Predstavitev
V današnjem hitrem tempu je storitev za stranke ključni vidik vsakega podjetja. Zendesk Answer Bot, ki ga poganjajo veliki jezikovni modeli (LLM), kot je GPT-4, lahko znatno poveča učinkovitost in kakovost podpore strankam z avtomatizacijo odgovorov. Ta objava v spletnem dnevniku vas bo vodila skozi gradnjo in uvajanje lastnega samodejnega odzivnika Zendesk z uporabo LLM-jev in implementacijo delovnih tokov, ki temeljijo na RAG, v GenAI za racionalizacijo postopka.

Kaj so delovni tokovi, ki temeljijo na RAG, v GenAI
Poteki dela, ki temeljijo na RAG (Retrieval Augmented Generation), v GenAI (Generative AI) združujejo prednosti pridobivanja in generiranja za izboljšanje zmogljivosti sistema AI, zlasti pri obdelavi podatkov iz resničnega sveta, specifičnih za domeno. Preprosto povedano, RAG omogoča umetni inteligenci, da pridobi ustrezne informacije iz baze podatkov ali drugih virov za podporo ustvarjanju natančnejših in informiranih odgovorov. To je še posebej koristno v poslovnih okoljih, kjer sta natančnost in kontekst ključnega pomena.
Katere so komponente v delovnem toku, ki temelji na RAG
- Baza znanja: Baza znanja je centralizirano skladišče informacij, na katere se sistem sklicuje, ko odgovarja na poizvedbe. Vključuje lahko pogosta vprašanja, priročnike in druge ustrezne dokumente.
- Sprožilec/poizvedba: Ta komponenta je odgovorna za začetek poteka dela. Običajno gre za vprašanje ali zahtevo stranke, ki potrebuje odgovor ali dejanje.
- Naloga/ukrep: Na podlagi analize sprožilca/poizvedbe sistem izvede določeno nalogo ali dejanje, kot je generiranje odgovora ali izvajanje zaledne operacije.
Nekaj primerov delovnih tokov, ki temeljijo na RAG
- Delovni tok interakcije s strankami v bančništvu:
- Klepetalni roboti, ki jih poganjata GenAI in RAG, lahko s personalizacijo interakcij znatno izboljšajo stopnjo angažiranosti v bančni industriji.
- Prek RAG lahko klepetalni roboti pridobijo in uporabijo ustrezne informacije iz baze podatkov za ustvarjanje prilagojenih odgovorov na vprašanja strank.
- Na primer, med sejo klepeta bi sistem GenAI, ki temelji na RAG, lahko pridobil strankino zgodovino transakcij ali podatke o računu iz zbirke podatkov, da bi zagotovil bolj informirane in prilagojene odgovore.
- Ta potek dela ne le poveča zadovoljstvo strank, ampak tudi potencialno poveča stopnjo zadrževanja z zagotavljanjem bolj prilagojene in informativne izkušnje interakcije.
- Potek dela e-poštnih kampanj:
- Pri trženju in prodaji je ustvarjanje ciljanih kampanj ključnega pomena.
- RAG se lahko uporabi za zbiranje najnovejših informacij o izdelkih, povratnih informacij strank ali tržnih trendov iz zunanjih virov, da bi pomagal ustvariti bolj ozaveščeno in učinkovito marketinško/prodajno gradivo.
- Na primer, pri izdelavi e-poštne kampanje bi potek dela, ki temelji na RAG, lahko pridobil nedavne pozitivne ocene ali nove funkcije izdelka za vključitev v vsebino kampanje, s čimer bi potencialno izboljšal stopnjo angažiranosti in prodajne rezultate.
- Avtomatizirano dokumentiranje kode in potek dela za spreminjanje:
- Na začetku lahko sistem RAG potegne obstoječo kodno dokumentacijo, zbirko kod in standarde kodiranja iz repozitorija projekta.
- Ko mora razvijalec dodati novo funkcijo, lahko RAG ustvari delček kode v skladu s standardi kodiranja projekta s sklicevanjem na pridobljene informacije.
- Če je potrebna sprememba kode, lahko sistem RAG predlaga spremembe z analizo obstoječe kode in dokumentacije, s čimer zagotovi doslednost in upoštevanje standardov kodiranja.
- S spremembo ali dodajanjem poštne kode lahko RAG samodejno posodobi dokumentacijo kode, da odraža spremembe, pri čemer pridobi potrebne informacije iz baze kode in obstoječe dokumentacije.
Kako prenesti in indeksirati vse vstopnice Zendesk za iskanje
Začnimo zdaj z vadnico. Izdelali bomo bota, ki bo odgovarjal na dohodne vstopnice Zendesk, medtem ko bomo uporabljali zbirko podatkov po meri preteklih vstopnic in odgovorov Zendesk za ustvarjanje odgovora s pomočjo LLM-jev.
- API za dostop do Zendesk: Uporabite Zendesk API za dostop in prenos vseh vstopnic. Prepričajte se, da imate potrebna dovoljenja in ključe API za dostop do podatkov.
Najprej ustvarimo ključ Zendesk API. Prepričajte se, da ste skrbnik in obiščite naslednjo povezavo, da ustvarite ključ API – https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/apis/zendesk-api/settings/tokens
Ustvarite ključ API in ga kopirajte v odložišče.

