Клей-студия AWS — это графический интерфейс, упрощающий создание, запуск и мониторинг заданий извлечения, преобразования и загрузки (ETL) в Клей AWS. Он позволяет визуально составлять рабочие процессы преобразования данных, используя узлы, представляющие различные этапы обработки данных, которые впоследствии автоматически преобразуются в код для выполнения.
Клей-студия AWS недавно выпущена Еще 10 визуальных преобразований, позволяющих создавать более сложные задания визуальным способом без навыков программирования. В этом посте мы обсудим возможные варианты использования, которые отражают общие потребности ETL.
Новые преобразования, которые будут продемонстрированы в этом посте: объединение, разделение строки, массив в столбцы, добавление текущей метки времени, сводные строки в столбцы, разведение столбцов в строки, поиск, разнесение массива или сопоставление в столбцы, производный столбец и обработка автобаланса. .
Обзор решения
В этом случае у нас есть несколько файлов JSON с операциями с фондовыми опционами. Мы хотим сделать некоторые преобразования перед сохранением данных, чтобы их было легче анализировать, а также мы хотим создать отдельную сводку набора данных.
В этом наборе данных каждая строка представляет собой сделку по опционным контрактам. Опционы — это финансовые инструменты, дающие право — но не обязательство — покупать или продавать акции по фиксированной цене (называемой цена исполнения) до установленной даты истечения срока действия.
Входные данные
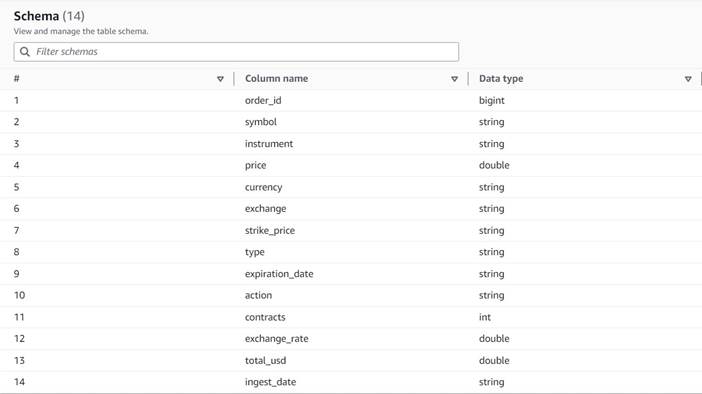
Данные следуют следующей схеме:
- номер заказа – Уникальный идентификатор
- символ – Код, обычно состоящий из нескольких букв, идентифицирующий корпорацию, которая выпускает базовые акции.
- инструмент – Имя, которое идентифицирует конкретный покупаемый или продаваемый опцион.
- валюта – Код валюты ISO, в которой выражена цена
- цена – Сумма, которая была уплачена за покупку каждого опционного контракта (на большинстве бирж один контракт позволяет купить или продать 100 акций)
- обмена – Код обменного центра или площадки, на которой была совершена сделка по опциону
- проданный – Список количества контрактов, которые были выделены для исполнения ордера на продажу, когда это сделка на продажу.
- купил – Список количества контрактов, выделенных для исполнения ордера на покупку, когда это сделка на покупку.
Ниже приведен пример синтетических данных, сгенерированных для этого поста:
ETL-требования
Эти данные имеют ряд уникальных характеристик, часто встречающихся в старых системах, которые затрудняют их использование.
Ниже приведены требования к ETL:
- Название прибора содержит ценную информацию, предназначенную для понимания людьми; мы хотим нормализовать его в отдельные столбцы для облегчения анализа.
- Атрибуты
boughtиsoldвзаимоисключающие; мы можем объединить их в один столбец с номерами контрактов и иметь еще один столбец, указывающий, были ли контракты куплены или проданы в этом порядке. - Мы хотим сохранить информацию о распределении отдельных контрактов, но в виде отдельных строк, вместо того, чтобы заставлять пользователей иметь дело с массивом чисел. Мы могли бы сложить цифры, но потеряли бы информацию о том, как был исполнен ордер (что свидетельствует о ликвидности рынка). Вместо этого мы решили денормализировать таблицу, чтобы в каждой строке было одно количество контрактов, разбивая заказы с несколькими номерами на отдельные строки. В сжатом формате столбцов дополнительный размер набора данных этого повторения часто невелик, когда применяется сжатие, поэтому допустимо упростить запрос к набору данных.
- Мы хотим создать сводную таблицу объема для каждого типа опциона (колл и пут) для каждой акции. Это дает представление о настроении рынка для каждой акции и рынка в целом (жадность против страха).
- Чтобы включить общие торговые сводки, мы хотим предоставить для каждой операции общий итог и стандартизировать валюту по долларам США, используя приблизительную ссылку конвертации.
