Slika avtorja
Ko se potopite v svet podatkovne znanosti in strojnega učenja, je ena temeljnih veščin, s katerimi se boste srečali, umetnost branja podatkov. Če imate s tem že nekaj izkušenj, verjetno poznate JSON (JavaScript Object Notation) – priljubljeno obliko za shranjevanje in izmenjavo podatkov.
Pomislite na to, kako zbirke podatkov NoSQL, kot je MongoDB, rade shranjujejo podatke v JSON ali kako se API-ji REST pogosto odzivajo v isti obliki.
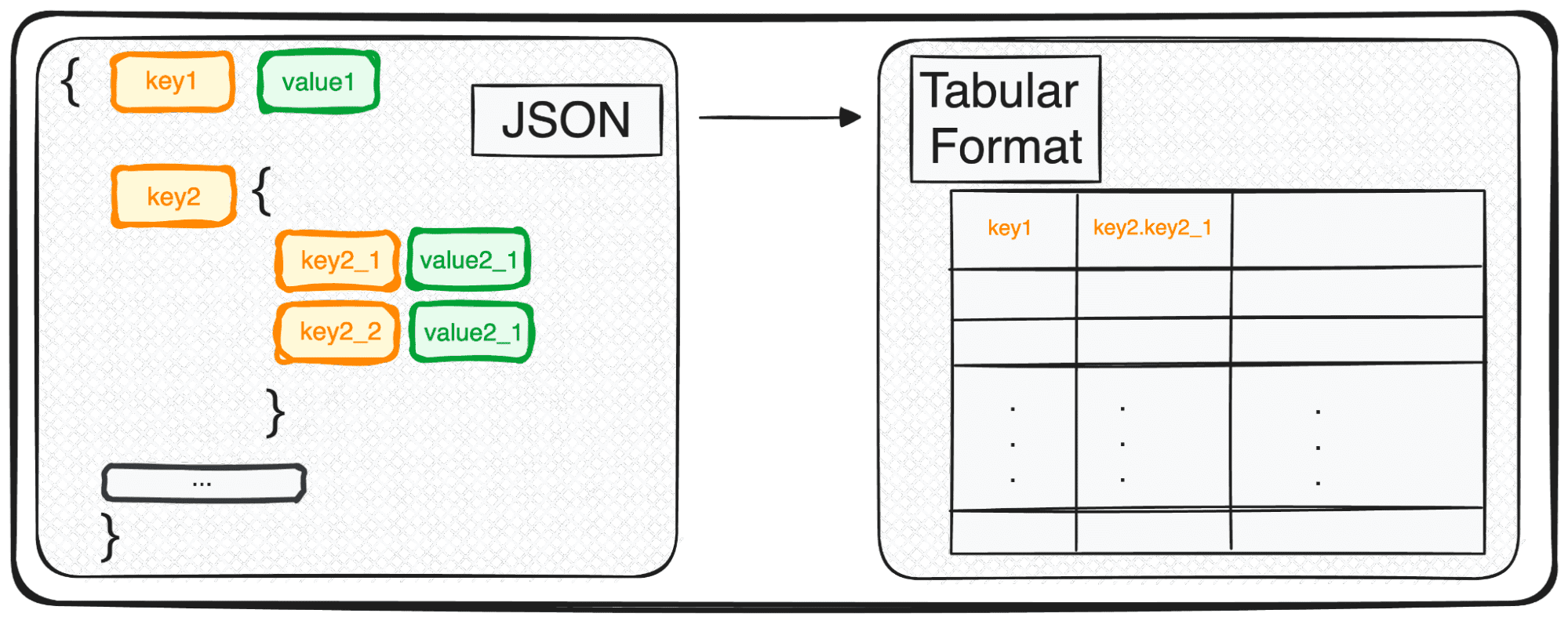
Kljub temu, da je JSON popoln za shranjevanje in izmenjavo, ni povsem pripravljen za poglobljeno analizo v svoji surovi obliki. Tu ga spremenimo v nekaj bolj analitično prijaznega – tabelarično obliko.
