
Slika avtorja
Med analiziranjem podatkov je stvar v našem umu iskanje skritih vzorcev in pridobivanje pomembnih vpogledov. Vstopimo v novo kategorijo učenja, ki temelji na ML, tj. nenadzorovanega učenja, v katerem je eden od močnih algoritmov za reševanje nalog združevanja v gruče algoritem za združevanje v gruče K-Means, ki revolucionira razumevanje podatkov.
K-Means je postal uporaben algoritem v aplikacijah strojnega učenja in podatkovnega rudarjenja. V tem članku se bomo poglobili v delovanje K-Means, njegovo implementacijo s Pythonom in raziskali njegova načela, aplikacije itd. Začnimo torej potovanje, da odklenemo skrivne vzorce in izkoristimo potencial K-Means algoritem združevanja v gruče.
Algoritem K-Means se uporablja za reševanje problemov združevanja v gruče, ki spadajo v razred nenadzorovanega učenja. S pomočjo tega algoritma lahko število opazovanj združimo v K skupin.
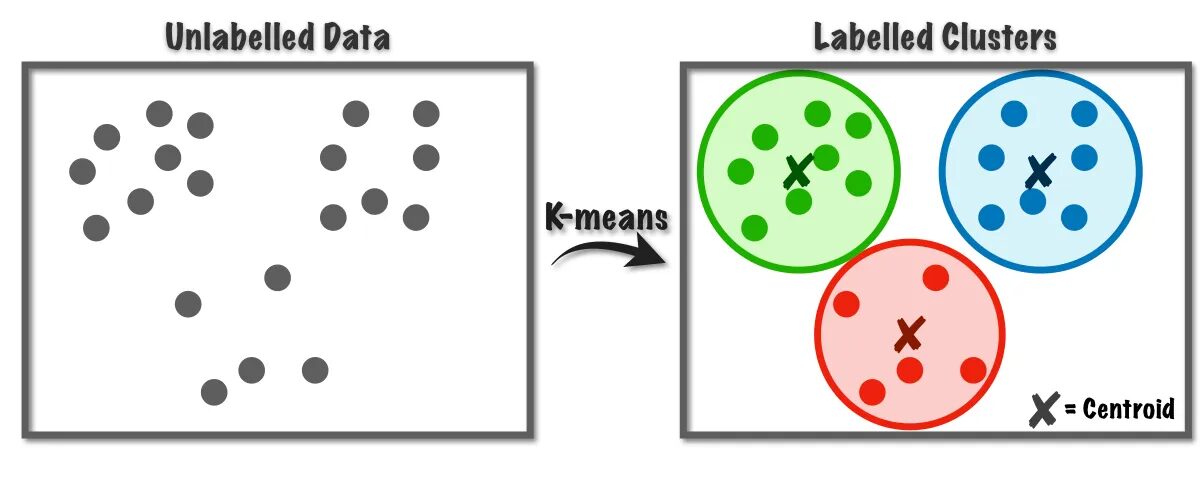
Slika 1 Delovanje algoritma K-Means | Slika iz Proti znanosti o podatkih
Ta algoritem interno uporablja vektorsko kvantizacijo, prek katere lahko vsako opazovanje v naboru podatkov dodelimo gruči z najmanjšo razdaljo, ki je prototip algoritma za gručevanje. Ta algoritem združevanja v gruče se običajno uporablja pri rudarjenju podatkov in strojnem učenju za particioniranje podatkov v K gruč na podlagi meritev podobnosti. Zato moramo v tem algoritmu minimizirati vsoto kvadratov razdalje med opazovanji in njihovimi ustreznimi centroidi, kar na koncu povzroči različne in homogene grozde.
Aplikacije združevanja v gruče K-means
Tukaj je nekaj standardnih aplikacij tega algoritma. Algoritem K-means je pogosto uporabljena tehnika v primerih industrijske uporabe za reševanje problemov, povezanih z združevanjem v gruče.
- Segmentacija strank: K-means grozdenja lahko segmentira različne stranke glede na njihove interese. Uporablja se lahko za bančništvo, telekomunikacije, e-trgovino, šport, oglaševanje, prodajo itd.
- Združevanje dokumentov v gruče: Pri tej tehniki bomo podobne dokumente združili iz nabora dokumentov, kar bo imelo za posledico podobne dokumente v istih gručah.
