
Slika avtorja | Bing Image Creator
Dolly 2.0 je odprtokodni model velikega jezika (LLM), ki sledi navodilom in je bil natančno nastavljen na naboru podatkov, ki ga je ustvaril človek. Uporablja se lahko tako v raziskovalne kot komercialne namene.
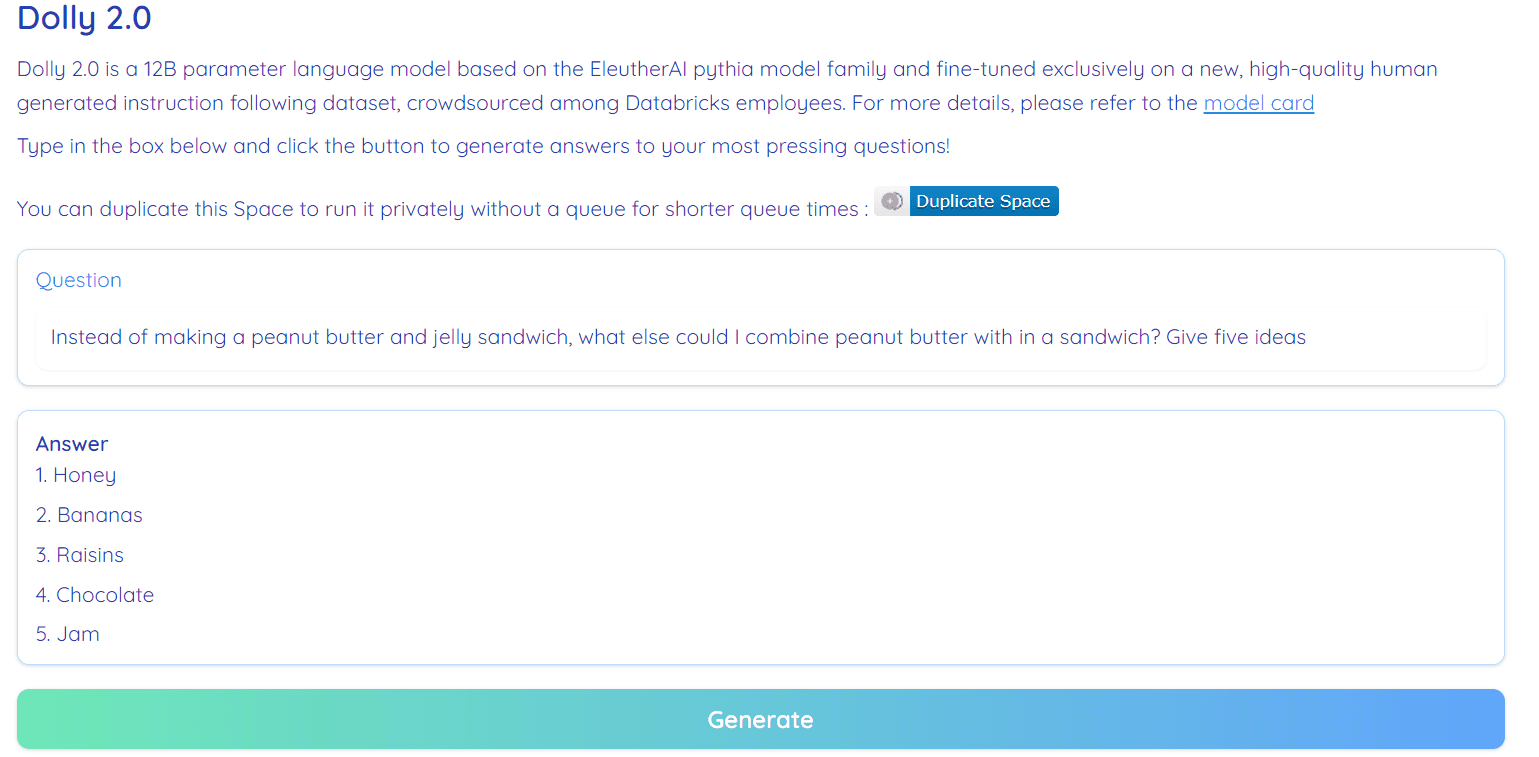
Slika iz Hugging Face Space avtor RamAnanth1
Prej je ekipa Databricks izdala Dolly 1.0, LLM, ki kaže sposobnost sledenja navodilom, podobnim ChatGPT, in stane manj kot 30 USD za usposabljanje. Uporabljal je nabor podatkov skupine Stanford Alpaca, ki je bil pod omejeno licenco (samo raziskave).
