В сегодняшнюю цифровую эпоху данные лежат в основе успеха каждой организации. Одним из наиболее часто используемых форматов обмена данными является XML. Анализ файлов XML имеет решающее значение по нескольким причинам. Во-первых, файлы XML используются во многих отраслях, включая финансы, здравоохранение и правительство. Анализ XML-файлов может помочь организациям получить представление о своих данных, что позволит им принимать более обоснованные решения и улучшать свою деятельность. Анализ файлов XML также может помочь в интеграции данных, поскольку многие приложения и системы используют XML в качестве стандартного формата данных. Анализируя файлы XML, организации могут легко интегрировать данные из разных источников и обеспечить согласованность в своих системах. Однако файлы XML содержат полуструктурированные, сильно вложенные данные, что затрудняет доступ к информации и ее анализ, особенно если файл большой и имеет сложная, сильно вложенная схема.
XML-файлы хорошо подходят для приложений, но могут быть неоптимальны для аналитических систем. Чтобы повысить производительность запросов и обеспечить легкий доступ к последующим аналитическим механизмам, таким как Амазонка Афина, крайне важно предварительно преобразовать XML-файлы в столбчатый формат, такой как Parquet. Это преобразование позволяет повысить эффективность и удобство использования аналитических рабочих процессов. В этом посте мы покажем, как обрабатывать данные XML с помощью Клей AWS и Афина.
Обзор решения
Мы исследуем два различных метода, которые могут упростить рабочий процесс обработки XML-файлов:
- Метод 1. Используйте сканер AWS Glue и визуальный редактор AWS Glue. – Вы можете использовать пользовательский интерфейс AWS Glue вместе с сканером, чтобы определить структуру таблиц для ваших XML-файлов. Этот подход обеспечивает удобный интерфейс и особенно подходит для людей, которые предпочитают графический подход к управлению своими данными.
- Метод 2. Использование AWS Glue DynamicFrames с выведенными и фиксированными схемами – У сканера есть ограничение при обработке одной строки в XML-файлах размером более 1 MB. Чтобы обойти это ограничение, мы используем блокнот AWS Glue для создания AWS Glue.
DynamicFrames, используя как выведенные, так и фиксированные схемы. Этот метод обеспечивает эффективную обработку XML-файлов, размер строк которых превышает 1 МБ.
В обоих подходах наша конечная цель — преобразовать XML-файлы в формат Apache Parquet, сделав их легко доступными для запросов с помощью Athena. С помощью этих методов вы можете повысить скорость обработки и доступность ваших XML-данных, что позволит вам с легкостью получать ценную информацию.
Предпосылки
Прежде чем приступить к работе с этим руководством, выполните следующие предварительные условия (они применимы к обоим методам):
- Загрузите XML-файлы техника1.xml и техника2.xml.
- Загрузите файлы на Простой сервис хранения Amazon (Amazon S3) ведро. Вы можете загрузить их в одну и ту же корзину S3 в разных папках или в разные корзины S3.
- Создать Управление идентификацией и доступом AWS (IAM) для вашего задания ETL или записной книжки, как указано в разделе Настройка разрешений IAM для AWS Glue Studio.
- Добавьте встроенную политику в свою роль с помощью уже: PassRole действие:
- Добавьте политику разрешений к роли с доступом к вашему сегменту S3.
Теперь, когда мы закончили с предварительными условиями, давайте перейдем к реализации первого метода.
Техника 1. Используйте сканер AWS Glue и визуальный редактор.
На следующей диаграмме показана простая архитектура, которую можно использовать для реализации решения.
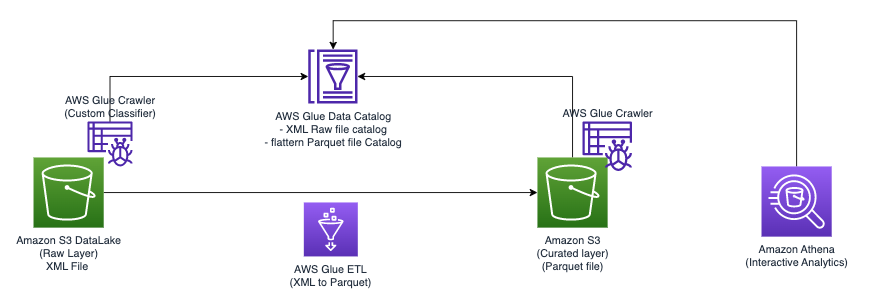
Чтобы проанализировать XML-файлы, хранящиеся в Amazon S3, с помощью AWS Glue и Athena, мы выполняем следующие шаги высокого уровня:
- Создайте сканер AWS Glue для извлечения метаданных XML и создания таблицы в каталоге данных AWS Glue.
- Обрабатывайте и преобразуйте XML-данные в формат (например, Parquet), подходящий для Athena, с помощью задания извлечения, преобразования и загрузки (ETL) AWS Glue.
- Настройте и запустите задание AWS Glue через консоль AWS Glue или Интерфейс командной строки AWS (Интерфейс командной строки AWS).
- Используйте обработанные данные (в формате Parquet) с таблицами Athena, включая запросы SQL.
- Используйте удобный интерфейс Athena для анализа данных XML с помощью SQL-запросов к вашим данным, хранящимся в Amazon S3.
Эта архитектура представляет собой масштабируемое и экономичное решение для анализа XML-данных в Amazon S3 с использованием AWS Glue и Athena. Вы можете анализировать большие наборы данных без сложного управления инфраструктурой.
Мы используем сканер AWS Glue для извлечения метаданных XML-файла. Вы можете выбрать классификатор AWS Glue по умолчанию для классификации XML общего назначения. Он автоматически определяет структуру и схему данных XML, что полезно для распространенных форматов.
В этом решении мы также используем собственный классификатор XML. Он разработан для конкретных схем или форматов XML и позволяет точно извлекать метаданные. Это идеально подходит для нестандартных форматов XML или когда вам нужен детальный контроль над классификацией. Пользовательский классификатор обеспечивает извлечение только необходимых метаданных, упрощая задачи последующей обработки и анализа. Этот подход оптимизирует использование XML-файлов.