- Priporočila motorjev: Včasih se lahko združevanje v skupine K-means uporabi za ustvarjanje sistemov priporočil. Na primer, želite priporočiti pesmi svojim prijateljem. Ogledate si lahko pesmi, ki so bile tej osebi všeč, nato pa z združevanjem v skupine poiščete podobne pesmi in priporočite najbolj podobne.
Obstaja veliko drugih aplikacij, za katere sem prepričan, da ste že pomislili in jih verjetno delite v razdelku s komentarji pod tem člankom.
V tem razdelku bomo začeli izvajati algoritem K-Means na enem od naborov podatkov z uporabo Pythona, ki se večinoma uporablja v projektih Data Science.
1. Uvozite potrebne knjižnice in odvisnosti
Najprej uvozimo knjižnice python, ki jih uporabljamo za implementacijo algoritma K-means, vključno z NumPy, Pandas, Seaborn, Marplotlib itd.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. Naložite in analizirajte nabor podatkov
V tem koraku bomo naložili nabor podatkov študentov tako, da jih shranimo v podatkovni okvir Pandas. Za prenos nabora podatkov se lahko obrnete na povezavo tukaj.
Celoten cevovod težave je prikazan spodaj:

Slika 2 Projektni načrt | Slika avtorja
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. Raztreseni grafikon nabora podatkov
Zdaj sledi korak modeliranja, ki je vizualizacija podatkov, zato uporabimo matplotlib za risanje razpršenega grafa, da preverimo, kako deluje algoritem združevanja v gruče in ustvarimo različne gruče.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
izhod:
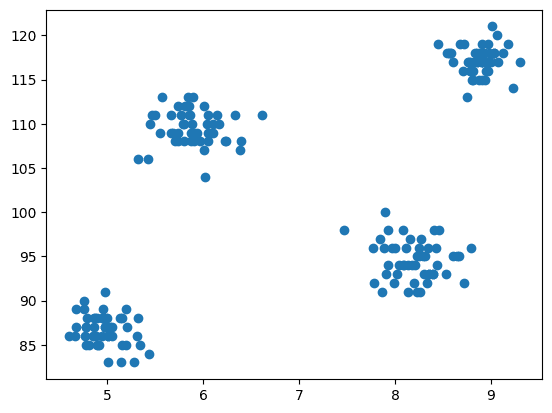
Slika 3 Raztreseni grafikon | Slika avtorja
4. Uvozite K-means iz razreda gruče Scikit-learn
Zdaj, ko moramo implementirati združevanje v gruče K-Means, najprej uvozimo razred gruče, nato pa imamo KMeans kot modul tega razreda.
from sklearn.cluster import KMeans5. Iskanje optimalne vrednosti K z uporabo metode komolca
V tem koraku bomo med izvajanjem algoritma našli optimalno vrednost K, enega od hiperparametrov. Vrednost K označuje, koliko gruč moramo ustvariti za naš nabor podatkov. Intuitivno iskanje te vrednosti ni mogoče, zato bomo za iskanje optimalne vrednosti ustvarili graf med WCSS(znotraj gruče-vsota-kvadratov) in različnimi K-vrednostmi, pri čemer moramo izbrati tisti K, ki nam daje minimalno vrednost WCSS.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
Zdaj pa narišimo komolec, da poiščemo optimalno vrednost K.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
izhod:
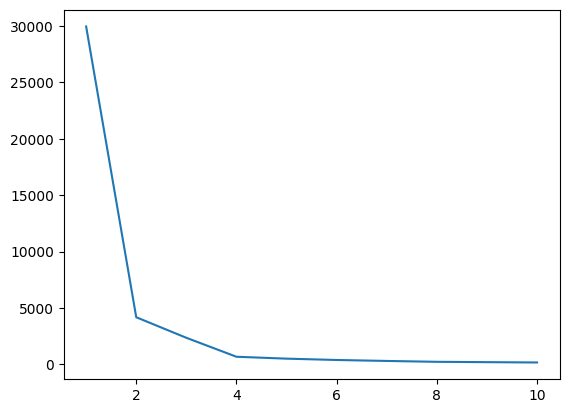
Slika 4 Komolec | Slika avtorja
Iz zgornjega komolca lahko vidimo pri K=4; obstaja padec vrednosti WCSS, kar pomeni, da če uporabimo optimalno vrednost kot 4, vam bo v tem primeru združevanje v gruče zagotovilo dobro zmogljivost.
