
Slike, ki jih rawpixel.com on Freepik
Ne glede na to, s katerim poslom se ukvarjate, je v dobi, ki temelji na podatkih, pomembnejše kot kdaj koli prej vedeti, kako analizirati podatke. Analiza podatkov bi podjetjem omogočila, da ostanejo konkurenčna, in omogočila sprejemanje boljših odločitev.
Pomen analize podatkov žene vsakega posameznika, da zna izvesti analizo podatkov. Vendar včasih analiza podatkov vzame preveč časa. Zato se lahko zanesemo na ChatGPT, da bo iz naše podatkovne datoteke ustvaril popolno poročilo.
Ta članek bo raziskal pet preprostih korakov za ustvarjanje popolnih analitičnih poročil iz vaše datoteke CSV. Teh pet korakov vključuje:
1. korak: uvoz datoteke CSV
2. korak: Povzetek podatkov in predhodna obdelava
3. korak: Analiza podatkov
4. korak: Vizualizacija podatkov
5. korak: Ustvarjanje poročila
Kot predpogoj ta članek predvideva, da je bralec naročen na ChatGPT Plus. S tem v mislih, začnimo.
Prvi korak je priprava datoteke CSV, ki jo želite analizirati, in ustvarjanje poročila. Ta datoteka bi lahko izvirala iz katerega koli zaupanja vrednega vira, vendar bi ta članek uporabil nabor podatkov Telecom Churn iz Kaggle.
Zagotovite, da so podatki strukturirani, organizirani in imajo jasno glavo. Če imate določeno tarčo, ki jo želite analizirati, potem ne pozabite vključiti teh podatkov v datoteko. V našem primeru bi poskušali izvesti analizo za stolpec odliva.
Ko so podatki pripravljeni, jih pritrdite na ChatGPT in pustite, da model opravi svoje delo.
Naslednji korak je pridobivanje povzetka podatkov iz naše datoteke CSV in njihova predhodna obdelava. Med nalaganjem podatkov vnesite naslednji poziv.
Provide the data summary to this file and perform appropriate data processing for the dataset.Zgornji poziv zagotavlja naslednje rezultate:
Tukaj je povzetek vašega nabora podatkov:
Število vrstic: 3333
Število stolpcev: 11
Imena stolpcev:
Churn
AccountWeeks
Obnova pogodbe
DataPlan
DataUsage
CustServCalls
DayMins
DayCalls
MonthlyCharge
OverageFee
RoamMins
Vrste podatkov:
Celo število: Churn, AccountWeeks, ContractRenewal, DataPlan, CustServCalls, DayCalls
Float: Poraba podatkov, DayMins, MonthlyCharge, OverageFee, RoamMins
Manjkajoče vrednosti: V nobenem od stolpcev ni manjkajočih vrednosti.
ChatGPT je jasno lahko dobro prebral podatke in lahko zagotovil dani nabor podatkov. Naslednji rezultat je predhodna obdelava podatkov iz ChatGPT.
Ker v naboru podatkov ni manjkajočih vrednosti, bo glavni poudarek čiščenja in predhodne obdelave podatkov na:
- Preverjanje morebitnih odstopanj ali nepravilnosti v podatkih.
- Po potrebi normalizirajte ali standardizirajte podatke, zlasti za stolpce z neprekinjenimi številčnimi vrednostmi.
- Po potrebi pretvorba kategoričnih podatkov v obliko, primerno za analizo.
Nadaljujmo s temi koraki.
