Predstavitev
V hitro razvijajočem se okolju generativne umetne inteligence postaja osrednja vloga vektorskih baz podatkov vse bolj očitna. Ta članek se potopi v dinamično sinergijo med vektorskimi zbirkami podatkov in generativnimi rešitvami umetne inteligence ter raziskuje, kako te tehnološke podlage oblikujejo prihodnost ustvarjalnosti umetne inteligence. Pridružite se nam na potovanju skozi zapletenost tega močnega zavezništva in odkrijte vpogled v transformativni učinek, ki ga vektorske baze podatkov prinašajo v ospredje inovativnih rešitev AI.
Učni cilji
Ta članek vam pomaga razumeti vidike spodnje vektorske zbirke podatkov.
- Pomen vektorskih baz podatkov in njenih ključnih komponent
- Podrobna študija primerjave baze podatkov Vector s tradicionalno bazo podatkov
- Raziskovanje vektorskih vdelav z vidika uporabe
- Gradnja vektorske baze podatkov z uporabo Pincone
- Implementacija baze podatkov Pinecone Vector z uporabo modela langchain LLM
Ta članek je bil objavljen kot del Blogaton podatkovne znanosti.
Kazalo
Kaj je vektorska zbirka podatkov?
Vektorska zbirka podatkov je oblika zbirke podatkov, shranjenih v prostoru. Kljub temu je tukaj shranjen v matematičnih predstavitvah, saj oblika, shranjena v zbirkah podatkov, omogoča, da si odprti modeli umetne inteligence lažje zapomnijo vnose in naši odprti aplikaciji umetne inteligence omogoča uporabo kognitivnega iskanja, priporočil in ustvarjanja besedila za različne primere uporabe v digitalno preoblikovane industrije. Shranjevanje podatkov in pridobivanje se imenuje "vektorske vdelave" ali "vdelave". Poleg tega je to predstavljeno v formatu numerične matrike. Iskanje je veliko lažje kot tradicionalne zbirke podatkov, ki se uporabljajo za perspektive AI z ogromnimi indeksiranimi zmogljivostmi.
Značilnosti vektorskih baz podatkov
- Izkorišča moč teh vektorskih vdelav, kar vodi do indeksiranja in iskanja po ogromnem naboru podatkov.
- Kompakten z vsemi formati podatkov (slike, besedilo ali podatki).
- Ker prilagaja tehnike vdelave in visoko indeksirane funkcije, lahko ponudi popolno rešitev za upravljanje podatkov in vnosa za dano težavo.
- Vektorska zbirka podatkov organizira podatke prek visokodimenzionalnih vektorjev, ki vsebujejo na stotine dimenzij. Konfiguriramo jih lahko zelo hitro.
- Vsaka dimenzija ustreza določeni funkciji ali lastnosti podatkovnega objekta, ki ga predstavlja.
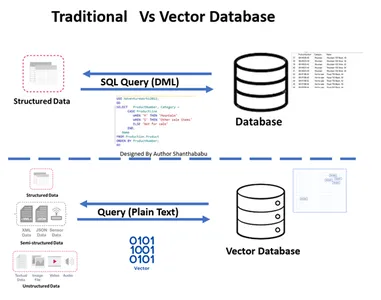
Tradicionalno vs. Vektorska zbirka podatkov
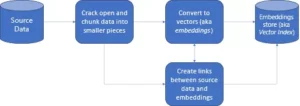
- Slika prikazuje potek dela tradicionalne in vektorske baze podatkov na visoki ravni
- Formalne interakcije baze podatkov potekajo prek SQL izjave in podatke, shranjene v obliki vrstice in tabele.
- V zbirki podatkov Vector se interakcije dogajajo prek navadnega besedila (npr. angleščina) in podatkov, shranjenih v matematičnih predstavitvah.
