Amazon RedShift je popolnoma upravljano skladišče podatkov v oblaku velikosti petabajtov, ki ga uporablja na desettisoče strank za obdelavo eksabajtov podatkov vsak dan za oskrbo s svojo analitično delovno obremenitvijo. Svoje podatke lahko strukturirate, merite poslovne procese in hitro pridobite dragocene vpoglede z uporabo dimenzijskega modela. Amazon Redshift ponuja vgrajene funkcije za pospešitev procesa modeliranja, orkestriranja in poročanja iz dimenzijskega modela.
V tej objavi razpravljamo o tem, kako implementirati dimenzijski model, natančneje o Metodologija Kimball. Razpravljamo o izvajanju razsežnosti in dejstev znotraj Amazon Redshift. Pokažemo, kako izvesti ekstrahiranje, preoblikovanje in nalaganje (ELT), proces integracije, ki je osredotočen na pridobivanje neobdelanih podatkov iz podatkovnega jezera v uprizoritveni sloj za izvedbo modeliranja. Na splošno vam bo objava dala jasno razumevanje uporabe dimenzijskega modeliranja v Amazon Redshift.
Pregled rešitev
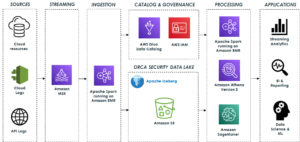
Naslednji diagram prikazuje arhitekturo rešitev.

V naslednjih razdelkih najprej razpravljamo in prikazujemo ključne vidike dimenzijskega modela. Po tem ustvarimo podatkovno trgovino z uporabo Amazon Redshift z dimenzionalnim podatkovnim modelom, vključno s tabelami razsežnosti in dejstev. Podatki se naložijo in razporedijo z uporabo COPY se podatki v dimenzijah naložijo z ukazom MERGE izjava, dejstva pa bodo združena z dimenzijami, iz katerih izhajajo vpogledi. Nalaganje dimenzij in dejstev načrtujemo s pomočjo Amazon Redshift Query Editor V2. Nazadnje uporabljamo Amazon QuickSight pridobiti vpogled v modelirane podatke v obliki nadzorne plošče QuickSight.
Za to rešitev uporabljamo vzorčni nabor podatkov (normaliziran), ki ga zagotavlja Amazon Redshift za prodajo vstopnic za dogodke. Za to objavo smo zaradi enostavnosti in predstavitve zožili nabor podatkov. Naslednje tabele prikazujejo primere podatkov za prodajo vstopnic in prizorišča.


Glede na Metodologija dimenzijskega modeliranja Kimball, obstajajo štirje ključni koraki pri oblikovanju dimenzijskega modela:
- Identificirajte poslovni proces.
- Navedite zrno svojih podatkov.
- Identificirajte in implementirajte dimenzije.
- Ugotovite in implementirajte dejstva.
Dodatno dodajamo še peti korak za demonstracijo, to je poročanje in analiza poslovnih dogodkov.
Predpogoji
Za ta korak morate imeti naslednje predpogoje:
Identificirajte poslovni proces
Preprosto povedano, prepoznavanje poslovnega procesa je prepoznavanje merljivega dogodka, ki ustvarja podatke znotraj organizacije. Običajno imajo podjetja nekakšen operativni izvorni sistem, ki generira njihove podatke v neobdelani obliki. To je dobro izhodišče za prepoznavanje različnih virov za poslovni proces.
Poslovni proces se nato ohrani kot a podatkovni mart v obliki dimenzij in dejstev. Če pogledamo naš vzorčni nabor podatkov, omenjen prej, lahko jasno vidimo, da je poslovni proces prodaja za določen dogodek.
Pogosta napaka je uporaba oddelkov podjetja kot poslovnega procesa. Podatki (poslovni procesi) morajo biti integrirani po različnih oddelkih, v tem primeru marketing lahko dostopa do podatkov o prodaji. Prepoznavanje pravilnega poslovnega procesa je ključnega pomena – napačna izvedba tega koraka lahko vpliva na celotno podatkovno trgovino (lahko povzroči podvajanje zrna in nepravilne meritve v končnih poročilih).