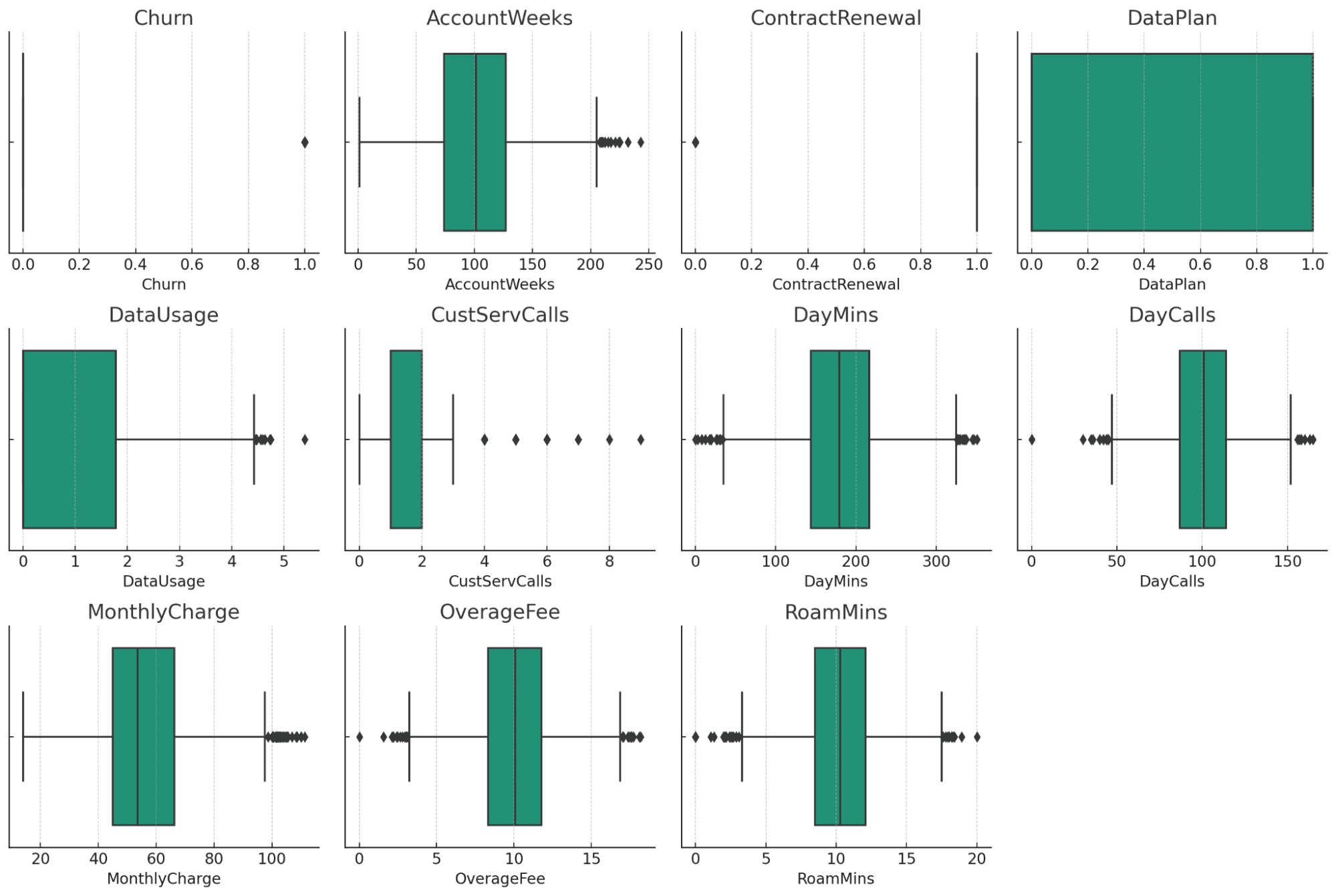
Škatla nudijo vizualni pregled možnih izstopajočih vrednosti v vsakem številskem stolpcu vašega nabora podatkov. Tukaj je nekaj opažanj:
- AccountWeeks, CustServCalls, DayCalls: ti stolpci prikazujejo dokaj normalno porazdelitev z nekaj odstopanji.
- DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins: ti stolpci prikazujejo tudi nekaj odstopanj, vendar se zdi, da so v razumnem obsegu glede na naravo podatkov.