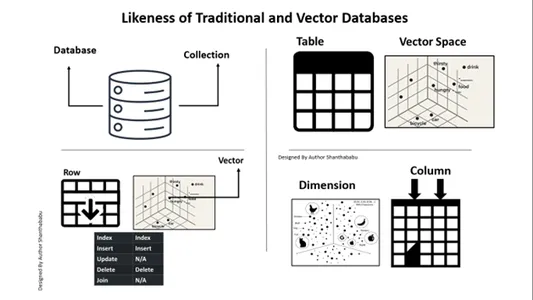
Podobnost tradicionalnih in vektorskih baz podatkov
Upoštevati moramo, kako se baze podatkov Vector razlikujejo od tradicionalnih. Razpravljajmo o tem tukaj. Ena hitra razlika, ki jo lahko navedem, je tista v običajnih zbirkah podatkov. Podatki so shranjeni natančno takšni, kot so; lahko dodamo nekaj poslovne logike za prilagoditev podatkov in združitev ali razdelitev podatkov glede na poslovne zahteve ali zahteve. Vendar ima vektorska podatkovna zbirka ogromno transformacijo in podatki postanejo kompleksna vektorska predstavitev.
Tukaj je zemljevid za vaše razumevanje in jasnost perspektive relacijske baze podatkov proti vektorskim zbirkam podatkov. Spodnja slika je samoumevna za razumevanje vektorskih baz podatkov s tradicionalnimi bazami podatkov. Skratka, izvajamo lahko vstavke in brisanja v vektorske baze podatkov, ne pa posodobitev izjav.
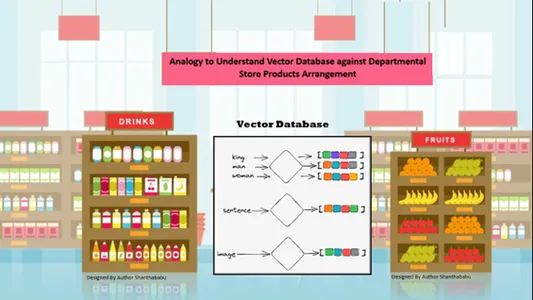
Preprosta analogija za razumevanje vektorskih baz podatkov
Podatki so samodejno prostorsko urejeni glede na vsebinsko podobnost shranjenih informacij. Torej, razmislimo o veleblagovnici za analogijo vektorske baze podatkov; vsi izdelki so na polici razvrščeni glede na naravo, namen, izdelavo, uporabo in količinsko osnovo. Podobno se obnašajo tudi podatki
samodejno razporejeni v vektorski zbirki podatkov po podobni sorti, tudi če zvrst med shranjevanjem ali dostopanjem do podatkov ni bila dobro definirana.
Vektorske baze podatkov omogočajo izrazito razdrobljenost in dimenzijo na določenih podobnostih, tako da kupec poišče želeni izdelek, proizvajalca in količino ter obdrži artikel v košarici. Vektorska zbirka podatkov shranjuje vse podatke v popolni strukturi shranjevanja; tukaj inženirjem strojnega učenja in umetne inteligence ni treba ročno označiti ali označiti shranjene vsebine.
Bistvene teorije v ozadju vektorskih podatkovnih zbirk
- Vektorske vdelave in njihov obseg
- Zahteve za indeksiranje
- Razumevanje semantičnega in podobnostnega iskanja
Vdelava vektorjev in njihov obseg
Vdelava vektorja je vektorska predstavitev v smislu numeričnih vrednosti. V stisnjenem formatu vdelave zajemajo inherentne lastnosti in povezave izvirnih podatkov, zaradi česar so stalnica v primerih uporabe umetne inteligence in strojnega učenja. Oblikovanje vdelav za kodiranje ustreznih informacij o izvirnih podatkih v nižjedimenzionalni prostor zagotavlja visoko hitrost iskanja, računalniško učinkovitost in učinkovito shranjevanje.
Zajemanje bistva podatkov na bolj enako strukturiran način je proces vdelave vektorjev, ki tvori 'model vdelave'. Navsezadnje ti modeli upoštevajo vse podatkovne objekte, izločijo pomembne vzorce in relacije znotraj vira podatkov ter jih pretvorijo v vektorske vdelave. Kasneje algoritmi izkoristijo te vektorske vdelave za izvajanje različnih nalog. Številni visoko razviti modeli vdelave, ki so na voljo na spletu kot brezplačni ali plačljivi po uporabi, olajšajo izvedbo vektorske vdelave.