Torej, ne glede na to, ali imate opravka z enim samim objektom JSON ali čudovitim nizom le-teh, v smislu Pythona, v bistvu upravljate dikt ali seznam dikt.
Raziščimo skupaj, kako se ta transformacija odvija, zaradi česar so naši podatki zreli za analizo ????
Danes bom razložil čarobni ukaz, ki nam omogoča enostavno razčlenitev katerega koli JSON v obliki tabele v nekaj sekundah.
In je… pd.json_normalize()
Pa poglejmo, kako deluje z različnimi vrstami JSON.
Prva vrsta JSON, s katero lahko delamo, so enonivojski JSON z nekaj ključi in vrednostmi. Naše prve preproste datoteke JSON definiramo takole:
Koda avtorja
Torej simulirajmo potrebo po delu s temi JSON. Vsi vemo, da v njihovem formatu JSON ni veliko za početi. Te datoteke JSON moramo pretvoriti v berljivo in spremenljivo obliko ... kar pomeni Pandas DataFrames!
1.1 Ukvarjanje s preprostimi strukturami JSON
Najprej moramo uvoziti knjižnico pandas in nato lahko uporabimo ukaz pd.json_normalize(), kot sledi:
import pandas as pd
pd.json_normalize(json_string)
Z uporabo tega ukaza za JSON z enim samim zapisom dobimo najbolj osnovno tabelo. Če pa so naši podatki nekoliko bolj zapleteni in predstavljajo seznam JSON, lahko še vedno uporabimo isti ukaz brez nadaljnjih zapletov in izhod bo ustrezal tabeli z več zapisi.

Slika avtorja
Enostavno ... kajne?
Naslednje naravno vprašanje je, kaj se zgodi, ko nekatere vrednosti manjkajo.
1.2 Ravnanje z ničelnimi vrednostmi
Predstavljajte si, da nekatere vrednosti niso obveščene, na primer manjka evidenca o dohodku za Davida. Pri preoblikovanju našega JSON v preprost podatkovni okvir pandas bo ustrezna vrednost prikazana kot NaN.
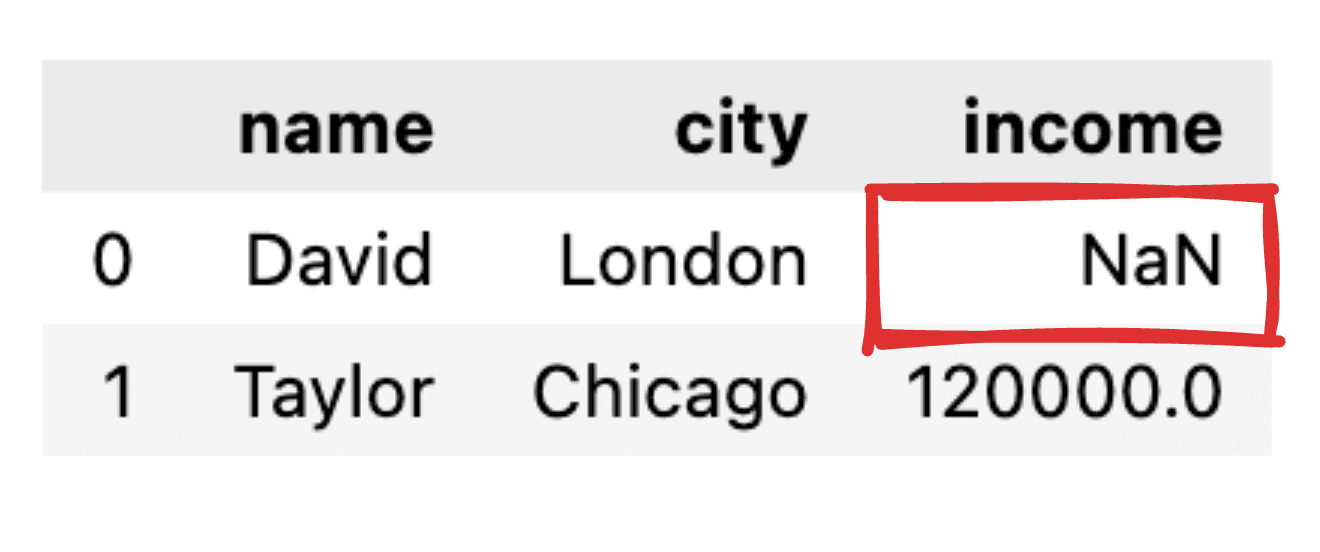
Slika avtorja
Kaj pa, če želim pridobiti samo nekatera polja?