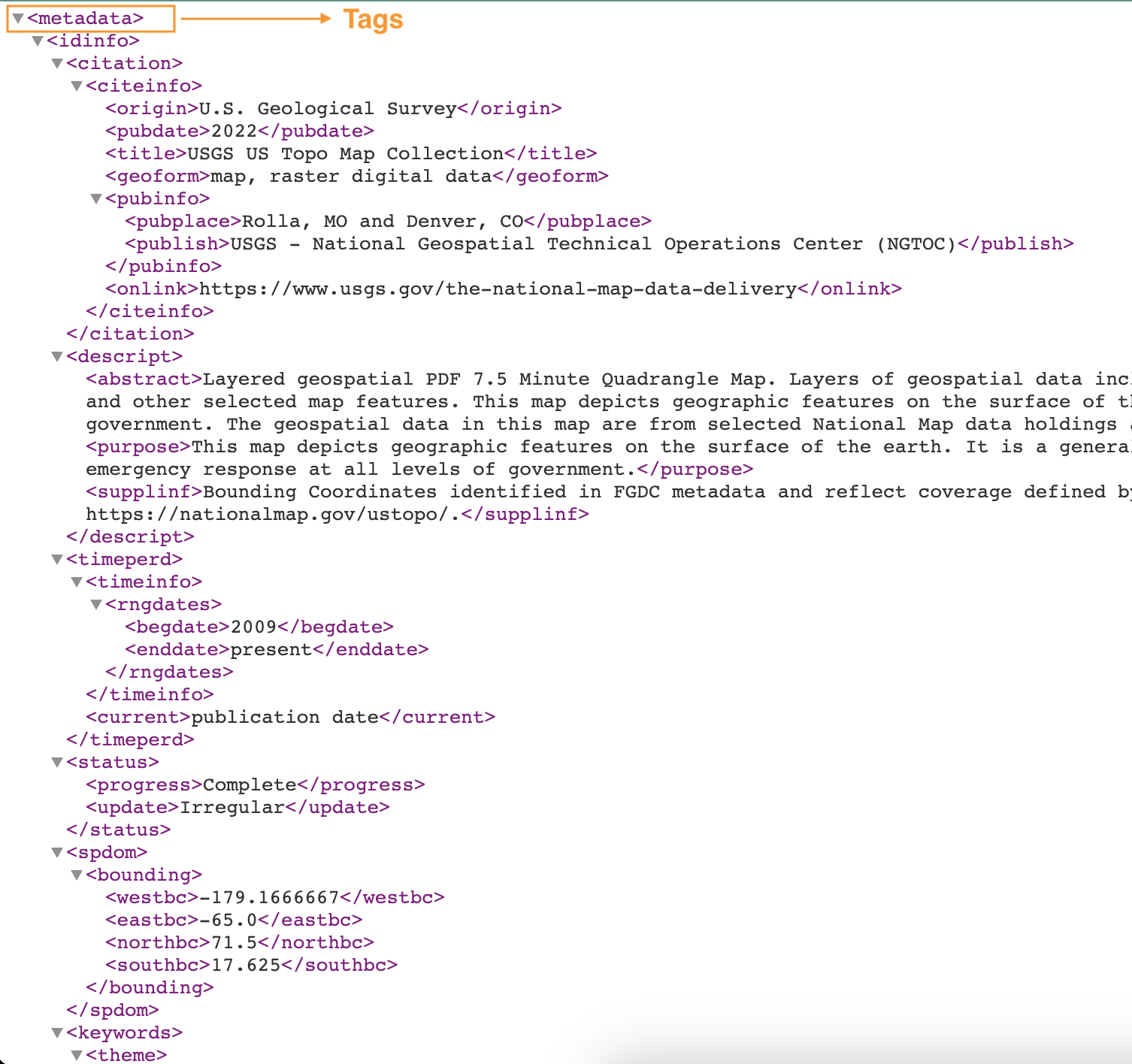
На следующем снимке экрана показан пример XML-файла с тегами.
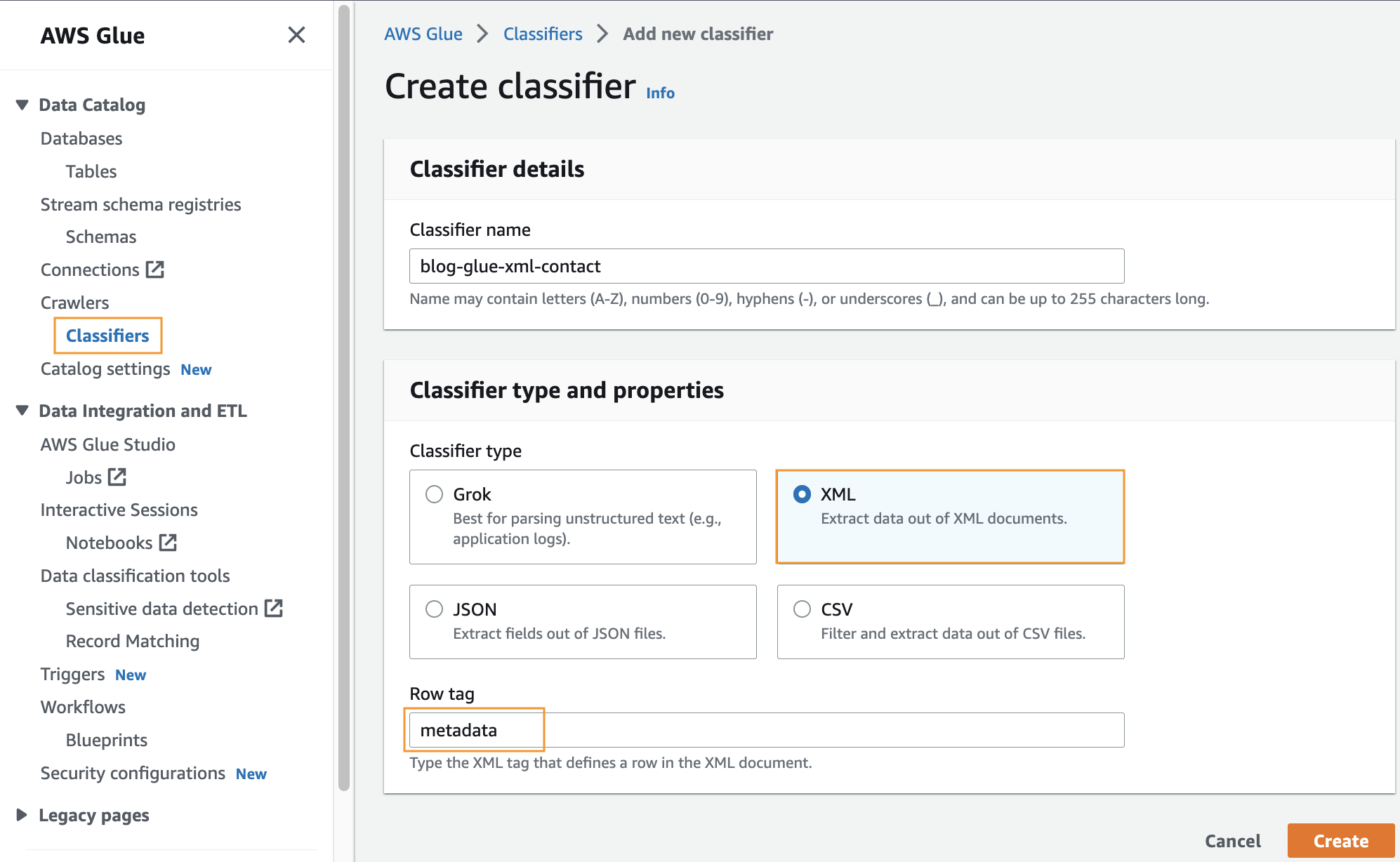
Создать пользовательский классификатор
На этом этапе вы создаете собственный классификатор AWS Glue для извлечения метаданных из XML-файла. Выполните следующие шаги:
- На консоли AWS Glue, под ползунки на панели навигации выберите Классификаторы.
- Выберите Добавить классификатор.
- Выберите XML как тип классификатора.
- Введите имя классификатора, например
blog-glue-xml-contact. - Что касается Тег строкивведите имя корневого тега, содержащего метаданные (например,
metadata). - Выберите Создавай.
Создайте сканер AWS Glue для сканирования XML-файла.
