Amazon RedShift, široko uporabljano skladišče podatkov v oblaku, se je močno razvilo, da bi izpolnilo zahteve glede zmogljivosti najzahtevnejših delovnih obremenitev. Ta objava pokriva eno takšnih novih funkcij – ključ za razvrščanje večdimenzionalne postavitve podatkov.
Amazon Redshift zdaj izboljša učinkovitost vaše poizvedbe s podporo večdimenzionalnih ključev za razvrščanje postavitve podatkov, ki je nova vrsta ključa za razvrščanje, ki razvršča podatke tabele po predikatih filtrov namesto po fizičnih stolpcih tabele. Ključi za razvrščanje večdimenzionalne postavitve podatkov bodo bistveno izboljšali zmogljivost skeniranja tabel, zlasti če delovna obremenitev poizvedbe vsebuje ponavljajoče se filtre skeniranja.
Amazon Redshift že omogoča zmožnost avtomatska optimizacija tabele (ATO), ki samodejno optimizira zasnovo tabel z uporabo ključev za razvrščanje in distribucijo brez potrebe po skrbniškem posredovanju. V tej objavi predstavljamo ključe za razvrščanje večdimenzionalne postavitve podatkov kot dodatno zmožnost, ki jo ponuja ATO in jo krepi algoritem svetovalca za razvrščanje ključev Amazon Redshift.
Ključi za razvrščanje večdimenzionalne postavitve podatkov
Ko definirate tabelo s ključem za SAMODEJNO razvrščanje, bo Amazon Redshift ATO analiziral vašo zgodovino poizvedb in samodejno izbral ključ za razvrščanje v enem stolpcu ali ključ za razvrščanje večdimenzionalne postavitve podatkov za vašo tabelo, glede na to, katera možnost je boljša za vašo delovno obremenitev. Ko je izbrana večdimenzionalna postavitev podatkov, bo Amazon Redshift izdelal večdimenzionalno funkcijo razvrščanja, ki locira vrstice, do katerih običajno dostopajo iste poizvedbe, in funkcija razvrščanja se nato uporabi med izvajanjem poizvedbe za preskok podatkovnih blokov in celo preskok skeniranja posameznega predikata stolpce.
Razmislite o naslednji uporabniški poizvedbi, ki je prevladujoč vzorec poizvedbe v uporabnikovi delovni obremenitvi:
Amazon Redshift shranjuje podatke za vsak stolpec v 1 MB diskovnih blokih in shranjuje najmanjše in največje vrednosti v vsakem bloku kot del metapodatkov tabele. Če poizvedba uporablja a predikat z omejenim obsegom, lahko Amazon Redshift uporabi najmanjše in največje vrednosti za hiter preskok velikega števila blokov med skeniranjem tabele. Vendar filtra te poizvedbe v stolpcu podregije ni mogoče uporabiti za določitev, katere bloke je treba preskočiti na podlagi najmanjših in največjih vrednosti, zato Amazon Redshift pregleda vse vrstice iz tabele naslovov:
Ko je bila uporabniška poizvedba zagnana z titles z uporabo ključa za razvrščanje v enem stolpcu subregion, je rezultat prejšnje poizvedbe naslednji:
To kaže, da je pregled tabele prebral 2,164,081,640 vrstic.
Za izboljšanje skeniranja na titles Amazon Redshift se lahko samodejno odloči za uporabo ključa za razvrščanje večdimenzionalne postavitve podatkov. Vse vrstice, ki izpolnjujejo lower(subregion) like '%United States%' predikat bi bil nameščen v namensko regijo tabele, zato bo Amazon Redshift skeniral le podatkovne bloke, ki izpolnjujejo predikat.
Ko se izvede uporabnikova poizvedba z titles z uporabo ključa za razvrščanje večdimenzionalne postavitve podatkov, ki vključuje lower(subregion) like '%United States%' kot predikat, rezultat sys_query_detail poizvedba je naslednja:
To kaže, da je skeniranje tabele prebralo 152,324,046 vrstic, kar je samo 7 % izvirnika, in je uporabilo ključ za razvrščanje večdimenzionalne postavitve podatkov.
Upoštevajte, da ta primer uporablja eno samo poizvedbo za predstavitev funkcije večdimenzionalne postavitve podatkov, vendar bo Amazon Redshift upošteval vse poizvedbe, ki se izvajajo v tabeli, in lahko ustvari več regij, da zadovolji najpogosteje izvajane predikate.