Začnimo zdaj z zvezkom Python.
Vnesemo naše poverilnice Zendesk, vključno s ključem API, ki smo ga pravkar pridobili.
subdomain = YOUR_SUBDOMAIN
username = ZENDESK_USERNAME
password = ZENDESK_API_KEY
username = '{}/token'.format(username)Zdaj pridobimo podatke o vstopnici. V spodnji kodi smo pridobili poizvedbe in odgovore iz vsake vstopnice in shranjujemo vsak niz [poizvedba, polje odgovorov], ki predstavlja vstopnico, v matriko, imenovano podatki o vstopnici.
Pridobivamo samo zadnjih 1000 vstopnic. To lahko po potrebi spremenite.
import requests ticketdata = []
url = f"https://{subdomain}.zendesk.com/api/v2/tickets.json" params = {"sort_by": "created_at", "sort_order": "desc"} headers = {"Content-Type": "application/json"} tickettext = "" while len(ticketdata) <= 1000: response = requests.get( url, auth=(username, password), params=params, headers=headers ) tickets = response.json()["tickets"] for ticket in tickets: ticketid = ticket["id"] url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticketid}/comments.json" headers = { "Content-Type": "application/json", } response2 = requests.get(url, auth=(username, password), headers=headers) try: comments = response2.json()["comments"] except: comments = ["", ""] ticketelement = [ticketid, comments] ticketdata.append(ticketelement) if response.json()["next_page"]: url = response.json()["next_page"] else: breakKot lahko vidite spodaj, smo podatke o vozovnicah pridobili iz Zendesk db. Vsak element v podatki o vstopnici vsebuje –
a. ID vstopnice
b. Vsi komentarji / odgovori v vstopnici.
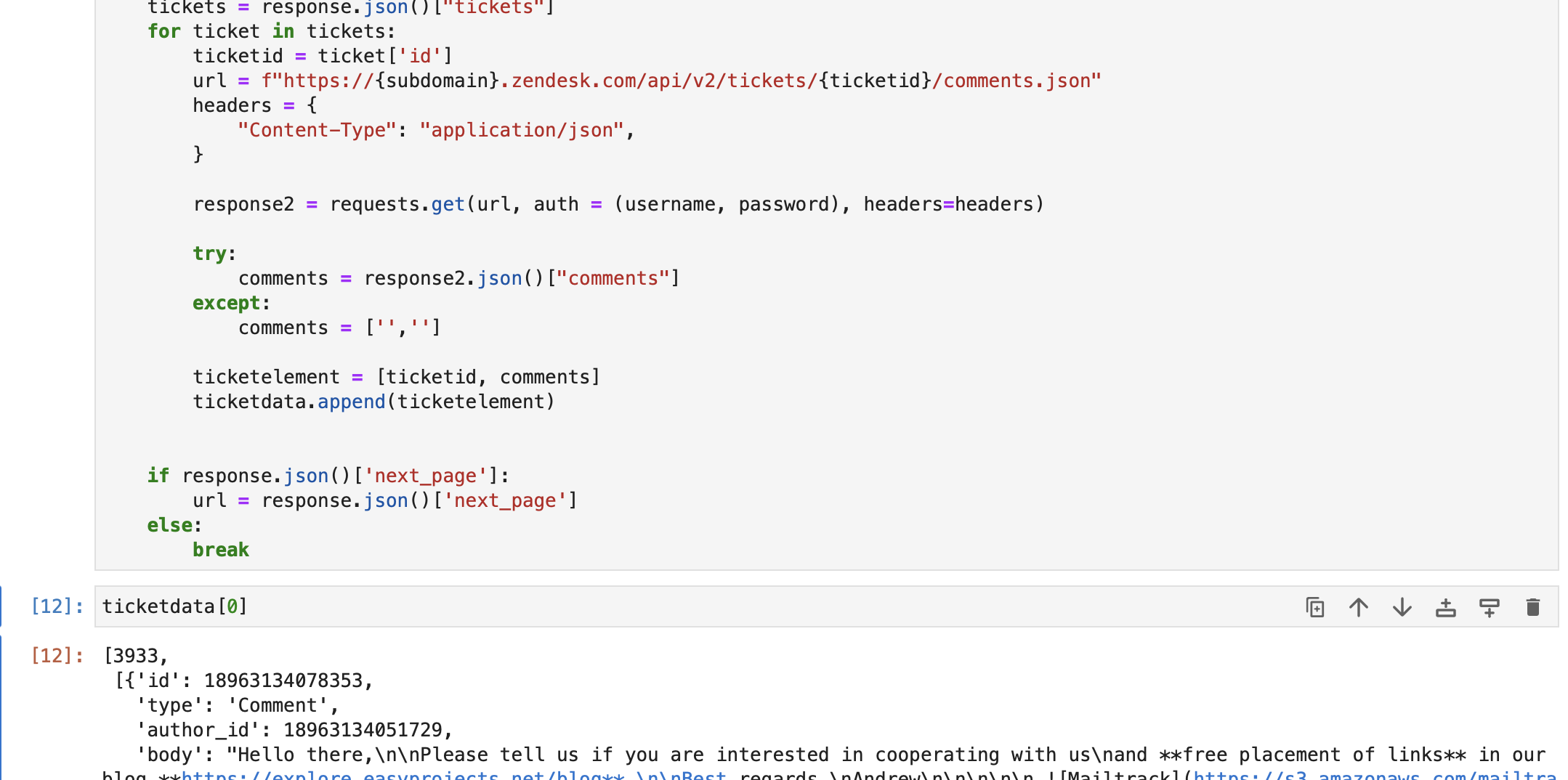
Nato z uporabo podatki o vstopnici matrika.
for ticket in ticketdata: try: text = ( "nnn" + "Question - " + ticket[1][0]["body"] + "n" + "Answer - " + ticket[1][1]["body"] ) tickettext = tickettext + text except: passO besedilo vstopnice niz zdaj vsebuje vse zahteve in prve odgovore, pri čemer so podatki vsake kartice ločeni z znaki za novo vrstico.

