In 2021 и 2020, мы рассказали вам о новых возможностях в Амазонка Redshift которые упрощают, ускоряют и удешевляют анализ всех ваших данных и находят ценные и полезные идеи. Мы рады сообщить, что в 2022 году команда Amazon Redshift усердно работала. Мы работали в обратном направлении от требований клиентов и объявили о множестве новых функций, чтобы сделать анализ всех ваших данных проще, быстрее и экономичнее. В этом посте рассматриваются некоторые из этих новых функций.
Наша стратегия AWS в отношении данных и аналитики заключается в том, чтобы предоставить вам современная архитектура данных это поможет вам освободиться от хранилищ данных; иметь специально созданные данные, аналитику, машинное обучение (ML) и службы искусственного интеллекта, чтобы использовать правильный инструмент для правильной работы; и иметь открытые, управляемые, безопасные и полностью управляемые службы, чтобы сделать аналитику доступной для всех. В современной архитектуре данных AWS Amazon Redshift в качестве облачного хранилища данных остается ключевым компонентом, позволяя выполнять сложную аналитику SQL в масштабе и производительности на терабайтах и петабайтах структурированных и неструктурированных данных, а также делать аналитические выводы широко доступными с помощью популярных средств бизнес-аналитики ( BI) и инструменты аналитики. Мы продолжаем работать в обратном направлении от требований клиентов и в 2022 году запустили более 40 функций в Amazon Redshift, чтобы помочь клиентам в их основных сценариях использования хранилищ данных, в том числе:
- Аналитика самообслуживания
- Простой прием данных
- Обмен данными и совместная работа
- Наука о данных и машинное обучение
- Безопасная и надежная аналитика
- Лучшая аналитика цены и эффективности
Давайте углубимся и обсудим новые функции Amazon Redshift в этих областях.