Navedite zrno svojih podatkov
Deklaracija zrna je dejanje enolične identifikacije zapisa v vašem viru podatkov. Zrnatost je uporabljena v tabeli dejstev za natančno merjenje podatkov in omogočanje nadaljnjega združevanja. V našem primeru je to lahko vrstična postavka v prodajnem poslovnem procesu.
V našem primeru uporabe je mogoče prodajo enolično identificirati tako, da pogledamo čas transakcije, ko je bila prodaja izvedena; to bo najbolj atomska raven.

Identificirajte in implementirajte dimenzije
Vaša razsežna tabela opisuje vašo tabelo dejstev in njene atribute. Ko identificirate opisni kontekst vašega poslovnega procesa, shranite besedilo v ločeno tabelo, pri čemer upoštevate zrnatost tabele dejstev. Ko združujete tabelo dimenzij s tabelo dejstev, mora biti s tabelo dejstev povezana samo ena vrstica. V našem primeru uporabljamo naslednjo tabelo, ki jo ločimo v tabelo dimenzij; ta polja opisujejo dejstva, ki jih bomo merili.
Pri načrtovanju strukture dimenzijskega modela (sheme) lahko ustvarite a zvezda or snežinka shema. Struktura mora biti tesno usklajena s poslovnim procesom; zato je zvezdasta shema najbolj primerna za naš primer. Naslednja slika prikazuje naš diagram odnosov entitet (ERD).

V naslednjih razdelkih podrobno opisujemo korake za implementacijo dimenzij.
Uprizorite izvorne podatke
Preden lahko ustvarimo in naložimo tabelo dimenzij, potrebujemo izvorne podatke. Zato izvorne podatke postavimo v uprizoritveno ali začasno tabelo. To se pogosto imenuje uprizoritveni sloj, ki je neobdelana kopija izvornih podatkov. Za to v Amazon Redshift uporabimo ukaz COPY za nalaganje podatkov iz javnega vedra dimenzionalnega-modeliranja-in-amazon-redshift S3, ki se nahaja na us-east-1 Regija. Upoštevajte, da ukaz COPY uporablja AWS upravljanje identitete in dostopa (IAM) vloga z dostop do Amazon S3. Vloga mora biti povezana z grozdom. Izvedite naslednje korake za uprizoritev izvornih podatkov:
- Ustvarite
venueizvorna tabela:
- Naložite podatke o prizorišču:
- Ustvarite
salesizvorna tabela:
- Naloži podatke o izvoru prodaje:
- Ustvarite
calendarmiza:
- Naloži podatke koledarja:
Ustvarite tabelo dimenzij
Oblikovanje tabele dimenzij je lahko odvisno od vaših poslovnih zahtev – ali morate na primer slediti spremembam podatkov skozi čas? obstajajo sedem različnih vrst dimenzij. Za naš primer uporabljamo Tip 1 ker nam ni treba slediti zgodovinskim spremembam. Za več o tipu 2 glejte Poenostavite nalaganje podatkov v počasi spreminjajoče se dimenzije vrste 2 v Amazon Redshift. Tabela dimenzij bo denormalizirana s primarnim ključem, nadomestnim ključem in nekaj dodanimi polji za označevanje sprememb v tabeli. Oglejte si naslednjo kodo:
Nekaj opomb o ustvarjanju tabele dimenzij:
- Imena polj se spremenijo v poslovno prijazna imena
- Naš primarni ključ je
VenueID, ki ga uporabljamo za enolično identifikacijo kraja, kjer je potekala prodaja - Dodani bosta dve dodatni vrstici, ki označujeta, kdaj je bil zapis vstavljen in posodobljen (za sledenje spremembam)
- Uporabljamo an AUTO distribucijski slog da Amazonu Redshift podeli odgovornost za izbiro in prilagajanje sloga distribucije
Drug pomemben dejavnik, ki ga je treba upoštevati pri dimenzijskem modeliranju, je uporaba nadomestni ključi. Nadomestni ključi so umetni ključi, ki se uporabljajo pri dimenzijskem modeliranju za enolično identifikacijo vsakega zapisa v dimenzijski tabeli. Običajno so ustvarjeni kot zaporedno celo število in v poslovni domeni nimajo nobenega pomena. Ponujajo številne prednosti, na primer zagotavljanje edinstvenosti in izboljšanje zmogljivosti pri združevanjih, ker so običajno manjši od naravnih ključev in se kot nadomestni ključi sčasoma ne spreminjajo. To nam omogoča, da smo dosledni in lažje združujemo dejstva in dimenzije.