Neobvezno : Podatke lahko pridobite tudi iz svojih člankov o podpori Zendesk, da še razširite bazo znanja, tako da zaženete spodnjo kodo.
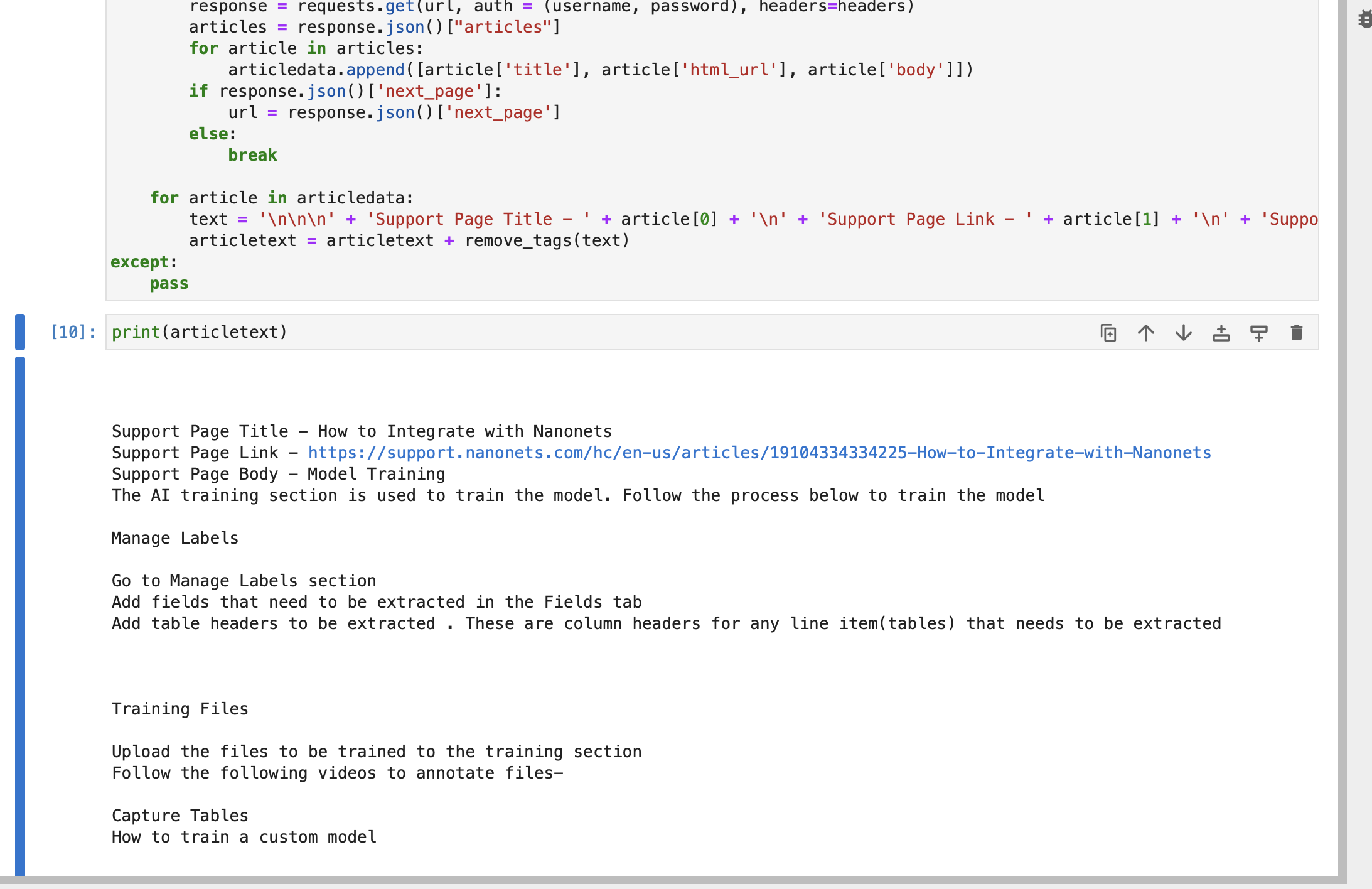
import re def remove_tags(text): clean = re.compile("<.*?>") return re.sub(clean, "", text) articletext = ""
try: articledata = [] url = f"https://{subdomain}.zendesk.com/api/v2/help_center/en-us/articles.json" headers = {"Content-Type": "application/json"} while True: response = requests.get(url, auth=(username, password), headers=headers) articles = response.json()["articles"] for article in articles: articledata.append([article["title"], article["html_url"], article["body"]]) if response.json()["next_page"]: url = response.json()["next_page"] else: break for article in articledata: text = ( "nnn" + "Support Page Title - " + article[0] + "n" + "Support Page Link - " + article[1] + "n" + "Support Page Body - " + article[2] ) articletext = articletext + remove_tags(text)
except: passNiz besedilo članka vsebuje naslov, povezavo in telo vsakega članka, ki je del vaših strani za podporo Zendesk.
neobvezno : lahko povežete svojo bazo podatkov o strankah ali katero koli drugo ustrezno bazo podatkov in jo nato uporabite med ustvarjanjem indeksne shrambe.
