Medtem ko OpenAI ChatGPT posrka ves kisik iz 24-urnega cikla novic, je Google tiho razkril nov model umetne inteligence, ki lahko generira videoposnetke, ko so mu vneseni video, slike in besedilo. Novi urejevalnik videoposnetkov Google Dreamix AI zdaj ustvarjeni videoposnetek približa resničnosti.
Glede na raziskavo, objavljeno na GitHubu, Dreamix ureja video na podlagi videoposnetka in besedilnega poziva. Nastali videoposnetek ohranja zvestobo barvi, drži, velikosti predmeta in položaju kamere, kar ima za posledico časovno dosleden videoposnetek. Dreamix trenutno ne more ustvariti videoposnetkov samo iz poziva, lahko pa vzame obstoječe gradivo in spremeni video z uporabo besedilnih pozivov.
Google uporablja modele video difuzije za Dreamix, pristop, ki je bil uspešno uporabljen za večino urejanja video slik, ki ga vidimo v slikovnih umetnih inteligencah, kot sta DALL-E2 ali odprtokodni Stable Diffusion.
Pristop vključuje močno zmanjšanje vhodnega videoposnetka, dodajanje umetnega šuma in njegovo nato obdelavo v modelu video difuzije, ki nato uporabi besedilni poziv za ustvarjanje novega videoposnetka iz njega, ki obdrži nekatere lastnosti prvotnega videa in ponovno upodobi druge glede na na vnos besedila.
Model video difuzije ponuja obetavno prihodnost, ki lahko uvede novo dobo za delo z videoposnetki.

Na primer, v spodnjem videoposnetku Dreamix spremeni opico jedo (levo) v plešočega medveda (desno) glede na poziv »Medved pleše in skače ob živahni glasbi ter premika celotno telo.«
V drugem spodnjem primeru Dreamix uporabi eno samo fotografijo kot predlogo (kot pri pretvorbi slike v videoposnetek), predmet pa je nato animiran iz nje v videu prek poziva. Možni so tudi premiki kamere v novem prizoru ali kasnejšem posnetku s časovnim zamikom.
V drugem primeru Dreamix spremeni orangutana v vodnem bazenu (levo) v orangutana z oranžnimi lasmi, ki se kopa v čudoviti kopalnici.
»Medtem ko so bili difuzijski modeli uspešno uporabljeni za urejanje slik, je zelo malo del to storilo za urejanje videa. Predstavljamo prvo metodo, ki temelji na difuziji in je sposobna izvajati besedilno montažo gibanja in videza splošnih videoposnetkov.”
Glede na Googlov raziskovalni članek Dreamix uporablja model video difuzije, da v času sklepanja združi prostorsko-časovne informacije nizke ločljivosti iz izvirnega videoposnetka z novimi informacijami visoke ločljivosti, ki jih je sintetiziral za uskladitev z vodilnim besedilnim pozivom.«
Google je dejal, da je ta pristop izbral, ker "pridobivanje visoke ločljivosti izvirnega videoposnetka zahteva ohranitev nekaterih njegovih visokoločljivostnih informacij, dodamo predhodno fazo natančnega prilagajanja modela na izvirnem videu, kar znatno poveča zvestobo."
Spodaj je video pregled delovanja Dreamixa.