Аналитика самообслуживания
Клиенты продолжают говорить нам, что данные и аналитика становятся повсеместными, и всем в их организации нужна аналитика. Мы объявили Amazon Redshift без сервера (в предварительной версии) в 2021 году, чтобы упростить запуск и масштабирование аналитики за считанные секунды без необходимости подготовки и управления инфраструктурой хранилища данных. В июле 2022 года мы объявили о общедоступность Redshift Serverless, и с тех пор тысячи клиентов, включая Peloton, Broadridge Financials и NextGen Healthcare, использовали его для быстрого и простого анализа своих данных. Amazon Redshift Serverless автоматически выделяет и интеллектуально масштабирует емкость хранилища данных, чтобы обеспечить высокую производительность для всей вашей аналитики, и вы платите только за вычислительные ресурсы, используемые в течение рабочих нагрузок на посекундной основе. Начиная с GA мы добавили такие функции, как тегирование ресурсов, упрощенный мониторинг и доступность в дополнительных регионах AWS для дальнейшего упрощения выставления счетов и расширения охвата в других регионах по всему миру.
В 2021 году мы запустили Amazon Redshift Query Editor V2 — бесплатный веб-инструмент для аналитиков данных, специалистов по данным и разработчиков, позволяющий исследовать, анализировать и совместно работать с данными в хранилищах и озерах данных Amazon Redshift. В 2022 году Query Editor V2 получил дополнительные улучшения, такие как поддержка ноутбука для улучшения совместной работы по созданию, организации и аннотированию запросов; доступ пользователя через учетные данные поставщика удостоверений (IdP) для единого входа; и возможность одновременного выполнения нескольких запросов для повышения производительности труда разработчиков.