Združi pridobljene podatke.
knowledge = tickettext + "nnn" + articletext- Indeksne vstopnice: Ko jih prenesete, jih indeksirajte z ustrezno metodo indeksiranja, da olajšate hitro in učinkovito iskanje.
Da bi to naredili, najprej namestimo odvisnosti, potrebne za ustvarjanje vektorske shrambe.
pip install langchain openai pypdf faiss-cpuUstvarite indeksno shrambo z uporabo pridobljenih podatkov. To bo delovalo kot naša baza znanja, ko bomo poskušali odgovoriti na nove zahteve prek GPT.
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY" from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np tokenizer = GPT2TokenizerFast.from_pretrained("gpt2") def count_tokens(text: str) -> int: return len(tokenizer.encode(text)) text_splitter = RecursiveCharacterTextSplitter( chunk_size=512, chunk_overlap=24, length_function=count_tokens,
) chunks = text_splitter.create_documents([knowledge]) token_counts = [count_tokens(chunk.page_content) for chunk in chunks]
df = pd.DataFrame({"Token Count": token_counts})
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(chunks, embeddings)
path = "zendesk-index"
db.save_local(path)
Vaš indeks se shrani v vaš lokalni sistem.

- Indeks redno posodabljajte: Indeks redno posodabljajte, da bo vključeval nove vstopnice in spremembe obstoječih, s čimer zagotovite, da ima sistem dostop do najnovejših podatkov.
Zgornji skript lahko načrtujemo za izvajanje vsak teden in posodobimo naš 'zendesk-index' ali katero koli drugo želeno pogostost.
Kako izvesti iskanje, ko pride nova vozovnica
- Monitor za nove vstopnice: Nastavite sistem za stalno spremljanje Zendeska glede novih vstopnic.
Ustvarili bomo osnovni Flask API in ga gostili. Za začetek,
- Ustvarite novo mapo z imenom 'Zendesk Answer Bot'.
- Dodajte mapo FAISS db 'zendesk-index' v mapo 'Zendesk Answer Bot'.
- Ustvarite novo datoteko python zendesk.py in vanjo kopirajte spodnjo kodo.
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): return 'dummy response' if __name__ == '__main__': app.run(port=3001, debug=True)- Zaženite kodo python.

- Prenesite in konfigurirajte ngrok z uporabo tukajšnjih navodil. Prepričajte se, da ste konfigurirali ngrok authtoken v vašem terminalu, kot je navedeno na povezavi.
- Odprite nov primerek terminala in zaženite spodnji ukaz.
ngrok http 3001- Zdaj imamo našo storitev Flask izpostavljeno prek zunanjega IP-ja, prek katerega lahko kličemo API naši storitvi od koder koli.

- Nato smo nastavili Zendesk Webhook tako, da bodisi obiščemo naslednjo povezavo – https://YOUR_SUBDOMAIN.zendesk.com/admin/apps-integrations/webhooks/webhooks ALI neposredno zaženemo spodnjo kodo v našem originalnem prenosnem računalniku Jupyter.
OPOMBA: Pomembno je omeniti, da je uporaba ngrok dobra za namene testiranja, vendar je zelo priporočljivo, da storitev Flask API premaknete na primerek strežnika. V tem primeru postane statični IP strežnika končna točka Zendesk Webhook in končno točko v svojem Zendesk Webhook boste morali konfigurirati tako, da kaže na ta naslov – https://YOUR_SERVER_STATIC_IP:3001/zendesk
zendesk_workflow_endpoint = "HTTPS_NGROK_FORWARDING_ADDRESS" url = "https://" + subdomain + ".zendesk.com/api/v2/webhooks"
payload = { "webhook": { "endpoint": zendesk_workflow_endpoint, "http_method": "POST", "name": "Nanonets Workflows Webhook v1", "status": "active", "request_format": "json", "subscriptions": ["conditional_ticket_events"], }
}
headers = {"Content-Type": "application/json"} auth = (username, password) response = requests.post(url, json=payload, headers=headers, auth=auth)
webhook = response.json() webhookid = webhook["webhook"]["id"]
- Zdaj smo nastavili sprožilec Zendesk, ki bo sprožil zgornji webhook, ki smo ga pravkar ustvarili, da se zažene vsakič, ko se pojavi nova vstopnica. Sprožilec Zendesk lahko nastavimo tako, da obiščemo naslednjo povezavo – https://YOUR_SUBDOMAIN.zendesk.com/admin/objects-rules/rules/triggers ALI tako, da neposredno zaženemo spodnjo kodo v našem izvirnem Jupyterjevem zvezku.
url = "https://" + subdomain + ".zendesk.com/api/v2/triggers.json" trigger_payload = { "trigger": { "title": "Nanonets Workflows Trigger v1", "active": True, "conditions": {"all": [{"field": "update_type", "value": "Create"}]}, "actions": [ { "field": "notification_webhook", "value": [ webhookid, json.dumps( { "ticket_id": "{{ticket.id}}", "org_id": "{{ticket.url}}", "subject": "{{ticket.title}}", "body": "{{ticket.description}}", } ), ], } ], }
} response = requests.post(url, auth=(username, password), json=trigger_payload)
trigger = response.json()
- Pridobite ustrezne informacije: Ko pride nova prijava, uporabite indeksirano bazo znanja, da pridobite ustrezne informacije in pretekle prijave, ki lahko pomagajo pri ustvarjanju odgovora.
