Студия Amazon SageMaker предоставляет полностью управляемое решение для специалистов по данным, позволяющее интерактивно создавать, обучать и развертывать модели машинного обучения (ML). Рабочие места для ноутбуков Amazon SageMaker позвольте ученым, работающим с данными, запускать свои блокноты по требованию или по расписанию с помощью нескольких щелчков мыши в SageMaker Studio. Благодаря этому запуску вы сможете программно запускать блокноты как задания, используя API, предоставленные Конвейеры Amazon SageMaker, функция оркестрации рабочих процессов машинного обучения Создатель мудреца Амазонки. Кроме того, с помощью этих API вы можете создать многоэтапный рабочий процесс машинного обучения с несколькими зависимыми блокнотами.
SageMaker Pipelines — это собственный инструмент оркестрации рабочих процессов для создания конвейеров машинного обучения, использующий преимущества прямой интеграции с SageMaker. Каждый конвейер SageMaker состоит из шага, которые соответствуют отдельным задачам, таким как обработка, обучение или обработка данных с использованием Амазонка ЭМИ. Задания блокнота SageMaker теперь доступны как встроенный тип шагов в конвейерах SageMaker. Вы можете использовать этот шаг задания блокнота, чтобы легко запускать блокноты как задания с помощью всего лишь нескольких строк кода, используя команду SDK Amazon SageMaker Python. Кроме того, вы можете объединить несколько зависимых блокнотов вместе, чтобы создать рабочий процесс в форме направленных ациклических графов (DAG). Затем вы можете запускать эти задания блокнотов или группы DAG, а также управлять ими и визуализировать их с помощью SageMaker Studio.
Специалисты по данным в настоящее время используют SageMaker Studio для интерактивной разработки своих блокнотов Jupyter, а затем используют задания блокнотов SageMaker для запуска этих блокнотов в качестве запланированных заданий. Эти задания можно запускать немедленно или по регулярному расписанию, при этом специалистам по работе с данными не требуется реорганизовать код в виде модулей Python. Некоторые распространенные случаи использования для этого включают в себя:
- Длительная работа ноутбуков в фоновом режиме
- Регулярный вывод модели для создания отчетов
- Переход от подготовки небольших выборочных наборов данных к работе с большими данными петабайтного масштаба
- Переобучение и развертывание моделей с определенной частотой
- Планирование заданий для мониторинга качества модели или отклонения данных
- Исследование пространства параметров для улучшения моделей
Хотя эта функциональность позволяет специалистам по обработке данных легко автоматизировать автономные блокноты, рабочие процессы машинного обучения часто состоят из нескольких блокнотов, каждый из которых выполняет определенную задачу со сложными зависимостями. Например, блокнот, который отслеживает отклонение данных модели, должен иметь предварительный этап, который позволяет извлекать, преобразовывать и загружать (ETL) и обрабатывать новые данные, а также последующий этап обновления и обучения модели на случай, если будет замечено значительное отклонение. . Кроме того, специалисты по обработке данных могут захотеть запустить весь этот рабочий процесс по повторяющемуся графику, чтобы обновить модель на основе новых данных. Чтобы вы могли легко автоматизировать свои блокноты и создавать такие сложные рабочие процессы, задания блокнотов SageMaker теперь доступны в качестве шага в SageMaker Pipelines. В этом посте мы покажем, как с помощью нескольких строк кода можно решить следующие варианты использования:
- Программно запускайте автономный блокнот немедленно или по регулярному графику.
- Создавайте многоэтапные рабочие процессы из блокнотов в качестве групп доступности базы данных для целей непрерывной интеграции и непрерывной доставки (CI/CD), которыми можно управлять через пользовательский интерфейс SageMaker Studio.
Обзор решения
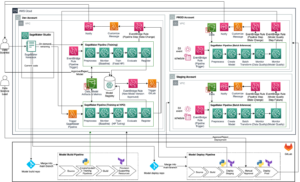
Следующая диаграмма иллюстрирует архитектуру нашего решения. Вы можете использовать SageMaker Python SDK для запуска одного задания блокнота или рабочего процесса. Эта функция создает обучающее задание SageMaker для запуска блокнота.