1.3 Izbira samo tistih stolpcev, ki vas zanimajo
V primeru, da želimo samo preoblikovati nekatera specifična polja v tabelarni pandas DataFrame, nam ukaz json_normalize() ne dovoljuje izbire polj za preoblikovanje.
Zato je treba izvesti majhno predhodno obdelavo JSON, kjer filtriramo samo tiste stolpce, ki nas zanimajo.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Torej, pojdimo na naprednejšo strukturo JSON.
Ko imamo opravka z večnivojskimi JSON-i, se znajdemo z ugnezdenimi JSON-ji na različnih ravneh. Postopek je enak kot prej, le da lahko v tem primeru izberemo, koliko nivojev želimo transformirati. Privzeto bo ukaz vedno razširil vse ravni in ustvaril nove stolpce, ki vsebujejo povezana imena vseh ugnezdenih ravni.
Če torej normaliziramo naslednje datoteke JSON.
Koda avtorja
Pod terenskimi veščinami bi dobili naslednjo tabelo s 3 stolpci:
- spretnosti.python
- spretnosti.SQL
- spretnosti.GCP
in 4 stolpce pod vlogami polja
- vloge.vodja projekta
- vloge.podatkovni inženir
- vloge.podatkovni znanstvenik
- vloge.analitik podatkov

Slika avtorja
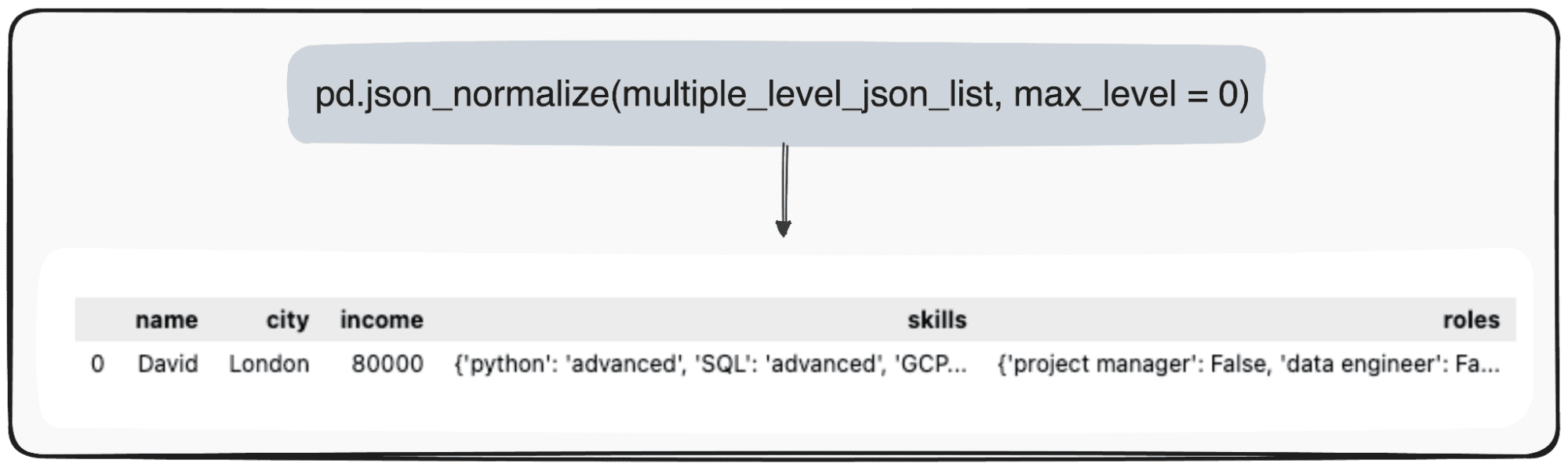
Predstavljajte si, da samo želimo spremeniti svojo najvišjo raven. To lahko storimo tako, da parameter max_level posebej definiramo na 0 (max_level, ki ga želimo razširiti).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
Čakajoče vrednosti bodo ohranjene v JSON-ih v našem pandas DataFrame.
