В этом посте мы демонстрируем, как использовать структурную обрезку на основе поиска нейронной архитектуры (NAS) для сжатия точно настроенной модели BERT, чтобы улучшить производительность модели и сократить время вывода. Предварительно обученные языковые модели (PLM) быстро внедряются в коммерческих целях и на предприятиях в области инструментов повышения производительности, обслуживания клиентов, поиска и рекомендаций, автоматизации бизнес-процессов и создания контента. Развертывание конечных точек вывода PLM обычно связано с более высокой задержкой и более высокими затратами на инфраструктуру из-за требований к вычислениям и снижения эффективности вычислений из-за большого количества параметров. Сокращение PLM уменьшает размер и сложность модели, сохраняя при этом ее прогнозные возможности. Урезанные PLM обеспечивают меньший объем памяти и меньшую задержку. Мы демонстрируем это, сокращая PLM и компенсируя количество параметров и ошибки проверки для конкретной целевой задачи, и можем добиться более быстрого времени отклика по сравнению с базовой моделью PLM.
Многокритериальная оптимизация — это область принятия решений, которая оптимизирует более одной целевой функции, такой как потребление памяти, время обучения и вычислительные ресурсы, для оптимизации одновременно. Структурное сокращение — это метод уменьшения размера и вычислительных требований PLM путем сокращения слоев или нейронов/узлов при попытке сохранить точность модели. Путем удаления слоев структурная обрезка обеспечивает более высокую степень сжатия, что приводит к более удобной для аппаратного обеспечения структурированной разреженности, что сокращает время выполнения и время отклика. Применение метода структурного сокращения к модели PLM приводит к созданию более легкой модели с меньшим объемом памяти, которая при размещении в качестве конечной точки вывода в SageMaker обеспечивает повышенную эффективность использования ресурсов и снижение затрат по сравнению с исходной точно настроенной PLM.
Концепции, проиллюстрированные в этом посте, могут быть применены к приложениям, использующим функции PLM, таким как системы рекомендаций, анализ настроений и поисковые системы. В частности, вы можете использовать этот подход, если у вас есть специальные группы по машинному обучению (ML) и науке о данных, которые точно настраивают свои собственные модели PLM с использованием наборов данных, специфичных для предметной области, и развертывают большое количество конечных точек вывода, используя Создатель мудреца Амазонки. Одним из примеров является интернет-магазин, который развертывает большое количество конечных точек вывода для обобщения текста, классификации каталога продуктов и классификации настроений в отзывах о продуктах. Другим примером может быть поставщик медицинских услуг, который использует конечные точки вывода PLM для классификации клинических документов, распознавания именованных объектов из медицинских отчетов, медицинских чат-ботов и стратификации рисков пациентов.
Обзор решения
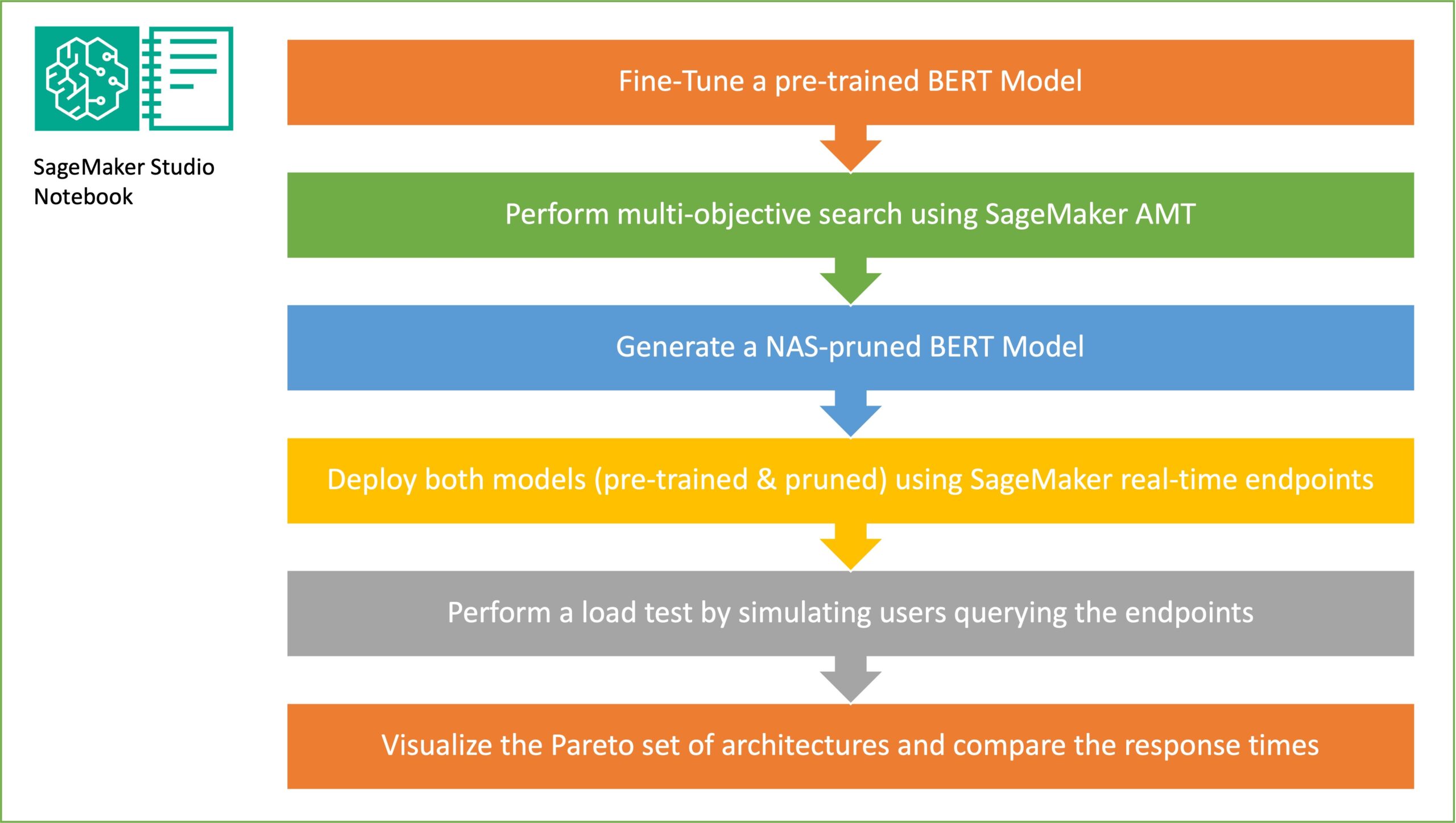