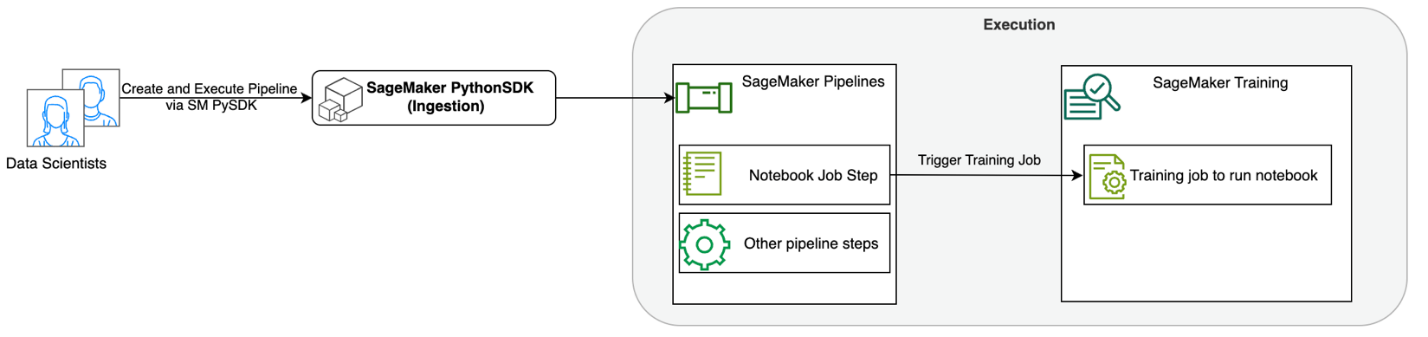
В следующих разделах мы рассмотрим пример варианта использования машинного обучения и продемонстрируем шаги по созданию рабочего процесса заданий блокнота, передаче параметров между различными этапами блокнота, планированию рабочего процесса и его мониторингу с помощью SageMaker Studio.
Для нашей задачи машинного обучения в этом примере мы создаем модель анализа настроений, которая представляет собой тип задачи классификации текста. Наиболее распространенные применения анализа настроений включают мониторинг социальных сетей, управление службой поддержки клиентов и анализ отзывов клиентов. В этом примере используется набор данных Stanford Sentiment Treebank (SST2), который состоит из обзоров фильмов и целого числа (0 или 1), которое указывает на положительное или отрицательное настроение обзора.
Ниже приведен пример data.csv файл, соответствующий набору данных SST2, и показывает значения в первых двух столбцах. Обратите внимание, что файл не должен иметь заголовка.
| Колонка 1 | Колонка 2 |
| 0 | скрыть новые выделения от родительских блоков |
| 0 | не содержит остроумия, только вымученные приколы |
| 1 | который любит своих персонажей и сообщает что-то довольно прекрасное о человеческой природе |
| 0 | остается полностью удовлетворенным, чтобы оставаться неизменным на протяжении всего |
| 0 | на худших клише о мести ботаников, которые смогли выкопать создатели фильма |
| 0 | это слишком трагично, чтобы заслуживать такого поверхностного отношения |
| 1 | демонстрирует, что режиссер таких голливудских блокбастеров, как патриотические игры, все еще может снять небольшой личный фильм с эмоциональной ударной силой. |
В этом примере ML мы должны выполнить несколько задач:
- Выполните разработку функций, чтобы подготовить этот набор данных в формате, понятном нашей модели.
- После проектирования функций запустите этап обучения с использованием трансформаторов.
- Настройте пакетный вывод с помощью точно настроенной модели, чтобы спрогнозировать настроение новых поступивших отзывов.
- Настройте этап мониторинга данных, чтобы мы могли регулярно отслеживать наши новые данные на предмет любого отклонения в качестве, которое может потребовать от нас повторного обучения весов модели.
Запустив задание блокнота в качестве шага в конвейерах SageMaker, мы можем организовать этот рабочий процесс, который состоит из трех отдельных шагов. Каждый шаг рабочего процесса разрабатывается в отдельной записной книжке, которая затем преобразуется в независимые этапы заданий записной книжки и подключаются в виде конвейера:
- предварительная обработка – Загрузите общедоступный набор данных SST2 с сайта Простой сервис хранения Amazon (Amazon S3) и создайте файл CSV для запуска блокнота на шаге 2. Набор данных SST2 представляет собой набор данных классификации текста с двумя метками (0 и 1) и столбцом текста для классификации.