Obseg vektorskih vdelav z vidika uporabe
Te vdelave so kompaktne, vsebujejo zapletene informacije, podedujejo razmerja med podatki, shranjenimi v vektorski zbirki podatkov, omogočajo učinkovito analizo obdelave podatkov za lažje razumevanje in sprejemanje odločitev ter dinamično gradnjo različnih inovativnih podatkovnih izdelkov v kateri koli organizaciji.
Tehnike vdelave vektorjev so bistvene pri povezovanju vrzeli med berljivimi podatki in kompleksnimi algoritmi. Ker so tipi podatkov numerični vektorji, smo lahko sprostili potencial za veliko različnih aplikacij Generative AI skupaj z razpoložljivimi modeli Open AI.
Več opravil z vdelavo vektorjev
Ta vdelava vektorjev nam pomaga opravljati več nalog:
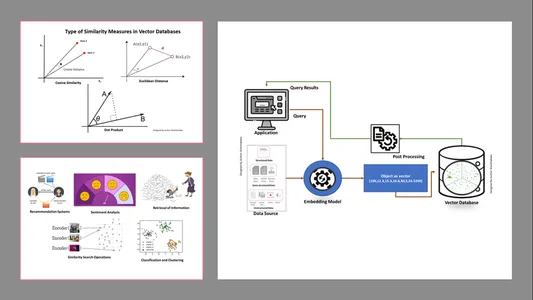
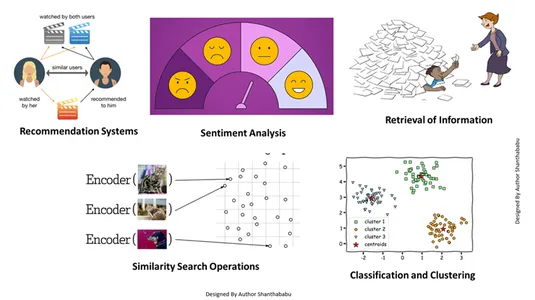
- Pridobivanje informacij: S pomočjo teh zmogljivih tehnik lahko zgradimo vplivne iskalnike, ki nam lahko pomagajo najti odgovore na podlagi uporabniških poizvedb iz shranjenih datotek, dokumentov ali medijev
- Operacije iskanja podobnosti: To je dobro organizirano in indeksirano; pomaga nam najti podobnost med različnimi pojavi v vektorskih podatkih.
- Razvrščanje in združevanje v skupine: Z uporabo teh tehnik vdelave lahko izvajamo te modele za usposabljanje ustreznih algoritmov strojnega učenja ter jih združujemo in razvrščamo.
- Sistemi priporočil: Ker so tehnike vdelave pravilno organizirane, to vodi do sistemov priporočil, ki natančno povezujejo izdelke, medije in članke na podlagi zgodovinskih podatkov.
- Analiza sentimenta: Ta model vdelave nam pomaga kategorizirati in izpeljati rešitve čustev.
Zahteve za indeksiranje
Kot vemo, bo indeks izboljšal iskalne podatke iz tabele v tradicionalnih bazah podatkov, podobnih vektorskim bazam podatkov, in zagotovil funkcije indeksiranja.
Vektorske podatkovne baze zagotavljajo "ravne indekse", ki so neposredna predstavitev vdelave vektorja. Zmožnost iskanja je celovita in ne uporablja vnaprej usposobljenih gruč. Izvede, da se vektor poizvedbe izvaja čez vsako posamezno vdelavo vektorja in K razdalj se izračuna za vsak par.
- Zaradi enostavnosti tega indeksa je za ustvarjanje novih indeksov potreben minimalen izračun.
- Ravni indeks lahko dejansko obravnava poizvedbe in zagotavlja hitre čase iskanja.
Razumevanje semantičnega in podobnostnega iskanja
V vektorskih zbirkah podatkov izvajamo dve različni iskanji: semantično in podobnostno iskanje.
- Semantično iskanje: Pri iskanju informacij lahko namesto iskanja po ključnih besedah le-te najdete na podlagi metodologije smiselnega pogovora. Hiter inženiring igra ključno vlogo pri prenosu vnosa v sistem. To iskanje nedvomno omogoča bolj kakovostno iskanje in rezultate, ki jih je mogoče uporabiti za inovativne aplikacije, SEO, ustvarjanje besedila in povzemanje.
