V današnji digitalni dobi so podatki v središču uspeha vsake organizacije. Eden najpogosteje uporabljenih formatov za izmenjavo podatkov je XML. Analiza datotek XML je ključnega pomena iz več razlogov. Prvič, datoteke XML se uporabljajo v številnih panogah, vključno s financami, zdravstvom in vlado. Analiza datotek XML lahko pomaga organizacijam pridobiti vpogled v njihove podatke, kar jim omogoča sprejemanje boljših odločitev in izboljšanje njihovega delovanja. Analiza datotek XML lahko pomaga tudi pri integraciji podatkov, saj številne aplikacije in sistemi uporabljajo XML kot standardni format podatkov. Z analizo datotek XML lahko organizacije enostavno integrirajo podatke iz različnih virov in zagotovijo doslednost v svojih sistemih. Vendar datoteke XML vsebujejo polstrukturirane, zelo ugnezdene podatke, zaradi česar je težko dostopati do informacij in jih analizirati, zlasti če je datoteka velika in ima kompleksna, zelo ugnezdena shema.
Datoteke XML so zelo primerne za aplikacije, vendar morda niso optimalne za analitične mehanizme. Da bi izboljšali zmogljivost poizvedb in omogočili enostaven dostop v nadaljnjih analitičnih motorjih, kot je npr Amazonska Atena, je ključnega pomena vnaprejšnja obdelava datotek XML v stolpčni format, kot je Parquet. Ta preobrazba omogoča izboljšano učinkovitost in uporabnost v analitičnih potekih dela. V tej objavi prikazujemo, kako obdelati podatke XML z uporabo AWS lepilo in Atena.
Pregled rešitev
Raziskujemo dve različni tehniki, ki lahko poenostavita proces obdelave datotek XML:
- 1. tehnika: uporabite pajka AWS Glue in vizualni urejevalnik AWS Glue – Za definiranje strukture tabele za vaše datoteke XML lahko uporabite uporabniški vmesnik AWS Glue v povezavi s pajkom. Ta pristop zagotavlja uporabniku prijazen vmesnik in je še posebej primeren za posameznike, ki imajo raje grafični pristop pri upravljanju svojih podatkov.
- 2. tehnika: uporabite AWS Glue DynamicFrames z ugotovljenimi in fiksnimi shemami – Pajek ima omejitev, ko gre za obdelavo ene vrstice v datotekah XML, večjih od 1 MB. Za premagovanje te omejitve uporabljamo prenosni računalnik AWS Glue za izdelavo AWS Glue
DynamicFrames, z uporabo ugotovljenih in fiksnih shem. Ta metoda zagotavlja učinkovito ravnanje z datotekami XML z vrsticami, večjimi od 1 MB.
Pri obeh pristopih je naš končni cilj pretvoriti datoteke XML v format Apache Parquet, tako da bodo takoj na voljo za poizvedovanje z uporabo Athene. S temi tehnikami lahko izboljšate hitrost obdelave in dostopnost svojih podatkov XML, kar vam omogoča, da z lahkoto pridobite dragocene vpoglede.
Predpogoji
Preden začnete s to vadnico, izpolnite naslednje predpogoje (veljajo za obe tehniki):
- Prenesite datoteke XML tehnika1.xml in tehnika2.xml.
- Naložite datoteke v Preprosta storitev shranjevanja Amazon (Amazon S3) vedro. Lahko jih naložite v isto vedro S3 v različnih mapah ali v različna vedra S3.
- Ustvari AWS upravljanje identitete in dostopa (IAM) za vaše opravilo ETL ali prenosni računalnik, kot je navedeno v Nastavite dovoljenja IAM za AWS Glue Studio.
- Svoji vlogi dodajte vgrajeni pravilnik z že: PassRole ukrepanje:
- Vlogi z dostopom do vedra S3 dodajte pravilnik o dovoljenjih.
Zdaj, ko smo končali s predpogoji, preidimo na izvajanje prve tehnike.
1. tehnika: Uporabite pajka AWS Glue in vizualni urejevalnik
Naslednji diagram ponazarja preprosto arhitekturo, ki jo lahko uporabite za implementacijo rešitve.
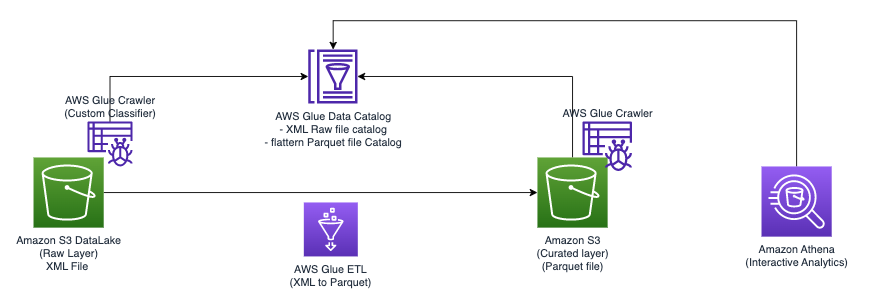
Za analizo datotek XML, shranjenih v Amazon S3 z uporabo AWS Glue in Athena, dokončamo naslednje korake na visoki ravni:
- Ustvarite pajka AWS Glue za ekstrahiranje metapodatkov XML in ustvarite tabelo v katalogu podatkov AWS Glue.
- Obdelajte in pretvorite podatke XML v obliko (kot je Parquet), ki je primerna za Atheno, z uporabo opravila AWS Glue ekstrahiraj, transformiraj in naloži (ETL).
- Nastavite in zaženite opravilo AWS Glue prek konzole AWS Glue ali Vmesnik ukazne vrstice AWS (AWS CLI).
- Uporabite obdelane podatke (v formatu Parquet) z Athena tabelami, ki omogočajo SQL poizvedbe.
- Uporabite uporabniku prijazen vmesnik v Atheni za analizo podatkov XML s poizvedbami SQL za vaše podatke, shranjene v Amazon S3.
Ta arhitektura je razširljiva, stroškovno učinkovita rešitev za analizo podatkov XML na Amazon S3 z uporabo AWS Glue in Athena. Analizirate lahko velike nabore podatkov brez zapletenega upravljanja infrastrukture.
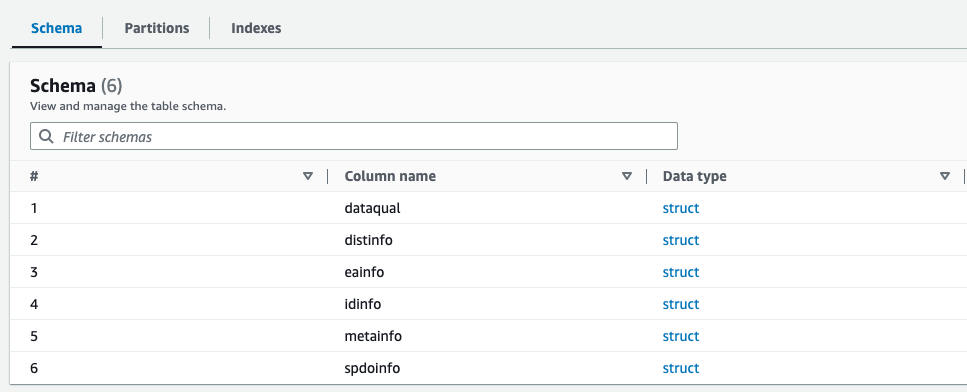
Za ekstrahiranje metapodatkov datoteke XML uporabljamo pajka AWS Glue. Izberete lahko privzeti klasifikator AWS Glue za klasifikacijo XML za splošne namene. Samodejno zazna podatkovno strukturo in shemo XML, kar je uporabno za pogoste formate.
V tej rešitvi uporabljamo tudi klasifikator XML po meri. Zasnovan je za posebne sheme ali formate XML, kar omogoča natančno ekstrakcijo metapodatkov. To je idealno za nestandardne formate XML ali kadar potrebujete podroben nadzor nad klasifikacijo. Klasifikator po meri zagotavlja, da se ekstrahirajo samo potrebni metapodatki, kar poenostavi nadaljnjo obdelavo in analize. Ta pristop optimizira uporabo vaših datotek XML.