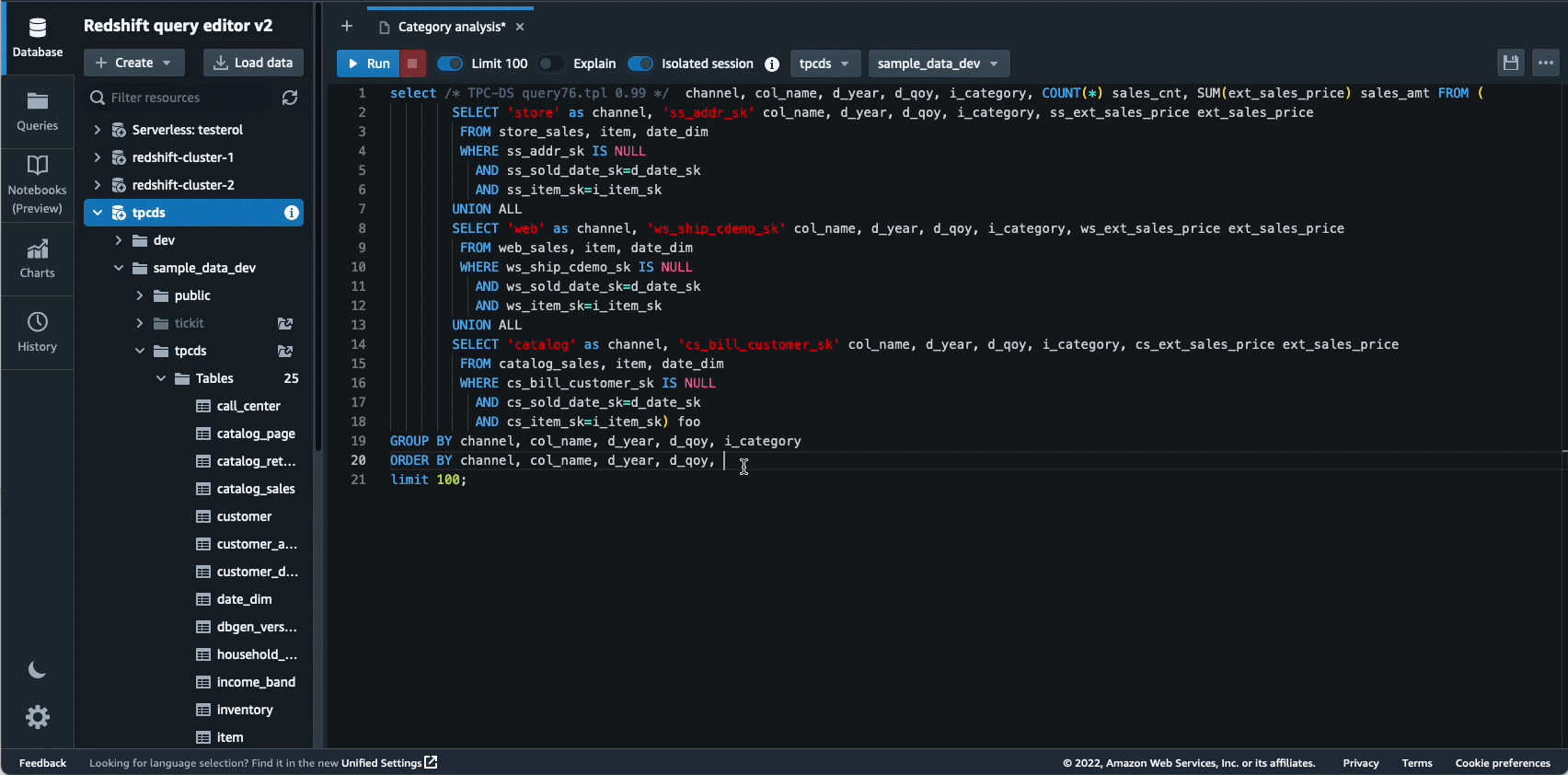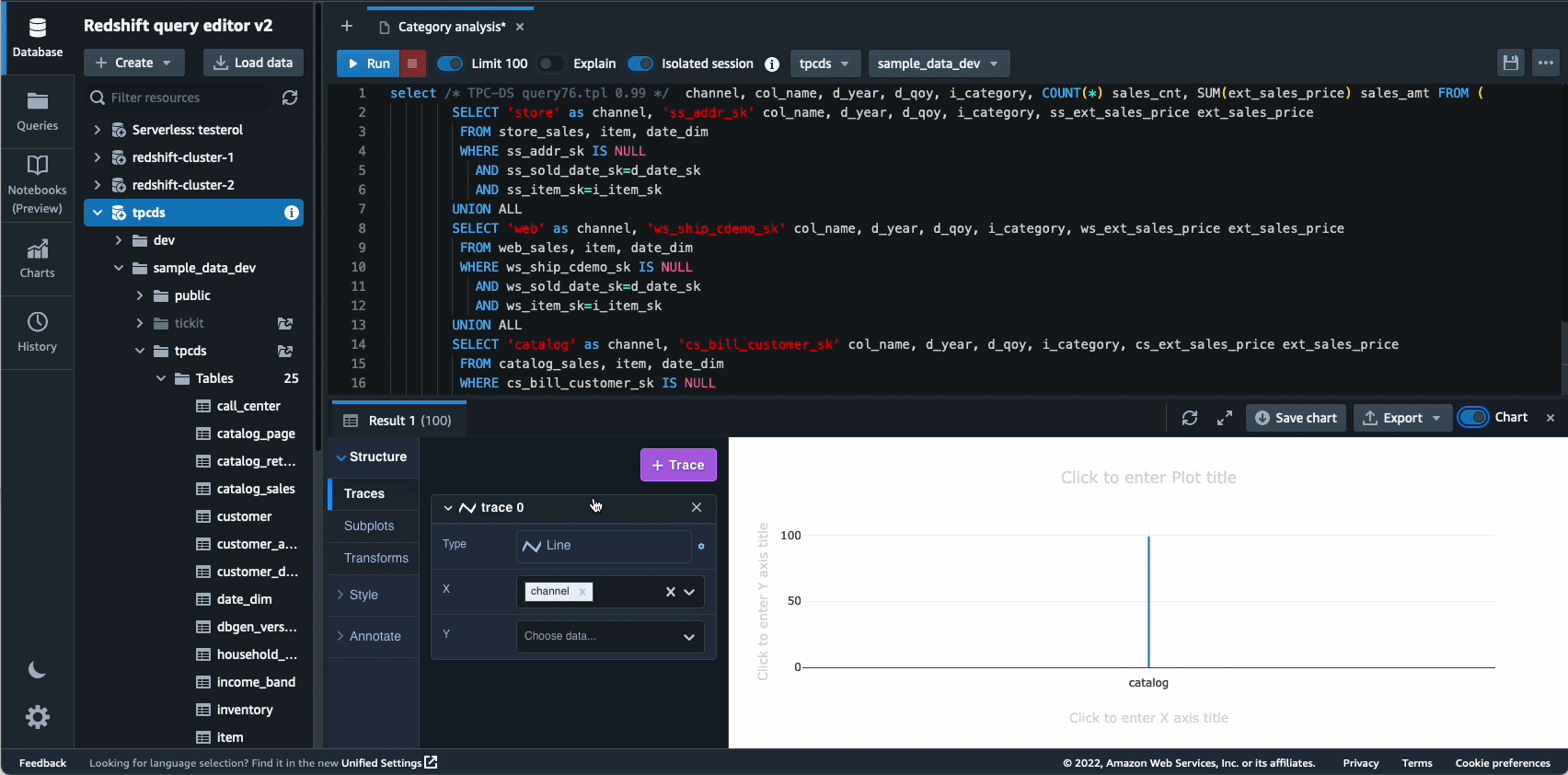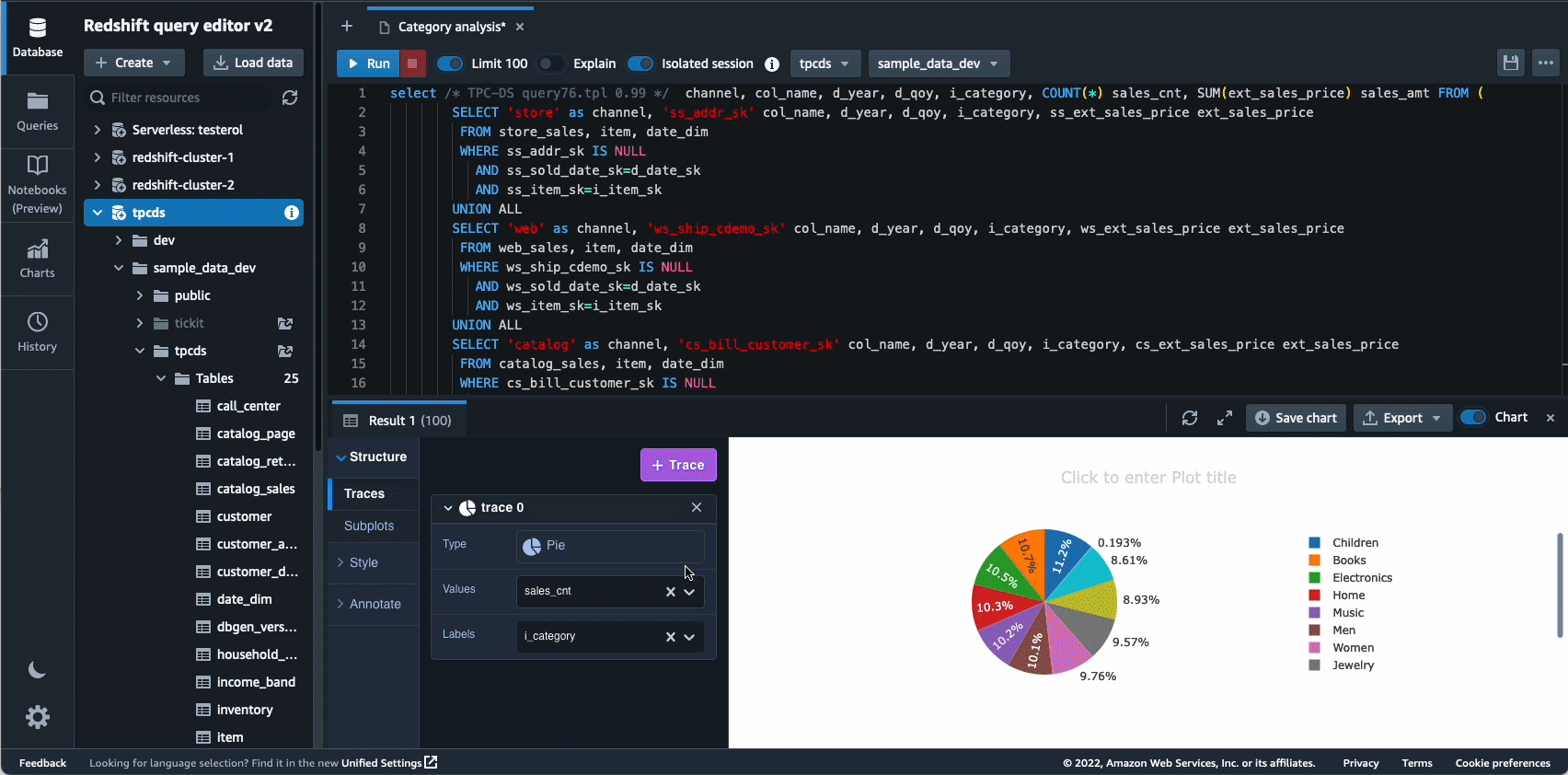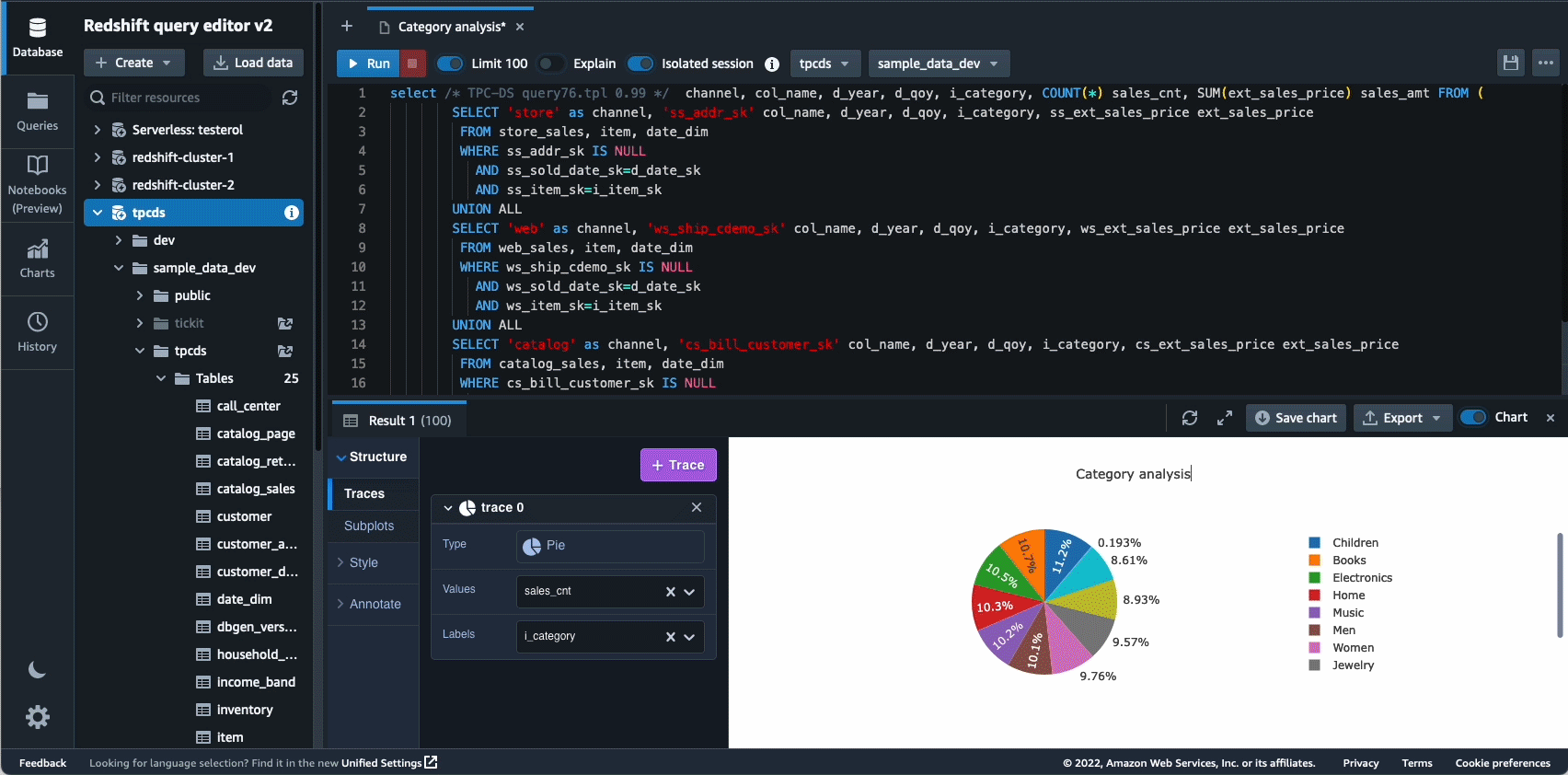
Автономность — еще одна область, в которой мы активно работаем над оптимизацией на основе машинного обучения и предоставлением клиентам самообучающегося и самооптимизирующегося хранилища данных. В 2022 году мы объявили об общедоступности Автоматизированные материализованные представления (AutoMV) для повышения производительности запросов (сокращения общего времени выполнения) без каких-либо усилий со стороны пользователя за счет автоматического создания и поддержки материализованных представлений. AutoMV в сочетании с автоматическим обновлением, добавочным обновлением и автоматическим перезаписью запросов для материализованных представлений сделали материализованные представления необслуживаемыми, автоматически повышая производительность. В дополнение автоматическая оптимизация стола (ATO) для оптимизации схемы и автоматическое управление нагрузкой (автоматический WLM) для оптимизации рабочей нагрузки получил дополнительные улучшения для повышения производительности запросов.
Простой прием данных
Клиенты сообщают нам, что их данные распределены по нескольким источникам данных, таким как транзакционные базы данных, хранилища данных, озера данных и системы больших данных. Им нужна гибкость, чтобы интегрировать эти данные с конвейерами данных без кода/мало кода, с нулевым ETL или анализировать эти данные на месте, не перемещая их. Клиенты сообщают нам, что их текущие конвейеры данных сложны, выполняются вручную, негибки и медленны, что приводит к неполным, противоречивым и устаревшим представлениям данных, что ограничивает понимание. Клиенты просили нас предложить лучший путь вперед, и мы рады объявить о ряде новых возможностей для упрощения и автоматизации конвейеров данных.