- Обучение – Возьмите сформированный файл CSV и запустите точную настройку с помощью BERT для классификации текста с использованием библиотек Transformers. На этом этапе мы используем блокнот для подготовки тестовых данных, который является зависимостью для этапов точной настройки и пакетного вывода. После завершения тонкой настройки этот блокнот запускается с помощью магии запуска и подготавливает тестовый набор данных для выборочного вывода с помощью точно настроенной модели.
- Трансформируйте и контролируйте – Выполните пакетный вывод и настройте качество данных с помощью мониторинга модели, чтобы получить рекомендации по базовому набору данных.
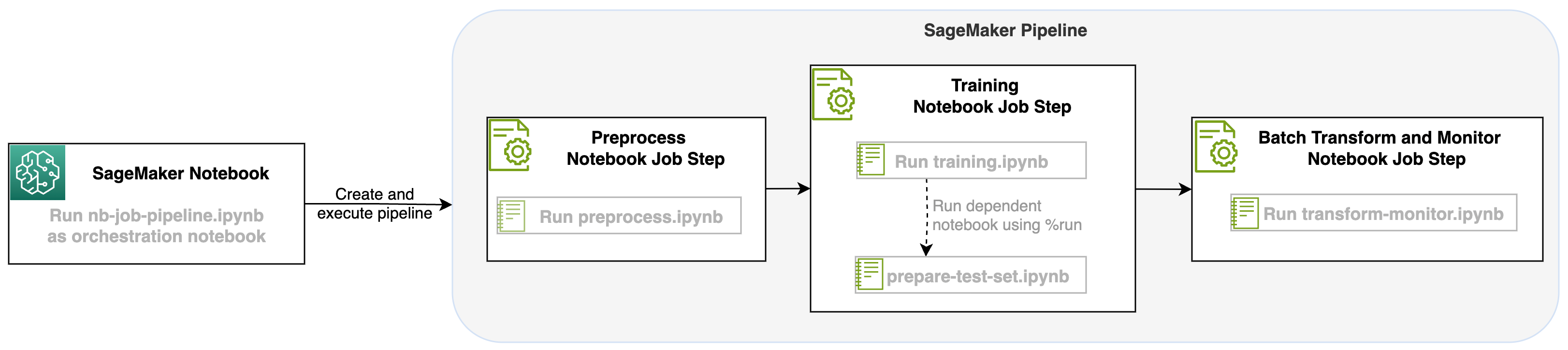
Запустите блокноты
Пример кода для этого решения доступен на сайте GitHub.
Создание шага задания блокнота SageMaker аналогично созданию других шагов SageMaker Pipeline. В этом примере блокнота мы используем SageMaker Python SDK для организации рабочего процесса. Чтобы создать шаг блокнота в SageMaker Pipelines, вы можете определить следующие параметры:
- Входной блокнот – Имя записной книжки, которую будет организовывать этот шаг записной книжки. Здесь вы можете передать локальный путь к входному блокноту. При желании, если на этом блокноте есть другие запущенные блокноты, вы можете передать их в
AdditionalDependenciesпараметр для шага задания блокнота. - URI изображения – Изображение Docker за этапом задания блокнота. Это могут быть предопределенные изображения, которые уже предоставляет SageMaker, или пользовательское изображение, которое вы определили и отправили в Реестр Amazon Elastic Container (Амазонка ECR). Обратитесь к разделу рекомендаций в конце этого поста, чтобы узнать о поддерживаемых изображениях.
- Имя ядра – Имя ядра, которое вы используете в SageMaker Studio. Эта спецификация ядра зарегистрирована в предоставленном вами образе.
- Тип экземпляра (необязательно) - Эластичное вычислительное облако Amazon (Amazon EC2) Тип экземпляра задания блокнота, которое вы определили и которое будет выполняться.
- Параметры (необязательно) – Параметры, которые вы можете передать и которые будут доступны для вашего блокнота. Их можно определить в парах ключ-значение. Кроме того, эти параметры можно изменять между различными запусками заданий записной книжки или запусками конвейера.
В нашем примере всего пять блокнотов:
- nb-job-pipeline.ipynb – Это наша основная записная книжка, в которой мы определяем наш конвейер и рабочий процесс.
- preprocess.ipynb – Этот блокнот является первым шагом в нашем рабочем процессе и содержит код, который извлекает общедоступный набор данных AWS и создает из него файл CSV.
