek podatkovne platforme Cloudera. Pomembno je, da Cloudera omogoča ustvarjanje delovnih tokov Retrieval Augmented Generation, ki združuje močno kombinacijo zmogljivosti pridobivanja in generiranja za izboljšane aplikacije AI.
Zbrati
Glean uporablja AI za izboljšanje iskanja na delovnem mestu in odkrivanja znanja. Izkorišča vektorsko iskanje in velike jezikovne modele, ki temeljijo na poglobljenem učenju, za semantično razumevanje poizvedb in nenehno izboljšuje ustreznost iskanja. Ponuja tudi pomočnika Generative AI za odgovarjanje na vprašanja in povzemanje informacij v dokumentih, vstopnicah in drugem. Platforma zagotavlja prilagojene rezultate iskanja in predlaga informacije na podlagi dejavnosti uporabnikov in trendov, poleg tega pa omogoča preprosto nastavitev in integracijo z več kot 100 priključki za različne aplikacije.
landbot
Landbot ponuja zbirko orodij za ustvarjanje pogovornih izkušenj. Omogoča ustvarjanje potencialnih strank, angažiranje strank in podporo prek chatbotov na spletnih mestih ali WhatsApp. Uporabniki lahko oblikujejo, uvajajo in spreminjajo klepetalne robote z graditeljem brez kode ter jih integrirajo s priljubljenimi platformami, kot sta Slack in Messenger. Ponuja tudi različne predloge za različne primere uporabe, kot so ustvarjanje potencialnih strank, podpora strankam in promocija izdelkov
Klepetalnica
Chatbase ponuja platformo za prilagoditev ChatGPT, da se uskladi z osebnostjo blagovne znamke in videzom spletnega mesta. Omogoča zbiranje potencialnih strank, dnevne povzetke pogovorov in integracijo z drugimi orodji, kot so Zapier, Slack in Messenger. Platforma je zasnovana tako, da podjetjem nudi prilagojeno izkušnjo chatbota.
AI lestvice
Scale AI obravnava ozko grlo pri razvoju aplikacij AI s ponudbo natančnega prilagajanja in RLHF za prilagajanje temeljnih modelov specifičnim poslovnim potrebam. Integrira ali sodeluje z vodilnimi modeli AI, kar podjetjem omogoča vključitev njihovih podatkov za strateško razlikovanje. Skupaj z možnostjo ustvarjanja delovnih tokov RAG in agentov LLM Scale AI zagotavlja generativno platformo AI s polnim skladom za pospešen razvoj aplikacij AI.
Shakudo – LLM rešitve
Shakudo ponuja enotno rešitev za uvajanje velikih jezikovnih modelov (LLM), upravljanje vektorskih baz podatkov in vzpostavitev robustnih podatkovnih cevovodov. Poenostavlja prehod z lokalnih predstavitev na storitve LLM proizvodnega razreda s spremljanjem v realnem času in avtomatizirano orkestracijo. Platforma podpira prilagodljive operacije generativne umetne inteligence, visoko zmogljive vektorske baze podatkov in ponuja vrsto specializiranih orodij LLMOps, ki povečujejo funkcionalno bogastvo obstoječih tehnoloških nizov.
Stran izdelka Shakundo RAG Workflows
Vsaka omenjena platforma/podjetje ima svoj nabor edinstvenih funkcij in zmogljivosti in bi jih bilo mogoče nadalje raziskati, da bi razumeli, kako bi jih lahko izkoristili za povezovanje podatkov podjetja in izvajanje delovnih tokov RAG.
Povežite svoje podatke in aplikacije s pomočnikom Nanonets AI Assistant za klepet s podatki, uvajanje klepetalnih botov in agentov po meri ter ustvarjanje delovnih tokov RAG.
Poteki dela RAG z nanoneti
Na področju dopolnjevanja jezikovnih modelov za zagotavljanje natančnejših in pronicljivih odzivov je Retrieval Augmented Generation (RAG) osrednji mehanizem. Ta zapleten proces dviguje zanesljivost in uporabnost sistemov umetne inteligence ter zagotavlja, da ne delujejo zgolj v informacijskem vakuumu.