- Мы хотим добавить дату, когда произошли эти преобразования. Это может быть полезно, например, чтобы иметь справку о том, когда была произведена конвертация валюты.
На основе этих требований задание выдаст два результата:
- CSV-файл со сводкой по количеству контрактов для каждого символа и типа.
- Таблица каталога для хранения истории заказа после выполнения указанных преобразований
Предпосылки
Вам понадобится собственное ведро S3, чтобы следовать этому варианту использования. Чтобы создать новый сегмент, см. Создание ведра.
Создание синтетических данных
Чтобы следовать этому сообщению (или поэкспериментировать с такими данными самостоятельно), вы можете создать этот набор данных синтетическим путем. Следующий скрипт Python можно запустить в среде Python с установленным Boto3 и доступом к Простой сервис хранения Amazon (Amazon S3).
Чтобы сгенерировать данные, выполните следующие шаги:
- В AWS Glue Studio создайте новое задание с параметром Редактор сценариев оболочки Python.
- Дайте заданию имя и на Детали работы вкладку, выберите подходящая роль и имя для скрипта Python.
- В Детали работы раздел, развернуть Дополнительные свойства и прокрутите вниз до Параметры работы.
- Введите параметр с именем
--bucketи назначьте в качестве значения имя корзины, которую вы хотите использовать для хранения демонстрационных данных. - Введите следующий скрипт в редактор оболочки AWS Glue:
- Запустите задание и подождите, пока оно не отобразится как успешно выполненное на вкладке «Выполнения» (это должно занять всего несколько секунд).
Каждый запуск будет генерировать файл JSON с 1,000 строками в указанном сегменте и префиксе transformsblog/inputdata/. Вы можете запустить задание несколько раз, если хотите протестировать большее количество входных файлов.
Каждая строка в синтетических данных представляет собой строку данных, представляющую объект JSON, как показано ниже:
Создание визуального задания AWS Glue
Чтобы создать визуальное задание AWS Glue, выполните следующие действия:
- Перейдите в AWS Glue Studio и создайте задание, используя опцию Визуальный с пустым холстом.
- Редактировать
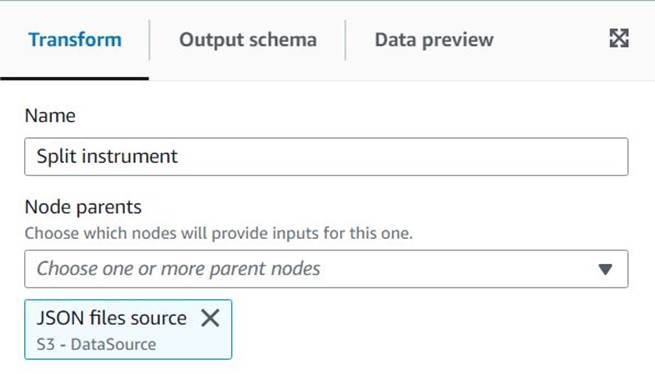
Untitled jobдать ему имя и назначить роль, подходящая для AWS Glue на Детали работы меню. - Добавьте источник данных S3 (вы можете назвать его
JSON files source) и введите URL-адрес S3, под которым хранятся файлы (например,s3://<your bucket name>/transformsblog/inputdata/), затем выберите JSON как формат данных. - Выберите Вывод схемы поэтому он устанавливает схему вывода на основе данных.
Из этого исходного узла вы будете продолжать цепочку преобразований. При добавлении каждого преобразования убедитесь, что выбранный узел добавлен последним, чтобы он был назначен родительским, если в инструкциях не указано иное.
Если вы выбрали не того родителя, вы всегда можете отредактировать родителя, выбрав его и выбрав другого родителя на панели конфигурации.
Каждому добавленному узлу вы даете конкретное имя (чтобы назначение узла отображалось на графике) и конфигурацию на Transform меню.
Каждый раз, когда преобразование изменяет схему (например, добавляет новый столбец), необходимо обновить выходную схему, чтобы она была видна нижестоящим преобразованиям. Вы можете вручную отредактировать схему вывода, но практичнее и безопаснее делать это с помощью предварительного просмотра данных.
Кроме того, таким образом вы можете убедиться, что преобразование работает так, как ожидалось. Для этого откройте Предварительный просмотр данных вкладку с выбранным преобразованием и начать сеанс предварительного просмотра. После того, как вы убедились, что преобразованные данные выглядят так, как ожидалось, перейдите к Выходная схема и выберите Использовать схему предварительного просмотра данных для автоматического обновления схемы.
По мере добавления новых видов преобразований предварительный просмотр может отображать сообщение об отсутствующей зависимости. Когда это произойдет, выберите Конец сессии и запустите новый, поэтому предварительный просмотр улавливает новый тип узла.
