Pri uvajanju velikega jezikovnega modela (LLM) izvajalci strojnega učenja (ML) običajno skrbijo za dve meritvi zmogljivosti streženja modela: zakasnitev, opredeljeno s časom, ki je potreben za ustvarjanje enega žetona, in prepustnost, opredeljeno s številom ustvarjenih žetonov. na sekundo. Čeprav bi ena sama zahteva za razporejeno končno točko pokazala prepustnost, ki je približno enaka obratni zakasnitvi modela, to ni nujno tako, ko je več sočasnih zahtev hkrati poslanih končni točki. Zaradi tehnik streženja modela, kot je neprekinjeno pakiranje sočasnih zahtev na strani odjemalca, imata zakasnitev in prepustnost zapleteno razmerje, ki se znatno razlikuje glede na arhitekturo modela, konfiguracije strežbe, vrsto strojne opreme primerka, število sočasnih zahtev in variacije v vhodnih obremenitvah, kot so kot število vhodnih in izhodnih žetonov.
Ta objava raziskuje ta razmerja prek obsežne primerjalne analize LLM-jev, ki so na voljo v Amazon SageMaker JumpStart, vključno z različicami Llama 2, Falcon in Mistral. S SageMaker JumpStart lahko praktiki ML izbirajo med širokim izborom javno dostopnih temeljnih modelov za uvedbo v namenske Amazon SageMaker primerke v omrežno izoliranem okolju. Ponujamo teoretična načela o tem, kako specifikacije pospeševalnika vplivajo na primerjalno analizo LLM. Prikazali smo tudi vpliv uvajanja več primerkov za eno končno točko. Nazadnje nudimo praktična priporočila za prilagajanje postopka uvajanja SageMaker JumpStart, da se uskladi z vašimi zahtevami glede zakasnitve, prepustnosti, stroškov in omejitev razpoložljivih vrst primerkov. Vsi rezultati primerjalne analize in priporočila temeljijo na vsestranskem prenosnik ki jih lahko prilagodite svojemu primeru uporabe.
Razporejeno primerjalno testiranje končne točke
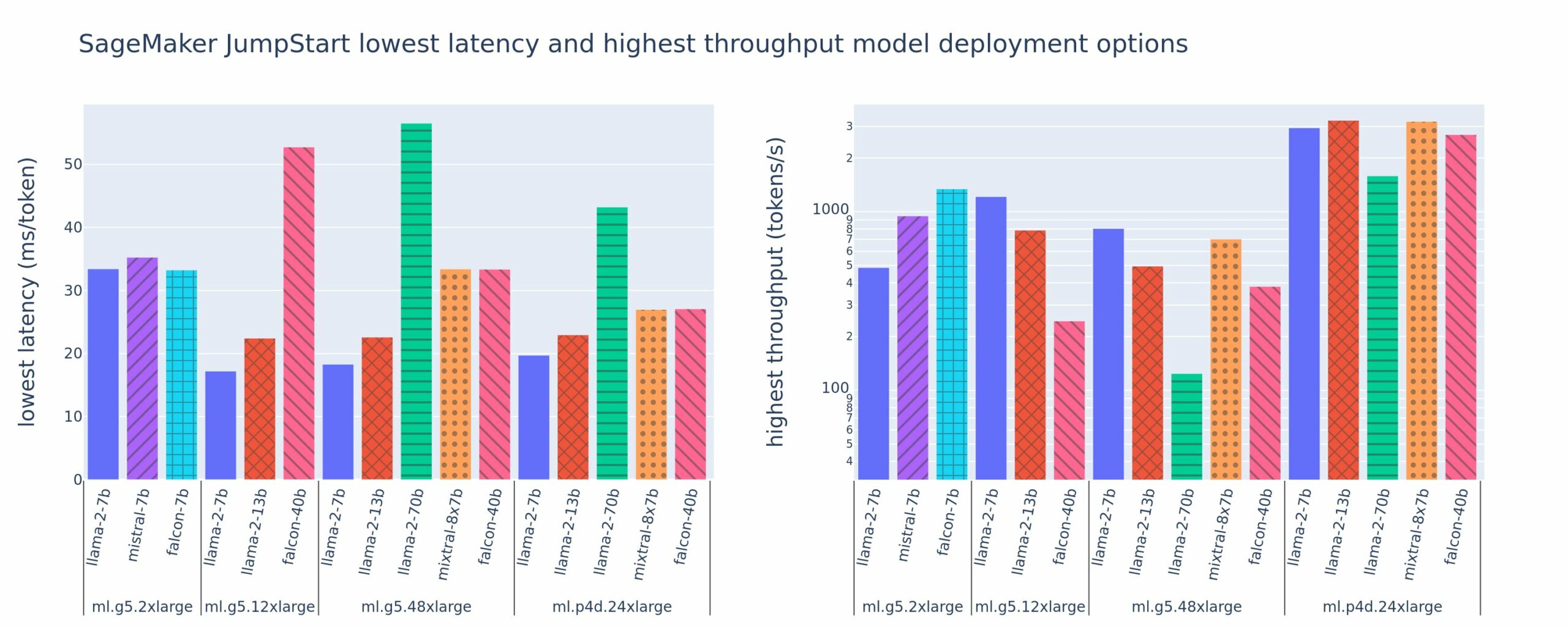
Naslednja slika prikazuje najnižje zakasnitve (levo) in najvišjo prepustnost (desno) za konfiguracije razmestitve v različnih tipih modelov in tipih primerkov. Pomembno je, da vsaka od teh uvedb modela uporablja privzete konfiguracije, ki jih zagotavlja SageMaker JumpStart glede na želeni ID modela in vrsto primerka za uvedbo.