6. Prilagodite algoritem K-Means z optimalno vrednostjo K
Končali smo z iskanjem optimalne vrednosti K. Zdaj pa izvedimo modeliranje, kjer bomo ustvarili matriko X, ki bo shranila celoten nabor podatkov z vsemi funkcijami. Tu ni potrebe po ločevanju ciljnega in značilnega vektorja, saj gre za nenadzorovan problem. Po tem bomo ustvarili objekt razreda KMeans z izbrano vrednostjo K in ga nato prilagodili ponujenemu naboru podatkov. Na koncu natisnemo y_means, ki označuje povprečja različnih oblikovanih grozdov.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. Preverite dodelitev gruče vsake kategorije
Preverimo, katere vse točke v naboru podatkov pripadajo kateremu grozdu.
X[y_means == 3,1]
Do zdaj smo za inicializacijo centroidov uporabljali strategijo K-Means++, zdaj pa inicializirajmo naključne centroide namesto K-Means++ in primerjajmo rezultate po istem postopku.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Preverite, koliko vrednosti se ujemajo.
sum(y_means == y_means_new)8. Vizualizacija grozdov
Za vizualizacijo vsakega grozda jih narišemo na osi in jim dodelimo različne barve, skozi katere zlahka vidimo nastale 4 grozde.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
izhod:
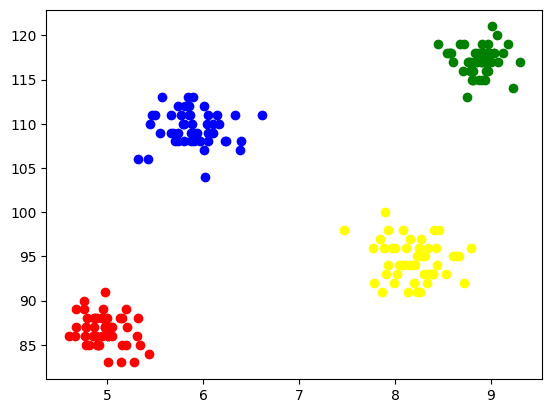
Slika 5 Vizualizacija oblikovanih grozdov | Slika avtorja
9. K-sredstva za 3D-podatke