- обучение.ipynb – Этот блокнот является вторым этапом нашего рабочего процесса и содержит код для использования CSV-файла из предыдущего шага и проведения локального обучения и тонкой настройки. Этот шаг также зависит от
prepare-test-set.ipynbблокнот, чтобы получить тестовый набор данных для выборочного вывода с помощью точно настроенной модели. - подготовить-тест-set.ipynb – В этом блокноте создается тестовый набор данных, который наш обучающий блокнот будет использовать на втором этапе конвейера и для выборочного вывода с помощью точно настроенной модели.
- Transform-monitor.ipynb – Этот блокнот является третьим шагом в нашем рабочем процессе. Он использует базовую модель BERT и запускает задание пакетного преобразования SageMaker, а также настраивает качество данных с помощью мониторинга модели.
Далее проходимся по основному блокноту nb-job-pipeline.ipynb, который объединяет все субноутбуки в конвейер и запускает сквозной рабочий процесс. Обратите внимание: хотя в следующем примере записная книжка запускается только один раз, вы также можете запланировать конвейер для многократного запуска записной книжки. Ссылаться на Документация SageMaker для получения подробных инструкций.
Для нашего первого шага задания блокнота мы передаем параметр с корзиной S3 по умолчанию. Мы можем использовать это ведро для сброса любых артефактов, которые мы хотим использовать для других шагов конвейера. Для первой тетради(preprocess.ipynb), мы извлекаем общедоступный набор данных поезда AWS SST2 и создаем из него обучающий CSV-файл, который помещаем в эту корзину S3. См. следующий код:
Затем мы можем преобразовать этот блокнот в NotebookJobStep со следующим кодом в нашей основной записной книжке:
Теперь, когда у нас есть образец CSV-файла, мы можем начать обучение нашей модели в учебном блокноте. Наш обучающий блокнот принимает тот же параметр, что и сегмент S3, и извлекает набор обучающих данных из этого места. Затем мы выполняем тонкую настройку с помощью объекта-тренера Transformers со следующим фрагментом кода:
После тонкой настройки мы хотим выполнить пакетный вывод, чтобы увидеть, как работает модель. Это делается с помощью отдельной тетради (prepare-test-set.ipynb) по тому же локальному пути, который создает тестовый набор данных для выполнения вывода на основе нашей обученной модели. Мы можем запустить дополнительный блокнот в нашем тренировочном блокноте с помощью следующей волшебной ячейки:
Мы определяем эту дополнительную зависимость блокнота в AdditionalDependencies параметр на втором этапе задания блокнота:
Мы также должны указать, что шаг задания обучающего блокнота (шаг 2) зависит от шага задания предварительной обработки блокнота (шаг 1), используя add_depends_on Вызов API следующим образом:
Наш последний шаг: модель BERT запустит пакетное преобразование SageMaker, а также настроит сбор данных и качество с помощью SageMaker Model Monitor. Обратите внимание, что это отличается от использования встроенного Transform or захват шаги через конвейеры. Наш блокнот на этом этапе будет выполнять те же API, но будет отслеживаться как шаг задания блокнота. Этот шаг зависит от шага обучающего задания, который мы определили ранее, поэтому мы также фиксируем его с помощью флагаdependent_on.
После определения различных этапов нашего рабочего процесса мы можем создать и запустить сквозной конвейер:
Следите за ходом трубопровода
Вы можете отслеживать и контролировать выполнение шагов записной книжки с помощью группы обеспечения доступности баз данных SageMaker Pipelines, как показано на следующем снимке экрана.
