V današnjem svetu stranke upravljajo ogromne količine podatkov v svojih Preprosta storitev shranjevanja Amazon (Amazon S3) podatkovna jezera, ki zahtevajo zapletene podatkovne cevovode za nenehno razumevanje sprememb v postavitvi podatkov in njihovo dajanje na voljo sistemom potrošnikom. AWS lepilo pajki zagotavljajo preprost način za katalogiziranje podatkov v katalogu podatkov AWS Glue Data Catalog, ki odpravlja težko delo, ko gre za upravljanje shem in klasifikacijo podatkov. Pajki AWS Glue ekstrahirajo podatkovno shemo in particije iz Amazon S3, da samodejno zapolnijo podatkovni katalog, pri čemer ohranjajo metapodatke posodobljene.
Ker pa podatki sčasoma eksponentno rastejo, lahko število particij v dani tabeli znatno naraste. Ker storitve analitike kot Amazonska Atena če poizvedujete po tabeli, ki vsebuje milijone particij, se čas, potreben za pridobitev particije, poveča in lahko povzroči podaljšanje časa izvajanja poizvedbe.
Danes je bila podpora za pajke AWS Glue razširjena na samodejno dodajanje indeksov particij za na novo odkrite tabele za optimizacijo obdelave poizvedb na particioniranem naboru podatkov. Zdaj, ko pajek med izvajanjem pajka ustvari novo tabelo podatkovnega kataloga, privzeto ustvari tudi indeks particije z največjo permutacijo vseh particijskih stolpcev številskega in nizovnega tipa kot ključev. Podatkovni katalog nato na podlagi teh ključev ustvari indeks po katerem je mogoče iskati, kar skrajša čas, potreben za pridobivanje in filtriranje metapodatkov o particijah v tabelah z milijoni particij. Ustvarjanje particijskih indeksov koristi analitičnim delovnim obremenitvam, ki se izvajajo na Atheni, Amazonski EMR, Amazonov rdeči premik spektrain lepilo AWS.
V tej objavi opisujemo, kako ustvariti indekse particij s pajkom AWS Glue in primerjamo izboljšanje zmogljivosti poizvedb pri dostopu do pajkanih podatkov z in brez indeksa particij iz Athene.
Pregled rešitev
Uporabljamo Oblikovanje oblaka AWS predlogo za ustvarjanje virov naše rešitve. V naslednjih korakih prikazujemo, kako konfigurirati pajka AWS Glue za ustvarjanje indeksa particije z uporabo konzole AWS Glue ali Vmesnik ukazne vrstice AWS (AWS CLI). Nato primerjamo izboljšave zmogljivosti poizvedbe z Atheno.
Predpogoji
Če želite spremljati to objavo, morate imeti dostop do AWS upravljanje identitete in dostopa (IAM) skrbniška vloga za ustvarjanje virov z uporabo AWS CloudFormation.
Nastavite svoje vire rešitev
Predloga CloudFormation ustvari naslednje vire:
- Vloge in politike IAM
- Baza podatkov AWS Glue za hrambo sheme
- Pajek AWS Glue, ki kaže na zelo particioniran nabor podatkov
- Delovna skupina Athena in vedro za shranjevanje rezultatov poizvedbe
Izvedite naslednje korake za nastavitev virov rešitve:
- Prijava na Konzola za upravljanje AWS kot skrbnik IAM.