Ker ima prejšnji nabor podatkov 2 stolpca, imamo 2-D problem. Zdaj bomo uporabili isti nabor korakov za 3-D problem in poskušali analizirati ponovljivost kode za n-dimenzionalne podatke.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
izhod:
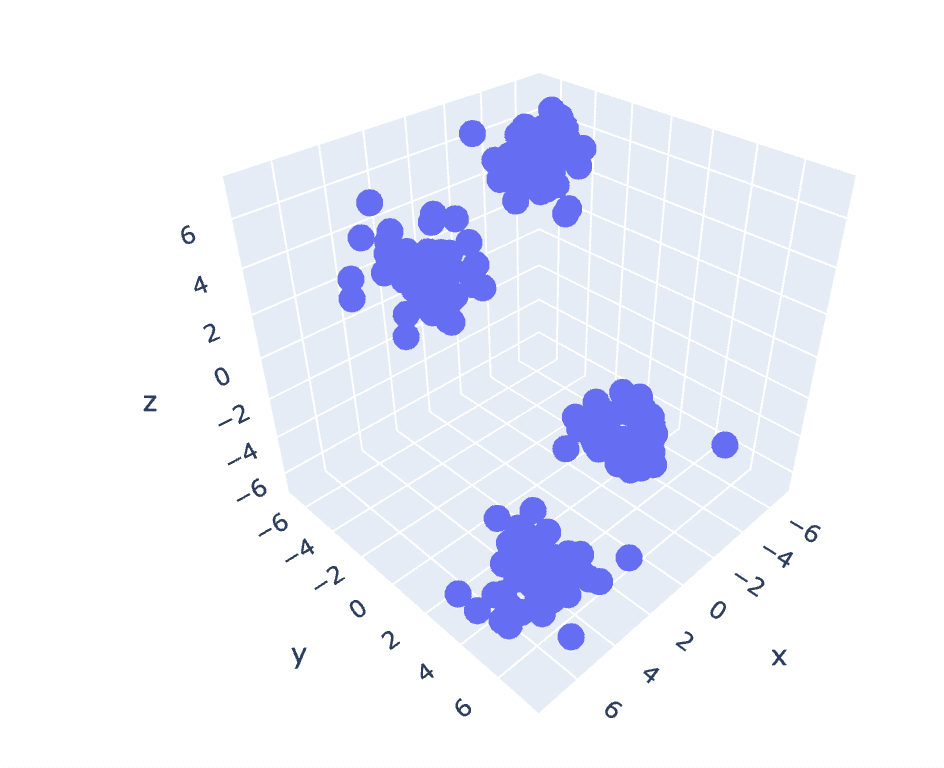
Slika 6 Raztreseni grafikon nabora 3-D podatkov | Slika avtorja
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
izhod:

Slika 7 Komolec | Slika avtorja
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
izhod:
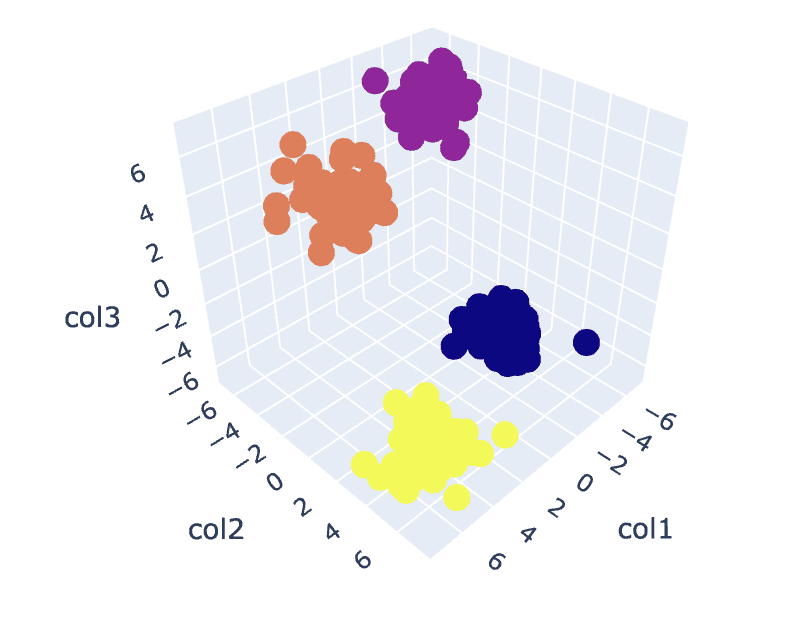
Slika 8. Vizualizacija grozdov | Slika avtorja
Celotno kodo najdete tukaj – Beležnica Colab
S tem je naša razprava zaključena. Razpravljali smo o delovanju, izvedbi in aplikacijah K-Means. Skratka, izvajanje nalog združevanja v gruče je pogosto uporabljen algoritem iz razreda nenadzorovanega učenja, ki zagotavlja preprost in intuitiven pristop k združevanju opazovanj nabora podatkov. Glavna moč tega algoritma je razdelitev opazovanj v več nizov na podlagi izbranih metrik podobnosti s pomočjo uporabnika, ki implementira algoritem.
Vendar pa se naš algoritem na podlagi izbire centroidov v prvem koraku obnaša drugače in konvergira k lokalnim ali globalnim optimumom. Zato je izbira števila gruč za implementacijo algoritma, predhodna obdelava podatkov, ravnanje z odstopanji itd. ključnega pomena za doseganje dobrih rezultatov. Toda če opazujemo drugo stran tega algoritma za omejitvami, je K-Means koristna tehnika za raziskovalno analizo podatkov in prepoznavanje vzorcev na različnih področjih.