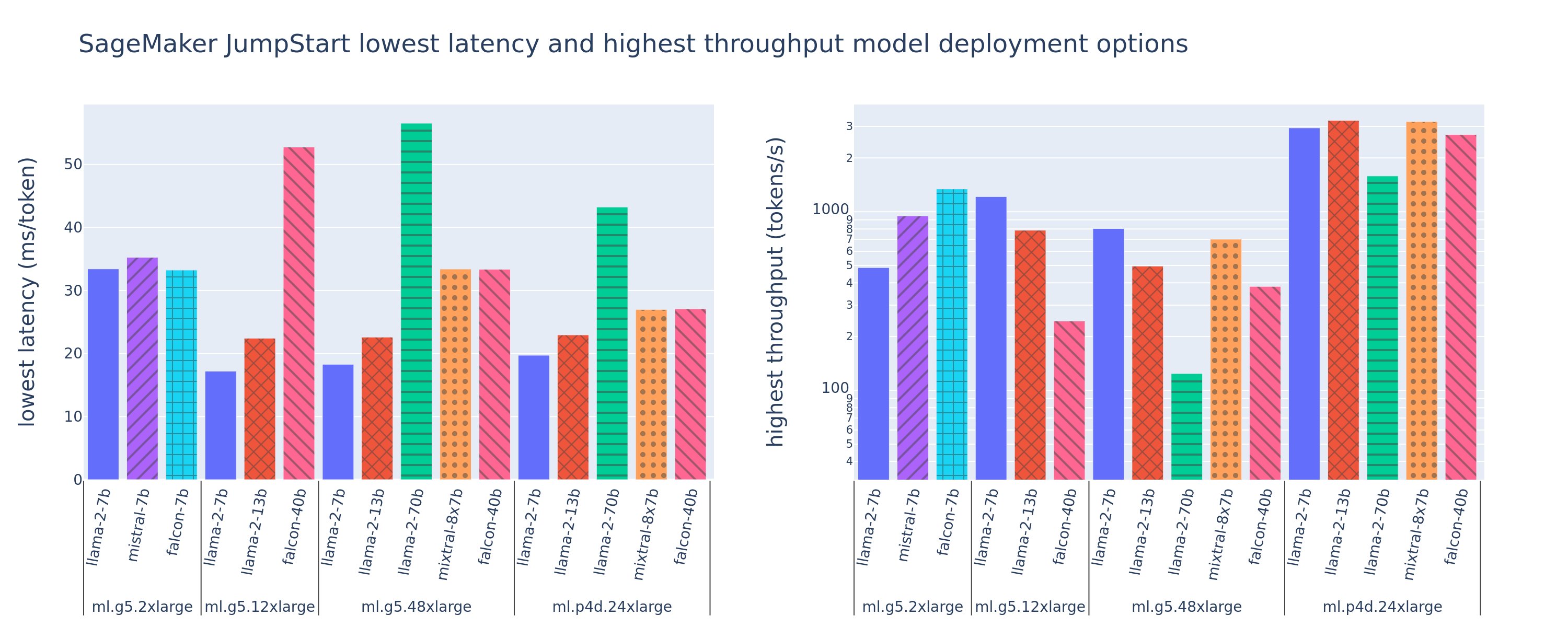
Te vrednosti zakasnitve in prepustnosti ustrezajo koristnim obremenitvam z 256 vhodnimi žetoni in 256 izhodnimi žetoni. Konfiguracija z najnižjo zakasnitvijo omeji strežbo modela na eno sočasno zahtevo, konfiguracija z najvišjo prepustnostjo pa poveča možno število sočasnih zahtev. Kot lahko vidimo v naši primerjalni analizi, povečanje sočasnih zahtev monotono poveča prepustnost z vse manjšim izboljšanjem velikih sočasnih zahtev. Poleg tega so modeli v celoti razdeljeni na podprti primerek. Na primer, ker ima primerek ml.g5.48xlarge 8 grafičnih procesorjev, so vsi modeli SageMaker JumpStart, ki uporabljajo ta primerek, razdeljeni z uporabo tenzorskega paralelizma na vseh osmih razpoložljivih pospeševalnikih.
Iz te številke lahko opazimo nekaj povzetkov. Prvič, vsi modeli niso podprti v vseh primerih; nekateri manjši modeli, kot je Falcon 7B, ne podpirajo drobljenja modelov, medtem ko imajo večji modeli višje zahteve glede računalniških virov. Drugič, ko se razrezovanje poveča, se zmogljivost običajno izboljša, vendar ni nujno, da se izboljša za majhne modele. To je zato, ker majhni modeli, kot sta 7B in 13B, povzročajo znatne komunikacijske stroške, če so razdeljeni na preveč pospeševalnikov. O tem bomo podrobneje razpravljali pozneje. Končno imajo primerki ml.p4d.24xlarge bistveno boljšo prepustnost zaradi izboljšav pasovne širine pomnilnika A100 v primerjavi z grafičnimi procesorji A10G. Kot bomo razpravljali kasneje, je odločitev o uporabi določenega tipa primerka odvisna od vaših zahtev po uvajanju, vključno z zakasnitvijo, prepustnostjo in stroškovnimi omejitvami.
Kako lahko pridobite te konfiguracijske vrednosti z najnižjo zakasnitvijo in najvišjo prepustnostjo? Začnimo z risanjem zakasnitve v primerjavi s prepustnostjo za končno točko Llama 2 7B na primerku ml.g5.12xlarge za koristno obremenitev s 256 vhodnimi in 256 izhodnimi žetoni, kot je prikazano na naslednji krivulji. Podobna krivulja obstaja za vsako razporejeno končno točko LLM.

Z večanjem sočasnosti se monotono povečujeta tudi prepustnost in zakasnitev. Zato se najnižja točka zakasnitve pojavi pri vrednosti sočasne zahteve 1 in lahko stroškovno učinkovito povečate prepustnost sistema s povečanjem števila sočasnih zahtev. Na tej krivulji obstaja jasno »koleno«, kjer je očitno, da povečana prepustnost, povezana z dodatno sočasnostjo, ne odtehta povezanega povečanja zakasnitve. Natančna lokacija tega kolena je odvisna od primera uporabe; nekateri izvajalci lahko definirajo koleno na točki, kjer je presežena vnaprej določena zahteva za zakasnitev (na primer 100 ms/žeton), medtem ko lahko drugi uporabijo merila uspešnosti preskusa obremenitve in metode teorije čakalne vrste, kot je pravilo polovične zakasnitve, tretji pa lahko uporabijo teoretične specifikacije pospeševalnika.
Upoštevamo tudi, da je največje število sočasnih zahtev omejeno. Na prejšnji sliki se sled vrstice konča s 192 sočasnimi zahtevami. Vir te omejitve je omejitev časovne omejitve priklica SageMaker, kjer končne točke SageMaker prekinejo odziv priklica po 60 sekundah. Ta nastavitev je specifična za račun in je ni mogoče konfigurirati za posamezno končno točko. Pri LLM lahko ustvarjanje velikega števila izhodnih žetonov traja nekaj sekund ali celo minut. Zato lahko velike vhodne ali izhodne obremenitve povzročijo neuspešne zahteve za priklic. Poleg tega, če je število sočasnih zahtevkov zelo veliko, bodo številne zahteve imele dolgo čakalno vrsto, kar bo povzročilo to 60-sekundno omejitev časovne omejitve. Za namene te študije uporabljamo omejitev časovne omejitve, da definiramo največjo možno prepustnost za uvedbo modela. Pomembno je, da čeprav lahko končna točka SageMaker obravnava veliko število sočasnih zahtev brez upoštevanja časovne omejitve odziva na poziv, boste morda želeli definirati največje število sočasnih zahtev glede na koleno v krivulji zakasnitve-prepustnosti. To je verjetno točka, na kateri začnete razmišljati o vodoravnem skaliranju, kjer ena končna točka zagotavlja več primerkov z replikami modela in uravnava obremenitev dohodnih zahtev med replikami, da podpira več sočasnih zahtev.
Če gremo še korak naprej, naslednja tabela vsebuje rezultate primerjalne analize za različne konfiguracije za model Llama 2 7B, vključno z različnim številom vhodnih in izhodnih žetonov, vrstami primerkov in številom sočasnih zahtev. Upoštevajte, da prejšnja slika prikazuje samo eno vrstico te tabele.
