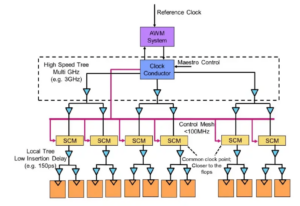
Strokovnjaki za mizo: Semiconductor Engineering so se pogovarjali o poti naprej za pomnilnik v vedno bolj heterogenih sistemih s Frankom Ferrom, direktorjem skupine za upravljanje izdelkov pri Cadence; Steven Woo, sodelavec in ugledni izumitelj pri Rambus; Jongsin Yun, pomnilniški tehnolog pri Siemens EDA; Randy White, programski vodja pomnilniških rešitev pri Keysight; in Frank Schirrmeister, podpredsednik za rešitve in poslovni razvoj pri Arteris. Sledi odlomek tega pogovora. Prvi del te razprave je na voljo tukaj.
![[L-D]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; in Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[L-D]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; in Frank Schirrmeister, Arteris
SE: Ko se borimo z AI/ML in zahtevami po energiji, katere konfiguracije je treba premisliti? Bomo videli odmik od von Neumannove arhitekture?
Woo: Kar zadeva sistemske arhitekture, se v industriji dogaja bifurkacija. Tradicionalne aplikacije, ki so prevladujoči vlečni konji in jih izvajamo v oblaku na strežnikih x86, ne bodo izginile. Obstajajo desetletja programske opreme, ki je bila zgrajena in se je razvijala in se bo za dobro delovanje zanašala na to arhitekturo. Nasprotno pa je AI/ML nov razred. Ljudje so premislili o arhitekturah in zgradili zelo domensko specifične procesorje. Vidimo, da se približno dve tretjini energije porabi samo za premikanje podatkov med procesorjem in napravo HBM, medtem ko se le približno tretjina porabi za dejanski dostop do bitov v jedrih DRAM. Pretok podatkov je zdaj veliko zahtevnejši in dražji. Ne bomo se znebili spomina. Potrebujemo ga, ker nabori podatkov postajajo večji. Vprašanje je torej: »Kaj je prava pot naprej?« O zlaganju je bilo veliko razprav. Če bi vzeli ta pomnilnik in ga postavili neposredno na vrh procesorja, bo namesto vas naredil dve stvari. Prvič, pasovna širina je danes omejena z obrežjem ali obodom čipa. Tja gredo V/I. Toda če bi ga naložili neposredno na vrh procesorja, lahko zdaj izkoristite celotno območje čipa za porazdeljene medsebojne povezave in lahko dobite večjo pasovno širino v samem pomnilniku in se lahko napaja neposredno navzdol procesor. Povezave postanejo veliko krajše, energetska učinkovitost pa se verjetno poveča za 5X do 6X. Drugič, količina pasovne širine, ki jo lahko dobite zaradi medsebojne povezave več območij s pomnilnikom, se prav tako poveča za več celih faktorjev. Če ti dve stvari izvajate skupaj, lahko zagotovite večjo pasovno širino in povečate energetsko učinkovitost. Industrija se razvija glede na kakršne koli potrebe in to je zagotovo eden od načinov, kako bomo videli, kako se bodo pomnilniški sistemi v prihodnosti začeli razvijati, da bodo postali učinkovitejši z energijo in zagotovili večjo pasovno širino.
železo: Ko sem okoli leta 2016 prvič začel delati na HBM, so nekatere naprednejše stranke vprašale, ali bi ga bilo mogoče združiti. Kar nekaj časa so iskali, kako zložiti DRAM na vrh, ker so očitne prednosti. Na fizični ravni postane PHY v bistvu zanemarljiv, kar prihrani veliko energije in učinkovitosti. Zdaj pa imate procesor z močjo več 100 W, ki ima poleg tega še pomnilnik. Spomin ne prenese vročine. To je verjetno najšibkejši člen v toplotni verigi, kar ustvarja še en izziv. Obstajajo prednosti, vendar morajo še vedno ugotoviti, kako ravnati s termiko. Zdaj je več spodbude za napredek te vrste arhitekture, saj vam resnično prihrani na splošno v smislu zmogljivosti in moči ter bo izboljšala vašo računalniško učinkovitost. Vendar pa obstaja nekaj izzivov fizičnega oblikovanja, s katerimi se je treba spopasti. Kot je rekel Steve, vidimo vse vrste arhitektur, ki prihajajo ven. Popolnoma se strinjam, da arhitekture GPU/CPE ne gredo nikamor, še vedno bodo prevladujoče. Hkrati si vsako podjetje na planetu prizadeva izmisliti boljšo mišelovko za njihovo umetno inteligenco. Vidimo SRAM na čipu in kombinacije pomnilnika z visoko pasovno širino. LPDDR je v teh dneh precej dvignil glavo glede tega, kako izkoristiti LPDDR v podatkovnem centru zaradi moči. Videli smo celo, da se GDDR uporablja v nekaterih aplikacijah za sklepanje AI, pa tudi v vseh starih pomnilniških sistemih. Zdaj poskušajo stisniti čim več DDR5 na odtis. Videl sem vsako arhitekturo, ki si jo lahko zamislite, pa naj gre za DDR, HBM, GDDR ali druge. Od jedra vašega procesorja je odvisno, kakšna je vaša skupna dodana vrednost, in nato, kako se lahko prebijete skozi svojo posebno arhitekturo. Pomnilniški sistem, ki gre zraven, tako da lahko oblikujete svoj CPE in svojo pomnilniško arhitekturo, odvisno od tega, kaj je na voljo.