V središču tega se Nanonets AI Assistant pojavi kot varen, večnamenski spremljevalec AI, zasnovan za premostitev vrzeli med vašim organizacijskim znanjem in velikimi jezikovnimi modeli (LLM), vse v uporabniku prijaznem vmesniku.
Tukaj je vpogled v brezhibno integracijo in izboljšavo poteka dela, ki jo ponujajo zmogljivosti Nanonets RAG:
Podatkovna povezljivost:
Nanonets omogoča brezhibne povezave z več kot 100 priljubljenimi aplikacijami za delovni prostor, vključno s Slack, Notion, Google Suite, Salesforce in Zendesk, med drugim. Spreten je pri ravnanju s širokim spektrom vrst podatkov, pa naj bodo to nestrukturirani, kot so PDF-ji, TXT-ji, slike, zvočne in video datoteke, ali strukturirani podatki, kot so CSV-ji, preglednice, baze podatkov MongoDB in SQL. Ta podatkovna povezljivost širokega spektra zagotavlja zanesljivo bazo znanja za mehanizem RAG.
Sprožilni in akcijski agenti:
Z Nanonets je nastavitev sprožilnih/dejavnih agentov prava stvar. Ti agenti so pozorni na dogodke v aplikacijah vašega delovnega prostora in po potrebi sprožijo dejanja. Vzpostavite na primer potek dela za spremljanje novih e-poštnih sporočil podpora@vaše_podjetje.com, uporabite svojo dokumentacijo in pretekle e-poštne pogovore kot bazo znanja, sestavite pronicljiv e-poštni odgovor in ga pošljite, vse brezhibno orkestrirano.
Poenostavljeno vnašanje in indeksiranje podatkov:
Optimiziran vnos podatkov in indeksiranje sta del paketa, ki zagotavlja gladko obdelavo podatkov, ki jo v ozadju upravlja Nanonets AI Assistant. Ta optimizacija je ključnega pomena za sinhronizacijo v realnem času z viri podatkov, saj zagotavlja, da ima mehanizem RAG najnovejše informacije za delo.
Za začetek se lahko obrnete na enega od naših strokovnjakov za umetno inteligenco in ponudimo vam prilagojeno predstavitev in preizkus Nanonets AI Assistant na podlagi vašega primera uporabe.
Ko je nastavljen, lahko uporabite pomočnika Nanonets AI Assistant za –
Ustvarite potek dela RAG Chat
Opolnomočite svoje ekipe z izčrpnimi informacijami v realnem času iz vseh vaših virov podatkov.

Ustvarite potek dela agenta RAG
Uporabite naravni jezik za ustvarjanje in izvajanje kompleksnih delovnih tokov, ki jih poganjajo LLM-ji, ki sodelujejo z vsemi vašimi aplikacijami in podatki.

Namestite klepetalne robote, ki temeljijo na RAG
Zgradite in uvedite pripravljene za uporabo prilagojene AI Chatbote, ki vas poznajo v nekaj minutah.