- Odliv, ContractRenewal, DataPlan: ker so kategorični/binarni podatki, ti stolpci ne prikazujejo tradicionalnih odstopanj.
Glede na te informacije lahko naslednji koraki pri čiščenju in predobdelavi podatkov vključujejo:
- Ravnanje z izstopajočimi vrednostmi: Odločimo se lahko, ali bomo odstranili, omejili ali kako drugače obravnavali izstopajoče vrednosti glede na vaše posebne analitične potrebe in poznavanje področja.
- Preoblikovanje podatkov: Po potrebi lahko normaliziramo ali standardiziramo stolpce, kot so DayMins, MonthlyCharge itd., še posebej, če nameravate uporabiti algoritme, ki so občutljivi na obseg podatkov.
- Kodiranje kategoričnih podatkov: Pretvorite kategorične podatke v obliko, primerno za analizo, če je potrebna takšna transformacija.
ChatGPT lahko dovolite, da izvede dodatne korake za čiščenje in predhodno obdelavo podatkov, ali pa pustite, da ostane tako, kot je. Za ta primer bi nadaljevali z naslednjimi koraki.
Nato bi izvedli analizo podatkov s ChatGPT. Analiza podatkov je odvisna od tega, kaj želite doseči. V našem primeru želimo izvesti analizo podatkov iz Churn POV.
Za izvedbo analize podatkov s ChatGPT za zgornji primer uporabimo naslednji poziv.
Please perform the data analysis based on the data above with respect to the churn data.
Analiza podatkov je razvidna iz naslednjega rezultata.
Za izvedbo analize podatkov v zvezi s podatki o odlivu se bomo osredotočili na razumevanje, kako so različni dejavniki povezani z odlivom strank. Odliv, ki je binarna spremenljivka (0 za brez odliva, 1 za odliv), se običajno analizira s klasifikacijskimi metodami in s preučevanjem odnosov z drugimi spremenljivkami. Tukaj je načrt:
- Analiza korelacije: Za začetek si bomo ogledali, kako je vsaka numerična značilnost povezana z odlivom. To nam daje začetno razumevanje, kateri dejavniki bi lahko bili tesneje povezani z odlivom.
- Statistični testi: Za kategorične spremenljivke, kot sta ContractRenewal in DataPlan, lahko uporabimo statistične teste, da ugotovimo, ali obstajajo znatne razlike v stopnjah opuščanja v različnih kategorijah.
- Vizualna analiza: Ustvarili bomo nekaj vizualizacij za nadaljnje raziskovanje teh odnosov. To vključuje primerjavo stopenj osipa med različnimi skupinami in prikaz ključnih spremenljivk glede na osip.
- Povzetek statističnih podatkov: Zagotovili bomo povzetek statističnih podatkov za različne skupine na podlagi statusa odpuščanja, da vidimo, ali obstajajo opazne razlike v sredstvih ali porazdelitvah.
Začnimo s korelacijsko analizo in nato preidimo na naslednje korake.
Korelacijska analiza z odlivom
Korelacija različnih spremenljivk z odlivom je naslednja (od najmočnejše negativne do najmočnejše pozitivne korelacije):
Negativna korelacija:
- Contract Renewal: Najmočnejša negativna korelacija. Kaže, da bodo stranke, ki ne podaljšajo pogodbe, bolj verjetno odpadle.
- Podatkovni načrt: Za stranke brez podatkovnega načrta obstaja nekoliko večja verjetnost, da bodo odpadle.
- Uporaba podatkov: večja poraba podatkov nekoliko zmanjša verjetnost odliva.
Pozitivna korelacija:
- AccountWeeks, DayCalls: zelo šibka pozitivna korelacija, kar kaže na minimalen vpliv na odliv.
- RoamMins: Rahlo povečanje verjetnosti odliva s povečanimi minutami gostovanja.