In a: Drugo vprašanje je nestanovitnost. Če se mora umetna inteligenca ukvarjati z intervalom moči med izvajanjem umetne inteligence, ki temelji na IoT, na primer, potem potrebujemo veliko izklopov in vklopov, vse te informacije za usposabljanje umetne inteligence pa se morajo vedno znova vrteti. Če imamo neke vrste rešitve, kjer lahko te uteži shranimo v čip, tako da se nam ni treba vedno premikati naprej in nazaj za isto težo, bo to veliko prihrankov energije, zlasti za AI, ki temelji na IoT. Obstaja še ena rešitev za pomoč pri teh zahtevah po moči.
Schirrmeister: Kar se mi zdi fascinantno z vidika NoC, je, da morate optimizirati te poti od procesorja, ki gre skozi NoC, dostopa do pomnilniškega vmesnika s krmilnikom, ki bi lahko šel skozi UCIe, da posreduje čiplet drugemu čipletu, ki ima nato pomnilnik v to. Ne gre za to, da so Von Neumannove arhitekture mrtve. Toda zdaj obstaja toliko različic, odvisno od delovne obremenitve, ki bi jo želeli izračunati. Upoštevati jih je treba v kontekstu spomina, spomin pa je le en vidik. Kje dobite podatke iz podatkovne lokacije, kako so urejeni v tem DRAM-u? Delamo skozi vse te stvari, kot je analiza zmogljivosti pomnilnikov in nato optimizacija sistemske arhitekture na njih. Spodbuja veliko inovacij za nove arhitekture, na katere nisem nikoli pomislil, ko sem se na univerzi učil o Von Neumannu. Na skrajnem drugem koncu imate stvari, kot so mreže. Zdaj je vmes veliko več arhitektur, ki jih je treba upoštevati, poganjajo pa jih pasovna širina pomnilnika, računalniške zmogljivosti in tako naprej, ki ne rastejo z enako hitrostjo.
bela: Obstaja trend, ki vključuje razčlenjeno računalništvo ali porazdeljeno računalništvo, kar pomeni, da mora imeti arhitekt na voljo več orodij. Hierarhija pomnilnika se je razširila. Vključena je semantika, pa tudi CXL in različni hibridni pomnilniki, ki so na voljo za flash in DRAM. Vzporedna aplikacija podatkovnemu centru je avtomobilska. Avtomobilizem je ta senzor vedno računal z ECU (elektronske krmilne enote). Fasciniran sem nad tem, kako se je razvil v podatkovni center. Hitro naprej in danes imamo porazdeljena računalniška vozlišča, imenovana krmilniki domene. To je ista stvar. Poskuša odgovoriti na to, da morda moč ni tako pomembna, ker obseg računalnikov ni tako velik, vendar je zakasnitev zagotovo velika stvar v avtomobilski industriji. ADAS potrebuje izjemno visoko pasovno širino in imate različne kompromise. In potem imate več mehanskih senzorjev, vendar podobne omejitve v podatkovnem centru. Imate hladno shrambo, za katero ni treba, da ima nizko zakasnitev, nato pa imate še druge aplikacije z visoko pasovno širino. Fascinantno je videti, koliko so se razvila orodja in možnosti za arhitekta. Industrija se je zelo dobro odzvala in vsi nudimo različne rešitve, ki vstopijo na trg.
SE: Kako so se razvila orodja za načrtovanje pomnilnika?
