
Изображение создано с помощью DALL-E3
Искусственный интеллект стал настоящей революцией в мире технологий.
Его способность имитировать человеческий интеллект и выполнять задачи, которые когда-то считались исключительно человеческими прерогативами, до сих пор поражает большинство из нас.
Однако какими бы хорошими ни были эти последние достижения в области искусственного интеллекта, всегда есть возможности для совершенствования.
И именно здесь начинается оперативная инженерия!
Войдите в эту область, которая может значительно повысить производительность моделей искусственного интеллекта.
Давайте откроем все это вместе!
Оперативное проектирование — это быстрорастущая область ИИ, которая фокусируется на повышении эффективности и результативности языковых моделей. Все дело в создании идеальных подсказок, которые помогут моделям ИИ добиться желаемых результатов.
Думайте об этом как о том, как научиться давать кому-то более эффективные инструкции, чтобы убедиться, что они правильно понимают и выполняют задачу.
Почему оперативное проектирование имеет значение
- Повышенная производительность: Используя высококачественные подсказки, модели ИИ могут генерировать более точные и релевантные ответы. Это означает меньше времени, затрачиваемого на исправления, и больше времени на использование возможностей ИИ.
- Эффективность затрат: Обучение моделей ИИ требует ресурсов. Оперативное проектирование может снизить необходимость в переобучении за счет оптимизации производительности модели за счет более эффективных подсказок.
- Универсальность: Хорошо продуманная подсказка может сделать модели ИИ более универсальными, позволяя им решать более широкий круг задач и задач.
Прежде чем погрузиться в самые продвинутые методы, давайте вспомним два наиболее полезных (и основных) метода оперативного проектирования.
Последовательное мышление: «Давайте подумаем шаг за шагом»
Сегодня общеизвестно, что точность моделей LLM значительно повышается при добавлении последовательности слов «Давайте подумаем шаг за шагом».
Почему… спросите вы?
Это потому, что мы заставляем модель разбивать любую задачу на несколько шагов, тем самым гарантируя, что у модели будет достаточно времени для обработки каждого из них.
Например, я мог бы бросить вызов GPT3.5 с помощью следующей подсказки:
Если у Джона есть 5 груш, он съедает 2, покупает еще 5, а затем дает 3 своему другу, сколько у него груш?
Модель сразу даст мне ответ. Однако если я добавлю последнее «Давайте подумаем шаг за шагом», я заставлю модель генерировать мыслительный процесс, состоящий из нескольких шагов.
Несколько выстрелов
В то время как подсказка с нулевым выстрелом подразумевает, что модель просят выполнить задачу без предоставления какого-либо контекста или предварительных знаний, техника подсказки с несколькими выстрелами подразумевает, что мы представляем LLM несколько примеров желаемого результата вместе с некоторым конкретным вопросом.
Например, если мы хотим придумать модель, которая определяет любой термин, используя поэтический тон, это может быть довольно сложно объяснить. Верно?
Однако мы могли бы использовать следующие подсказки, чтобы направить модель в нужном направлении.
Ваша задача — отвечать в едином стиле, соответствующем следующему стилю.
: Научите меня устойчивости.
: Устойчивость подобна дереву, которое гнется на ветру, но никогда не ломалось.
Это способность оправиться от невзгод и продолжать двигаться вперед.
: Ваш вклад здесь.
Если вы еще не пробовали, вы можете бросить вызов GPT.
Однако, поскольку я почти уверен, что большинство из вас уже знают эти базовые техники, я попытаюсь бросить вам вызов некоторыми продвинутыми техниками.
1. Подсказка цепочки мыслей (ЦТ)
Введен Google в 2022 годуЭтот метод включает в себя указание модели пройти несколько этапов рассуждения, прежде чем выдать окончательный ответ.
Звучит знакомо, правда? Если так, то вы совершенно правы.
Это похоже на слияние последовательного мышления и кратковременных подсказок.