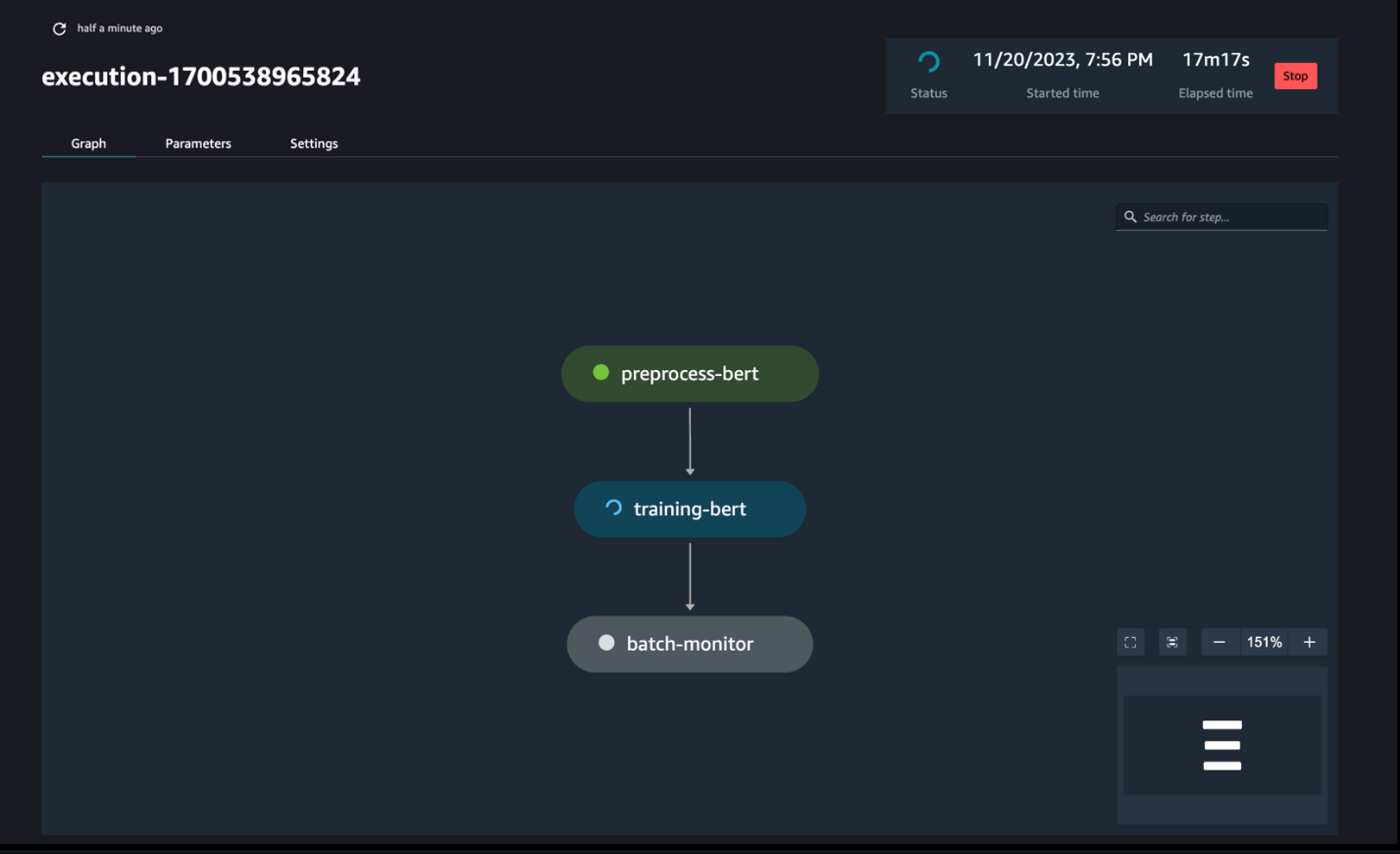
При желании вы также можете отслеживать выполнение отдельных блокнотов на панели задач блокнота и переключать выходные файлы, созданные через пользовательский интерфейс SageMaker Studio. При использовании этой функции за пределами SageMaker Studio вы можете определить пользователей, которые смогут отслеживать статус выполнения на информационной панели заданий блокнота с помощью тегов. Дополнительные сведения о тегах, которые следует включить, см. Просматривайте задания записной книжки и загружайте результаты на панели мониторинга пользовательского интерфейса Studio..
