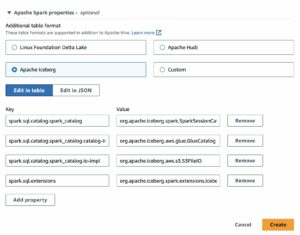
Apače Hudi je oblika odprte tabele, ki podatkovnim jezerom prinaša zmogljivosti baze podatkov in podatkovnega skladišča. Apache Hudi pomaga podatkovnim inženirjem pri obvladovanju zapletenih izzivov, kot je upravljanje stalno razvijajočih se naborov podatkov s transakcijami ob ohranjanju zmogljivosti poizvedb. Podatkovni inženirji uporabljajo Apache Hudi za pretakanje delovnih obremenitev kot tudi za ustvarjanje učinkovitih inkrementalnih podatkovnih cevovodov. Hudi zagotavlja mize, transakcije, učinkovita vstavljanja in brisanja, napredni indeksi, storitve pretakanja, podatki grozdenje in zbijanje optimizacije in nadzor sočasnosti, pri čemer so vaši podatki v odprtokodnih oblikah datotek. Hudijeve napredne optimizacije zmogljivosti omogočajo hitrejše analitične delovne obremenitve s katerim koli od priljubljenih poizvedovalnih mehanizmov, vključno z Apache Spark, Presto, Trino, Hive in tako naprej.
Številne stranke AWS so uporabile Apache Hudi na svojih podatkovnih jezerih, zgrajenih na vrhu Amazon S3 AWS lepilo, storitev integracije podatkov brez strežnika, ki olajša odkrivanje, pripravo, premikanje in integracijo podatkov iz več virov za analitiko, strojno učenje (ML) in razvoj aplikacij. AWS Glue Crawler je komponenta AWS Glue, ki vam omogoča samodejno ustvarjanje metapodatkov tabele iz vsebine podatkov, ne da bi morali ročno definirati metapodatke.
Pajki AWS Glue zdaj podpirajo tabele Apache Hudi, poenostavitev sprejemanja Katalog podatkov o lepilu AWS kot katalog miz Hudi. En tipičen primer uporabe je registracija tabel Hudi, ki nima definicije kataloške tabele. Drug tipičen primer uporabe je selitev iz drugih katalogov Hudi, kot je Hive metastore. Pri selitvi iz drugih katalogov Hudi lahko ustvarite in načrtujete pajka AWS Glue ter zagotovite eno ali več poti Amazon S3, kjer se nahajajo datoteke tabele Hudi. Imate možnost zagotoviti največjo globino poti Amazon S3, ki jih lahko prehodi pajek AWS Glue. Z vsakim zagonom bodo pajki AWS Glue ekstrahirali informacije o shemi in particiji ter posodobili katalog podatkov AWS Glue s spremembami sheme in particije. Pajki AWS Glue posodabljajo najnovejšo lokacijo metapodatkovne datoteke v katalogu podatkov AWS Glue, ki ga lahko analitični motorji AWS neposredno uporabljajo.
S tem zagonom lahko ustvarite in načrtujete pajka AWS Glue za registracijo tabel Hudi v katalogu podatkov AWS Glue. Nato lahko zagotovite eno ali več poti Amazon S3, kjer se nahajajo tabele Hudi. Imate možnost zagotoviti največjo globino poti Amazon S3, ki jih lahko prehodijo pajki. Z vsakim zagonom pajka pajek pregleda vsako od poti S3 in katalogizira informacije o shemi, kot so nove tabele, izbrisi in posodobitve shem v katalogu podatkov AWS Glue Data Catalog. Pajki pregledajo podatke o particiji in dodajo novo dodane particije v katalog podatkov AWS Glue. Pajki prav tako posodobijo lokacijo datoteke z najnovejšimi metapodatki v katalogu podatkov AWS Glue, ki ga lahko analitični motorji AWS neposredno uporabljajo.
Ta objava prikazuje, kako deluje ta nova zmožnost pajkanja tabel Hudi.
Kako pajek AWS Glue deluje s tabelami Hudi
Tabele Hudi imajo dve kategoriji, s posebnimi posledicami za vsako:
- Kopiraj pri pisanju (CoW) – Podatki so shranjeni v stolpčnem formatu (Parquet), vsaka posodobitev pa med pisanjem ustvari novo različico datotek.
- Spoji ob branju (MoR) – Podatki se shranjujejo s kombinacijo stolpčnega (Parquet) in vrstičnega (Avro) formata. Posodobitve se beležijo na podlagi vrstic
deltadatoteke in so po potrebi stisnjene za ustvarjanje novih različic stolpčnih datotek.
Pri naborih podatkov CoW se vsakič, ko pride do posodobitve zapisa, datoteka, ki vsebuje zapis, prepiše s posodobljenimi vrednostmi. Pri naboru podatkov MoR Hudi vsakič, ko pride do posodobitve, zapiše samo vrstico za spremenjen zapis. MoR je bolj primeren za težke delovne obremenitve pisanja ali spreminjanja z manj branja. CoW je bolj primeren za velike obremenitve pri branju podatkov, ki se manj pogosto spreminjajo.
Hudi ponuja tri vrste poizvedb za dostop do podatkov:
- Poizvedbe po posnetkih – Poizvedbe, ki vidijo najnovejši posnetek tabele glede na dano dejanje objave ali stiskanja. Za tabele MoR poizvedbe po posnetkih razkrijejo najnovejše stanje tabele tako, da združijo osnovne in delta datoteke zadnje rezine datoteke v času poizvedbe.
- Inkrementalne poizvedbe – Poizvedbe vidijo samo nove podatke, zapisane v tabelo, od dane objave ali stiskanja. To učinkovito zagotavlja tokove sprememb za omogočanje inkrementalnih podatkovnih cevovodov.
- Preberite optimizirane poizvedbe – Za tabele MoR poizvedbe vidijo najnovejše podatke strnjene. Za tabele CoW poizvedbe vidijo najnovejše posredovane podatke.
Za tabele kopiranja ob pisanju pajki ustvarijo eno samo tabelo v katalogu podatkov AWS Glue s funkcijo ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Za tabele spajanja ob branju pajki ustvarijo dve tabeli v katalogu podatkov AWS Glue Data Catalog za isto lokacijo tabele:
- Tabela s končnico
_ro, ki uporablja ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Tabela s končnico
_rt, ki uporablja RealTime Serde, ki omogoča poizvedbe Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Med vsakim iskanjem po vsebini za vsako podano pot Hudi pajki izvedejo klic API seznama Amazon S3, filtrirajo na podlagi .hoodie mape in poiščite najnovejšo datoteko z metapodatki v tej mapi z metapodatki tabele Hudi.
Preiščite tabelo Hudi CoW s pajkom AWS Glue
V tem razdelku si poglejmo, kako pajkati Hudi CoW z uporabo pajkov AWS Glue.
Predpogoji
Tukaj so predpogoji za to vadnico:
- Namestite in konfigurirajte AWS vmesnik ukazne vrstice (AWS CLI).
- Ustvarite svoje vedro S3, če ga nimate.
- Ustvarite svojo vlogo IAM za AWS Glue če ga nimate. Potrebujete
s3:GetObjectzas3://your_s3_bucket/data/sample_hudi_cow_table/. - Zaženite naslednji ukaz, da kopirate vzorčno tabelo Hudi v vedro S3. (Zamenjati
your_s3_bucketz imenom vedra S3.)
To navodilo vas vodi do kopiranja vzorčnih podatkov, vendar lahko preprosto ustvarite poljubne tabele Hudi z uporabo AWS Glue. Več o tem v Predstavljamo izvorno podporo za Apache Hudi, Delta Lake in Apache Iceberg na AWS Glue za Apache Spark, 2. del: vizualni urejevalnik AWS Glue Studio.