- Izberite Izstrelite sklad za uvedbo predloge CloudFormation:

- za DatabaseName, ohrani privzeto
blog_partition_index_crawlerdb.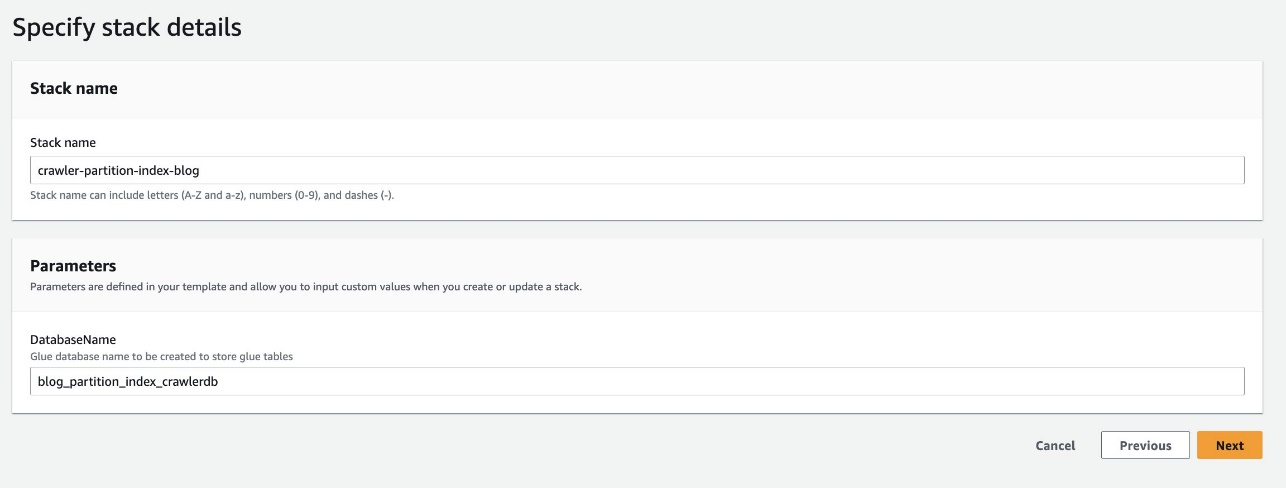
- Izberite Naslednji.
- Preglejte podrobnosti na zadnji strani in izberite Priznavam, da lahko AWS CloudFormation ustvari vire IAM.
- Izberite Ustvari sklad.
- Ko je sklad končan, se na konzoli AWS CloudFormation pomaknite do Izhodi zavihek sklada.
- Zapišite si vrednosti
DatabaseNameinGlueCrawlerName.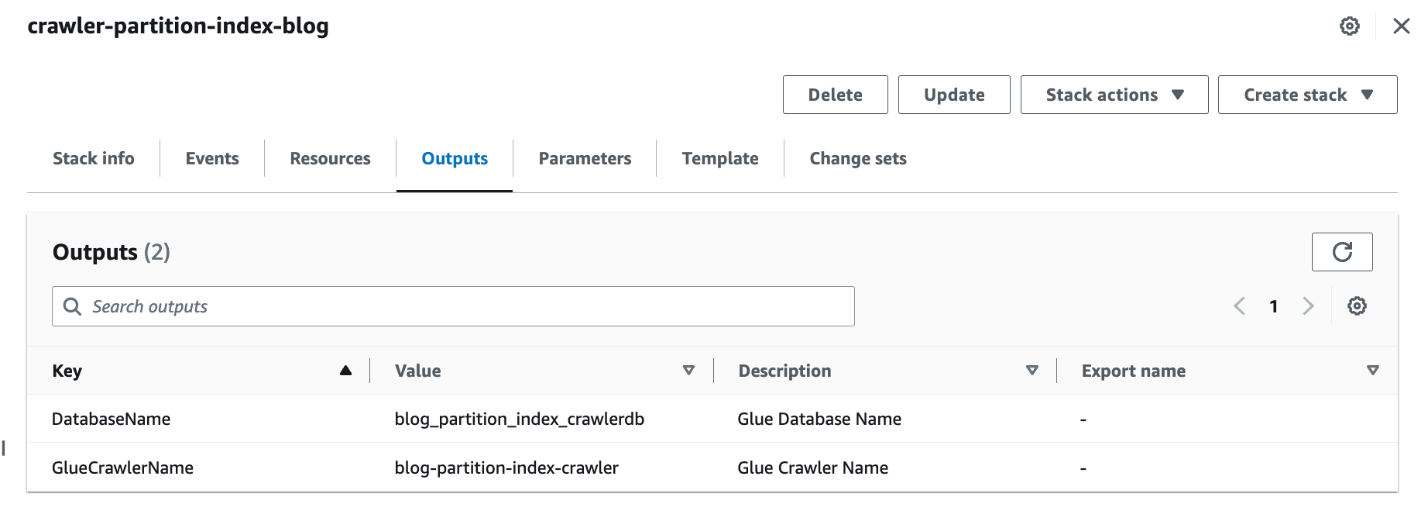
Nekateri viri, ki jih uporablja ta sklad, povzročajo stroške, ko so v uporabi.