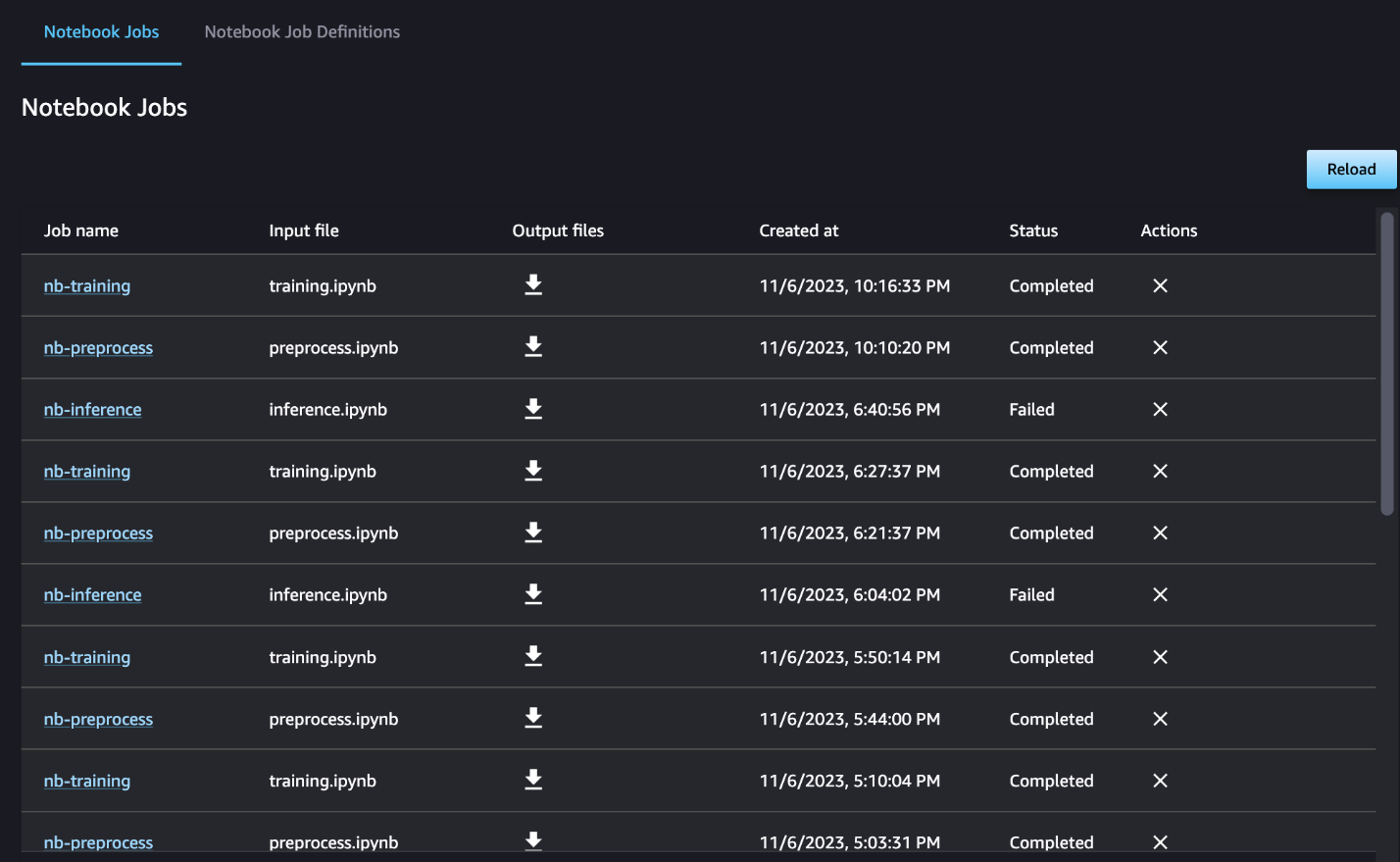
В этом примере мы выводим полученные задания блокнота в каталог с именем outputs в вашем локальном пути с кодом запуска вашего конвейера. Как показано на следующем снимке экрана, здесь вы можете увидеть выходные данные входного блокнота, а также любые параметры, которые вы определили для этого шага.
Убирать
Если вы последовали нашему примеру, обязательно удалите созданный конвейер, задания блокнота и данные s3, загруженные примерами блокнотов.
Соображения
Ниже приведены некоторые важные соображения по поводу этой функции:
- Ограничения SDK – Шаг задания блокнота можно создать только с помощью SageMaker Python SDK.
- Ограничения изображения –Шаг задания блокнота поддерживает следующие изображения:
Заключение
Благодаря этому запуску сотрудники, работающие с данными, теперь могут программно запускать свои блокноты с помощью нескольких строк кода, используя SDK для SageMaker Python. Кроме того, вы можете создавать сложные многоэтапные рабочие процессы, используя свои блокноты, что значительно сокращает время, необходимое для перехода от блокнота к конвейеру CI/CD. После создания конвейера вы можете использовать SageMaker Studio для просмотра и запуска групп обеспечения доступности баз данных для ваших конвейеров, а также для управления и сравнения запусков. Независимо от того, планируете ли вы сквозные рабочие процессы машинного обучения или их часть, мы рекомендуем вам попробовать рабочие процессы на основе блокнота.