В этом разделе мы представляем общий рабочий процесс и объясняем подход. Сначала мы используем Студия Amazon SageMaker ноутбук для точной настройки предварительно обученной модели BERT для целевой задачи с использованием набора данных для конкретной предметной области. БЕРТ (Представления двунаправленного кодировщика от Transformers) — это предварительно обученная языковая модель, основанная на трансформаторная архитектура используется для задач обработки естественного языка (NLP). Поиск нейронной архитектуры (NAS) — это подход к автоматизации проектирования искусственных нейронных сетей, тесно связанный с оптимизацией гиперпараметров, широко используемым подходом в области машинного обучения. Цель NAS — найти оптимальную архитектуру для конкретной задачи путем поиска по большому набору возможных архитектур с использованием таких методов, как безградиентная оптимизация или путем оптимизации желаемых показателей. Производительность архитектуры обычно измеряется с использованием таких показателей, как потери при проверке. Автоматическая настройка модели SageMaker (AMT) автоматизирует утомительный и сложный процесс поиска оптимальных комбинаций гиперпараметров модели ML, которые обеспечивают наилучшую производительность модели. AMT использует интеллектуальные алгоритмы поиска и итеративные оценки с использованием заданного вами диапазона гиперпараметров. Он выбирает значения гиперпараметров, которые создают модель, которая работает лучше всего, что измеряется такими показателями производительности, как точность и показатель F-1.
Подход тонкой настройки, описанный в этом посте, является универсальным и может применяться к любому набору текстовых данных. Задача, назначенная BERT PLM, может быть текстовой задачей, такой как анализ настроений, классификация текста или вопросы и ответы. В этой демонстрации целевой задачей является задача двоичной классификации, где BERT используется для определения на основе набора данных, состоящего из набора пар текстовых фрагментов, можно ли вывести значение одного текстового фрагмента из другого фрагмента. Мы используем Распознавание набора данных Textual Entailment из пакета бенчмаркинга GLUE. Мы выполняем многокритериальный поиск с использованием SageMaker AMT, чтобы определить подсети, которые предлагают оптимальный компромисс между количеством параметров и точностью прогнозирования для целевой задачи. При выполнении многокритериального поиска мы начинаем с определения точности и количества параметров как целей, которые мы стремимся оптимизировать.
В сети BERT PLM могут быть модульные автономные подсети, которые позволяют модели иметь специализированные возможности, такие как понимание языка и представление знаний. BERT PLM использует многоглавую подсеть самообслуживания и подсеть прямой связи. Многоголовый уровень самообслуживания позволяет BERT связывать различные позиции одной последовательности, чтобы вычислить представление последовательности, позволяя нескольким головкам обрабатывать несколько контекстных сигналов. Входные данные разбиваются на несколько подпространств, и самообладание применяется к каждому из подпространств отдельно. Несколько головок в преобразователе PLM позволяют модели совместно обрабатывать информацию из разных подпространств представления. Подсеть прямой связи — это простая нейронная сеть, которая принимает выходные данные многоголовой подсети самообслуживания, обрабатывает данные и возвращает окончательные представления кодера.