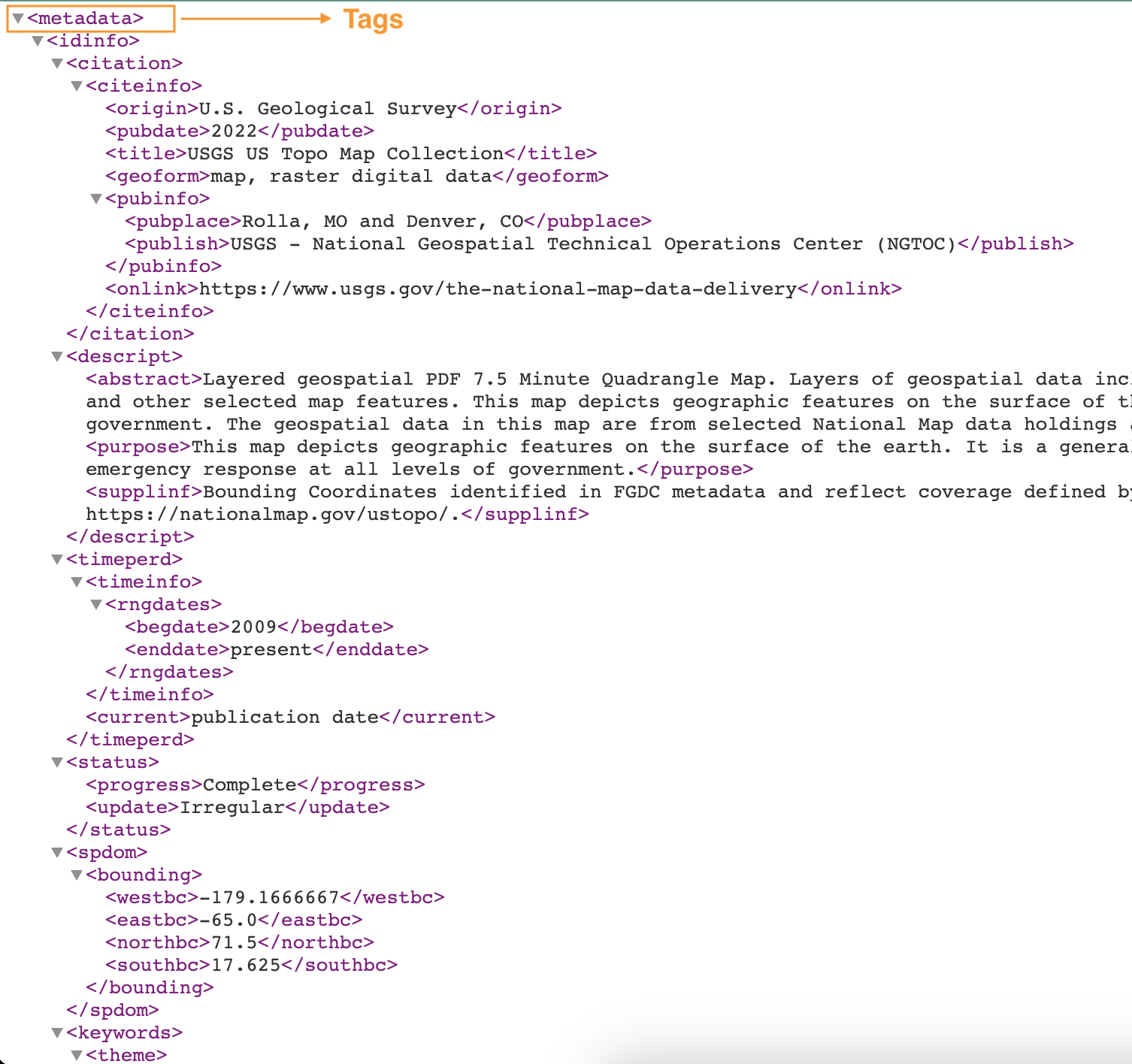
Naslednji posnetek zaslona prikazuje primer datoteke XML z oznakami.
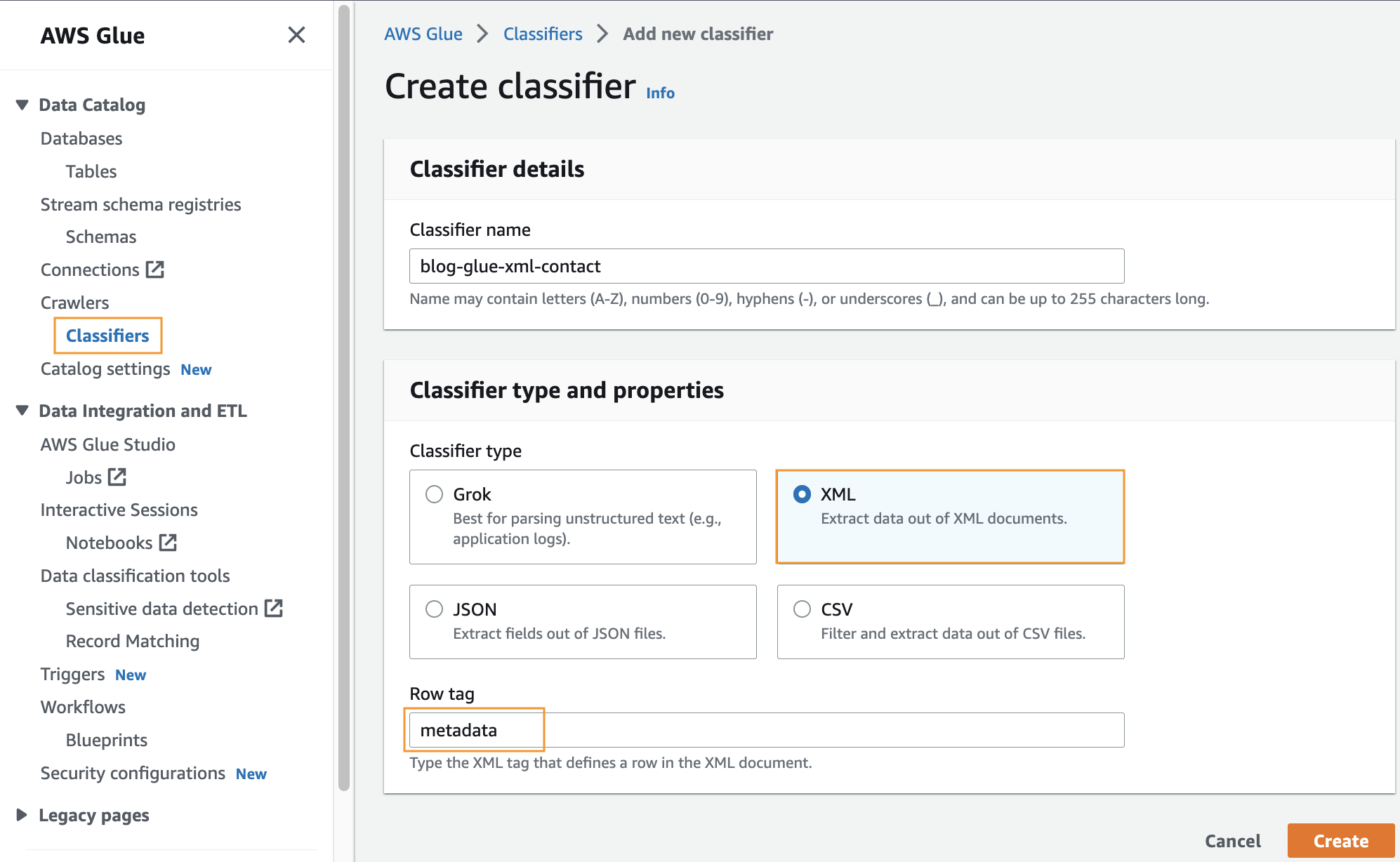
Ustvarite klasifikator po meri
V tem koraku ustvarite klasifikator AWS Glue po meri za ekstrahiranje metapodatkov iz datoteke XML. Izvedite naslednje korake:
- Na konzoli AWS Glue, pod Pajki v podoknu za krmarjenje izberite Klasifikatorji.