V Amazon Redshift se nadomestni ključi običajno ustvarijo s ključno besedo IDENTITY. Na primer, prejšnji stavek CREATE ustvari tabelo dimenzij z a VenueSkey nadomestni ključ. The VenueSkey se samodejno zapolni z edinstvenimi vrednostmi, ko se v tabelo dodajo nove vrstice. Ta stolpec lahko nato uporabite za pridružitev tabele prizorišča v FactSaleTransactions miza.
Nekaj nasvetov za oblikovanje nadomestnih ključev:
- Za nadomestni ključ uporabite majhen podatkovni tip s fiksno širino. To bo izboljšalo zmogljivost in zmanjšalo prostor za shranjevanje.
- Uporabite ključno besedo IDENTITY ali ustvarite nadomestni ključ z uporabo zaporedne vrednosti ali vrednosti GUID. To bo zagotovilo, da je nadomestni ključ edinstven in ga ni mogoče spremeniti.
Naloži tabelo dim z uporabo MERGE
Obstaja veliko načinov za nalaganje dimne mize. Upoštevati je treba nekatere dejavnike – na primer zmogljivost, količino podatkov in morda čas nalaganja SLA. z MERGE stavek izvedemo upsert, ne da bi morali podati več ukazov za vstavljanje in posodabljanje. Lahko nastavite MERGE izjava v a shranjen postopek za zapolnitev podatkov. Nato načrtujete programsko izvajanje shranjene procedure prek urejevalnika poizvedb, kar bomo prikazali kasneje v objavi. Naslednja koda ustvari shranjeno proceduro, imenovano SalesMart.DimVenueLoad:
Nekaj opomb o nalaganju dimenzij:
- Ko je zapis vstavljen prvič, bosta zapolnjena vstavljeni datum in posodobljeni datum. Ko se katera koli vrednost spremeni, se podatki posodobijo in posodobljeni datum odraža datum, ko je bil spremenjen. Vstavljeni datum ostane.
- Ker bodo podatke uporabljali poslovni uporabniki, moramo vrednosti NULL, če obstajajo, nadomestiti z bolj poslovno primernimi vrednostmi.
Ugotovite in implementirajte dejstva
Zdaj, ko smo svoje žito razglasili za dogodek prodaje, ki se je zgodila ob določenem času, bo naša tabela dejstev shranila številčna dejstva za naš poslovni proces.
Ugotovili smo naslednja številčna dejstva za merjenje:
- Količina prodanih vstopnic na prodajo
- Provizija za prodajo
Izvajanje dejstva
obstajajo tri vrste tabel dejstev (tabela dejstev o transakcijah, periodična tabela dejstev posnetkov in kopična tabela dejstev posnetkov). Vsak služi drugačnemu pogledu na poslovni proces. Za naš primer uporabljamo tabelo dejstev o transakcijah. Izvedite naslednje korake:
- Ustvarite tabelo dejstev
Doda se vstavljeni datum s privzeto vrednostjo, ki označuje, ali in kdaj je bil zapis naložen. To lahko uporabite pri ponovnem nalaganju tabele dejstev, da odstranite že naložene podatke in se izognete dvojnikom.
Nalaganje tabele dejstev je sestavljeno iz preprostega vstavitvenega stavka, ki združuje vaše povezane dimenzije. Pridružujemo se iz DimVenue nastala tabela, ki opisuje naša dejstva. To je najboljša praksa, vendar izbirno koledarski datum dimenzije, ki končnemu uporabniku omogočajo krmarjenje po tabeli dejstev. Podatki se lahko naložijo ob novi prodaji ali dnevno; tu pride prav vstavljeni datum ali datum nalaganja.
Tabelo dejstev naložimo s pomočjo shranjene procedure in uporabimo datumski parameter.