Ustvari pajka Hudi
V tem navodilu ustvarite pajka prek konzole. Izvedite naslednje korake, da ustvarite pajka Hudi:
- Na konzoli AWS Glue izberite Pajki.
- Izberite Ustvari pajka.
- za Ime, vnesite
hudi_cow_crawler. Izberite Naslednji. - Pod Konfiguracija vira podatkov, izberite Dodaj vir podatkov.
- za Vir podatkov, izberite Hudi.
- za Vključite poti tabele hudi, vnesite
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Zamenjatiyour_s3_bucketz imenom vedra S3.) - Izberite Dodajte vir podatkov Hudi.
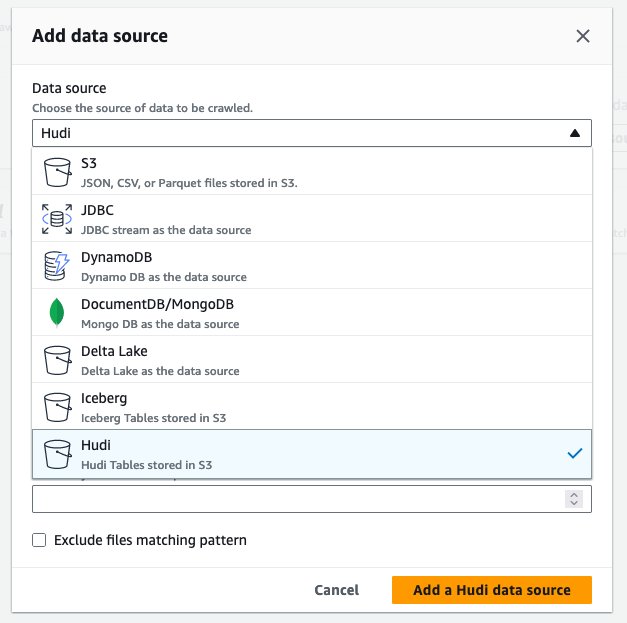
- Izberite Naslednji.
- za Obstoječa vloga IAM, izberite svojo vlogo IAM in nato izberite Naslednji.
- za Ciljna zbirka podatkov, izberite Dodaj bazo podatkov, nato pa Dodaj bazo podatkov prikaže se pogovorno okno. Za Ime baze podatkov, vnesite
hudi_crawler_blog, nato izberite ustvarjanje. Izberite Naslednji. - Izberite Ustvari pajka.
Zdaj je bil uspešno ustvarjen nov pajek Hudi. Pajka je mogoče sprožiti, da deluje prek konzole ali prek SDK ali AWS CLI z uporabo StartCrawl API. Prek konzole je lahko tudi razporejeno, da ob določenih urah sproži pajke. V tem navodilu zaženite pajka skozi konzolo.
- Izberite Zaženi pajek.
- Počakajte, da pajek dokonča.
Ko se pajek zažene, si lahko ogledate definicijo tabele Hudi v konzoli AWS Glue:
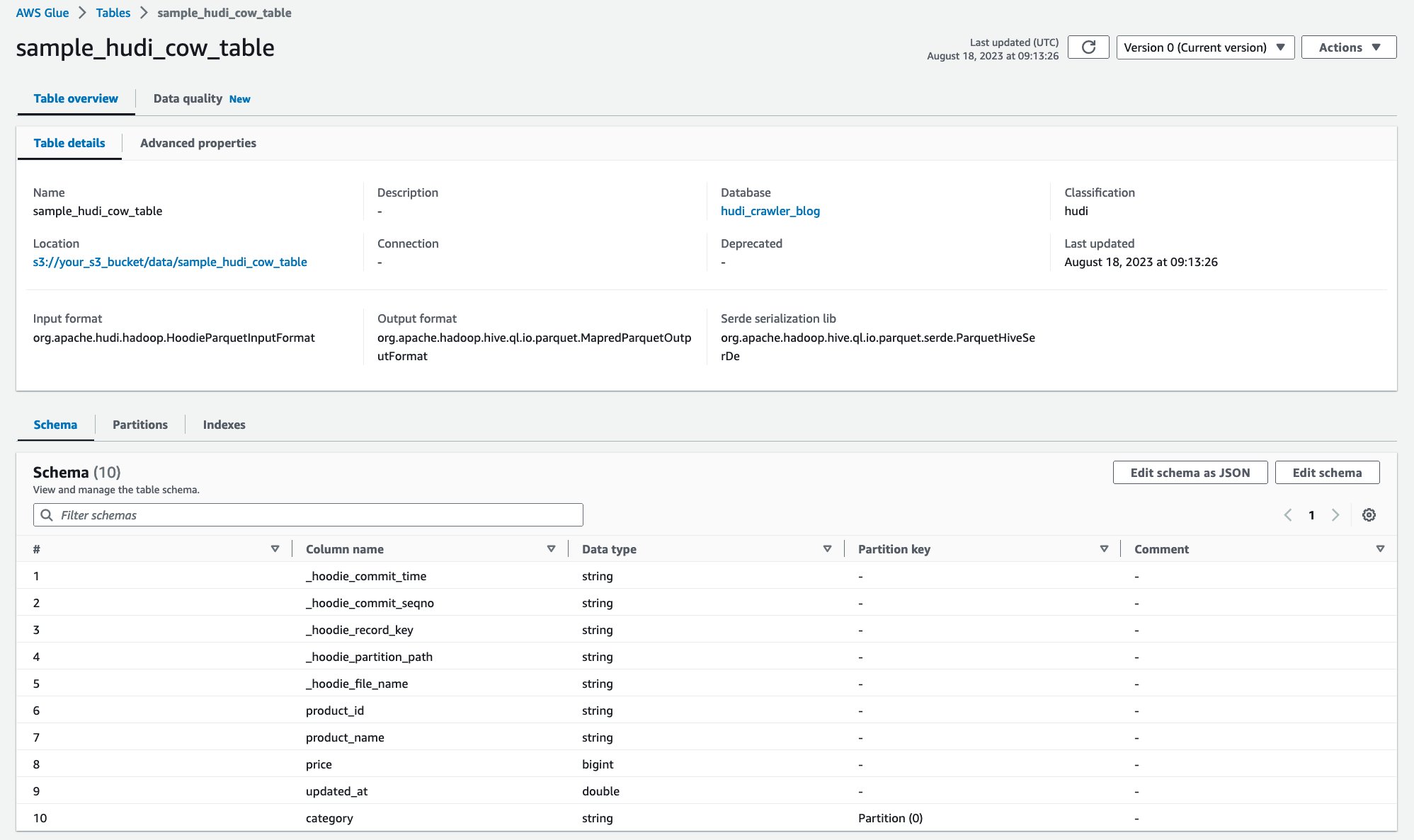
Uspešno ste preiskali tabelo Hudi CoR s podatki na Amazon S3 in ustvarili tabelo AWS Glue Data Catalog z izpolnjeno shemo. Ko ustvarite definicijo tabele v AWS Glue Data Catalog, lahko storitve analitike AWS, kot je Amazon Athena, poizvedujejo po tabeli Hudi.