Slika avtorja
Zadnji primer, ki ga lahko najdemo, je ugnezdeni seznam znotraj polja JSON. Zato najprej definiramo naše JSON-e za uporabo.
Koda avtorja
S temi podatki lahko učinkovito upravljamo s Pandas v Pythonu. Funkcija pd.json_normalize() je v tem kontekstu še posebej uporabna. Lahko izravna podatke JSON, vključno z ugnezdenim seznamom, v strukturirano obliko, primerno za analizo. Ko se ta funkcija uporabi za naše podatke JSON, ustvari normalizirano tabelo, ki vključuje ugnezdeni seznam kot del svojih polj.
Poleg tega Pandas ponuja možnost nadaljnjega izboljšanja tega procesa. Z uporabo parametra record_path v pd.json_normalize() lahko usmerimo funkcijo, da specifično normalizira ugnezdeni seznam.
Rezultat tega dejanja je namenska tabela izključno za vsebino seznama. Privzeto bo ta postopek razgrnil le elemente na seznamu. Vendar pa lahko za obogatitev te tabele z dodatnim kontekstom, kot je ohranitev povezanega ID-ja za vsak zapis, uporabimo metaparameter.

Slika avtorja
Če povzamemo, je pretvorba podatkov JSON v datoteke CSV z uporabo Pythonove knjižnice Pandas enostavna in učinkovita.
JSON je še vedno najpogostejši format v sodobnem shranjevanju in izmenjavi podatkov, zlasti v bazah podatkov NoSQL in API-jih REST. Vendar predstavlja nekaj pomembnih analitičnih izzivov pri obravnavi podatkov v neobdelani obliki.
Osrednja vloga Pandas pd.json_normalize() se kaže kot odličen način za obdelavo takšnih formatov in pretvorbo naših podatkov v pandas DataFrame.
Upam, da je bil ta vodnik koristen in ko boste naslednjič imeli opravka z JSON, lahko to storite na bolj učinkovit način.
Preverite lahko ustrezen Jupyter Notebook v po repo GitHub.
