Iskanje podobnih stolpcev v a podatkovno jezero ima pomembne aplikacije pri čiščenju in označevanju podatkov, ujemanju shem, odkrivanju podatkov in analitiki v več virih podatkov. Nezmožnost natančnega iskanja in analiziranja podatkov iz različnih virov predstavlja potencialnega morilca učinkovitosti za vse, od podatkovnih znanstvenikov, medicinskih raziskovalcev, akademikov do finančnih in vladnih analitikov.
Običajne rešitve vključujejo iskanje po leksikalnih ključnih besedah ali ujemanje regularnih izrazov, ki so dovzetni za težave s kakovostjo podatkov, kot so odsotna imena stolpcev ali različna pravila poimenovanja stolpcev v različnih nizih podatkov (npr. zip_code, zcode, postalcode).
V tej objavi prikazujemo rešitev za iskanje podobnih stolpcev na podlagi imena stolpca, vsebine stolpca ali obojega. Rešitev uporablja približni algoritmi najbližjih sosedov na voljo v Storitev Amazon OpenSearch za iskanje pomensko podobnih stolpcev. Za olajšanje iskanja ustvarimo predstavitve funkcij (vdelave) za posamezne stolpce v podatkovnem jezeru z uporabo vnaprej pripravljenih modelov Transformer iz knjižnica transformatorjev stavkov in Amazon SageMaker. Nazadnje, za interakcijo in vizualizacijo rezultatov naše rešitve zgradimo interaktivno Poenostavljeno deluje spletna aplikacija AWS Fargate.
Vključujemo a vadnica za kodo za uvedbo virov za izvajanje rešitve na vzorčnih podatkih ali vaših lastnih podatkih.
Pregled rešitev
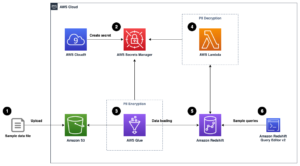
Naslednji diagram arhitekture ponazarja dvostopenjski potek dela za iskanje pomensko podobnih stolpcev. Prva stopnja poteka Korak funkcije AWS potek dela, ki ustvarja vdelave iz tabelaričnih stolpcev in gradi iskalni indeks OpenSearch Service. Druga stopnja ali stopnja spletnega sklepanja izvaja aplikacijo Streamlit prek Fargate. Spletna aplikacija zbira vhodne iskalne poizvedbe in iz indeksa OpenSearch Service pridobi približne k-najbolj podobnih stolpcev poizvedbi.

Slika 1. Arhitektura rešitve
Samodejni potek dela poteka v naslednjih korakih:
- Uporabnik naloži tabelarične nabore podatkov v Preprosta storitev shranjevanja Amazon (Amazon S3) vedro, ki prikliče an AWS Lambda funkcijo, ki sproži delovni tok funkcij korakov.
- Potek dela se začne z an AWS lepilo opravilo, ki pretvori datoteke CSV v Parket Apache format podatkov.
- Opravilo SageMaker Processing ustvari vdelave za vsak stolpec z uporabo vnaprej usposobljenih modelov ali modelov za vdelavo stolpcev po meri. Opravilo SageMaker Processing shrani vdelave stolpcev za vsako tabelo v Amazon S3.
- Funkcija Lambda ustvari domeno storitve OpenSearch Service in gručo za indeksiranje vdelav stolpcev, ustvarjenih v prejšnjem koraku.
- Končno je interaktivna spletna aplikacija Streamlit uvedena s Fargate. Spletna aplikacija ponuja uporabniku vmesnik za vnos poizvedb za iskanje podobnih stolpcev v domeni OpenSearch Service.
Vadnico za kodo lahko prenesete s GitHub da preizkusite to rešitev na vzorčnih podatkih ali svojih podatkih. Navodila za uporabo potrebnih virov za to vadnico so na voljo na GitHub.
Predpogoji
Za izvedbo te rešitve potrebujete naslednje:
- An AWS račun.