Целью случайной выборки подсети является обучение меньших моделей BERT, которые могут достаточно хорошо работать при выполнении целевых задач. Мы выбираем 100 случайных подсетей из точно настроенной базовой модели BERT и оцениваем 10 сетей одновременно. Обученные подсети оцениваются по объективным метрикам, и окончательная модель выбирается на основе компромиссов, найденных между объективными метриками. Мы визуализируем Фронт Парето для выбранных подсетей, которые содержат сокращенную модель, предлагающую оптимальный компромисс между точностью модели и ее размером. Мы выбираем подсеть-кандидат (модель BERT с сокращением NAS) на основе размера модели и точности модели, которыми мы готовы пожертвовать. Затем мы размещаем конечные точки, предварительно обученную базовую модель BERT и модель BERT, очищенную от NAS, с помощью SageMaker. Для проведения нагрузочного тестирования мы используем саранча, инструмент нагрузочного тестирования с открытым исходным кодом, который можно реализовать с помощью Python. Мы проводим нагрузочное тестирование на обеих конечных точках с помощью Locust и визуализируем результаты с помощью фронта Парето, чтобы проиллюстрировать компромисс между временем отклика и точностью для обеих моделей. На следующей диаграмме представлен обзор рабочего процесса, описанного в этом посте.
Предпосылки
Для этой должности необходимы следующие предпосылки:
Вам также необходимо увеличить квота на обслуживание для доступа как минимум к трем экземплярам ml.g4dn.xlarge в SageMaker. Тип экземпляра ml.g4dn.xlarge — это экономичный экземпляр графического процессора, который позволяет запускать PyTorch в исходном виде. Чтобы увеличить квоту обслуживания, выполните следующие действия:
- На консоли перейдите к «Квоты служб».
- Что касается Управление квотами, выберите Создатель мудреца Амазонки, а затем выберите Просмотр квот.

- Найдите «ml-g4dn.xlarge для использования в учебных заданиях» и выберите элемент квоты.
- Выберите Запросить увеличение на уровне аккаунта.
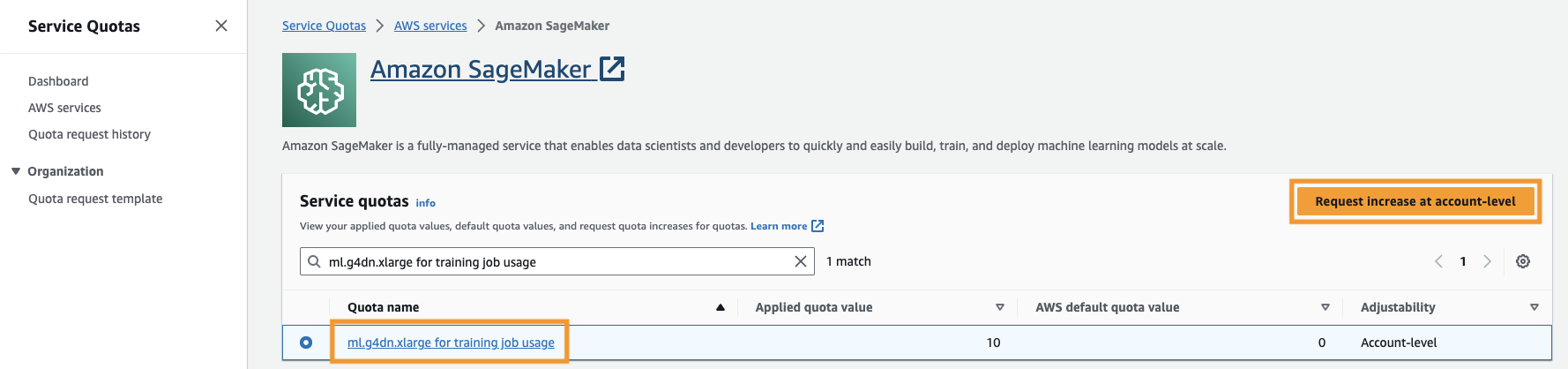
- Что касается Увеличение значения квоты, введите значение 5 или выше.
- Выберите Запрос.
Запрошенное утверждение квоты может занять некоторое время в зависимости от разрешений учетной записи.

- Откройте SageMaker Studio из консоли SageMaker.

- Выберите Системный терминал под Утилиты и файлы.

- Запустите следующую команду, чтобы клонировать Репо GitHub в экземпляр SageMaker Studio:
- Перейдите в
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Открыть файл
nas_for_llm_with_amt.ipynb. - Настройте среду с помощью
ml.g4dn.xlargeэкземпляр и выберите Выберите.

Настройте предварительно обученную модель BERT
В этом разделе мы импортируем набор данных «Распознавание текстового слежения» из библиотеки наборов данных и разделяем этот набор данных на обучающий и проверочный наборы. Этот набор данных состоит из пар предложений. Задача BERT PLM состоит в том, чтобы по двум фрагментам текста распознать, можно ли вывести значение одного фрагмента текста из другого фрагмента. В следующем примере мы можем вывести значение первой фразы из второй фразы:
Мы загружаем набор данных текстового распознавания из КЛЕЙ пакет бенчмаркинга через библиотека наборов данных из «Обнимающего лица» в нашем сценарии обучения (./training.py). Мы разделили исходный набор обучающих данных из GLUE на набор для обучения и проверки. В нашем подходе мы точно настраиваем базовую модель BERT, используя набор обучающих данных, затем выполняем многокритериальный поиск, чтобы определить набор подсетей, которые оптимально балансируют между целевыми метриками. Мы используем набор обучающих данных исключительно для точной настройки модели BERT. Тем не менее, мы используем данные проверки для многоцелевого поиска, измеряя точность набора данных проверки.