- MonthlyCharge: nekoliko višje stopnje odliva s povečanimi mesečnimi stroški.
- OverageFee: višje provizije za presežek so zmerno povezane s povečanim odlivom.
- Dnevne minute: višje dnevne minute so zmerno povezane s povečanim odlivom.
- CustServCalls: Močna pozitivna korelacija. Več klicev v službo za stranke je povezano z višjimi stopnjami odliva.
Glede na te korelacije se zdi, da so dejavniki, kot so obnovitev pogodbe, klici v službo za stranke, dnevne minute in stroški presežka, tesneje povezani z odlivom. Te dejavnike lahko dodatno raziščemo z vizualno analizo in statističnimi testi, zlasti za kategorične spremenljivke, kot sta ContractRenewal in DataPlan.
Vizualna analiza
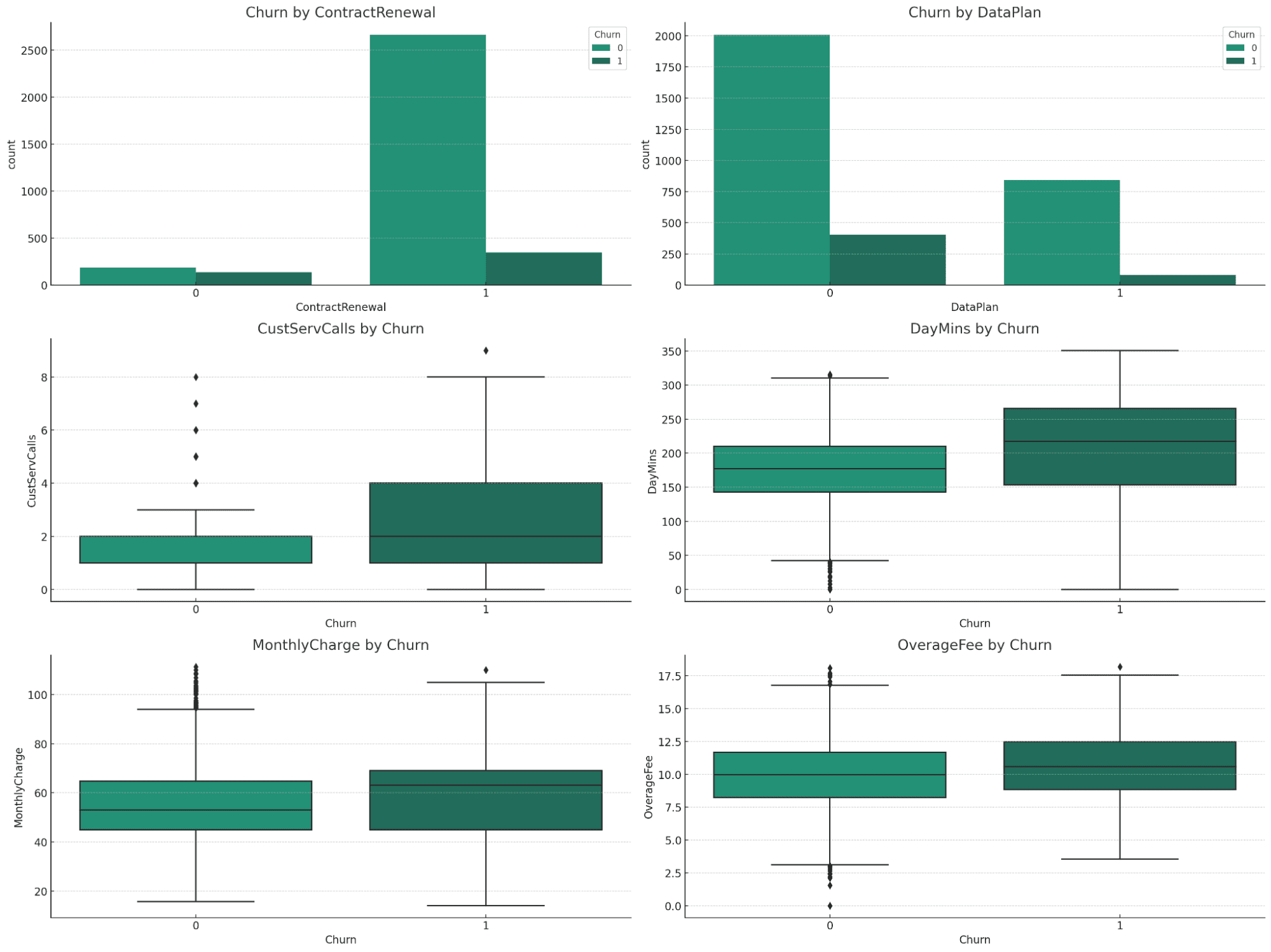
Vizualizacije ponujajo dragocene vpoglede v razmerje med različnimi spremenljivkami in odlivom:
Odliv s ContractRenewal in DataPlan:
- Obnova pogodbe: očitna je pomembna razlika v stopnjah odliva. Stranke, ki niso podaljšale pogodbe, kažejo višjo stopnjo odliva.