- Osnovno poznavanje storitev AWS, kot je Komplet za razvoj oblaka AWS (AWS CDK), Lambda, storitev OpenSearch in obdelava SageMaker.
- Tabelarni nabor podatkov za ustvarjanje iskalnega indeksa. Lahko prinesete svoje tabelarične podatke ali prenesete vzorčne nabore podatkov GitHub.
Zgradite iskalni indeks
Prva faza zgradi indeks iskalnika stolpcev. Naslednja slika ponazarja potek dela funkcij korakov, ki izvaja to stopnjo.

Slika 2 – Potek dela funkcij koraka – več modelov vdelave
Podatkovni nizi
V tej objavi gradimo iskalni indeks, ki vključuje več kot 400 stolpcev iz več kot 25 tabelarnih naborov podatkov. Nabori podatkov izvirajo iz naslednjih javnih virov:
Za celoten seznam tabel, vključenih v indeks, si oglejte vadnico za kodo GitHub.
Prinesete lahko svoj nabor tabelaričnih podatkov, da povečate vzorčne podatke ali zgradite svoj iskalni indeks. Vključujemo dve funkciji Lambda, ki sprožita potek dela Step Functions za izgradnjo iskalnega indeksa za posamezne datoteke CSV ali skupino datotek CSV.
Pretvorite CSV v Parquet
Neobdelane datoteke CSV se pretvorijo v format podatkov Parquet z AWS Glue. Parquet je format datoteke formata, usmerjenega v stolpce, ki je prednosten v analizi velikih podatkov in zagotavlja učinkovito stiskanje in kodiranje. V naših poskusih je format podatkov Parquet ponudil znatno zmanjšanje velikosti shranjevanja v primerjavi z neobdelanimi datotekami CSV. Parquet smo uporabili tudi kot običajni format podatkov za pretvorbo drugih formatov podatkov (na primer JSON in NDJSON), ker podpira napredne ugnezdene podatkovne strukture.
Ustvarite vdelave tabelarnih stolpcev
Za ekstrahiranje vdelav za posamezne stolpce tabele v vzorčnih naborih tabelarnih podatkov v tej objavi uporabimo naslednje vnaprej usposobljene modele iz sentence-transformers knjižnica. Za dodatne modele glejte Vnaprej usposobljeni modeli.
Zažene se opravilo SageMaker Processing create_embeddings.py(Koda) za en model. Za pridobivanje vdelav iz več modelov potek dela izvaja vzporedna opravila SageMaker Processing, kot je prikazano v poteku dela Funkcije korakov. Model uporabljamo za ustvarjanje dveh nizov vdelav:
- ime_stolpca_vdelave – Vdelave imen stolpcev (glave)
- vdelave_vsebine_stolpca – Povprečna vdelava vseh vrstic v stolpcu
Za več informacij o postopku vdelave stolpcev glejte vadnico za kodo na GitHub.
Alternativa koraku obdelave SageMaker je izdelava paketne transformacije SageMaker za pridobitev vdelav stolpcev v velike nize podatkov. To bi zahtevalo namestitev modela na končno točko SageMaker. Za več informacij glejte Uporabite paketno preoblikovanje.
Indeksirajte vdelave s storitvijo OpenSearch
V zadnjem koraku te stopnje funkcija Lambda doda vdelave stolpcev v storitev OpenSearch približnega k-najbližjega soseda (kNN) indeks iskanja. Vsakemu modelu je dodeljen lasten iskalni indeks. Za več informacij o približnih parametrih iskalnega indeksa kNN glejte k-NN.
Spletno sklepanje in semantično iskanje s spletno aplikacijo
Druga stopnja poteka dela poteka a Poenostavljeno spletno aplikacijo, kjer lahko zagotovite vnose in iščete pomensko podobne stolpce, indeksirane v storitvi OpenSearch. Aplikacijska plast uporablja an Izravnalnik obremenitve aplikacije, Fargate in Lambda. Aplikacijska infrastruktura se samodejno uvede kot del rešitve.