Za začetek poizvedb na Atheni izvedite naslednje korake:
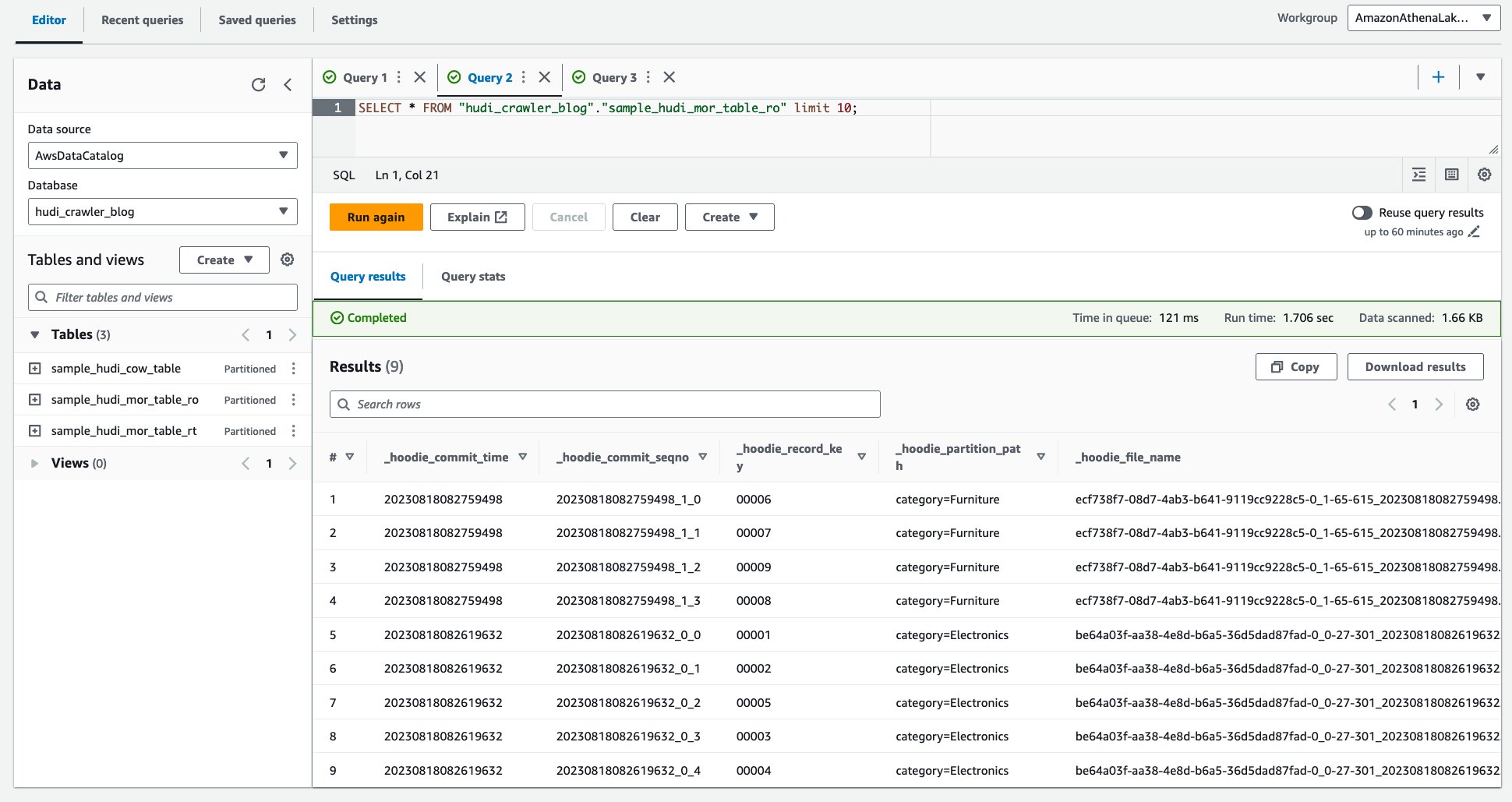
- Odprite konzolo Amazon Athena.
- Zaženite naslednjo poizvedbo.
Naslednji posnetek zaslona prikazuje naš rezultat:
Preglejte tabelo Hudi MoR s pajkom AWS Glue z dovoljenji za podatke AWS Lake Formation
V tem razdelku si poglejmo, kako pajkati tabelo Hudi MoR z uporabo lepila AWS. Tokrat uporabljate dovoljenje za podatke AWS Lake Formation za iskanje po virih podatkov Amazon S3 namesto dovoljenja IAM in Amazon S3. To ni obvezno, vendar poenostavlja konfiguracije dovoljenj, ko vaše podatkovno jezero upravljajo dovoljenja AWS Lake Formation.
Predpogoji
Tukaj so predpogoji za to vadnico:
- Namestite in konfigurirajte AWS vmesnik ukazne vrstice (AWS CLI).
- Ustvarite svoje vedro S3, če ga nimate.
- Ustvarite svojo vlogo IAM za AWS Glue če ga nimate. Potrebujete
lakeformation:GetDataAccess. Ampak ne potrebujetes3:GetObjectzas3://your_s3_bucket/data/sample_hudi_mor_table/ker za dostop do datotek uporabljamo podatkovno dovoljenje Lake Formation. - Zaženite naslednji ukaz, da kopirate vzorčno tabelo Hudi v vedro S3. (Zamenjati
your_s3_bucketz imenom vedra S3.)
Poleg korakov obdelave izvedite naslednje korake za posodobitev nastavitev kataloga podatkov AWS Glue za uporabo dovoljenj Lake Formation za nadzor virov kataloga namesto nadzora dostopa na podlagi IAM:
- Prijavite se v konzolo Lake Formation kot skrbnik podatkovnega jezera.
- Če prvič dostopate do konzole Lake Formation, dodajte sebe kot skrbnika podatkovnega jezera.
- Pod Administracija, izberite Nastavitve kataloga podatkov.
- za Privzeta dovoljenja za novo ustvarjene zbirke podatkov in tabele, prekliči izbiro Za nove zbirke podatkov uporabite samo nadzor dostopa IAM in Uporabite samo nadzor dostopa IAM za nove tabele v novih zbirkah podatkov.
- za Nastavitev različice med računi, izberite Verzija 3.
- Izberite Shrani.
Naslednji korak je registracija vašega vedra S3 v lokacijah podatkovnega jezera Lake Formation:
- Na konzoli Lake Formation izberite Lokacije podatkovnega jezera, in izberite Registriraj lokacijo.
- za Pot Amazon S3, vnesite
s3://your_s3_bucket/. (Zamenjatiyour_s3_bucketz imenom vedra S3.) - Izberite Registriraj lokacijo.
Nato pajku Glue dodelite dostop do lokacije podatkov, tako da lahko pajek uporabi dovoljenje Lake Formation za dostop do podatkov in ustvarjanje tabel na lokaciji:
- Na konzoli Lake Formation izberite Lokacije podatkov In izberite Grant.
- za Uporabniki in vloge IAM, izberite vlogo IAM, ki ste jo uporabili za pajka.
- za Mesto shranjevanja, vnesite
s3://your_s3_bucket/data/. (Zamenjatiyour_s3_bucketz imenom vedra S3.) - Izberite Grant.
Nato dodelite vlogo pajka za ustvarjanje tabel v bazi podatkov hudi_crawler_blog:
- Na konzoli Lake Formation izberite Dovoljenja podatkovnega jezera.
- Izberite Grant.
- za Ravnatelji, izberite Uporabniki in vloge IAMin izberite vlogo pajka.
- za LF oznake ali kataloški viri, izberite Viri imenskega kataloga podatkov.
- za Baze podatkov, izberite bazo podatkov
hudi_crawler_blog. - Pod Dovoljenja baze podatkovtako, da izberete Ustvari tabelo.
- Izberite Grant.
Ustvarite pajka Hudi z dovoljenji za podatke Lake Formation
Izvedite naslednje korake, da ustvarite pajka Hudi:
- Na konzoli AWS Glue izberite Pajki.
- Izberite Ustvari pajka.
- za Ime, vnesite
hudi_mor_crawler. Izberite Naslednji. - Pod Konfiguracija vira podatkov, izberite Dodaj vir podatkov.
- za Vir podatkov, izberite Hudi.