- Iskanje podobnosti: Pri analizi podatkov iskanje podobnosti vedno omogoča nestrukturirane, veliko bolje podane nize podatkov. Pri vektorskih bazah podatkov moramo ugotoviti bližino dveh vektorjev in kako sta si podobna: tabele, besedilo, dokumenti, slike, besede in zvočne datoteke. V procesu razumevanja se podobnost med vektorji razkrije kot podobnost med podatkovnimi objekti v danem nizu podatkov. Ta vaja nam pomaga razumeti interakcijo, prepoznati vzorce, pridobiti vpoglede in sprejemati odločitve z vidika aplikacije. Iskanje po semantiki in podobnosti bi nam pomagalo zgraditi spodnje aplikacije za koristi industrije.
- Pridobivanje informacij: Z uporabo odprtih AI in vektorskih baz podatkov bi zgradili iskalnike za iskanje informacij z uporabo poizvedb poslovnih ali končnih uporabnikov in indeksiranih dokumentov znotraj vektorske baze podatkov.
- Razvrščanje in združevanje v skupine:Klasificiranje ali združevanje podobnih podatkovnih točk ali skupin predmetov vključuje njihovo dodeljevanje v več kategorij na podlagi skupnih značilnosti.
- Odkrivanje nepravilnosti: Odkrivanje odstopanj od običajnih vzorcev z merjenjem podobnosti podatkovnih točk in odkrivanjem nepravilnosti.
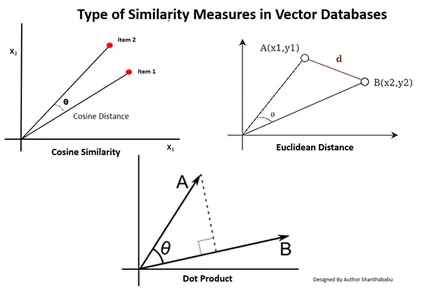
Vrste mer podobnosti v vektorskih bazah podatkov
Metode merjenja so odvisne od narave podatkov in specifične aplikacije. Običajno se za merjenje podobnosti in poznavanja strojnega učenja uporabljajo tri metode.
Evklidska razdalja
Preprosto povedano, razdalja med obema vektorjema je razdalja v ravni črti med dvema vektorskima točkama, ki merita st.
Dot Product
To nam pomaga razumeti poravnavo med dvema vektorjema, ki kaže, ali kažeta v isto smer, nasprotni smeri ali sta pravokotna drug na drugega.
Kosinus podobnosti
Ocenjuje podobnost dveh vektorjev z uporabo kota med njima, kot je prikazano na sliki. V tem primeru so vrednosti in velikost vektorjev nepomembne in ne vplivajo na rezultate; pri izračunu se upošteva le kot.
Tradicionalne baze podatkov Iskanje natančnih ujemanj stavkov SQL in pridobivanje podatkov v obliki tabele. Istočasno se ukvarjamo z vektorskimi bazami podatkov, ki iščejo najbolj podoben vektor vhodni poizvedbi v navadni angleščini s tehnikami Prompt Engineering. Podatkovna baza uporablja iskalni algoritem približnega najbližjega soseda (ANN) za iskanje podobnih podatkov. Vedno zagotovite razmeroma natančne rezultate z visoko zmogljivostjo, natančnostjo in odzivnim časom.
Delovni mehanizem
- Vektorske baze podatkov najprej pretvorijo podatke v vdelane vektorje, jih shranijo v vektorske baze podatkov in ustvarijo indeksiranje za hitrejše iskanje.
- Poizvedba iz aplikacije bo sodelovala z vdelanim vektorjem, iskala najbližjega soseda ali podobne podatke v vektorski bazi podatkov z uporabo indeksa in pridobila rezultate, posredovane aplikaciji.
- Na podlagi poslovnih zahtev bi bili pridobljeni podatki natančno nastavljeni, oblikovani in prikazani strani končnega uporabnika ali viru poizvedb ali dejanj.