- Podatkovni načrt: Obstaja opazna razlika v stopnjah odliva glede na to, ali imajo stranke podatkovni načrt ali ne, pri tistih brez podatkovnega načrta pa je odliv večji.
Številske spremenljivke (CustServCalls, DayMins, MonthlyCharge, OverageFee) s strani Churn:
- CustServCalls: Stranke z večjim številom klicev v službo za pomoč strankam običajno odpadejo več.
- Dnevne minute: višje dnevne minute so povezane z večjo verjetnostjo odliva.
- MonthlyCharge: višji mesečni stroški so povezani s povečano stopnjo osipa.
- OverageFee: višje provizije za presežek so povezane tudi s povečanim odlivom.
Sklepi iz analize
- Stanje podaljšanja pogodbe in prisotnost podatkovnega načrta sta pomembna dejavnika pri odlivu strank.
- Visoka poraba (v smislu dnevnih minut) in visoki stroški (mesečni stroški in nadomestila za presežek) so povezani z višjimi stopnjami odliva.
- Večje število klicev službe za stranke je močan pokazatelj potencialnega odliva.
Naslednji koraki
Na podlagi teh vpogledov je mogoče razviti ciljne strategije za zmanjšanje odliva, kot je izboljšanje storitev za stranke, revizija cenovnih strategij ali ponudba spodbud za obnovo pogodbe in naročnine na paket podatkov.
Z enim samim pozivom lahko vidimo, kako dobro nam lahko ChatGPT zagotovi popolno analizo podatkov in pride do vpogleda iz podatkov. Cilje analize lahko prilagodite in začnete od tam.
Vizualizacija podatkov je podporna dejavnost za izboljšanje analize podatkov in splošnega poročila. Z vizualizacijo lahko imamo bolj celovito poročilo za razumevanje naših podatkov.
Z naslednjim pozivom lahko izvedemo vizualizacijo podatkov s ChatGPT.
Please perform data visualization from the data analysis to explain the data better.Za izboljšanje razumevanja rezultatov analize podatkov bom ustvaril niz vizualizacij, ki jasno prikazujejo ključne ugotovitve v zvezi z odlivom strank. Te vizualizacije bodo vključevale:
- Palični grafikoni za kategorične spremenljivke:
- Primerjava stopenj opuščanja za stranke z in brez podaljšanja pogodbe.
- Primerjava stopenj opuščanja za stranke s podatkovnim paketom in brez njega.
- Škatla za ključne številske spremenljivke:
- Klici v službo za stranke v primerjavi z odsekom.
- Dnevne minute proti odlivu.
- Mesečni stroški v primerjavi z odpadom.
- Presežne provizije v primerjavi z odlivom.
- Toplotni zemljevid korelacije:
Za vizualizacijo korelacije vseh spremenljivk z odlivom.