Ko sta sprožilec in webhook nastavljena, bo Zendesk zagotovil, da bo naša trenutno delujoča storitev Flask prejela klic API na poti /zendesk z ID-jem vstopnice, zadevo in telesom, kadar koli prispe nova vstopnica.
Zdaj moramo konfigurirati našo storitev Flask za
a. ustvarite odgovor z uporabo naše vektorske shrambe 'zendesk-index'.
b. posodobi vstopnico z ustvarjenim odgovorom.
Našo trenutno servisno kodo bučke v zendesk.py zamenjamo s spodnjo kodo –
from flask import Flask, request, jsonify
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from transformers import GPT2TokenizerFast
import os
import pandas as pd
import numpy as np app = Flask(__name__) @app.route('/zendesk', methods=['POST'])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson['body'] zendb = FAISS.load_local('zendesk-index', zenembeddings) docs = zendb.similarity_search(query) if __name__ == '__main__': app.run(port=3001, debug=True)Kot lahko vidite, smo izvedli iskanje podobnosti na našem vektorskem indeksu in pridobili najbolj ustrezne vstopnice in članke, da bi pomagali ustvariti odgovor.
Kako ustvariti odgovor in objaviti na Zendesku
- Ustvari odgovor: Uporabite LLM za ustvarjanje skladnega in natančnega odgovora na podlagi pridobljenih informacij in analiziranega konteksta.
Nadaljujmo z nastavitvijo naše končne točke API. Nadalje spreminjamo kodo, kot je prikazano spodaj, da ustvarimo odgovor na podlagi ustreznih pridobljenih informacij.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query)
O odgovor spremenljivka bo vsebovala ustvarjen odgovor.
- Odgovor na pregled: Po želji naj človeški agent pred objavo pregleda ustvarjeni odgovor glede točnosti in ustreznosti.
To zagotavljamo tako, da odgovora, ki ga ustvari GPT, NE objavimo neposredno kot odgovor Zendesk. Namesto tega bomo ustvarili funkcijo za posodobitev novih vstopnic z notranjo opombo, ki bo vsebovala odgovor, ustvarjen GPT.
Storitvi bučke zendesk.py dodajte naslednjo funkcijo –
def update_ticket_with_internal_note( subdomain, ticket_id, username, password, comment_body
): url = f"https://{subdomain}.zendesk.com/api/v2/tickets/{ticket_id}.json" email = username headers = {"Content-Type": "application/json"} comment_body = "Suggested Response - " + comment_body data = {"ticket": {"comment": {"body": comment_body, "public": False}}} response = requests.put(url, json=data, headers=headers, auth=(email, password))
- Objavi v Zendesku: Uporabite Zendesk API za objavo ustvarjenega odgovora na ustrezno vstopnico, kar zagotavlja pravočasno komunikacijo s stranko.
V našo končno točko API-ja zdaj vključimo notranjo funkcijo za ustvarjanje zapiskov.
@app.route("/zendesk", methods=["POST"])
def zendesk(): updatedticketjson = request.get_json() zenembeddings = OpenAIEmbeddings() query = updatedticketjson["body"] zendb = FAISS.load_local("zendesk-index", zenembeddings) docs = zendb.similarity_search(query) zenchain = load_qa_chain(OpenAI(temperature=0.7), chain_type="stuff") answer = zenchain.run(input_documents=docs, question=query) update_ticket_with_internal_note(subdomain, ticket, username, password, answer) return answer
S tem je naš potek dela zaključen!
Popravimo potek dela, ki smo ga vzpostavili –
- Naš Zendesk Trigger začne potek dela, ko se pojavi nova vstopnica Zendesk.
- Sprožilec pošlje podatke o novi vstopnici v naš Webhook.
- Naš Webhook pošlje zahtevo naši storitvi Flask.
- Naša storitev Flask poizveduje v vektorski shrambi, ustvarjeni s preteklimi podatki Zendeska, da pridobi ustrezne pretekle vstopnice in članke za odgovor na novo vstopnico.
- Ustrezne pretekle vstopnice in članki se posredujejo GPT skupaj s podatki nove vstopnice za ustvarjanje odgovora.
- Nova vstopnica je posodobljena z notranjo opombo, ki vsebuje ustvarjen odgovor GPT.
To lahko preizkusimo ročno –
- V Zendesku ročno ustvarimo vstopnico, da preizkusimo tok.