Uredite in zaženite pajka AWS Glue
Če želite konfigurirati in zagnati pajka AWS Glue, izvedite naslednje korake:
- Na konzoli AWS Glue izberite Pajki v podoknu za krmarjenje.
- Poiščite
crawler blog-partition-index-crawlerIn izberite Uredi.
- v Nastavite izhod in razporejanje oddelek, pod Dodatne možnostitako, da izberete Samodejno ustvarite indekse particij.
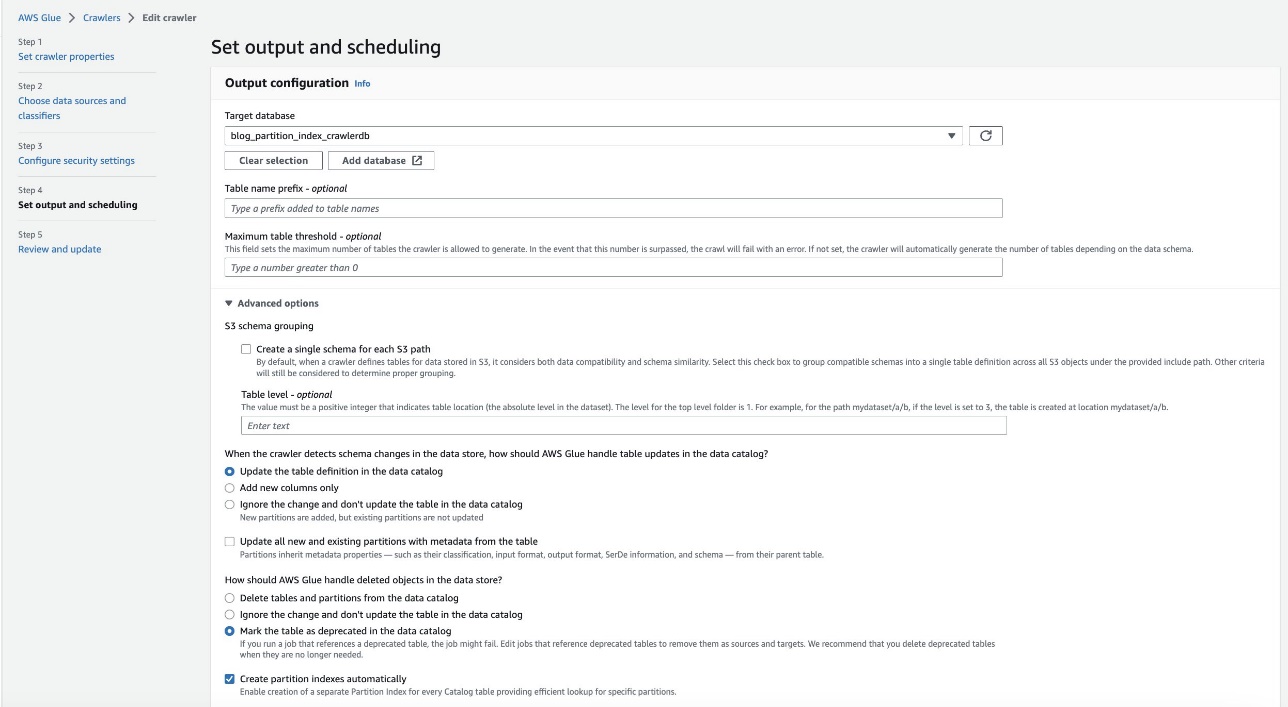
- Preglejte in posodobite nastavitve pajka.