- za Vključite poti tabele hudi, vnesite
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Zamenjatiyour_s3_bucketz imenom vedra S3.) - Izberite Dodajte vir podatkov Hudi.
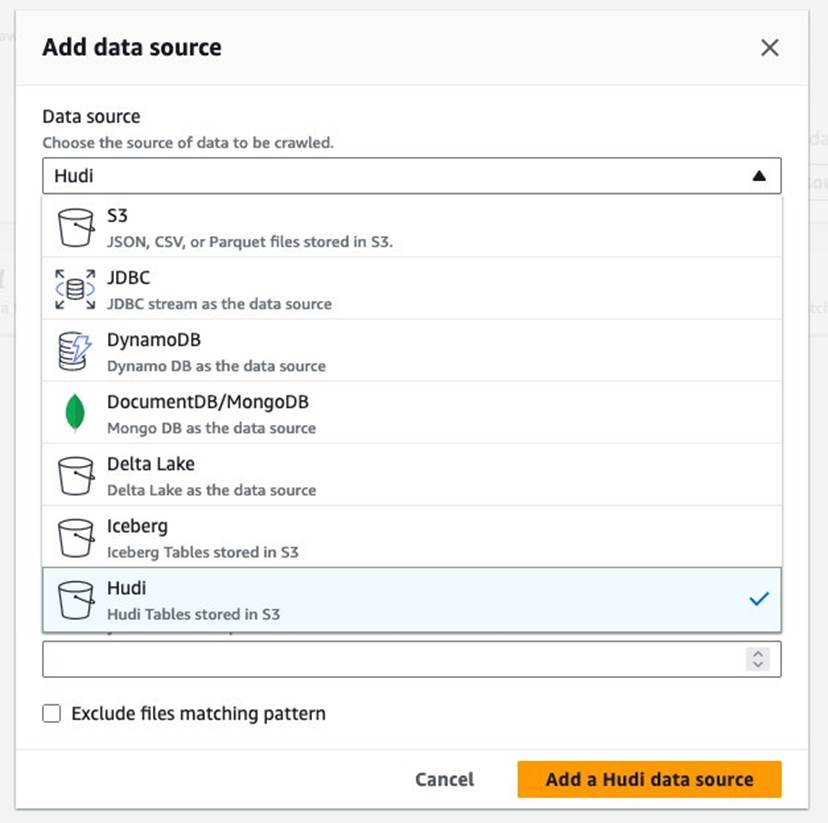
- Izberite Naslednji.
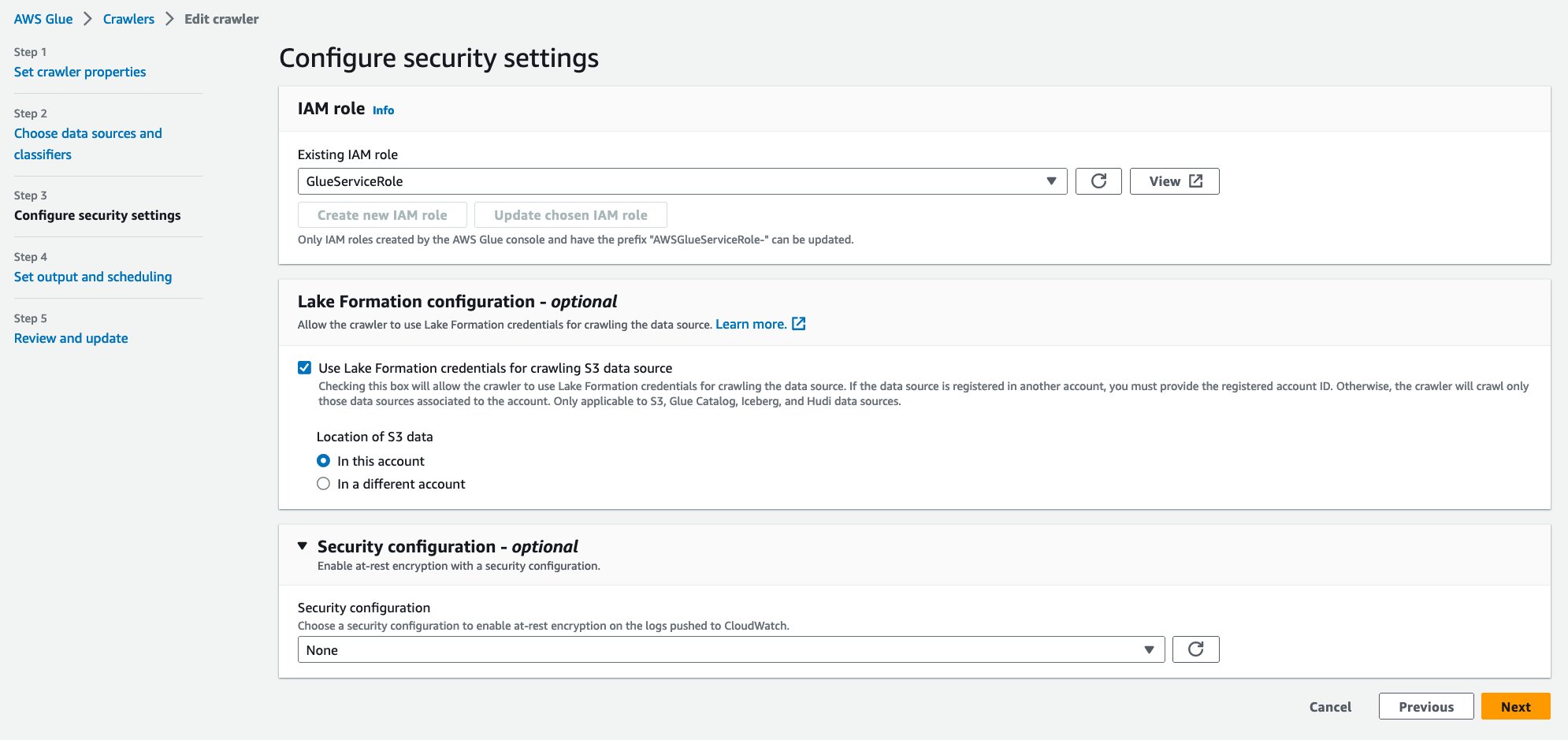
- za Obstoječa vloga IAM, izberite svojo vlogo IAM.
- Pod Konfiguracija Lake Formation – neobveznotako, da izberete Uporabite poverilnice Lake Formation za pajkanje vira podatkov S3.
- Izberite Naslednji.
- za Ciljna zbirka podatkov, izberite
hudi_crawler_blog. Izberite Naslednji. - Izberite Ustvari pajka.
Zdaj je bil uspešno ustvarjen nov pajek Hudi. Pajek uporablja poverilnice Lake Formation za iskanje po datotekah Amazon S3. Zaženimo novega pajka:
- Izberite Zaženi pajek.
- Počakajte, da pajek dokonča.