Как?
По сути, подсказки CoT предписывают LLM последовательно обрабатывать информацию. Это означает, что мы показываем, как решить первую проблему с помощью многоэтапного рассуждения, а затем отправляем в модель нашу реальную задачу, ожидая, что она будет имитировать сопоставимую цепочку мыслей при ответе на реальный запрос, который мы хотим решить.
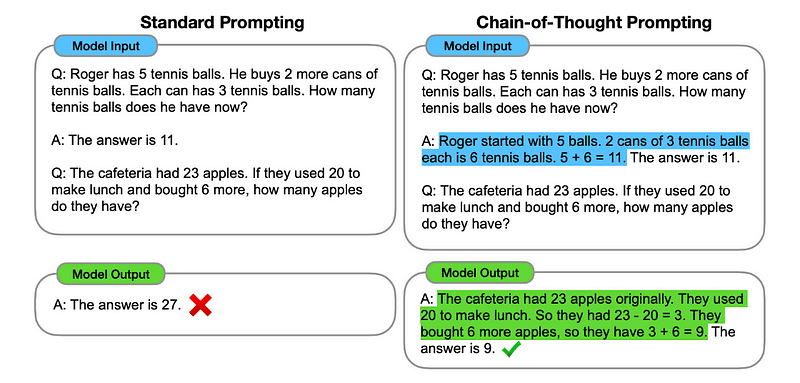
Изображение взято из бумаги.
Итак, следуя самому первому примеру, мы могли бы предоставить подсказку с первой проблемой и последовательное объяснение способа ее решения. Затем мы можем отправить наши данные и посмотреть, как происходит волшебство!
Если у Джона есть 5 груш, он съедает 2, покупает еще 5, а затем дает 3 своему другу, сколько у него груш? Давайте думать поэтапно.
Давайте идти шаг за шагом. Джон начинает с 5 груш. Он съедает 2 груши, значит, у него осталось 5–2 = 3 груши. Затем он покупает еще 5 груш. Итак, у него теперь 3+5=8 груш. Наконец он дает своему другу 3 груши. Следовательно, у него осталось 8–3=5 груш. Итак, после всех этих действий у Джона есть 5 груш.
Ваш вклад здесь.
Однако большинство из вас, должно быть, думают… Должен ли я думать о последовательном способе решения любой проблемы каждый раз, когда я хочу что-то спросить в ChatGPT?
Ну… ты не первый! И это приводит нас к…
2. Автоматическая цепочка мыслей (Auto-CoT)
В 2022 Zhang и коллеги представили метод, позволяющий избежать этого ручного процесса. Есть две основные причины избегать любых задач, выполняемых вручную:
- Это может быть скучно.
- Это может привести к плохим результатам – например, когда наш умственный процесс неправильный.
Они предложили использовать LLM в сочетании с подсказкой «Давайте подумаем шаг за шагом», чтобы последовательно создавать цепочки рассуждений для каждой демонстрации.
Это означает, что вы задаете ChatGPT, как последовательно решить любую проблему, а затем на этом же примере обучаете его решению любой другой проблемы.
3. Самосогласованность
Самопоследовательность — еще один интересный метод подсказок, целью которого является улучшение цепочки мыслей, подсказывающей более сложные задачи рассуждения.
Итак… в чем главное отличие?
Основная идея самосогласованности заключается в осознании того, что мы можем обучить модель на неправильном примере. Представьте себе, что я решаю предыдущую задачу с помощью неправильного мыслительного процесса:
Если у Джона есть 5 груш, он съедает 2, покупает еще 5, а затем дает 3 своему другу, сколько у него груш? Давайте думать поэтапно.
Начните с 5 груш. Джон ест 2 груши. Затем он дает своему другу 3 груши. Эти действия можно комбинировать: 2 (съедено) + 3 (дано) = всего затронуто 5 груш. Теперь вычтите общее количество затронутых груш из первоначальных 5 груш: 5 (первоначально) – 5 (пострадало) = осталось 0 груш.