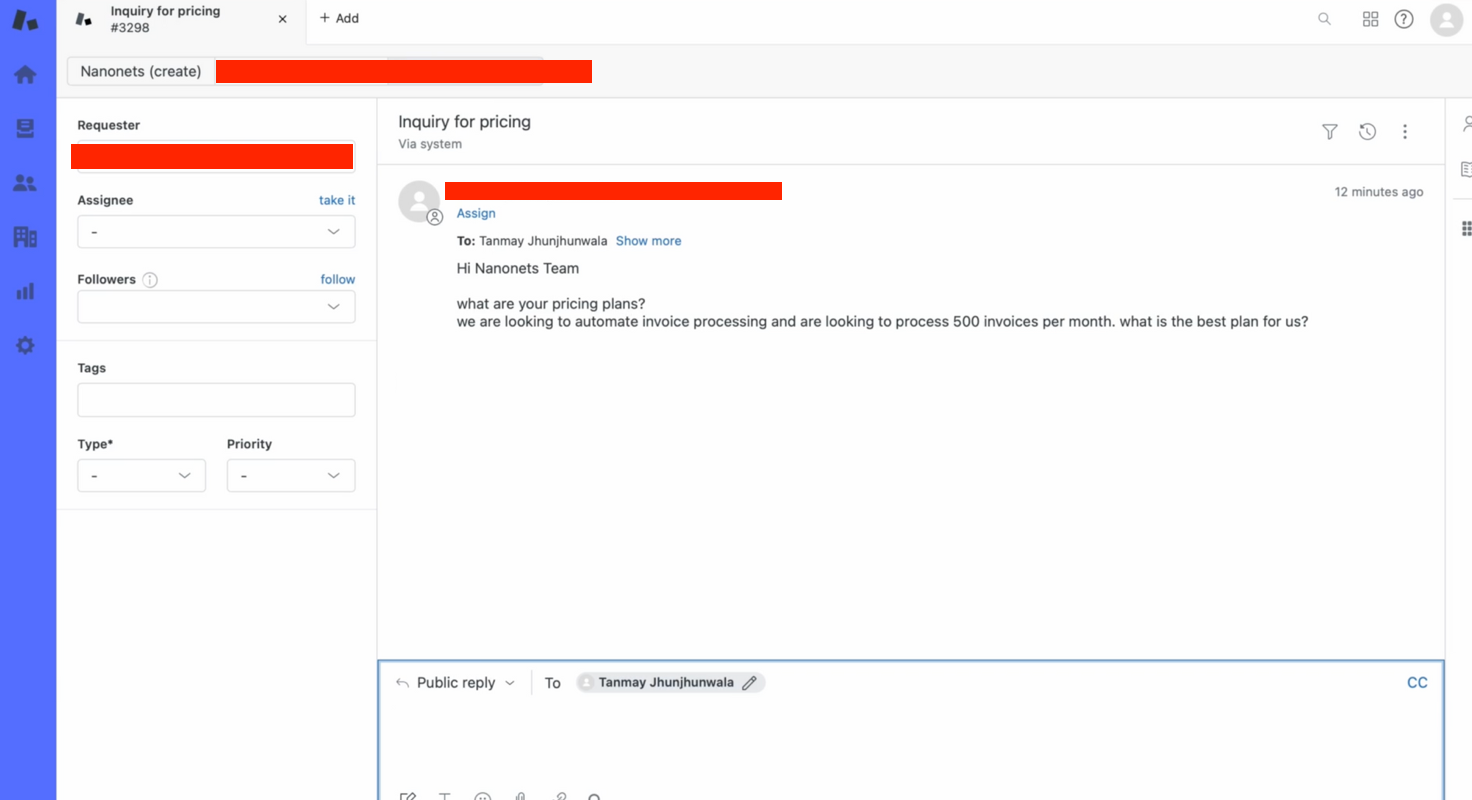
- V nekaj sekundah naš bot ponudi ustrezen odgovor na poizvedbo o vstopnici!
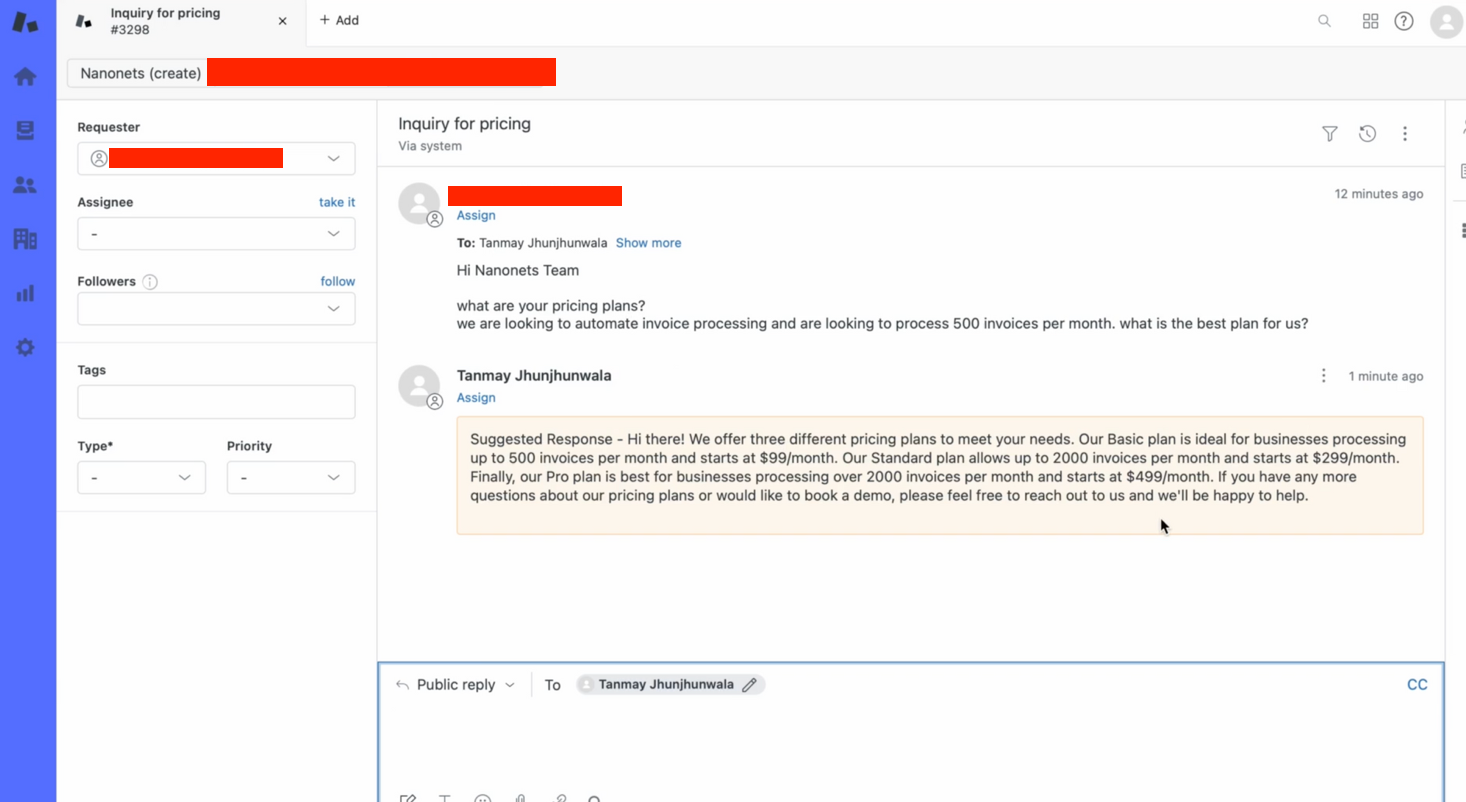
Kako narediti ta celoten potek dela z Nanonets
Nanonets ponuja zmogljivo platformo za brezhibno izvajanje in upravljanje delovnih tokov, ki temeljijo na RAG. Tukaj je opisano, kako lahko izkoristite Nanonets za ta potek dela:
- Integracija z Zendeskom: Povežite Nanonets z Zendeskom za učinkovito spremljanje in pridobivanje vstopnic.
- Zgradite in usposobite modele: Uporabite Nanonets za izgradnjo in usposabljanje LLM za ustvarjanje natančnih in skladnih odgovorov na podlagi baze znanja in analiziranega konteksta.
- Avtomatizirajte odgovore: Nastavite pravila avtomatizacije v Nanonets za samodejno objavo ustvarjenih odgovorov v Zendesk ali jih posredujte človeškim agentom v pregled.
- Spremljajte in optimizirajte: Nenehno spremljajte delovanje delovnega toka in optimizirajte modele in pravila za izboljšanje natančnosti in učinkovitosti.
Z integracijo LLM-jev z delovnimi tokovi, ki temeljijo na RAG, v GenAI in izkoriščanjem zmogljivosti Nanonetov lahko podjetja znatno izboljšajo svoje operacije podpore strankam ter zagotavljajo hitre in natančne odgovore na poizvedbe strank na Zendesku.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://nanonets.com/blog/build-your-own-zendesk-answer-bot-with-llms/
- :ima
- : je
- :ne
- :kje
- $GOR
- 06
- 08
- 1
- 2000
- 28
- 32
- 40
- 7
- a
- nad
- dostop
- Račun
- natančnost
- natančna
- Zakon
- Ukrep
- dejavnosti
- aktivna
- dodajte
- Poleg tega
- Naslov
- privrženost
- admin
- Agent
- agenti
- AI
- vsi
- skupaj
- Prav tako
- an
- Analiza
- analizirati
- analiziranje
- in
- odgovor
- kaj
- kjerkoli
- API
- aplikacija
- se prikaže
- SE
- Array
- Prihaja
- članek
- članki
- AS
- vidik
- At
- poskus
- Povečana
- Auth
- avto
- samodejno
- avtomatizacija
- Avtomatizacija
- Backend
- Bančništvo
- bančna industrija
- baza
- temeljijo
- Osnovni
- BE
- postane
- bilo
- pred
- spodaj
- koristno
- Prednosti
- Blog
- telo
- Bot
- Break
- izgradnjo
- Building