- Izberite Dodaj klasifikator.
- Izberite XML kot tip klasifikatorja.
- Vnesite ime za klasifikator, kot npr
blog-glue-xml-contact. - za Oznaka vrstice, vnesite ime korenske oznake, ki vsebuje metapodatke (npr.
metadata). - Izberite ustvarjanje.
Ustvarite pajka AWS Glue Crawler za pajkanje datoteke xml
V tem razdelku ustvarjamo Glue Crawler za ekstrahiranje metapodatkov iz datoteke XML z uporabo klasifikatorja strank, ustvarjenega v prejšnjem koraku.
Ustvari bazo podatkov
- Pojdi na Konzola za lepilo AWS, izberite Baze podatkov v podoknu za krmarjenje.
- Kliknite na Dodajte bazo podatkov.
- Navedite ime, kot je npr
blog_glue_xml - Izberite ustvarjanje Baze podatkov
Ustvari pajka
Izvedite naslednje korake, da ustvarite svojega prvega pajka:
- Na konzoli AWS Glue izberite Pajki v podoknu za krmarjenje.
- Izberite Ustvari pajka.
- o Nastavite lastnosti pajka strani vnesite ime za novega pajka (npr
blog-glue-parquet), nato izberite Naslednji. - o Izberite vire podatkov in klasifikatorje stran, izberite Ne še pod Konfiguracija vira podatkov.
- Izberite Dodajte podatkovno shrambo.
- za S3 pot, pobrskajte po
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Prepričajte se, da ste izbrali mapo XML in ne datoteke v mapi.
- Ostale možnosti pustite privzete in izberite Dodajte vir podatkov S3.
- Razširi Klasifikatorji po meri – neobvezno, izberite blog-glue-xml-contact in nato izberite Naslednji ostale možnosti pa ohranite kot privzete.
- Izberite svojo vlogo IAM ali izberite Ustvari novo vlogo IAM, dodajte pripono
glue-xml-contact(npr.AWSGlueServiceNotebookRoleBlog), in izberite Naslednji. - o Nastavite izhod in razporejanje strani, pod Izhodna konfiguracija, izberite
blog_glue_xmlza Ciljna zbirka podatkov. - Vnesite
console_kot predpona, dodana tabelam (neobvezno) in pod Urnik pajka, naj bo frekvenca nastavljena na Na zahtevo. - Izberite Naslednji.
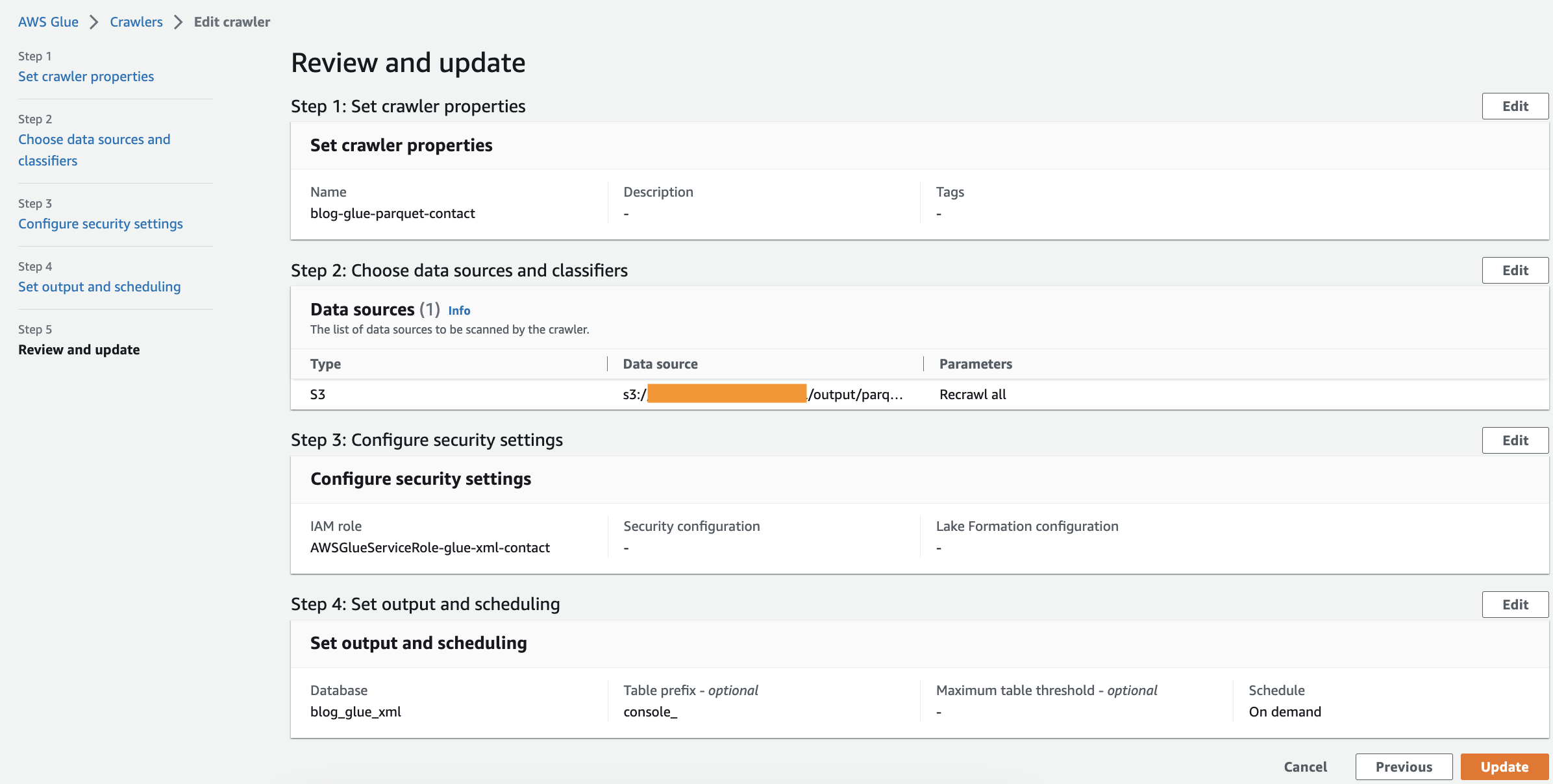
- Preglejte vse parametre in izberite Ustvari pajka.
Zaženite pajka
Ko ustvarite pajka, dokončajte naslednje korake, da ga zaženete:
- Na konzoli AWS Glue izberite Pajki v podoknu za krmarjenje.
- Odprite pajka, ki ste ga ustvarili, in izberite Run.
Pajek bo dokončal 1–2 minuti.
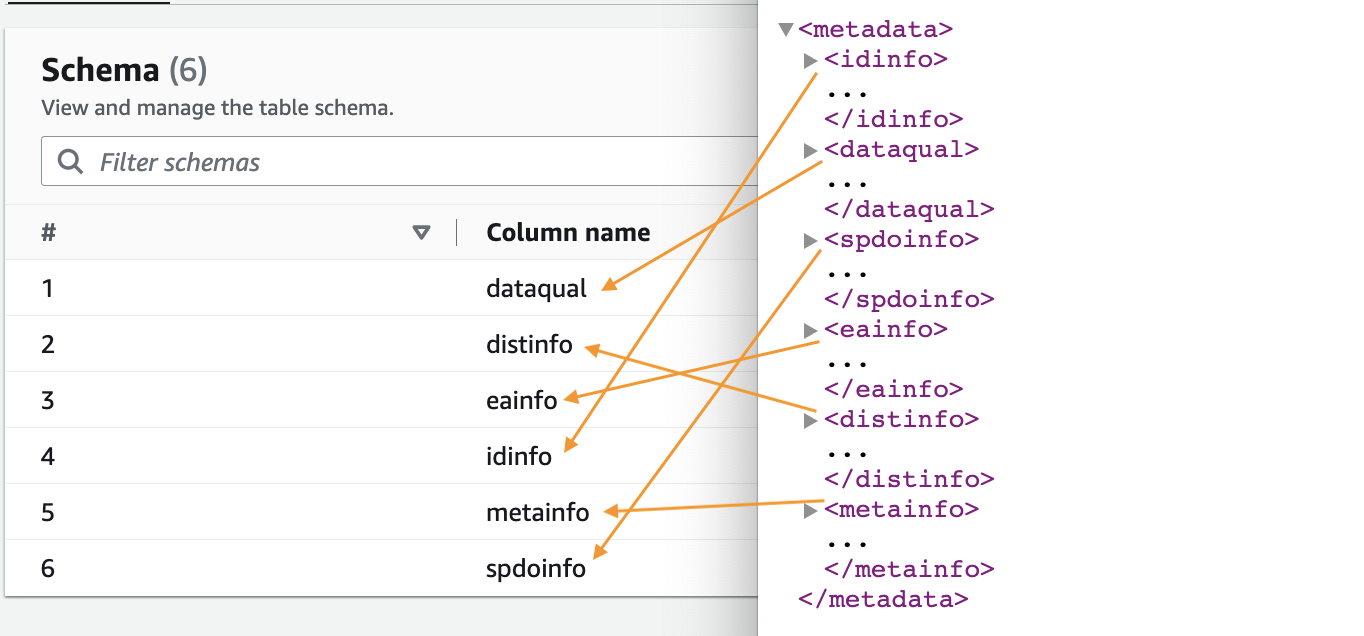
- Ko je pajek končan, izberite Baze podatkov v podoknu za krmarjenje.