Интеграция Amazon Aurora с нулевым ETL и Amazon Redshift (предварительная версия) позволяет выполнять аналитику и машинное обучение почти в реальном времени на петабайтах транзакционных данных. Он предлагает решение без кода для создания транзакционных данных из нескольких Амазон Аврора базы данных доступны в хранилищах данных Amazon Redshift в течение нескольких секунд после записи в Aurora, что избавляет от необходимости создавать и поддерживать сложные конвейеры данных. С помощью этой функции клиенты Aurora также могут получить доступ к возможностям Amazon Redshift, таким как сложная аналитика SQL, встроенное машинное обучение, совместное использование данных и федеративный доступ к нескольким хранилищам данных и озерам данных. Эта функция теперь доступна в предварительной версии для Amazon Aurora, совместимая с MySQL, версия версии 3 (с совместимостью с MySQL 8.0), и вы можете запросить доступ к предварительному просмотру.
Amazon Redshift теперь поддерживает автоматическое копирование с Amazon S3 (предварительная версия) для упрощения загрузки данных из Простой сервис хранения Amazon (Amazon S3) в Amazon Redshift. Теперь вы можете настроить правила непрерывной загрузки файлов (задания копирования), чтобы отслеживать пути к Amazon S3 и автоматически загружать новые файлы без необходимости использования дополнительных инструментов или пользовательских решений. Задания копирования можно отслеживать с помощью системных таблиц, они автоматически отслеживают ранее загруженные файлы и исключают их из процесса приема, чтобы предотвратить дублирование данных. Эта функция теперь доступна в предварительной версии; вы можете попробовать эту функцию, создав новый кластер с помощью дорожки предварительного просмотра.