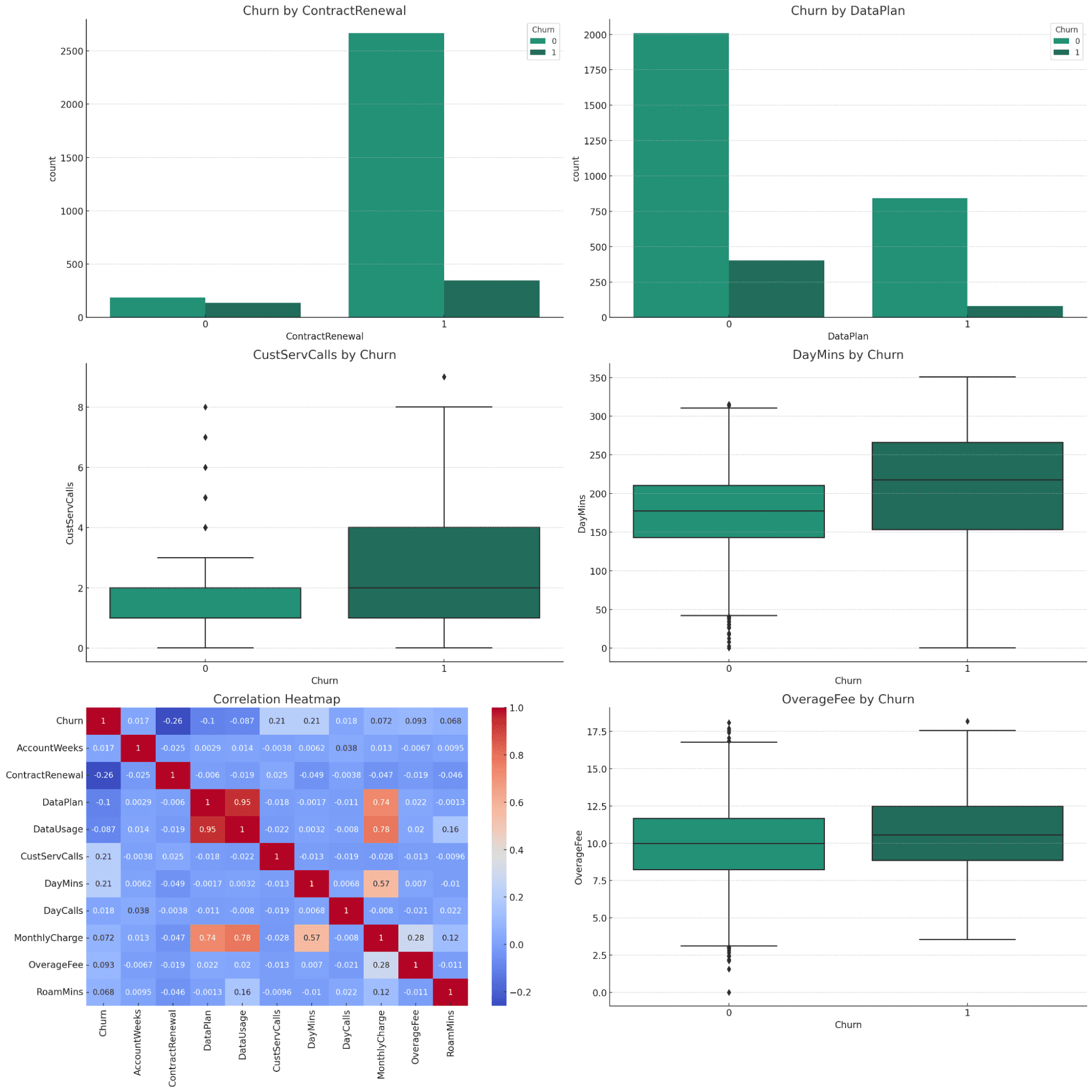
Vizualizacija bi prikazala vse pomembne ploskve, ki zajemajo celoten nabor podatkov. Za vsako parcelo lahko zahtevamo podrobnejše opise, ki jih lahko preizkusite samostojno.