| . | Prepustnost (žetoni/s) | Zakasnitev (ms/žeton) | ||||||||||||||||||
| Sočasne zahteve | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Število skupnih žetonov: 512, Število izhodnih žetonov: 256 | ||||||||||||||||||||
| ml.g5.2xvelik | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xvelik | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xvelik | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xvelika | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Število skupnih žetonov: 4096, Število izhodnih žetonov: 256 | ||||||||||||||||||||
| ml.g5.2xvelik | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xvelik | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xvelik | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xvelika | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
V teh podatkih opazimo nekaj dodatnih vzorcev. Pri povečanju velikosti konteksta se zakasnitev poveča in prepustnost zmanjša. Na primer, na ml.g5.2xlarge s sočasnostjo 1 je prepustnost 30 žetonov/s, ko je skupno število žetonov 512, v primerjavi z 20 žetonov/s, če je skupno število žetonov 4,096. To je zato, ker je za obdelavo večjega vnosa potrebno več časa. Vidimo lahko tudi, da povečanje zmogljivosti GPE in razrez vplivata na največjo prepustnost in največje število podprtih sočasnih zahtev. Tabela kaže, da ima Llama 2 7B opazno različne vrednosti največje prepustnosti za različne tipe instanc in te vrednosti največje prepustnosti se pojavijo pri različnih vrednostih sočasnih zahtev. Te značilnosti bi izvajalca strojnega pisanja spodbudile, da upraviči stroške enega primerka pred drugim. Na primer, glede na zahtevo po nizki zakasnitvi lahko izvajalec izbere primerek ml.g5.12xlarge (4 grafični procesorji A10G) namesto primerka ml.g5.2xlarge (1 grafični procesor A10G). Če bi bila dana zahteva po visoki prepustnosti, bi bila uporaba primerka ml.p4d.24xlarge (8 grafičnih procesorjev A100) s popolnim razrezom upravičena le pri visoki sočasnosti. Upoštevajte pa, da je pogosto koristno namesto tega naložiti več komponent sklepanja modela 7B na en primer ml.p4d.24xlarge; takšna podpora za več modelov je obravnavana kasneje v tej objavi.
Prejšnja opažanja so bila narejena za model Llama 2 7B. Vendar podobni vzorci ostajajo veljavni tudi za druge modele. Primarni zaključek je, da so številke zakasnitve in zmogljivosti prepustnosti odvisne od obremenitve, vrste instance in števila sočasnih zahtev, zato boste morali poiskati idealno konfiguracijo za vašo specifično aplikacijo. Če želite ustvariti prejšnje številke za vaš primer uporabe, lahko zaženete povezano prenosnik, kjer lahko konfigurirate to analizo preizkusa obremenitve za svoj model, vrsto instance in obremenitev.
Osmišljanje specifikacij pospeševalnika
Izbira ustrezne strojne opreme za sklepanje LLM je v veliki meri odvisna od posebnih primerov uporabe, ciljev uporabniške izkušnje in izbranega LLM. Ta razdelek poskuša ustvariti razumevanje kolena v krivulji zakasnitve-prepustnosti glede na načela visoke ravni, ki temeljijo na specifikacijah pospeševalnika. Ta načela sama po sebi ne zadoščajo za odločitev: potrebna so prava merila. Izraz naprava se tukaj uporablja za zajemanje vseh pospeševalnikov strojne opreme ML. Trdimo, da koleno na krivulji zakasnitve-prepustnosti poganja eden od dveh dejavnikov:
- Pospeševalnik je izčrpal pomnilnik za predpomnilnik KV matric, zato so naslednje zahteve v čakalni vrsti
- Pospeševalnik ima še vedno rezervni pomnilnik za predpomnilnik KV, vendar uporablja dovolj veliko velikost paketa, da čas obdelave poganja zakasnitev operacij računanja in ne pasovna širina pomnilnika
Običajno smo raje omejeni z drugim dejavnikom, ker to pomeni, da so viri pospeševalnika nasičeni. V bistvu povečate vire, ki ste jih plačali. Raziščimo to trditev podrobneje.
KV predpomnjenje in pomnilnik naprave
Standardni transformatorski mehanizmi pozornosti izračunajo pozornost za vsak nov žeton glede na vse prejšnje žetone. Večina sodobnih strežnikov ML predpomni ključe in vrednosti v pomnilnik naprave (DRAM), da se izogne ponovnemu izračunu na vsakem koraku. To se imenuje ta KV predpomnilnik, in raste z velikostjo serije in dolžino zaporedja. Določa, koliko uporabniških zahtev je mogoče postreči vzporedno, in bo določil koleno na krivulji zakasnitve-prepustnosti, če režim, vezan na računalništvo v drugem prej omenjenem scenariju, glede na razpoložljivi DRAM še ni izpolnjen. Naslednja formula je grob približek za največjo velikost predpomnilnika KV.

V tej formuli je B velikost serije, N pa število pospeševalnikov. Na primer, model Llama 2 7B v FP16 (2 bajta/parameter), postrežen z GPE A10G (24 GB DRAM), porabi približno 14 GB, pri čemer ostane 10 GB za predpomnilnik KV. Če vključimo celotno dolžino konteksta modela (N = 4096) in preostale parametre (n_layers=32, n_kv_attention_heads=32 in d_attention_head=128), ta izraz pokaže, da smo zaradi omejitev DRAM-a omejeni na vzporedno streženje velikosti paketa štirih uporabnikov . Če opazujete ustrezna merila uspešnosti v prejšnji tabeli, je to dober približek za opazovano koleno v tej krivulji zakasnitev-prepustnost. Metode, kot je npr skupinska poizvedba pozornost (GQA) lahko zmanjša velikost predpomnilnika KV, v primeru GQA z enakim faktorjem zmanjša število glav KV.
Aritmetična intenzivnost in pasovna širina pomnilnika naprave
Rast računalniške moči pospeševalnikov ML je presegla pasovno širino njihovega pomnilnika, kar pomeni, da lahko izvedejo veliko več izračunov na vsakem bajtu podatkov v času, ki je potreben za dostop do tega bajta.
O aritmetična intenzivnostali razmerje med računalniškimi operacijami in dostopi do pomnilnika za operacijo določa, ali je omejena s pasovno širino pomnilnika ali računalniško zmogljivostjo na izbrani strojni opremi. Na primer, GPU A10G (družina primerkov vrste g5) s 70 TFLOPS FP16 in pasovno širino 600 GB/s lahko izračuna približno 116 operacij/bajt. GPU A100 (družina primerkov p4d) lahko izračuna približno 208 operacij/bajt. Če je aritmetična intenzivnost za model transformatorja pod to vrednostjo, je vezan na pomnilnik; če je zgoraj, je vezan na izračun. Mehanizem pozornosti za Llama 2 7B zahteva 62 operacij/bajt za paketno velikost 1 (za razlago glejte Vodnik za LLM sklepanje in uspešnost), kar pomeni, da je vezan na pomnilnik. Ko je mehanizem pozornosti vezan na pomnilnik, dragi FLOPS ostanejo neizkoriščeni.
Obstajata dva načina za boljši izkoristek pospeševalnika in povečanje aritmetične intenzivnosti: zmanjšajte potrebne dostope do pomnilnika za operacijo (to je tisto, FlashAttention se osredotoča na) ali poveča velikost serije. Vendar pa morda ne bomo mogli dovolj povečati velikosti naše serije, da bi dosegli režim, vezan na računalništvo, če je naš DRAM premajhen, da bi zadržal ustrezen predpomnilnik KV. Surov približek kritične velikosti serije B*, ki ločuje računsko vezane režime od pomnilniško vezanih režimov za standardno sklepanje dekoderja GPT, je opisan z naslednjim izrazom, kjer je A_mb pasovna širina pomnilnika pospeševalnika, A_f je FLOPS pospeševalnika in N je število pospeševalnikov. To kritično velikost serije je mogoče izpeljati tako, da se ugotovi, kje je čas dostopa do pomnilnika enak času izračuna. Nanašati se na to objavo v spletnem dnevniku da bi podrobneje razumeli enačbo 2 in njene predpostavke.

To je enako razmerje operacij/bajt, ki smo ga predhodno izračunali za A10G, tako da je kritična velikost paketa na tem GPE 116. Eden od načinov, kako se približati tej teoretični, kritični velikosti paketa, je povečanje razdeljevanja modela in razdelitev predpomnilnika na več pospeševalnikov N. To učinkovito poveča kapaciteto predpomnilnika KV in velikost paketa, vezanega na pomnilnik.
