Slika urednika
14. marca 2023 je OpenAI predstavil GPT-4, najnovejšo in najzmogljivejšo različico svojega jezikovnega modela.
V samo nekaj urah po izstrelitvi je GPT-4 osupnil ljudi, ko je spremenil a ročno narisano skico v funkcionalno spletno stran, opravljen pravosodni izpitin ustvarjanje natančnih povzetkov člankov v Wikipediji.
Prekaša tudi svojega predhodnika, GPT-3.5, pri reševanju matematičnih problemov in odgovarjanju na vprašanja, ki temeljijo na logiki in sklepanju.
ChatGPT, chatbot, ki je bil zgrajen na vrhu GPT-3.5 in objavljen v javnosti, je bil znan po tem, da je "haluciniral". Ustvaril bi odgovore, ki bi bili na videz pravilni, in bi branil svoje odgovore z "dejstvi", čeprav so bili obremenjeni z napakami.
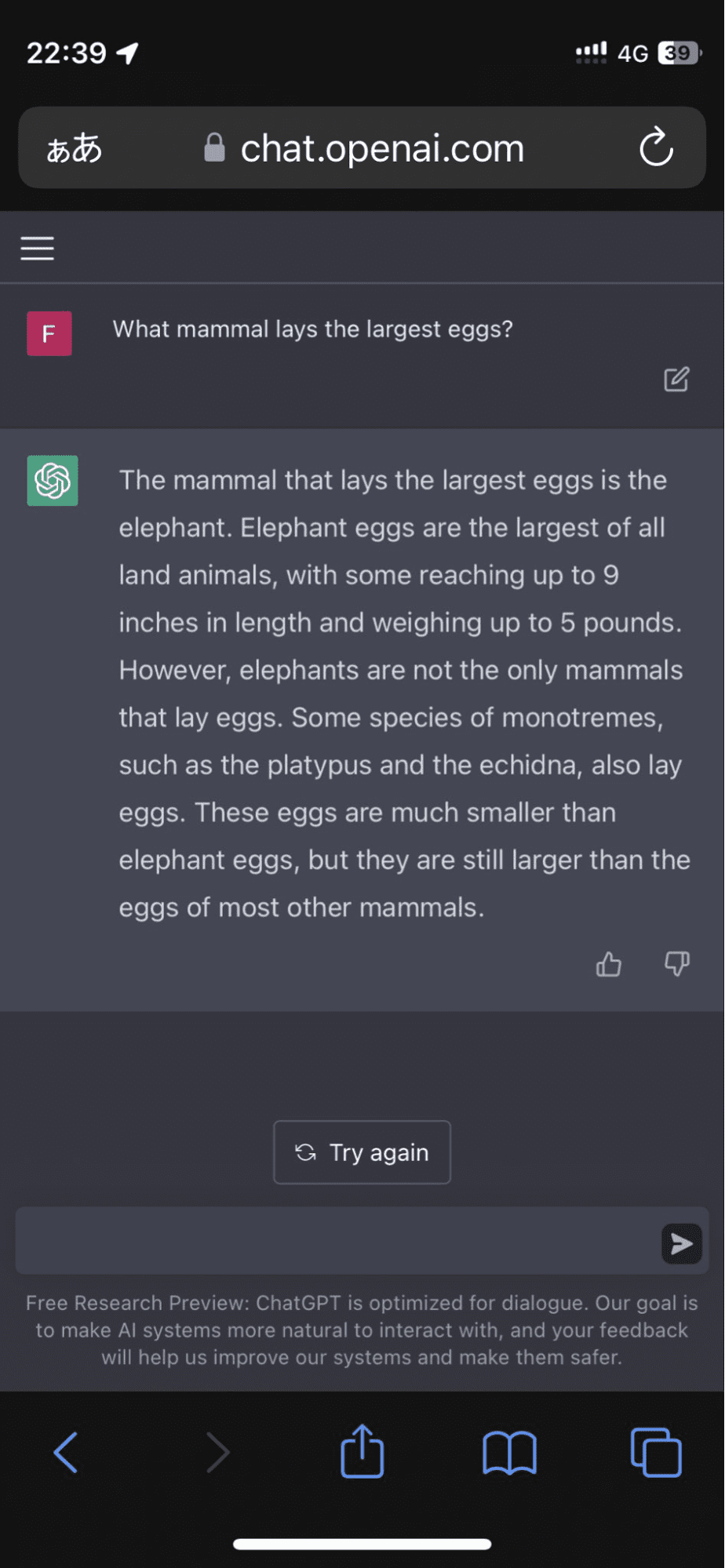
En uporabnik se je oglasil na Twitterju, potem ko je model vztrajal, da so slonja jajca največja od vseh kopenskih živali:
Slika iz FioraAeterna
In tu se ni ustavilo. Algoritem je nato podkrepil svoj odgovor z izmišljenimi dejstvi, ki so me za trenutek skoraj prepričala.
GPT-4 je bil na drugi strani usposobljen za "haluciniranje" manj pogosto. Najnovejši model OpenAI je težje pretentati in ne samozavestno ustvarja laži tako pogosto.
Kot podatkovni znanstvenik moje delo zahteva, da najdem ustrezne vire podatkov, vnaprej obdelam velike nabore podatkov in zgradim zelo natančne modele strojnega učenja, ki spodbujajo poslovno vrednost.
Velik del svojega dneva porabim za pridobivanje podatkov iz različnih formatov datotek in njihovo združevanje na enem mestu.
Potem ko je bil ChatGPT prvič uveden novembra 2022, sem se obrnil na klepetalni robot za nekaj navodil glede svojih dnevnih delovnih tokov. Orodje sem uporabil, da sem prihranil količino časa, porabljenega za manjše delo – da sem se lahko namesto tega osredotočil na nove zamisli in ustvarjanje boljših modelov.
Ko je bil GPT-4 izdan, me je zanimalo, ali bo to kaj spremenilo pri delu, ki ga opravljam. Ali je imela uporaba GPT-4 kakšne pomembne koristi v primerjavi z njegovimi predhodniki? Ali bi mi pomagalo prihraniti več časa, kot sem ga že z GPT-3.5?
V tem članku vam bom pokazal, kako uporabljam ChatGPT za avtomatizacijo podatkovnih tokov dela.
Ustvaril bom enake pozive in jih vložil v GPT-4 in GPT-3.5, da vidim, ali prvi res deluje bolje in prihrani več časa.
Če želite slediti vsemu, kar počnem v tem članku, morate imeti dostop do GPT-4 in GPT-3.5.