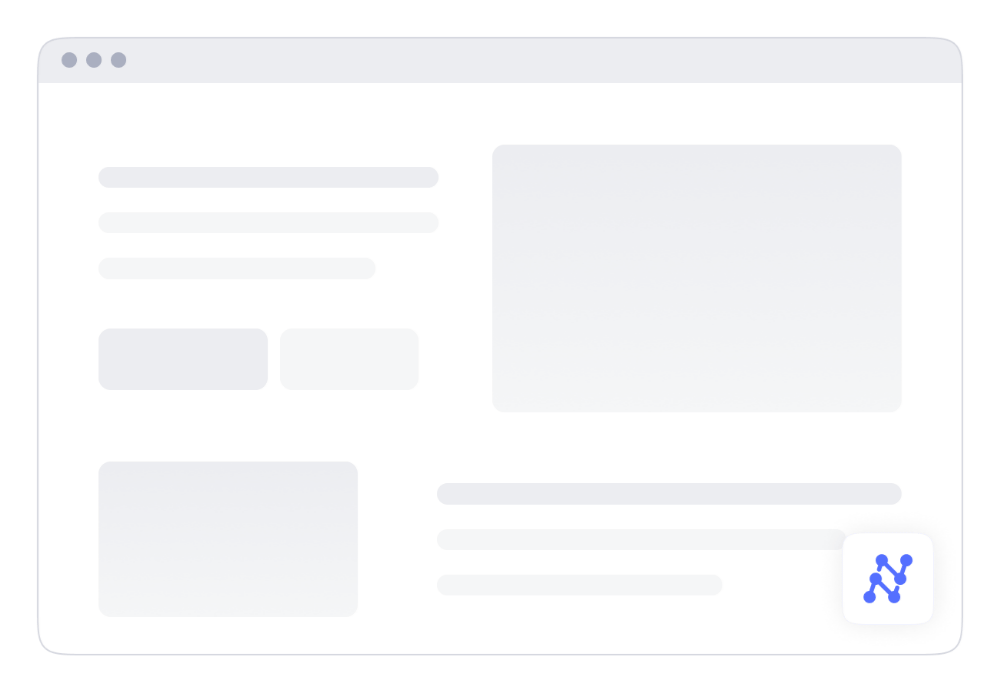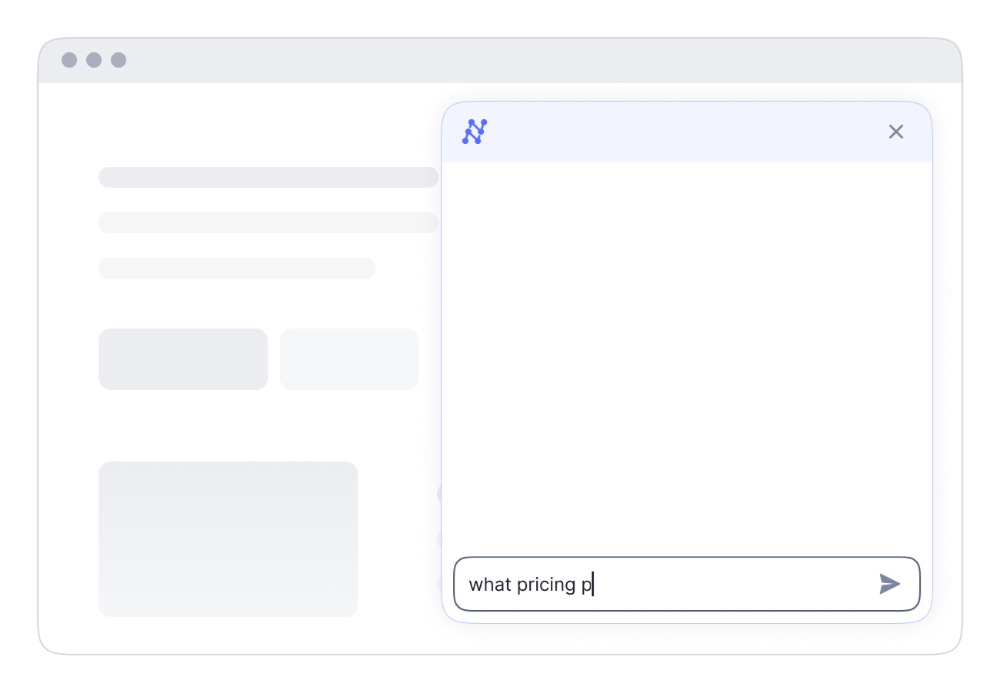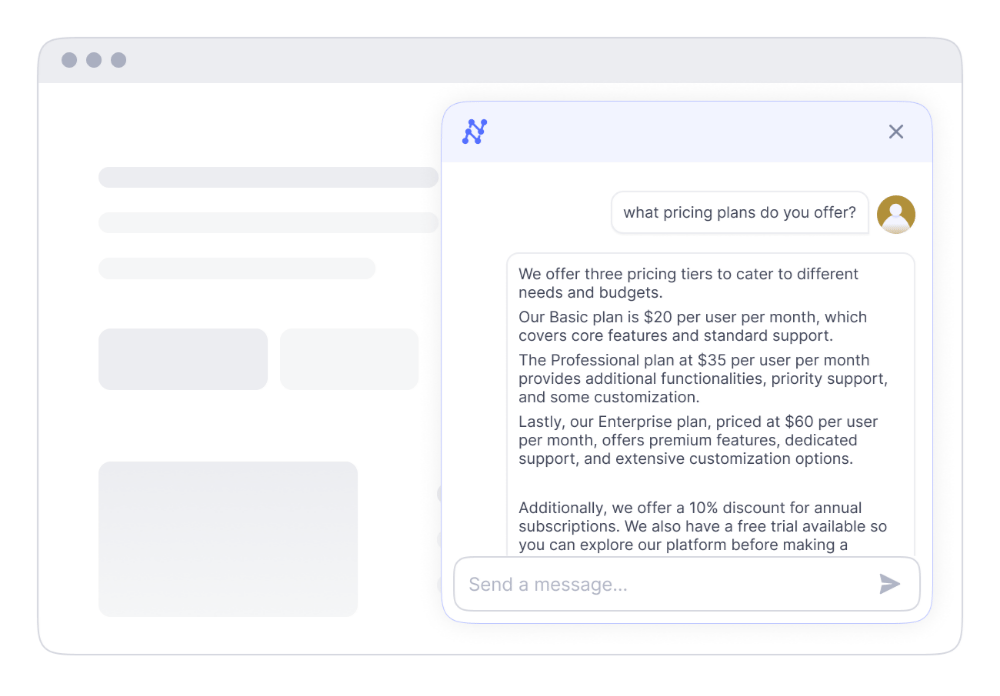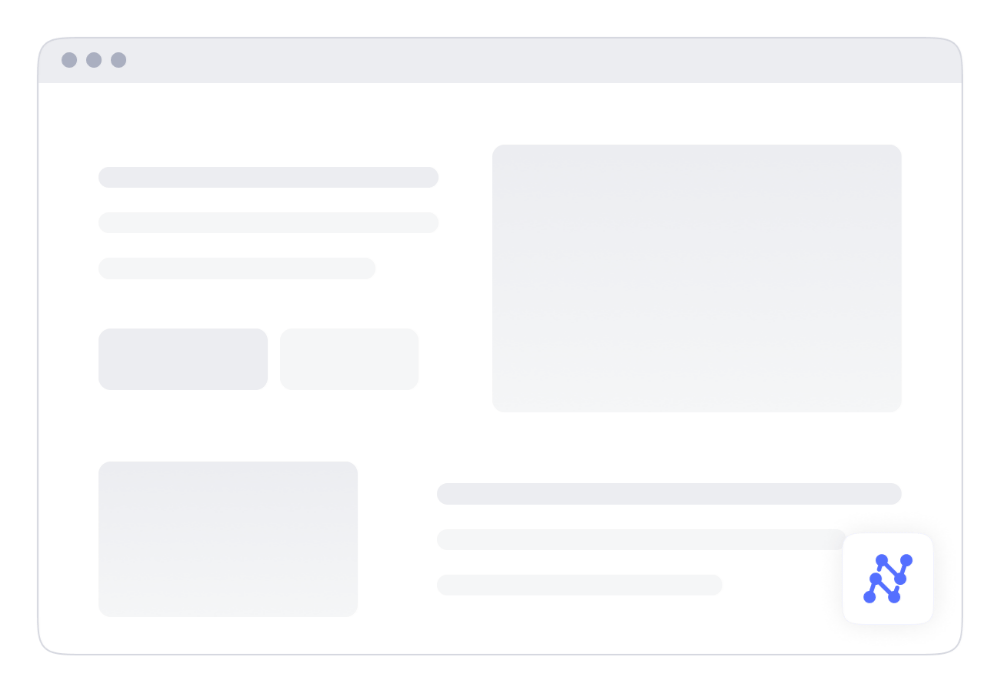
Povečajte učinkovitost svoje ekipe
Z umetno inteligenco Nanonets ne integrirate samo podatkov; nadgrajujete zmogljivosti svoje ekipe. Z avtomatizacijo vsakodnevnih opravil in zagotavljanjem pronicljivih odgovorov lahko vaše ekipe preusmerijo svojo osredotočenost na strateške pobude.