Druga prednost drobljenja modela je razdelitev parametrov modela in nalaganja podatkov na N pospeševalnikov. Ta vrsta drobljenja je vrsta paralelizma modela, imenovana tudi tenzorski paralelizem. Naivno, obstaja N-kratnik pasovne širine pomnilnika in računske moči skupaj. Ob predpostavki, da ni nobenih dodatnih stroškov (komunikacija, programska oprema itd.), bi to zmanjšalo zakasnitev dekodiranja na žeton za N, če smo vezani na pomnilnik, ker je zakasnitev dekodiranja žetona v tem režimu vezana na čas, potreben za nalaganje modela uteži in predpomnilnik. V resničnem življenju pa povečanje stopnje drobljenja povzroči večjo komunikacijo med napravami za skupno rabo vmesnih aktivacij na vsaki plasti modela. Ta komunikacijska hitrost je omejena s pasovno širino medsebojne povezave naprave. Njegov vpliv je težko natančno oceniti (za podrobnosti glej Paralelizem modela), vendar lahko to sčasoma preneha prinašati koristi ali poslabša zmogljivost - to še posebej velja za manjše modele, ker manjši prenosi podatkov povzročijo nižje hitrosti prenosa.
Za primerjavo pospeševalnikov ML na podlagi njihovih specifikacij priporočamo naslednje. Najprej izračunajte približno kritično velikost serije za vsako vrsto pospeševalnika v skladu z drugo enačbo in velikost predpomnilnika KV za velikost kritične serije v skladu s prvo enačbo. Nato lahko uporabite razpoložljivi DRAM na pospeševalniku, da izračunate najmanjše število pospeševalnikov, potrebnih za prilagajanje predpomnilniku KV in parametrom modela. Če se odločate med več pospeševalniki, dajte prednost pospeševalcem po najnižji ceni na GB/s pasovne širine pomnilnika. Končno primerjajte te konfiguracije in preverite, katera je najboljša cena/žeton za vašo zgornjo mejo želene zakasnitve.
Izberite konfiguracijo uvedbe končne točke
Številni LLM-ji, ki jih distribuira SageMaker JumpStart, uporabljajo sklepanje o ustvarjanju besedila (TGI) Posoda SageMaker za serviranje modela. Naslednja tabela opisuje, kako prilagoditi različne parametre streženja modela, da bodisi vpliva na streženje modela, ki vpliva na krivuljo zakasnitve-prepustnosti, bodisi zaščiti končno točko pred zahtevami, ki bi jo preobremenile. To so primarni parametri, ki jih lahko uporabite za konfiguracijo razmestitve končne točke za vaš primer uporabe. Če ni določeno drugače, uporabljamo privzeto parametri koristne obremenitve za generiranje besedila in Spremenljivke okolja TGI.
| Spremenljivka okolja | Opis | Privzeta vrednost SageMaker JumpStart |
| Konfiguracije serviranja modela | . | . |
MAX_BATCH_PREFILL_TOKENS |
Omejuje število žetonov v operaciji predizpolnjevanja. Ta operacija ustvari predpomnilnik KV za novo zaporedje vnosnih pozivov. Zahteva veliko pomnilnika in je vezana na izračune, zato ta vrednost omejuje dovoljeno število žetonov v eni operaciji predizpolnjevanja. Koraki dekodiranja za druge poizvedbe se ustavijo, medtem ko poteka vnaprejšnje izpolnjevanje. | 4096 (privzeto TGI) ali največja podprta dolžina konteksta, specifična za model (priložen SageMaker JumpStart), kar je večje. |
MAX_BATCH_TOTAL_TOKENS |
Nadzoruje največje število žetonov za vključitev v paket med dekodiranjem ali enim samim prehodom naprej skozi model. V idealnem primeru je to nastavljeno tako, da poveča uporabo vse razpoložljive strojne opreme. | Ni določeno (privzeto TGI). TGI bo nastavil to vrednost glede na preostali pomnilnik CUDA med ogrevanjem modela. |
SM_NUM_GPUS |
Število drobcev za uporabo. To je število grafičnih procesorjev, uporabljenih za izvajanje modela z uporabo tenzorskega paralelizma. | Odvisno od primerka (priložen SageMaker JumpStart). Za vsak podprt primerek za dani model SageMaker JumpStart zagotavlja najboljšo nastavitev za tenzorski paralelizem. |
| Konfiguracije za zaščito vaše končne točke (nastavite jih za svoj primer uporabe) | . | . |
MAX_TOTAL_TOKENS |
To omeji pomnilniški proračun posamezne odjemalske zahteve z omejitvijo števila žetonov v vhodnem zaporedju in števila žetonov v izhodnem zaporedju ( max_new_tokens tovorni parameter). |
Največja podprta dolžina konteksta, specifična za model. Na primer 4096 za Llama 2. |
MAX_INPUT_LENGTH |
Določa največje dovoljeno število žetonov v vhodnem zaporedju za posamezno zahtevo odjemalca. Stvari, ki jih je treba upoštevati pri povečanju te vrednosti, vključujejo: daljša vnosna zaporedja zahtevajo več pomnilnika, kar vpliva na neprekinjeno paketno obdelavo, številni modeli pa imajo podprto dolžino konteksta, ki je ne smete preseči. | Največja podprta dolžina konteksta, specifična za model. Na primer 4095 za Llama 2. |
MAX_CONCURRENT_REQUESTS |
Največje število sočasnih zahtev, ki jih dovoljuje nameščena končna točka. Nove zahteve, ki presegajo to omejitev, bodo takoj sprožile napako preobremenjenosti modela, da se prepreči nizka zakasnitev za trenutne zahteve za obdelavo. | 128 (privzeto TGI). Ta nastavitev vam omogoča, da pridobite visoko prepustnost za različne primere uporabe, vendar bi morali pripeti, kot je primerno, da ublažite napake časovne omejitve klica SageMaker. |
Strežnik TGI uporablja neprekinjeno serijsko obdelavo, ki dinamično združuje sočasne zahteve skupaj, da deli enoten prehod sklepanja po modelu naprej. Obstajata dve vrsti prehodov naprej: predizpolnjevanje in dekodiranje. Vsaka nova zahteva mora zagnati en sam prehod vnaprejšnjega polnjenja, da napolni predpomnilnik KV za žetone vhodnega zaporedja. Ko je predpomnilnik KV napolnjen, prehod za dekodiranje naprej izvede predvidevanje enega naslednjega žetona za vse paketne zahteve, ki se iterativno ponavlja, da se ustvari izhodno zaporedje. Ko so nove zahteve poslane strežniku, mora naslednji korak dekodiranja počakati, da se lahko izvede korak predizpolnjevanja za nove zahteve. To se mora zgoditi, preden so te nove zahteve vključene v naslednje neprekinjeno paketne korake dekodiranja. Zaradi omejitev strojne opreme neprekinjeno pakiranje, ki se uporablja za dekodiranje, morda ne bo vključevalo vseh zahtev. Na tej točki zahteve vstopijo v čakalno vrsto za obdelavo in zakasnitev sklepanja se začne znatno povečevati z le manjšim povečanjem prepustnosti.