Zadnji korak je ustvarjanje poročila na podlagi prejšnjih korakov. Na žalost ChatGPT morda ne bo zajel vseh opisov in vpogledov iz analize podatkov, vendar lahko še vedno imamo preprosto različico poročila.
Uporabite naslednji poziv za ustvarjanje poročila PDF na podlagi prejšnje analize.
Please provide me with the pdf report from the first step to the last step.Prejeli boste rezultat povezave PDF z vašo prejšnjo analizo. Poskusite ponoviti korake, če menite, da je rezultat nezadosten ali če želite nekaj spremeniti.
Analiza podatkov je dejavnost, ki bi jo moral poznati vsak, saj je to ena najbolj zahtevanih veščin v sedanji dobi. Vendar bi lahko učenje o izvajanju analize podatkov trajalo dolgo. S ChatGPT lahko zmanjšamo ves ta čas dejavnosti.
V tem članku smo razpravljali o tem, kako ustvariti celotno analitično poročilo iz datotek CSV v 5 korakih. ChatGPT uporabnikom omogoča analizo podatkov od konca do konca, od uvoza datoteke do izdelave poročila.
Cornellius Yudha Wijaya je vodja podatkovne znanosti in pisec podatkov. Medtem ko dela s polnim delovnim časom pri Allianz Indonesia, rad deli nasvete o Pythonu in podatkih prek družbenih medijev in pisnih medijev.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps?utm_source=rss&utm_medium=rss&utm_campaign=from-csv-to-complete-analytical-report-with-chatgpt-in-5-simple-steps
- :ima
- : je
- :ne
- $GOR
- 1
- 7
- a
- sposobnost
- Sposobna
- O meni
- nad
- Doseči
- čez
- dejavnost
- Dodatne
- proti
- Cilje
- algoritmi
- vsi
- Allianz
- Prav tako
- an
- Analiza
- Analitično
- analizirati
- analizirati
- in
- kaj
- primerno
- SE
- članek
- AS
- vprašati
- Pomočnik
- povezan
- predpostavlja
- At
- pripisujejo
- bar
- temeljijo
- BE
- počutje
- Boljše
- med
- Pasovi
- poslovni
- podjetja
- vendar
- by
- poziva
- CAN
- cap
- zajemanje
- primeru
- kategorije
- nekatere
- spremenite
- Stroški
- ChatGPT
- preverjanje
- Razvrstitev
- čiščenje
- jasno
- jasno
- tesno
- Stolpec
- Stolpci
- kako
- primerjavo
- konkurenčno
- dokončanje
- celovito
- Ravnanje
- upoštevamo
- naprej
- neprekinjeno
- Naročilo
- pogodbe
- pretvorbo
- pretvorbo
- korelacija
- Korelacija
- korelacije
- bi
- zajeti
- ustvarjajo
- Trenutna
- stranka
- Za stranke
- Stranke, ki so
- vsak dan
- datum
- Analiza podatkov
- obdelava podatkov
- znanost o podatkih
- vizualizacija podatkov
- Podatkov usmerjenih
- dan
- odloča
- odločitve
- zmanjšuje
- Odvisno
- opis
- podrobno
- razvili
- DID
- Razlika
- razlike
- drugačen
- razpravljali
- distribucija
- Distribucije
- do
- domena
- don
- dont
- diski
- vsak
- omogočajo
- kodiranje
- konec koncev
- okrepi
- Era
- zlasti
- itd
- VEDNO
- Tudi vsak
- vsi
- očitno
- Preučevanje
- Primer
- izvršiti
- Pojasnite
- raziskuje