GPT-3.5
GPT-3.5 je javno dostopen na spletni strani OpenAI. Preprosto se pomaknite do https://chat.openai.com/auth/login, izpolnite zahtevane podatke in imeli boste dostop do jezikovnega modela:
Slika iz ChatGPT
GPT-4
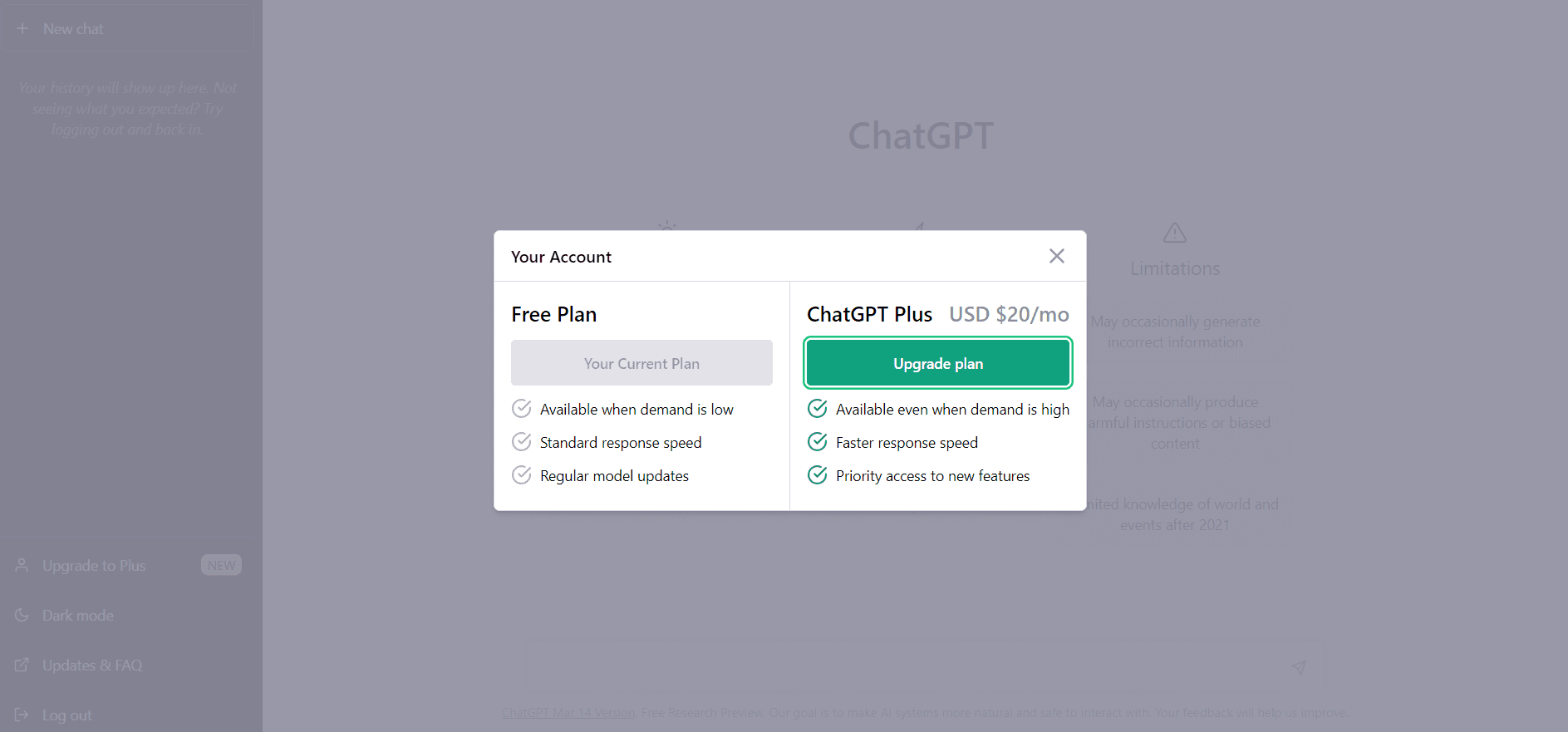
GPT-4 pa je trenutno skrit za plačilnim zidom. Za dostop do modela morate nadgraditi na ChatGPTPlus s klikom na »Nadgradi na Plus«.
Obstaja mesečna naročnina v višini 20 $/mesec, ki jo lahko kadar koli prekličete:
Slika iz ChatGPT
Če ne želite plačevati mesečne naročnine, se lahko tudi pridružite Čakalna lista za API za GPT-4. Ko dobite dostop do API-ja, lahko sledite ta vodnik za uporabo v Pythonu.
Nič hudega, če trenutno nimate dostopa do GPT-4.
Še vedno lahko sledite tej vadnici z brezplačno različico ChatGPT, ki v ozadju uporablja GPT-3.5.
1. Vizualizacija podatkov
Pri izvajanju raziskovalne analize podatkov mi generiranje hitre vizualizacije v Pythonu pogosto pomaga bolje razumeti nabor podatkov.
Na žalost lahko ta naloga postane neverjetno zamudna - še posebej, če ne poznate prave sintakse, ki bi jo uporabili za dosego želenega rezultata.
Pogosto se zalotim, da iščem po Seabornovi obsežni dokumentaciji in uporabljam StackOverflow za ustvarjanje enega samega grafa Python.
Poglejmo, ali lahko ChatGPT pomaga rešiti to težavo.
Uporabili bomo Sladkorna bolezen Pima Indijancev nabor podatkov v tem razdelku. Nabor podatkov lahko prenesete, če želite slediti rezultatom, ki jih ustvari ChatGPT.
Ko prenesemo nabor podatkov, ga naložimo v Python s knjižnico Pandas in natisnemo glavo podatkovnega okvira:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
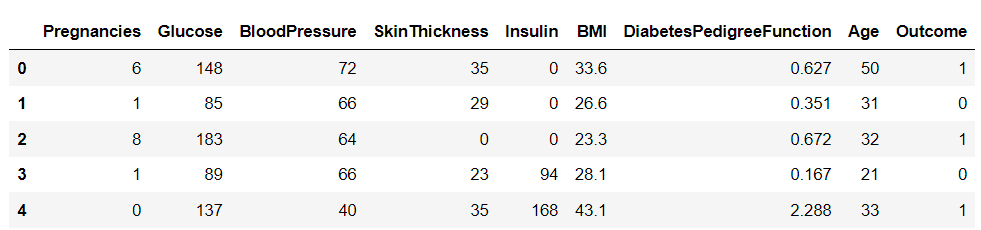
V tem naboru podatkov je devet spremenljivk. Ena od njih, »Izid«, je ciljna spremenljivka, ki nam pove, ali bo oseba razvila sladkorno bolezen. Preostale so neodvisne spremenljivke, ki se uporabljajo za napovedovanje izida.
V redu! Zato želim videti, katera od teh spremenljivk vpliva na to, ali bo oseba razvila sladkorno bolezen.
Da bi to dosegli, lahko ustvarimo gručast palični grafikon za vizualizacijo spremenljivke »Diabetes« v vseh odvisnih spremenljivkah v naboru podatkov.