Analizo primerjalne analize zakasnitve LLM je mogoče ločiti na zakasnitev vnaprejšnjega polnjenja, zakasnitev dekodiranja in zakasnitev čakalne vrste. Čas, ki ga porabi vsaka od teh komponent, je po naravi bistveno drugačen: vnaprejšnje izpolnjevanje je enkraten izračun, dekodiranje se izvede enkrat za vsak žeton v izhodnem zaporedju, čakalna vrsta pa vključuje procese pakiranja strežnika. Ko se obdeluje več sočasnih zahtev, postane težko ločiti zakasnitve iz vsake od teh komponent, ker zakasnitve, ki jih ima katera koli dana zahteva odjemalca, vključujejo zakasnitve v čakalni vrsti, ki jih poganja potreba po vnaprejšnjem izpolnjevanju novih sočasnih zahtev, kot tudi zakasnitve v čakalni vrsti, ki jih poganja vključitev zahteve v postopkih paketnega dekodiranja. Zaradi tega se ta objava osredotoča na zakasnitev obdelave od konca do konca. Koleno na krivulji zakasnitev-prepustnost se pojavi na točki nasičenosti, kjer se zakasnitve v čakalni vrsti začnejo znatno povečevati. Ta pojav se pojavi pri katerem koli strežniku za sklepanje modelov in ga poganjajo specifikacije pospeševalnika.
Pogoste zahteve med uvajanjem vključujejo izpolnjevanje najmanjše zahtevane prepustnosti, največje dovoljene zakasnitve, najvišjega stroška na uro in najvišjega stroška za ustvarjanje 1 milijona žetonov. Te zahteve bi morali pogojevati s koristnimi obremenitvami, ki predstavljajo zahteve končnih uporabnikov. Zasnova, ki izpolnjuje te zahteve, mora upoštevati številne dejavnike, vključno s posebno arhitekturo modela, velikostjo modela, vrstami primerkov in številom primerkov (vodoravno skaliranje). V naslednjih razdelkih se osredotočamo na uvajanje končnih točk, da zmanjšamo zakasnitev, povečamo prepustnost in zmanjšamo stroške. Ta analiza upošteva 512 skupnih žetonov in 256 izhodnih žetonov.
Zmanjšajte zakasnitev
Zakasnitev je pomembna zahteva v številnih primerih uporabe v realnem času. V naslednji tabeli si ogledamo najmanjšo zakasnitev za vsak model in vsako vrsto primerka. Z nastavitvijo lahko dosežete minimalno zakasnitev MAX_CONCURRENT_REQUESTS = 1.
| Najmanjša zakasnitev (ms/žeton) | |||||
| ID modela | ml.g5.2xvelik | ml.g5.12xvelik | ml.g5.48xvelik | ml.p4d.24xvelika | ml.p4de.24xvelik |
| Lama 2 7B | 33 | 17 | 18 | 20 | - |
| Lama 2 7B Klepet | 33 | 17 | 18 | 20 | - |
| Lama 2 13B | - | 22 | 23 | 23 | - |
| Lama 2 13B Klepet | - | 23 | 23 | 23 | - |
| Lama 2 70B | - | - | 57 | 43 | - |
| Lama 2 70B Klepet | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Mistral 7B Instruct | 35 | - | - | - | - |
| Mixtral 8x7B | - | - | 33 | 27 | - |
| Falcon 7B | 33 | - | - | - | - |
| Falcon 7B Instruct | 33 | - | - | - | - |
| Falcon 40B | - | 53 | 33 | 27 | - |
| Falcon 40B Instruct | - | 53 | 33 | 28 | - |
| Falcon 180B | - | - | - | - | 42 |
| Falcon 180B Chat | - | - | - | - | 42 |
Če želite doseči minimalno zakasnitev za model, lahko uporabite naslednjo kodo, medtem ko zamenjate želeni ID modela in vrsto primerka:
Upoštevajte, da se številke zakasnitev spreminjajo glede na število vhodnih in izhodnih žetonov. Vendar pa postopek uvajanja ostaja enak, razen spremenljivk okolja MAX_INPUT_TOKENS in MAX_TOTAL_TOKENS. Tukaj so te spremenljivke okolja nastavljene tako, da pomagajo zagotoviti zahteve za zakasnitev končne točke, ker lahko večja vhodna zaporedja kršijo zahtevo za zakasnitev. Upoštevajte, da SageMaker JumpStart že zagotavlja druge optimalne spremenljivke okolja pri izbiri vrste primerka; na primer, uporaba ml.g5.12xlarge bo nastavila SM_NUM_GPUS do 4 v modelnem okolju.
Povečajte prepustnost
V tem razdelku povečamo število ustvarjenih žetonov na sekundo. To se običajno doseže pri največjem številu veljavnih sočasnih zahtev za model in vrsto primerka. V naslednji tabeli poročamo o prepustnosti, doseženi pri največji doseženi vrednosti sočasne zahteve, preden naletimo na časovno omejitev priklica SageMaker za katero koli zahtevo.
| Največja prepustnost (žetoni/s), sočasne zahteve | |||||
| ID modela | ml.g5.2xvelik | ml.g5.12xvelik | ml.g5.48xvelik | ml.p4d.24xvelika | ml.p4de.24xvelik |
| Lama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Lama 2 7B Klepet | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Lama 2 13B Klepet | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Lama 2 70B Klepet | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Mistral 7B Instruct | 986 (128) | - | - | - | - |
| Mixtral 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Falcon 7B | 1340 (128) | - | - | - | - |
| Falcon 7B Instruct | 1313 (128) | - | - | - | - |
| Falcon 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B Instruct | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Falcon 180B | - | - | - | - | 1100 (128) |
| Falcon 180B Chat | - | - | - | - | 1081 (128) |
Če želite doseči največjo zmogljivost za model, lahko uporabite naslednjo kodo:
Upoštevajte, da je največje število sočasnih zahtev odvisno od vrste modela, vrste primerka, največjega števila vhodnih žetonov in največjega števila izhodnih žetonov. Zato morate te parametre nastaviti pred nastavitvijo MAX_CONCURRENT_REQUESTS.
Upoštevajte tudi, da je uporabnik, ki ga zanima čim manjša zakasnitev, pogosto v nasprotju z uporabnikom, ki ga zanima maksimiranje prepustnosti. Prvega zanimajo odzivi v realnem času, medtem ko drugega zanima paketna obdelava, tako da je čakalna vrsta končne točke vedno nasičena, s čimer se zmanjša čas izpadov obdelave. Uporabniki, ki želijo povečati prepustnost glede na zahteve glede zakasnitve, so pogosto zainteresirani za delovanje na kolenu krivulje zakasnitev-prepustnost.
Zmanjšajte stroške
Prva možnost za zmanjšanje stroškov vključuje zmanjšanje stroškov na uro. S tem lahko uvedete izbrani model na instanci SageMaker z najnižjo ceno na uro. Za cene primerkov SageMaker v realnem času glejte Cene Amazon SageMaker. Na splošno je privzeti tip primerka za SageMaker JumpStart LLMs najcenejša možnost uvajanja.
Druga možnost za zmanjšanje stroškov vključuje zmanjšanje stroškov za ustvarjanje 1 milijona žetonov. To je preprosta preobrazba tabele, o kateri smo razpravljali prej, da bi povečali prepustnost, kjer lahko najprej izračunate čas v urah, ki je potreben za ustvarjanje 1 milijona žetonov (1e6 / prepustnost / 3600). Nato lahko ta čas pomnožite, da ustvarite 1 milijon žetonov s ceno na uro določenega primerka SageMaker.