Тогда любая другая задача, которую я отправлю модели, будет неправильной.
Вот почему самосогласованность предполагает выборку различных путей рассуждения, каждый из которых содержит цепочку мыслей, а затем позволяет LLM выбрать лучший и наиболее последовательный путь для решения проблемы.
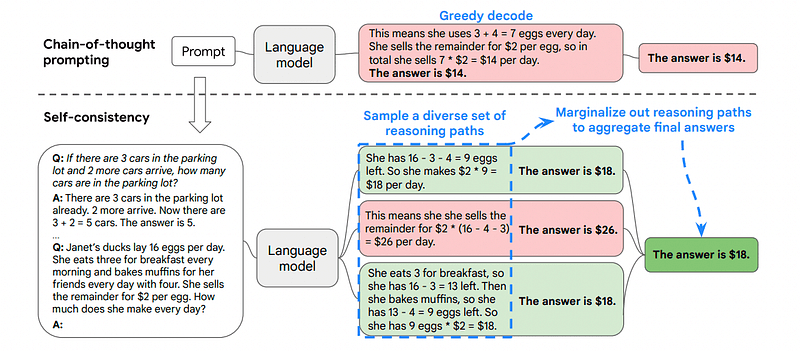
Изображение взято из бумаги
В этом случае и снова следуя самому первому примеру, мы можем показать модели различные способы решения проблемы.
Если у Джона есть 5 груш, он съедает 2, покупает еще 5, а затем дает 3 своему другу, сколько у него груш?
Начните с 5 груш. Джон съедает 2 груши, и у него остается 5–2 = 3 груши. Он покупает еще 5 груш, в результате чего общая сумма становится 3 + 5 = 8 груш. Наконец, он отдает 3 груши своему другу, так что у него осталось 8–3 = 5 груш.
Если у Джона есть 5 груш, он съедает 2, покупает еще 5, а затем дает 3 своему другу, сколько у него груш?
Начните с 5 груш. Затем он покупает еще 5 груш. Джон сейчас ест 2 груши. Эти действия можно комбинировать: 2 (съедено) + 5 (куплено) = всего 7 груш. Вычтите грушу, которую съел Джон, из общего количества груш 7 (общее количество) – 2 (съеденных) = осталось 5 груш.
Ваш вклад здесь.
И вот последний прием.
4. Подсказка общих знаний
Распространенной практикой оперативного проектирования является дополнение запроса дополнительными сведениями перед отправкой окончательного вызова API в GPT-3 или GPT-4.
По Цзячэн Лю и компания, мы всегда можем добавить некоторую информацию к любому запросу, чтобы LLM лучше знал вопрос.
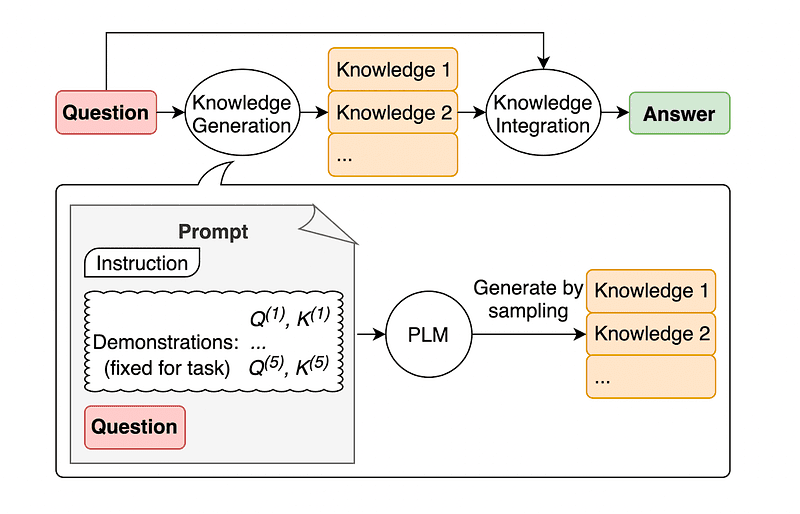
Изображение взято из бумаги.