Точная настройка BERT PLM с использованием набора данных для конкретной предметной области
Типичные варианты использования необработанной модели BERT включают прогнозирование следующего предложения или моделирование языка в масках. Чтобы использовать базовую модель BERT для последующих задач, таких как распознавание текста, нам необходимо дополнительно настроить модель, используя набор данных для конкретной предметной области. Вы можете использовать точно настроенную модель BERT для таких задач, как классификация последовательностей, ответы на вопросы и классификация токенов. Однако для целей этой демонстрации мы используем точно настроенную модель двоичной классификации. Мы настраиваем предварительно обученную модель BERT с помощью набора обучающих данных, который мы подготовили ранее, используя следующие гиперпараметры:
Сохраняем контрольную точку обучения модели в файле Простой сервис хранения Amazon (Amazon S3), чтобы модель можно было загрузить во время многокритериального поиска на основе NAS. Прежде чем обучать модель, мы определяем такие метрики, как эпоха, потери обучения, количество параметров и ошибка проверки:
После начала процесса тонкой настройки выполнение обучающего задания занимает около 15 минут.
Выполните многоцелевой поиск для выбора подсетей и визуализируйте результаты.
На следующем этапе мы выполняем многокритериальный поиск по точно настроенной базовой модели BERT путем выборки случайных подсетей с помощью SageMaker AMT. Чтобы получить доступ к подсети внутри суперсети (точно настроенная модель BERT), мы маскируем все компоненты PLM, которые не являются частью подсети. Маскирование суперсети для поиска подсетей в PLM — это метод, используемый для изоляции и выявления закономерностей поведения модели. Обратите внимание, что трансформерам Hugging Face требуется, чтобы скрытый размер был кратен количеству голов. Скрытый размер в преобразователе PLM контролирует размер скрытого векторного пространства состояний, что влияет на способность модели изучать сложные представления и закономерности в данных. В BERT PLM вектор скрытого состояния имеет фиксированный размер (768). Мы не можем изменить скрытый размер, поэтому количество голов должно быть в пределах [1, 3, 6, 12].
В отличие от одноцелевой оптимизации, при многоцелевой оптимизации обычно нет единого решения, которое одновременно оптимизирует все цели. Вместо этого мы стремимся собрать набор решений, которые доминируют над всеми другими решениями хотя бы по одной цели (например, по ошибке проверки). Теперь мы можем начать многокритериальный поиск через AMT, задав метрики, которые мы хотим уменьшить (ошибка валидации и количество параметров). Случайные подсети определяются параметром max_jobs а количество одновременных заданий определяется параметром max_parallel_jobs. Код для загрузки контрольной точки модели и оценки подсети доступен в файле evaluate_subnetwork.py скрипты.
Выполнение задания настройки AMT занимает примерно 2 часа 20 минут. После успешного выполнения задания настройки AMT мы анализируем историю задания и собираем конфигурации подсети, такие как количество головок, количество слоев, количество единиц, а также соответствующие показатели, такие как ошибка проверки и количество параметров. На следующем снимке экрана показана сводка успешного задания настройки AMT.
Затем мы визуализируем результаты с помощью набора Парето (также известного как граница Парето или оптимальный набор Парето), который помогает нам определить оптимальные наборы подсетей, которые доминируют над всеми другими подсетями в целевой метрике (ошибка проверки):
Сначала мы собираем данные из задания по настройке AMT. Затем мы строим набор Парето, используя matplotlob.pyplot с количеством параметров по оси X и ошибкой проверки по оси Y. Это означает, что когда мы переходим от одной подсети множества Парето к другой, мы должны либо пожертвовать производительностью или размером модели, но улучшить другую. В конечном счете, набор Парето дает нам возможность выбрать подсеть, которая лучше всего соответствует нашим предпочтениям. Мы можем решить, насколько мы хотим уменьшить размер нашей сети и какой производительностью мы готовы пожертвовать.

Разверните точно настроенную модель BERT и модель подсети, оптимизированную для NAS, с помощью SageMaker.
Затем мы развертываем самую большую модель в нашем наборе Парето, которая приводит к наименьшему снижению производительности до Конечная точка SageMaker. Лучшая модель — это та, которая обеспечивает оптимальный компромисс между ошибкой проверки и количеством параметров для нашего варианта использования.
Сравнение моделей
Мы взяли предварительно обученную базовую модель BERT, настроили ее с использованием набора данных для конкретной предметной области, запустили поиск NAS для выявления доминирующих подсетей на основе объективных показателей и развернули сокращенную модель на конечной точке SageMaker. Кроме того, мы взяли предварительно обученную базовую модель BERT и развернули ее на второй конечной точке SageMaker. Далее мы побежали нагрузочное тестирование используя Locust для обеих конечных точек вывода, и оценил производительность с точки зрения времени отклика.