Josep Ferrer je inženir analitike iz Barcelone. Diplomiral je iz fizike in trenutno dela na področju Data Science, ki se uporablja za mobilnost ljudi. Je ustvarjalec vsebin s krajšim delovnim časom, osredotočen na podatkovno znanost in tehnologijo. Lahko ga kontaktirate na LinkedIn, Twitter or srednje.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- : je
- :ne
- :kje
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- O meni
- Ukrep
- Dodatne
- napredno
- vsi
- omogočajo
- omogoča
- že
- vedno
- an
- Analiza
- Analitik
- Analitični
- analitika
- in
- kaj
- API-ji
- zdi
- uporabna
- Uporaba
- SE
- Array
- Umetnost
- AS
- povezan
- Barcelona
- Osnovni
- BE
- pred
- Bit
- tako
- vendar
- by
- CAN
- zmožnost
- primeru
- izzivi
- preveriti
- Izberite
- mesto
- Stolpci
- Skupno
- kompleksna
- zaplete
- kontakt
- vsebina
- Vsebina
- ozadje
- pretvorbo
- pretvorbo
- ustreza
- Ustrezno
- kreator
- Trenutno
- datum
- podatkovni analitik
- podatkovni inženir
- znanost o podatkih
- podatkovni znanstvenik
- shranjevanje podatkov
- baze podatkov
- David
- deliti
- namenjen
- privzeto
- opredeliti
- definiranje
- čudovito
- DICT
- drugačen
- neposredna
- do
- ne
- vsak
- enostavno
- lahka
- Učinkovito
- učinkovito
- elementi
- nastane
- srečanje
- inženir
- Inženiring
- obogatiti
- v bistvu
- Izmenjava
- izmenjava
- ekskluzivno
- Razširi
- izkušnje
- pojasnjujejo
- raziskuje
- seznanjeni
- Nekaj
- Polje
- Področja
- datoteke
- filter
- Najdi
- prva
- osredotočena
- po
- sledi
- za
- obrazec
- format
- Prijazno
- iz
- funkcija
- temeljna
- nadalje
- GCP
- ustvarjajo
- dobili
- GitHub
- Go
- veliko
- vodi
- ročaj
- Ravnanje
- se zgodi
- Imajo
- ob
- he
- ga
- upam,
- Kako
- Vendar
- HTTPS
- človeškega
- i
- Bom
- ID
- if
- slika
- uvoz
- Pomembno
- in
- Poglobljena
- vključujejo
- Vključno
- prihodki
- vključuje
- obvestila
- primer
- obresti
- v
- isn
- IT
- ITS
- JavaScript
- json
- Jupyter Notebook
- samo
- KDnuggets
- Ključne
- tipke
- Vedite
- Zadnja
- učenje
- Stopnja
- ravni
- Knjižnica
- kot
- Seznam
- malo
- ll
- ljubezen
- stroj
- strojno učenje
- magic
- vzdrževati
- Izdelava
- upravljanje
- upravitelj
- več
- pomeni
- Meta
- manjka
- mobilnost
- sodobna
- MongoDB
- več
- Najbolj
- premikanje
- veliko
- več
- Ime
- naravna
- Nimate
- ugnezdena
- Novo
- Naslednja
- št
- predvsem
- prenosnik
- predmet
- pridobi
- of
- Ponudbe
- pogosto
- on
- ONE
- samo
- or
- naši
- sami
- izhod
- pand
- parameter
- del
- zlasti
- dokler
- popolna
- opravljeno
- Fizika
- ključno
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Popular
- darila
- verjetno
- postopek
- Postopek
- proizvaja
- Projekt
- Python
- vprašanje
- precej
- Surovi
- RE
- reading
- pripravljen
- zapis
- evidence
- izboljšati
- Odzove
- REST
- Rezultati
- ohranitev
- Pravica
- vloga
- s
- Enako
- Znanost
- Znanost in tehnologija
- Znanstvenik
- sekund
- glej
- izbiranje
- shouldnt
- Enostavno
- simulirati
- sam
- spretnosti
- majhna
- So
- nekaj
- Nekaj
- specifična
- posebej
- SQL
- Še vedno
- shranjevanje
- trgovina
- Struktura
- strukturirano
- taka
- primerna
- POVZETEK
- T
- miza
- Tehnologija
- Pogoji
- da
- O
- svet
- njihove
- Njih
- POTEM
- te
- ta
- tisti,
- čas
- do
- skupaj
- vrh
- Transform
- Preoblikovanje
- preoblikovanje
- tip
- Vrste
- pod
- us
- uporaba
- koristno
- uporabo
- Uporaben
- vrednost
- Vrednote
- želeli
- je
- način..
- we
- Kaj
- kdaj
- ali
- ki
- medtem
- bo
- z
- v
- delo
- deluje
- deluje
- svet
- bi
- jo
- zefirnet