- Izberite bazo podatkov, ki ste jo ustvarili, in izberite ime tabele, da si ogledate shemo, ki jo ekstrahira pajek.
Ustvarite opravilo AWS Glue za pretvorbo XML v format Parquet
V tem koraku ustvarite opravilo AWS Glue Studio za pretvorbo datoteke XML v datoteko Parquet. Izvedite naslednje korake:
- Na konzoli AWS Glue izberite Delovna mesta v podoknu za krmarjenje.
- Pod Ustvari službotako, da izberete Vizualno s praznim platnom.
- Izberite ustvarjanje.
- Preimenujte opravilo v
blog_glue_xml_job.
Zdaj imate prazen vizualni urejevalnik opravil AWS Glue Studio. Na vrhu urejevalnika so zavihki za različne poglede.
- Izberite Script da vidite prazno lupino skripta AWS Glue ETL.
Ko dodamo nove korake v vizualnem urejevalniku, se bo skript samodejno posodobil.
- Izberite Podrobnosti o delovnem mestu za ogled vseh konfiguracij opravil.
- za Vloga IAM, izberite
AWSGlueServiceNotebookRoleBlog. - za Različica z lepilom, izberite Glue 4.0 – podpora za Spark 3.3, Scala 2, Python 3.
- Kompleti Zahtevano število delavcev da 2.
- Kompleti Število ponovnih poskusov da 0.
- Izberite Vizualni da se vrnete v vizualni urejevalnik.
- o vir spustni meni, izberite Katalog podatkov o lepilu AWS.
- o Lastnosti vira podatkov – Katalog podatkov vnesite naslednje podatke:
- za Baze podatkov, izberite
blog_glue_xml. - za Tabela, izberite tabelo, ki se začne z imenom console_, ki ga je ustvaril pajek (na primer
console_geologicalsurvey).
- za Baze podatkov, izberite
- o Lastnosti vozlišča vnesite naslednje podatke:
- Spreminjanje Ime do
geologicalsurveynabor podatkov. - Izberite Ukrep in preobrazbo Spremeni shemo (uporabi preslikavo).
- Izberite Lastnosti vozlišča in spremenite ime transformacije iz Spremeni shemo (Uporabi preslikavo) v
ApplyMapping. - o ciljna izberite meni S3.
- Spreminjanje Ime do
- o Lastnosti vira podatkov - S3 vnesite naslednje podatke:
- za oblikovanatako, da izberete Parket.
- za Vrsta stiskanjatako, da izberete Nekomprimirano.
- za Vrsta vira S3tako, da izberete S3 lokacija.
- za S3 URL, vnesite
s3://${BUCKET_NAME}/output/parquet/. - Izberite Lastnosti vozlišča in spremenite ime v
Output.
- Izberite Shrani rešiti službo.
- Izberite Run voditi delo.
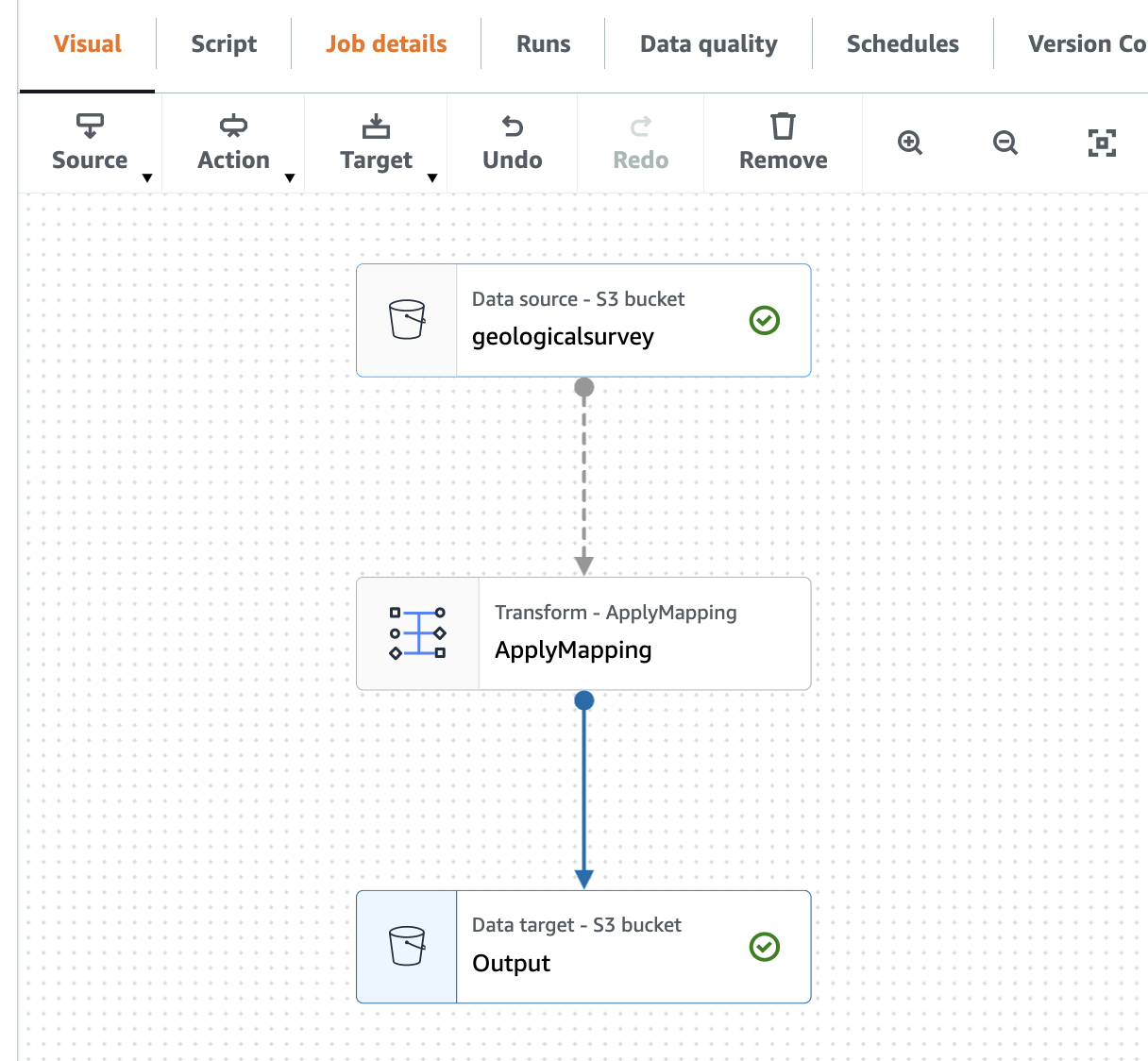
Naslednji posnetek zaslona prikazuje opravilo v vizualnem urejevalniku.