Nanonetsov AI Assistant, ki ga poganja RAG, je več kot le orodje; je katalizator, ki poenostavi delovanje, izboljša dostopnost podatkov in požene vašo organizacijo v prihodnost informiranega odločanja in avtomatizacije.
Povežite svoje podatke in aplikacije s pomočnikom Nanonets AI Assistant za klepet s podatki, uvajanje klepetalnih botov in agentov po meri ter ustvarjanje delovnih tokov RAG.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://nanonets.com/blog/retrieval-augmented-generation/
- :ima
- : je
- :ne
- :kje
- $GOR
- 100
- 2020
- 2021
- 2022
- a
- sposobnost
- O meni
- nad
- pospešeno
- dostop
- dostopna
- dostopnost
- dostopen
- Dostop
- natančna
- Doseči
- čez
- Ukrep
- dejavnosti
- dejavnost
- prilagodijo
- dodajanje
- Dodatne
- Poleg tega
- naslovljena
- naslovi
- naslavljanje
- Dodaja
- prilagajanje
- Popravki
- Sprejetje
- zagovorništvo
- agencija
- Agent
- agenti
- AI
- Pomočnik AI
- AI modeli
- AI platforma
- AI sistemi
- Namerjen
- algoritmi
- uskladiti
- vsi
- ublažiti
- omogočajo
- omogoča
- privlačnost
- Ally
- sam
- skupaj
- že
- Prav tako
- Amazon
- Amazon SageMaker
- med
- znesek
- an
- Analiza
- in
- odgovor
- odgovori
- kaj
- API-ji
- pritožbe
- uporaba
- Razvoj aplikacij
- aplikacije
- pristop
- primerno
- aplikacije
- APT
- SE
- članki
- umetni
- Umetna inteligenca
- AS
- Pomočnik
- pomočniki
- povezan
- At
- audio
- povečanje
- Povečana
- avtomatizirati
- Avtomatizirano
- samodejno
- avtomatizacija
- Avtomatizacija
- avtonomno
- izogniti
- AWS
- Sklepanje AWS
- nazaj
- ozadje
- pasovna širina
- baza
- temeljijo
- Osnovni
- V bistvu
- BE
- postanejo
- postane
- pred
- vedenje
- spodaj
- koristi
- Prednosti
- poleg tega
- BEST
- najboljše prakse
- med
- Big
- zaračunavanje
- Blend
- mešanice
- Blog
- Knjiga
- tako
- blagovne znamke
- Break
- MOST
- Broken
- izgradnjo
- builder
- Building
- poslovni
- Poslovne aplikacije
- podjetja
- vendar
- by
- klic
- Akcija
- Kampanje
- CAN
- Lahko dobiš
- Zmogljivosti
- kapitalizirati
- primeru
- primeri
- Katalizator
- poskrbi
- nekatere
- izziv
- izzivi
- spremenite
- kanali
- polnjenje
- chatbot
- klepetalnice
- ChatGPT
- preverjanje
- Pregledi
- Razvrstitev
- Razvrsti
- Cloud
- cloudera
- zbirka
- COM
- kombinacija
- združujejo
- kombinirani
- združuje
- združevanje
- kako
- prihaja
- Skupno
- Communications
- skupnosti
- spremljevalec
- podjetje
- dokončanje
- Končana
- kompleksna
- celovito
- sklenjene
- Povezovanje
- povezave
- Povezovanje
- upoštevamo
- gradnjo
- Potrošnik
- vedenje potrošnikov
- vsebina
- ozadje
- neprekinjeno
- stalno
- Pogovor
- pogovorni
- pogovorov
- Pretvorba
- kamen
- Corporate
- KORPORACIJA
- popravi
- strošek
- stroškovno učinkovito
- drago
- stroški
- bi
- skupaj
- Tečaj
- ustvarjajo
- Ustvarjanje
- Oblikovanje
- kritično
- ključnega pomena
- kurirano
- Trenutna
- po meri
- stranka