Так, например, если ChatGPT спросит, пытается ли часть игроков в гольф набрать больше очков, чем другие, он подтвердит нас. Но главная цель гольфа прямо противоположная. Вот почему мы можем добавить некоторые предыдущие знания, сказав: «Побеждает игрок с меньшим количеством очков».

Итак... что смешного, если мы сообщаем модели именно тот ответ?
В данном случае этот метод используется для улучшения взаимодействия LLM с нами.
Поэтому вместо того, чтобы извлекать дополнительный контекст из внешней базы данных, авторы статьи рекомендуют, чтобы LLM производил свои собственные знания. Эти самогенерированные знания затем интегрируются в подсказку, чтобы поддержать здравый смысл и обеспечить более качественные результаты.
Вот как можно улучшить LLM, не увеличивая набор обучающих данных!
Оперативное проектирование стало ключевым методом расширения возможностей LLM. Повторяя и улучшая подсказки, мы можем более напрямую взаимодействовать с моделями ИИ и, таким образом, получать более точные и контекстуально релевантные результаты, экономя время и ресурсы.
Для технических энтузиастов, специалистов по данным и создателей контента понимание и освоение оперативного проектирования может стать ценным активом в использовании всего потенциала ИИ.
Сочетая тщательно разработанные подсказки для ввода с этими более продвинутыми методами, наличие набора навыков в области разработки подсказок, несомненно, даст вам преимущество в ближайшие годы.
Хосеп Феррер инженер-аналитик из Барселоны. Он получил диплом инженера-физика и в настоящее время работает в области науки о данных, применяемой к человеческой мобильности. Он по совместительству создает контент, специализирующийся на науке о данных и технологиях. Вы можете связаться с ним по LinkedIn, Twitter or Medium.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :имеет
- :является
- :нет
- :куда
- $UP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- способность
- О нас
- точность
- точный
- действия
- фактического соединения
- Добавить
- добавить
- дополнительный
- продвинутый
- После
- снова
- AI
- AI модели
- Цель
- выровненный
- одинаково
- Все
- Позволяющий
- вдоль
- уже
- всегда
- am
- количество
- an
- аналитика
- и
- Другой
- ответ
- любой
- API
- прикладной
- МЫ
- AS
- спросить
- спрашивающий
- активы
- Авторы
- Автоматический
- избежать
- знать
- прочь
- назад
- Плохой
- Барселона
- основной
- BE
- , так как:
- было
- до
- не являетесь
- ЛУЧШЕЕ
- Лучшая
- поддерживать
- повышение
- Сверление
- изоферменты печени
- купил
- подпрыгивать
- Ломать
- брейки
- Приносит
- шире
- но
- Покупает
- by
- призывают
- CAN
- возможности
- осторожно
- случаев
- цепь
- цепи
- вызов
- проблемы
- ChatGPT
- Выберите
- коллеги
- сочетании
- комбинируя
- как
- выходит
- приход
- Общий
- общаться
- сравнимый
- полный
- комплекс
- считается
- последовательный
- обращайтесь
- содержание
- создатели контента
- контекст
- исправления
- правильно
- может
- создали
- создатель
- Создатели
- В настоящее время
- данным
- наука о данных
- База данных
- Определяет
- доставки
- предназначенный
- желанный
- разница
- различный
- направлять
- направление
- обнаружить
- дайвинг
- do
- приносит
- домен
- доменов
- вниз
- каждый
- Edge
- эффективность
- затрат