Upoštevajte, da primerki z najnižjimi stroški na uro niso enaki kot primerki z najnižjimi stroški za ustvarjanje 1 milijona žetonov. Na primer, če so zahteve za priklic občasne, je primerek z najnižjo ceno na uro morda optimalen, medtem ko je v scenarijih dušenja najnižji strošek za ustvarjanje milijona žetonov morda bolj primeren.
Kompromis med tenzorsko vzporednico in multi-modelom
V vseh prejšnjih analizah smo razmišljali o uvedbi ene replike modela s tenzorsko vzporedno stopnjo, ki je enaka številu grafičnih procesorjev na vrsti primerka uvedbe. To je privzeto vedenje SageMaker JumpStart. Vendar, kot smo že omenili, lahko razdeljevanje modela izboljša zakasnitev in prepustnost modela le do določene meje, nad katero zahteve za komunikacijo med napravami prevladujejo nad časom izračuna. To pomeni, da je pogosto koristno uporabiti več modelov z nižjo stopnjo vzporednosti tenzorja na enem primerku namesto enega modela z višjo stopnjo vzporednosti tenzorja.
Tukaj razmestimo končne točke Llama 2 7B in 13B na primerke ml.p4d.24xlarge s stopnjami tenzorskega vzporednika (TP) 1, 2, 4 in 8. Zaradi jasnosti obnašanja modela vsaka od teh končnih točk naloži samo en model.
| . | Prepustnost (žetoni/s) | Zakasnitev (ms/žeton) | ||||||||||||||||||
| Sočasne zahteve | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| TP stopnja | Lama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Naše prejšnje analize so že pokazale znatne prednosti prepustnosti na instancah ml.p4d.24xlarge, kar pogosto pomeni boljšo zmogljivost v smislu stroškov za ustvarjanje 1 milijona žetonov v primerjavi z družino instanc g5 pod pogoji visoke obremenitve sočasnih zahtev. Ta analiza jasno dokazuje, da bi morali razmisliti o kompromisu med razčlenjevanjem modela in replikacijo modela znotraj enega primerka; to pomeni, da popolnoma razdeljen model običajno ni najboljša uporaba računalniških virov ml.p4d.24xlarge za družine modelov 7B in 13B. Pravzaprav za družino modelov 7B dobite najboljšo prepustnost za posamezno repliko modela s tenzorsko paralelno stopnjo 4 namesto 8.
Od tu lahko ekstrapolirate, da najvišja prepustna konfiguracija za model 7B vključuje tenzorsko paralelno stopnjo 1 z osmimi replikami modela, najvišja prepustna konfiguracija za model 13B pa je verjetno tenzorska paralelna stopnja 2 s štirimi modelskimi replikami. Če želite izvedeti več o tem, kako to doseči, glejte Z najnovejšimi funkcijami Amazon SageMaker znižajte stroške uvajanja modela v povprečju za 50 %, ki prikazuje uporabo končnih točk, ki temeljijo na komponentah sklepanja. Zaradi tehnik uravnoteženja obremenitve, usmerjanja strežnika in skupne rabe virov CPE morda ne boste v celoti dosegli izboljšav prepustnosti, ki so natančno enake številu replik, pomnoženemu s prepustnostjo za posamezno repliko.
Horizontalno skaliranje
Kot smo že omenili, ima vsaka uvedba končne točke omejitev števila sočasnih zahtev glede na število vhodnih in izhodnih žetonov ter vrsto primerka. Če to ne izpolnjuje vaše zahteve glede prepustnosti ali sočasne zahteve, lahko povečate obseg, da uporabite več kot en primerek za razporejeno končno točko. SageMaker samodejno izvede uravnoteženje obremenitve poizvedb med primerki. Naslednja koda na primer uvede končno točko, ki jo podpirajo trije primerki:
Naslednja tabela prikazuje povečanje prepustnosti kot faktor števila primerkov za model Llama 2 7B.
| . | . | Prepustnost (žetoni/s) | Zakasnitev (ms/žeton) | ||||||||||||||
| . | Sočasne zahteve | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Število primerov | Vrsta primerka | Število skupnih žetonov: 512, Število izhodnih žetonov: 256 | |||||||||||||||
| 1 | ml.g5.2xvelik | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xvelik | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xvelik | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Predvsem se koleno na krivulji zakasnitev-prepustnost premakne v desno, ker lahko višje število instanc obravnava večje število sočasnih zahtev znotraj končne točke z več instancami. Za to tabelo je vrednost sočasne zahteve za celotno končno točko in ne za število sočasnih zahtev, ki jih prejme vsak posamezen primerek.
Uporabite lahko tudi samodejno skaliranje, funkcijo za spremljanje vaših delovnih obremenitev in dinamično prilagajanje zmogljivosti za vzdrževanje stalne in predvidljive zmogljivosti po najnižji možni ceni. To presega obseg te objave. Če želite izvedeti več o samodejnem skaliranju, glejte Konfiguriranje končnih točk sklepanja samodejnega skaliranja v Amazon SageMaker.
Priklic končne točke s sočasnimi zahtevami
Recimo, da imate veliko skupino poizvedb, ki bi jih radi uporabili za ustvarjanje odgovorov iz razporejenega modela v pogojih visoke prepustnosti. Na primer, v naslednjem bloku kode sestavimo seznam 1,000 koristnih obremenitev, pri čemer vsaka koristna obremenitev zahteva generiranje 100 žetonov. Vsega skupaj zahtevamo generiranje 100,000 žetonov.
Pri pošiljanju velikega števila zahtev API-ju izvajalnega okolja SageMaker lahko pride do napak pri dušenju. Da bi to ublažili, lahko ustvarite izvajalnega odjemalca SageMaker po meri, ki poveča število poskusov ponovnega poskusa. Dobljeni predmet seje SageMaker lahko posredujete bodisi v JumpStartModel konstruktor oz sagemaker.predictor.retrieve_default če želite na že razporejeno končno točko pripeti nov napovedovalec. V naslednji kodi uporabljamo ta predmet seje pri uvajanju modela Llama 2 s privzetimi konfiguracijami SageMaker JumpStart:
Ta razporejena končna točka ima MAX_CONCURRENT_REQUESTS = 128 privzeto. V naslednjem bloku uporabljamo sočasno terminsko knjižnico za ponavljanje klicanja končne točke za vse obremenitve s 128 delovnimi nitmi. Končna točka bo obdelala največ 128 sočasnih zahtev in kadar koli zahteva vrne odgovor, bo izvajalec končni točki takoj poslal novo zahtevo.
Posledica tega je generiranje 100,000 skupnih žetonov s prepustnostjo 1255 žetonov/s na enem primerku ml.g5.2xlarge. Ta obdelava traja približno 80 sekund.
Upoštevajte, da se ta prepustna vrednost bistveno razlikuje od največje prepustnosti za Llama 2 7B na ml.g5.2xlarge v prejšnjih tabelah te objave (486 žetonov/s pri 64 sočasnih zahtevah). To je zato, ker vhodni koristni tovor uporablja 8 žetonov namesto 256, število izhodnih žetonov je 100 namesto 256, manjše število žetonov pa omogoča 128 sočasnih zahtev. To je zadnji opomnik, da so vse številke zakasnitve in prepustnosti odvisne od tovora! Spreminjanje števila žetonov koristne obremenitve bo vplivalo na procese pakiranja med streženjem modela, kar bo posledično vplivalo na nastajajoče čase predizpolnjevanja, dekodiranja in čakalne vrste za vašo aplikacijo.
zaključek
V tej objavi smo predstavili primerjalno analizo SageMaker JumpStart LLM, vključno z Llama 2, Mistral in Falcon. Predstavili smo tudi vodnik za optimizacijo zakasnitve, prepustnosti in stroškov za vašo konfiguracijo uvedbe končne točke. Začnete lahko tako, da zaženete pripadajoči zvezek za primerjavo primera uporabe.