Извлечь информацию о приборе
Давайте начнем с обработки информации об имени инструмента, чтобы нормализовать ее в столбцах, к которым легче получить доступ в результирующей выходной таблице.
- Добавить Разделить строку узел и назовите его
Split instrument, который будет токенизировать столбец инструмента с помощью регулярного выражения с пробелами:s+(в этом случае подойдет один пробел, но этот способ более гибкий и визуально более четкий). - Мы хотим сохранить исходную информацию об инструменте как есть, поэтому введите новое имя столбца для разделенного массива:
instrument_arr.
- Добавьте Массив в столбцы узел и назовите его
Instrument columnsдля преобразования только что созданного столбца массива в новые поля, за исключениемsymbol, для которого у нас уже есть столбец. - Выберите столбец
instrument_arr, пропустите первый токен и скажите ему извлечь выходные столбцыmonth, day, year, strike_price, typeс использованием индексов2, 3, 4, 5, 6(пробелы после запятых для удобства чтения, они не влияют на конфигурацию).
Извлеченный год выражается только двумя цифрами; давайте положим временную паузу, чтобы предположить, что это в этом столетии, если они просто используют две цифры.
- Добавить Производный столбец узел и назовите его
Four digits year. - Enter
yearв качестве производного столбца, чтобы он переопределял его, и введите следующее выражение SQL:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
Для удобства строим expiration_date поле, которое пользователь может иметь в качестве ссылки на последнюю дату, когда опцион может быть исполнен.
- Добавить Объединить столбцы узел и назовите его
Build expiration date. - Назовите новый столбец
expiration_date, выберите столбцыyear,monthиday(именно в таком порядке) и дефис в качестве разделителя.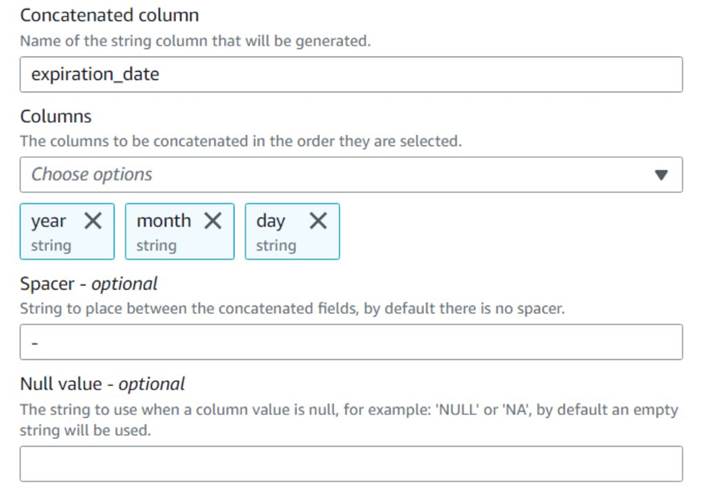
Пока что диаграмма должна выглядеть как следующий пример.
![]()
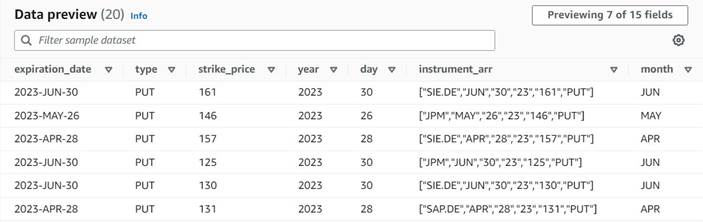
Предварительный просмотр данных новых столбцов на данный момент должен выглядеть так, как показано на следующем снимке экрана.
Нормировать количество контрактов
В каждой строке данных указано количество контрактов каждого опциона, которые были куплены или проданы, и партии, по которым были исполнены ордера. Без потери информации об отдельных пакетах мы хотим, чтобы каждая сумма была в отдельной строке с одним значением суммы, в то время как остальная информация реплицируется в каждой созданной строке.
Во-первых, давайте объединим суммы в один столбец.
- Добавьте Развернуть столбцы в строки узел и назовите его
Unpivot actions. - Выберите столбцы
boughtиsoldчтобы развернуть и сохранить имена и значения в столбцах с именамиactionиcontracts, Соответственно.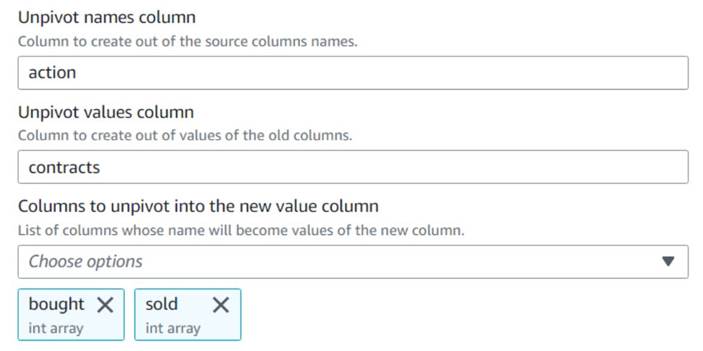
Обратите внимание, что в предварительном просмотре новый столбецcontractsостается массивом чисел после этого преобразования.