Druga možnost je, da pajka konfigurirate z uporabo AWS CLI (vnesite svojo vlogo IAM in regijo):
- Zdaj zaženite pajka in preverite, ali je zagon pajka končan.
To je zelo particioniran nabor podatkov in traja približno 90 minut.
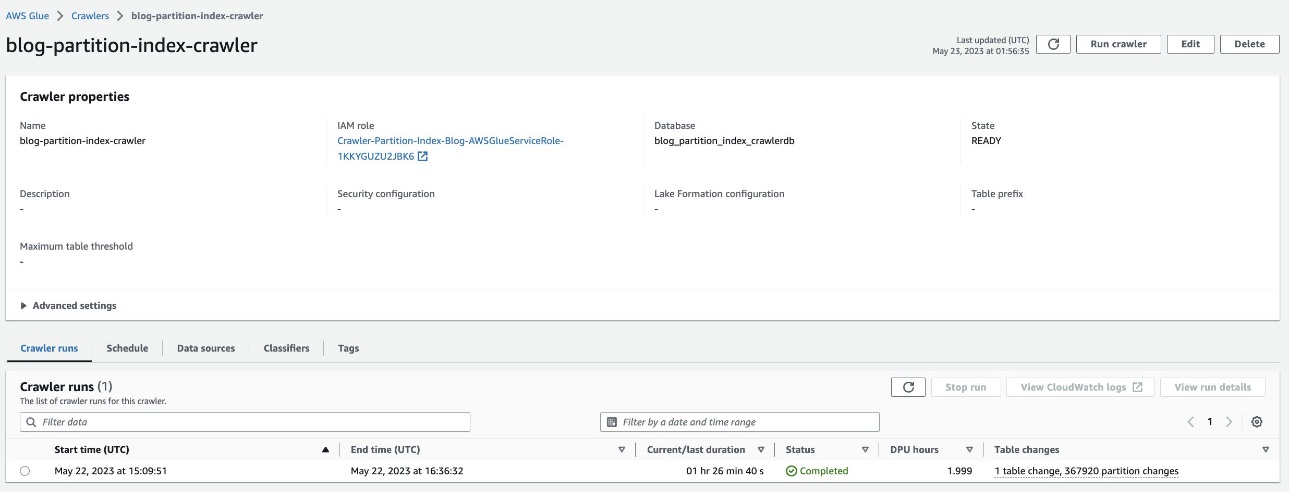
Preverite particionirano tabelo
V bazi podatkov AWS Glue blog_partition_index_crawlerdb, preverite, ali tabela highly_partitioned_table je ustvarjen.
Pajek po privzetku določi indeks na podlagi največje permutacije particijskih stolpcev veljavnih tipov stolpcev v istem vrstnem redu particijskih stolpcev, ki so številski ali nizovni. Za tabelo, ki jo je ustvaril pajek (highly_partitioned_table), imamo pregradne stebre year (vrvica), month (vrvica), day (niz) in hour (vrvica).
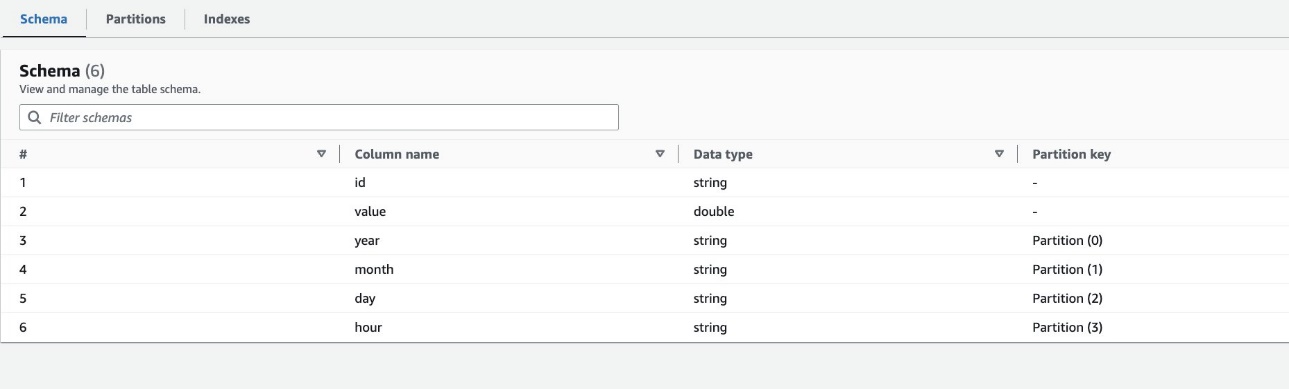
Na podlagi te definicije je pajek ustvaril indeks za permutacijo leta, meseca, dneva in ure. Pajek je ustvaril indekse s predpono crawler_ na katerem koli privzeto ustvarjenem particijskem indeksu.