- poslovni
- podjetja
- vendar
- by
- klic
- se imenuje
- poziva
- Akcija
- Kampanje
- CAN
- Zmogljivosti
- primeru
- centralizirano
- verige
- Spremembe
- znaki
- chatbot
- klepetalnice
- Koda
- Koda
- Kodiranje
- KOHERENTNO
- COM
- združujejo
- prihaja
- komentar
- komentarji
- Komunikacija
- Zaključi
- komponenta
- deli
- Pogoji
- Connect
- vsebujejo
- Vsebuje
- vsebina
- ozadje
- naprej
- stalno
- Ustrezno
- bi
- ustvarjajo
- ustvaril
- Ustvarjanje
- Oblikovanje
- Mandatno
- kritično
- ključnega pomena
- Trenutna
- Trenutno
- po meri
- stranka
- Zadovoljstvo kupcev
- Za stranke
- Pomoč strankam
- datum
- Baze podatkov
- odvisnosti
- uvajanja
- želeno
- Razvojni
- usmerjen
- neposredno
- do
- Dokumentacija
- Dokumenti
- prenesi
- med
- vsak
- Učinkovito
- učinkovitosti
- učinkovite
- učinkovito
- bodisi
- element
- ostalo
- E-naslov
- vgrajeni
- zaposleni
- omogoča
- Končna točka
- sodelovanje
- okrepi
- Izboljša
- zagotovitev
- zagotoviti
- Celotna
- Eter (ETH)
- Tudi vsak
- Primer
- Primeri
- Razen
- obstoječih
- Razširi
- izpostavljena
- zunanja
- olajšati
- false
- hitro tempu
- Feature
- Lastnosti
- povratne informacije
- Preneseno
- Polje
- file
- prva
- Pretok
- po
- za
- Naprej
- frekvenca
- iz
- funkcija
- nadalje
- ustvarjajo
- ustvarila
- ustvarjajo
- generacija
- generativno
- Generativna AI
- dobili
- gif
- dobro
- vodi
- Ravnanje
- Imajo
- ob
- Glave
- pomoč
- zgodovina
- gostitelj
- Kako
- http
- HTTPS
- človeškega
- ID
- if
- izvajati
- izvajanja
- uvoz
- Pomembno
- izboljšanje
- izboljšanju
- in
- vključujejo
- Vključno
- Dohodni
- vključi
- Poveča
- Indeks
- indeksirane
- Industrija
- Podatki
- informativni
- obvestila
- začetku
- vhod
- Poizvedbe
- namestitev
- primer
- Namesto
- Navodila
- Povezovanje
- interakcije
- interakcije
- notranji
- v
- Predstavitev
- IP
- IT
- json
- Jupyter Notebook
- samo
- Ključne
- tipke
- znanje
- jezik
- velika
- Zadnji
- Vzvod
- vzvod
- kot
- LINK
- lokalna
- Znamka
- upravljanje
- ročno
- Tržna
- Tržni trendi
- Trženje
- Material
- Metoda
- modeli
- spremembe
- spremenite
- monitor