- dejavniki
- pošteno
- Feature
- občutek
- pristojbine
- Nekaj
- file
- datoteke
- Ugotovitve
- prva
- pet
- Osredotočite
- po
- sledi
- za
- format
- iz
- nadalje
- ustvarjajo
- dobili
- Daj
- dana
- daje
- več
- Skupine
- ročaj
- Ravnanje
- Imajo
- ob
- he
- tukaj
- visoka
- več
- Kako
- Kako
- Vendar
- HTTPS
- i
- if
- vpliv
- Pomembnost
- Pomembno
- uvoz
- izboljšanje
- izboljšanju
- in
- spodbude
- vključujejo
- vključuje
- Povečajte
- povečal
- neodvisno
- označuje
- Kazalec
- individualna
- Indonezija
- Podatki
- začetna
- vhod
- vpogled
- vpogledi
- v
- IT
- jpg
- KDnuggets
- Ključne
- Vedite
- Vedeti
- znanje
- Zadnja
- učenje
- Naj
- kot
- verjetnost
- Verjeten
- LINK
- ll
- Long
- dolgo časa
- Poglej
- ljubi
- Glavne
- Znamka
- upravitelj
- Matter
- me
- pomeni
- mediji
- Metode
- morda
- moti
- minimalna
- zmanjšajo
- min
- manjka
- Model
- mesečno
- več
- Najbolj
- premikanje
- veliko
- Imena
- Narava
- potrebno
- potrebna
- potrebe
- negativna
- Naslednja
- št
- normalno
- Številka
- številke
- opažanja
- of
- ponudba
- ponujanje
- on
- ONE
- or
- Organizirano
- Ostalo
- drugače
- naši
- Splošni
- pregled
- opravlja
- izvajati
- Načrt
- platon
- Platonova podatkovna inteligenca
- PlatoData
- plus
- pozitiven
- potencial
- Pripravimo
- Prisotnost
- prejšnja
- cenitev
- nadaljujte
- obravnavati
- proizvodnjo
- zagotavljajo
- zagotavlja
- Python
- območje
- Oceniti
- Cene
- Preberi
- Bralec
- pripravljen
- razumno
- zmanjša
- povezane
- Razmerje
- Razmerja
- zanašajo
- odstrani
- poročilo
- Poročila
- obvezna
- spoštovanje
- povzroči
- Rezultati
- s
- Lestvica
- Znanost
- glej
- zdi se
- Zdi se,
- videl
- občutljiva
- Serija
- Storitev
- Delite s prijatelji, znanci, družino in partnerji :-)
- shouldnt
- Prikaži
- Prikaz
- pomemben
- Enostavno
- sam
- spretnosti
- socialna
- družbeni mediji
- nekaj
- Včasih
- vir
- specifična
- standardiziranje
- Začetek
- začel
- Statistično
- Statistika
- Status
- bivanje
- Korak
- Koraki
- Še vedno
- strategije
- močna
- najmočnejši
- strukturirano
- naročnine
- taka
- primerna
- POVZETEK
- podporni
- T
- Bodite
- meni
- ciljna
- ciljno
- telecom
- Pogoji
- testi
- kot
- da
- O
- njihove
- Njih
- POTEM
- Tukaj.
- te
- jih
- stvari
- ta
- tisti,
- skozi
- čas
- nasveti
- do
- tudi
- tradicionalna
- Preoblikovanje
- zaupanja
- poskusite
- poteg
- tipično
- razumeli
- razumevanje
- na žalost
- us
- Uporaba
- uporaba
- Uporabniki
- dragocene
- Vrednote
- spremenljivka
- različica
- zelo
- preko
- vizualna
- vizualizacija
- vizualizirati
- vs
- želeli
- je
- we
- Dobro
- Kaj
- ali
- ki
- medtem
- WHO
- celoti
- zakaj
- bo
- z
- v
- brez
- delo
- deluje
- bi
- Pisatelj
- pisanje
- jo
- Vaša rutina za
- zefirnet