Об авторах
 Анчит Гупта — старший менеджер по продукту Amazon SageMaker Studio. Она специализируется на обеспечении интерактивных рабочих процессов обработки данных и обработки данных в интегрированной среде разработки SageMaker Studio. В свободное время она любит готовить, играть в настольные/карточные игры и читать.
Анчит Гупта — старший менеджер по продукту Amazon SageMaker Studio. Она специализируется на обеспечении интерактивных рабочих процессов обработки данных и обработки данных в интегрированной среде разработки SageMaker Studio. В свободное время она любит готовить, играть в настольные/карточные игры и читать.
 Рам Вегираджу является архитектором машинного обучения в команде SageMaker Service. Он помогает клиентам создавать и оптимизировать свои решения AI/ML на Amazon SageMaker. В свободное время любит путешествовать и писать.
Рам Вегираджу является архитектором машинного обучения в команде SageMaker Service. Он помогает клиентам создавать и оптимизировать свои решения AI/ML на Amazon SageMaker. В свободное время любит путешествовать и писать.
 Эдвард Сан — старший SDE, работающий в SageMaker Studio в Amazon Web Services. Он занимается созданием интерактивного решения машинного обучения и упрощением работы с клиентами для интеграции SageMaker Studio с популярными технологиями в области обработки данных и экосистемы машинного обучения. В свободное время Эдвард любит походы, походы и рыбалку, а также любит проводить время со своей семьей.
Эдвард Сан — старший SDE, работающий в SageMaker Studio в Amazon Web Services. Он занимается созданием интерактивного решения машинного обучения и упрощением работы с клиентами для интеграции SageMaker Studio с популярными технологиями в области обработки данных и экосистемы машинного обучения. В свободное время Эдвард любит походы, походы и рыбалку, а также любит проводить время со своей семьей.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :имеет
- :является
- :куда
- $UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- О нас
- доступной
- ациклический
- дополнительный
- Дополнительно
- плюс
- После
- AI / ML
- Все
- позволяет
- вдоль
- уже
- причислены
- Несмотря на то, что
- Amazon
- Amazon EC2
- Создатель мудреца Амазонки
- Студия Amazon SageMaker
- Amazon Web Services
- an
- анализ
- анализ
- и
- любой
- API
- API
- Приложения
- архитектура
- МЫ
- AS
- At
- автоматизировать
- доступен
- AWS
- Использование темпера с изогнутым основанием
- основанный
- Базовая линия
- BE
- красивая
- было
- за
- не являетесь
- Лучшая
- между
- большой
- строить
- Строительство
- встроенный
- но
- by
- призывают
- под названием
- кемпинг
- CAN
- захватить
- случаев
- случаев
- ячейка
- символы
- классификация
- код
- Column
- Колонки
- комбинаты
- как
- Общий
- сравнить
- полный
- комплекс
- состоящие
- Состоит
- Вычисление
- Проводить
- подключенный
- соображения
- состоит
- Container
- содержит
- (CIJ)
- конвертировать
- переделанный
- приготовление
- соответствующий
- может
- Создайте
- создали
- создает
- Создающий
- В настоящее время
- изготовленный на заказ
- клиент
- опыт работы с клиентами
- служба поддержки
- Клиенты
- DAG
- приборная панель
- данным
- мониторинг данных
- Подготовка данных
- обработка данных
- Качество данных
- наука о данных
- Наборы данных
- По умолчанию
- определять
- определенный
- поставка
- Спрос
- Зависимости
- Зависимость
- зависимый
- зависит
- развертывание
- развертывание
- подробный
- подробнее
- развивать
- развитый
- различный
- направлять
- направленный
- директор
- отчетливый
- Docker
- дело
- сделанный
- вниз
- скачать
- дамп
- каждый
- легко
- экосистема
- Эдвард
- включить
- позволяет
- поощрять
- конец
- впритык
- Проект и
- Весь
- эпоха
- Эфир (ETH)
- пример
- выполнять
- выполнение
- опыт
- дополнительно
- извлечение
- семья
- вентилятор
- далеко
- Особенность
- Обратная связь
- несколько
- Файл
- Файлы
- фильм
- режиссеры
- Во-первых,
- Рыбалка
- 5
- внимание
- фокусируется
- следует
- после
- следующим образом
- Что касается
- форма
- формат
- от
- полностью
- функциональность
- Более того
- Игры
- порождать
- Графики
- Есть
- he
- помощь
- помощь
- ее
- здесь
- пеший туризм
- его
- Голливуд
- Как
- HTML
- HTTP
- HTTPS
- человек
- if
- иллюстрирует
- изображение
- изображений
- немедленно
- Импортировать
- важную
- in
- включают
- независимые
- указывает
- individual
- вход
- пример
- инструкции
- интегрировать
- интеграции.