Dolly 2.0 je to težavo rešil s fino nastavitvijo modela jezika parametrov 12B (Pitija) na visokokakovostnem navodilu, ki ga je ustvaril človek, v naslednjem naboru podatkov, ki ga je označil uslužbenec podjetja Datbricks. Tako model kot nabor podatkov sta na voljo za komercialno uporabo.
Dolly 1.0 je bil usposobljen na naboru podatkov Stanford Alpaca, ki je bil ustvarjen z uporabo API-ja OpenAI. Nabor podatkov vsebuje izhod iz ChatGPT in preprečuje, da bi ga kdorkoli uporabil za tekmovanje z OpenAI. Skratka, na podlagi tega nabora podatkov ne morete zgraditi komercialnega chatbota ali jezikovne aplikacije.
Večina najnovejših modelov, izdanih v zadnjih nekaj tednih, je imela enake težave, modeli, kot je Alpaca, Koala, GPT4Allin vikunje. Da bi se obrnili, moramo ustvariti nove visokokakovostne nabore podatkov, ki jih je mogoče uporabiti za komercialno uporabo, in to je ekipa Databricks naredila z naborom podatkov databricks-dolly-15k.
Nov nabor podatkov vsebuje 15,000 visokokakovostnih parov poziv/odziv, označenih s človekom, ki jih je mogoče uporabiti za načrtovanje navodil za prilagajanje velikih jezikovnih modelov. The databricks-dolly-15k nabor podatkov je priložen Neprenesena licenca Creative Commons Attribution-ShareAlike 3.0, ki omogoča vsakomur, da ga uporablja, spreminja in na njem ustvari komercialno aplikacijo.
Kako so ustvarili nabor podatkov databricks-dolly-15k?
Raziskava OpenAI papirja navaja, da je bil prvotni model InstructGPT učen na 13,000 pozivih in odzivih. Z uporabo teh informacij je ekipa Databricks začela delati na tem in izkazalo se je, da je bilo ustvarjanje 13 vprašanj in odgovorov težka naloga. Ne morejo uporabljati sintetičnih podatkov ali generativnih podatkov AI in morajo ustvariti izvirne odgovore na vsako vprašanje. Tu so se odločili uporabiti 5,000 zaposlenih v podjetju Databricks za ustvarjanje podatkov, ki jih ustvari človek.
Databricks so pripravili tekmovanje, v katerem bi 20 najboljših založnikov prejelo veliko nagrado. V tem tekmovanju je sodelovalo 5,000 Databricks zaposlenih, ki so bili zelo zainteresirani za LLM
Dolly-v2-12b ni najsodobnejši model. V nekaterih merilih ocenjevanja je slabši od dolly-v1-6b. Morda je to posledica sestave in velikosti osnovnih naborov podatkov za natančno nastavitev. Družina modelov Dolly je v aktivnem razvoju, zato boste morda v prihodnosti videli posodobljeno različico z boljšim delovanjem.
Skratka, model dolly-v2-12b se je izkazal bolje kot EleutherAI/gpt-neox-20b in EleutherAI/pythia-6.9b.

Slika iz Brezplačna Dolly
Dolly 2.0 je 100% odprtokoden. Na voljo je s kodo za usposabljanje, naborom podatkov, utežmi modela in cevovodom sklepanja. Vse komponente so primerne za komercialno uporabo. Model lahko preizkusite na Hugging Face Spaces Dolly V2 avtorja RamAnanth1.