[Vgrajeni vsebina]
Kako delujejo modeli Dreamix Video Diffusion
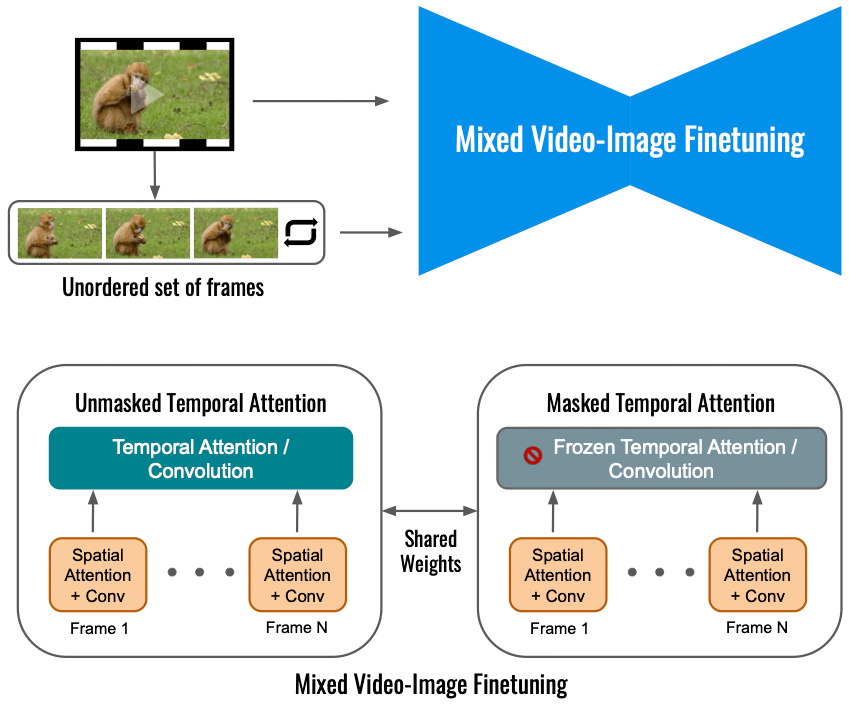
Po mnenju Googla natančno prilagajanje modela video difuzije za Dreamix samo na vhodnem videu omejuje obseg spremembe gibanja. Namesto tega uporabljamo mešani cilj, ki poleg prvotnega cilja (spodaj levo) tudi natančno prilagaja neurejen niz okvirjev. To se naredi z uporabo »zamaskirane časovne pozornosti«, ki preprečuje, da bi se časovna pozornost in konvolucija natančno nastavila (spodaj desno). To omogoča dodajanje gibanja statičnemu videu.
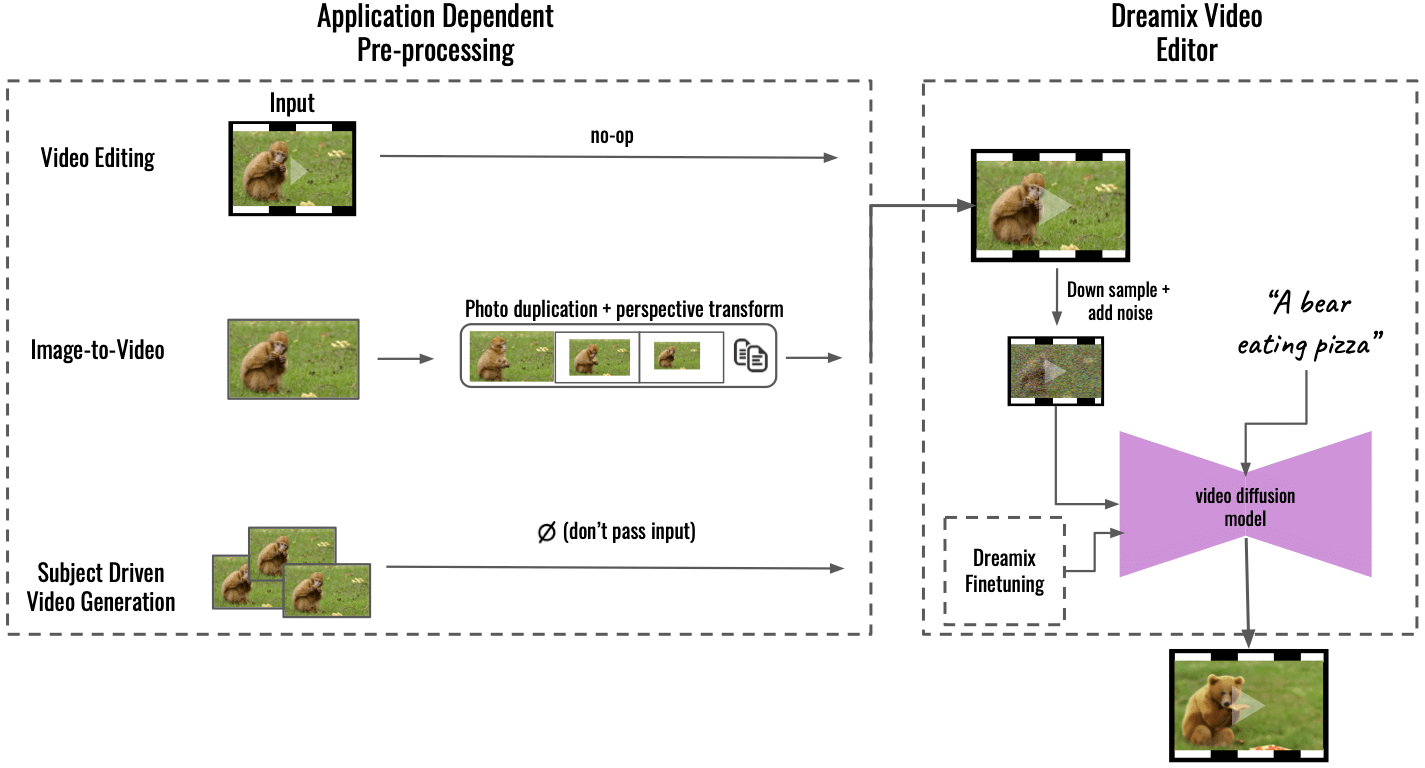
»Naša metoda podpira več aplikacij s predhodno obdelavo, odvisno od aplikacije (levo), ki pretvarja vhodno vsebino v enoten video format. Za sliko v video se vhodna slika podvoji in preoblikuje z uporabo perspektivnih transformacij, pri čemer se sintetizira grob video z nekaj gibanja kamere. Pri ustvarjanju videa, ki temelji na temi, je vnos izpuščen – za zvestobo poskrbi samo fina nastavitev. Ta grobi videoposnetek nato uredimo z našim splošnim »urejevalnikom videoposnetkov Dreamix« (desno): najprej pokvarimo videoposnetek z znižanjem vzorčenja, ki mu sledi dodajanje šuma. Nato uporabimo natančno nastavljen model video difuzije, voden z besedilom, ki nadgradi video na končno prostorsko-časovno ločljivost,« je zapisal Dream na GitHub.
Spodaj si lahko preberete raziskovalno nalogo.
Google Dreamix- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- Sposobna
- Po
- AI
- ai video
- Z AI napajanjem
- vsi
- omogoča