To je pravzaprav zelo enostavno kodirati, a začnimo preprosto. Ko bomo napredovali skozi članek, bomo prešli na bolj zapletene pozive.
Vizualizacija podatkov z GPT-3.5
Ker imam plačano naročnino na ChatGPT, mi orodje omogoča izbiro osnovnega modela, ki ga želim uporabiti vsakič, ko do njega dostopam.
Izbral bom GPT-3.5:
Slika iz ChatGPT Plus
Če nimate naročnine, lahko uporabite brezplačno različico ChatGPT, saj chatbot privzeto uporablja GPT-3.5.
Zdaj pa vnesite naslednji poziv za ustvarjanje vizualizacije z uporabo nabora podatkov o sladkorni bolezni:
Imam nabor podatkov z 8 neodvisnimi spremenljivkami in 1 odvisno spremenljivko. Odvisna spremenljivka "Izid" nam pove, ali bo oseba razvila sladkorno bolezen.
Za napoved tega izida se uporabljajo neodvisne spremenljivke "Nosečnosti", "Glukoza", "Krvni tlak", "Debelina kože", "Insulin", "BMI", "DiabetesPedigreeFunction" in "Starost".
Ali lahko ustvarite kodo Python za vizualizacijo vseh teh neodvisnih spremenljivk glede na rezultat? Izhod mora biti en palični grafikon v gručah, ki je obarvan s spremenljivko »Izid«. Skupaj mora biti 16 vrstic, 2 za vsako neodvisno spremenljivko.
Tukaj je odgovor modela na zgornji poziv:
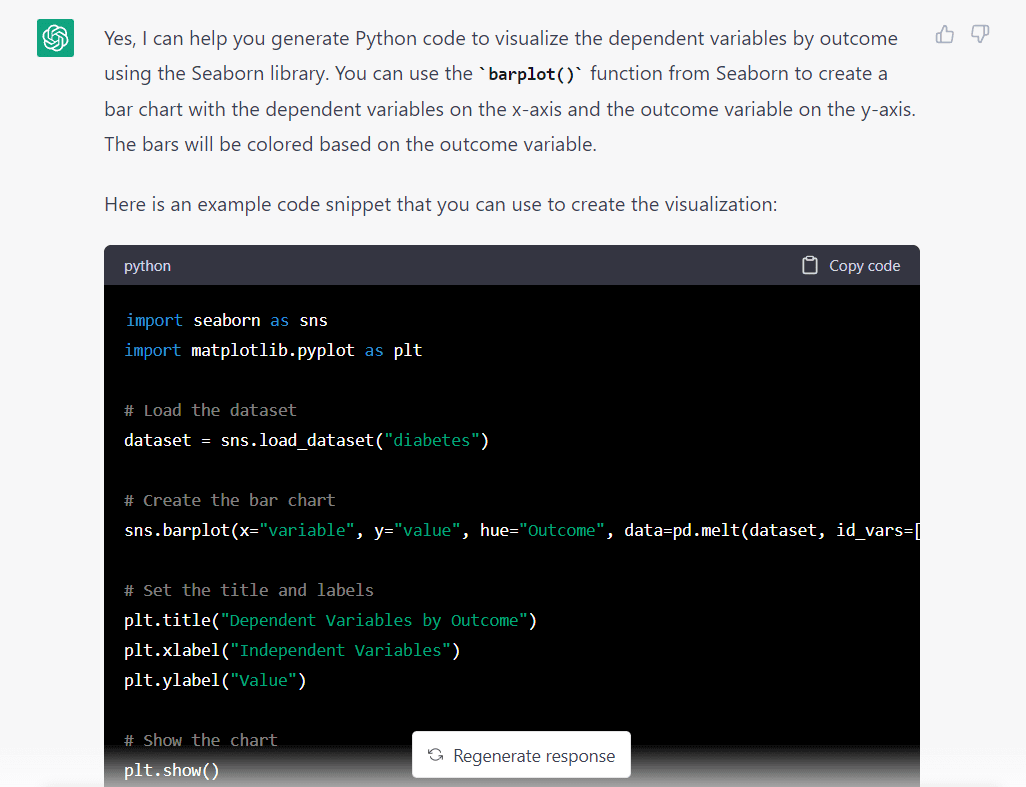
Ena stvar, ki takoj izstopa, je, da je model predvideval, da želimo uvoziti nabor podatkov iz Seaborna. Verjetno je to domneval, ker smo ga prosili za uporabo knjižnice Seaborn.
To ni velika težava, spremeniti moramo le eno vrstico, preden zaženemo kode.
Tukaj je celoten delček kode, ki ga je ustvaril GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
To lahko kopirate in prilepite v svoj Python IDE.
Tukaj je rezultat, ustvarjen po zagonu zgornje kode:
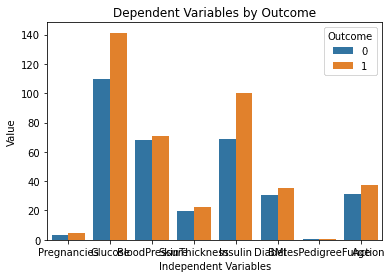
Ta grafikon je videti popoln! Točno tako sem si zamislil, ko sem vtipkal poziv v ChatGPT.
Ena težava, ki izstopa, pa je, da se besedilo na tem grafikonu prekriva. Model bom vprašal, ali nam lahko pomaga popraviti to, tako da vnesem naslednji poziv:
Algoritem je razložil, da lahko to prekrivanje preprečimo tako, da zasukamo oznake grafikona ali prilagodimo velikost figure. Ustvaril je tudi novo kodo, ki nam bo to pomagala doseči.
Zaženimo to kodo, da vidimo, ali nam daje želene rezultate:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
Zgornje vrstice kode bi morale ustvariti naslednje rezultate:
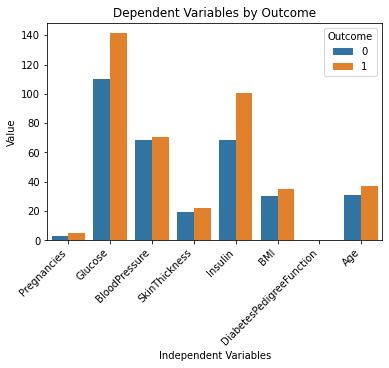
To izgleda super!
Zdaj veliko bolje razumem nabor podatkov, če preprosto pogledam ta grafikon. Zdi se, kot da imajo ljudje z višjo ravnjo glukoze in insulina večjo verjetnost, da bodo zboleli za sladkorno boleznijo.
Upoštevajte tudi, da nam spremenljivka »DiabetesPedigreeFunction« v tem grafikonu ne daje nobenih informacij. To je zato, ker je funkcija v manjšem merilu (med 0 in 2.4). Če želite še naprej eksperimentirati s ChatGPT, ga lahko pozovete, da ustvari več podgrafov v enem grafikonu in tako reši to težavo.