- Ustvarite shranjeno proceduro z naslednjo kodo. Da bi ohranili isto celovitost podatkov, kot smo jo uporabili pri nalaganju dimenzije, nadomestimo vrednosti NULL, če obstajajo, z bolj poslovno primernimi vrednostmi:
- Naložite podatke tako, da pokličete proceduro z naslednjim ukazom:
Načrtujte nalaganje podatkov
Zdaj lahko avtomatiziramo postopek modeliranja z razporejanjem shranjenih procedur v Amazon Redshift Query Editor V2. Izvedite naslednje korake:
- Najprej pokličemo nalaganje dimenzij in po uspešnem izvajanju nalaganja dimenzij se začne nalaganje dejstev:
Če nalaganje dimenzij ne uspe, se nalaganje dejstev ne bo izvajalo. To zagotavlja doslednost podatkov, ker ne želimo naložiti tabele dejstev z zastarelimi dimenzijami.
- Če želite načrtovati obremenitev, izberite Urnik v urejevalniku poizvedb V2.

- Poizvedbo načrtujemo vsak dan ob 5 zjutraj.
- Po želji lahko dodate obvestila o napakah, tako da omogočite Amazon Simple notification Service (Amazon SNS) obvestila.

Poročanje in analiza podatkov v Amazon Quicksight
QuickSight je storitev poslovnega obveščanja, ki omogoča preprosto zagotavljanje vpogledov. Kot popolnoma upravljana storitev vam QuickSight omogoča preprosto ustvarjanje in objavo interaktivnih nadzornih plošč, do katerih lahko nato dostopate iz katere koli naprave in jih vdelate v svoje aplikacije, portale in spletna mesta.
Svojo podatkovno borzo uporabljamo za vizualno predstavitev dejstev v obliki nadzorne plošče. Če želite začeti in nastaviti QuickSight, glejte Ustvarjanje nabora podatkov z zbirko podatkov, ki ni samodejno odkrita.
Ko ustvarite vir podatkov v QuickSightu, združimo modelirane podatke (data mart) na podlagi našega nadomestnega ključa skey. Ta nabor podatkov uporabljamo za vizualizacijo podatkovne tržnice.

Naša končna nadzorna plošča bo vsebovala vpoglede v podatkovno trgovino in odgovarjala na kritična poslovna vprašanja, kot so skupna provizija na prizorišče in datumi z največjo prodajo. Naslednji posnetek zaslona prikazuje končni izdelek podatkovne tržnice.

Čiščenje
Da se izognete prihodnjim stroškom, izbrišite vse vire, ki ste jih ustvarili v okviru te objave.
zaključek
Zdaj smo uspešno implementirali podatkovni trg z našimi DimVenue, DimCalendarin FactSaleTransactions mize. Naše skladišče ni popolno; ker lahko razširimo podatkovno trgovino z več dejstvi in implementiramo več tržnic, in ko poslovni proces in zahteve sčasoma rastejo, se bo povečalo tudi podatkovno skladišče. V tej objavi smo predstavili celovit pogled na razumevanje in implementacijo dimenzijskega modeliranja v Amazon Redshift.
Začnite s svojim Amazon RedShift dimenzionalni model danes.
O avtorjih
 Bernard Verster je izkušen inženir v oblaku z dolgoletnimi izkušnjami pri ustvarjanju razširljivih in učinkovitih podatkovnih modelov, definiranju strategij integracije podatkov ter zagotavljanju upravljanja in varnosti podatkov. Navdušen je nad uporabo podatkov za pridobivanje vpogledov, hkrati pa se usklajuje s poslovnimi zahtevami in cilji.
Bernard Verster je izkušen inženir v oblaku z dolgoletnimi izkušnjami pri ustvarjanju razširljivih in učinkovitih podatkovnih modelov, definiranju strategij integracije podatkov ter zagotavljanju upravljanja in varnosti podatkov. Navdušen je nad uporabo podatkov za pridobivanje vpogledov, hkrati pa se usklajuje s poslovnimi zahtevami in cilji.
 Abhishek Pan je WWSO Specialist SA-Analytics, ki dela s strankami javnega sektorja AWS India. S strankami sodeluje pri definiranju strategije, ki temelji na podatkih, zagotavlja poglobljene seje o primerih uporabe analitike in oblikuje razširljive in zmogljive analitične aplikacije. Ima 12 let izkušenj in je navdušen nad podatkovnimi bazami, analitiko in AI/ML. Je navdušen popotnik in skuša ujeti svet skozi objektiv fotoaparata.