Клиенты продолжают говорить нам, что им нужна мгновенная аналитика в реальном времени, и мы рады объявить о общая доступность поддержки потоковой передачи в Amazon Redshift для Потоки данных Amazon Kinesis и Amazon Managed Streaming для Apache Kafka (Амазон МСК). Эта функция устраняет необходимость промежуточного хранения потоковых данных в Amazon S3 перед их добавлением в Amazon Redshift, позволяя добиться низкой задержки, измеряемой в секундах, при одновременном приеме сотен мегабайт потоковых данных в секунду в ваши хранилища данных. Вы можете использовать SQL в Amazon Redshift для подключения и прямого приема данных из нескольких потоков данных Kinesis или тем MSK, создавать автоматически обновляемые материализованные представления потоковой передачи с преобразованиями поверх потоков для прямого доступа к потоковым данным и объединять данные в реальном времени с историческими данными. данные для лучшего понимания. Например, Adobe интегрировала прием потоковой передачи Amazon Redshift как часть своей платформы Adobe Experience Platform для приема и анализа в режиме реального времени информации о посещениях веб-сайтов и приложений, а также данных о сеансах для различных приложений, таких как CRM и приложения поддержки клиентов.
Клиенты сообщили нам, что им нужна простая готовая интеграция между Amazon Redshift, инструментами BI и ETL (извлечение, преобразование и загрузка) и бизнес-приложениями, такими как Salesforce и Marketo. Мы рады сообщить об общедоступности Загрузчик данных Informatica для Amazon Redshift, который позволяет бесплатно использовать Informatica Data Loader для высокоскоростной загрузки больших объемов данных в Amazon Redshift. Вы можете просто выбрать параметр Informatica Data Loader в консоли Amazon Redshift. В Informatica Data Loader вы можете подключиться к таким источникам, как Salesforce или Marketo, выбрать Amazon Redshift в качестве цели и начать загрузку данных.
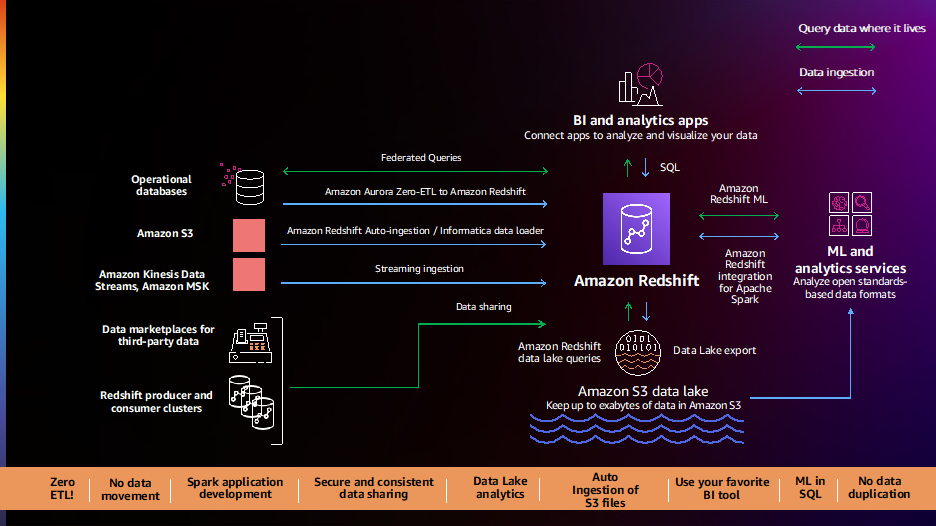
Обмен данными и совместная работа
Клиенты продолжают говорить нам, что они хотят анализировать все свои собственные и сторонние данные и предоставлять своим клиентам, партнерам и поставщикам обширную информацию, основанную на данных. В 2021 году мы запустили новые функции, такие как Обмен данными и Интеграция с обменом данными AWS, чтобы вам было проще анализировать все свои данные и делиться ими внутри и за пределами вашей организации.
Отличным примером клиента, использующего обмен данными, является Orion. Orion предоставляет решения «данные как услуга» (DaaS) в режиме реального времени для клиентов в сфере финансовых услуг, таких как управление капиталом, управление активами и поставщики услуг по управлению инвестициями. У них есть более 2,500 источников данных, которые в основном представляют собой базы данных SQL Server, размещенные как локально, так и в AWS. Данные передаются с помощью коннекторов Kafka в Amazon Redshift. У них есть кластер производителей, который получает все эти данные, а затем использует общий доступ к данным для обмена данными в режиме реального времени для совместной работы. Это многопользовательская архитектура, которая обслуживает несколько клиентов. Учитывая конфиденциальность их данных, совместное использование данных — это способ обеспечить изоляцию рабочей нагрузки между кластерами, а также безопасный обмен этими данными с конечными пользователями.
В 2022 году мы продолжили инвестировать в эту область, чтобы улучшить производительность, управление и производительность разработчиков с помощью новых функций, которые упрощают, упрощают и ускоряют обмен данными и совместную работу над ними.
Поскольку клиенты создают крупномасштабные конфигурации для обмена данными, они просят упростить управление и безопасность для общих данных, и мы добавляем централизованный контроль доступа с помощью AWS Lake Formation для совместного использования данных Amazon Redshift, чтобы обеспечить совместное использование данных в реальном времени между несколькими хранилищами данных Amazon Redshift. Благодаря этой функции Amazon Redshift теперь поддерживает упрощенное управление общими ресурсами Amazon Redshift с помощью Формирование озера AWS как единая панель для централизованного управления данными или разрешениями на общие ресурсы. Вы можете просматривать, изменять и проверять разрешения, включая безопасность на уровне строк и столбцов для таблиц и представлений в общих ресурсах Amazon Redshift, используя API Lake Formation и Консоль управления AWS, а также разрешить обнаружение общих ресурсов данных Amazon Redshift и их использование другими хранилищами данных Amazon Redshift.