В этом разделе мы создаем Glue Crawler для извлечения метаданных из XML-файла с использованием классификатора клиентов, созданного на предыдущем шаге.
Создать базу данных
- Перейдите в Консоль AWS Glue, выберите Databases в навигационной панели.
- Нажмите на Добавить базу данных.
- Укажите имя, например
blog_glue_xml - Выберите Создавай База данных
Создать краулер
Выполните следующие шаги, чтобы создать свой первый сканер:
- На консоли AWS Glue выберите ползунки в навигационной панели.
- Выберите Создать сканер.
- На Установить свойства сканера странице укажите имя нового сканера (например,
blog-glue-parquet), тогда выбирай Следующая. - На Выбирайте источники данных и классификаторы страницы, выберите Еще нет под Конфигурация источника данных.
- Выберите Добавить хранилище данных.
- Что касается путь S3, перейдите к
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Убедитесь, что вы выбрали папку XML, а не файл внутри папки.
- Остальные параметры оставьте по умолчанию и выберите Добавьте источник данных S3.
- Расширьте Пользовательские классификаторы – опционально, выберите blog-glue-xml-contact, затем выберите Следующая и оставьте остальные параметры по умолчанию.
- Выберите свою роль IAM или выберите Создать новую роль IAM, добавьте суффикс
glue-xml-contact(например,AWSGlueServiceNotebookRoleBlog), и выберите Следующая. - На Установить выход и расписание страница, под Конфигурация выхода, выберите
blog_glue_xmlдля Целевая база данных. - Enter
console_в качестве префикса, добавляемого к таблицам (необязательно) и под Расписание краулера, оставьте частоту установленной на По требованию. - Выберите Следующая.
- Просмотрите все параметры и выберите Создать сканер.
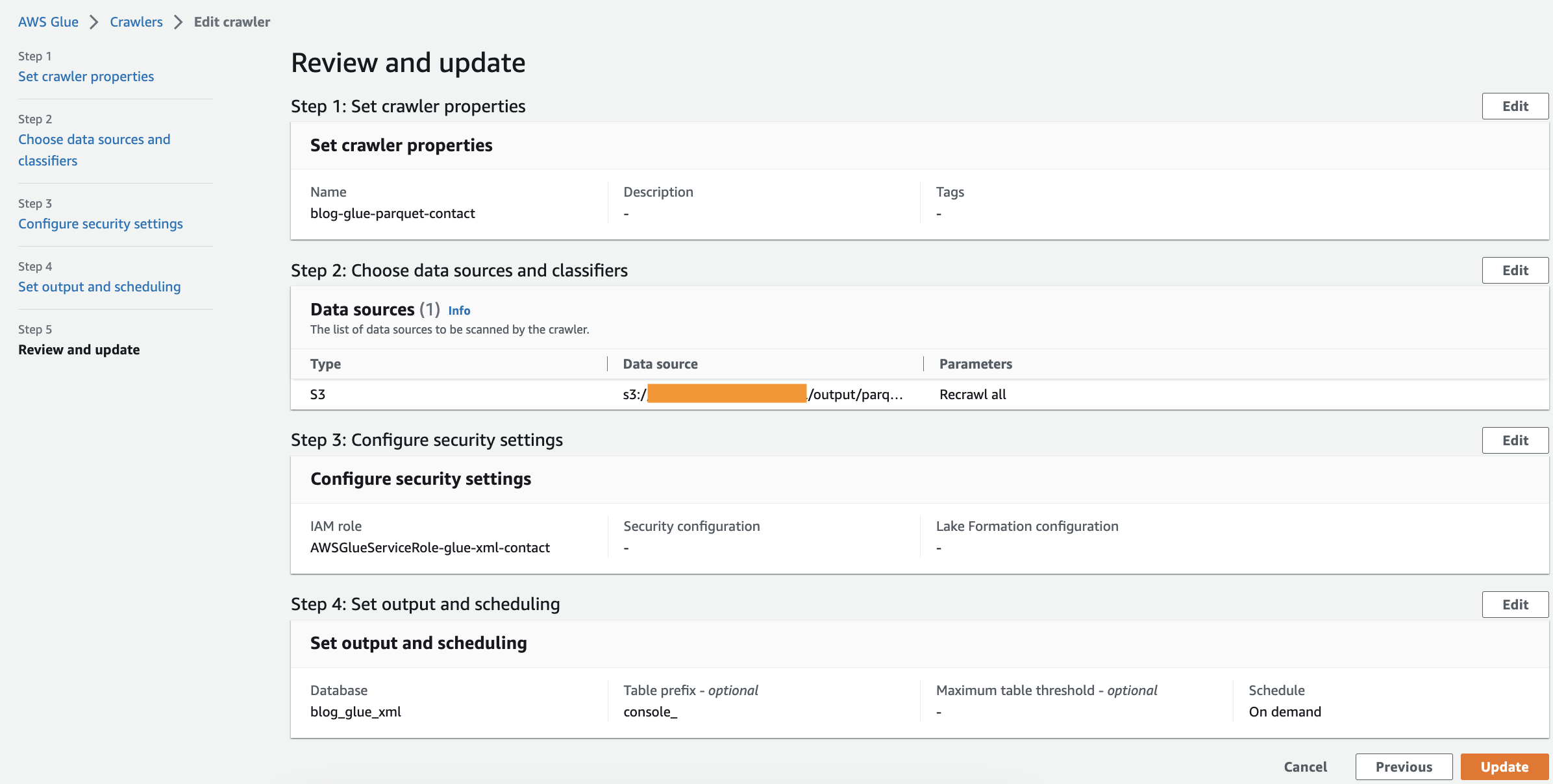
Запустить краулер
После создания искателя выполните следующие шаги для его запуска:
- На консоли AWS Glue выберите ползунки в навигационной панели.
- Откройте созданный вами сканер и выберите Run.
Поисковому роботу потребуется 1–2 минуты.