Enako preverite tako, da se pomaknete do tabele highly_partitioned_table na konzoli AWS Glue in izbiro Kazala tab.
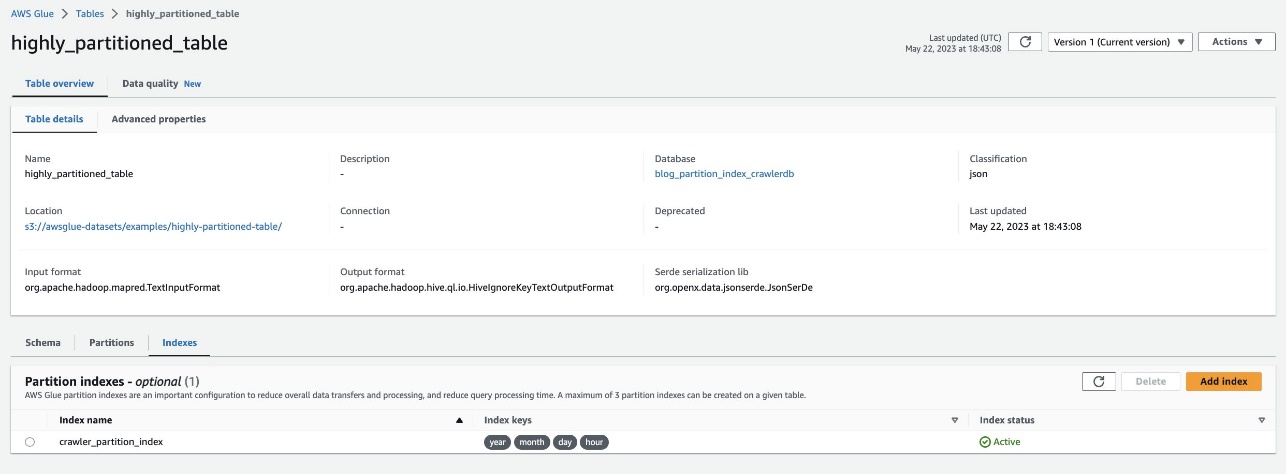
Pajek je uspel preiskati izvor podatkov S3 in uspešno zapolniti indekse particij za tabelo.
Primerjajte izboljšave zmogljivosti poizvedb z Atheno
Najprej izvedemo poizvedbo po tabeli v Atheni brez uporabe indeksa particije. Če želite preveriti tabele z Atheno, izvedite naslednje korake:
- Na konzoli Athena izberite
crawler-primary-workgroupkot delovna skupina Athena in izberite Priznati.