Наука о данных и машинное обучение
Клиенты продолжают говорить нам, что они хотят, чтобы их системы данных и аналитики помогали им отвечать на широкий круг вопросов, от того, что происходит в их бизнесе (описательная аналитика), до того, почему это происходит (диагностическая аналитика) и что произойдет в будущем. (предиктивная аналитика). Amazon Redshift предоставляет такие функции, как комплексная аналитика SQL, аналитика озера данных и Amazon Redshift ML для клиентов, чтобы проанализировать свои данные и получить важные идеи. Красное смещение ML интегрирует Amazon Redshift с Создатель мудреца Амазонки, полностью управляемая служба машинного обучения, позволяющая создавать, обучать и развертывать модели машинного обучения с помощью знакомых команд SQL.
Клиенты также просили нас улучшить интеграцию между Amazon Redshift и Apache Spark, поэтому мы рады объявить Интеграция Amazon Redshift для Apache Spark сделать хранилища данных легко доступными для приложений на основе Spark. Теперь разработчики, использующие аналитику AWS и сервисы машинного обучения, такие как Амазонка ЭМИ, Клей AWS, а SageMaker может без особых усилий создавать приложения Apache Spark, которые считывают и записывают в свои хранилища данных Amazon Redshift. Amazon EMR и AWS Glue упаковывают коннектор Redshift-Spark, чтобы вы могли легко подключаться к своему хранилищу данных из своих приложений на основе Spark. Вы можете использовать несколько возможностей pushdown для таких операций, как сортировка, агрегирование, ограничение, объединение и скалярные функции, чтобы из хранилища данных Amazon Redshift в потребляющее приложение Spark перемещались только нужные данные. Вы также можете сделать свои приложения более безопасными, используя Управление идентификацией и доступом AWS (IAM) для подключения к Amazon Redshift.
Безопасная и надежная аналитика
Клиенты продолжают говорить нам, что их хранилища данных — это критически важные системы, требующие высокой доступности, надежности и безопасности. В 2022 году мы запустили ряд новых функций в этой области.
Amazon Redshift теперь поддерживает Развертывание в нескольких зонах доступности (в предварительной версии) для кластеров на основе экземпляров RA3, что позволяет запускать хранилище данных в нескольких зонах доступности AWS одновременно и непрерывно работать в непредвиденных сценариях сбоя всей зоны доступности. Поддержка нескольких зон доступности уже доступна для Redshift Serverless. Развертывание Amazon Redshift в нескольких зонах доступности позволяет выполнять восстановление в случае сбоев в зоне доступности без вмешательства пользователя. Доступ к хранилищу данных Amazon Redshift в нескольких зонах доступности осуществляется как к единому хранилищу данных с одной конечной точкой, что помогает максимизировать производительность за счет автоматического распределения обработки рабочей нагрузки по нескольким зонам доступности. Для обеспечения непрерывности бизнеса во время непредвиденных простоев не требуется никаких изменений приложений.
В 2022 году мы запустили такие функции, как управление доступом на основе ролей, безопасность на уровне строк и маскирование данных (в предварительной версии), чтобы вам было проще управлять доступом и решать, кто имеет доступ к тем или иным данным, включая запутывание информации, позволяющей установить личность (PII). ) как номера кредитных карт.
Вы можете использовать управление доступом на основе ролей (RBAC) для управления доступом конечных пользователей к данным на широком или детализированном уровне в зависимости от роли и разрешений конечного пользователя. С помощью RBAC вы можете создать роль с помощью SQL, предоставить набор детальных разрешений для роли, а затем назначить эту роль конечным пользователям. Ролям могут быть предоставлены разрешения на уровне объекта, столбца и системы. Кроме того, RBAC представляет готовые системные роли для администраторов баз данных, операторов, администраторов безопасности или настраиваемые роли.
Безопасность на уровне строк (RLS) упрощает проектирование и реализацию детального доступа к строкам в таблицах. С помощью RLS вы можете ограничить доступ к подмножеству строк в таблице на основе роли пользователя или разрешений с помощью SQL.
Amazon Redshift поддерживает динамическое маскирование данных (DDM), который сейчас доступен в предварительной версии, позволяет упростить защиту личных данных, таких как номера социального страхования, номера кредитных карт и номера телефонов, в хранилище данных Amazon Redshift. Благодаря динамическому маскированию данных вы контролируете доступ к своим данным с помощью простых политик маскирования на основе SQL, которые определяют, как Amazon Redshift возвращает конфиденциальные данные пользователю во время запроса. Вы можете создать политики маскирования, чтобы определить согласованные, сохраняющие формат и необратимые маскированные значения данных. Вы можете применить политику маскирования к определенному столбцу или списку столбцов в таблице. Кроме того, у вас есть возможность выбрать способ отображения замаскированных данных. Например, вы можете полностью скрыть данные, заменить частичные действительные значения подстановочными знаками или определить собственный способ маскирования данных с помощью выражений SQL, Python или AWS Lambda определяемые пользователем функции. Кроме того, вы можете применить политику условного маскирования на основе других столбцов, которая выборочно защищает данные столбцов в таблице на основе значений в одном или нескольких разных столбцах.
Мы также объявили об улучшениях журнал аудита, нативная интеграция с Microsoft Azure Active Directoryи поддержка роли IAM по умолчанию в дополнительных регионах для дальнейшего упрощения управления безопасностью.