Abhishek Pan je WWSO Specialist SA-Analytics, ki dela s strankami javnega sektorja AWS India. S strankami sodeluje pri definiranju strategije, ki temelji na podatkih, zagotavlja poglobljene seje o primerih uporabe analitike in oblikuje razširljive in zmogljive analitične aplikacije. Ima 12 let izkušenj in je navdušen nad podatkovnimi bazami, analitiko in AI/ML. Je navdušen popotnik in skuša ujeti svet skozi objektiv fotoaparata.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Avtomobili/EV, Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- BlockOffsets. Posodobitev okoljskega offset lastništva. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- O meni
- pospeši
- dostop
- dostopna
- natančno
- čez
- Zakon
- dodajte
- dodano
- Dodatne
- po
- AI / ML
- uskladiti
- poravnava
- omogočajo
- omogoča
- že
- am
- Amazon
- Amazon Web Services
- an
- Analiza
- Analitično
- analitika
- analizirati
- in
- odgovor
- kaj
- aplikacije
- uporabna
- primerno
- Arhitektura
- SE
- umetni
- AS
- vidiki
- povezan
- At
- lastnosti
- avto
- avtomatizirati
- samodejno
- izogniti
- AWS
- b
- temeljijo
- BE
- ker
- začetek
- Prednosti
- BEST
- vgrajeno
- poslovni
- Poslovna inteligenca
- Poslovni proces
- poslovnih procesov
- vendar
- by
- Koledar
- klic
- se imenuje
- kliče
- kamera
- CAN
- zajemanje
- primeru
- primeri
- Vzrok
- nekatere
- spremenite
- spremenilo
- Spremembe
- spreminjanje
- značaja
- Stroški
- Izberite
- jasno
- jasno
- tesno
- Cloud
- Koda
- Stolpec
- prihaja
- Komisija
- Skupno
- Podjetja
- podjetje
- dokončanje
- Razmislite
- dosledno
- vsebuje
- ozadje
- popravi
- bi
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- Oblikovanje
- kritično
- Stranke, ki so
- vsak dan
- Armaturna plošča
- nadzorne plošče
- datum
- integracija podatkov
- Data jezero
- podatkovno skladišče
- Podatkov usmerjenih
- Strategija, ki temelji na podatkih
- Baze podatkov
- baze podatkov
- Datum
- Termini
- Datum čas
- dan
- globoko
- globok potop
- privzeto
- definiranje
- poda
- izkazati
- oddelki
- Izpeljano
- opisati
- Oblikovanje
- oblikovanje
- Podatki
- naprava
- drugačen
- Dimenzije
- dimenzije
- razpravlja
- izrazit
- distribucija
- do
- domena
- opravljeno
- dont
- navzdol
- pogon
- dvojnikov
- vsak
- prej
- enostavno
- lahka
- urednik
- učinkovite
- bodisi
- vgrajeni
- omogočajo
- omogočanje
- konec
- konec koncev
- se ukvarja
- inženir
- zagotovitev
- zagotavlja
- zagotoviti
- Celotna
- entiteta
- Eter (ETH)
- Event
- dogodki
- Tudi vsak
- vsak dan
- Primer
- Primeri
- Razširi
- izkušnje
- izkušen
- Izpostavljenost
- ekstrakt
- Dejstvo
- Faktor
- dejavniki
- dejstva
- ne uspe
- Napaka
- Lastnosti
- Nekaj
- Polje
- Področja
- peti
- Slika
- filter
- končna
- prva
- prvič
- fit
- osredotočena
- po
- za
- obrazec
- format
- štiri
- iz
- v celoti
- nadalje
- Prihodnost
- Gain
- ustvarjajo
- ustvarila
- ustvarja
- dobili
- pridobivanje
- Daj
- dana
- dobro
- upravljanje
- Grow
- priročen
- Imajo
- he
- najvišja
- njegov
- zgodovinski
- počitnice
- Kako