Ustvarite pajka AWS Gue za pajkanje po datoteki Parquet
V tem koraku ustvarite pajka AWS Glue za ekstrahiranje metapodatkov iz datoteke Parquet, ki ste jo ustvarili z opravilom AWS Glue Studio. Tokrat boste uporabili privzeti klasifikator. Izvedite naslednje korake:
- Na konzoli AWS Glue izberite Pajki v podoknu za krmarjenje.
- Izberite Ustvari pajka.
- o Nastavite lastnosti pajka stran, vnesite ime za novega pajka, kot je blog-glue-parquet-contact, nato izberite Naslednji.
- o Izberite vire podatkov in klasifikatorje stran, izberite Ne še za Konfiguracija vira podatkov.
- Izberite Dodajte podatkovno shrambo.
- za S3 pot, pobrskajte po
s3://${BUCKET_NAME}/output/parquet/.
Prepričajte se, da ste izbrali parquet namesto datoteke v mapi.
- Izberite svojo vlogo IAM, ustvarjeno v razdelku s predpogoji, ali izberite Ustvari novo vlogo IAM (npr.
AWSGlueServiceNotebookRoleBlog), in izberite Naslednji. - o Nastavite izhod in razporejanje strani, pod Izhodna konfiguracija, izberite
blog_glue_xmlza Baze podatkov. - Vnesite
parquet_kot predpona, dodana tabelam (neobvezno) in pod Urnik pajka, naj bo frekvenca nastavljena na Na zahtevo. - Izberite Naslednji.
- Preglejte vse parametre in izberite Ustvari pajka.
Zdaj lahko zaženete pajka, ki traja 1–2 minuti.

Novo ustvarjeno shemo za datoteko Parquet si lahko predogledate v katalogu podatkov AWS Glue Data Catalog, ki je podobna shemi datoteke XML.
Zdaj imamo podatke, ki so primerni za uporabo z Atheno. V naslednjem razdelku izvajamo podatkovne poizvedbe z Atheno.
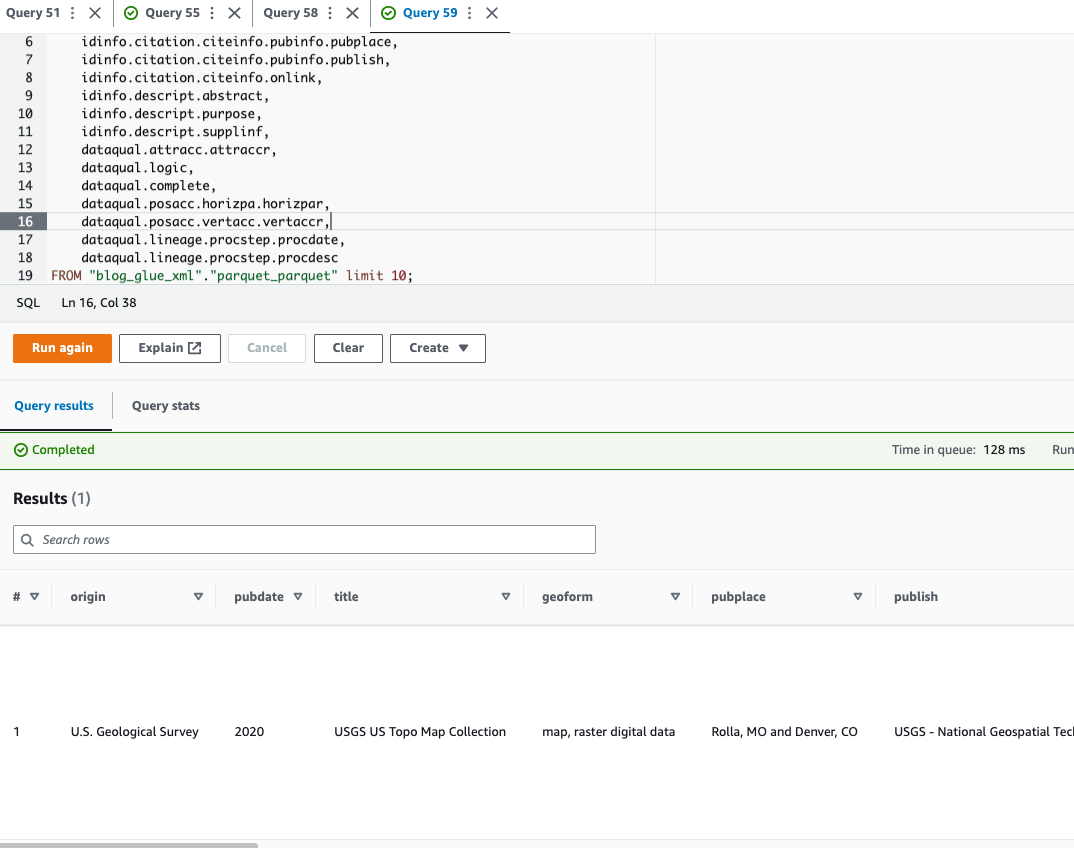
Poizvedite datoteko Parquet z Atheno
Athena ne podpira poizvedovanja Format datoteke XML, zato ste datoteko XML pretvorili v Parquet za učinkovitejše poizvedovanje in uporabo podatkov zapis s pikami za poizvedovanje po kompleksnih vrstah in ugnezdenih strukturah.
Naslednji primer kode uporablja zapis s pikami za poizvedovanje po ugnezdenih podatkih:
Zdaj, ko smo dokončali tehniko 1, pojdimo naprej, da spoznamo tehniko 2.
2. tehnika: uporabite AWS Glue DynamicFrames z ugotovljenimi in fiksnimi shemami
V prejšnjem razdelku smo obravnavali postopek ravnanja z majhno datoteko XML z uporabo pajka AWS Glue za ustvarjanje tabele, opravila AWS Glue za pretvorbo datoteke v format Parquet in Athene za dostop do podatkov Parquet. Vendar pa pajek naleti na omejitve, ko gre za obdelavo datotek XML, ki presegajo Velikost 1 MB. V tem razdelku se poglobimo v temo paketne obdelave večjih datotek XML, ki zahteva dodatno razčlenjevanje za ekstrahiranje posameznih dogodkov in izvedbo analize z uporabo Athene.
Naš pristop vključuje branje datotek XML prek AWS Glue DynamicFrames, ki uporablja ugotovljene in fiksne sheme. Nato izvlečemo posamezne dogodke v obliki Parquet z uporabo relativizirati transformacijo, kar nam omogoča, da jih nemoteno poizvedujemo in analiziramo z uporabo Athene.
Če želite implementirati to rešitev, opravite naslednje korake na visoki ravni:
- Ustvarite zvezek AWS Glue za branje in analizo datoteke XML.
- Uporaba
DynamicFrameszInferSchemaza branje datoteke XML. - Uporabite funkcijo relacije, da razgnezdite poljubna polja.
- Pretvorite podatke v format Parquet.
- Poizvedite po podatkih Parquet z Atheno.
- Ponovite prejšnje korake, vendar tokrat posredujte shemo
DynamicFramesnamesto uporabeInferSchema.
Datoteka XML s podatki o prebivalstvu električnih vozil ima a response oznako na korenski ravni. Ta oznaka vsebuje niz row oznake, ki so v njem ugnezdene. Oznaka vrstice je matrika, ki vsebuje nabor drugih oznak vrstic, ki zagotavljajo informacije o vozilu, vključno z njegovo znamko, modelom in drugimi ustreznimi podrobnostmi. Naslednji posnetek zaslona prikazuje primer.