Vzemimo drug primer, tokrat z bolj zapletenimi predikati in več poizvedbami.
Predstavljajte si, da imate mizo items (cost int, available int, demand int) s štirimi vrsticami, kot je prikazano v naslednjem primeru.
| #id | stroški | Na voljo | Povpraševanje |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Vaša prevladujoča delovna obremenitev je sestavljena iz dveh poizvedb:
- 70 % vzorec poizvedb:
- 20 % vzorec poizvedb:
S tradicionalnimi tehnikami razvrščanja se lahko odločite za razvrščanje tabele po stolpcu s stroški, tako da bo ocena cost > 3 bo imel koristi od vrste. Torej, tabela elementov po razvrščanju z enojnim cost bo videti takole.
| #id | stroški | Na voljo | Povpraševanje |
| Regija #1, s ceno <= 3 | |||
| Regija št. 2, s ceno > 3 | |||
| #id | stroški | Na voljo | Povpraševanje |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Z uporabo tega tradicionalnega razvrščanja lahko takoj izključimo zgornji dve (modri) vrstici z ID-jem 4 in ID-jem 2, ker ne izpolnjujeta cost > 3.
Po drugi strani pa bo z večdimenzionalnim ključem za razvrščanje postavitve podatkov tabela razvrščena na podlagi kombinacije dveh predikatov, ki se običajno pojavljata v delovni obremenitvi uporabnika, ki sta cost > 3 in available < demand. Posledično so vrstice tabele razvrščene v štiri regije.
| #id | stroški | Na voljo | Povpraševanje |
| Regija št. 1, s ceno <= 3 in na voljo < povpraševanja | |||
| Regija št. 2, s ceno <= 3 in na voljo >= povpraševanje | |||
| Regija št. 3, s ceno > 3 in na voljo < povpraševanja | |||
| Regija #4, s ceno > 3 in na voljo >= povpraševanje | |||
| #id | stroški | Na voljo | Povpraševanje |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Ta koncept je še močnejši, če ga uporabimo za celotne bloke namesto posameznih vrstic, ko ga uporabimo za kompleksne predikate, ki uporabljajo operatorje, ki niso primerni za tradicionalne tehnike razvrščanja (kot je npr. like), in kadar se uporablja za več kot dva predikata.
Sistemske tabele
Naslednje sistemske tabele Amazon Redshift bodo uporabnikom pokazale, ali so v njihovih tabelah in poizvedbah uporabljene večdimenzionalne postavitve podatkov:
- Če želite ugotoviti, ali določena tabela uporablja ključ za razvrščanje večdimenzionalne postavitve podatkov, lahko preverite, ali