Schirrmeister: Ko sem v 90-ih začel s svojimi prvimi čipi, je bil najbolj uporabljeno sistemsko orodje Excel. Od takrat sem vedno upal, da se bo na eni točki pokvarilo zaradi stvari, ki jih počnemo na ravni sistema, pomnilnika, analize pasovne širine in tako naprej. To je precej vplivalo na moje ekipe. Takrat je bila to zelo napredna stvar. Toda kar zadeva Randyjevo stališče, je zdaj treba nekatere zapletene stvari simulirati na ravni zvestobe, ki prej ni bila mogoča brez računanja. Na primer, predpostavka določene zakasnitve za dostop do DRAM-a lahko privede do napačnih arhitekturnih odločitev in potencialno nepravilnega oblikovanja arhitektur za prenos podatkov na čipu. Druga stran je tudi resnična. Če vedno predvidevate najslabši primer, boste preveč oblikovali arhitekturo. Z orodji, ki izvajajo analizo DRAM-a in zmogljivosti, in z ustreznimi modeli, ki so na voljo za krmilnike, arhitekt lahko simulira vse to, to je fascinantno okolje. Iz 90-ih upam, da bo Excel na eni točki izgubil vlogo orodje na sistemski ravni bi se lahko dejansko uresničilo, ker nekaterih dinamičnih učinkov ne morete več izvajati v Excelu, ker jih morate simulirati – še posebej, če dodate vmesnik die-to-die z lastnostmi PHY in nato povezovalni sloj lastnosti, kot so vsa preverjanja, ali je vse pravilno, in morebitno ponovno pošiljanje podatkov. Neopravljene te simulacije bodo povzročile neoptimalno arhitekturo.
železo: Prvi korak pri večini ocen, ki jih naredimo, je, da jim damo preskusno napravo za pomnilnik, da začnejo preverjati učinkovitost DRAM-a. To je ogromen korak, tudi če počnemo tako preproste stvari, kot je izvajanje lokalnih orodij za simulacijo DRAM-a, nato pa gremo v popolne simulacije. Vidimo, da več strank zahteva to vrsto simulacije. Zagotavljanje, da je učinkovitost vašega DRAM-a v visokih 90-ih, je zelo pomemben prvi korak pri vsakem ocenjevanju.
Woo: Razlog za porast orodij za popolno simulacijo sistema je del tega, da so DRAM-i postali veliko bolj zapleteni. Zdaj je z uporabo preprostih orodij, kot je Excel, zelo težko biti celo v vrsti za nekatere od teh zapletenih delovnih obremenitev. Če pogledate podatkovni list za DRAM v 90-ih, so bili ti podatkovni listi približno 40 strani. Zdaj imajo na stotine strani. To samo govori o kompleksnosti naprave, da bi dobili visoke pasovne širine. To povežete z dejstvom, da je pomnilnik tako gonilo stroškov sistema, pa tudi pasovne širine in zakasnitve, povezane z zmogljivostjo procesorja. Je tudi velik gonilnik moči, tako da morate zdaj simulirati na veliko bolj podrobni ravni. Kar zadeva pretok orodij, sistemski arhitekti razumejo, da je pomnilnik velik dejavnik. Orodja morajo biti torej bolj izpopolnjena in se morajo zelo dobro povezovati z drugimi orodji, tako da sistemski arhitekt dobi najboljši globalni pogled na to, kaj se dogaja – zlasti glede tega, kako pomnilnik vpliva na sistem.
In a: Ko se premikamo v dobo AI, se uporablja veliko večjedrnih sistemov, vendar ne vemo, kateri podatki gredo kam. Prav tako gre bolj vzporedno s čipom. Velikost pomnilnika je veliko večja. Če uporabimo AI tipa ChatGPT, potem obdelava podatkov za modele zahteva približno 350 MB podatkov, kar je ogromna količina podatkov samo za težo, dejanski vhod/izhod pa je veliko večji. To povečanje količine zahtevanih podatkov pomeni, da obstaja veliko verjetnostnih učinkov, ki jih še nismo videli. Videti vse napake, povezane s to veliko količino pomnilnika, je izjemno zahteven preizkus. In ECC se uporablja povsod, tudi v SRAM-u, ki tradicionalno ni uporabljal ECC, zdaj pa je zelo pogost za največje sisteme. Testiranje za vse to je zelo zahtevno in mora biti podprto z rešitvami EDA za testiranje vseh teh različnih pogojev.