- Kako
- HTML
- http
- HTTPS
- IAM
- identificirati
- identificirati
- identifikacijo
- identiteta
- if
- ponazarja
- vpliv
- izvajati
- izvajali
- izvajanja
- Pomembno
- izboljšanje
- izboljšanju
- in
- Vključno
- india
- Navedite
- označuje
- info
- vpogledi
- integrirana
- integracija
- celovitost
- Intelligence
- interaktivno
- v
- IT
- ITS
- pridružite
- pridružil
- pridružil
- Pridružuje
- jpg
- Imejte
- vzdrževanje
- Ključne
- tipke
- Jezero
- jezik
- pozneje
- Zadnji
- plast
- levo
- Lens
- Lets
- Stopnja
- vrstica
- obremenitev
- nalaganje
- obremenitve
- nahaja
- si
- je
- IZDELA
- upravlja
- Trženje
- ujema
- kar pomeni,
- merjenje
- omenjeno
- Spoji
- Meritve
- moti
- napaka
- Model
- modeliranje
- modeliranje
- modeli
- mesec
- več
- Najbolj
- več
- Imena
- naravna
- Krmarjenje
- Nimate
- potrebujejo
- potrebe
- Novo
- Opombe
- Obvestilo
- Obvestila
- zdaj
- številne
- Cilji
- of
- ponudba
- pogosto
- on
- samo
- operativno
- or
- Organizacija
- naši
- več
- Splošni
- parameter
- del
- strastno
- za
- opravlja
- performance
- mogoče
- periodično
- Kraj
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- naseljeno
- Prispevek
- moč
- praksa
- predpogoji
- predstaviti
- primarni
- postopek
- Postopki
- Postopek
- Procesi
- Izdelek
- zagotavljajo
- če
- zagotavlja
- javnega
- objavijo
- namene
- vprašanja
- hitro
- dvigniti
- Surovi
- surovi podatki
- zapis
- evidence
- zmanjša
- besedilu
- odseva
- okolica
- Razmerje
- ostanki
- odstrani
- zamenjajte
- poročilo
- Poročanje
- Poročila
- Zahteve
- viri
- Odgovornost
- vloga
- Roll
- ROW
- Run
- deluje
- prodaja
- prodaja
- Enako
- Vzorčni niz podatkov
- razširljive
- urnik
- razporejanje
- oddelki
- sektor
- varnost
- glej
- ločena
- služi
- Storitev
- Storitve
- sej
- nastavite
- več
- shouldnt
- Prikaži
- Razstave
- Enostavno
- preprostost
- sam
- Počasi
- majhna
- manj
- Posnetek
- So
- prodaja
- Rešitev
- nekaj
- vir
- Viri
- Vesolje
- specialist
- specifična
- posebej
- Stage
- uprizoritev
- zvezda
- začel
- Začetek
- Izjava
- Korak
- Koraki
- shranjevanje
- trgovina
- shranjeni
- strategije
- Strategija
- Struktura
- uspešno
- Uspešno
- taka
- sistem
- miza
- začasna
- deset
- Pogoji
- kot
- da
- O
- Vir
- svet
- njihove
- POTEM
- Tukaj.
- zato
- te
- jih
- ta
- tisoče
- skozi
- Vstopnica
- prodaja vstopnic
- vstopnice
- čas
- krat
- Časovni žig
- nasveti
- do
- danes
- skupaj
- vzel
- Skupaj za plačilo
- sledenje
- transakcija
- Transform
- preoblikovati
- popotnik
- tip
- Vrste
- tipično
- razumevanje
- edinstven
- edinstveno
- Edinstvenost
- neznan
- Nadgradnja
- posodobljeno
- us
- Uporaba
- uporaba
- primeru uporabe
- Rabljeni
- Uporabniki
- uporablja
- uporabo
- navadno
- dragocene
- vrednost
- Vrednote
- različnih
- Kraj
- Prizoriščih
- preko
- Poglej
- Obseg
- walkthrough
- želeli
- Skladišče
- je
- načini
- we
- web
- spletne storitve
- spletne strani
- teden
- kdaj
- ki
- medtem
- bo
- z
- v
- brez
- deluje
- svet
- Napačen
- leto
- let
- jo
- Vaša rutina za
- zefirnet