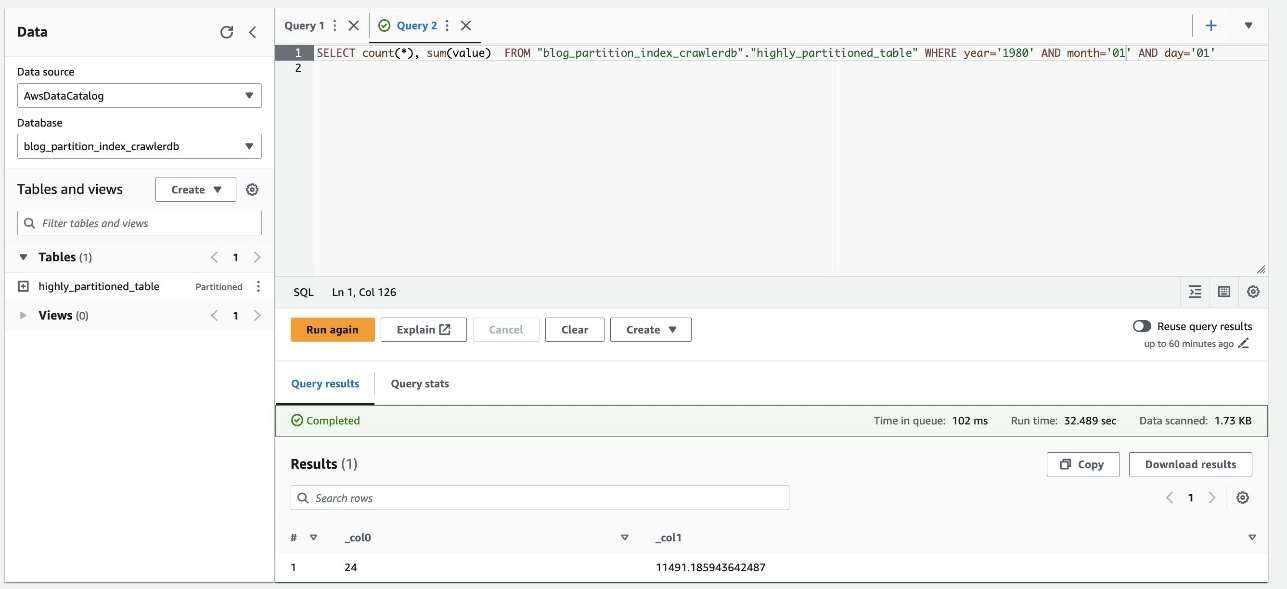
- Zaženite naslednjo poizvedbo:
Naslednji posnetek zaslona prikazuje, da je poizvedba trajala približno 32 sekund brez omogočenega filtriranja z uporabo indeksa particije.
- Zdaj omogočimo indeks particije na poizvedbi Athena:
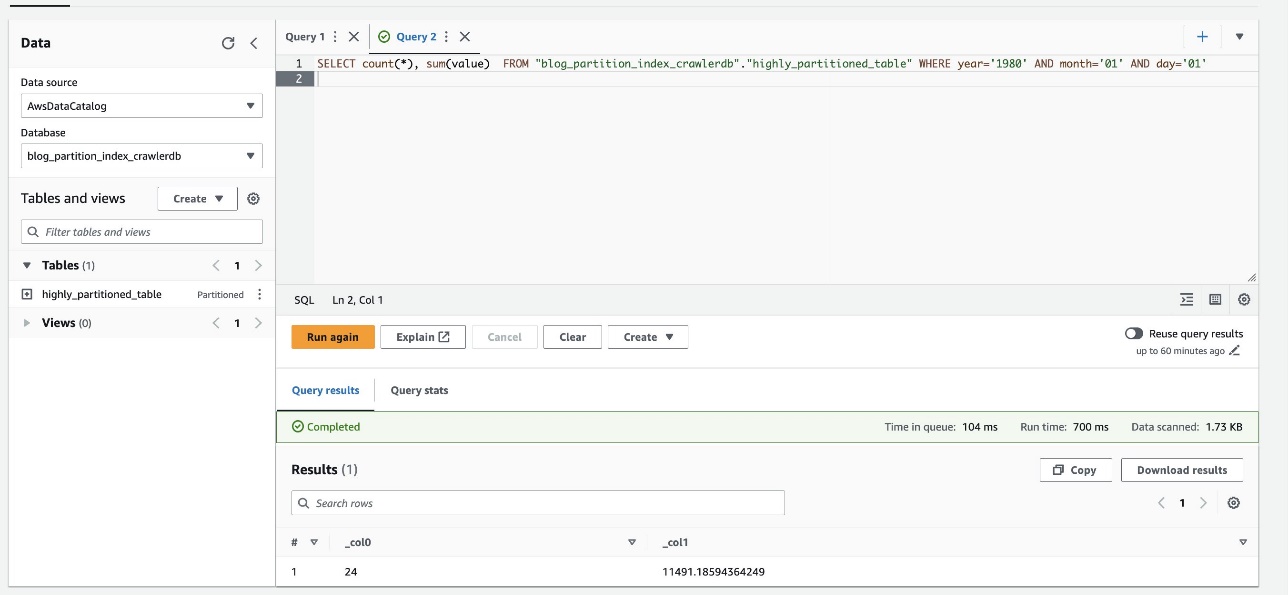
- Ponovno zaženite naslednjo poizvedbo in zabeležite čas izvajanja:
Naslednji posnetek zaslona prikazuje, da je poizvedba trajala le 700 milisekund, kar je veliko hitreje, če je filtriranje omogočeno z uporabo indeksa particije.