Vizualizacija podatkov z GPT-4
Zdaj pa dajmo iste pozive v GPT-4, da vidimo, ali bomo prejeli drugačen odgovor. Izbral bom model GPT-4 znotraj ChatGPT in vnesel isti poziv kot prej:
Opazite, kako GPT-4 ne predvideva, da bomo uporabljali podatkovni okvir, ki je vgrajen v Seaborn.
Pove nam, da bo za izdelavo vizualizacije uporabil podatkovni okvir, imenovan »df«, kar je izboljšava odziva, ki ga ustvari GPT-3.5.
Tukaj je celotna koda, ki jo ustvari ta algoritem:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
Zgornja koda bi morala ustvariti naslednji izris:
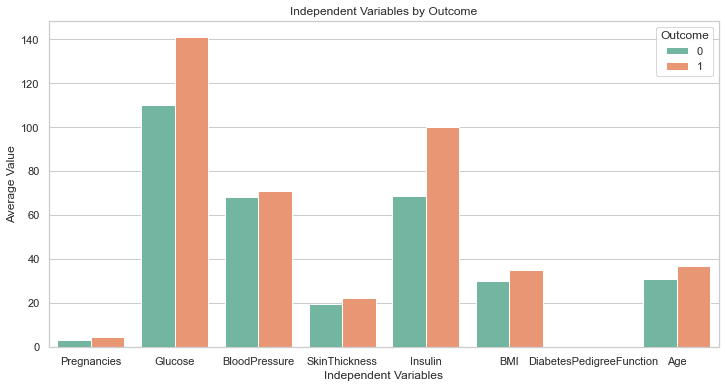
To je popolno!
Čeprav tega nismo zahtevali, je GPT-4 vključil vrstico kode za povečanje velikosti ploskve. Vse oznake na tem grafikonu so jasno vidne, zato se nam ni treba vrniti in spremeniti kode, kot smo to storili prej.
To je korak nad odzivom, ki ga ustvari GPT-3.5.
Na splošno pa se zdi, da sta GPT-3.5 in GPT-4 učinkovita pri ustvarjanju kode za izvajanje nalog, kot sta vizualizacija in analiza podatkov.
Pomembno je upoštevati, da ker ne morete naložiti podatkov v vmesnik ChatGPT, morate modelu zagotoviti natančen opis vašega nabora podatkov za optimalne rezultate.
2. Delo z dokumenti PDF
Čeprav to ni običajen primer uporabe v znanosti o podatkih, sem moral enkrat izvleči besedilne podatke iz več sto datotek PDF, da sem zgradil model analize razpoloženja. Podatki so bili nestrukturirani in porabil sem veliko časa za njihovo ekstrahiranje in predhodno obdelavo.
Pogosto sodelujem tudi z raziskovalci, ki berejo in ustvarjajo vsebine o aktualnih dogodkih v določenih panogah. Biti morajo na tekočem z novicami, razčlenjevati poročila podjetij in brati o možnih trendih v industriji.
Namesto branja 100 strani poročila podjetja, ali ni lažje preprosto izluščiti besede, ki vas zanimajo, in prebrati samo stavke, ki vsebujejo te ključne besede?
Če pa vas zanimajo trendi, lahko ustvarite avtomatiziran potek dela, ki prikaže rast ključnih besed skozi čas, namesto da ročno pregledujete vsako poročilo.
V tem razdelku bomo uporabili ChatGPT za analizo datotek PDF v Pythonu. Od chatbota bomo zahtevali, da izvleče vsebino datoteke PDF in jo zapiše v besedilno datoteko.
Ponovno bo to storjeno z uporabo obeh GPT-3.5 in GPT-4, da se ugotovi, ali obstaja pomembna razlika v ustvarjeni kodi.
Branje datotek PDF z GPT-3.5
V tem razdelku bomo analizirali javno dostopen dokument PDF z naslovom Kratek uvod v strojno učenje za inženirje. Ne pozabite prenesti te datoteke, če želite kodirati ta razdelek.
Najprej prosimo algoritem, naj ustvari kodo Python za ekstrahiranje podatkov iz tega dokumenta PDF in njihovo shranjevanje v besedilno datoteko:
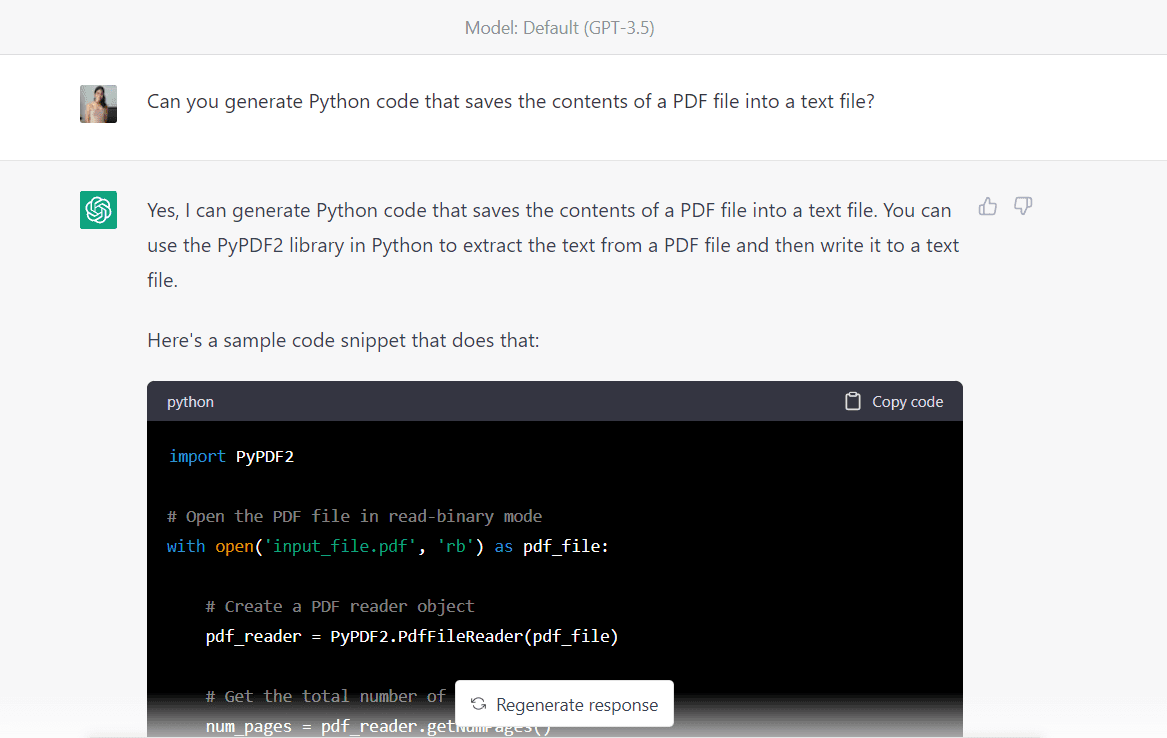
Tukaj je celotna koda, ki jo zagotavlja algoritem:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Opomba: ne pozabite spremeniti imena datoteke PDF v tisto, ki ste jo shranili, preden zaženete to kodo.)