Ko se pajek zažene, si lahko ogledate dve tabeli definicije tabele Hudi v konzoli AWS Glue:
sample_hudi_mor_table_ro(beri optimizirano tabelo)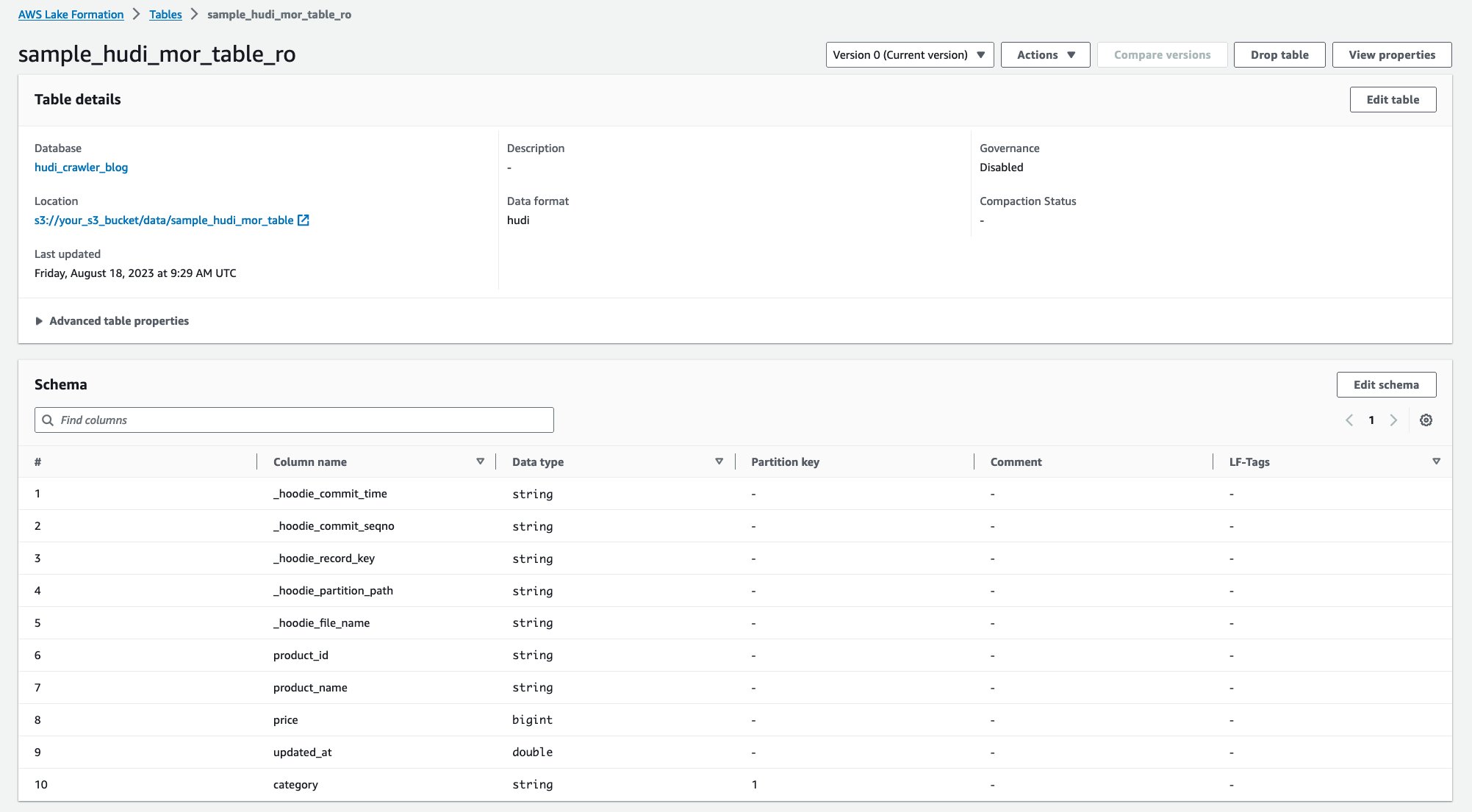
sample_hudi_mor_table_rt(tabela v realnem času)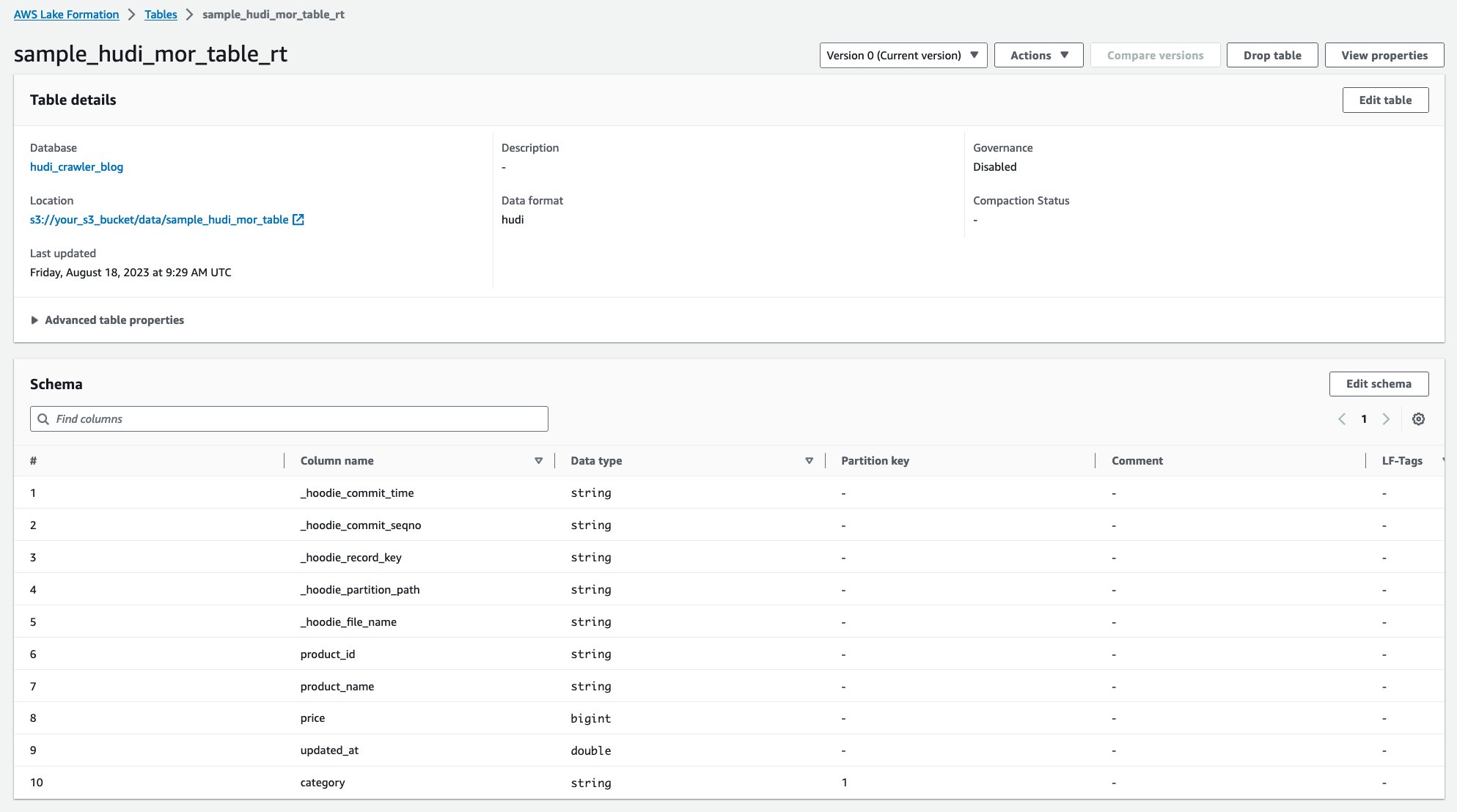
Registrirali ste vedro podatkovnega jezera pri Lake Formation in omogočili pajkanje do podatkovnega jezera z dovoljenji Lake Formation. Uspešno ste preiskali tabelo Hudi MoR s podatki na Amazon S3 in ustvarili tabelo kataloga podatkov AWS Glue s izpolnjeno shemo. Ko ustvarite definicije tabel v AWS Glue Data Catalog, lahko storitve analitike AWS, kot je Amazon Athena, poizvedujejo po tabeli Hudi.
Za začetek poizvedb na Atheni izvedite naslednje korake:
- Odprite konzolo Amazon Athena.
- Zaženite naslednjo poizvedbo.
Naslednji posnetek zaslona prikazuje naš rezultat:
- Zaženite naslednjo poizvedbo.