Сначала импортируем необходимые библиотеки Locust и Boto3. Затем мы создаем метаданные запроса и записываем время начала, которое будет использоваться для нагрузочного тестирования. Затем полезные данные передаются в API вызова конечной точки SageMaker через BotoClient для имитации реальных запросов пользователя. Мы используем Locust для создания нескольких виртуальных пользователей для параллельной отправки запросов и измерения производительности конечной точки под нагрузкой. Тесты запускаются путем увеличения количества пользователей для каждой из двух конечных точек соответственно. После завершения тестов Locust выводит CSV-файл статистики запросов для каждой из развернутых моделей.
Затем мы генерируем графики времени отклика из CSV-файлов, загруженных после запуска тестов с помощью Locust. Целью построения графика зависимости времени ответа от количества пользователей является анализ результатов нагрузочного тестирования путем визуализации влияния времени ответа конечных точек модели. На следующей диаграмме мы видим, что конечная точка модели с сокращением NAS обеспечивает более низкое время отклика по сравнению с конечной точкой базовой модели BERT.
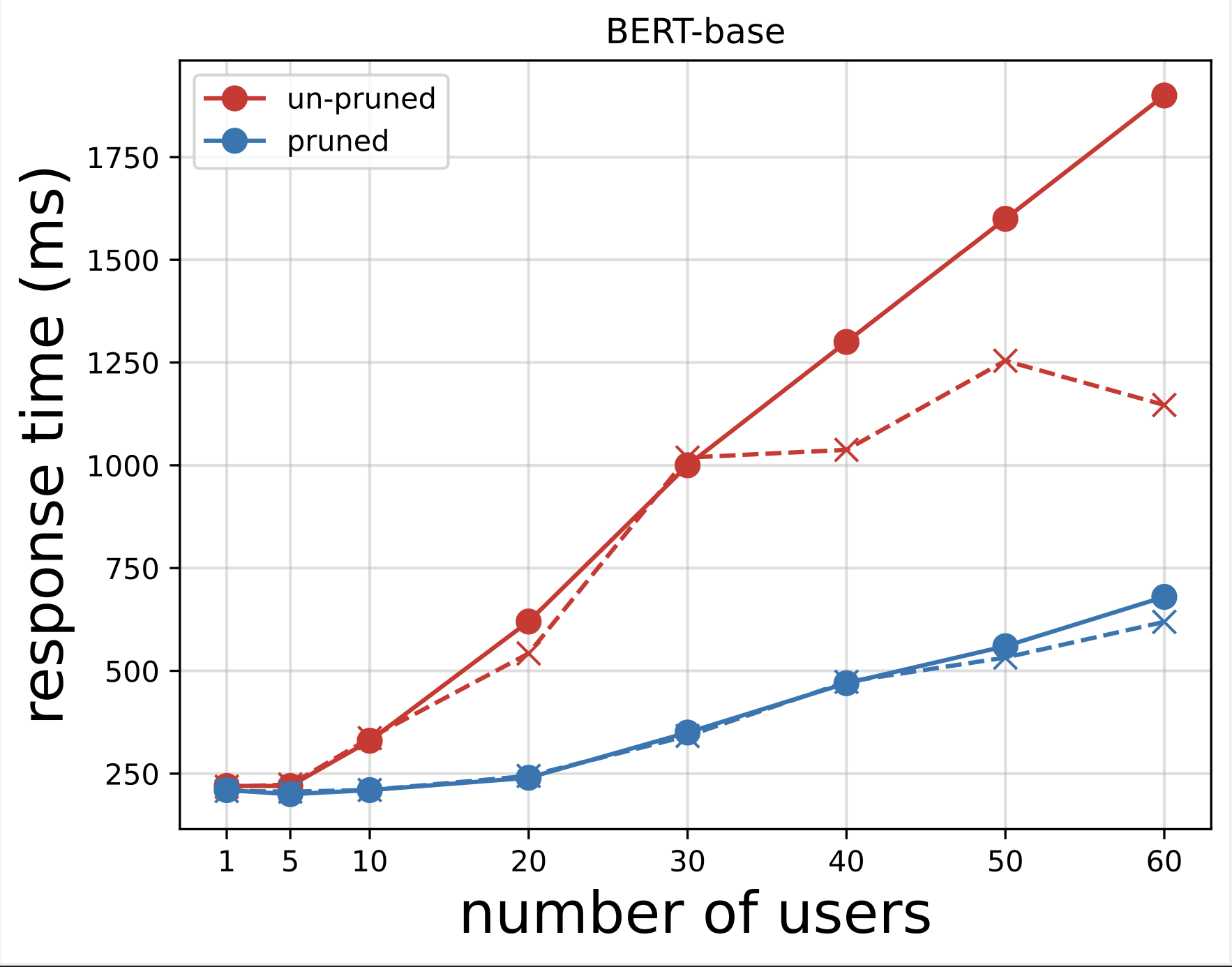
На второй диаграмме, которая является расширением первой диаграммы, мы видим, что примерно после 70 пользователей SageMaker начинает регулировать конечную точку базовой модели BERT и выдает исключение. Однако для конечной точки модели с сокращением NAS регулирование происходит между 90–100 пользователями и с меньшим временем отклика.