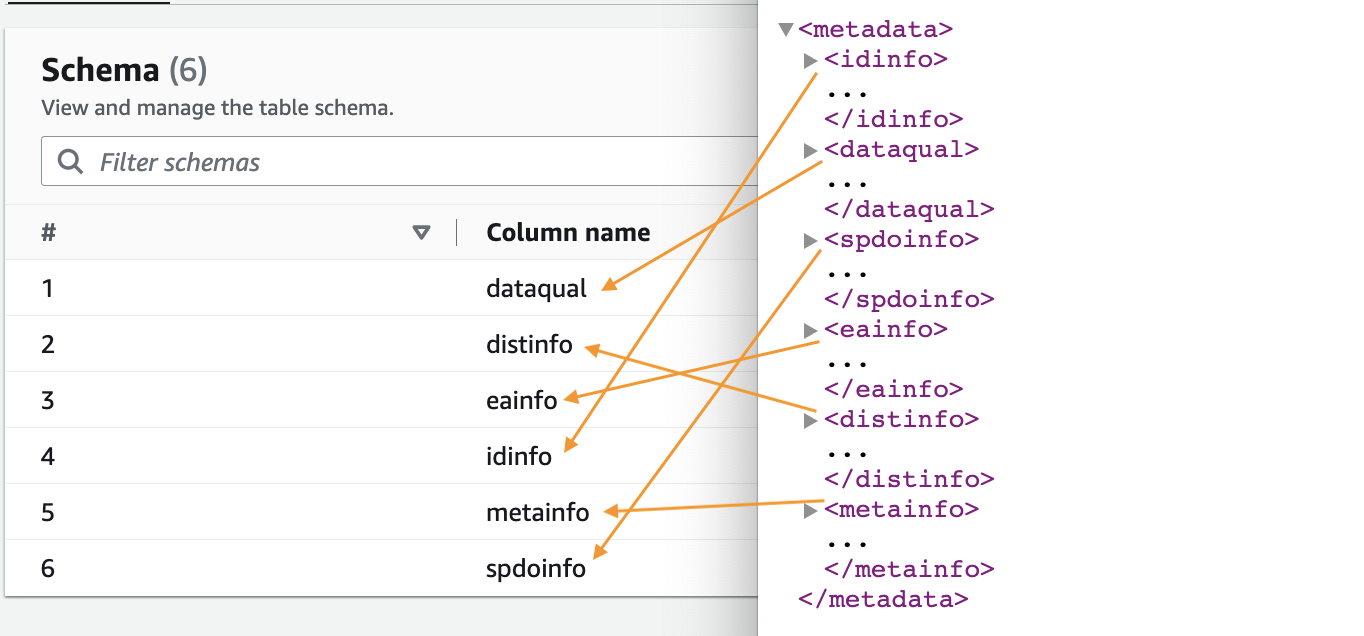
- Когда поисковый робот завершит работу, выберите Databases в навигационной панели.
- Выберите базу данных, которую вы создали, и выберите имя таблицы, чтобы просмотреть схему, извлеченную сканером.
Создайте задание AWS Glue для преобразования XML в формат Parquet.
На этом этапе вы создаете задание AWS Glue Studio для преобразования XML-файла в файл Parquet. Выполните следующие шаги:
- На консоли AWS Glue выберите Джобс в навигационной панели.
- Под Создать работу, наведите на Визуальный с пустым холстом.
- Выберите Создавай.
- Переименуйте задание в
blog_glue_xml_job.
Теперь у вас есть пустой визуальный редактор заданий AWS Glue Studio. В верхней части редактора расположены вкладки для различных представлений.
- Выберите Сценарий Tab, чтобы увидеть пустую оболочку ETL-скрипта AWS Glue.
По мере добавления новых шагов в визуальном редакторе скрипт будет обновляться автоматически.
- Выберите Детали работы вкладка, чтобы просмотреть все конфигурации заданий.
- Что касается Роль IAM, выберите
AWSGlueServiceNotebookRoleBlog. - Что касается Версия клея, выберите Glue 4.0 — поддержка Spark 3.3, Scala 2, Python 3..
- Поставьте Запрашиваемое количество рабочих в 2.
- Поставьте Количество попыток в 0.
- Выберите визуальный Tab, чтобы вернуться в визуальный редактор.
- На Источник выпадающее меню, выберите Каталог данных AWS Glue.
- На Свойства источника данных — Каталог данных на вкладке укажите следующую информацию:
- Что касается База данных, выберите
blog_glue_xml. - Что касается Настольные, выберите таблицу, которая начинается с имени console_, созданного искателем (например,
console_geologicalsurvey).
- Что касается База данных, выберите
- На Свойства узла на вкладке укажите следующую информацию:
- Изменить Имя в
geologicalsurveyнабор данных. - Выберите Действие и преобразование Изменить схему (применить сопоставление).
- Выберите Свойства узла и измените имя преобразования с «Изменить схему (применить сопоставление)» на
ApplyMapping. - На цель Меню, выберите S3.
- Изменить Имя в
- На Свойства источника данных - S3 на вкладке укажите следующую информацию:
- Что касается Формат, наведите на паркет.
- Что касается Тип сжатия, наведите на несжатого.
- Что касается Тип источника S3, наведите на S3 местоположение.
- Что касается URL-адрес S3, войти
s3://${BUCKET_NAME}/output/parquet/. - Выберите Свойства узла и измените имя на
Output.
- Выберите Сохранить чтобы сохранить работу.
- Выберите Run для запуска работы.
На следующем снимке экрана показано задание в визуальном редакторе.
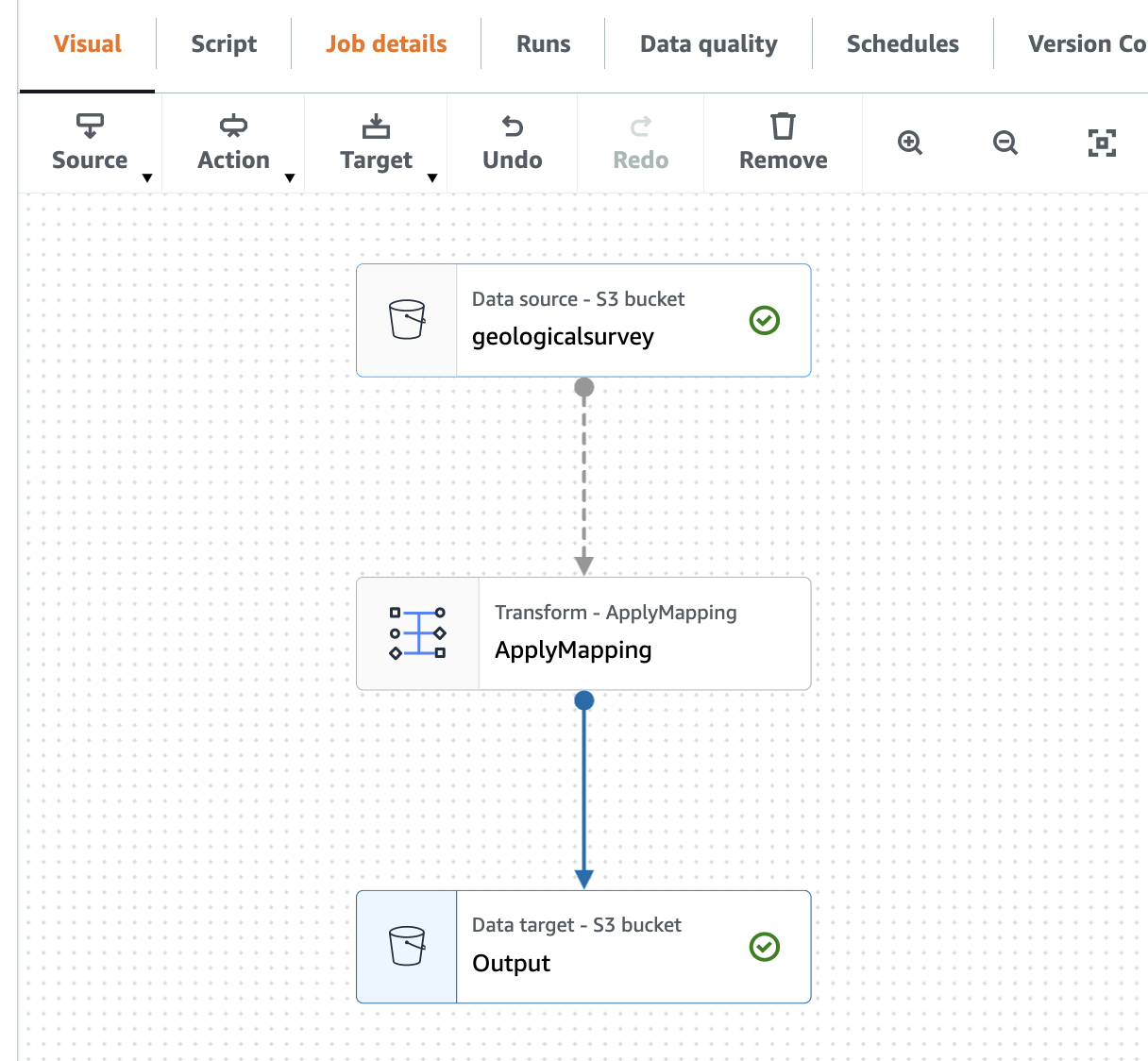
Создайте сканер AWS Gue для сканирования файла Parquet.