Aplikacija omogoča vnos in iskanje pomensko podobnih imen stolpcev, vsebine stolpcev ali obojega. Poleg tega lahko izberete model vdelave in število najbližjih sosedov, ki se vrnejo iz iskanja. Aplikacija prejme vnose, jih vdela v podani model in uporabi iskanje kNN v storitvi OpenSearch za iskanje indeksiranih vdelav stolpcev in iskanje najbolj podobnih stolpcev danemu vnosu. Prikazani rezultati iskanja vključujejo imena tabel, imena stolpcev in ocene podobnosti za identificirane stolpce ter lokacije podatkov v Amazon S3 za nadaljnje raziskovanje.
Naslednja slika prikazuje primer spletne aplikacije. V tem primeru smo iskali stolpce v našem podatkovnem jezeru, ki imajo podobno Column Names (vrsta tovora) do district (tovor). Uporabljena aplikacija all-MiniLM-L6-v2 kot vgradni model in se vrnil 10 (k) najbližjih sosedov iz našega indeksa OpenSearch Service.
Aplikacija se je vrnila transit_district, city, boroughin location kot štiri najbolj podobne stolpce glede na podatke, indeksirane v storitvi OpenSearch. Ta primer prikazuje zmožnost iskalnega pristopa za prepoznavanje semantično podobnih stolpcev v nizih podatkov.

Slika 3: Uporabniški vmesnik spletne aplikacije
Čiščenje
Če želite izbrisati vire, ki jih je ustvaril AWS CDK v tej vadnici, zaženite naslednji ukaz:
cdk destroy --allzaključek
V tej objavi smo predstavili potek dela od konca do konca za izdelavo semantičnega iskalnika za tabelarične stolpce.
Začnite že danes z lastnimi podatki z našo vadnico za kodo, ki je na voljo na GitHub. Če želite pomoč pri pospeševanju uporabe ML v svojih izdelkih in procesih, se obrnite na Amazonski laboratorij za strojno učenje.
O avtorjih
![]() Kachi Odoemene je uporabni znanstvenik pri AWS AI. Gradi rešitve AI/ML za reševanje poslovnih težav za stranke AWS.
Kachi Odoemene je uporabni znanstvenik pri AWS AI. Gradi rešitve AI/ML za reševanje poslovnih težav za stranke AWS.
![]() Taylor McNally je arhitekt poglobljenega učenja pri Amazon Machine Learning Solutions Lab. Strankam iz različnih industrij pomaga zgraditi rešitve, ki uporabljajo AI/ML na AWS. Uživa v skodelici dobre kave, na prostem ter času s svojo družino in energičnim psom.
Taylor McNally je arhitekt poglobljenega učenja pri Amazon Machine Learning Solutions Lab. Strankam iz različnih industrij pomaga zgraditi rešitve, ki uporabljajo AI/ML na AWS. Uživa v skodelici dobre kave, na prostem ter času s svojo družino in energičnim psom.
![]() Austin Welch je podatkovni znanstvenik v Amazon ML Solutions Lab. Razvija modele poglobljenega učenja po meri, da bi strankam AWS v javnem sektorju pomagal pospešiti uvajanje umetne inteligence in oblaka. V prostem času uživa v branju, potovanjih in jiu-jitsu.