Из двух диаграмм мы видим, что сокращенная модель имеет более быстрое время отклика и лучше масштабируется по сравнению с необрезанной моделью. По мере того как мы масштабируем количество конечных точек вывода, как это происходит с пользователями, которые развертывают большое количество конечных точек вывода для своих PLM-приложений, экономическая выгода и повышение производительности начинают становиться весьма существенными.
Убирать
Чтобы удалить конечные точки SageMaker для точно настроенной базовой модели BERT и модели с сокращением NAS, выполните следующие шаги:
- На консоли SageMaker выберите вывод и Endpoints в навигационной панели.
- Выберите конечную точку и удалите ее.
Альтернативно, из блокнота SageMaker Studio выполните следующие команды, указав имена конечных точек:
Заключение
В этом посте мы обсудили, как использовать NAS для обрезки точно настроенной модели BERT. Сначала мы обучили базовую модель BERT, используя данные, специфичные для предметной области, и развернули ее на конечной точке SageMaker. Мы выполнили многокритериальный поиск по точно настроенной базовой модели BERT с использованием SageMaker AMT для целевой задачи. Мы визуализировали фронт Парето, выбрали оптимальную по Парето модель BERT, сокращенную с помощью NAS, и развернули ее на второй конечной точке SageMaker. Мы провели нагрузочное тестирование с помощью Locust, чтобы имитировать пользователей, запрашивающих обе конечные точки, а также измерили и записали время ответа в файл CSV. Мы построили график зависимости времени отклика от количества пользователей для обеих моделей.
Мы заметили, что урезанная модель BERT работает значительно лучше как по времени отклика, так и по порогу регулирования экземпляра. Мы пришли к выводу, что модель с сокращением NAS была более устойчивой к увеличению нагрузки на конечную точку, обеспечивая более низкое время отклика, даже если больше пользователей подвергали систему нагрузке, по сравнению с базовой моделью BERT. Вы можете применить метод NAS, описанный в этом посте, к любой большой языковой модели, чтобы найти сокращенную модель, которая сможет выполнить целевую задачу со значительно меньшим временем отклика. Вы можете дополнительно оптимизировать подход, используя задержку в качестве параметра в дополнение к потерям при проверке.
Хотя в этой статье мы используем NAS, квантование — еще один распространенный подход, используемый для оптимизации и сжатия моделей PLM. Квантование снижает точность весов и активаций в обученной сети с 32-битной плавающей запятой до более низких разрядностей, таких как 8-битные или 16-битные целые числа, что приводит к сжатой модели, которая генерирует более быстрый вывод. Квантование не уменьшает количество параметров; вместо этого он снижает точность существующих параметров, чтобы получить сжатую модель. Очистка NAS удаляет избыточные сети в PLM, что создает разреженную модель с меньшим количеством параметров. Обычно сокращение и квантование NAS используются вместе для сжатия больших PLM-файлов, чтобы сохранить точность модели, уменьшить потери при проверке, одновременно повышая производительность и уменьшая размер модели. Другие часто используемые методы уменьшения размера PLM включают в себя: дистилляция знаний, матричная факторизацияи дистилляционные каскады.
Подход, предложенный в блоге, подходит для команд, которые используют SageMaker для обучения и точной настройки моделей с использованием данных, специфичных для предметной области, а также развертывания конечных точек для генерации логических выводов. Если вы ищете полностью управляемый сервис, предлагающий выбор высокопроизводительных базовых моделей, необходимых для создания генеративных приложений искусственного интеллекта, рассмотрите возможность использования Коренная порода Амазонки. Если вы ищете предварительно обученные модели с открытым исходным кодом для широкого спектра вариантов использования в бизнесе и хотите получить доступ к шаблонам решений и примерам блокнотов, рассмотрите возможность использования Amazon SageMaker JumpStart. Предварительно обученная версия базовой модели Hugging Face BERT, которую мы использовали в этом посте, также доступна в SageMaker JumpStart.
Об авторах
 Апараджитан Вайдьянатан — главный архитектор корпоративных решений в AWS. Он облачный архитектор с более чем 24-летним опытом проектирования и разработки корпоративных, крупномасштабных и распределенных программных систем. Он специализируется на генеративном искусственном интеллекте и машинном обучении данных. Он начинающий марафонец, а его хобби — пеший туризм, езда на велосипеде и проведение времени с женой и двумя сыновьями.
Апараджитан Вайдьянатан — главный архитектор корпоративных решений в AWS. Он облачный архитектор с более чем 24-летним опытом проектирования и разработки корпоративных, крупномасштабных и распределенных программных систем. Он специализируется на генеративном искусственном интеллекте и машинном обучении данных. Он начинающий марафонец, а его хобби — пеший туризм, езда на велосипеде и проведение времени с женой и двумя сыновьями.
 Аарон Кляйн — старший научный сотрудник AWS, работающий над методами автоматизированного машинного обучения для глубоких нейронных сетей.