sortkey1in svv_table_info je enakoAUTO(SORTKEY(padb_internal_mddl_key_col)). - Če želite ugotoviti, ali določena poizvedba uporablja večdimenzionalno postavitev podatkov za pospešitev skeniranja tabel, lahko preverite
step_attributev sys_query_detail pogled. Vrednost bo enakamulti-dimensionalče je bil med skeniranjem uporabljen ključ za razvrščanje večdimenzionalne postavitve podatkov tabele.
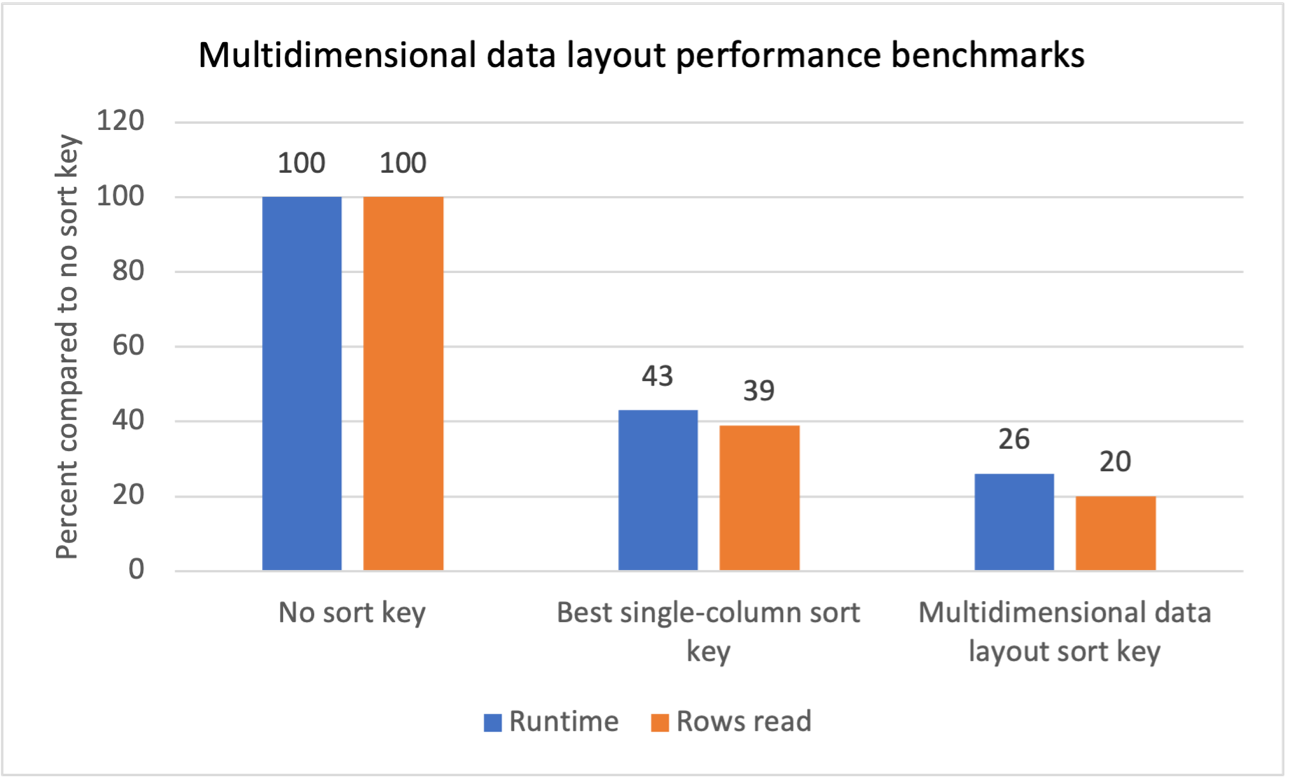
Merila uspešnosti
Izvedli smo interno primerjalno testiranje za več delovnih obremenitev s ponavljajočimi se filtri skeniranja in ugotovili, da je uvedba ključev za razvrščanje večdimenzionalne postavitve podatkov dala naslednje rezultate:
- Skupni čas izvajanja se zmanjša za 74 % v primerjavi z brez ključa za razvrščanje.
- Skupni čas izvajanja se zmanjša za 40 % v primerjavi z najboljšim ključem za razvrščanje v enem stolpcu v vsaki tabeli.
- 80-odstotno zmanjšanje skupnega števila vrstic, prebranih iz tabel, v primerjavi z brez ključa za razvrščanje.
- 47-odstotno zmanjšanje skupnega števila vrstic, prebranih iz tabel, v primerjavi z najboljšim ključem za razvrščanje v enem stolpcu v vsaki tabeli.
Primerjava funkcij
Z uvedbo večdimenzionalnih ključev za razvrščanje postavitve podatkov je zdaj mogoče vaše tabele razvrstiti po izrazih, ki temeljijo na predikatih filtrov, ki se pogosto pojavljajo v vaši delovni obremenitvi. Naslednja tabela ponuja primerjavo funkcij za Amazon Redshift z dvema konkurentoma.
| Feature | Amazon RedShift | Tekmovalec A | Tekmovalec B |
| Podpora za razvrščanje po stolpcih | Da | Da | Da |
| Podpora za razvrščanje po izrazu | Da | Da | Ne |
| Samodejna izbira stolpcev za razvrščanje | Da | Ne | Da |
| Samodejna izbira izrazov za razvrščanje | Da | Ne | Ne |
| Samodejna izbira med razvrščanjem stolpcev ali razvrščanjem izrazov | Da | Ne | Ne |
| Samodejna uporaba lastnosti razvrščanja za izraze med skeniranjem | Da | Ne | Ne |
Premisleki
Pri uporabi večdimenzionalne postavitve podatkov upoštevajte naslednje:
- Večdimenzionalna postavitev podatkov je omogočena, ko svojo tabelo nastavite kot SORTKEY AUTO.
- Amazon Redshift Advisor bo z analizo vaše pretekle delovne obremenitve samodejno izbral ključ za razvrščanje v enem stolpcu ali večdimenzionalno postavitev podatkov za tabelo.
- Amazon Redshift ATO prilagodi rezultate razvrščanja večdimenzionalne postavitve podatkov glede na način interakcije tekočih poizvedb z delovno obremenitvijo.