Čiščenje
Če se želite izogniti neželenim bremenitvam vašega računa AWS, lahko izbrišete vire AWS:
- Prijavite se v konzolo CloudFormation kot skrbnik IAM, uporabljen za ustvarjanje sklada CloudFormation.
- Izbrišite sklad CloudFormation, ki ste ga ustvarili.
zaključek
V tej objavi smo razložili, kako konfigurirati pajka AWS za ustvarjanje indeksov particij in primerjali zmogljivost poizvedb pri dostopu do podatkov z indeksi iz Athene.
Če v tabeli ni indeksov particij, AWS Glue naloži vse particije tabele in nato filtrira naložene particije, kar ima za posledico neučinkovito pridobivanje metapodatkov. Storitve analitike, kot so Redshift Spectrum, Amazon EMR in AWS Glue ETL Spark DataFrames, lahko zdaj uporabljajo indekse za pridobivanje particij, kar ima za posledico znatno zmogljivost poizvedb.
Za več informacij o indeksih particij in zmogljivosti poizvedb v različnih analitičnih motorjih glejte Izboljšajte zmogljivost poizvedb Amazon Athena z uporabo indeksov particij AWS Glue Data Catalog in Izboljšajte zmogljivost poizvedb z uporabo indeksov particij AWS Glue.
Posebna zahvala vsem, ki so prispevali k predstavitvi te funkcije pajka: Yuhang Chen, Kyle Duong in Mita Gavade.
O avtorjih
 Srividya Parthasarathy je višji arhitekt za velike podatke v ekipi AWS Lake Formation. Uživa v gradnji rešitev podatkovnih mrež in jih deli s skupnostjo.
Srividya Parthasarathy je višji arhitekt za velike podatke v ekipi AWS Lake Formation. Uživa v gradnji rešitev podatkovnih mrež in jih deli s skupnostjo.
 Sandeep Adwankar je višji tehnični produktni vodja pri AWS. S sedežem na območju kalifornijskega zaliva sodeluje s strankami po vsem svetu pri prevajanju poslovnih in tehničnih zahtev v izdelke, ki strankam omogočajo izboljšanje načina upravljanja, zaščite in dostopa do podatkov.
Sandeep Adwankar je višji tehnični produktni vodja pri AWS. S sedežem na območju kalifornijskega zaliva sodeluje s strankami po vsem svetu pri prevajanju poslovnih in tehničnih zahtev v izdelke, ki strankam omogočajo izboljšanje načina upravljanja, zaščite in dostopa do podatkov.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- EVM Finance. Poenoten vmesnik za decentralizirane finance. Dostopite tukaj.
- Quantum Media Group. IR/PR ojačan. Dostopite tukaj.