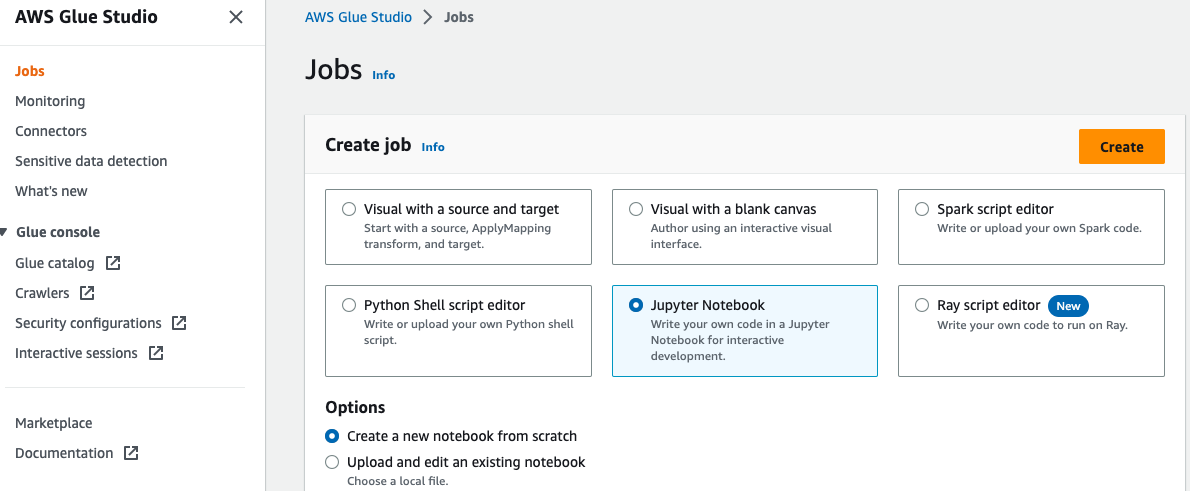
Ustvarite AWS Glue Notebook
Če želite ustvariti zvezek AWS Glue, izvedite naslednje korake:
- odprite AWS Glue Studio konzolo, izberite Delovna mesta v podoknu za krmarjenje.
- Izberite Jupyter Notebook In izberite ustvarjanje.
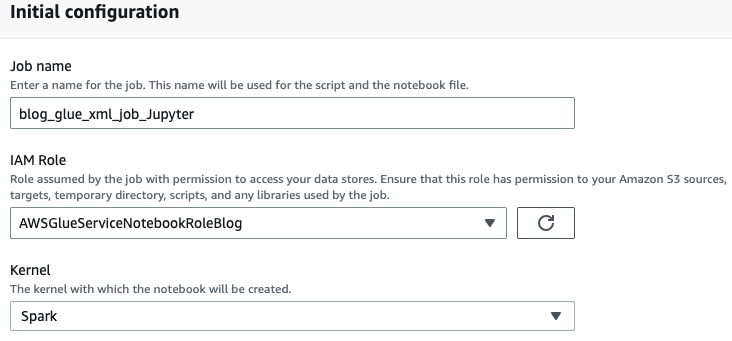
- Vnesite ime za svoje opravilo AWS Glue, na primer
blog_glue_xml_job_Jupyter. - Izberite vlogo, ki ste jo ustvarili v predpogojih (
AWSGlueServiceNotebookRoleBlog).
Beležnica AWS Glue je opremljena z že obstoječim primerom, ki prikazuje, kako poizvedovati po zbirki podatkov in zapisati izhod v Amazon S3.
- Prilagodite časovno omejitev (v minutah), kot je prikazano na naslednjem posnetku zaslona, in zaženite celico, da ustvarite interaktivno sejo AWS Glue.
Ustvarite osnovne spremenljivke
Ko ustvarite interaktivno sejo, na koncu zvezka ustvarite novo celico z naslednjimi spremenljivkami (vnesite svoje ime vedra):
Preberite datoteko XML, ki sklepa na shemo
Če sheme ne posredujete v DynamicFrame, bo sklepal na shemo datotek. Za branje podatkov z uporabo dinamičnega okvirja lahko uporabite naslednji ukaz:
Natisnite shemo DynamicFrame
Natisnite shemo z naslednjo kodo:
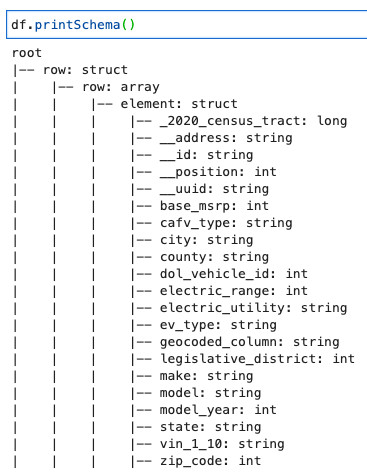
Shema prikazuje ugnezdeno strukturo z a row niz, ki vsebuje več elementov. Če želite razgnezditi to strukturo v črte, lahko uporabite lepilo AWS relativizirati transformacija:
Zanimajo nas samo informacije, ki jih vsebuje niz vrstic, shemo pa si lahko ogledamo z naslednjim ukazom:
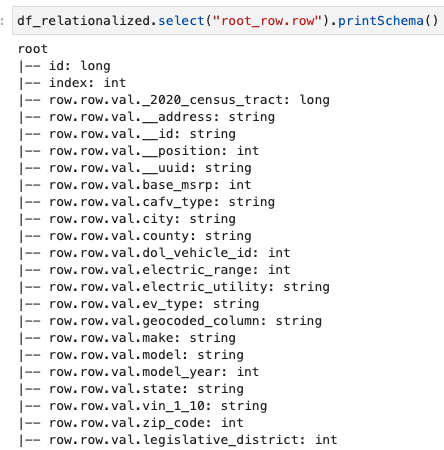
Imena stolpcev vsebujejo row.row, ki ustrezajo strukturi polja in stolpcu polja v naboru podatkov. Stolpcev v tej objavi ne preimenujemo; za navodila za to glejte Avtomatizirajte dinamično preslikavo in preimenovanje imen stolpcev v podatkovnih datotekah z uporabo AWS Glue: 1. del. Nato lahko pretvorite podatke v format Parquet in ustvarite tabelo AWS Glue z naslednjim ukazom:
AWS lepilo DynamicFrame nudi funkcije, ki jih lahko uporabite v skriptu ETL za ustvarjanje in posodabljanje sheme v podatkovnem katalogu. Uporabljamo updateBehavior parameter za ustvarjanje tabele neposredno v katalogu podatkov. S tem pristopom nam po končanem opravilu AWS Glue ni treba zagnati pajka AWS Glue.

Preberite datoteko XML z nastavitvijo sheme
Druga možnost za branje datoteke je vnaprejšnja določitev sheme. Če želite to narediti, izvedite naslednje korake:
- Uvozite vrste podatkov AWS Glue:
- Ustvarite shemo za datoteko XML:
- Pri branju datoteke XML posredujte shemo:
- Odstranite nabor podatkov kot prej:
- Pretvorite nabor podatkov v Parquet in ustvarite tabelo AWS Glue:
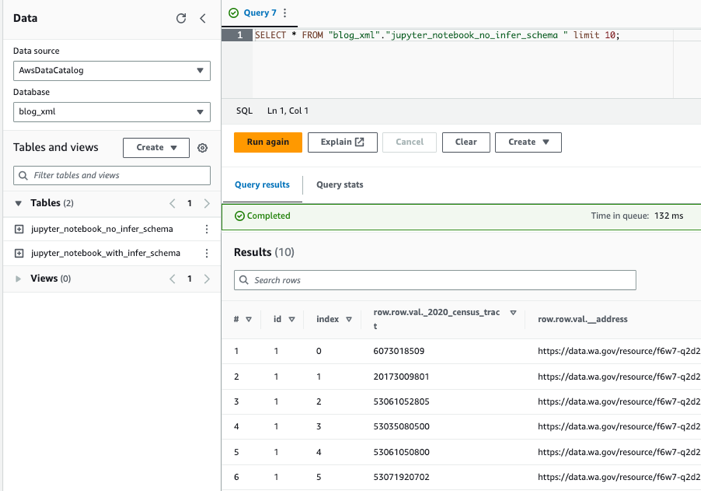
Poizvedujte po tabelah z uporabo Athene
Zdaj, ko smo ustvarili obe tabeli, lahko poizvedujemo po tabelah z uporabo Athene. Uporabimo lahko na primer naslednjo poizvedbo:
Clean Up
V tej objavi smo ustvarili vlogo IAM, zvezek AWS Glue Jupyter in dve tabeli v katalogu podatkov AWS Glue. Nekaj datotek smo naložili tudi v vedro S3. Če želite počistiti te predmete, izvedite naslednje korake:
- Na konzoli IAM izbrišite vlogo, ki ste jo ustvarili.