- появившийся
- инженер
- Проект и
- повышать
- повышение
- достаточно
- обеспечивать
- энтузиастов
- точно,
- пример
- Примеры
- выполнять
- ожидается
- Объяснять
- объяснение
- знакомый
- несколько
- поле
- окончательный
- в заключение
- Во-первых,
- внимание
- фокусируется
- после
- Что касается
- принуждение
- вперед
- друг
- от
- полный
- веселая
- Общие
- порождать
- получить
- Дайте
- данный
- дает
- Go
- цель
- гольф
- хорошо
- инструкция
- Жесткий
- Освоение
- Есть
- имеющий
- he
- здесь
- высококачественный
- высший
- его
- его
- Как
- How To
- Однако
- HTTPS
- человек
- человеческий интеллект
- i
- идея
- if
- картина
- улучшать
- улучшенный
- улучшение
- улучшение
- in
- повышение
- информация
- начальный
- вход
- пример
- инструкции
- интегрированный
- Интеллекта
- взаимодействует
- интересный
- в
- выпустили
- включает в себя
- IT
- ЕГО
- John
- джон
- всего
- КДнаггетс
- Сохранить
- удар
- Kicks
- Знать
- знания
- знает
- язык
- Фамилия
- Поздно
- Лиды
- Leap
- изучение
- уход
- оставил
- Меньше
- позволять
- позволяя
- Используя
- такое как
- ниже
- магия
- Главная
- сделать
- Создание
- способ
- руководство
- многих
- Освоение
- Вопрос
- me
- означает
- психический
- объединение
- метод
- может быть
- мобильность
- модель
- Модели
- БОЛЕЕ
- самых
- перемещение
- с разными
- должен
- Необходимость
- никогда
- нет
- сейчас
- получать
- of
- on
- консолидировать
- противоположность
- оптимизирующий
- or
- Другое
- Другое
- наши
- внешний
- выходной
- выходы
- внешнюю
- собственный
- бумага & картон
- часть
- путь
- ИДЕАЛЬНОЕ
- выполнять
- производительность
- Физика
- основной
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игрок
- Точка
- потенциал
- практика
- Точно
- представить
- довольно
- предыдущий
- Проблема
- проблемам
- процесс
- производит
- производительность
- обеспечивать
- обеспечение
- тянущий
- вопрос
- вполне
- ассортимент
- скорее
- реальные
- причины
- рекомендовать
- уменьшить
- понимается
- соответствующие
- запросить
- упругость
- ресурсоемкий
- Полезные ресурсы
- ответ
- ответ
- ответы
- Итоги
- переквалификация
- Революция
- правую
- Комната
- s
- то же
- экономия
- Наука
- Наука и технологии
- Ученые
- Гол
- посмотреть
- Отправить
- отправка
- Последовательность
- набор
- несколько
- показывать
- существенно
- умение
- So
- только
- РЕШАТЬ
- Решение
- некоторые
- Кто-то
- удалось
- конкретный
- потраченный
- этапы
- Начало
- начинается
- управлять
- Шаг
- Шаги
- По-прежнему
- стиль
- Убедитесь
- снасти
- приняты
- Сложность задачи
- задачи
- технологии
- техника
- снижения вреда
- Технологии
- говорят
- срок
- чем
- который
- Ассоциация
- Их
- тогда
- Там.
- следовательно
- Эти
- они
- think
- мышление
- этой
- мысль
- Через
- Таким образом
- время
- в
- TONE
- Всего
- ПОЛНОСТЬЮ
- Train
- Обучение
- дерево
- пыталась
- стараться
- пытается
- два
- окончательный
- под
- претерпевать
- понимать
- понимание
- несомненно
- us
- использование
- используемый
- через
- VALIDATE
- ценный
- различный
- разносторонний
- очень
- хотеть
- Путь..
- способы
- we
- известный
- были
- когда
- который
- зачем
- будете
- ветер
- в
- без
- Word
- работает
- Мир
- Неправильно
- лет
- еще
- Уступать
- являетесь
- ВАШЕ
- зефирнет