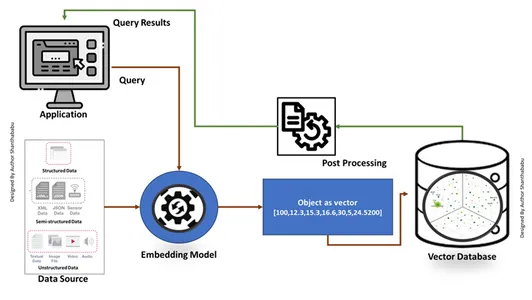
Ustvarjanje vektorske baze podatkov
Povežimo se s Pinecone.
S Pinecone se lahko povežete z Google, GitHub ali Microsoft ID.
Ustvarite novo uporabniško prijavo za svojo uporabo.
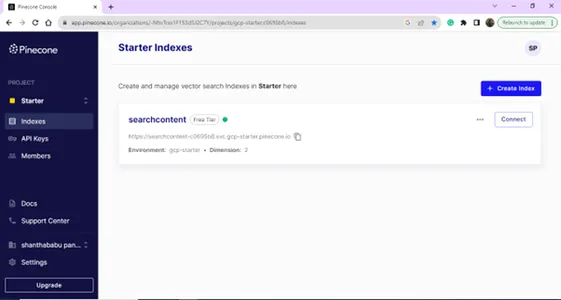
Po uspešni prijavi boste pristali na strani Index; ustvarite lahko indeks za namene vaše vektorske baze podatkov. Kliknite na gumb Ustvari indeks.
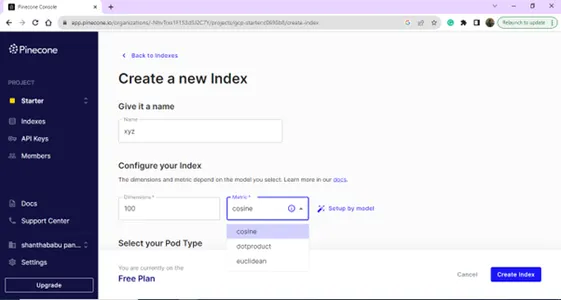
Ustvarite nov indeks tako, da vnesete ime in dimenzije.
Stran z indeksnim seznamom,
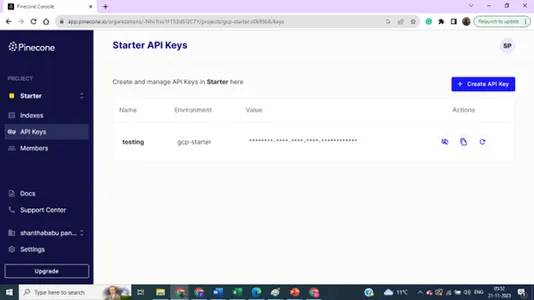
Podrobnosti indeksa – ime, regija in okolje – vse te podrobnosti potrebujemo za povezavo naše vektorske baze podatkov s kodo gradnje modela.
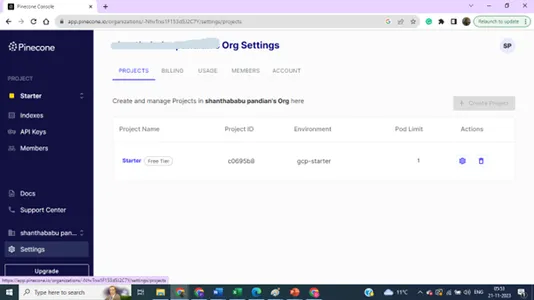
podrobnosti o nastavitvah projekta,
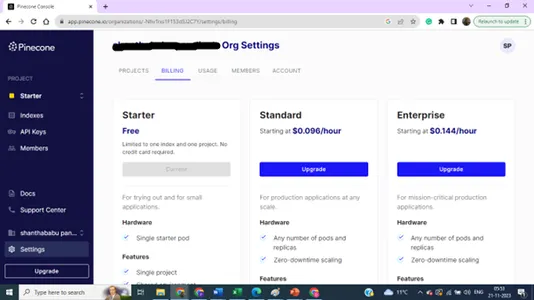
Za namene projekta lahko nadgradite svoje nastavitve za več indeksov in ključev.
Doslej smo razpravljali o ustvarjanju indeksa vektorske baze podatkov in nastavitev v Pinecone.