- Na konzoli AWS Glue Studio izbrišite klasifikator po meri, pajek, opravila ETL in beležnico Jupyter.
- Pomaknite se do kataloga podatkov AWS Glue in izbrišite tabele, ki ste jih ustvarili.
- Na konzoli Amazon S3 se pomaknite do vedra, ki ste ga ustvarili, in izbrišite imenovane mape
temp,infer_schemainno_infer_schema.
Ključni izdelki
V AWS Glue obstaja funkcija, imenovana InferSchema v lepilu AWS DynamicFrames. Samodejno ugotovi strukturo podatkovnega okvira na podlagi podatkov, ki jih vsebuje. Nasprotno pa definiranje sheme pomeni eksplicitno navedbo, kakšna naj bo struktura podatkovnega okvira pred nalaganjem podatkov.
XML, ki je format, ki temelji na besedilu, ne omejuje vrst podatkov v svojih stolpcih. To lahko povzroči težave s funkcijo InferSchema. Na primer, v prvem zagonu datoteka s stolpcem A z vrednostjo 2 povzroči datoteko Parquet s stolpcem A kot celo število. V drugem zagonu ima nova datoteka stolpec A z vrednostjo C, kar vodi do datoteke Parquet s stolpcem A kot nizom. Zdaj sta na S3 dve datoteki, vsaka s stolpcem A z različnimi vrstami podatkov, kar lahko povzroči težave na nižji stopnji.
Enako se zgodi s kompleksnimi vrstami podatkov, kot so ugnezdene strukture ali polja. Na primer, če ima datoteka en vnos oznake, imenovan transaction, se sklepa kot struktura. Če pa ima druga datoteka enako oznako, se sklepa kot niz
Kljub tem težavam z vrsto podatkov, InferSchema je uporaben, ko ne poznate sheme ali pa je ročno definiranje nepraktično. Vendar pa ni idealen za velike ali nenehno spreminjajoče se nabore podatkov. Opredelitev sheme je bolj natančna, zlasti pri zapletenih tipih podatkov, vendar ima svoje težave, kot je zahteva ročnega truda in neprilagodljivost za spremembe podatkov.
InferSchema ima omejitve, kot je nepravilno sklepanje podatkovnega tipa in težave z obravnavanjem ničelnih vrednosti. Definiranje sheme ima tudi omejitve, kot so ročni napor in morebitne napake.
Izbira med sklepanjem in definiranjem sheme je odvisna od potreb projekta. InferSchema je odlična za hitro raziskovanje majhnih naborov podatkov, medtem ko je definiranje sheme boljše za večje, kompleksne nabore podatkov, ki zahtevajo natančnost in doslednost. Upoštevajte kompromise in omejitve vsake metode, da izberete tisto, ki najbolj ustreza vašemu projektu.
zaključek
V tej objavi smo raziskali dve tehniki za upravljanje podatkov XML z uporabo AWS Glue, od katerih je vsaka prilagojena posebnim potrebam in izzivom, na katere lahko naletite.
Tehnika 1 ponuja uporabniku prijazno pot za tiste, ki imajo raje grafični vmesnik. Uporabite lahko pajka AWS Glue in vizualni urejevalnik za enostavno definiranje strukture tabele za vaše datoteke XML. Ta pristop poenostavi postopek upravljanja podatkov in je še posebej privlačen za tiste, ki iščejo enostaven način za ravnanje s svojimi podatki.
Vendar se zavedamo, da ima pajek svoje omejitve, zlasti pri delu z datotekami XML z vrsticami, večjimi od 1 MB. Tu na pomoč priskoči tehnika 2. Z uporabo lepila AWS DynamicFrames z ugotovljenimi in fiksnimi shemami ter z uporabo prenosnega računalnika AWS Glue lahko učinkovito upravljate z datotekami XML katere koli velikosti. Ta metoda zagotavlja robustno rešitev, ki zagotavlja brezhibno obdelavo tudi za datoteke XML z vrsticami, ki presegajo omejitev 1 MB.
Ko krmarite po svetu upravljanja podatkov, vam te tehnike v kompletu orodij omogočajo sprejemanje premišljenih odločitev na podlagi posebnih zahtev vašega projekta. Ne glede na to, ali imate raje preprostost tehnike 1 ali razširljivost tehnike 2, AWS Glue zagotavlja prožnost, ki jo potrebujete za učinkovito obdelavo podatkov XML.
O avtorjih
 Navnit Shukladeluje kot specialist za rešitve AWS s poudarkom na analitiki. Ima velik entuziazem za pomoč strankam pri odkrivanju dragocenih vpogledov iz njihovih podatkov. S svojim strokovnim znanjem ustvarja inovativne rešitve, ki podjetjem omogočajo, da sprejemajo informirane odločitve, ki temeljijo na podatkih. Predvsem Navnit Shukla je uspešen avtor knjige z naslovom »Data Wrangling on AWS.
Navnit Shukladeluje kot specialist za rešitve AWS s poudarkom na analitiki. Ima velik entuziazem za pomoč strankam pri odkrivanju dragocenih vpogledov iz njihovih podatkov. S svojim strokovnim znanjem ustvarja inovativne rešitve, ki podjetjem omogočajo, da sprejemajo informirane odločitve, ki temeljijo na podatkih. Predvsem Navnit Shukla je uspešen avtor knjige z naslovom »Data Wrangling on AWS.
 Patrick Muller dela kot višji podatkovni laboratorijski arhitekt pri AWS. Njegova glavna odgovornost je pomagati strankam pri pretvorbi njihovih idej v podatkovni izdelek, pripravljen za proizvodnjo. V prostem času Patrick rad igra nogomet, gleda filme in potuje.
Patrick Muller dela kot višji podatkovni laboratorijski arhitekt pri AWS. Njegova glavna odgovornost je pomagati strankam pri pretvorbi njihovih idej v podatkovni izdelek, pripravljen za proizvodnjo. V prostem času Patrick rad igra nogomet, gleda filme in potuje.
 Amogh Gaikwad je višji razvijalec rešitev pri Amazon Web Services. Pomaga globalnim strankam zgraditi in uvesti rešitve AI/ML na AWS. Njegovo delo je v glavnem osredotočeno na računalniški vid in obdelavo naravnega jezika ter pomoč strankam pri optimizaciji njihovih delovnih obremenitev AI/ML za trajnost. Amogh je magistriral iz računalništva in se specializiral za strojno učenje.
Amogh Gaikwad je višji razvijalec rešitev pri Amazon Web Services. Pomaga globalnim strankam zgraditi in uvesti rešitve AI/ML na AWS. Njegovo delo je v glavnem osredotočeno na računalniški vid in obdelavo naravnega jezika ter pomoč strankam pri optimizaciji njihovih delovnih obremenitev AI/ML za trajnost. Amogh je magistriral iz računalništva in se specializiral za strojno učenje.
 Sheela Sonone je višji stalni arhitekt pri AWS. Strankam AWS pomaga pri ozaveščenih odločitvah in kompromisih glede pospeševanja podatkov, analitike ter delovnih obremenitev in implementacij AI/ML. V prostem času rada preživlja čas z družino – običajno na teniških igriščih.
