- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- : je
- 10
- 100
- 15%
- 2023
- 7
- a
- Sposobna
- čez
- Sprejem
- AI
- podobno
- vsi
- Čeprav
- med
- an
- in
- odgovori
- uporabna
- SE
- AS
- sprašuje
- vidiki
- pomočniki
- povezan
- At
- napad
- Napadi
- Na voljo
- stran
- BE
- počutje
- med
- milijardah
- izgradnjo
- podjetja
- vendar
- by
- CAN
- previdno
- ceo
- klepetalnice
- ChatGPT
- jasno
- zaprto
- Skupno
- Podjetja
- računalnik
- Skrb
- v zvezi
- Konferenca
- bi
- ustvarjajo
- Ustvarjanje
- kritično
- Trenutno
- cyber
- Datum
- izkazati
- Dokazano
- uvajanja
- podrobno
- Odkrivanje
- Razvoj
- drugačen
- digitalni
- odkril
- dr
- podjetja
- Celotna
- Tudi
- dokazi
- obstajajo
- obstoječih
- Izkoristite
- pridobivanje
- izredno
- zanimivo
- finančna
- finančne storitve
- prva
- osredotočena
- za
- iz
- nadalje
- pridobljeno
- dana
- Giving
- Igrišče
- Imajo
- skrita
- Poudarki
- gostila
- Kako
- Kako
- Vendar
- HTTPS
- HuggingFace
- Pomembno
- in
- povečal
- vedno
- Industrija
- obvesti
- Podatki
- varnost informacij
- pronicljiv
- Internet
- Invest
- vlaganjem
- IT
- jpg
- Ključne
- znanje
- znano
- jezik
- velika
- Velika podjetja
- kosilo
- vodi
- UČITE
- učenje
- manj
- malo
- stroj
- strojno učenje
- velika
- Maj ..
- merjenje
- milijoni
- Model
- modeli
- veliko
- Novo
- of
- on
- odprite
- open source
- or
- ven
- lastne
- Papir
- zabava
- Peter
- Mesta
- načrtovanje
- platon
- Platonova podatkovna inteligenca
- PlatoData
- mogoče
- potencialno
- močan
- priprava
- predstavljeni
- , ravnateljica
- zasebna
- zagotavljajo
- javno
- območje
- Oceniti
- podvojeno
- zahteva
- Raziskave
- raziskovalci
- razkrivajo
- tveganja
- Je dejal
- pravijo,
- Znanstveniki
- varnost
- Storitve
- nastavite
- shouldnt
- Prikaži
- manj
- pametna
- So
- nekaj
- vir
- Stage
- Start-up
- Storm
- študija
- uspeh
- Uspešno
- taka
- sprejeti
- pogovor
- ciljno
- ciljanje
- Naloge
- skupina
- Tehnologije
- Tehnologija
- Testiranje
- kot
- da
- O
- informacije
- UK
- svet
- njihove
- POTEM
- Tukaj.
- te
- jih
- mislim
- tretja
- ta
- letos
- krat
- do
- orodja
- prenese
- transformativno
- Uk
- razumevanje
- zavezujeta
- univerza
- uporaba
- Rabljeni
- uporablja
- vrednoti
- zelo
- Ranljivosti
- je
- način..
- we
- teden
- so bili
- ki
- široka
- Širok spekter
- bo
- z
- v
- brez
- delo
- telovaditi
- deluje
- svet
- zaskrbljujoče
- leto
- zefirnet
Več od Nanowerk
Sprostitev nove dobe barvno nastavljivih nano naprav – najmanjši vir svetlobe s preklopljivimi oblikovanimi barvami
Izvorno vozlišče: 2801585
Časovni žig: Avgust 3, 2023

'Čarobno' topilo ustvari močnejše tanke filme
Izvorno vozlišče: 1957849
Časovni žig: Februar 14, 2023
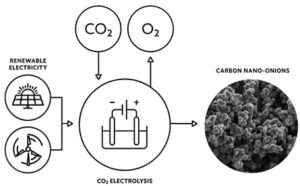
Ogljikove nanocevke lahko igrajo pomembno vlogo pri vezavi atmosferskega ogljikovega dioksida
Izvorno vozlišče: 2836729
Časovni žig: Avgust 21, 2023

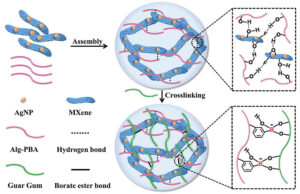
Antibakterijski povrhnjični senzorji na osnovi hidrogela MXene
Izvorno vozlišče: 2661017
Časovni žig: Maj 18, 2023
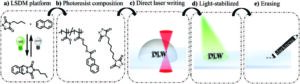
3D-tiski se pridružijo temni strani in izginejo
Izvorno vozlišče: 2903619
Časovni žig: September 27, 2023
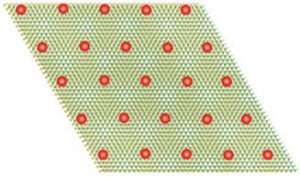
Ko material postane kvantni, se elektroni upočasnijo in tvorijo kristal
Izvorno vozlišče: 1975767
Časovni žig: Februar 23, 2023

Inženirji razvijajo učinkovit postopek za pridobivanje goriva iz ogljikovega dioksida
Izvorno vozlišče: 2963812
Časovni žig: Oktober 30, 2023