- Добавьте Разбить массив или карту на строки строка с именем
Explode contracts. - Выберите
contractsстолбца и введитеcontractsкак новый столбец, чтобы переопределить его (нам не нужно сохранять исходный массив).
Предварительный просмотр теперь показывает, что каждая строка имеет один contracts сумма, а остальные поля одинаковы.
Это также означает, что order_id больше не является уникальным ключом. Для ваших собственных вариантов использования вам нужно решить, как моделировать ваши данные и хотите ли вы денормализации или нет.
На следующем снимке экрана показан пример того, как выглядят новые столбцы после преобразований.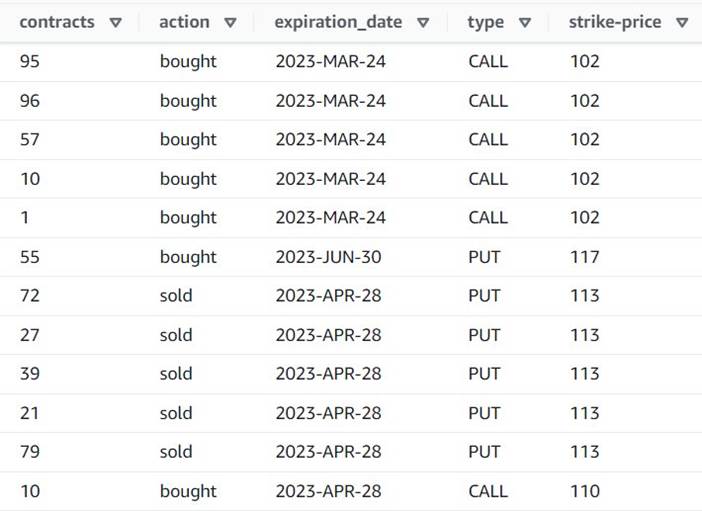
Создайте сводную таблицу
Теперь вы создаете сводную таблицу с количеством контрактов, торгуемых для каждого типа и каждого символа акции.
Давайте для наглядности предположим, что обработанные файлы относятся к одному дню, поэтому эта сводка дает бизнес-пользователям информацию о том, каковы рыночные интересы и настроения в этот день.
- Добавить Выбрать поля узел и выберите следующие столбцы, чтобы сохранить сводку:
symbol,typeиcontracts.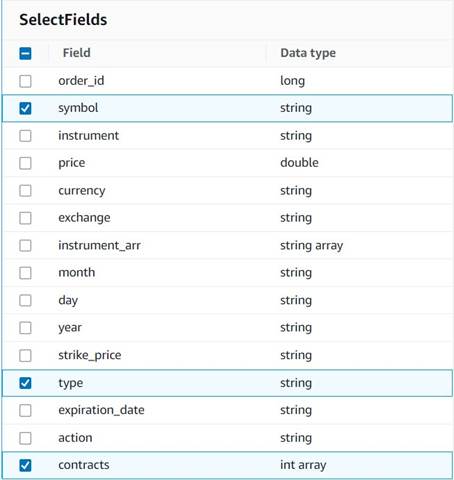
- Добавить Сводные строки в столбцы узел и назовите его
Pivot summary. - Совокупность по
contractsстолбец с использованиемsumи выберите преобразованиеtypeколонка.
Обычно вы храните его во внешней базе данных или файле для справки; в этом примере мы сохраняем его как файл CSV на Amazon S3.
- Добавьте Обработка автобаланса узел и назовите его
Single output file. - Хотя этот тип преобразования обычно используется для оптимизации параллелизма, здесь мы используем его для сокращения вывода до одного файла. Поэтому введите
1в конфигурации количества разделов.
- Добавьте цель S3 и назовите ее
CSV Contract summary. - Выберите CSV в качестве формата данных и введите путь S3, где роли задания разрешено хранить файлы.
Последняя часть задания теперь должна выглядеть так, как показано в следующем примере.![]()
- Сохраните и запустите задание. Использовать Работает вкладку, чтобы проверить успешное завершение.
По этому пути вы найдете файл в формате CSV, несмотря на отсутствие такого расширения. Вам, вероятно, потребуется добавить расширение после его загрузки, чтобы открыть его.