На этом этапе вы создаете сканер AWS Glue для извлечения метаданных из файла Parquet, созданного с помощью задания AWS Glue Studio. На этот раз вы используете классификатор по умолчанию. Выполните следующие шаги:
- На консоли AWS Glue выберите ползунки в навигационной панели.
- Выберите Создать сканер.
- На Установить свойства сканера странице, укажите имя нового сканера, например blog-glue-parquet-contact, затем выберите Следующая.
- На Выбирайте источники данных и классификаторы страницы, выберите Еще нет для Конфигурация источника данных.
- Выберите Добавить хранилище данных.
- Что касается путь S3, перейдите к
s3://${BUCKET_NAME}/output/parquet/.
Убедитесь, что вы выбрали parquet папку, а не файл внутри папки.
- Выберите роль IAM, созданную в разделе обязательных требований, или выберите Создать новую роль IAM (например,
AWSGlueServiceNotebookRoleBlog), и выберите Следующая. - На Установить выход и расписание страница, под Конфигурация выхода, выберите
blog_glue_xmlдля База данных. - Enter
parquet_в качестве префикса, добавляемого к таблицам (необязательно) и под Расписание краулера, оставьте частоту установленной на По требованию. - Выберите Следующая.
- Просмотрите все параметры и выберите Создать сканер.
Теперь вы можете запустить сканер, работа которого займет 1–2 минуты.

Вы можете просмотреть вновь созданную схему для файла Parquet в каталоге данных AWS Glue, которая аналогична схеме XML-файла.
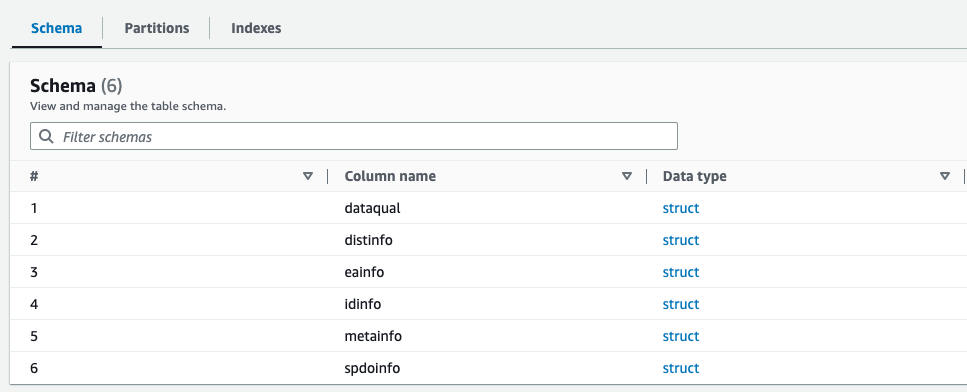
Теперь у нас есть данные, которые можно использовать с Афиной. В следующем разделе мы выполняем запросы данных с помощью Athena.
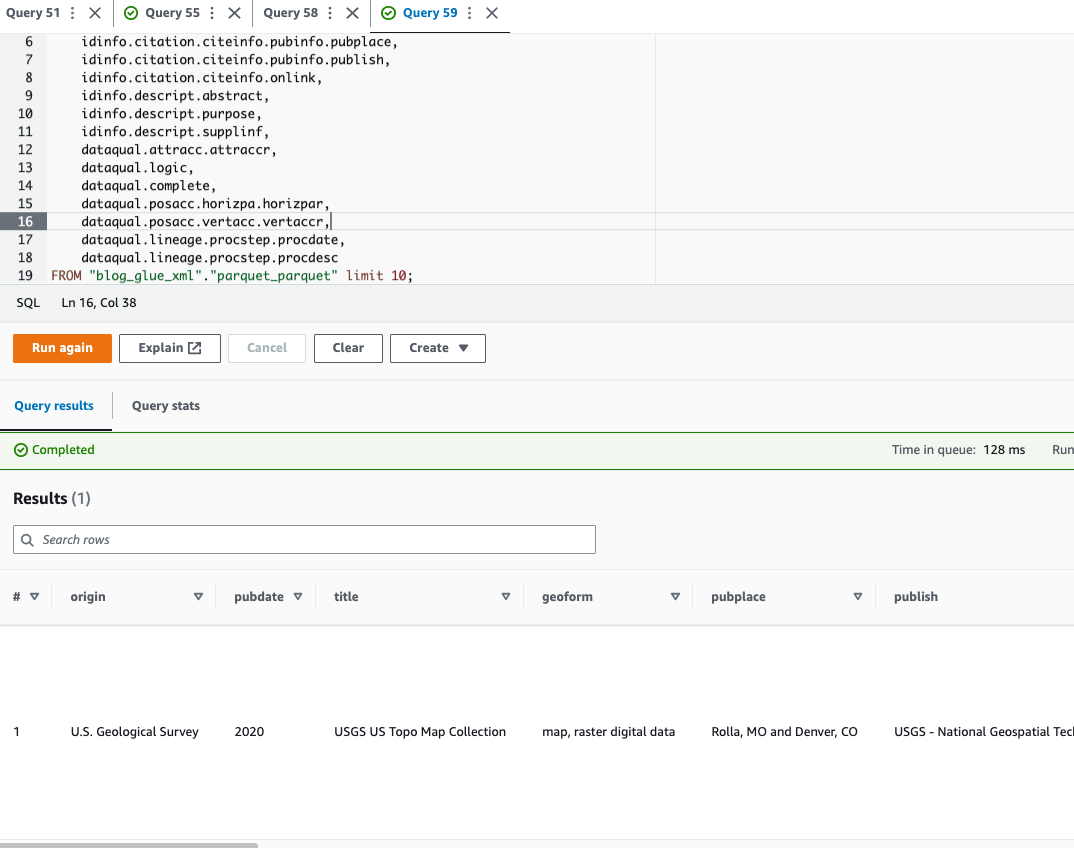
Запросить файл Parquet с помощью Athena
Athena не поддерживает запросы к Формат XML-файла, поэтому вы преобразовали XML-файл в Parquet для более эффективного запроса и использования данных. точечная запись для запроса сложных типов и вложенных структур.
В следующем примере кода для запроса вложенных данных используется запись через точку:
Теперь, когда мы завершили технику 1, давайте перейдем к изучению техники 2.