SE: S kakšnimi izzivi se vsakodnevno srečujejo inženirske ekipe?
bela: Vsak dan me boste našli v laboratoriju. Zaviham rokave in imam umazane roke, prebadanje žic, spajkanje in še kaj. Veliko razmišljam o validaciji po silikonu. Govorili smo o zgodnjih simulacijah in orodjih na matrici — BiST in podobnih stvareh. Na koncu dneva, preden pošljemo, želimo opraviti neko obliko validacije sistema ali preizkusov na ravni naprave. Pogovarjali smo se o tem, kako premagati spominski zid. Kolociramo spomin, HBM, podobne stvari. Če pogledamo razvoj tehnologije pakiranja, smo začeli z osvinčeno embalažo. Niso bili zelo dobri za celovitost signala. Desetletja pozneje smo prešli na optimizirano celovitost signala, kot so nizi s kroglično mrežo (BGA). Do tega nismo mogli dostopati, kar je pomenilo, da ga niste mogli preizkusiti. Tako smo prišli do tega koncepta, imenovanega vmesnik naprave – vmesnik BGA – in to nam je omogočilo, da v sendvič vključimo posebno napeljavo, ki je usmerjala signale. Nato bi ga lahko povezali s testno opremo. Hitro naprej do danes in zdaj imamo HBM in čiplete. Kako vstavim svojo napeljavo vmes na silikonski vmesni element? Ne moremo in to je boj. To je izziv, zaradi katerega ponoči ne morem spati. Kako izvedemo analizo napak na terenu z OEM ali sistemsko stranko, kjer ne dosežejo 90-odstotne učinkovitosti. V povezavi je več napak, ne morejo se pravilno inicializirati in usposabljanje ne deluje. Je to težava s celovitostjo sistema?
Schirrmeister: Ali ne bi raje tega počeli od doma z virtualnim vmesnikom kot pa hoditi v laboratorij? Ali ni odgovor bolj analitika, ki jo vgradite v čip? S čipleti vse še dodatno integriramo. Spraviti svoj spajkalnik tja pravzaprav ni možnosti, zato mora obstajati način za analitiko na čipu. Enak problem imamo za NoC. Ljudje pogledajo NoC, vi pošljete podatke in potem jih ni več. Potrebujemo analitiko, ki jo bomo dali noter, da bodo lahko ljudje odpravljali napake, in to sega do ravni proizvodnje, tako da boste končno lahko delali od doma in vse to počeli na podlagi analize čipov.
železo: Zlasti pri pomnilniku z visoko pasovno širino ne morete fizično priti tja. Ko licenciramo PHY, imamo tudi izdelek, ki gre s tem, tako da lahko pogledate vsakega od teh 1,024 bitov. Z orodjem lahko začnete brati in zapisovati DRAM, tako da vam ni treba fizično priti tja. Všeč mi je ideja o interposerju. Med testiranjem iz vmesnika izvlečemo nekaj zatičev, česar v sistemu ne morete storiti. Priti v te 3D sisteme je res izziv. Celo s stališča pretoka orodij za načrtovanje se zdi, da večina podjetij izvaja svoj individualni tok na številnih teh 2.5D orodjih. Začenjamo sestavljati bolj standardiziran način za izgradnjo 2.5D sistema, od celovitosti signala, moči, celotnega celotnega toka.
bela: Ker se stvari premikajo naprej, upam, da bomo še vedno lahko ohranili enako raven natančnosti. Sem v skupini za skladnost s faktorjem oblike UCIe. Iščem, kako bi označil znano dobro kocko, zlato kocko. Sčasoma bo to vzelo veliko več časa, vendar bomo našli srečno sredino med zmogljivostjo in natančnostjo testiranja, ki ga potrebujemo, ter vgrajeno prilagodljivostjo.
Schirrmeister: Če pogledam čiplete in njihovo sprejetje v bolj odprtem produkcijskem okolju, je testiranje eden večjih izzivov pri zagotavljanju pravilnega delovanja. Če sem veliko podjetje in nadzorujem vse njegove strani, potem lahko zadeve ustrezno omejim, da postane testiranje in tako naprej izvedljivo. Če želim preiti na slogan UCIe, da je UCI le ena črka oddaljena od PCI, in si predstavljam prihodnost, v kateri bo sestavljanje UCIe z vidika proizvodnje postalo podobno kot reže PCI v današnjem osebnem računalniku, potem so vidiki testiranja za to res zahtevno. Moramo najti rešitev. Veliko je dela.