Аарон Кляйн — старший научный сотрудник AWS, работающий над методами автоматизированного машинного обучения для глубоких нейронных сетей.
 Яцек Голебёвски является старшим научным сотрудником в AWS.
Яцек Голебёвски является старшим научным сотрудником в AWS.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :имеет
- :является
- :нет
- :куда
- ][п
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- способность
- в состоянии
- доступ
- Учетная запись
- точность
- Достигать
- Достигает
- активации
- дополнение
- Принятие
- После
- AI
- цель
- Стремясь
- алгоритмы
- Все
- позволять
- Позволяющий
- позволяет
- причислены
- Amazon
- Amazon Web Services
- количество
- an
- анализ
- аналитика
- анализировать
- и
- Другой
- ответ
- любой
- API
- Приложения
- прикладной
- Применить
- Применение
- подхода
- утверждение
- примерно
- архитектура
- МЫ
- ПЛОЩАДЬ
- области
- Аргументы
- около
- искусственный
- искусственные нейронные сети
- AS
- стремящийся
- назначенный
- связанный
- At
- попытки
- посещать
- Автоматизированный
- автоматизированное машинное обучение
- автоматы
- Автоматический
- Автоматизация
- автоматизация
- доступен
- AWS
- Ось
- Баланс
- Использование темпера с изогнутым основанием
- основанный
- BE
- становиться
- до
- поведение
- бенчмаркинг
- Преимущества
- ЛУЧШЕЕ
- Лучшая
- между
- Немного
- тело
- изоферменты печени
- строить
- бизнес
- Бизнес-процесс
- Автоматизация бизнес процессов
- но
- by
- CAN
- кандидат
- возможности
- случаев
- случаев
- каталог
- изменение
- График
- Графики
- chatbots
- выбор
- Выберите
- выбранный
- класс
- классификация
- Клинический
- тесно
- облако
- код
- собирать
- лыжных шлемов
- комбинации
- коммерческая
- Общий
- обычно
- сравненный
- полный
- Заполненная
- комплекс
- сложность
- компоненты
- вычислительный
- Вычисление
- понятия
- в заключении исследования, финансируемого Центрами по контролю и профилактике заболеваний (CDC) и написанного бывшим начальником полиции Вермонта
- Рассматривать
- состоит
- Консоли
- ограничения
- строить
- потребление
- содержит
- содержание
- контентного создание
- контекст
- продолжать
- контраст
- контрольная
- соответствующий
- Цена
- Расходы
- считать
- Создайте
- создает
- создание
- клиент
- Служба поддержки игроков
- данным
- наука о данных
- Наборы данных
- Дата и время
- решать
- Принятие решений
- преданный
- глубоко
- глубокие нейронные сети
- определять
- определенный
- определяющий
- Демо
- демонстрировать
- в зависимости
- развертывание
- развернуть
- развертывание
- развертывает
- описано
- Проект
- проектирование
- желанный
- развивающийся
- различный
- обсуждается
- распределенный
- документ
- не
- доминирующий
- господствовать
- Dont
- два
- в течение
- e
- каждый
- затрат
- эффективный
- или
- Конечная точка
- конечные точки
- Проект и
- Двигатели
- достаточно
- Enter
- Предприятие
- принятие на предприятии
- Решения для предприятий
- организация
- запись
- Окружающая среда
- эпоха
- ошибка
- Эфир (ETH)
- оценивать
- оценивается
- оценки
- Даже
- События
- пример
- Кроме
- исключение
- исключительно
- существующий
- опыт
- Объяснять
- объяснены
- расширение
- Face
- ложный
- быстрее
- Особенности
- Обратная связь
- меньше
- поле
- Файл
- Файлы
- окончательный
- Найдите
- обнаружение
- First
- фиксированной
- Трансформируемость
- плавающий
- после
- след
- Что касается
- найденный
- Год основания
- от
- передний
- Граница
- полностью
- функция
- далее
- порождать
- генерирует
- генеративный
- Генеративный ИИ
- получить
- данный
- цель
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- серый
- происходит
- Есть
- he
- главы
- здравоохранение
- помогает
- Скрытый
- высокопроизводительный
- высший
- пеший туризм
- его
- история
- Увлечения
- кашель
- состоялся
- ЧАСЫ
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- ОбниматьЛицо
- Оптимизация гиперпараметра
- Настройка гиперпараметра
- i
- определения
- IDX
- if
- иллюстрировать
- Влияние
- Воздействие
- осуществлять
- Импортировать
- улучшать
- улучшенный
- улучшение
- улучшение
- in
- включают
- Увеличение
- расширились
- повышение
- информация
- Инфраструктура
- вход
- пример
- случаев
- вместо
- Умный
- в
- IT
- ЕГО
- работа
- Джобс
- JPG
- JSON
- знания
- известный
- язык
- большой
- крупномасштабный
- крупнейших
- Задержка
- слой
- слоев
- Лиды
- УЧИТЬСЯ
- изучение
- наименее
- позволять
- библиотеки
- Библиотека
- линия
- загрузка
- журнал
- каротаж
- искать
- от
- потери
- ниже
- машина
- обучение с помощью машины
- поддерживать
- сохранение
- человек
- управляемого
- Марафон
- маска
- Matplotlib
- максимальный
- Май..