Naslednji posnetek zaslona prikazuje naš rezultat:
Natančen nadzor dostopa z uporabo dovoljenj AWS Lake Formation
Za uporabo natančnega nadzora dostopa na tabeli Hudi lahko izkoristite dovoljenja AWS Lake Formation. Dovoljenja Lake Formation vam omogočajo, da omejite dostop do določenih tabel, stolpcev ali vrstic in nato poizvedujete po tabelah Hudi prek Amazon Athena z natančnim nadzorom dostopa. Konfigurirajmo dovoljenje Lake Formation za tabelo Hudi MoR.
Predpogoji
Tukaj so predpogoji za to vadnico:
- Izpolnite prejšnji del Preglejte tabelo Hudi MoR s pajkom AWS Glue z dovoljenji za podatke AWS Lake Formation.
- Ustvarite uporabnika IAM DataAnalyst, ki ima pravilnik, ki ga upravlja AWS AmazonAthenaFullAccess.
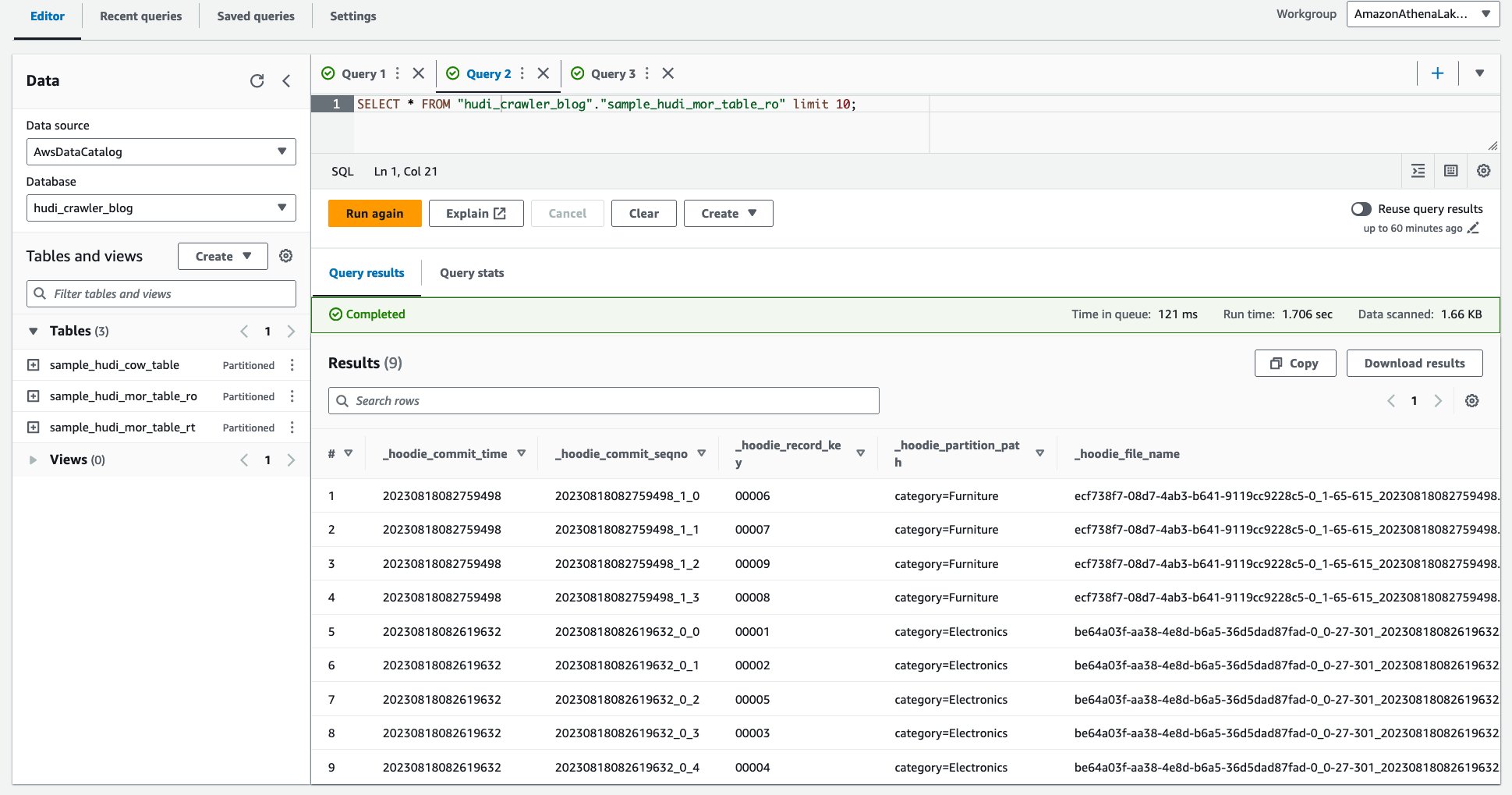
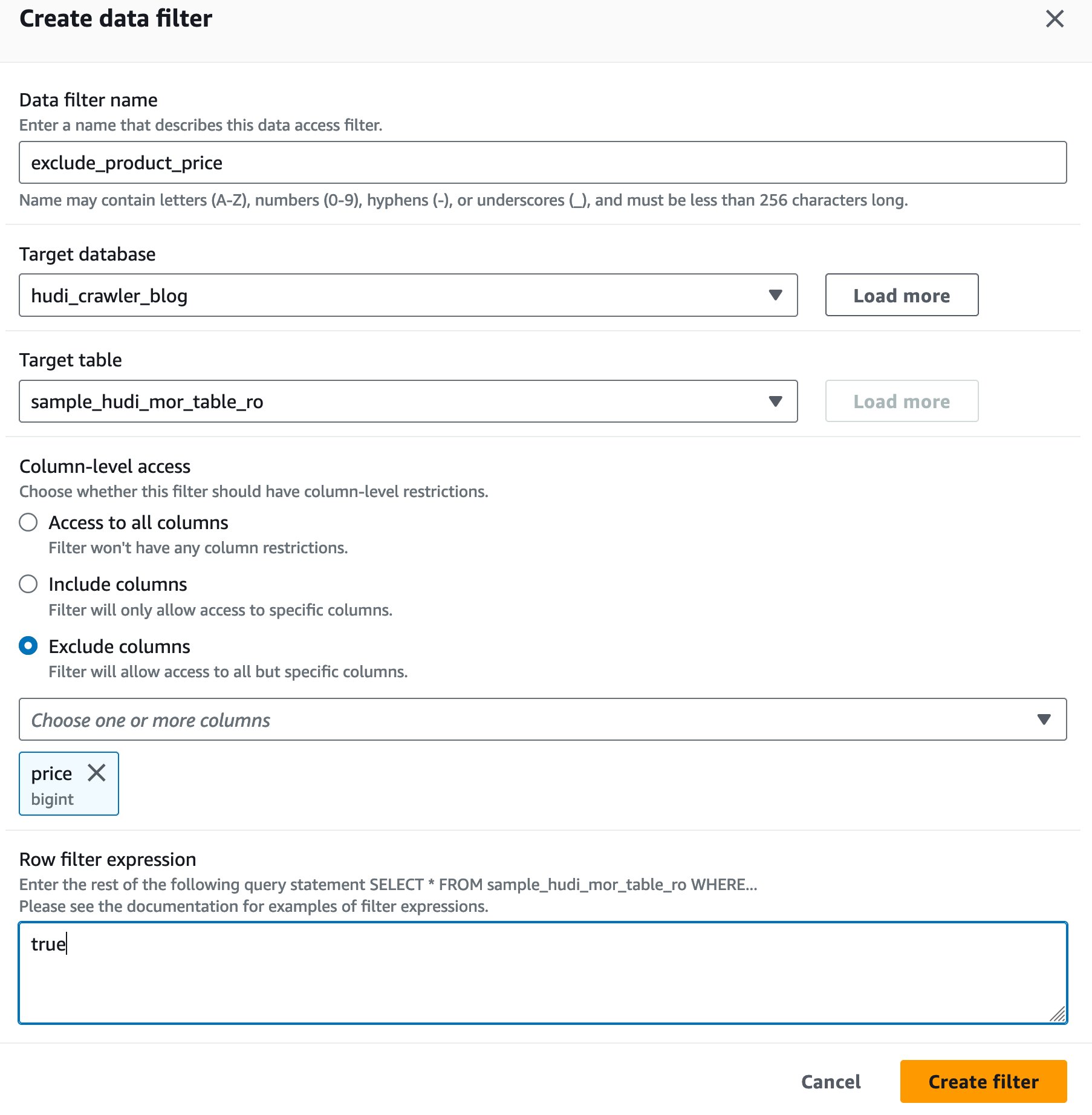
Ustvarite filter podatkovne celice Lake Formation
Najprej nastavimo filter za optimizirano tabelo za branje MoR.