Na žalost sem po zagonu kode, ki jo je ustvaril GPT-3.5, naletel na to napako unicode:

Vrnimo se k GPT-3.5 in poglejmo, ali lahko model to popravi:
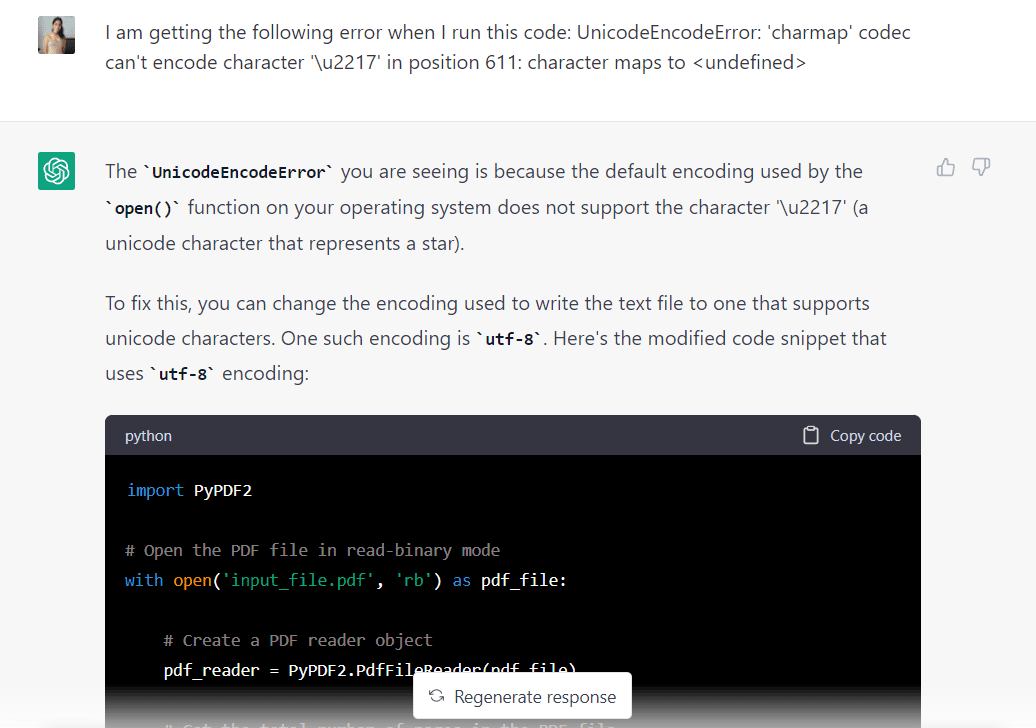
Napako sem prilepil v ChatGPT in model je odgovoril, da jo je mogoče popraviti s spremembo uporabljenega kodiranja v »utf-8«. Prav tako mi je dal nekaj spremenjene kode, ki je odražala to spremembo:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Ta koda se je uspešno izvedla in ustvarila besedilno datoteko z imenom »output_file.txt«. Vsa vsebina v dokumentu PDF je zapisana v datoteko:
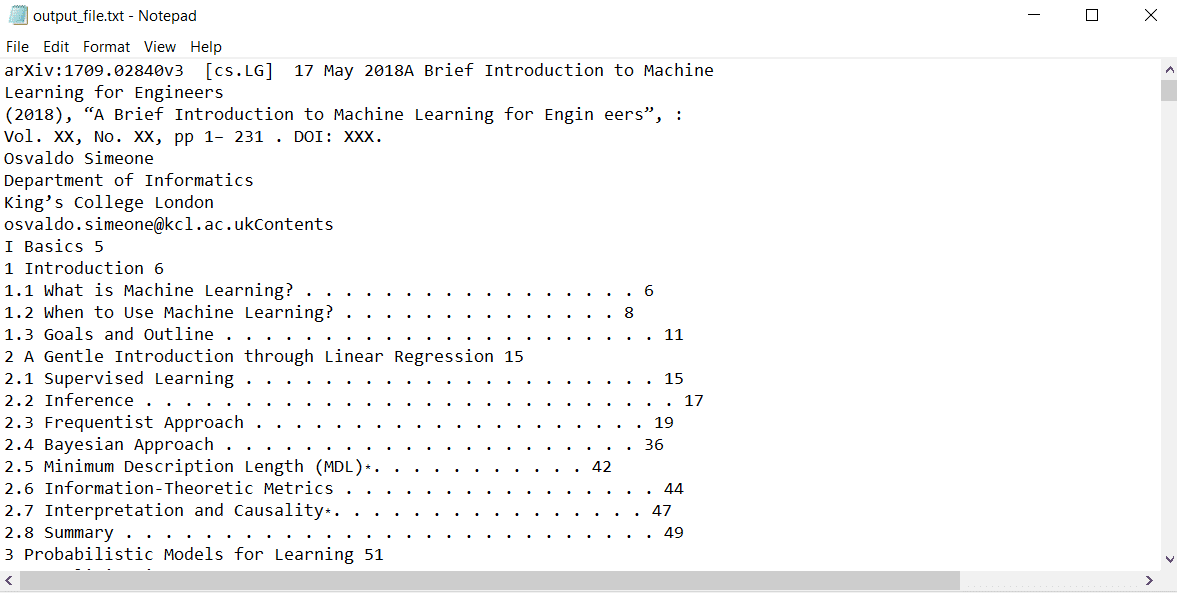
Branje datotek PDF z GPT-4
Sedaj bom isti poziv prilepil v GPT-4, da vidim, kaj model ponuja:
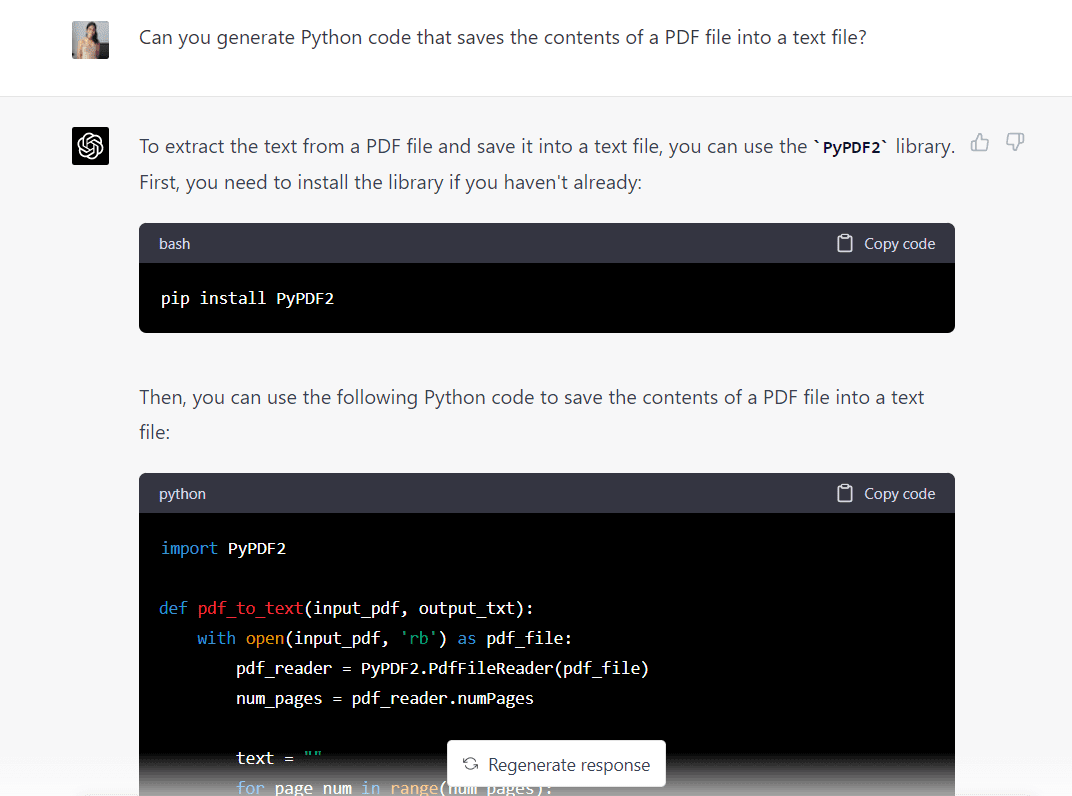
Tukaj je celotna koda, ki jo ustvari GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Poglej to!
Za razliko od GPT-3.5 je GPT-4 že določil, da je treba za odpiranje besedilne datoteke uporabiti kodiranje "utf-8". Ni se nam treba vrniti in spremeniti kode, kot smo to storili prej.
Koda, ki jo zagotavlja GPT-4, bi se morala uspešno izvesti in v besedilni datoteki, ki je bila ustvarjena, bi morali videti vsebino dokumenta PDF.
Obstaja veliko drugih tehnik, ki jih lahko uporabite za avtomatizacijo dokumentov PDF s Pythonom. Če želite to podrobneje raziskati, je tukaj nekaj drugih pozivov, ki jih lahko vnesete v ChatGPT:
- Ali lahko napišete kodo Python za združitev dveh datotek PDF?
- Kako lahko s Pythonom preštejem pojavitve določene besede ali fraze v dokumentu PDF?
- Ali lahko napišete kodo Python za ekstrahiranje tabel iz datotek PDF in njihovo pisanje v Excelu?
Predlagam, da nekaj od tega poskusite med prostim časom - presenečeni boste, kako hitro vam lahko GPT-4 pomaga opraviti nizka opravila, ki običajno trajajo več ur.