Метод 2. Использование AWS Glue DynamicFrames с выведенными и фиксированными схемами
В предыдущем разделе мы рассмотрели процесс обработки небольшого XML-файла с использованием сканера AWS Glue для создания таблицы, задания AWS Glue для преобразования файла в формат Parquet и Athena для доступа к данным Parquet. Однако сканер сталкивается с ограничениями при обработке XML-файлов, размер которых превышает 1 МБ. В этом разделе мы углубляемся в тему пакетной обработки больших XML-файлов, требующую дополнительного анализа для извлечения отдельных событий и проведения анализа с помощью Athena.
Наш подход предполагает чтение XML-файлов с помощью AWS Glue. Динамические фреймы, используя как выведенные, так и фиксированные схемы. Затем мы извлекаем отдельные события в формате Parquet, используя метод отношения преобразование, позволяющее нам легко запрашивать и анализировать их с помощью Athena.
Чтобы реализовать это решение, выполните следующие высокоуровневые шаги:
- Создайте блокнот AWS Glue для чтения и анализа XML-файла.
- Используйте
DynamicFramesInferSchemaдля чтения файла XML. - Используйте функцию реляционализации, чтобы отменить вложение любых массивов.
- Преобразуйте данные в формат Parquet.
- Запросите данные Parquet с помощью Athena.
- Повторите предыдущие шаги, но на этот раз передайте схему
DynamicFramesВместо того, чтобы использоватьInferSchema.
XML-файл данных о численности электромобилей имеет response тег на его корневом уровне. Этот тег содержит массив row теги, которые вложены в него. Тег строки — это массив, который содержит набор других тегов строки, которые предоставляют информацию о транспортном средстве, включая его марку, модель и другие соответствующие сведения. На следующем снимке экрана показан пример.

Создайте блокнот AWS Glue
Чтобы создать блокнот AWS Glue, выполните следующие действия:
- Откройте приложение Клей-студия AWS консоль, выберите Джобс в навигационной панели.
- Выберите Jupyter Notebook , а затем выбрать Создавай.
- Введите имя задания AWS Glue, например
blog_glue_xml_job_Jupyter. - Выберите роль, которую вы создали в предварительных условиях (
AWSGlueServiceNotebookRoleBlog).
В блокнот AWS Glue включен уже существующий пример, демонстрирующий, как выполнить запрос к базе данных и записать выходные данные в Amazon S3.
- Настройте время ожидания (в минутах), как показано на следующем снимке экрана, и запустите ячейку, чтобы создать интерактивный сеанс AWS Glue.
Создание базовых переменных
После создания интерактивного сеанса в конце записной книжки создайте новую ячейку со следующими переменными (укажите собственное имя сегмента):
Прочтите XML-файл, содержащий схему.
Если вы не передадите схему в DynamicFrame, он выведет схему файлов. Чтобы прочитать данные с использованием динамического фрейма, вы можете использовать следующую команду:
Распечатайте схему DynamicFrame
Распечатайте схему со следующим кодом:
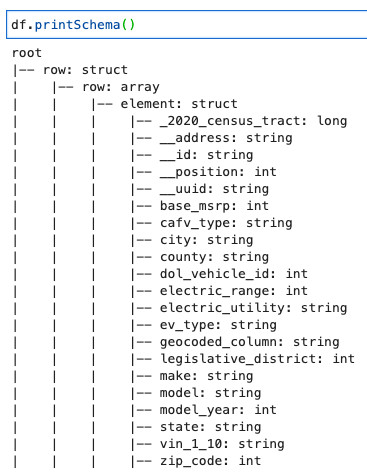
На схеме показана вложенная структура с row массив, содержащий несколько элементов. Чтобы разложить эту структуру на линии, вы можете использовать AWS Glue. отношения трансформация:
Нас интересует только информация, содержащаяся в массиве строк, и мы можем просмотреть схему с помощью следующей команды:
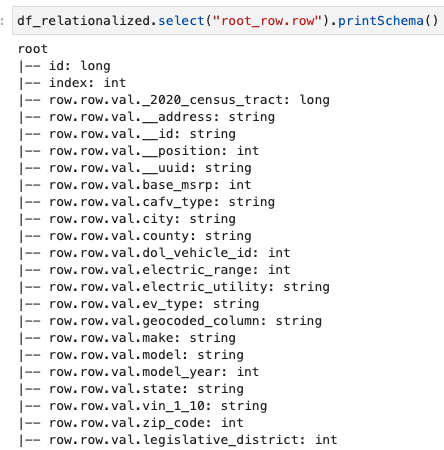
Имена столбцов содержат row.row, которые соответствуют структуре массива и столбцу массива в наборе данных. Мы не переименовываем столбцы в этом посте; инструкции по этому поводу см. Автоматизируйте динамическое сопоставление и переименование имен столбцов в файлах данных с помощью AWS Glue: часть 1. Затем вы можете преобразовать данные в формат Parquet и создать таблицу AWS Glue с помощью следующей команды:
Клей AWS DynamicFrame предоставляет функции, которые вы можете использовать в своем сценарии ETL для создания и обновления схемы в каталоге данных. Мы используем updateBehavior параметр для создания таблицы непосредственно в каталоге данных. При таком подходе нам не нужно запускать сканер AWS Glue после завершения задания AWS Glue.

Прочитайте XML-файл, установив схему
Альтернативный способ чтения файла — предварительное определение схемы. Для этого выполните следующие шаги:
- Импортируйте типы данных AWS Glue:
- Создайте схему для XML-файла:
- Передайте схему при чтении XML-файла:
- Отмените вложение набора данных, как раньше:
- Преобразуйте набор данных в Parquet и создайте таблицу AWS Glue:
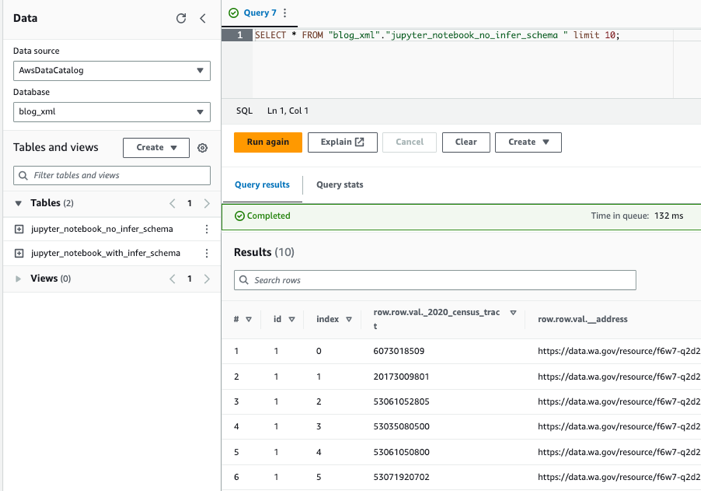
Запрос к таблицам с помощью Athena
Теперь, когда мы создали обе таблицы, мы можем запросить их с помощью Athena. Например, мы можем использовать следующий запрос:
Убирать
В этом посте мы создали роль IAM, блокнот AWS Glue Jupyter и две таблицы в каталоге данных AWS Glue. Мы также загрузили несколько файлов в корзину S3. Чтобы очистить эти объекты, выполните следующие действия:
- В консоли IAM удалите созданную роль.
- В консоли AWS Glue Studio удалите пользовательский классификатор, искатель, задания ETL и блокнот Jupyter.
- Перейдите в каталог данных AWS Glue и удалите созданные вами таблицы.