- Amazon Redshift ATO vzdržuje ključe za razvrščanje večdimenzionalne postavitve podatkov na enak način kot trenutno za obstoječe ključe za razvrščanje. Nanašati se na Delo s samodejno optimizacijo tabele za več podrobnosti o ATO.
- Ključi za razvrščanje večdimenzionalne postavitve podatkov bodo delovali tako z oskrbovanimi gručami kot z delovnimi skupinami brez strežnikov.
- Ključi za razvrščanje večdimenzionalne postavitve podatkov bodo delovali z vašimi obstoječimi podatki, dokler je v vaši tabeli omogočen AUTO SORTKEY in je zaznana delovna obremenitev s ponavljajočimi se filtri skeniranja. Tabela bo reorganizirana glede na rezultate funkcije večdimenzionalnega razvrščanja.
- Če želite onemogočiti tipke za razvrščanje večdimenzionalne postavitve podatkov za tabelo, uporabite alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. To onemogoči funkcijo ključa SAMODEJNO razvrščanje v tabeli. - Ključi za razvrščanje večdimenzionalne postavitve podatkov se ohranijo pri obnavljanju ali selitvi vaše oskrbljene gruče v gručo brez strežnika ali obratno.
zaključek
V tej objavi smo pokazali, da lahko večdimenzionalni ključi za razvrščanje postavitve podatkov znatno izboljšajo zmogljivost izvajalnega časa poizvedbe za delovne obremenitve, kjer imajo prevladujoče poizvedbe ponavljajoče se filtre skeniranja.
Če želite ustvariti gručo predogleda iz konzole Amazon Redshift, se pomaknite do Grozdi stran in izberite Ustvarite gručo predogleda. Ustvarite lahko gručo v regijah Vzhod ZDA (Ohio), Vzhod ZDA (N. Virginia), Zahod ZDA (Oregon), Azija Pacifik (Tokio), Evropa (Irska) in Evropa (Stockholm) ter preizkusite svoje delovne obremenitve.
Radi bi slišali vaše povratne informacije o tej novi funkciji in veselimo se vaših komentarjev na to objavo.
O avtorjih
 Milind Oke je specialist za rešitve za skladišča podatkov s sedežem v New Yorku. Že več kot 15 let gradi rešitve za skladišča podatkov in je specializiran za Amazon Redshift.
Milind Oke je specialist za rešitve za skladišča podatkov s sedežem v New Yorku. Že več kot 15 let gradi rešitve za skladišča podatkov in je specializiran za Amazon Redshift.
 Jialin Ding je uporabni znanstvenik v skupini Learned Systems Group, specializiran za uporabo tehnik strojnega učenja in optimizacije za izboljšanje učinkovitosti podatkovnih sistemov, kot je Amazon Redshift.
Jialin Ding je uporabni znanstvenik v skupini Learned Systems Group, specializiran za uporabo tehnik strojnega učenja in optimizacije za izboljšanje učinkovitosti podatkovnih sistemov, kot je Amazon Redshift.
 Yanzhu Ji je produktni vodja v ekipi Amazon Redshift. Ima izkušnje z vizijo in strategijo izdelkov v vodilnih podatkovnih izdelkih in platformah v industriji. Ima izjemno znanje pri gradnji obsežnih izdelkov programske opreme z uporabo spletnega razvoja, načrtovanja sistemov, baz podatkov in tehnik porazdeljenega programiranja. V osebnem življenju Yanzhu rada slika, fotografira in igra tenis.