- Angažiranje strank
- Pomoč strankam
- Stranke, ki so
- customization
- prilagodite
- vsak dan
- Temnomodra
- datum
- Upravljanje podatkov
- Podatkovna platforma
- obdelava podatkov
- Varstvo podatkov
- shranjevanje podatkov
- Baze podatkov
- baze podatkov
- dan
- december
- december 2021
- Odločanje
- namenjen
- globoko
- poda
- potopite
- Povpraševanje
- Predstavitev
- Demografski podatki
- Predstavitve
- Oddelek
- razporedi
- uvajanja
- uvajanje
- razpolaga
- Oblikovanje
- zasnovan
- modeli
- želeno
- Podatki
- podrobno
- Podrobnosti
- Ugotovite,
- določa
- določanje
- škodljive
- Razvijalci
- razvoju
- Razvoj
- razlike
- drugačen
- razlikovati
- digitalni
- digitalni marketing
- neposredno
- Odkritje
- potop
- razne
- raznolika
- raznolik portfelj
- do
- dokument
- upravljanje dokumentov
- Dokumentacija
- Dokumenti
- domen
- opravljeno
- navzdol
- Osnutek
- med
- dinamično
- e-trgovina
- vsak
- lahka
- Edge
- učinkovitost
- učinkovitosti
- učinkovite
- učinkovito
- bodisi
- povzdigne
- E-naslov
- e-pošta
- vdelava
- nastane
- poudarja
- Zaposlen
- Zaposleni
- zaposlovanja
- zaposluje
- pooblašča
- omogoča
- omogočanje
- prizadevati
- energija
- energetske učinkovitosti
- energetski projekti
- , ki se ukvarjajo
- sodelovanje
- okrepi
- okrepljeno
- Izboljšave
- Izboljša
- izboljšanje
- zagotovitev
- zagotavlja
- zagotoviti
- Podjetje
- podjetja
- Celotna
- zlasti
- Bistvo
- vzpostaviti
- ustanovljena
- vzpostavitev
- itd
- Eter (ETH)
- Tudi
- dogodki
- razvija
- Primer
- Primeri
- odlično
- izvedba
- obstoječih
- pospešiti
- drago
- izkušnje
- Doživetja
- strokovno znanje
- Strokovnjaki
- pojasnjujejo
- Raziskano
- razširiti
- razširitev
- zunanja
- ekstrakt
- pridobivanje
- obrazi
- olajša
- olajšanje
- Padec
- FAST
- Lastnosti
- hranjenje
- Nekaj
- datoteke
- končna
- Najdi
- Firm
- prva
- fit
- prilagodljiv
- Pretok
- nihanja
- Osredotočite
- za
- obrazec
- format
- Naprej
- Fundacija
- okviri
- frekvenca
- pogosto
- sveže
- iz
- polno
- v celoti
- funkcionalno
- nadalje
- fuzija
- Prihodnost
- Games
- vrzel
- ustvarjajo
- ustvarja
- ustvarjajo
- generacija
- generativno
- Generativna AI
- dobili
- gif
- Daj
- daje
- Pogled
- gmail
- dobro
- Grafične kartice
- odobri
- Igrišče
- raste
- Smernice
- Vodniki
- strani
- ročaj
- Ravnanje
- hands-on
- strojna oprema
- Imajo
- ob
- vodil
- Srce
- pomoč
- Pomaga
- Poudarjeno
- Poudarki
- najem
- zgodovina
- celosten
- Kako
- Kako
- Vendar
- hr
- HTTPS
- HubSpot
- Hybrid
- i
- identificirati
- identificirati
- if
- slike
- takoj
- vpliv
- izvajati
- Izvajanje
- izvajanja
- izvedbe
- izboljšanje
- izboljšanju
- in
- vključujejo
- vključuje
- Vključno
- vključi
- posamezniki
- Industrija
- vodilne
- info
- Podatki
- obvestila
- Infrastruktura
- začetku
- pobuda
- pobud
- novosti
- vhod
- pronicljiv
- vpogledi
- namestitev
- primer
- takoj
- Navodila