В инструменте, который может читать CSV, сводка должна выглядеть примерно так, как показано в следующем примере.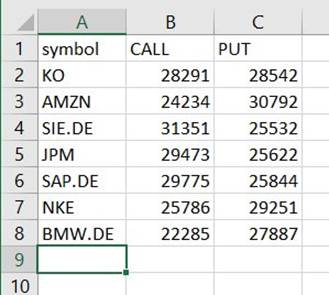
Очистить временные столбцы
При подготовке к сохранению заказов в исторической таблице для будущего анализа давайте очистим некоторые временные столбцы, созданные по ходу дела.
- Добавить Перетащите поля узел с
Explode contractsузел, выбранный в качестве его родителя (мы разветвляем конвейер данных для создания отдельного вывода). - Выберите поля, которые нужно удалить:
instrument_arr,month,dayиyear.
Остальные мы хотим сохранить, чтобы они были сохранены в исторической таблице, которую мы создадим позже.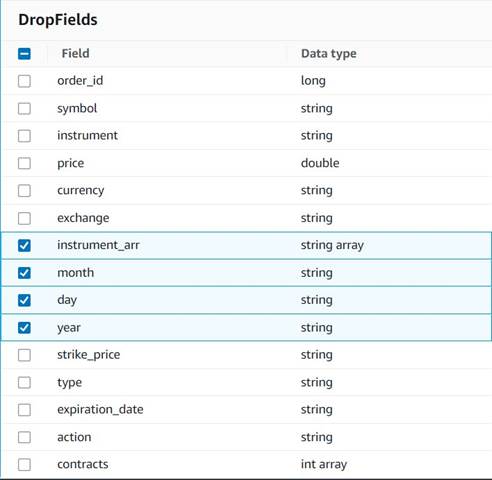
Стандартизация валюты
Эти синтетические данные содержат вымышленные операции с двумя валютами, но в реальной системе вы могли бы получать валюты с рынков по всему миру. Полезно стандартизировать обрабатываемые валюты в единую базовую валюту, чтобы их можно было легко сравнивать и объединять для отчетности и анализа.
МЫ ИСПОЛЬЗУЕМ Амазонка Афина для имитации таблицы с приблизительными преобразованиями валют, которая периодически обновляется (здесь мы предполагаем, что обрабатываем заказы достаточно своевременно, чтобы преобразование было разумным репрезентативным для целей сравнения).
- Откройте консоль Athena в том же регионе, где вы используете AWS Glue.
- Выполните следующий запрос, чтобы создать таблицу, задав местоположение S3, где ваши роли Athena и AWS Glue могут читать и записывать. Кроме того, вы можете захотеть сохранить таблицу в другой базе данных, чем
default(если вы это сделаете, соответственно обновите квалифицированное имя таблицы в приведенных примерах). - Введите несколько примеров преобразования в таблицу:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Теперь вы должны иметь возможность просматривать таблицу со следующим запросом:
SELECT * FROM default.exchange_rates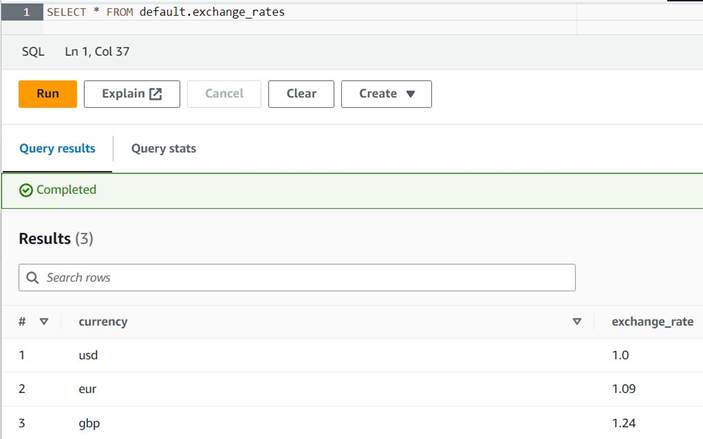
- Вернувшись к визуальному заданию AWS Glue, добавьте Поиск узел (как дочерний элемент
Drop Fields) и назовите этоExchange rate. - Введите полное имя только что созданной таблицы, используя
currencyв качестве ключа и выберитеexchange_rateполе для использования.