Povezani članki
Prihodnost spomina (1. del zgoraj zaokroženega)
Od poskusov reševanja težav s toploto in močjo do vlog CXL in UCIe ima prihodnost številne priložnosti za spomin.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://semiengineering.com/rethinking-memory/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 2016
- 3d
- 40
- a
- O meni
- nad
- dostop
- Dostop
- natančnost
- dejanska
- dejansko
- ADA
- dodajte
- Naslov
- Sprejetje
- napredno
- Prednost
- Prednosti
- spet
- AI
- AI usposabljanje
- AI / ML
- vsi
- dovoljene
- omogoča
- Prav tako
- vedno
- znesek
- an
- Analiza
- analitika
- in
- Še ena
- odgovor
- kaj
- več
- kjerkoli
- uporaba
- aplikacije
- ustrezno
- arhitekti
- Arhitektura
- SE
- OBMOČJE
- okoli
- urejeno
- Array
- AS
- sprašuje
- vidik
- vidiki
- Skupščina
- domnevati
- At
- Poskusi
- avtomobilska
- Na voljo
- stran
- nazaj
- Slab
- žoga
- pasovna širina
- bar
- temeljijo
- V bistvu
- Osnova
- BE
- ker
- postanejo
- postane
- bilo
- pred
- počutje
- Prednosti
- BEST
- Boljše
- med
- Big
- večji
- Bit
- Break
- prinašajo
- izgradnjo
- zgrajena
- poslovni
- poslovni razvoj
- vendar
- by
- Cadence
- se imenuje
- prišel
- CAN
- Lahko dobiš
- Zmogljivosti
- primeru
- center
- nekatere
- Zagotovo
- verige
- izziv
- izzivi
- izziv
- lastnosti
- karakterizira
- preverjanje
- čip
- čipi
- razred
- jasno
- Cloud
- hladno
- Hladilnica
- kombinacije
- kako
- prihajajo
- Skupno
- Podjetja
- podjetje
- kompleksna
- kompleksnost
- skladnost
- zapleten
- Izračunajte
- računalniki
- računalništvo
- Koncept
- Pogoji
- Connect
- šteje
- omejitve
- ozadje
- kontrast
- nadzor
- krmilnik
- Pogovor
- Core
- popravi
- strošek
- bi
- par
- CPU
- ustvari
- stranka
- Stranke, ki so
- datum
- Podatkovno središče
- nabor podatkov
- dan
- iz dneva v dan
- Dnevi
- mrtva
- ponudba
- desetletja
- odločitve
- vsekakor
- zahteve
- Odvisno
- odvisno
- Oblikovanje
- oblikovanje
- podrobno
- Razvoj
- naprava
- Polnilna postaja
- drugačen
- težko
- neposredno
- Direktor
- Razprava
- odstranjevanje
- Razločen
- porazdeljena
- porazdeljeno računalništvo
- do
- ne
- Ne
- tem
- domena
- prevladujoč
- opravljeno
- dont
- navzdol
- vozi
- voznik
- med
- dinamično
- Zgodnje
- Učinki
- učinkovitosti
- učinkovite
- Electronic
- konec
- energija
- Inženiring
- Celotna
- okolje
- oprema
- Era
- napake
- zlasti
- Eter (ETH)
- Ocena
- vrednotenja
- Tudi
- sčasoma
- Tudi vsak
- vse
- Povsod
- evolucija
- razvijajo
- razvil
- razvija
- Primer
- Excel
- razširiti
- drago
- Se razširi
- ekstremna
- izredno
- oči
- Obraz
- Dejstvo
- Faktor
- Napaka
- zanimivo
- FAST
- izvedljivo
- kolega
- zvestoba
- Polje
- Slika
- končno
- Najdi
- prva
- Flash
- prilagodljivost
- Flip
- Pretok
- sledi
- Odtis
- za
- obrazec
- Naprej
- Naprej
- je pokazala,
- frank
- iz
- polno
- nadalje
- Prihodnost
- dobili
- pridobivanje
- Daj
- dana
- Globalno
- Go
- goes
- dogaja
- Zlata
- več
- dobro
- dobro delo
- prisodil
- Mreža
- skupina
- Pridelovanje
- imel
- Ravnanje
- roke
- srečna
- Imajo
- ob
- Glava
- pomoč
- hierarhija
- visoka
- drži
- Domov
- upam,
- Kako
- Kako
- HTML
- HTTPS
- velika
- Stotine
- Hybrid
- i
- Ideja