- Prijavite se v konzolo Lake Formation kot skrbnik podatkovnega jezera.
- Izberite Podatkovni filtri.
- Izberite Ustvari nov filter.
- za Ime podatkovnega filtra, vnesite
exclude_product_price. - za Ciljna zbirka podatkov, izberite bazo podatkov
hudi_crawler_blog. - za Ciljna tabela, izberite tabelo
sample_hudi_mor_table_ro. - za Na ravni stolpca dostop, izberite Izključi stolpce, in izberite stolpec cena.
- za Izraz filtra vrstice, vnesite
true. - Izberite Ustvari filter.
Dodelite dovoljenja Lake Formation uporabniku DataAnalyst
Izvedite naslednje korake, da dodelite dovoljenje za nastanek jezera DataAnalyst uporabnik
- Na konzoli Lake Formation izberite Dovoljenja podatkovnega jezera.
- Izberite Grant.
- za Ravnatelji, izberite Uporabniki in vloge IAMin izberite uporabnika
DataAnalyst. - za LF oznake ali kataloški viri, izberite Viri imenskega kataloga podatkov.
- za Baze podatkov, izberite bazo podatkov
hudi_crawler_blog. - za Tabela – neobvezno, izberite tabelo
sample_hudi_mor_table_ro. - za Podatkovni filtri – neobvezno, izberite
exclude_product_price. - za Dovoljenja podatkovnega filtratako, da izberete Izberite.
- Izberite Grant.
Podelili ste dovoljenje Lake Formation za bazo podatkov hudi_crawler_blog in mizo sample_hudi_mor_table_ro, razen stolpca price uporabniku DataAnalyst. Zdaj pa preverimo uporabniški dostop do podatkov z Atheno.
- Prijavite se v konzolo Athena kot uporabnik DataAnalyst.
- V urejevalniku poizvedb zaženite naslednjo poizvedbo:
Naslednji posnetek zaslona prikazuje naš rezultat:
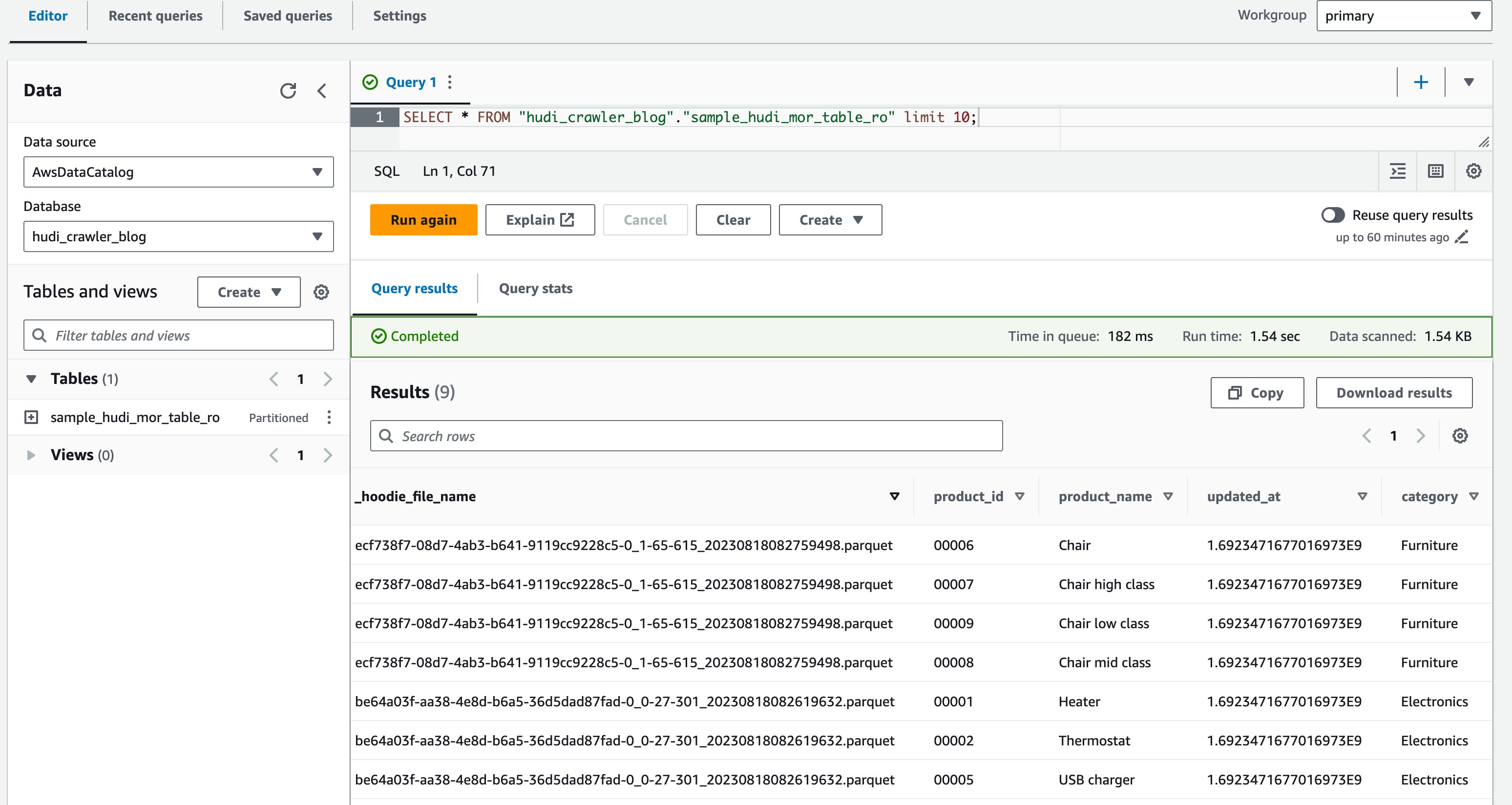
Zdaj ste potrdili ta stolpec price ni prikazan, ampak drugi stolpci product_id, product_name, update_atin category so prikazani.
Čiščenje
Da se izognete neželenim bremenitvam vašega računa AWS, izbrišite naslednje vire AWS:
- Izbrišite bazo podatkov AWS Glue
hudi_crawler_blog. - Izbrišite pajke AWS Glue
hudi_cow_crawlerinhudi_mor_crawler. - Izbrišite datoteke Amazon S3 pod
s3://your_s3_bucket/data/sample_hudi_cow_table/ins3://your_s3_bucket/data/sample_hudi_mor_table/.
zaključek
Ta objava je pokazala, kako pajki AWS Glue delujejo za tabele Hudi. S podporo za pajek Hudi se lahko hitro premaknete na uporabo kataloga podatkov AWS Glue kot svojega primarnega kataloga tabele Hudi. Svoje transakcijsko podatkovno jezero brez strežnika lahko začnete graditi s Hudijem na AWS z uporabo AWS Glue, AWS Glue Data Catalog in natančnega nadzora dostopa Lake Formation za tabele in formate, ki jih podpirajo analitični motorji AWS.