O avtorjih
 Dr. Kyle Ulrich je uporabni znanstvenik pri ekipi Amazon SageMaker JumpStart. Njegovi raziskovalni interesi vključujejo skalabilne algoritme strojnega učenja, računalniški vid, časovne vrste, Bayesove neparametrične in Gaussove procese. Njegov doktorat je pridobil na Univerzi Duke in je objavil članke v NeurIPS, Cell in Neuron.
Dr. Kyle Ulrich je uporabni znanstvenik pri ekipi Amazon SageMaker JumpStart. Njegovi raziskovalni interesi vključujejo skalabilne algoritme strojnega učenja, računalniški vid, časovne vrste, Bayesove neparametrične in Gaussove procese. Njegov doktorat je pridobil na Univerzi Duke in je objavil članke v NeurIPS, Cell in Neuron.
 Dr. Vivek Madan je uporabni znanstvenik pri ekipi Amazon SageMaker JumpStart. Doktoriral je na Univerzi Illinois v Urbana-Champaign in bil podoktorski raziskovalec na Georgia Tech. Je aktiven raziskovalec strojnega učenja in oblikovanja algoritmov ter je objavil članke na konferencah EMNLP, ICLR, COLT, FOCS in SODA.
Dr. Vivek Madan je uporabni znanstvenik pri ekipi Amazon SageMaker JumpStart. Doktoriral je na Univerzi Illinois v Urbana-Champaign in bil podoktorski raziskovalec na Georgia Tech. Je aktiven raziskovalec strojnega učenja in oblikovanja algoritmov ter je objavil članke na konferencah EMNLP, ICLR, COLT, FOCS in SODA.
 Dr. Ashish Khetan je višji aplikativni znanstvenik pri Amazon SageMaker JumpStart in pomaga pri razvoju algoritmov strojnega učenja. Doktoriral je na Univerzi Illinois Urbana-Champaign. Je aktiven raziskovalec strojnega učenja in statističnega sklepanja ter je objavil številne članke na konferencah NeurIPS, ICML, ICLR, JMLR, ACL in EMNLP.
Dr. Ashish Khetan je višji aplikativni znanstvenik pri Amazon SageMaker JumpStart in pomaga pri razvoju algoritmov strojnega učenja. Doktoriral je na Univerzi Illinois Urbana-Champaign. Je aktiven raziskovalec strojnega učenja in statističnega sklepanja ter je objavil številne članke na konferencah NeurIPS, ICML, ICLR, JMLR, ACL in EMNLP.
 João Moura je višji strokovnjak za rešitve AI/ML pri AWS. João pomaga strankam AWS – od majhnih novoustanovljenih podjetij do velikih podjetij – pri učinkovitem usposabljanju in uvajanju velikih modelov ter širši gradnji platform ML na AWS.
João Moura je višji strokovnjak za rešitve AI/ML pri AWS. João pomaga strankam AWS – od majhnih novoustanovljenih podjetij do velikih podjetij – pri učinkovitem usposabljanju in uvajanju velikih modelov ter širši gradnji platform ML na AWS.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- :ima
- : je
- :ne
- :kje
- $GOR
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- Sposobna
- O meni
- nad
- plin
- pospeševalniki
- sprejem
- dostop
- doseganje
- Po
- Doseči
- doseže
- čez
- aktivacije
- aktivna
- prilagodijo
- Dodatne
- Poleg tega
- prilagodite
- Prednosti
- vplivajo
- po
- proti
- agregat
- AI / ML
- algoritem
- algoritmi
- uskladiti
- vsi
- omogočajo
- dovoljene
- omogoča
- sam
- že
- Prav tako
- Čeprav
- vedno
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- znesek
- an
- analize
- Analiza
- in
- Še ena
- kaj
- API
- uporaba
- uporabna
- pristop
- primerno
- približno
- približno
- Arhitektura
- SE
- AS
- povezan
- predpostavke
- At
- pripisujejo
- Poskusi
- pozornosti
- samodejno
- Na voljo
- povprečno
- izogniti
- AWS
- b
- tehtnice
- uravnoteženje
- pasovna širina
- temeljijo
- V bistvu
- šaržiranje
- Bajezijski
- BE
- ker
- postane
- pred
- vedenje
- zadaj
- počutje
- Verjemite
- merilo
- primerjalna analiza
- meril
- koristno
- koristi
- Prednosti
- BEST
- Boljše
- med
- Poleg
- Block
- Blog
- zavezuje
- široka
- splošno
- proračun
- izgradnjo
- vendar
- by
- predpomnilnik
- izračun
- izračuna
- se imenuje
- CAN
- Lahko dobiš
- zmožnost
- kapaciteta
- kape
- ki
- primeru
- primeri
- Vzrok
- celica
- nekatere
- spremenite
- spreminjanje
- lastnosti
- Izberite
- izbran
- jasnost
- jasno
- stranke
- Koda
- Komunikacija
- primerjate
- kompleksna
- deli
- celovito
- računanje
- računalniški
- računska moč
- izračuni
- Izračunajte
- računalnik
- Računalniška vizija
- sočasno
- stanje
- Pogoji
- konference
- konfiguracija
- Razmislite
- šteje
- meni
- omejitve
- porabi
- Vsebuje
- ozadje
- neprekinjeno
- stalno
- Ustrezno
- strošek
- stroški
- štetje
- CPU
- ustvarjajo
- kritično
- surovo
- Trenutna
- krivulja
- po meri
- Stranke, ki so
- datum
- Odločanje
- Odločitev
- dekodiranje
- zmanjša
- zmanjšuje
- namenjen
- privzeto
- opredeliti
- opredeljen
- Določa
- Stopnja
- izkazati
- dokazuje,
- odvisno
- Odvisno
- odvisno
- razporedi
- razporejeni
- uvajanja
- uvajanje
- razmestitve
- razpolaga
- globina
- Izpeljano
- opisano
- Oblikovanje
- želeno
- Podatki
- Podrobnosti
- Ugotovite,
- določa
- Razvoj
- naprava
- naprave
- drugačen
- težko
- zmanjšuje
- razpravlja
- razpravljali
- izrazit
- porazdeljena
- Ne
- prevladujejo
- dont
- odmore
- dr
- pogon
- vozi
- vožnjo
- 2
- Duke
- vojvodska univerza
- med
- dinamično
- vsak
- prej
- učinkovito
- učinkovito
- 8
- bodisi
- obsegajo
- srečanje
- konec koncev
- Končna točka
- Končne točke
- konča
- dovolj
- Vnesite
- podjetja
- Celotna
- okolje
- enako
- enako
- Napaka
- napake
- zlasti
- oceniti
- Eter (ETH)
- Tudi
- sčasoma
- Tudi vsak
- točno
- Primer
- presežena
- Razen
- izkazujejo
- obstaja
- drago
- izkušnje
- izkušen
- Razlaga
- raziskuje
- raziskuje
- izraz
- Dejstvo
- Faktor
- dejavniki
- FAIL
- sokol
- družine
- družina
- izvedljivo
- Feature
- Lastnosti
- Nekaj
- Slika
- končna
- končno
- Najdi
- iskanje
- prva
- fit
- Osredotočite
- Osredotoča
- po
- za
- Nekdanji
- Formula
- Naprej
- Fundacija
- štiri
- iz
- polno
- v celoti
- v osnovi
- nadalje
- Poleg tega
- Terminske pogodbe
- Gain
- zaslužek
- splošno
- ustvarjajo
- ustvarila
- ustvarja
- ustvarjajo
- generacija
- Georgia
- dobili
- dana
- Cilji
- dobro
- prisodil
- GPU
- Grafične kartice
- več
- raste
- Rast
- Garancija
- Guard
- vodi
- ročaj
- strojna oprema
- Imajo
- he
- glave
- močno
- pomoč
- Pomaga
- tukaj
- visoka
- na visoki ravni
- več
- najvišja
- njegov
- držite
- Horizontalno
- uro
- URE
- Kako
- Kako
- Vendar
- HTTPS
- i
- ICLR
- ID
- idealen
- idealno
- identificirati
- if
- Illinois
- takoj
- vpliv
- Vplivi
- uvoz
- Pomembno
- kar je pomembno
- izboljšanje
- Izboljšanje
- Izboljšave
- izboljšuje
- in
- vključujejo
- vključeno
- Vključno
- vključitev
- Dohodni
- Povečajte
- povečal
- Poveča
- narašča
- individualna
- vhod
- vhodi
- primer
- primerov
- Namesto
- zainteresirani
- interesi
- Vmesna
- v
- vključuje
- IT
- ITS
- jpg
- upravičeno
- tipke
- Otrok
- Kyle
- jezik
- velika
- Velika podjetja
- večja
- Največji
- Latenca
- pozneje
- Zadnji
- plast
- vodi
- UČITE
- učenje
- odhodu
- levo
- dolžina
- Knjižnica
- življenje
- kot
- Verjeten
- LIMIT
- Omejitev
- Limited
- Meje
- vrstica
- Seznam
- Llama
- obremenitev
- nalaganje
- kraj aktivnosti
- več
- Poglej
- nizka
- nižje
- najnižja
- stroj
- strojno učenje
- je
- vzdrževati
- Znamka
- več
- Povečajte
- maksimira
- maksimiranje
- največja
- Maj ..