Austin Welch je podatkovni znanstvenik v Amazon ML Solutions Lab. Razvija modele poglobljenega učenja po meri, da bi strankam AWS v javnem sektorju pomagal pospešiti uvajanje umetne inteligence in oblaka. V prostem času uživa v branju, potovanjih in jiu-jitsu.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- sposobnost
- O meni
- odsoten
- pospeši
- pospeševanje
- natančno
- čez
- Dodatne
- Poleg tega
- Dodaja
- Sprejetje
- napredno
- AI
- AI / ML
- vsi
- omogoča
- alternativa
- Amazon
- Strojno učenje Amazon
- Amazon ML Solutions Lab
- Analitiki
- analitika
- analizirati
- in
- Apache
- uporaba
- aplikacije
- uporabna
- pristop
- Arhitektura
- dodeljena
- Avtomatizirano
- samodejno
- Na voljo
- povprečno
- AWS
- AWS lepilo
- temeljijo
- ker
- Big
- Big Podatki
- prinašajo
- izgradnjo
- Building
- Gradi
- poslovni
- čiščenje
- Cloud
- sprejem v oblak
- Grozd
- Koda
- Kava
- zbira
- Stolpec
- Stolpci
- Skupno
- v primerjavi z letom
- kontakt
- vsebina
- Konvencij
- pretvorbo
- pretvori
- ustvarjajo
- ustvaril
- ustvari
- Pokal
- po meri
- Stranke, ki so
- datum
- Podatkovna analiza
- Data jezero
- kakovosti podatkov
- podatkovni znanstvenik
- nabor podatkov
- globoko
- globoko učenje
- izkazati
- dokazuje,
- razporedi
- razporejeni
- uvajanja
- uniči
- Razvoj
- razvija
- drugačen
- Odkritje
- različno
- razne
- Pes
- domena
- prenesi
- vsak
- učinkovitosti
- učinkovite
- konec koncev
- Končna točka
- Motor
- Eter (ETH)
- vsi
- Primer
- raziskovanje
- ekstrakt
- olajšati
- Poznavanje
- družina
- Lastnosti
- Slika
- file
- datoteke
- končna
- končno
- finančna
- Najdi
- iskanje
- prva
- po
- format
- iz
- polno
- funkcija
- funkcije
- nadalje
- dobili
- dana
- dobro
- vlada
- Glave
- pomoč
- Pomaga
- Kako
- Kako
- HTML
- HTTPS
- identificirati
- identificirati
- izvajati
- Pomembno
- in
- nezmožnost
- vključujejo
- vključeno
- Indeks
- individualna
- industrij
- Podatki
- Infrastruktura
- sproži
- Iniciatorji
- vhod
- Navodila
- interakcijo
- interaktivno
- vmesnik
- prikliče
- vključujejo
- Vprašanja
- IT
- Job
- Delovna mesta
- json
- lab
- Jezero
- velika
- plast
- učenje
- vzvod
- Knjižnica
- Seznam
- obremenitev
- Lokacije
- stroj
- strojno učenje
- ujemanje
- medicinski
- ML
- Model
- modeli
- več
- Najbolj
- več
- Ime
- Imena
- poimenovanje
- Nimate
- sosedi
- Številka
- ponujen
- na spletu
- Ostalo
- na prostem
- lastne
- vzporedno
- parametri
- del
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prosim
- Prispevek
- potencial
- prednostno
- predstavljeni
- prejšnja
- Težave
- izkupiček
- Postopek
- Procesi
- obravnavati
- Proizvedeno
- Izdelki
- zagotavljajo
- zagotavlja
- javnega
- kakovost
- Surovi
- reading
- prejme
- redni
- predstavlja
- zahteva
- obvezna
- raziskovalci
- viri
- oziroma
- Rezultati
- vrnitev
- Run
- tek
- sagemaker
- Znanstvenik
- Znanstveniki
- Iskalnik
- iskalnik
- iskanje
- drugi
- sektor
- Storitev
- Storitve
- Kompleti
- pokazale
- Razstave
- pomemben
- Podoben
- Enostavno
- sam
- Velikosti
- Rešitev
- rešitve
- SOLVE
- Viri
- določeno
- Stage
- začel
- Korak
- Koraki
- shranjevanje
- taka
- Podpira
- dovzetne
- miza
- O
- njihove
- skozi
- čas
- do
- danes
- Transform
- transformatorji
- Potovanje
- Navodila
- uporaba
- uporabnik
- Uporabniški vmesnik
- različnih
- web
- Spletna aplikacija
- ki
- potek dela
- bi
- Vaša rutina za
- zefirnet