3. Pošiljanje avtomatiziranih e-poštnih sporočil
Ure delovnega tedna porabim za branje in odgovarjanje na e-pošto. Ne samo, da je to zamudno, ampak je lahko tudi neverjetno stresno ostati na tekočem z e-poštnimi sporočili, ko lovite tesne roke.
In čeprav ne morete doseči, da ChatGPT napiše vsa vaša e-poštna sporočila (želim si), ga lahko še vedno uporabite za pisanje programov, ki pošiljajo načrtovana e-poštna sporočila ob določenem času, ali spreminjanje ene same e-poštne predloge, ki jo je mogoče poslati več osebam .
V tem razdelku bomo dobili GPT-3.5 in GPT-4, ki nam bosta pomagala napisati skript Python za pošiljanje samodejnih e-poštnih sporočil.
Pošiljanje samodejne e-pošte z GPT-3.5
Najprej vnesite naslednji poziv za ustvarjanje kod za pošiljanje samodejnega e-poštnega sporočila:
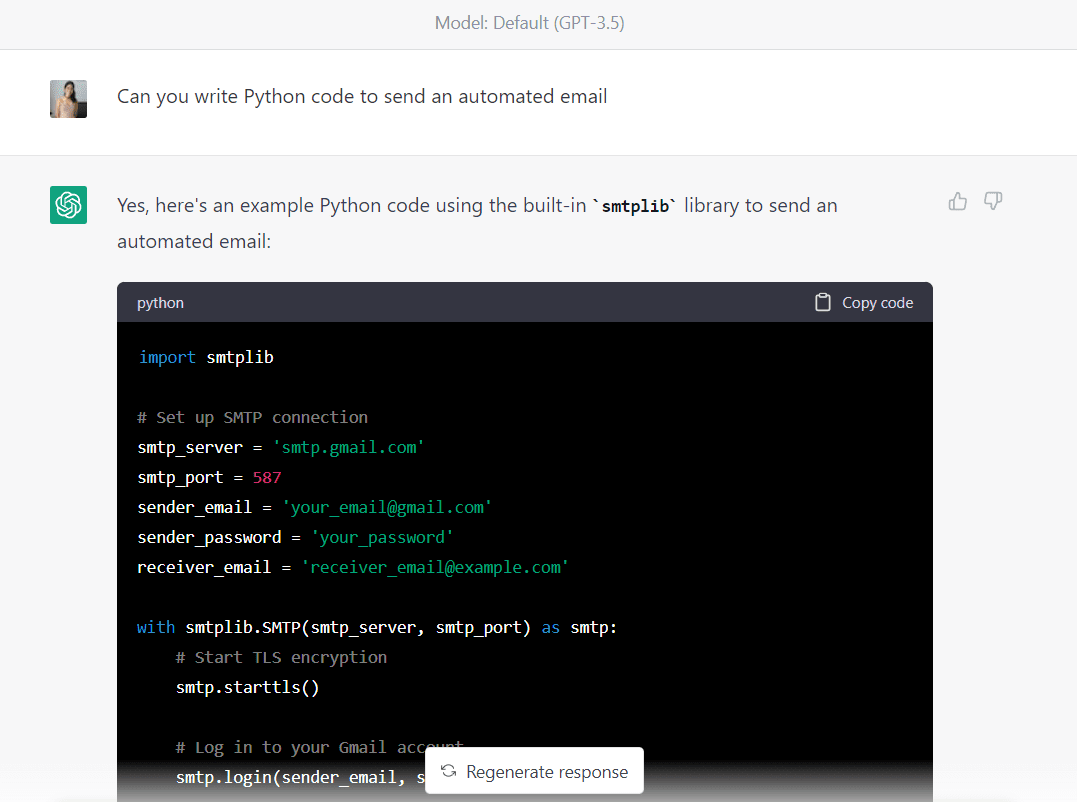
Tukaj je celotna koda, ki jo ustvari GPT-3.5 (prepričajte se, da ste spremenili e-poštne naslove in geslo, preden zaženete to kodo):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Na žalost se ta koda zame ni uspešno izvedla. Ustvaril je naslednjo napako:
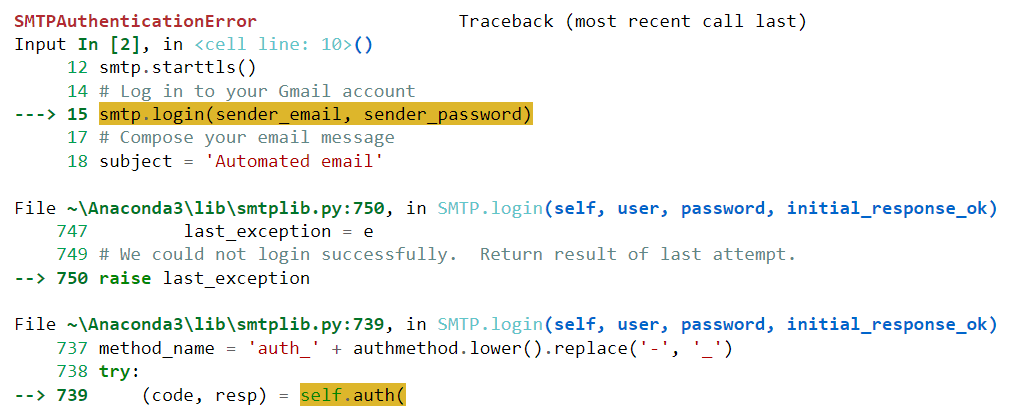
Prilepimo to napako v ChatGPT in poglejmo, ali nam jo lahko model pomaga rešiti:

V redu, torej je algoritem pokazal nekaj razlogov, zakaj lahko naletimo na to napako.
Zanesljivo vem, da so bili moji podatki za prijavo in e-poštni naslovi veljavni in da v kodi ni bilo tipkarskih napak. Te razloge je torej mogoče izključiti.
GPT-3.5 prav tako nakazuje, da bi to težavo lahko rešili z dovoljevanjem manj varnih aplikacij.
Če poskusite to, pa v svojem Google Računu ne boste našli možnosti, ki bi omogočila dostop manj varnim aplikacijam.
To je zato, ker Google nič več omogoča uporabnikom, da dovolijo manj varne aplikacije zaradi varnostnih razlogov.