Поскольку имя поля одинаково и в данных, и в таблице поиска, мы можем просто ввести имяcurrencyи не нужно определять сопоставление.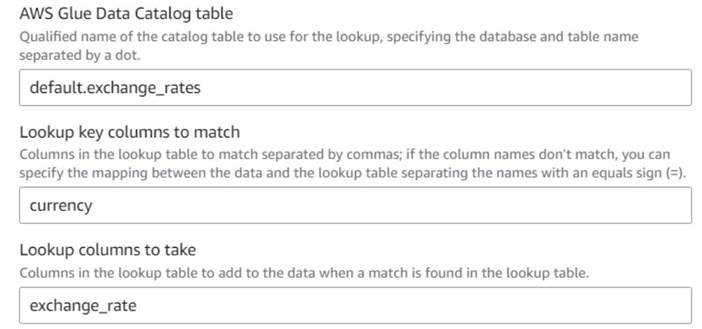
На момент написания этой статьи преобразование «Уточняющий запрос» не поддерживается в предварительном просмотре данных, и оно покажет ошибку, что таблица не существует. Это только для предварительного просмотра данных и не мешает правильному выполнению задания. Несколько оставшихся шагов поста не требуют обновления схемы. Если вам нужно запустить предварительный просмотр данных на других узлах, вы можете временно удалить узел поиска, а затем вернуть его обратно. - Добавить Производный столбец узел и назовите его
Total in usd. - Назовите производный столбец
total_usdи используйте следующее выражение SQL:round(contracts * price * exchange_rate, 2)
- Добавить Добавить текущую метку времени узел и имя столбца
ingest_date. - Используйте формат
%Y-%m-%dдля вашей метки времени (в демонстрационных целях мы просто используем дату; вы можете сделать ее более точной, если хотите).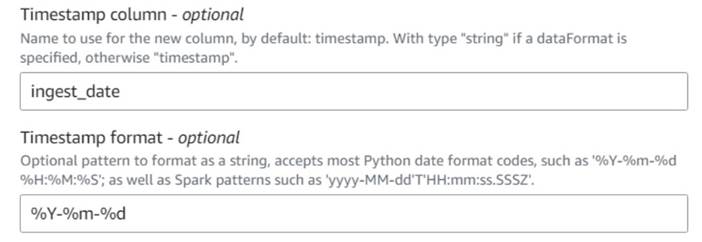
Сохраните таблицу исторических заказов
Чтобы сохранить таблицу исторических заказов, выполните следующие шаги:
- Добавьте целевой узел S3 и назовите его
Orders table. - Настройте формат Parquet с быстрым сжатием и укажите целевой путь S3 для хранения результатов (отдельно от сводки).
- Выберите Создайте таблицу в каталоге данных и при последующих запусках обновите схему и добавьте новые разделы..
- Введите целевую базу данных и имя для новой таблицы, например:
option_orders.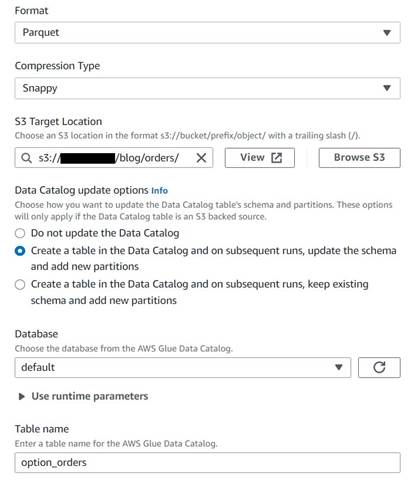
Последняя часть диаграммы теперь должна выглядеть примерно так, как показано ниже, с двумя ответвлениями для двух отдельных выходов.![]()
После успешного запуска задания вы можете использовать такой инструмент, как Athena, для просмотра данных, полученных заданием, путем запроса новой таблицы. Вы можете найти таблицу в списке Athena и выбрать Таблица предварительного просмотра или просто запустите запрос SELECT (обновив имя таблицы на имя и каталог, которые вы использовали):
SELECT * FROM default.option_orders limit 10
Содержимое вашей таблицы должно выглядеть примерно так, как показано на следующем снимке экрана.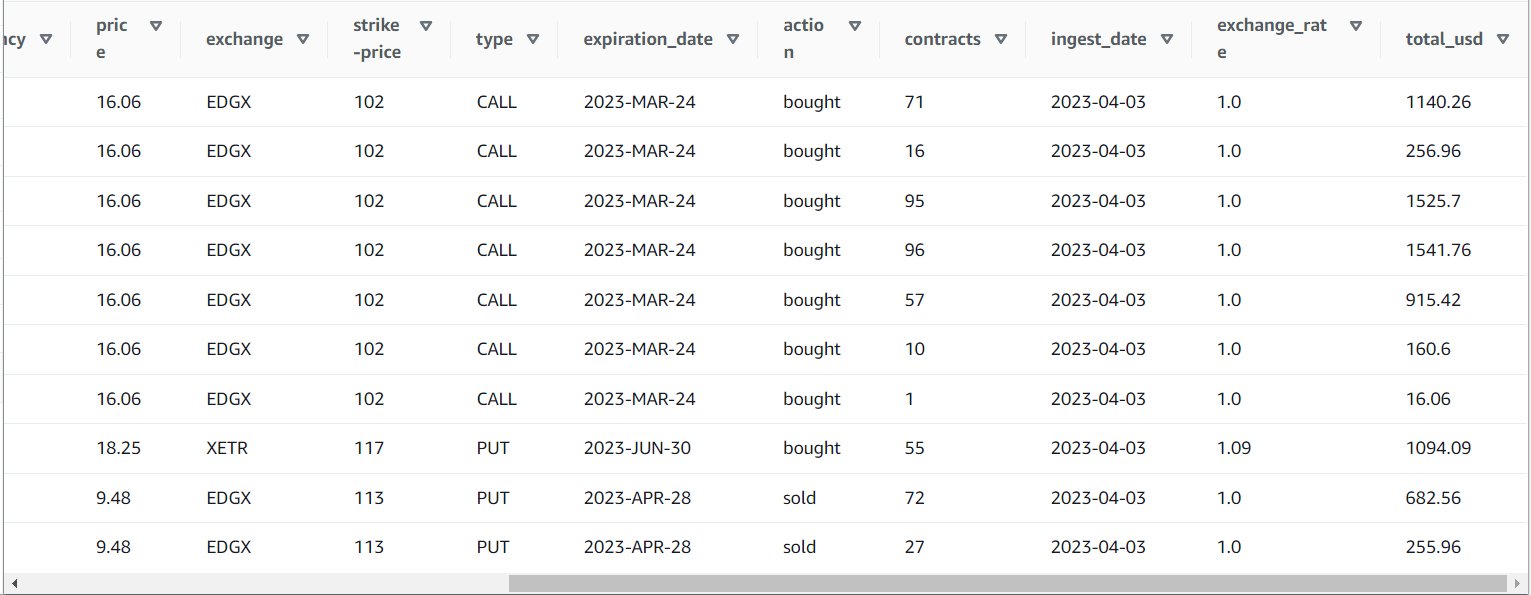
Убирать
Если вы не хотите сохранять этот пример, удалите два созданных вами задания, две таблицы в Athena и пути S3, где хранились входные и выходные файлы.
Заключение
В этом посте мы показали, как новые преобразования в AWS Glue Studio могут помочь вам выполнять более сложные преобразования с минимальной конфигурацией. Это означает, что вы можете реализовать больше случаев использования ETL без необходимости писать и поддерживать какой-либо код. Новые преобразования уже доступны в AWS Glue Studio, поэтому вы можете использовать новые преобразования уже сегодня в своих визуальных задачах.
Об авторе
![]() Гонсало Эррерос является старшим архитектором больших данных в команде AWS Glue.