- integrirati
- Integrira
- Povezovanje
- integracija
- Intelligence
- interakcijo
- vmesnik
- vmesniki
- notranji
- interno
- v
- zapletenosti
- zapleten
- Predstavitev
- inventar
- sodelovanje
- vključuje
- Vprašanja
- IT
- ITS
- Johnson
- Potovanje
- junij
- samo
- Ključne
- Vedite
- znanje
- Pomanjkanje
- jezik
- velika
- nazadnje
- Zadnji
- zakon
- odvetniška pisarna
- plast
- vodi
- vodi
- Interesenti
- Liga
- učenje
- Led
- Pravne informacije
- manj
- Naj
- Stopnja
- ravni
- finančni vzvod
- Leverages
- vzvod
- Knjižnica
- Leži
- življenski krog
- kot
- Omejitev
- Povezave
- Seznam
- Navedeno
- lokalna
- kraj aktivnosti
- Long
- Poglej
- si
- POGLEDI
- nizka
- stroj
- strojno učenje
- magic
- Glavne
- velika
- Znamka
- IZDELA
- Izdelava
- upravljanje
- upravljanje
- upravitelj
- upravljanje
- več
- znamka
- Tržna
- Tržni trendi
- Trženje
- marketinško agencijo
- Marketinške kampanje
- Maj ..
- pomeni
- Mehanizem
- Mehanizmi
- srečanja
- omenjeno
- zgolj
- Messenger
- morda
- moti
- min
- zavajajoče
- mešanice
- ML
- Model
- modeli
- MongoDB
- monitor
- spremljanje
- več
- Poleg tega
- Najbolj
- veliko
- multinacionalno
- več
- nešteto
- naravna
- Naravni jezik
- Narava
- potrebno
- Nimate
- potrebna
- potrebe
- nikoli
- Novo
- novice
- Naslednja
- Pojem
- zdaj
- številne
- Nutshell
- Nvidia
- predmet
- Cilji
- of
- off
- ponudba
- ponujen
- ponujanje
- Ponudbe
- pogosto
- on
- Na vkrcanje
- enkrat
- ONE
- samo
- odprite
- Odpri podatki
- OpenAI
- deluje
- operacije
- optimalna
- optimizacija
- optimizirana
- možnosti
- or
- Oracle
- orkestrirana
- orkestracijo
- Da
- Organizacija
- organizacijsko
- organizacije
- izvirno
- Ostalo
- drugi
- naši
- ven
- rezultatov
- izhod
- več
- Premagajte
- Remont
- lastne
- paket
- del
- partnerji
- preteklosti
- opravlja
- performance
- opravlja
- Obdobje
- Dovoljenja
- Osebnost
- Prilagojene
- osebje
- ključno
- Kraj
- Načrt
- načrti
- platforma
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- predvajalnik
- Točka
- politike
- politika
- Pops
- Popular
- Portfelj
- mogoče
- potencial
- moč
- poganja
- močan
- Praktično
- vaje
- natančna
- Predvidljivo
- predhodno
- Priprava
- Pripravimo
- predstaviti
- Predstavitve
- Cena
- cenitev
- zasebnost
- zasebna
- problem
- Postopek
- Procesi
- obravnavati
- naročil
- Izdelek
- Izdelki
- strokovnjaki
- profil
- Projekt
- projekti
- Spodbujanje
- promocijsko
- snubitev
- predlagano
- zaščita
- Prototip
- Dokaži
- zagotavljajo
- če
- Ponudnik
- ponudniki
- zagotavlja
- zagotavljanje
- javnega
- vlečenje
- Potegne
- nakup
- naročila
- Dajanje
- kakovost
- Količina
- poizvedbe
- vprašanje
- območje
- RE
- Doseže
- Preberi
- pripravljen
- v realnem času
- podatki v realnem času
- kraljestvo
- prejema
- nedavno
- prepoznavanje
- Priporočamo
- zmanjša
- zmanjšanje
- reference
- rafiniranje
- o
- povezane
- relativno