- if
- slika
- prizadeti
- udarne
- Pomembno
- izboljšanje
- in
- Spodbuda
- vključeno
- nepravilno
- Povečajte
- vedno
- individualna
- Industrija
- Podatki
- Inovacije
- v notranjosti
- integrirati
- celovitost
- medsebojne povezave
- vmesnik
- v
- vključujejo
- vprašanje
- Vprašanja
- IT
- ITS
- sam
- Job
- samo
- Vedite
- znano
- lab
- velika
- večja
- Največji
- Latenca
- pozneje
- plast
- vodi
- učenje
- pismo
- Stopnja
- Licenca
- kot
- Limited
- LINK
- Povezave
- lokalna
- Poglej
- si
- Sklop
- veliko
- nizka
- vzdrževati
- Znamka
- Izdelava
- upravljanje
- upravitelj
- proizvodnja
- več
- Tržna
- max širine
- mogoče
- me
- pomeni
- pomenilo
- mehanska
- srednje
- spomini
- Spomin
- morda
- modeli
- več
- Najbolj
- premikanje
- premaknjeno
- Gibanje
- premikanje
- veliko
- my
- Nimate
- potrebe
- nikoli
- Novo
- noč
- vozlišča
- zdaj
- Številka
- of
- off
- Staro
- on
- ONE
- samo
- odprite
- Priložnosti
- Optimizirajte
- optimizirana
- optimizacijo
- Možnost
- možnosti
- or
- Da
- Ostalo
- drugi
- ven
- Splošni
- Premagajte
- lastne
- pakete
- embalaža
- strani
- vzporedno
- del
- zlasti
- mimo
- pot
- poti
- PC
- ljudje
- opravlja
- performance
- perspektiva
- fizično
- Fizično
- zatiči
- planet
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- mogoče
- potencialno
- moč
- Predsednik
- prej
- verjetno
- problem
- Procesor
- procesorji
- Izdelek
- upravljanje izdelkov
- proizvodnja
- Program
- pravilno
- pravilno
- zagotavljajo
- dal
- vprašanje
- precej
- dvig
- Oceniti
- precej
- reading
- res
- povezane
- zanašajo
- obvezna
- zahteva
- reševanje
- odziva
- povzroči
- znebi
- Pravica
- Rise
- vloge
- Roll
- Run
- tek
- Enako
- Shrani
- Prihranki
- rek
- Lestvica
- drugi
- glej
- videnje
- Zdi se,
- videl
- semantika
- polprevodnik
- pošljite
- senzor
- senzorji
- strežniki
- več
- listov
- premik
- ladja
- strani
- Strani
- Siemens
- Signal
- signali
- Silicij
- Podoben
- Enostavno
- Simulacija
- simulacije
- saj
- sam
- Velikosti
- reže
- So
- Software
- Rešitev
- rešitve
- nekaj
- prefinjeno
- Govori
- posebna
- porabljen
- Stisnite
- sveženj
- zloženi
- zlaganje
- standardizirani
- stališče
- Začetek
- začel
- Začetek
- Korak
- Steve
- steven
- Še vedno
- shranjevanje
- trgovina
- Boj
- taka
- Podprti
- Preverite
- sistem
- sistemi
- miza
- Bodite
- Pogovor
- Skupine
- tehnolog
- Tehnologija
- Pogoji
- Test
- Testiranje
- testi
- kot
- da
- O
- Prihodnost
- njihove
- Njih
- POTEM
- Tukaj.
- toplotna
- te
- jih
- stvar
- stvari
- mislim
- tretja
- ta
- tisti,
- mislil
- skozi
- čas
- do
- danes
- skupaj
- orodje
- orodja
- vrh
- POPOLNOMA
- kompromisi
- tradicionalna
- tradicionalno
- usposabljanje
- prevoz
- Trend
- Res
- poskuša
- dva
- dve tretjini
- tip
- razumeli
- enote
- univerza
- us
- uporaba
- Rabljeni
- uporabo
- potrjevanje
- vrednost
- variacije
- različnih
- zelo
- vice
- Podpredsednica
- Poglej
- Virtual
- za
- hoja
- Wall
- želeli
- je
- način..
- we
- teža
- Dobro
- so bili
- Kaj
- karkoli
- kdaj
- ali
- ki
- medtem
- bele
- celoti
- zakaj
- bo
- z
- brez
- woo
- delo
- Delo od doma
- deluje
- Klobase
- pisanje
- jo
- Vaša rutina za
- zefirnet