Гонсало Эррерос является старшим архитектором больших данных в команде AWS Glue.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15%
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- в состоянии
- О нас
- приемлемый
- доступ
- соответственно
- Добавить
- добавленный
- добавить
- продвинутый
- После
- Все
- выделено
- ассигнования
- позволять
- позволяет
- вдоль
- уже
- причислены
- всегда
- Amazon
- количество
- суммы
- an
- анализ
- анализировать
- и
- Другой
- любой
- прикладной
- приблизительный
- апрель
- МЫ
- аргумент
- массив
- AS
- назначенный
- At
- Атрибуты
- автоматически
- доступен
- AWS
- Клей AWS
- назад
- основанный
- BE
- до
- не являетесь
- большой
- Big Data
- пустой
- BMW
- изоферменты печени
- купил
- ветви
- строить
- бизнес
- но
- купить
- by
- призывают
- CAN
- случаев
- случаев
- каталог
- Центр
- Век
- изменения
- характеристика
- проверка
- ребенок
- Выберите
- Выбирая
- понятнее
- код
- Кодирование
- Column
- Колонки
- Общий
- сравненный
- сравнение
- полный
- Заполненная
- Конфигурация
- Консоли
- консолидировать
- содержит
- содержание
- контракт
- контрактов
- удобство
- Конверсия
- конверсий
- конвертировать
- переделанный
- КОРПОРАЦИЯ
- может
- Создайте
- создали
- Создающий
- валюты
- Валюта
- Текущий
- DAG
- данным
- База данных
- Время
- Финики
- Дата и время
- день
- сделка
- занимавшийся
- решать
- По умолчанию
- определенный
- убивают
- Зависимость
- Производный
- Несмотря на
- подробнее
- различный
- цифры
- обсуждать
- do
- не
- дело
- долларов
- Dont
- двойной
- вниз
- Падение
- упал
- каждый
- легче
- легко
- легко
- редактор
- включить
- достаточно
- Enter
- Окружающая среда
- ошибка
- Эфир (ETH)
- EUR
- пример
- Примеры
- Кроме
- обмена
- Биржи
- Эксклюзивные
- существовать
- Расширьте
- ожидаемый
- эксперимент
- истечение
- выраженный
- расширение
- и, что лучший способ
- дополнительно
- извлечение
- далеко
- страх
- несколько
- вымышленный
- поле
- Поля
- Файл
- Файлы
- заполнять
- заполненный
- финансовый
- Финансовые инструменты
- Найдите
- First
- фиксированной
- гибкого
- следовать
- после
- следующим образом
- Что касается
- формат
- найденный
- от
- будущее
- GBP
- Общие
- в общем
- порождать
- генерируется
- получить
- Дайте
- дает
- Go
- график
- Жадность
- Управляемость
- происходит
- Есть
- имеющий
- помощь
- здесь
- исторический
- история
- Как
- How To
- HTML
- HTTP
- HTTPS
- Людей
- i
- идентифицирует
- определения
- if
- Влияние
- осуществлять
- Импортировать
- in
- Индексы
- указанный
- указывает
- с указанием
- индикация
- individual
- информация
- вход
- пример
- вместо
- инструкции
- инструмент
- инструменты
- интерес
- Интерфейс
- в
- ISO
- IT
- ЕГО
- работа
- Джобс
- JPG
- JSON
- всего
- Сохранить
- Основные
- Вид
- Фамилия
- новее
- такое как
- ОГРАНИЧЕНИЯ
- линия
- Ликвидность
- Список
- загрузка
- расположение
- дольше
- посмотреть
- выглядит как
- ВЗГЛЯДЫ
- поиск
- терять
- потери
- сделанный
- поддерживать
- сделать
- ДЕЛАЕТ
- вручную
- карта
- отображение
- рынок
- настроение рынка
- Области применения:
- Май..