- На консоли Amazon S3 перейдите к созданному вами сегменту и удалите папки с именем
temp,infer_schemaиno_infer_schema.
Основные выводы
В AWS Glue есть функция под названием InferSchema в AWS-клее DynamicFrames. Он автоматически определяет структуру фрейма данных на основе содержащихся в нем данных. Напротив, определение схемы означает явное указание того, какой должна быть структура фрейма данных, перед загрузкой данных.
XML, будучи текстовым форматом, не ограничивает типы данных своих столбцов. Это может вызвать проблемы с функцией InferSchema. Например, при первом запуске файл со столбцом A, имеющим значение 2, приводит к созданию файла Parquet со столбцом A как целое число. При втором запуске новый файл имеет столбец A со значением C, что приводит к созданию файла Parquet со столбцом A в виде строки. Теперь на S3 есть два файла, каждый со столбцом A разных типов данных, что может создать проблемы в дальнейшем.
То же самое происходит со сложными типами данных, такими как вложенные структуры или массивы. Например, если файл имеет одну запись тега, называемую transaction, это подразумевается как структура. Но если другой файл имеет тот же тег, он рассматривается как массив.
Несмотря на эти проблемы с типами данных, InferSchema полезно, когда вы не знаете схему или определить ее вручную непрактично. Однако он не идеален для больших или постоянно меняющихся наборов данных. Определение схемы является более точным, особенно для сложных типов данных, но имеет свои проблемы, такие как необходимость ручного труда и негибкость к изменениям данных.
InferSchema имеет ограничения, такие как неправильный вывод типа данных и проблемы с обработкой нулевых значений. Определение схемы также имеет ограничения, такие как ручная работа и потенциальные ошибки.
Выбор между выводом и определением схемы зависит от потребностей проекта. InferSchema отлично подходит для быстрого исследования небольших наборов данных, тогда как определение схемы лучше подходит для больших и сложных наборов данных, требующих точности и согласованности. Рассмотрите компромиссы и ограничения каждого метода, чтобы выбрать тот, который лучше всего подходит для вашего проекта.
Заключение
В этом посте мы рассмотрели два метода управления XML-данными с помощью AWS Glue, каждый из которых предназначен для решения конкретных потребностей и задач, с которыми вы можете столкнуться.
Метод 1 предлагает удобный путь для тех, кто предпочитает графический интерфейс. Вы можете использовать сканер AWS Glue и визуальный редактор, чтобы легко определить структуру таблицы для ваших XML-файлов. Этот подход упрощает процесс управления данными и особенно привлекателен для тех, кто ищет простой способ обработки своих данных.
Однако мы понимаем, что у сканера есть свои ограничения, особенно при работе с XML-файлами, имеющими строки размером более 1 МБ. Здесь на помощь приходит техника 2. Используя AWS Glue DynamicFrames как с выведенными, так и с фиксированными схемами, а также с помощью блокнота AWS Glue вы можете эффективно обрабатывать XML-файлы любого размера. Этот метод обеспечивает надежное решение, обеспечивающее бесперебойную обработку даже файлов XML, размер строк которых превышает ограничение в 1 МБ.
Когда вы ориентируетесь в мире управления данными, наличие этих методов в вашем наборе инструментов позволит вам принимать обоснованные решения, основанные на конкретных требованиях вашего проекта. Независимо от того, предпочитаете ли вы простоту метода 1 или масштабируемость метода 2, AWS Glue обеспечивает гибкость, необходимую для эффективной обработки XML-данных.
Об авторах
 Навнит Шуклаработает специалистом по архитектуре решений AWS, специализирующимся на аналитике. Он с большим энтузиазмом помогает клиентам находить ценную информацию из их данных. Благодаря своему опыту он создает инновационные решения, которые позволяют предприятиям принимать обоснованные решения на основе данных. Примечательно, что Навнит Шукла является опытным автором книги «Обработка данных на AWS».
Навнит Шуклаработает специалистом по архитектуре решений AWS, специализирующимся на аналитике. Он с большим энтузиазмом помогает клиентам находить ценную информацию из их данных. Благодаря своему опыту он создает инновационные решения, которые позволяют предприятиям принимать обоснованные решения на основе данных. Примечательно, что Навнит Шукла является опытным автором книги «Обработка данных на AWS».
 Патрик Мюллер работает старшим архитектором лаборатории данных в AWS. Его основная обязанность — помогать клиентам превращать их идеи в готовый к производству информационный продукт. В свободное время Патрик любит играть в футбол, смотреть фильмы и путешествовать.
Патрик Мюллер работает старшим архитектором лаборатории данных в AWS. Его основная обязанность — помогать клиентам превращать их идеи в готовый к производству информационный продукт. В свободное время Патрик любит играть в футбол, смотреть фильмы и путешествовать.
 Амог Гайквад — старший разработчик решений в Amazon Web Services. Он помогает клиентам со всего мира создавать и развертывать решения AI/ML на AWS. Его работа в основном сосредоточена на компьютерном зрении и обработке естественного языка, а также на оказании помощи клиентам в оптимизации рабочих нагрузок искусственного интеллекта и машинного обучения для обеспечения устойчивости. Амог получил степень магистра компьютерных наук по специальности «Машинное обучение».
Амог Гайквад — старший разработчик решений в Amazon Web Services. Он помогает клиентам со всего мира создавать и развертывать решения AI/ML на AWS. Его работа в основном сосредоточена на компьютерном зрении и обработке естественного языка, а также на оказании помощи клиентам в оптимизации рабочих нагрузок искусственного интеллекта и машинного обучения для обеспечения устойчивости. Амог получил степень магистра компьютерных наук по специальности «Машинное обучение».
 Шила Сононе — старший архитектор-резидент в AWS. Она помогает клиентам AWS сделать осознанный выбор и найти компромиссные решения в отношении ускорения работы с данными, аналитикой, а также рабочих нагрузок и внедрения искусственного интеллекта и машинного обучения. В свободное время она любит проводить время со своей семьей – обычно на теннисных кортах.