- PlatoAiStream. Podatkovna inteligenca Web3. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :ima
- : je
- :kje
- $GOR
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Sposobna
- dostop
- Dostop
- Račun
- potrditi
- čez
- dodajte
- admin
- spet
- vsi
- skupaj
- Prav tako
- Amazon
- Amazonska Atena
- Amazonski EMR
- Amazon Web Services
- zneski
- an
- Analitično
- analitika
- in
- kaj
- približno
- SE
- OBMOČJE
- okoli
- AS
- At
- samodejno
- Na voljo
- izogniti
- AWS
- Oblikovanje oblaka AWS
- AWS lepilo
- Oblikovanje jezera AWS
- temeljijo
- zaliv
- ker
- bilo
- Prednosti
- Big
- Big Podatki
- Building
- poslovni
- by
- california
- CAN
- Katalog
- Vzrok
- Spremembe
- Stroški
- chen
- Izberite
- izbiri
- Razvrstitev
- Stolpec
- Stolpci
- prihaja
- skupnost
- primerjate
- v primerjavi z letom
- dokončanje
- Konzole
- stalno
- prispevali
- stroški
- gosenicah
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- Oblikovanje
- Trenutna
- Stranke, ki so
- datum
- dostop do podatkov
- Data jezero
- Baze podatkov
- dan
- privzeto
- izkazati
- razporedi
- razpolaga
- opisati
- Podrobnosti
- določa
- odkril
- navzdol
- med
- učinkovito
- bodisi
- omogočajo
- omogočena
- Motorji
- Eter (ETH)
- vsi
- razširiti
- razložiti
- eksponentno
- ekstrakt
- izvlecite podatke
- hitreje
- Feature
- filter
- filtriranje
- Filtri
- končna
- sledi
- po
- za
- Oblikovanje
- iz
- ustvarja
- dana
- globus
- Grow
- Pridelovanje
- Imajo
- he
- težka
- težko dvigovanje
- zelo
- držite
- uro
- Kako
- Kako
- HTML
- http
- HTTPS
- IAM
- identiteta
- izboljšanje
- Izboljšanje
- Izboljšave
- in
- Povečajte
- Poveča
- Indeks
- indekse
- neučinkovit
- Podatki
- v
- IT
- jpg
- Imejte
- vzdrževanje
- tipke
- Jezero
- Največji
- kosilo
- postavitev
- dviganje
- kot
- vrstica
- obremenitve
- Znamka
- upravljanje
- upravljanje
- upravitelj
- očesa
- metapodatki
- morda
- milijoni
- min
- mesec
- več
- veliko
- morajo
- Krmarjenje
- krmarjenje
- ostalo
- potrebna
- Novo
- na novo
- št
- zdaj
- Številka
- of
- on
- samo
- Optimizirajte
- or
- Da
- naši
- izhod
- več
- Stran
- podokno
- pot
- performance
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Prispevek
- predstaviti
- obravnavati
- Izdelek
- produktni vodja
- Izdelki
- zagotavljajo
- zmanjšanje
- okolica
- obvezna
- Zahteve
- zahteva
- viri
- rezultat
- Rezultati
- vloga
- vloge
- Run
- tek
- Enako
- sekund
- Oddelek
- zavarovanje
- višji
- Storitve
- nastavite
- nastavitve
- delitev
- je
- Razstave
- pomemben
- bistveno
- Enostavno
- Rešitev
- rešitve
- vir
- Spark
- Spectrum
- sveženj
- Koraki
- shranjevanje
- trgovina
- naravnost
- String
- Uspešno
- podpora
- sistemi
- miza
- Bodite
- skupina
- tehnični
- Predloga
- hvala
- da
- O
- njihove
- Njih
- POTEM
- te
- jih
- ta
- čas
- do
- današnje
- vzel
- prevesti
- Res
- tip
- Vrste
- pod
- razumeli
- nezaželen
- Nadgradnja
- uporaba
- Rabljeni
- uporabo
- uporabiti
- vrednost
- Vrednote
- različnih
- Popravljeno
- preverjanje
- različica
- je
- način..
- we
- web
- spletne storitve
- kdaj
- ki
- WHO
- bo
- z
- brez
- Delovna skupina
- deluje
- svet
- yaml
- leto
- jo
- Vaša rutina za
- zefirnet