O avtorjih
 Noritaka Sekiyama je glavni arhitekt velikih podatkov v skupini AWS Glue. Deluje v Tokiu na Japonskem. Odgovoren je za gradnjo artefaktov programske opreme za pomoč strankam. V prostem času rad kolesari s svojim cestnim kolesom.
Noritaka Sekiyama je glavni arhitekt velikih podatkov v skupini AWS Glue. Deluje v Tokiu na Japonskem. Odgovoren je za gradnjo artefaktov programske opreme za pomoč strankam. V prostem času rad kolesari s svojim cestnim kolesom.
 Kyle Duong je inženir za razvoj programske opreme v skupini AWS Glue and Lake Formation. Navdušen je nad gradnjo tehnologij velikih podatkov in porazdeljenih sistemov.
Kyle Duong je inženir za razvoj programske opreme v skupini AWS Glue and Lake Formation. Navdušen je nad gradnjo tehnologij velikih podatkov in porazdeljenih sistemov.
 Sandeep Adwankar je višji tehnični produktni vodja pri AWS. S sedežem na območju kalifornijskega zaliva sodeluje s strankami po vsem svetu pri prevajanju poslovnih in tehničnih zahtev v izdelke, ki strankam omogočajo izboljšanje načina upravljanja, zaščite in dostopa do podatkov.
Sandeep Adwankar je višji tehnični produktni vodja pri AWS. S sedežem na območju kalifornijskega zaliva sodeluje s strankami po vsem svetu pri prevajanju poslovnih in tehničnih zahtev v izdelke, ki strankam omogočajo izboljšanje načina upravljanja, zaščite in dostopa do podatkov.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :ima
- : je
- :ne
- :kje
- $GOR
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Sposobna
- O meni
- dostop
- Dostop do podatkov
- Dostop
- Račun
- Ukrep
- dodajte
- dodano
- Poleg tega
- sprejet
- Sprejetje
- napredno
- po
- vsi
- omogočajo
- Dovoli
- omogoča
- Prav tako
- Amazon
- Amazonska Atena
- Amazon Web Services
- an
- Analitično
- analitika
- in
- Še ena
- kaj
- Apache
- Apache Spark
- API
- se prikaže
- uporaba
- Razvoj aplikacij
- Uporabi
- SE
- OBMOČJE
- okoli
- AS
- At
- samodejno
- izogniti
- AWS
- AWS lepilo
- Oblikovanje jezera AWS
- baza
- temeljijo
- zaliv
- BE
- ker
- bilo
- koristi
- Boljše
- Big
- Big Podatki
- Prinaša
- Building
- zgrajena
- poslovni
- vendar
- by
- california
- klic
- CAN
- Zmogljivosti
- zmožnost
- primeru
- Katalog
- kataloge
- kategorije
- celica
- izzivi
- spremenite
- spremenilo
- Spremembe
- Stroški
- Izberite
- Stolpec
- Stolpci
- kombinacija
- Zavezati
- storjeno
- dokončanje
- kompleksna
- komponenta
- konfiguracija
- Konzole
- Vsebuje
- vsebina
- stalno
- nadzor
- Nadzor
- bi
- gosenicah
- ustvarjajo
- ustvaril
- ustvari
- Mandatno
- Stranke, ki so
- datum
- integracija podatkov
- Data jezero
- podatkovno skladišče
- Baze podatkov
- baze podatkov
- nabor podatkov
- opredelitev
- definicije
- Delta
- Dokazano
- dokazuje,
- globina
- Razvoj
- neposredno
- odkriti
- porazdeljena
- porazdeljeni sistemi
- do
- ne
- med
- vsak
- lažje
- enostavno
- urednik
- učinkovito
- učinkovite
- omogočajo
- omogočena
- inženir
- Inženirji
- Motorji
- Vnesite
- Eter (ETH)
- razvija
- izključuje
- ekstrakt
- hitreje
- manj
- file
- datoteke
- filter
- Filtri
- Najdi
- prva
- prvič
- po
- za
- format
- Oblikovanje
- pogosto
- iz
- dana
- globus
- Go
- odobri
- odobreno
- Vodniki
- Hadoop
- Imajo
- he
- pomoč
- Pomaga
- njegov
- Panj
- Kako
- Kako
- HTML
- HTTPS
- IAM
- if
- posledice
- izboljšanje
- in
- Vključno
- inkrementalno
- Podatki
- Namesto
- integrirati
- integracija
- vmesnik
- v
- Predstavljamo
- IT
- Japonska
- jpg
- vzdrževanje
- Jezero
- jezera
- Zadnji
- kosilo
- UČITE
- učenje
- manj
- LIMIT
- vrstica
- Seznam
- nahaja
- kraj aktivnosti
- Lokacije
- prijavljen
- stroj
- strojno učenje
- vzdrževanje
- Znamka
- IZDELA
- upravljanje
- upravlja
- upravitelj
- upravljanje
- Navodilo
- največja
- združitev
- metapodatki
- selitev
- migracije
- ML
- več
- Najbolj
- premikanje
- več
- Ime
- materni
- Nimate
- potrebna
- Novo
- na novo
- Naslednja
- zdaj
- of
- on
- ONE
- samo
- odprite
- open source
- optimizirana
- Možnost
- or
- Ostalo
- naši
- izhod
- del
- strastno
- pot
- poti
- performance
- Dovoljenje
- Dovoljenja
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Popular
- naseljeno
- Prispevek
- Pripravimo
- predpogoji
- prejšnja
- Cena
- primarni
- , ravnateljica
- obravnavati
- Izdelek
- produktni vodja
- Izdelki
- zagotavljajo
- če
- zagotavlja
- poizvedbe
- hitro
- Preberi
- pravo
- v realnem času
- realtime
- nedavno
- zapis
- Registracija
- registriranih
- zamenjajte
- Zahteve
- viri
- odgovorna
- omejiti
- cesta
- vloga
- ROW
- Run
- Enako
- urnik
- načrtovano
- SDK
- Oddelek
- zavarovanje
- glej
- izberite
- višji
- Brez strežnika
- Storitev
- Storitve
- nastavite
- nastavitve
- pokazale
- Razstave
- poenostavlja
- saj
- sam
- Slice
- Posnetek
- So
- Software
- Razvoj programske opreme
- vir
- Viri
- Spark
- specifična
- Začetek
- Država
- Korak
- Koraki
- shranjeni
- pretakanje
- tokovi
- studio
- Uspešno
- taka
- podpora
- Podprti
- sinhronizacijo.
- sistemi
- miza
- skupina
- tehnični
- Tehnologije
- da
- O
- njihove
- POTEM
- Tukaj.
- jih
- ta
- 3
- skozi
- čas
- krat
- do
- tokio
- vrh
- transakcijski
- Transakcije
- prevesti
- prečkanje
- sprožijo
- sprožilo
- Navodila
- dva
- Vrste
- tipičen
- pod
- nezaželen
- Nadgradnja
- posodobljeno
- posodobitve
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- Uporabniki
- uporablja
- uporabo
- POTRDI
- potrjeno
- Vrednote
- različica
- vizualna
- Skladišče
- we
- web
- spletne storitve
- Dobro
- kdaj
- ki
- medtem
- WHO
- bo
- z
- brez
- delo
- deluje
- pisati
- pisni
- jo
- Vaša rutina za
- sami
- zefirnet