Шила Сононе — старший архитектор-резидент в AWS. Она помогает клиентам AWS сделать осознанный выбор и найти компромиссные решения в отношении ускорения работы с данными, аналитикой, а также рабочих нагрузок и внедрения искусственного интеллекта и машинного обучения. В свободное время она любит проводить время со своей семьей – обычно на теннисных кортах.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- О нас
- АБСТРАКТ НАЯ
- ускоряющий
- доступ
- доступность
- выполнено
- точность
- через
- Действие
- Добавить
- добавленный
- дополнительный
- адрес
- После
- возраст
- AI / ML
- Все
- позволять
- Позволяющий
- позволяет
- причислены
- альтернатива
- Amazon
- Амазонка Афина
- Amazon Web Services
- an
- анализ
- аналитика
- анализировать
- анализ
- и
- Другой
- любой
- апаш
- привлекательный
- Приложения
- Применить
- подхода
- подходы
- архитектура
- МЫ
- массив
- AS
- помощь
- содействие
- At
- автор
- автоматически
- доступен
- AWS
- Клей AWS
- назад
- основанный
- основной
- BE
- , так как:
- до
- начинать
- не являетесь
- ЛУЧШЕЕ
- Лучшая
- между
- пустой
- книга
- изоферменты печени
- строить
- бизнес
- но
- by
- под названием
- CAN
- каталог
- Вызывать
- ячейка
- проблемы
- изменение
- изменения
- изменения
- выбор
- Выберите
- Город
- классификация
- клиентов
- код
- Column
- Колонки
- COM
- выходит
- Общий
- обычно
- полный
- Заполненная
- комплекс
- компьютер
- Информатика
- Компьютерное зрение
- состояние
- Проводить
- связь
- Рассматривать
- Консоли
- постоянно
- ограничения
- строить
- содержать
- содержащегося
- содержит
- контраст
- контроль
- конвертировать
- переделанный
- рентабельным
- экономичное решение
- округ
- Суды
- покрытый
- гусеничный
- Создайте
- создали
- Создающий
- решающее значение
- изготовленный на заказ
- клиент
- Клиенты
- данным
- Интеграция данных
- управление данными
- управляемых данными
- База данных
- Наборы данных
- занимавшийся
- решения
- По умолчанию
- определять
- определяющий
- копаться
- демонстрирует
- зависит
- развертывание
- предназначенный
- подробный
- подробнее
- Застройщик
- различный
- трудный
- Интернет
- Цифровой век
- непосредственно
- обнаружение
- отчетливый
- do
- не
- сделанный
- Dont
- DOT
- в течение
- динамический
- каждый
- простота
- легко
- легко
- редактор
- эффект
- фактически
- затрат
- эффективный
- эффективно
- усилие
- легко
- Электрический
- электрических транспортных средств
- элементы
- используя
- расширение прав и возможностей
- Наделяет
- пустой
- включить
- позволяет
- столкновение
- конец
- Двигатели
- повышать
- обеспечивать
- обеспечивает
- Enter
- энтузиазм
- запись
- ошибки
- особенно
- Эфир (ETH)
- Даже
- События
- Каждая
- пример
- превышать
- обмена
- опыта
- исследование
- Больше
- Разведанный
- извлечение
- добыча
- семья
- Особенность
- Особенности
- цифры
- Файл
- Файлы
- финансы
- Во-первых,
- фиксированной
- Трансформируемость
- Фокус
- внимание
- после
- Что касается
- формат
- КАДР
- Бесплатно
- частота
- от
- функция
- Gain
- общее назначение
- порождать
- Глобальный
- Go
- цель
- Правительство
- большой
- обрабатывать
- Управляемость
- происходит
- Освоение
- Есть
- имеющий
- he
- здравоохранение
- Сердце
- помощь
- помощь
- помогает
- ее
- на высшем уровне
- очень
- его
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- IAM
- идеальный
- идеи
- Личность
- if
- иллюстрирует
- осуществлять
- реализации
- Осуществляющий
- Импортировать
- улучшать
- улучшенный
- in
- В том числе
- individual
- лиц
- промышленности
- информация
- сообщил
- Инфраструктура
- инновационный
- внутри
- размышления
- вместо
- инструкции
- интегрировать
- интеграции.
- интерактивный
- заинтересованный
- Интерфейс
- в
- включает в себя
- вопросы
- IT
- ЕГО
- работа
- Джобс
- JPG
- JSON
- Jupyter Notebook
- Сохранить
- Знать
- лаборатория
- язык
- большой
- больше
- ведущий
- УЧИТЬСЯ
- изучение
- уровень
- такое как
- ОГРАНИЧЕНИЯ
- ограничение
- недостатки
- линия
- линий
- загрузка
- погрузка
- логика
- искать
- машина
- обучение с помощью машины
- Главная
- в основном
- сделать
- Создание
- управление
- управления
- руководство
- вручную
- многих
- отображение
- магистра
- Май..
- означает
- Меню
- Метаданные
- метод
- минут
- модель
- БОЛЕЕ
- более эффективным
- самых
- двигаться
- Кино
- с разными
- имя
- Названный
- имена
- натуральный
- Естественный язык
- Обработка естественного языка
- Откройте
- Навигация
- необходимо
- Необходимость
- потребности
- Новые
- вновь
- следующий
- особенно
- ноутбук
- сейчас
- номер
- объекты
- of
- Предложения
- on
- ONE
- только
- Операционный отдел
- оптимальный
- Оптимизировать
- оптимизирует
- Опции
- or
- заказ
- организации
- Origin
- Другое
- наши
- внешний
- выходной
- за
- Преодолеть
- собственный
- страница
- хлеб
- параметр
- параметры
- часть
- особенно
- pass
- путь
- Патрик
- выполнять
- производительность
- Разрешения
- выбирать
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- политика
- население
- обладать
- После
- потенциал
- необходимость
- предпочитать
- предпосылки
- предварительный просмотр
- предыдущий
- проблемам
- процесс
- обрабатываемых
- обработка
- Продукт
- Проект
- проектов
- свойства
- обеспечивать
- приводит
- публиковать
- цель
- Питон
- Запросы
- САЙТ
- скорее
- Читать
- легко
- Reading
- причины
- получила
- признавать
- относиться
- соответствующие
- Требования
- спасать
- ресурс
- ответ
- ответственность
- ОТДЫХ
- ограничивать
- ограничение
- Итоги
- надежный
- Роли
- корень
- РЯД
- Run
- то же
- Сохранить
- масштаб
- Масштабируемость
- масштабируемые
- Наука
- скрипт
- бесшовные
- легко
- Во-вторых
- Раздел
- посмотреть
- старший
- Услуги
- Сессия
- набор
- установка
- несколько
- она
- Оболочка
- должен
- показывать
- показанный
- Шоу
- аналогичный
- просто
- простота
- упрощение
- одинарной
- Размер
- небольшой
- So
- Футбольный
- Решение
- Решения
- некоторые
- Источник
- Источники
- Искриться
- специалист
- специализация
- конкретный
- конкретно
- скорость
- Расходы
- SQL
- стандарт
- начинается
- Область
- заявление
- заявив,
- Шаг
- Шаги
- диск
- хранить
- простой
- упорядочить
- строка
- сильный
- Структура
- структур
- студия
- успех
- такие
- подходящее
- поддержка
- Убедитесь
- Стабильность
- системы
- ТАБЛИЦЫ
- TAG
- с учетом
- взять
- принимает
- задачи
- снижения вреда
- теннис
- чем
- который
- Ассоциация
- информация
- мир
- их
- Их
- тогда
- Там.
- Эти
- они
- этой
- те
- Через
- время
- Название
- титулованный
- в
- Сегодняшних
- Инструментарий
- топ
- тема
- Transform
- трансформация
- Путешествие
- Поворот
- учебник
- два
- напишите
- Типы
- окончательный
- под
- Обновление ПО
- обновление
- загружено
- us
- юзабилити
- использование
- используемый
- Информация о пользователе
- Пользовательский интерфейс
- удобно
- использования
- через
- обычно
- Использующий
- ценный
- ценностное
- Наши ценности
- автомобиль
- версия
- с помощью
- Вид
- Просмотры
- видение
- наблюдение
- Путь..
- we
- Web
- веб-сервисы
- Что
- когда
- в то время как
- будь то
- который
- КТО
- зачем
- будете
- в
- без
- Работа
- рабочий
- Рабочие процессы
- работает
- Мир
- записывать
- XML
- являетесь
- ВАШЕ
- зефирнет