Izvedba vektorske baze podatkov z uporabo Pythona
Naredimo nekaj kodiranja.
Uvoz knjižnic
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIZagotavljanje ključa API za zbirko podatkov OpenAI in Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Začetek LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Začetek Pinecon
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Nalaganje datoteke .csv za izdelavo vektorske baze podatkov
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Besedilo razdelite na dele
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Iskanje besedila v text_chunk
text_chunksizhod
[Document(page_content='name: 100% Brannmfr: Nntype: Ccalories: 70nprotein: 4nmaščobe: 1nsodium: 130nfiber: 10ncarbo: 5nsugars: 6npotass: 280nvitamini: 25nshelf: 3nweight: 1ncups: 0.33nrating: 68.402973 100npriporočilo: Otroci, metapodatki={ 'vir': '0 % otrobi', 'vrstica': XNUMX}), , …..
Vgradnja stavbe
embeddings = OpenAIEmbeddings()Ustvarite primerek Pinecone za vektorsko bazo podatkov iz 'data'
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Ustvarite retriever za poizvedovanje po vektorski bazi podatkov.
retriever = vectordb.as_retriever(score_threshold = 0.7)Pridobivanje podatkov iz vektorske baze
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsUporabite Poziv in pridobite podatke
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Poizvedimo po podatkih.
chain('Can you please provide cereal recommendation for Kids?')Izhod iz poizvedbe
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]zaključek
Upam, da razumete, kako delujejo vektorske baze podatkov, njihove komponente, arhitektura in značilnosti vektorskih baz podatkov v generativnih rešitvah AI. Razumeti, kako se vektorska baza podatkov razlikuje od tradicionalne baze podatkov in primerjati z običajnimi elementi baze podatkov. Dejansko vam analogija pomaga bolje razumeti vektorsko bazo podatkov. Vektorska zbirka storžev in koraki indeksiranja bi vam pomagali ustvariti vektorsko bazo podatkov in prinesli ključ za naslednjo implementacijo kode.
Ključni izdelki
- Zgoščen s strukturiranimi, nestrukturiranimi in polstrukturiranimi podatki.
- Prilagaja tehnike vdelave in visoko indeksirane funkcije.
- Interakcije potekajo prek navadnega besedila z uporabo poziva (npr. angleščina). In podatki, shranjeni v matematičnih predstavitvah.
- Podobnost se kalibrira v vektorskih zbirkah podatkov prek – evklidske razdalje, kosinusne podobnosti in pikčastega produkta.
Pogosto zastavljena vprašanja
A. Vektorska zbirka podatkov shranjuje zbirko podatkov v prostoru. Podatke hrani v matematičnih predstavitvah. ker oblika, shranjena v podatkovnih zbirkah, olajša odprtim modelom umetne inteligence, da si zapomnijo prejšnje vnose, naši odprti aplikaciji umetne inteligence pa omogoča uporabo kognitivnega iskanja, priporočil in natančnega ustvarjanja besedila za različne primere uporabe v digitalno preoblikovanih panogah.
A. Nekatere značilnosti so: 1. Izkorišča moč teh vektorskih vdelav, kar vodi do indeksiranja in iskanja po ogromnem naboru podatkov. 2. Združljiv s strukturiranimi, nestrukturiranimi in polstrukturiranimi podatki. 3. Vektorska zbirka podatkov organizira podatke prek visokodimenzionalnih vektorjev, ki vsebujejo na stotine dimenzij
A. Baza podatkov ==> Zbirke
Tabela==> Vektorski prostor
Vrstica==>Cector
Stolpec==>Dimenzija
V vektorskih zbirkah podatkov je možno vstavljanje in brisanje, tako kot v tradicionalni bazi podatkov.
Posodobitev in pridružitev nista v obsegu.
– Hitro pridobivanje informacij za množično zbiranje podatkov.
– Operacije iskanja semantike in podobnosti iz dokumentov ogromne velikosti.
– Aplikacija za razvrščanje in združevanje v gruče.
– Sistemi za analizo priporočil in razpoloženja.
A5: Spodaj so tri metode za merjenje podobnosti:
– Evklidska razdalja
– Kosinusna podobnost
– Dot Product
Mediji, prikazani v tem članku, niso v lasti Analytics Vidhya in se uporabljajo po lastni presoji avtorja.