Slika iz Objemni obraz
Vir:
Predstavitev Dolly 2.0: Dolly V2 avtorja RamAnanth1
Abid Ali Awan (@1abidaliawan) je certificiran strokovnjak za podatkovne znanstvenike, ki rad gradi modele strojnega učenja. Trenutno se osredotoča na ustvarjanje vsebin in pisanje tehničnih blogov o strojnem učenju in tehnologijah podatkovne znanosti. Abid ima magisterij iz tehnološkega managementa in diplomo iz telekomunikacijskega inženiringa. Njegova vizija je zgraditi izdelek AI z uporabo grafične nevronske mreže za študente, ki se borijo z duševnimi boleznimi.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- Kovanje prihodnosti z Adryenn Ashley. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :ima
- : je
- :ne
- $GOR
- 000
- 1
- 20
- a
- sposobnost
- aktivna
- AI
- vsi
- omogoča
- alternativa
- an
- in
- odgovori
- kdo
- API
- uporaba
- SE
- okoli
- Avtor
- Na voljo
- Nagrada
- temeljijo
- BE
- meril
- Berkeley
- Boljše
- Big
- bing
- blogi
- tako
- izgradnjo
- Building
- by
- CAN
- ne more
- Certified
- chatbot
- ChatGPT
- Koda
- komercialna
- Commons
- tekmujejo
- deli
- Vsebuje
- vsebina
- ustvarjanje vsebine
- Tekmovanje
- stroški
- ustvarjajo
- ustvaril
- Oblikovanje
- Trenutno
- datum
- znanost o podatkih
- podatkovni znanstvenik
- Podatkovne palice
- nabor podatkov
- odločil
- Stopnja
- Predstavitev
- Oblikovanje
- Razvoj
- DID
- težko
- Dolly
- Zaposlen
- Zaposleni
- Inženiring
- Ocena
- Tudi vsak
- eksponati
- Obraz
- družina
- Nekaj
- osredotoča
- po
- za
- iz
- Prihodnost
- ustvarjajo
- ustvarjajo
- generativno
- dobili
- graf
- Grafična nevronska mreža
- Imajo
- he
- visoka kvaliteta
- drži
- HTML
- HTTPS
- bolezen
- slika
- in
- Podatki
- zainteresirani
- vprašanje
- Vprašanja
- IT
- jpg
- KDnuggets
- jezik
- velika
- Zadnja
- Zadnji
- učenje
- Licenca
- kot
- stroj
- strojno učenje
- upravljanje
- mojster
- duševne
- Mentalna bolezen
- morda
- Model
- modeli
- spremenite
- Nimate
- mreža
- Nevronski
- nevronska mreža
- Novo
- of
- on
- samo
- odprite
- open source
- OpenAI
- or
- izvirno
- izhod
- parov
- parameter
- sodelovali
- performance
- plinovod
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Izdelek
- strokovni
- namene
- vprašanje
- vprašanja
- sprosti
- Raziskave
- rešiti
- omejeno
- s
- Enako
- Znanost
- Znanstvenik
- nastavite
- Kratke Hlače
- Velikosti
- So
- nekaj
- vir
- Vesolje
- prostori
- Stanford
- začel
- state-of-the-art
- Države
- Boriti se
- Študenti
- primerna
- sintetična
- sintetični podatki
- Naloga
- skupina
- tehnični
- Tehnologije
- Tehnologija
- telekomunikacije
- kot
- da
- O
- Prihodnost
- jih
- ta
- do
- vrh
- Vlak
- usposobljeni
- usposabljanje
- pod
- osnovni
- posodobljeno
- uporaba
- Rabljeni
- uporabo
- različica
- Vizija
- je
- we
- Weeks
- so bili
- Kaj
- ki
- WHO
- z
- delo
- bi
- pisanje
- jo
- zefirnet