- sam
- in
- Še ena
- aplikacije
- uporabna
- Uporabi
- pristop
- umetni
- pozornosti
- temeljijo
- Nosijo
- lepa
- ker
- počutje
- spodaj
- telo
- povečanje
- Bottom
- Prinaša
- kamera
- ne more
- ki
- spremenite
- ChatGPT
- bližje
- barva
- združujejo
- dosledno
- vsebina
- Ustvarjanje
- cikel
- ples
- Difuzija
- sanje
- urednik
- vgrajeni
- Era
- Primer
- obstoječih
- Nekaj
- zvestoba
- končna
- prva
- sledili
- format
- iz
- Prihodnost
- splošno
- ustvarjajo
- ustvarila
- generacija
- gif
- GitHub
- dana
- Hair
- močno
- visoka ločljivost
- Kako
- Vendar
- HTTPS
- slika
- slike
- in
- Podatki
- vhod
- Namesto
- IT
- izstrelki
- Meje
- vzdržuje
- Material
- max
- Metoda
- mešano
- Model
- modeli
- spremenite
- Trenutek
- Najbolj
- motion
- gibanja
- premikanje
- več
- Glasba
- Novo
- novice
- hrup
- predmet
- Cilj
- Ponudbe
- open source
- OpenAI
- Oranžna
- izvirno
- drugi
- pregled
- Kisik
- Papir
- opravlja
- perspektiva
- platon
- Platonova podatkovna inteligenca
- PlatoData
- bazen
- mogoče
- predstaviti
- preprečevanje
- obravnavati
- obetaven
- Lastnosti
- objavljeno
- tiho
- Preberi
- Reality
- Snemanje
- zmanjšanje
- zahteva
- Raziskave
- Resolucija
- rezultat
- ohranitev
- Je dejal
- Prizor
- nastavite
- bistveno
- sam
- Velikosti
- So
- nekaj
- stabilna
- Stage
- kasneje
- Uspešno
- taka
- Podpira
- Bodite
- Predloga
- O
- čas
- do
- transformacije
- preoblikovati
- predstavil
- uporaba
- preko
- Video
- Video posnetki
- Voda
- ki
- deluje
- deluje
- youtube
- zefirnet