- интерактивный
- в
- IT
- ЕГО
- работа
- Джобс
- JPG
- всего
- этикетка
- Этикетки
- Фамилия
- запуск
- изучение
- библиотеки
- линия
- линий
- загрузка
- локальным
- расположение
- Длинное
- любит
- машина
- обучение с помощью машины
- магия
- Главная
- ДЕЛАЕТ
- управлять
- управляемого
- управление
- менеджер
- Медиа
- Заслуга
- может быть
- ML
- модель
- Модели
- модифицировало
- Модули
- монитор
- Мониторинг
- Мониторы
- БОЛЕЕ
- самых
- двигаться
- кино
- с разными
- должен
- имя
- родной
- Необходимость
- необходимый
- отрицательный
- Новые
- нет
- в своих размышлениях
- ноутбук
- ноутбуки
- сейчас
- объект
- of
- .
- on
- ONE
- только
- Оптимизировать
- or
- оркестровка
- Другое
- наши
- внешний
- выходной
- выходы
- внешнюю
- пар
- параметр
- параметры
- часть
- pass
- Прохождение
- путь
- выполнять
- выполнения
- личного
- трубопровод
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- Популярное
- положительный
- После
- предсказывать
- подготовка
- Подготовить
- Готовит
- подготовка
- предыдущий
- предварительно
- Проблема
- обработка
- Продукт
- Менеджер по продукции
- обеспечивать
- при условии
- приводит
- что такое варган?
- Тянет
- целей
- Push
- толкнул
- Питон
- быстрее
- R
- скорее
- Читать
- Reading
- повторяющихся
- снижение
- Рефакторинг
- относиться
- зарегистрированный
- регулярно
- оставаться
- НЕОДНОКРАТНО
- требовать
- в результате
- обзоре
- Отзывы
- Run
- Бег
- работает
- sagemaker
- Конвейеры SageMaker
- то же
- довольный
- график
- считаться
- Запланированные задания
- планирование
- Наука
- Ученые
- SDK
- Во-вторых
- Раздел
- разделах
- посмотреть
- видел
- старший
- настроение
- отдельный
- обслуживание
- Услуги
- Сессия
- набор
- установка
- несколько
- формы
- она
- должен
- показывать
- демонстрации
- показанный
- Шоу
- значительный
- существенно
- аналогичный
- просто
- упрощение
- одинарной
- небольшой
- меньше
- отрывок
- So
- Соцсети
- социальные сети
- Решение
- Решения
- РЕШАТЬ
- некоторые
- удалось
- Space
- конкретный
- Расходы
- автономные
- Стэнфорд
- Начало
- Статус:
- Шаг
- Шаги
- По-прежнему
- диск
- простой
- студия
- такие
- Вс
- поддержка
- Поддержанный
- Поддержка
- Убедитесь
- взять
- принимает
- Сложность задачи
- задачи
- команда
- технологии
- тестXNUMX
- текст
- Классификация текста
- который
- Ассоциация
- их
- Их
- тогда
- Эти
- В третьих
- этой
- те
- три
- Через
- время
- в
- вместе
- слишком
- инструментом
- Всего
- трек
- Train
- специалистов
- Обучение
- Transform
- трансформеры
- Путешествие
- вызвать
- ОЧЕРЕДЬ
- два
- напишите
- ui
- понимать
- Обновление ПО
- us
- использование
- прецедент
- используемый
- пользователей
- использования
- через
- Использующий
- Наши ценности
- различный
- с помощью
- Вид
- визуализации
- от
- хотеть
- we
- Web
- веб-сервисы
- когда
- будь то
- , которые
- в то время как
- КТО
- будете
- в
- без
- рабочие
- рабочий
- Рабочие процессы
- работает
- Наихудший
- письмо
- являетесь
- ВАШЕ
- зефирнет