Za SQL ali zakaj sem preveč zaščiten do svojih podatkovnih oseb
Desetletja je bil SQL temelj za interakcijo ljudi s podatki. Zdi se, da alternativni pristopi nenehno poskušajo nadomestiti ta močan jezik. Čeprav je še veliko napredka pri tehnikah in orodjih za urejanje in upravljanje podatkov, bodo usposobljeni obrtniki, ki delajo s podatki – skozi lečo SQL – verjetno prisotni še desetletja.
By Pedram Navid, vodja podatkov pri Hightouch.

Zdi se, da je SQL spet mrtev. Nekateri se spomnimo, ko je NoSQL obljubil, da nas bo odvezal od bremen SQL. Videli smo, da se MongoDB, Redis, DynamoDB in drugi pojavljajo kot ubijalci SQL. Ljudje so se zgrinjali k tem rešitvam, a so kmalu ugotovili, da jih morda res zanimajo stvari, kot so doslednost, transakcije ACID in ne izguba vseh vaših podatkov. Morda SQL takrat ni umrl, a vedno bodo drugi, ki ga bodo poskušali ubiti. Zdi se, da je to eden tistih časov.
Tako gre Manifest Jamieja Brandona proti SQL. Trdi, da je SQL slab in da je tako slab, da vpliva na celotno industrijo. Težave SQL se skrčijo v njegovo neizraznost, nestisljivost in neporoznost. Moj cilj ni ovreči njegovih trditev, a če vas skrbi SQL, da nima tipov Union in da sta pandas in Flink modela, h katerima bi si morali prizadevati in ne bežati od njih, potem imava z Jamiejem vsaj zelo različne poglede na svet, v katerem deluje SQL.
Ne dvomim, da obstaja svet, kjer:
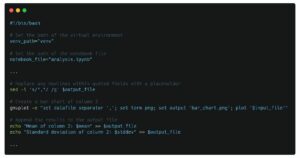
churn[['State','Score']].groupby('State').mean().sort_values(by='Score', ascending=False)
je bolj uporaben kot:
SELECT stanje, AVG(rezultat) FROM churn GROUP BY vrstni red stanja po rezultatu;
Vendar obstaja veliko svetov, kjer je slednje več kot le v redu. Večina Jamiejevih argumentov je proti delom jezika, s katerimi skoraj nihče ne komunicira, ostalo pa že ima nekaj precej odličnih rešitev. Nikoli mi ni bilo mar, da ne morem napisati:
izberite x2 iz skupine foo z x+1 kot x2;
In medtem ko navaja nekaj tehtnih primerov, ko gre za sestavljivost, so orodja, kot je dbt, pomagala premostiti to vrzel in prinesla moč predlog jinja v SQL, hkrati pa omogočila vedno priljubljene DAG-je, ki poganjajo vsako skladišče, vredno svoje teže.
Ko vidim te argumente proti SQL in se pojavljajo vedno znova, so skoraj vedno od programskih inženirjev in izključno leče programskega inženiringa. Moje skrbi glede takšnih člankov niso, da bo jasno, da bo SQL umrl. SQL bo živel še dolgo potem, ko me ne bo več. Resnično se bojim, da ljudi odvrača od učenja SQL in da se zaradi tega tisti, katerih primarni jezik je SQL, počutijo nezadostne.
V programskem inženiringu okoli podatkov na splošno obstaja vztrajna neizrečena avra. Skoraj razredna ločnica med "programskim inženiringom" in "podatkovnimi ljudmi". Podatkovni inženirji, podatkovni analitiki, podatkovni znanstveniki, analitični inženirji: Prepogosto sem videl drugačnost in drugorazrednost teh vlog. Dejstvo je še toliko bolj zaskrbljujoče, če upoštevate, da so ljudje, ki se ukvarjajo s podatki, bolj raznoliki in manj moški prevladujejo (in na splošno bolj zabavno). Prav tako čutim resno zaskrbljenost pri tistih na tem področju, ki niso izhajali iz tradicionalnih okolij programskega inženiringa, pogosto se ugibajo in podcenjujejo svoje sposobnosti in sposobnosti. Sindrom prevaranta se zdi skoraj prevladujoča lastnost vseh, s katerimi se pogovarjam.
