За последние несколько лет модели большого языка (LLM) приобрели известность как выдающиеся инструменты, способные понимать, генерировать и манипулировать текстом с беспрецедентным мастерством. Их потенциальные области применения простираются от диалоговых агентов до создания контента и поиска информации, что обещает совершить революцию во всех отраслях. Однако использование этого потенциала при обеспечении ответственного и эффективного использования этих моделей зависит от критического процесса оценки LLM. Оценка — это задача, используемая для измерения качества и ответственности результатов LLM или службы генеративного искусственного интеллекта. Оценка LLM мотивируется не только желанием понять эффективность модели, но и необходимостью внедрения ответственного ИИ, а также необходимостью снизить риск предоставления дезинформации или предвзятого контента, а также свести к минимуму создание вредных, небезопасных, злонамеренных и неэтичных материалов. содержание. Кроме того, оценка LLM также может помочь снизить риски безопасности, особенно в контексте быстрого подделки данных. Для приложений на основе LLM крайне важно выявлять уязвимости и внедрять меры безопасности, защищающие от потенциальных взломов и несанкционированных манипуляций с данными.
Предоставляя необходимые инструменты для оценки LLM с простой настройкой и подходом в один клик, Amazon SageMaker Уточнить Возможности оценки LLM предоставляют клиентам доступ к большинству вышеупомянутых преимуществ. Имея в наличии эти инструменты, следующей задачей будет интеграция оценки LLM в жизненный цикл машинного обучения и эксплуатации (MLOps) для достижения автоматизации и масштабируемости этого процесса. В этом посте мы покажем, как интегрировать оценку LLM Amazon SageMaker Clarify с конвейерами Amazon SageMaker Pipelines, чтобы обеспечить масштабную оценку LLM. Кроме того, мы предоставляем пример кода в этом GitHub репозиторий, позволяющий пользователям проводить параллельную оценку нескольких моделей в любом масштабе, используя такие примеры, как Llama2-7b-f, Falcon-7b и точно настроенные модели Llama2-7b.
Кому необходимо проводить оценку LLM?
Любой, кто обучает, настраивает или просто использует предварительно обученный LLM, должен точно оценить его, чтобы оценить поведение приложения, работающего на основе этого LLM. Основываясь на этом принципе, мы можем разделить пользователей генеративного ИИ, которым необходимы возможности оценки LLM, на 3 группы, как показано на следующем рисунке: поставщики моделей, специалисты по точной настройке и потребители.
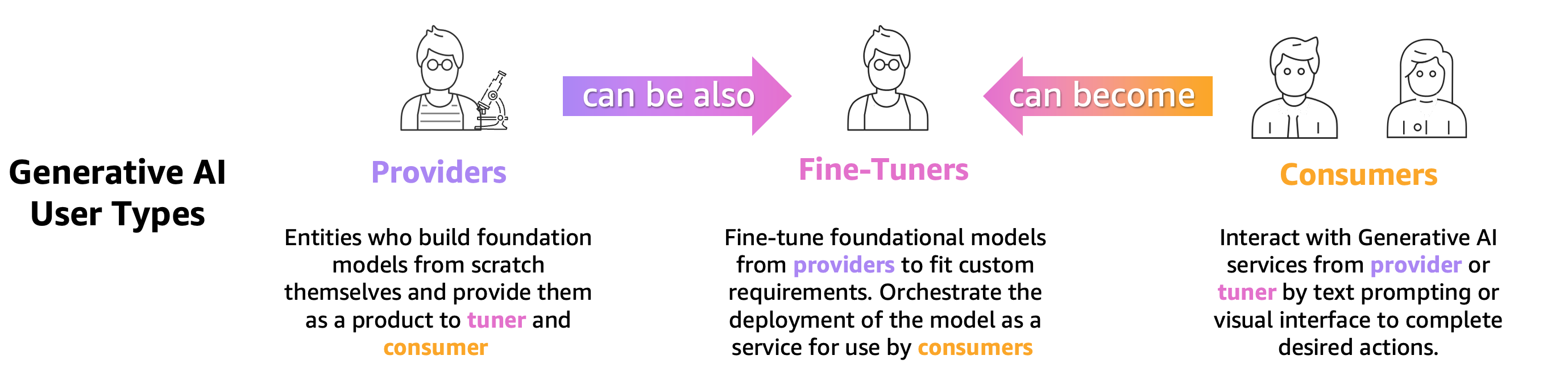
- Поставщики базовой модели (FM) модели поездов общего назначения. Эти модели можно использовать для многих последующих задач, таких как извлечение функций или создание контента. Каждую обученную модель необходимо сравнивать со многими задачами не только для оценки ее эффективности, но и для сравнения ее с другими существующими моделями, для определения областей, требующих улучшений, и, наконец, для отслеживания достижений в этой области. Поставщикам моделей также необходимо проверять наличие каких-либо систематических ошибок, чтобы гарантировать качество исходного набора данных и правильное поведение своей модели. Сбор оценочных данных жизненно важен для поставщиков моделей. Кроме того, эти данные и показатели должны быть собраны в соответствии с будущими правилами. ISO 42001, Распоряжение администрации Байденаи Закон ЕС об искусственном интеллекте разрабатывать стандарты, инструменты и тесты, которые помогут обеспечить безопасность, надежность и надежность систем искусственного интеллекта. Например, Закон ЕС об искусственном интеллекте призван предоставлять информацию о том, какие наборы данных используются для обучения, какая вычислительная мощность требуется для запуска модели, сообщать о результатах модели в соответствии с публичными/отраслевыми стандартами и обмениваться результатами внутреннего и внешнего тестирования.