Podobni
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :ima
- : je
- :ne
- $GOR
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Sposobna
- O meni
- Dostop
- natančnost
- natančna
- natančno
- čez
- prilagaja
- dodajte
- vplivajo
- AI
- AI modeli
- algoritem
- algoritmi
- poravnava
- vsi
- Alliance
- omogočajo
- omogoča
- skupaj
- vedno
- med
- an
- Analiza
- analitika
- Analitika Vidhya
- in
- odgovor
- kaj
- API
- očitno
- uporaba
- specifično za aplikacijo
- aplikacije
- približno
- Arhitektura
- SE
- urejeno
- Array
- članek
- članki
- umetni
- Umetna inteligenca
- Umetna inteligenca in strojno učenje
- AS
- vidiki
- ocenjuje
- združenja
- At
- audio
- samodejno
- Na voljo
- temeljijo
- BE
- postanejo
- postane
- vedenje
- zadaj
- počutje
- spodaj
- Prednosti
- Boljše
- med
- blogaton
- prinašajo
- izgradnjo
- Building
- poslovni
- Gumb
- by
- izračuna
- izračun
- se imenuje
- CAN
- Zmogljivosti
- zmožnost
- zajemanje
- primeru
- primeri
- kategorije
- verige
- verige
- lastnosti
- jasnost
- Razvrstitev
- Razvrsti
- klik
- grozdenje
- Koda
- Kodiranje
- kognitivni
- zbirka
- pogosto
- kompaktna
- primerjate
- Primerjava
- dokončanje
- kompleksna
- deli
- celovito
- računanje
- računalniški
- Connect
- Povezovanje
- Razmislite
- šteje
- vsebujejo
- vsebina
- ozadje
- konvencionalne
- Pogovor
- pretvorbo
- ustreza
- bi
- ustvarjajo
- Ustvarjanje
- ustvarjalnost
- stranka
- datum
- Analiza podatkov
- podatkovne točke
- obdelava podatkov
- Baze podatkov
- baze podatkov
- nabor podatkov
- ponudba
- Odločanje
- odločitve
- zahteve
- drift
- oblikovanje
- želeno
- Podrobnosti
- Odkrivanje
- razvili
- se razlikujejo
- Razlika
- drugačen
- digitalno
- Dimenzije
- dimenzije
- neposredna
- smer
- Smeri
- odkrivanje
- diskretnost
- razpravlja
- razpravljali
- prikazano
- razdalja
- do
- Dokumenti
- ne
- don
- DOT
- dinamično
- dinamično
- e
- vsak
- enostavnost
- lažje
- učinkovito
- učinkovitosti
- učinkovite
- bodisi
- elementi
- vdelava
- omogočajo
- konec
- Inženiring
- Inženirji
- Motorji
- Angleščina
- zagotavlja
- okolje
- Bistvo
- bistvena
- Eter (ETH)
- Tudi
- razvija
- izvršiti
- Vaja
- Raziskovati
- ekstrakt
- olajšati
- Poznavanje
- daleč
- Feature
- Lastnosti
- Fed
- Slika
- file
- datoteke
- Najdi
- prva
- stanovanje
- po
- za
- ospredju
- obrazec
- format
- brezplačno
- iz
- Prihodnost
- vrzel
- ustvarjajo
- generacija
- generativno
- Generativna AI
- žanr
- GitHub
- Daj
- dana
- skupina
- Skupine
- ročaj
- se zgodi
- Imajo
- pomoč
- Pomaga
- tukaj
- visoka
- na visoki ravni
- zelo
- zgodovinski
- Kako
- Vendar
- HTTPS
- velika
- Stotine
- i
- ID
- identificirati
- if
- slike
- vpliv
- Izvajanje
- uvoz
- izboljšanje
- in
- vedno
- Indeks
- indeksirane
- indekse
- označuje
- indeksi
- industrij
- Industrija
- Vplivno
- Podatki
- inherentno
- inovativne
- vhod
- vhodi
- Vložki
- v notranjosti
- vpogledi
- primer
- Namesto
- Intelligence
- interakcijo
- interakcije
- interakcije