Yanzhu Ji je produktni vodja v ekipi Amazon Redshift. Ima izkušnje z vizijo in strategijo izdelkov v vodilnih podatkovnih izdelkih in platformah v industriji. Ima izjemno znanje pri gradnji obsežnih izdelkov programske opreme z uporabo spletnega razvoja, načrtovanja sistemov, baz podatkov in tehnik porazdeljenega programiranja. V osebnem življenju Yanzhu rada slika, fotografira in igra tenis.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :ima
- : je
- :ne
- :kje
- 1
- 100
- 15 let
- 15%
- 152
- 7
- 8
- 9
- a
- pospeši
- dostopna
- Dodatne
- svetovalec
- po
- proti
- algoritem
- vsi
- že
- Amazon
- Amazon Web Services
- an
- analizirati
- analiziranje
- in
- Še ena
- uporabna
- Uporaba
- SE
- AS
- asia
- azijska pacifična
- avto
- Samodejno
- samodejno
- Na voljo
- AWS
- temeljijo
- BE
- ker
- bilo
- merilo
- koristi
- BEST
- Boljše
- med
- Block
- Bloki
- Modra
- tako
- Building
- vendar
- by
- CAN
- zmožnost
- preveriti
- Izberite
- Cloud
- Grozd
- Stolpec
- Stolpci
- kombinacija
- komentarji
- pogosto
- v primerjavi z letom
- Primerjava
- tekmovalci
- kompleksna
- Koncept
- Razmislite
- vsebuje
- Konzole
- gradnjo
- Vsebuje
- strošek
- prevleke
- ustvarjajo
- Trenutno
- datum
- podatkovno skladišče
- Baze podatkov
- odloča
- namenjen
- opredeliti
- Povpraševanje
- zahtevno
- Oblikovanje
- Podrobnosti
- Zaznali
- Ugotovite,
- Razvoj
- porazdeljena
- distribucija
- ne
- prevladujoč
- dont
- med
- vsak
- East
- bodisi
- omogočena
- Celotna
- enako
- zlasti
- Eter (ETH)
- Evropa
- Ocena
- Tudi
- razvil
- Primer
- obstoječih
- izkušnje
- izrazi
- Feature
- povratne informacije
- filter
- Filtri
- po
- sledi
- za
- Naprej
- štiri
- iz
- funkcija
- skupina
- strani
- Imajo
- ob
- he
- slišati
- jo
- zgodovinski
- zgodovina
- Vendar
- HTML
- HTTPS
- ID
- if
- takoj
- izboljšanje
- izboljšuje
- in
- vključuje
- individualna
- vodilne
- Namesto
- interakcijo
- notranji
- intervencije
- v
- uvesti
- Predstavljamo
- Predstavitev
- Irska
- IT
- Izdelkov
- Ključne
- tipke
- velika
- postavitev
- naučili
- učenje
- življenje
- kot
- všeč mi je
- Long
- Poglej
- izgleda kot
- ljubezen
- stroj
- strojno učenje
- vzdržuje
- upravitelj
- Način
- največja
- Srečati
- metapodatki
- morda
- selitev
- moti
- minimalna
- več
- Najbolj
- več
- Krmarjenje
- Nimate
- Novo
- nova funkcija
- NY
- št
- zdaj
- številke
- se pojavljajo
- of
- off
- ponujen
- Ohio
- on
- ONE
- v teku
- samo
- operaterji
- optimizacija
- Optimizira
- Možnost
- or
- Da
- Oregon
- izvirno
- Ostalo
- ven
- Neporavnani
- več
- Pacific
- Slika
- del
- zlasti
- Vzorec
- performance
- opravljeno
- Osebni
- fotografija
- fizično
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- Prispevek
- močan
- ohranjeno
- predogled
- Proizvedeno
- Izdelek
- produktni vodja
- Izdelki
- Programiranje
- Lastnosti
- zagotavlja
- poizvedbe
- hitro
- Preberi
- Zmanjšanje
- glejte
- okolica
- regije
- ponavljajoč
- Zahteve
- obnavljanje
- povzroči
- Rezultati
- Run
- tek
- deluje
- Enako
- skeniranje
- skeniranje
- skenira
- Znanstvenik
- Sezona
- glej
- izberite
- izbran
- izbor
- Brez strežnika
- Storitve
- nastavite
- je
- Prikaži
- predstavitev
- je pokazala,
- pokazale
- Razstave
- bistveno
- sam
- spretnost
- So
- Software
- rešitve
- specialist
- specializirano
- specializacijo
- trgovine
- Strategija
- Kasneje
- precejšen
- taka
- primerna
- Podpora
- sistem
- sistemi
- miza
- Bodite
- skupina
- tehnike
- tenis
- Test
- Testiranje
- kot
- da
- O
- njihove
- zato
- jih
- ta
- čas
- naslove
- do
- tokio
- vrh
- Skupaj za plačilo
- tradicionalna
- dva
- tip
- tipično
- us
- uporaba
- Rabljeni
- uporabnik
- Uporabniki
- uporablja
- uporabo
- vrednost
- Vrednote
- vice
- Poglej
- Virginia
- Vizija
- Skladišče
- je
- način..
- we
- web
- Izdelava spletnih strani
- spletne storitve
- West
- kdaj
- ali
- ki
- pogosto
- bo
- z
- brez
- delo
- bi
- let
- york
- jo
- Vaša rutina za
- zefirnet