Лучшая аналитика цены и эффективности
Клиенты продолжают говорить нам, что им нужны быстрые и экономичные хранилища данных, обеспечивающие высокую производительность в любом масштабе при низких затратах. С 1-го дня с Запуск Amazon Redshift в 2012 г., мы выбрали подход, основанный на данных, и использовали телеметрию парка для создания службы облачного хранилища данных, которая обеспечивает наилучшее соотношение цены и качества в любом масштабе. С годами мы развивались Архитектура Amazon Redshift и запустил такие функции, как Управляемое хранилище Redshift (RMS) для разделения хранилища и вычислений, Спектр красного смещения Амазонки для запросов озера данных, автоматическая оптимизация стола для оптимизации физической схемы, автоматическое управление нагрузкой расставлять приоритеты для рабочих нагрузок и правильно распределять вычислительные ресурсы и память, изменение размера кластера для вертикального масштабирования вычислений и хранилища, а также параллельное масштабирование для динамического масштабирования вычислений. Наши показатели производительности продолжают демонстрировать лидерство Amazon Redshift по соотношению цены и качества.
В 2022 году мы добавили новые функции, такие как общедоступность параллельное масштабирование для операций записи такие как COPY, INSERT, UPDATE и DELETE для поддержки практически неограниченного количества одновременных пользователей и запросов. Мы также улучшили производительность для обработки строковых данных за счет векторизованного сканирования по облегченным, эффективным для ЦП строковым столбцам, закодированным в словаре, что позволяет ядру базы данных работать непосредственно со сжатыми данными.
Мы также добавили поддержку операторов SQL, таких как MERGE (один оператор для вставок или обновлений); CONNECY_BY (для иерархических запросов); НАБОРЫ ГРУППИРОВКИ, ОБЪЕДИНЕНИЕ и КУБ (для многомерной отчетности); и увеличил размер типа данных SUPER до 16 МБ, чтобы упростить миграцию с устаревших хранилищ данных на Amazon Redshift.
Заключение
Наши клиенты продолжают говорить нам, что данные и аналитика остаются для них главным приоритетом, и потребность в рентабельном извлечении большей ценности для бизнеса из их данных в это время более выражена, чем когда-либо в прошлом. Amazon Redshift в качестве облачного хранилища данных позволяет выполнять сложную аналитику SQL с масштабированием и производительностью на терабайтах и петабайтах структурированных и неструктурированных данных, а также делать аналитические выводы широко доступными с помощью популярных инструментов бизнес-аналитики и аналитики.
Несмотря на то, что в 40 году мы запустили более 2022 функций, а темпы инноваций продолжают ускоряться, это все еще первый день, и мы с нетерпением ждем ваших отзывов о том, как эти функции помогут вам извлечь больше пользы для ваших организаций. Мы приглашаем вас попробовать эти новые функции и связаться с нами через вашу команду по работе с клиентами AWS, если у вас есть дополнительные комментарии.
Об авторе
 Манан Гоэль является лидером по выходу на рынок продуктов AWS Analytics Services, включая Amazon Redshift в AWS. Он имеет более чем 25-летний опыт работы и хорошо разбирается в базах данных, хранилищах данных, бизнес-аналитике и аналитике. Манан имеет степень магистра делового администрирования Университета Дьюка и степень бакалавра в области электроники и коммуникаций.
Манан Гоэль является лидером по выходу на рынок продуктов AWS Analytics Services, включая Amazon Redshift в AWS. Он имеет более чем 25-летний опыт работы и хорошо разбирается в базах данных, хранилищах данных, бизнес-аналитике и аналитике. Манан имеет степень магистра делового администрирования Университета Дьюка и степень бакалавра в области электроники и коммуникаций.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- способность
- О нас
- ускорять
- доступ
- Доступ к данным
- Доступ
- доступной
- Учетная запись
- Достигать
- через
- активный
- активно
- добавленный
- дополнение
- дополнительный
- Дополнительно
- саман
- Все
- позволяет
- уже
- Amazon
- Амазонка ЭМИ
- Аналитики
- аналитика
- анализировать
- анализ
- и
- анонсировать
- объявило
- Другой
- ответ
- апаш
- Apache Spark
- API
- Применение
- Приложения
- Применить
- подхода
- архитектура
- ПЛОЩАДЬ
- области
- искусственный
- искусственный интеллект
- активы
- управление активами
- аудит
- Aurora
- автор
- автоматический
- автоматизировать
- Автоматический
- автоматически
- свободных мест
- доступен
- AWS
- Клей AWS
- Лазурный
- основанный
- основа
- становление
- до
- не являетесь
- ЛУЧШЕЕ
- Лучшая
- между
- большой
- Big Data
- биллинг
- Ломать
- широкий
- Broadridge
- строить
- Строительство
- встроенный
- бизнес
- Бизнес-приложения
- Непрерывность бизнеса
- бизнес-аналитика
- возможности
- Пропускная способность
- карта
- случаев
- случаев
- изменения
- символы
- Выберите
- Выбирая
- клиентов
- облако
- Кластер
- сотрудничать
- сотрудничество
- лыжных шлемов
- Column
- Колонки
- объединять
- сочетании
- Комментарии
- Связь
- совместимость
- полностью
- комплекс
- компонент
- Вычисление
- параллельный
- Свяжитесь
- последовательный
- Консоли
- потребленный
- продолжать
- продолжающийся
- продолжается
- (CIJ)
- контроль
- рентабельным
- Расходы
- чехлы
- Создайте
- Создающий
- Полномочия
- кредит
- кредитная карта
- кредиты
- CRM
- Текущий
- изготовленный на заказ
- клиент
- служба поддержки
- Клиенты
- подгонянный
- данным
- Обмен данными
- Озеро данных
- обработка данных
- обмен данными
- информационное хранилище
- хранилища данных
- управляемых данными
- База данных
- базы данных
- день
- более глубокий
- доставить
- демонстрировать
- развертывание
- развертывание
- Проект
- Определять
- Застройщик
- застройщиков
- различный
- непосредственно
- обнаружить
- открытый
- обсуждать
- распределенный
- распределительный
- Герцог
- Университет Дюка
- в течение
- динамический
- легче
- легко
- редактор
- усилие
- Electronics
- ликвидирует
- уничтожение
- включить
- позволяет
- позволяет
- Конечная точка
- Двигатель
- Проект и
- Эфир (ETH)
- все члены
- эволюционировали
- пример
- обмена
- возбужденный
- Расширьте
- опыт
- Больше
- выражения
- извлечение
- Ошибка
- знакомый
- БЫСТРО
- быстрее
- Особенность
- Особенности
- Файл
- Файлы
- финансовый
- финансовые услуги
- финансовые
- Найдите
- ФЛОТ
- Трансформируемость
- образование
- вперед
- Бесплатно
- от
- полностью
- Функции
- далее
- будущее
- Общие
- получить
- GIF
- Дайте
- данный
- дает
- Отдаете
- стекло
- Иди в магазин
- управление
- предоставлять
- предоставленный
- большой
- происходить
- счастливый
- Жесткий
- имеющий
- здравоохранение
- слух
- помощь
- помогает
- Спрятать
- High
- исторический
- имеет
- Как
- How To
- HTML
- HTTPS
- Сотни
- IAM
- Личность
- реализация
- улучшать
- улучшенный
- улучшение
- in
- В том числе
- расширились
- промышленность
- информация
- Инфраструктура
- Инновации
- Вставки
- размышления
- интегрировать
- интегрированный
- Интегрируется
- интеграции.