- смысл
- проводить измерение
- измеренный
- измерение
- основным медицинским
- Встречайте
- Память
- Метаданные
- методы
- метрический
- Метрика
- может быть
- минимизировать
- минут
- ML
- модель
- моделирование
- Модели
- модульный
- БОЛЕЕ
- двигаться
- много
- с разными
- должен
- имя
- Названный
- имена
- в
- натуральный
- Естественный язык
- Обработка естественного языка
- Откройте
- Навигация
- необходимо
- Необходимость
- необходимый
- потребности
- сеть
- сетей
- нервный
- нейронной сети
- нейронные сети
- следующий
- НЛП
- Ничто
- в своих размышлениях
- ноутбук
- ноутбуки
- сейчас
- номер
- объект
- цель
- целей
- наблюдать
- наблюдается
- of
- от
- предлагают
- Предложения
- on
- ONE
- онлайн
- интернет-магазин
- только
- открытый
- с открытым исходным кодом
- оптимальный
- оптимизация
- Оптимизировать
- оптимизированный
- оптимизирует
- оптимизирующий
- or
- заказ
- оригинал
- Другое
- наши
- внешний
- выходной
- выходы
- за
- общий
- обзор
- собственный
- пар
- хлеб
- Параллельные
- параметр
- параметры
- Парето
- часть
- Прошло
- путь
- пациент
- паттеранами
- выполнять
- производительность
- выполнены
- выполнения
- выполняет
- Разрешения
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Точка
- пунктов
- позиции
- После
- Точность
- прогноз
- интеллектуального
- Predictor
- предпочтения
- подготовленный
- предпосылки
- представить
- предварительно
- Основной
- Проблема
- процесс
- Автоматизация процессов
- Процессы
- обработка
- Продукт
- производительность
- Инструменты для
- предложило
- Недвижимости
- приводит
- обеспечение
- тянущий
- Тянет
- цель
- целей
- Питон
- pytorch
- Вопросы и ответы
- вопрос
- вполне
- случайный
- ассортимент
- быстро
- Стоимость
- Сырье
- реальные
- признание
- признавать
- признавая
- Рекомендация
- рекомендаций
- запись
- записанный
- Red
- уменьшить
- Цена снижена
- снижает
- регресс
- Связанный
- удаляет
- удаление
- Отчеты
- представление
- запросить
- просил
- Запросы
- обязательный
- Требования
- упругий
- ресурс
- Полезные ресурсы
- соответственно
- ответ
- Итоги
- розничный торговец
- удерживающий
- Возвращает
- верховая езда
- Снижение
- РЯД
- Run
- бегун
- Бег
- работает
- s
- жертвовать
- sagemaker
- Вывод SageMaker
- Сохранить
- Шкала
- Весы
- Наука
- Ученый
- Гол
- скрипт
- Поиск
- Поисковые системы
- поиск
- Во-вторых
- Раздел
- посмотреть
- выберите
- выбранный
- SELF
- Отправить
- предложение
- настроение
- Последовательность
- обслуживание
- Услуги
- Сессия
- набор
- Наборы
- установка
- Шоу
- сигналы
- существенно
- просто
- одновременный
- одновременно
- одинарной
- Размер
- меньше
- So
- Software
- Решение
- Решения
- некоторые
- Источник
- Space
- Порождать
- специализированный
- специализируется
- конкретный
- конкретно
- Расходы
- раскол
- Начало
- начинается
- Область
- статистика
- Шаг
- Шаги
- диск
- структурный
- структурированный
- студия
- существенный
- успешный
- Успешно
- такие
- подходящее
- suite
- РЕЗЮМЕ
- система
- системы
- T
- взять
- принимает
- цель
- Сложность задачи
- задачи
- команды
- техника
- снижения вреда
- шаблоны
- terms
- Тестирование
- тестов
- текст
- Классификация текста
- текстовый
- чем
- который
- Ассоциация
- их
- тогда
- Там.
- следовательно
- Эти
- этой
- три
- порог
- Через
- время
- раз
- в
- вместе
- знак
- приняли
- инструментом
- инструменты
- торговать
- Торговля
- Train
- специалистов
- Обучение
- трансформатор
- трансформеры
- правда
- стараться
- два
- напишите
- Типы
- типичный
- типично
- В конечном счете
- под
- Проходят
- понимание
- единиц
- us
- использование
- прецедент
- используемый
- Информация о пользователе
- пользователей
- использования
- через
- Проверка
- ценностное
- Наши ценности
- версия
- с помощью
- Виртуальный
- визуализации
- vs
- хотеть
- законопроект
- we
- Web
- веб-сервисы
- ЧТО Ж
- когда
- будь то
- который
- в то время как
- КТО
- широкий
- Широкий диапазон
- широко
- жена
- Википедия.
- будете
- готовый
- в
- Работа
- рабочий
- работает
- X
- лет
- Уступать
- являетесь
- ВАШЕ
- зефирнет