Nazadnje GPT-3.5 omenja tudi, da je treba ustvariti geslo za aplikacijo, če je omogočeno dvofaktorsko preverjanje pristnosti.
Nimam omogočene dvofaktorske avtentikacije, zato bom (začasno) opustil ta model in videl, ali ima GPT-4 rešitev.
Pošiljanje samodejne e-pošte z GPT-4
V redu, torej če vnesete isti poziv v GPT-4, boste ugotovili, da algoritem ustvari kodo, ki je zelo podobna tisti, ki nam jo je dal GPT-3.5. To bo povzročilo isto napako, na katero smo naleteli prej.
Poglejmo, ali nam GPT-4 lahko pomaga odpraviti to napako:

Predlogi GPT-4 so zelo podobni tistemu, kar smo videli prej.
Vendar pa nam tokrat ponuja korak za korakom razčlenitev, kako doseči vsak korak.
GPT-4 predlaga tudi ustvarjanje gesla za aplikacijo, zato ga poskusimo.
Najprej obiščite svoj Google Račun, se pomaknite do »Varnost« in omogočite dvostopenjsko preverjanje pristnosti. Nato bi morali v istem razdelku videti možnost, ki pravi »Gesla za aplikacije«.
Kliknite nanj in prikazal se bo naslednji zaslon:
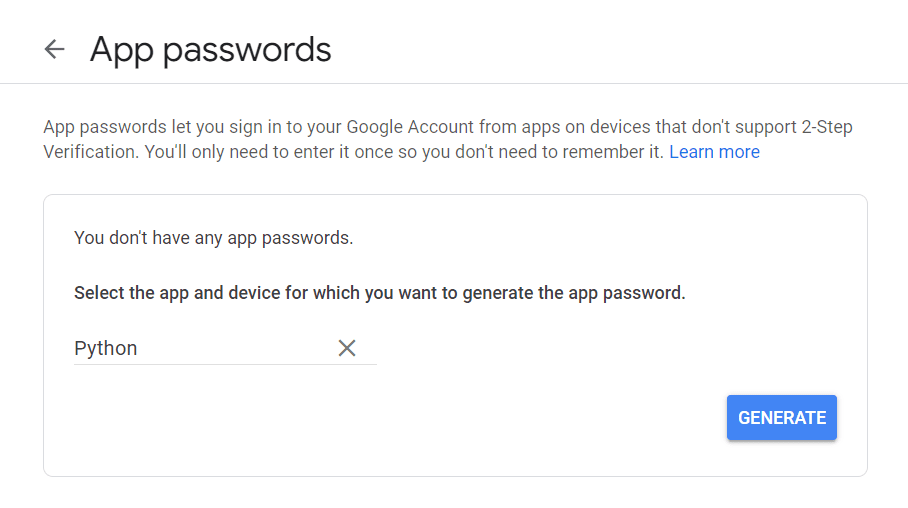
Vnesete lahko poljubno ime in kliknete »Ustvari«.
Prikaže se novo geslo za aplikacijo.
Zamenjajte obstoječe geslo v kodi Python s tem geslom za aplikacijo in znova zaženite kodo:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Tokrat bi moralo delovati uspešno in vaš prejemnik bo prejel e-poštno sporočilo, ki je videti takole:
Perfect!
Zahvaljujoč ChatGPT smo uspešno poslali samodejno e-pošto s Pythonom.
Če želite narediti korak naprej, predlagam, da ustvarite pozive, ki vam omogočajo:
- Pošljite množično e-pošto več prejemnikom hkrati
- Pošljite načrtovana e-poštna sporočila na vnaprej določen seznam e-poštnih naslovov
- Prejemnikom pošljite prilagojeno e-pošto, ki je prilagojena njihovi starosti, spolu in lokaciji.