Nič ne pomaga, če se takšni članki pojavijo in se povzpnejo na vrh na Orange Sites. Ohranja mit, da je analiza podatkov drugorazredna veščina, slabša od prave računalniške znanosti programskega inženiringa. Videl sem te inženirje programske opreme in naj vam povem, da bi imeli boljšo programsko opremo, če bi jim bilo mar za njihovo obrt vsaj toliko, kot je ljudem s podatki mar za njihove analize.
Resnica je, da so podatki težki. Ekosistem je težak. Podatki so neurejeni. Težko je preizkusiti. Nismo našli pravega orodja, pravega odpravljanja napak, pravih okolij ali celo pravega načina za poučevanje.
Zagon nečesa, kot je dbt, podatkovno skladišče in python, ni trivialno. Še vedno ni odličnega vmesnika za prenos količine podatkov v skladišče. Tudi če vam uspe zagnati Docker in Postgres lokalno, vso srečo pri ustvarjanju tabel in sejanju baze podatkov, da se začnete igrati.
Testiranje je še vedno nerešen problem. Orodja, kot je Velika pričakovanja, pomagajo, vendar zares zajemajo podatke šele naknadno. Še vedno moramo iti, ko moramo ugotoviti, kako enotno testirati manjše dele naše kode ali kako pravilno testirati integracije, ne da bi se posmehovali polovici knjižnice.
Vse to je veliko delo v teku in delo ni nič manj pomembno kot izdelava spletnega mesta, zaledne aplikacije ali infrastrukture. Samo pogledati morate v dbt #jobs-posting slack, da vidite, koliko podjetij poskuša zapolniti vloge analitikov in podatkovnih inženirjev za pomoč pri reševanju kritičnih poslovnih težav, povezanih s podatki. Raven sofisticiranosti in orodij v zadnjih nekaj letih je eksplodirala, prav tako pričakovanja strank glede personalizacije – vse poganjajo podatki.
Ljudje, ki to delo opravljajo, niso nič manj usposobljeni. In orodja in jeziki, ki jih uporabljajo, niso nič manj uporabni, ker nimajo funkcij drugih jezikov. Dober analitik je zlata vreden. So neusmiljeni v svoji natančnosti in odlični komunikatorji. Sočutni so do posla in so neskončno radovedni. Podatkovni ljudje so eni najpametnejših in najprijaznejših ljudi, kar sem jih srečal.
Torej, čeprav so tam zunaj morda ljudje Proti SQL, vedite, da nas je veliko takih, ki zelo Za SQL. In svet je zaradi tega boljši.
prvotni. Poročeno z dovoljenjem.
Povezano:
Vir: https://www.kdnuggets.com/2021/08/for-sql-data-people.html
- "
- &
- vsi
- Analiza
- Analitik
- analitika
- Anksioznost
- uporaba
- Argumenti
- okoli
- članki
- avto
- meja
- MOST
- Building
- poslovni
- ki
- primeri
- Koda
- Podjetja
- Računalništvo
- Ustvarjanje
- radovednost
- datum
- Analiza podatkov
- kakovosti podatkov
- znanost o podatkih
- podatkovno skladišče
- Baze podatkov
- mrtva
- globoko učenje
- DID
- Direktor
- Lučki delavec
- vozi
- ekosistem
- inženir
- Inženiring
- Inženirji
- Lastnosti
- konec
- zabava
- vrzel
- splošno
- Gold
- dobro
- Grafične kartice
- veliko
- skupina
- Glava
- Kako
- Kako
- HTTPS
- Ljudje
- Industrija
- Infrastruktura
- integracije
- IT
- jezik
- jeziki
- UČITE
- učenje
- Stopnja
- Knjižnica
- lokalno
- Long
- upravljanje
- ML
- MongoDB
- na spletu
- odprite
- open source
- Da
- Ostalo
- drugi
- ljudje
- moč
- Precision
- Python
- kakovost
- REST
- Run
- tek
- Znanost
- Znanstveniki
- Občutek
- Spletna mesta
- spretnosti
- Slack
- So
- Software
- inženiring programske opreme
- rešitve
- SOLVE
- SQL
- Začetek
- začel
- Država
- zgodbe
- Test
- vrh
- Transakcije
- unija
- us
- Obseg
- Skladišče
- Spletna stran
- WHO
- delo
- svet
- vredno
- X
- let