Aryan Garg je B.Tech. Študent elektrotehnike, trenutno v zadnjem letniku dodiplomskega študija. Njegovo zanimanje je področje spletnega razvoja in strojnega učenja. Zasledoval je to zanimanje in si želi še več delati v teh smereh.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Avtomobili/EV, Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- BlockOffsets. Posodobitev okoljskega offset lastništva. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :ima
- : je
- :ne
- :kje
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- nad
- Oglaševanje
- po
- algoritem
- algoritmi
- vsi
- že
- am
- an
- analizirati
- Analiza
- analizirati
- analiziranje
- in
- aplikacije
- uporabna
- pristop
- SE
- Array
- članek
- AS
- At
- OSI
- b
- Bančništvo
- temeljijo
- BE
- postanejo
- zadaj
- spodaj
- med
- Modra
- Building
- vendar
- by
- CAN
- primeru
- primeri
- Kategorija
- preveriti
- Izberite
- razred
- klub
- Grozd
- grozdenje
- Koda
- Stolpci
- prihaja
- komentarji
- pogosto
- primerjate
- dokončanje
- Zaključi
- Sklenitev
- Ustrezno
- ustvarjajo
- ključnega pomena
- Trenutno
- stranka
- Stranke, ki so
- datum
- Analiza podatkov
- rudarjenje podatkov
- znanost o podatkih
- nabor podatkov
- globoko
- globok potop
- Razvoj
- drugačen
- Potopite
- Smeri
- razpravljali
- Razprava
- razdalja
- izrazit
- do
- dokument
- Dokumenti
- opravljeno
- prenesi
- pripravi
- e
- e-trgovina
- vsak
- željni
- enostavno
- elektrotehnike
- Inženiring
- Motorji
- Vnesite
- itd
- sčasoma
- Primer
- Raziskovalne analize podatkov
- Raziskovati
- express
- ekstrakt
- Feature
- Lastnosti
- Polje
- Področja
- Slika
- končna
- končno
- Najdi
- iskanje
- prva
- fit
- po
- za
- oblikovana
- prijatelji
- iz
- Daj
- daje
- Globalno
- dogaja
- dobro
- Zelen
- skupina
- Ravnanje
- plezalni pas
- Imajo
- ob
- he
- pomoč
- pomoč
- tukaj
- skrita
- njegov
- Kako
- HTTPS
- i
- if
- slika
- izvajati
- Izvajanje
- izvajanja
- uvoz
- in
- Vključno
- označuje
- industrijske
- vztrajnost
- vpogledi
- Namesto
- obresti
- interesi
- interno
- v
- intuitivno
- IT
- ITS
- Potovanje
- jpg
- KDnuggets
- label
- učenje
- knjižnice
- Leži
- omejitve
- LINK
- Seznam
- obremenitev
- lokalna
- Poglej
- stroj
- strojno učenje
- Glavne
- v glavnem
- Znamka
- več
- Stave
- matplotlib
- smiselna
- pomeni
- Meritve
- moti
- minimalna
- Rudarstvo
- Model
- modeliranje
- modul
- več
- Najbolj
- več
- morajo
- potrebno
- Nimate
- Novo
- št
- zdaj
- Številka
- otopeli
- predmet
- opazujejo
- pridobi
- of
- on
- ONE
- tiste
- optimalna
- or
- Ostalo
- naši
- pand
- mimo
- Vzorec
- vzorci
- performance
- oseba
- plinovod
- platon
- Platonova podatkovna inteligenca
- PlatoData
- točke
- mogoče
- potencial
- močan
- prejšnja
- Načela
- Tiskanje
- verjetno
- problem
- Težave
- Postopek
- Projekt
- projekti
- Prototip
- če
- zagotavlja
- Python
- naključno
- Priznanje
- Priporočamo
- Priporočilo
- Rdeča
- Raziskave
- rezultat
- Rezultati
- revolucionira
- s
- prodaja
- Enako
- Znanost
- morski rojen
- skrivnost
- Oddelek
- glej
- Segment
- segmentacija
- izbran
- izbiranje
- izbor
- ločena
- nastavite
- Kompleti
- Oblikujte
- Delite s prijatelji, znanci, družino in partnerji :-)
- pokazale
- strani
- pomeni
- Podoben
- Enostavno
- So
- SOLVE
- Reševanje
- nekaj
- Šport
- kvadratov
- standardna
- Začetek
- Korak
- Koraki
- trgovina
- trgovine
- Strategija
- moč
- študent
- Preverite
- sintetična
- sistemi
- ciljna
- Naloge
- tech
- telecom
- da
- O
- njihove
- Njih
- POTEM
- Tukaj.
- zato
- te
- stvar
- ta
- mislil
- skozi
- do
- poskusite
- razumevanje
- sproščeno
- odklepanje
- nenadzorovano učenje
- us
- uporaba
- Rabljeni
- uporabnik
- uporablja
- uporabo
- uporabiti
- vrednost
- Vrednote
- različnih
- vizualizacija
- vs
- želeli
- we
- web
- Izdelava spletnih strani
- ki
- medtem
- WHO
- pogosto
- bo
- z
- delo
- deluje
- dela
- deluje
- X
- leto
- rumene
- jo
- Vaša rutina za
- zefirnet