- kar pomeni,
- pomeni
- meritve
- Mehanizem
- Mehanizmi
- Srečati
- Spomin
- omenjeno
- pol
- Metode
- morda
- milijonov
- zmanjšajo
- minimiziranje
- minimalna
- mladoletnika
- min
- Omiliti
- ML
- način
- Model
- modeli
- sodobna
- monitor
- več
- Najbolj
- več
- morajo
- Narava
- nujno
- potrebno
- Nimate
- NeurIPS
- Novo
- Naslednja
- št
- predvsem
- Upoštevajte
- opozoriti
- Številka
- številke
- predmet
- opažanja
- opazujejo
- opazovana
- pridobi
- Očitna
- pojavijo
- se pojavljajo
- Kvota
- of
- pogosto
- on
- ONE
- samo
- deluje
- Delovanje
- operacije
- optimalna
- Optimizirajte
- Možnost
- or
- Da
- Ostalo
- drugi
- drugače
- naši
- izhod
- več
- članki
- vzporedno
- parameter
- parametri
- zlasti
- mimo
- vozovnice
- vzorci
- pavza
- za
- opravlja
- performance
- opravlja
- Dr.
- pojav
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- plus
- Točka
- slaba
- naseljeno
- mogoče
- Prispevek
- moč
- Praktično
- pred
- Ravno
- napovedati
- Predvidljivo
- napoved
- Predictor
- raje
- predstavljeni
- preprečiti
- prejšnja
- prej
- Cena
- cenitev
- primarni
- Načela
- Prednost
- Postopek
- obdelani
- Procesi
- obravnavati
- proizvodnjo
- zaščito
- zagotavljajo
- če
- zagotavlja
- javno
- objavljeno
- Namen
- poizvedbe
- dvigniti
- Cene
- precej
- razmerje
- dosežejo
- pravo
- resnično življenje
- v realnem času
- Razlog
- prejme
- Priporočamo
- Priporočila
- zmanjša
- zmanjšuje
- glejte
- besedilu
- Režim
- režimi
- Razmerje
- Razmerja
- ostajajo
- Preostalih
- ostanki
- opomnik
- ponovi
- odgovori
- replikacija
- poročilo
- predstavljajo
- zahteva
- zahtevajo
- zahteva
- zahteva
- obvezna
- zahteva
- Zahteve
- zahteva
- Raziskave
- raziskovalec
- vir
- viri
- spoštovanje
- Odgovor
- odgovorov
- rezultat
- Rezultati
- vrne
- Pravica
- usmerjanje
- ROW
- Pravilo
- Run
- tek
- sagemaker
- Enako
- razširljive
- Lestvica
- skaliranje
- Scenarij
- scenariji
- Znanstvenik
- Obseg
- drugi
- sekund
- Oddelek
- oddelki
- glej
- videl
- izberite
- izbran
- izbiranje
- izbor
- pošljite
- pošiljanja
- višji
- Občutek
- poslan
- ločena
- Zaporedje
- Serija
- služil
- strežnik
- strežniki
- Storitve
- služijo
- Zasedanje
- nastavite
- nastavitev
- ostro
- brušenje
- Delite s prijatelji, znanci, družino in partnerji :-)
- delitev
- Izmene
- shouldnt
- je pokazala,
- Razstave
- pomemben
- bistveno
- Podoben
- Enostavno
- hkrati
- sam
- Velikosti
- majhna
- manj
- So
- Software
- rešitve
- nekaj
- vir
- specialist
- specifična
- specifikacije
- določeno
- La tienda de Love Monkey entregado a Enfermería Fitzroy, de convalecencia y casas de reposo
- hitrost
- po delih
- občasno
- standardna
- Začetek
- začel
- začne
- Ustanavljanjem
- Statistično
- dinamičnega ravnovesja
- Korak
- Koraki
- Še vedno
- stop
- študija
- kasneje
- precejšen
- taka
- primerna
- podpora
- Podprti
- sistem
- miza
- krojenje
- Bodite
- Takeaways
- meni
- skupina
- tech
- tehnike
- nagiba
- Izraz
- Pogoji
- Test
- kot
- da
- O
- Vir
- njihove
- POTEM
- Teoretični
- Teorija
- Tukaj.
- s tem
- zato
- te
- jih
- stvari
- ta
- tisti,
- 3
- skozi
- pretočnost
- čas
- Časovne serije
- krat
- do
- skupaj
- žeton
- Boni
- tudi
- Skupaj za plačilo
- tp
- sledenje
- Vlak
- prenos
- transferji
- Preoblikovanje
- transformator
- Res
- OBRAT
- dva
- tip
- Vrste
- tipično
- pod
- razumeli
- razumevanje
- univerza
- Uporaba
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- Uporabniška izkušnja
- Uporabniki
- uporablja
- uporabo
- uporabiti
- veljavno
- vrednost
- Vrednote
- variacije
- raznolikost
- preverjanje
- vsestranski
- zelo
- preko
- Vizija
- vs
- Počakaj
- želeli
- topla
- je
- način..
- načini
- we
- web
- spletne storitve
- Dobro
- so bili
- Kaj
- Kaj je
- kdaj
- kadar koli
- medtem ko
- ki
- medtem
- WHO
- bo
- z
- v
- brez
- delo
- delavec
- bi
- še
- Mehek
- jo
- Vaša rutina za
- zefirnet