- Интеллекта
- вмешательство
- выпустили
- Представляет
- Грин- карта инвестору
- инвестиций
- приглашать
- изоляция
- IT
- работа
- Джобс
- присоединиться
- июль
- Кафка
- Сохранить
- хранение
- Основные
- Потоки данных Kinesis
- озеро
- крупномасштабный
- Задержка
- запуск
- запустили
- лидер
- Наша команда
- изучение
- Наследие
- уровень
- легкий
- ОГРАНИЧЕНИЯ
- Список
- жить
- живые данные
- загрузка
- загрузчик
- погрузка
- посмотреть
- Низкий
- машина
- обучение с помощью машины
- сделанный
- поддерживать
- техническое обслуживание
- сделать
- Создание
- управлять
- управляемого
- управление
- руководство
- Marketo
- маска
- Максимизировать
- Память
- мигрировать
- ML
- Модели
- Модерн
- изменять
- контролируемый
- Мониторинг
- БОЛЕЕ
- перемещение
- с разными
- MySQL
- родной
- Необходимость
- необходимый
- потребности
- Новые
- Новые функции
- номер
- номера
- Предложения
- ONE
- открытый
- работать
- операция
- Операционный отдел
- оператор
- Операторы
- оптимизация
- Опция
- организация
- организации
- Другое
- Отключения
- внешнюю
- собственный
- Темп
- пакет
- хлеб
- часть
- партнеры
- мимо
- ОПЛАТИТЬ
- пелотон
- производительность
- Разрешения
- Лично
- Телефон
- физический
- PII
- Часть
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- довольный
- сборах
- политика
- Популярное
- После
- мощный
- Predictive Analytics
- предотвращать
- предварительный просмотр
- предварительно
- цена
- в первую очередь
- Расставляйте приоритеты
- приоритет
- процесс
- обработка
- производитель
- Продукт
- производительность
- защищающий
- обеспечивать
- Недвижимости
- поставщики
- приводит
- обеспечение
- Питон
- Вопросы
- быстро
- ассортимент
- достигать
- Читать
- реальные
- реального времени
- данные в реальном времени
- получает
- Recover
- уменьшить
- районы
- соответствующие
- надежность
- складская
- остатки
- замещать
- отчету
- Reporting
- Требования
- ограничивать
- в результате
- Возвращает
- обзоре
- перезаписи
- Богатые
- жесткий
- Роли
- роли
- свернуть
- условиями,
- Run
- Бег
- sagemaker
- Salesforce
- Шкала
- Весы
- масштабирование
- Сценарии
- Наука
- Ученые
- Во-вторых
- секунды
- безопасный
- безопасно
- безопасность
- чувствительный
- чувствительность
- Serverless
- служит
- обслуживание
- Услуги
- Сессия
- набор
- Наборы
- несколько
- Поделиться
- общие
- разделение
- показывать
- просто
- упрощенный
- упростить
- просто
- одновременно
- с
- одинарной
- Сидящий
- Размер
- медленной
- So
- Соцсети
- Решение
- Решения
- некоторые
- Источники
- Искриться
- конкретный
- SQL
- Этап
- диск
- магазины
- Стратегия
- потоковый
- потоковый
- потоки
- структурированный
- структурированные и неструктурированные данные
- такие
- супер
- поставщики
- поддержка
- Поддержка
- система
- системы
- ТАБЛИЦЫ
- цель
- команда
- Ассоциация
- Будущее
- их
- сторонние
- тысячи
- Через
- время
- раз
- в
- инструментом
- инструменты
- топ
- Темы
- Всего
- трогать
- трек
- Train
- транзакционный
- Transform
- преобразований
- вездесущий
- непредвиденный
- Университет
- Неограниченный
- отпереть
- Обновление ПО
- Updates
- us
- использование
- Информация о пользователе
- пользователей
- Использующий
- ценностное
- Наши ценности
- различный
- версия
- Вид
- Просмотры
- фактически
- Склады
- Складирование
- Богатство
- управление активами
- Web
- Web-Based
- Что
- Что такое
- который
- в то время как
- КТО
- широкий
- Широкий диапазон
- широко
- будете
- в
- без
- Работа
- работавший
- работает
- по всему миру
- записывать
- письменный
- год
- лет
- ВАШЕ
- зефирнет
- зоны