Nataša Selvaraj je samouk podatkovni znanstvenik s strastjo do pisanja. Z njo se lahko povežete na LinkedIn.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- : je
- $GOR
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- O meni
- nad
- dostop
- doseganje
- Račun
- natančna
- Doseči
- čez
- dejansko
- naslovi
- po
- algoritem
- vsi
- Dovoli
- omogoča
- že
- Čeprav
- znesek
- Analiza
- analizirati
- analiziranje
- in
- Živali
- odgovori
- API
- aplikacija
- zdi
- aplikacije
- SE
- članek
- AS
- domnevajo
- predpostavka
- At
- Preverjanje pristnosti
- avtomatizirati
- Avtomatizirano
- Na voljo
- povprečno
- nazaj
- Backend
- bar
- bari
- temeljijo
- BE
- ker
- postanejo
- pred
- zadaj
- Prednosti
- Boljše
- med
- bmi
- telo
- Dolgočasen
- Razčlenitev
- izgradnjo
- zgrajena
- poslovni
- by
- se imenuje
- CAN
- prekinjeno
- ne more
- Vzrok
- spremenite
- spreminjanje
- Graf
- chatbot
- ChatGPT
- jasno
- klik
- Koda
- COM
- prihajajo
- Skupno
- podjetje
- Podjetja
- dokončanje
- zapleten
- Skrbi
- samozavestno
- Connect
- povezava
- utrjevanje
- vsebina
- Vsebina
- potrditi
- bi
- ustvarjajo
- ustvaril
- Ustvarjanje
- Mandatno
- radovedna
- Trenutna
- Trenutno
- prilagodite
- meri
- vsak dan
- datum
- Analiza podatkov
- znanost o podatkih
- podatkovni znanstvenik
- vizualizacija podatkov
- nabor podatkov
- dan
- privzeto
- odvisno
- opis
- Podrobnosti
- Razvoj
- Sladkorna bolezen
- DID
- Razlika
- drugačen
- dokument
- Dokumentacija
- Dokumenti
- Ne
- tem
- dont
- prenesi
- pogon
- med
- vsak
- prej
- lažje
- Učinkovito
- Jajca
- bodisi
- slon
- E-naslov
- e-pošta
- omogočajo
- omogočena
- šifriranje
- Vnesite
- Napaka
- napake
- zlasti
- Eter (ETH)
- dogodki
- Tudi vsak
- vse
- točno
- Excel
- izvršiti
- obstoječih
- poskus
- razložiti
- Raziskovalne analize podatkov
- raziskuje
- obsežen
- ekstrakt
- Feature
- pristojbina
- Nekaj
- Slika
- file
- datoteke
- izpolnite
- Najdi
- prva
- fiksna
- Všita
- Osredotočite
- sledi
- po
- za
- Nekdanji
- brezplačno
- pogosto
- iz
- funkcionalno
- nadalje
- Spol
- ustvarjajo
- ustvarila
- ustvarja
- ustvarjajo
- dobili
- Daj
- daje
- gmail
- Go
- dogaja
- Rast
- Navodila
- vodi
- strani
- Imajo
- Glava
- pomoč
- Pomaga
- tukaj
- skrita
- več
- zelo
- Horizontalno
- URE
- Kako
- Kako
- Vendar
- HTTPS
- velika
- Stotine
- i
- Ideje
- takoj
- vpliv
- uvoz
- Pomembno
- Izboljšanje
- in
- vključeno
- Povečajte
- neverjetno
- Neodvisni
- industrij
- Industrija
- Podatki
- Namesto
- zainteresirani
- vmesnik
- Predstavitev
- vprašanje
- IT
- ITS
- Job
- pridružite
- KDnuggets
- Vedite
- Oznake
- Država
- jezik
- velika
- Največji
- Zadnji
- kosilo
- začela
- učenje
- Lets
- ravni
- Knjižnica
- kot
- Verjeten
- vrstica
- linije
- Seznam
- obremenitev
- kraj aktivnosti
- Pogledal
- si
- POGLEDI
- Sklop
- stroj
- strojno učenje
- je
- Znamka
- ročno
- več
- marec
- math
- matplotlib
- omenja
- Spoji
- Sporočilo
- morda
- način
- Model
- modeli
- spremembe
- spremenite
- Trenutek
- mesečno
- mesečno naročnino
- več
- Najbolj
- premikanje
- več
- Ime
- Krmarjenje
- Nimate
- Novo
- nova aplikacija
- Najnovejši
- novice
- znano
- november
- Številka
- predmet
- of
- Ok
- on
- ONE
- odprite
- OpenAI
- Optimalno
- Možnost
- Ostalo
- Rezultat
- Presega
- izhod
- Stran
- plačana
- pand
- strast
- Geslo
- gesla
- Plačajte
- ljudje
- opravlja
- izvajati
- oseba
- Kraj
- platon
- Platonova podatkovna inteligenca
- PlatoData
- plus
- potencial
- močan
- predhodnik
- napovedati
- precej
- preprečiti
- prej
- Tiskanje
- verjetno
- problem
- Težave
- programi
- Napredek
- zagotavljajo
- če
- javnega
- javno
- Python
- vprašanja
- Hitro
- hitro
- Preberi
- Bralec
- reading
- Razlogi
- prejeti
- prejemnikov
- odsevalo
- sprosti
- pomembno
- Preostalih
- poročilo
- Poročila
- obvezna
- zahteva
- raziskovalci
- odziva
- Odgovor
- povzroči
- Rezultati
- Run
- tek
- Enako
- Shrani
- Prihranki
- pravi
- Lestvica
- načrtovano
- Znanost
- Znanstvenik
- Zaslon
- morski rojen
- iskanje
- Oddelek
- zavarovanje
- varnost
- pošiljanja
- sentiment
- nastavite
- shouldnt
- Prikaži
- pomemben
- Podoben
- Enostavno
- preprosto
- saj
- sam
- Velikosti
- manj
- So
- Rešitev
- SOLVE
- Reševanje
- nekaj
- Viri
- specifična
- določeno
- preživeti
- porabljen
- stojala
- Začetek
- bivanje
- Korak
- Še vedno
- stop
- predmet
- naročnina
- Uspešno
- Predlaga
- primerna
- presenečen
- sintaksa
- prilagojene
- Bodite
- ob
- ciljna
- Naloga
- Naloge
- tehnike
- pove
- Predloga
- da
- O
- njihove
- Njih
- Tukaj.
- te
- stvar
- skozi
- čas
- zamudno
- Naslov
- z naslovom
- TLS
- do
- orodje
- vrh
- Skupaj za plačilo
- usposobljeni
- Trends
- Obračalni
- Navodila
- osnovni
- razumeli
- unicode
- nadgradnja
- us
- uporaba
- uporabnik
- Uporabniki
- navadno
- vrednost
- različica
- vidna
- obisk
- vizualizacija
- W
- hotel
- Spletna stran
- Kaj
- ali
- ki
- WHO
- Wikipedia
- bo
- z
- v
- beseda
- besede
- delo
- potek dela
- delovnih tokov
- deluje
- bi
- pisati
- pisanje
- pisni
- Vaša rutina za
- zefirnet