- означает
- идти
- сообщение
- может быть
- минимальный
- отсутствующий
- модель
- монитор
- БОЛЕЕ
- самых
- с разными
- взаимно
- имя
- Названный
- имена
- Необходимость
- потребности
- Новые
- нет
- узел
- узлы
- нормально
- сейчас
- номер
- номера
- объект
- of
- .
- on
- ONE
- только
- открытый
- операция
- Операционный отдел
- Оптимизировать
- Опция
- Опции
- or
- заказ
- заказы
- оригинал
- Другое
- в противном случае
- выходной
- за
- общий
- переопределение
- собственный
- выплачен
- хлеб
- параметр
- часть
- путь
- Выборы
- трубопровод
- Стержень
- Часть
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- После
- потенциал
- практическое
- необходимость
- предотвращать
- предварительный просмотр
- цена
- вероятно
- процесс
- обработка
- производит
- Произведенный
- обеспечивать
- при условии
- приводит
- покупки
- цель
- целей
- положил
- Питон
- квалифицированный
- повышение
- случайный
- Читать
- реальные
- разумный
- уменьшить
- отражать
- область
- осталось
- удаление
- реплицируются
- Reporting
- представлять
- представитель
- представляющий
- представляет
- требовать
- Требования
- требуется
- соответственно
- ОТДЫХ
- в результате
- Итоги
- обзоре
- Роли
- роли
- РЯД
- Run
- Бег
- безопаснее
- то же
- живица
- Сохранить
- экономия
- пролистать
- секунды
- выбранный
- выбор
- продаем
- старший
- настроение
- отдельный
- Сессия
- Наборы
- установка
- Акции
- Оболочка
- должен
- показывать
- Шоу
- аналогичный
- просто
- одинарной
- Размер
- навыки
- небольшой
- So
- уже
- проданный
- некоторые
- удалось
- Источник
- Space
- пространства
- конкретный
- указанный
- раскол
- Таблица
- SQL
- Начало
- Шаги
- По-прежнему
- акции
- диск
- магазин
- хранить
- строка
- студия
- последующее
- Успешно
- подходящее
- РЕЗЮМЕ
- Поддержанный
- символ
- синтетический
- синтетические данные
- синтетически
- система
- системы
- ТАБЛИЦЫ
- взять
- цель
- команда
- сказать
- временный
- 10
- тестXNUMX
- чем
- который
- Ассоциация
- График
- информация
- мир
- Их
- тогда
- следовательно
- Эти
- они
- этой
- те
- время
- раз
- отметка времени
- в
- сегодня
- знак
- токенизировать
- приняли
- инструментом
- Всего
- торговать
- торговал
- Transform
- трансформация
- преобразований
- преобразован
- два
- напишите
- под
- лежащий в основе
- понимать
- созданного
- до
- Обновление ПО
- обновление
- обновление
- URL
- us
- Доллары США
- USD
- использование
- прецедент
- используемый
- Информация о пользователе
- пользователей
- через
- ценный
- Ценная информация
- ценностное
- Наши ценности
- место встречи
- проверено
- проверить
- Вид
- видимый
- объем
- vs
- ждать
- хотеть
- законопроект
- Путь..
- we
- были
- Что
- когда
- который
- в то время как
- будете
- без
- Рабочие процессы
- работает
- Мир
- бы
- записывать
- письмо
- год
- являетесь
- ВАШЕ
- зефирнет