- ustreznost
- pomembno
- zanesljivost
- zanesljiv
- ostanki
- Obnovljivi viri
- obnovljiva energija
- Poročila
- Skladišče
- zastopanje
- zahteva
- zahteva
- obvezna
- Zahteve
- zahteva
- reševanje
- Raziskave
- viri
- Odgovor
- odgovorov
- odgovornosti
- Rezultati
- preusposabljanje
- Rich
- Pravica
- robusten
- vloga
- Run
- deluje
- s
- sagemaker
- prodaja
- prodajni center
- Shrani
- Prilagodljivost
- Lestvica
- lestvica ai
- skaliranje
- Scenarij
- praska
- brezšivne
- brez težav
- Iskalnik
- iskanja
- iskanje
- sezonska
- oddelki
- Sektorji
- zavarovanje
- varnost
- izbiranje
- pošljite
- pošiljanja
- Občutek
- sentiment
- september
- Storitev
- Storitve
- nastavite
- nastavitev
- nastavitev
- več
- deli
- delitev
- streljanje
- shouldnt
- pomemben
- bistveno
- Enostavno
- poenostavitev
- Slack
- pametna
- nemoteno
- So
- Software
- sončna
- na sončno energijo
- trdna
- Rešitev
- rešitve
- SOLVE
- nekaj
- Nekaj
- Viri
- specializirani
- specifična
- določeno
- Spectrum
- govor
- preživeti
- Šport
- Šport
- SQL
- Skladovnice
- stojala
- Začetek
- začel
- Začetek
- začne
- postaja
- Koraki
- Še vedno
- zaloge
- shranjevanje
- trgovina
- shranjeni
- Strateško
- strategije
- pretakanje
- racionalizirati
- strukturirano
- strukturirani in nestrukturirani podatki
- strukturiranje
- precejšen
- taka
- Predlaga
- apartma
- Povzamemo
- superpolnjenje
- superior
- dobavitelj
- podpora
- Podpira
- Preverite
- Trajnostni razvoj
- Gugalnice
- Sinhronizacija
- sistem
- sistemi
- prilagojene
- Bodite
- meni
- ciljna
- ciljno
- Naloga
- Naloge
- skupina
- Skupine
- tech
- tehnični
- Tehnologije
- Tehnologija
- telekomunikacije
- pove
- predloge
- besedilo
- Razvrstitev besedil
- kot
- da
- O
- informacije
- njihove
- Njih
- sami
- POTEM
- Tukaj.
- s tem
- te
- jih
- stvar
- mislim
- ta
- tisti,
- 3
- Prag
- skozi
- Tako
- vozovnice
- vstopnice
- čas
- krat
- naslove
- do
- žeton
- orodje
- orodja
- Teme
- proti
- Sledenje
- usposobljeni
- usposabljanje
- Transform
- Prehod
- Trend
- Trends
- sojenje
- sprožijo
- Zaupajte
- zaupanja
- Turbina
- vaje
- Vrste
- dežnik
- nedvomno
- pod
- osnovni
- podčrtaj
- razumeli
- razumevanje
- razume
- poenoteno
- edinstven
- edinstvene lastnosti
- posodobitve
- posodabljanje
- naprej
- us
- uporaba
- primeru uporabe
- uporabnik
- Uporabniški vmesnik
- Uporabniku prijazen
- Uporabniki
- uporablja
- uporabo
- navadno
- uporabiti
- Vakuumska
- dragocene
- raznolikost
- različnih
- vsestranskost
- preko
- preživetja
- Video
- sprehod
- je
- način..
- we
- Spletna stran
- spletne strani
- Dobro
- so bili
- kdaj
- kadar koli
- ki
- medtem
- WHO
- široka
- Širok spekter
- bo
- veter
- vetrna energija
- Vetrna turbina
- z
- v
- brez
- delo
- delal
- potek dela
- delovnih tokov
- Delovno mesto
- delovno mesto
- pisati
- let
- ja
- jo
- Vaša rutina za
- Zendesk
- zefirnet