- v
- zapletenosti
- vključuje
- IT
- ITS
- Delovna mesta
- pridružite
- Pridruži se nam
- Potovanje
- samo
- Ključne
- tipke
- ključne besede
- otroci
- Vedite
- label
- Država
- Pokrajina
- velika
- vodi
- Interesenti
- učenje
- Vzvod
- Leverages
- kot
- Seznam
- nakladač
- Logika
- prijava
- stroj
- strojno učenje
- velika
- Znamka
- IZDELA
- Izdelava
- upravljanje
- Način
- ročno
- Proizvajalec
- map
- ogromen
- tekme
- matematični
- smiselna
- merjenje
- ukrepe
- merjenje
- Mehanizem
- mediji
- Spoji
- Metodologija
- Metode
- Microsoft
- minimalna
- Model
- modeli
- več
- Poleg tega
- Najbolj
- veliko
- več
- morajo
- Ime
- Narava
- Nimate
- Novo
- zdaj
- številne
- predmet
- predmeti
- of
- ponudba
- on
- ONE
- tiste
- na spletu
- samo
- odprite
- OpenAI
- operacije
- Nasprotno
- or
- organizacija
- Organizirano
- organizira
- izvirno
- OS
- Ostalo
- naši
- v lasti
- Stran
- par
- del
- opravil
- Podaje
- vzorci
- popolna
- opravlja
- performance
- opravljeno
- opravlja
- perspektiva
- perspektive
- slika
- ključno
- Plain
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igra
- prosim
- Točka
- točke
- mogoče
- potencial
- moč
- močan
- Praktično
- Praktični Aplikacije
- natančna
- Ravno
- nastavitve
- prejšnja
- problem
- Postopek
- Izdelek
- Izdelki
- Projekt
- ugledni
- pozove
- pravilno
- Lastnosti
- nepremičnine
- zagotavljajo
- zagotavljanje
- zagotavljanje
- objavljeno
- puder
- Namen
- namene
- Količina
- poizvedbe
- vprašanje
- Hitri
- hitreje
- hitro
- hitro
- Priporočilo
- Priporočila
- o
- okolica
- Odnosi
- Razmerja
- pomembno
- zastopanje
- zastopan
- predstavlja
- obvezna
- Zahteve
- Odgovor
- odgovorov
- povzroči
- Rezultati
- Razkrito
- vloga
- ROW
- s
- Enako
- Znanost
- Obseg
- Iskalnik
- Iskalniki
- iskanja
- iskanje
- sentiment
- seo
- nastavitve
- Oblikujte
- oblikovanje
- deli
- Rok
- Kratke Hlače
- pokazale
- Razstave
- strani
- Podoben
- podobnosti
- Enostavno
- saj
- sam
- Velikosti
- So
- Rešitev
- rešitve
- nekaj
- vir
- Vesolje
- specifična
- hitrost
- po delih
- madeži
- SQL
- Država
- Izjava
- Izjave
- Koraki
- Še vedno
- shranjevanje
- trgovina
- shranjeni
- trgovine
- Struktura
- strukturirano
- študija
- Kasneje
- uspešno
- sinergija
- sistem
- sistemi
- T
- miza
- TAG
- Naloge
- tehnike
- tehnološki
- Pogoji
- besedilo
- tvorjenje besedila
- kot
- da
- O
- Prihodnost
- njihove
- Njih
- te
- jih
- ta
- 3
- skozi
- čas
- krat
- do
- tradicionalna
- Vlak
- Transform
- Preoblikovanje
- transformativno
- preoblikovati
- poskusite
- dva
- Vrste
- Konec koncev
- razumeli
- razumevanje
- nedvomno
- odklepanje
- odklepanje
- Nadgradnja
- nadgradnja
- us
- Uporaba
- uporaba
- Rabljeni
- uporabnik
- uporablja
- uporabo
- običajno
- Vrednote
- raznolikost
- različnih
- zelo
- ključnega pomena
- vs
- je
- we
- webp
- dobro opredeljen
- so bili
- Kaj
- Kaj je
- ali
- ki
- medtem
- bo
- z
- v
- besede
- delo
- deluje
- bi
- jo
- Vaša rutina za
- zefirnet