- več
- Najbolj
- premikanje
- Ime
- potrebno
- Nimate
- potrebna
- potrebe
- Novo
- nova funkcija
- Nov izdelek
- Upoštevajte
- prenosnik
- zdaj
- otopeli
- pridobljeni
- of
- Ponudbe
- on
- enkrat
- tiste
- samo
- OpenAI
- Delovanje
- operacije
- Optimizirajte
- or
- izvirno
- OS
- Ostalo
- naši
- več
- lastne
- Stran
- strani
- pand
- del
- zlasti
- opravil
- Geslo
- preteklosti
- pot
- opravlja
- performance
- izvajati
- opravlja
- Dovoljenja
- Prilagojene
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- pozitiven
- Prispevek
- potencialno
- poganja
- močan
- Postopek
- Izdelek
- Podatki o izdelku
- Projekt
- projekti
- predlaga
- zagotavljajo
- zagotavlja
- zagotavljanje
- javnega
- vlečenje
- namene
- Python
- kakovost
- poizvedbe
- vprašanje
- Hitri
- Oceniti
- Cene
- RE
- resnični svet
- nedavno
- priporočeno
- sklicevanje
- nanaša
- odražajo
- redno
- pomembno
- zamenjajte
- odgovori
- Skladišče
- predstavlja
- zahteva
- zahteva
- obvezna
- Odgovor
- odgovorov
- odgovorna
- zadrževanje
- vrnitev
- pregleda
- Mnenja
- revidirati
- Pot
- pravila
- Run
- tek
- s
- prodaja
- Zadovoljstvo
- shranjena
- urnik
- script
- brez težav
- Iskalnik
- sekund
- glej
- pošlje
- strežnik
- Storitev
- Zasedanje
- nastavite
- nastavitev
- nastavitve
- premik
- pokazale
- bistveno
- Enostavno
- delček
- Viri
- specifična
- standardi
- začel
- začne
- Status
- trgovina
- racionalizirati
- String
- Močno
- poddomene
- predmet
- naročnine
- taka
- primerna
- podpora
- Preverite
- SWIFT
- sistem
- ciljno
- Naloga
- terminal
- Pogoji
- Test
- Testiranje
- besedilo
- da
- O
- njihove
- Njih
- POTEM
- ta
- skozi
- Tako
- Vstopnica
- vstopnice
- pravočasno
- Naslov
- do
- današnje
- žeton
- proti
- Vlak
- transakcija
- transformatorji
- Trends
- sprožijo
- Res
- poskusite
- Navodila
- Nadgradnja
- posodobljeno
- URL
- us
- uporaba
- uporabnik
- uporabo
- navadno
- uporabiti
- v1
- vrednost
- preko
- Vimeo
- obisk
- način..
- we
- teden
- kdaj
- kadar koli
- ki
- medtem
- bo
- z
- potek dela
- delovnih tokov
- svet
- jo
- Vaša rutina za
- Zendesk
- zefirnet