Sheela Sonone je višji stalni arhitekt pri AWS. Strankam AWS pomaga pri ozaveščenih odločitvah in kompromisih glede pospeševanja podatkov, analitike ter delovnih obremenitev in implementacij AI/ML. V prostem času rada preživlja čas z družino – običajno na teniških igriščih.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- O meni
- POVZETEK
- pospeševanje
- dostop
- dostopnost
- doseženo
- natančnost
- čez
- Ukrep
- dodajte
- dodano
- Dodatne
- Naslov
- po
- starost
- AI / ML
- vsi
- omogočajo
- Dovoli
- omogoča
- Prav tako
- alternativa
- Amazon
- Amazonska Atena
- Amazon Web Services
- an
- Analiza
- analitika
- analizirati
- analiziranje
- in
- Še ena
- kaj
- Apache
- privlačna
- aplikacije
- Uporabi
- pristop
- pristopi
- Arhitektura
- SE
- Array
- AS
- pomoč
- pomoč
- At
- Avtor
- samodejno
- Na voljo
- AWS
- AWS lepilo
- nazaj
- temeljijo
- Osnovni
- BE
- ker
- pred
- začetek
- počutje
- BEST
- Boljše
- med
- prazno
- Knjiga
- tako
- izgradnjo
- podjetja
- vendar
- by
- se imenuje
- CAN
- Katalog
- Vzrok
- celica
- izzivi
- spremenite
- Spremembe
- spreminjanje
- možnosti
- Izberite
- mesto
- Razvrstitev
- stranke
- Koda
- Stolpec
- Stolpci
- COM
- prihaja
- Skupno
- pogosto
- dokončanje
- Končana
- kompleksna
- računalnik
- Računalništvo
- Računalniška vizija
- stanje
- Ravnanje
- veznik
- Razmislite
- Konzole
- nenehno
- omejitve
- gradnjo
- vsebujejo
- vseboval
- Vsebuje
- kontrast
- nadzor
- pretvorbo
- pretvori
- stroškovno učinkovito
- stroškovno učinkovita rešitev
- občine
- Sodišča
- zajeti
- gosenicah
- ustvarjajo
- ustvaril
- Ustvarjanje
- ključnega pomena
- po meri
- stranka
- Stranke, ki so
- datum
- integracija podatkov
- Upravljanje podatkov
- Podatkov usmerjenih
- Baze podatkov
- nabor podatkov
- deliti
- odločitve
- privzeto
- opredeliti
- definiranje
- potopite
- dokazuje,
- odvisno
- razporedi
- zasnovan
- podrobno
- Podrobnosti
- Razvojni
- drugačen
- težko
- digitalni
- digitalni dobi
- neposredno
- odkrivanje
- izrazit
- do
- Ne
- opravljeno
- dont
- DOT
- med
- dinamično
- vsak
- enostavnost
- enostavno
- lahka
- urednik
- učinek
- učinkovito
- učinkovitosti
- učinkovite
- učinkovito
- prizadevanje
- truda
- električni
- Električno vozilo
- elementi
- zaposlovanja
- opolnomočiti
- pooblašča
- prazen
- omogočajo
- omogočanje
- srečanje
- konec
- Motorji
- okrepi
- zagotovitev
- zagotavlja
- Vnesite
- navdušenje
- Vpis
- napake
- zlasti
- Eter (ETH)
- Tudi
- dogodki
- Tudi vsak
- Primer
- presega
- izmenjava
- strokovno znanje
- raziskovanje
- raziskuje
- Raziskano
- ekstrakt
- pridobivanje
- družina
- Feature
- Lastnosti
- Številke
- file
- datoteke
- financiranje
- prva
- Všita
- prilagodljivost
- Osredotočite
- osredotočena
- po
- za
- format
- FRAME
- brezplačno
- frekvenca
- iz
- funkcija
- Gain
- glavni namen
- ustvarjajo
- Globalno
- Go
- Cilj
- vlada
- veliko
- ročaj
- Ravnanje
- se zgodi
- Dovoljenje
- Imajo
- ob
- he
- zdravstveno varstvo
- Srce
- pomoč
- pomoč
- Pomaga
- jo
- na visoki ravni
- zelo
- njegov
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- IAM
- idealen
- Ideje
- identiteta
- if
- ponazarja
- izvajati
- izvedbe
- izvajanja
- uvoz
- izboljšanje
- izboljšalo
- in
- Vključno
- individualna
- posamezniki
- industrij
- Podatki
- obvestila
- Infrastruktura
- inovativne
- v notranjosti
- vpogledi
- Namesto
- Navodila
- integrirati
- integracija
- interaktivno
- zainteresirani
- vmesnik
- v
- vključuje
- Vprašanja
- IT
- ITS
- Job
- Delovna mesta
- jpg
- json
- Jupyter Notebook
- Imejte
- Vedite
- lab
- jezik
- velika
- večja
- vodi
- UČITE
- učenje
- Stopnja
- kot
- LIMIT
- Omejitev
- omejitve
- vrstica
- linije
- obremenitev
- nalaganje
- Logika
- si
- stroj
- strojno učenje
- Glavne
- v glavnem
- Znamka
- Izdelava
- upravljanje
- upravljanje
- Navodilo
- ročno
- več
- kartiranje
- poveljnika
- Maj ..
- pomeni
- Meni
- metapodatki
- Metoda
- min
- Model
- več
- učinkovitejše
- Najbolj
- premikanje
- filmi
- več
- Ime
- Imenovan
- Imena
- naravna
- Naravni jezik
- Obdelava Natural Language
- Krmarjenje
- ostalo
- potrebno
- Nimate
- potrebe
- Novo
- na novo
- Naslednja
- predvsem
- prenosnik
- zdaj
- Številka
- predmeti
- of
- Ponudbe
- on
- ONE
- samo
- operacije
- optimalna
- Optimizirajte
- Optimizira
- možnosti
- or
- Da
- organizacije
- izvor
- Ostalo
- naši
- ven
- izhod
- več
- Premagajte
- lastne
- Stran
- podokno
- parameter
- parametri
- del
- zlasti
- mimo
- pot
- Patrick
- opravlja
- performance
- Dovoljenja
- kramp
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- politika
- prebivalstvo
- imeti
- Prispevek
- potencial
- natančna
- raje
- predpogoji
- predogled
- prejšnja
- Težave
- Postopek
- obdelani
- obravnavati
- Izdelek
- Projekt
- projekti
- Lastnosti
- zagotavljajo
- zagotavlja
- objavijo
- Namen
- Python
- poizvedbe
- Hitri
- precej
- Preberi
- zlahka
- reading
- Razlogi
- prejetih
- priznajo
- glejte
- pomembno
- Zahteve
- reševanje
- vir
- Odgovor
- Odgovornost
- REST
- omejiti
- omejitev
- Rezultati
- robusten
- vloga
- koren
- ROW
- Run
- Enako
- Shrani
- Lestvica
- Prilagodljivost
- razširljive
- Znanost
- script
- brezšivne
- brez težav
- drugi
- Oddelek
- glej
- višji
- Storitve
- Zasedanje
- nastavite
- nastavitev
- več
- je
- Shell
- shouldnt
- Prikaži
- pokazale
- Razstave
- Podoben
- Enostavno
- preprostost
- poenostavitev
- sam
- Velikosti
- majhna
- So
- Soccer
- Rešitev
- rešitve
- nekaj
- vir
- Viri
- Spark
- specialist
- specializacijo
- specifična
- posebej
- hitrost
- Poraba
- SQL
- standardna
- začne
- Država
- Izjava
- navedbo
- Korak
- Koraki
- shranjevanje
- shranjeni
- naravnost
- racionalizirati
- String
- močna
- Struktura
- strukture
- studio
- uspeh
- taka
- primerna
- podpora
- Preverite
- Trajnostni razvoj
- sistemi
- miza
- TAG
- prilagojene
- Bodite
- meni
- Naloge
- tehnike
- tenis
- kot
- da
- O
- informacije
- svet
- njihove
- Njih
- POTEM
- Tukaj.
- te
- jih
- ta
- tisti,
- skozi
- čas
- Naslov
- z naslovom
- do
- današnje
- Orodje
- vrh
- temo
- Transform
- Preoblikovanje
- Potovanje
- Obračalni
- Navodila
- dva
- tip
- Vrste
- Končni
- pod
- Nadgradnja
- posodobljeno
- naložili
- us
- uporabnost
- uporaba
- Rabljeni
- uporabnik
- Uporabniški vmesnik
- Uporabniku prijazen
- uporablja
- uporabo
- navadno
- Uporaben
- dragocene
- vrednost
- Vrednote
- vozilo
- različica
- preko
- Poglej
- ogledov
- Vizija
- gledanju
- način..
- we
- web
- spletne storitve
- Kaj
- kdaj
- medtem ko
- ali
- ki
- WHO
- zakaj
- bo
- z
- v
- brez
- delo
- potek dela
- delovnih tokov
- deluje
- svet
- pisati
- XML
- jo
- Vaša rutina za
- zefirnet