- Модель точные настройки хотят решать конкретные задачи (например, классификацию настроений, обобщение, ответы на вопросы), а также предварительно обученные модели для решения задач, специфичных для предметной области. Им нужны метрики оценки, генерируемые поставщиками моделей, чтобы выбрать правильную предварительно обученную модель в качестве отправной точки.
Им необходимо оценить свои точно настроенные модели в соответствии с желаемым вариантом использования с наборами данных для конкретных задач или предметной области. Зачастую им приходится курировать и создавать свои частные наборы данных, поскольку общедоступные наборы данных, даже те, которые предназначены для конкретной задачи, могут неадекватно отражать нюансы, необходимые для их конкретного варианта использования.
Точная настройка выполняется быстрее и дешевле, чем полное обучение, и требует более быстрой оперативной итерации для развертывания и тестирования, поскольку обычно создается множество моделей-кандидатов. Оценка этих моделей позволяет постоянно совершенствовать модели, калибровать и отлаживать их. Обратите внимание, что специалисты по точной настройке могут стать потребителями своих собственных моделей при разработке реальных приложений. - Модель потребителей или разработчики моделей обслуживают и контролируют модели общего назначения или точно настроенные модели в производстве, стремясь улучшить свои приложения или услуги за счет внедрения LLM. Первой задачей, с которой они сталкиваются, является обеспечение того, чтобы выбранный LLM соответствовал их конкретным потребностям, затратам и ожиданиям в отношении производительности. Интерпретация и понимание результатов модели является постоянной проблемой, особенно когда речь идет о конфиденциальности и безопасности данных (например, при аудите рисков и соблюдении требований в регулируемых отраслях, таких как финансовый сектор). Непрерывная оценка модели имеет решающее значение для предотвращения распространения предвзятости или вредного контента. Внедряя надежную систему мониторинга и оценки, потребители моделей могут заранее выявлять и устранять регрессию в LLM, гарантируя, что эти модели сохранят свою эффективность и надежность с течением времени.
Как провести оценку LLM
Эффективная оценка модели включает в себя три фундаментальных компонента: одну или несколько FM или точно настроенных моделей для оценки входных наборов данных (подсказки, диалоги или регулярные входные данные) и логику оценки.
Чтобы выбрать модели для оценки, необходимо учитывать различные факторы, включая характеристики данных, сложность проблемы, доступные вычислительные ресурсы и желаемый результат. Хранилище входных данных предоставляет данные, необходимые для обучения, точной настройки и тестирования выбранной модели. Очень важно, чтобы это хранилище данных было хорошо структурированным, репрезентативным и высокого качества, поскольку производительность модели во многом зависит от данных, на которых она обучается. Наконец, логика оценки определяет критерии и показатели, используемые для оценки эффективности модели.
Вместе эти три компонента образуют целостную структуру, которая обеспечивает строгую и систематическую оценку моделей машинного обучения, что в конечном итоге приводит к принятию обоснованных решений и повышению эффективности моделей.
Методы оценки моделей по-прежнему являются активной областью исследований. За последние несколько лет сообществом исследователей было создано множество общедоступных тестов и фреймворков для охвата широкого спектра задач и сценариев, таких как КЛЕЙ, Супер клей, ШЛЕМ, ММЛУ и БОЛЬШАЯ скамья. Эти тесты имеют таблицы лидеров, которые можно использовать для сравнения и сопоставления оцененных моделей. Бенчмарки, такие как HELM, также направлены на оценку показателей, выходящих за рамки показателей точности, таких как точность или показатель F1. Тест HELM включает показатели справедливости, предвзятости и токсичности, которые имеют одинаково важное значение для общей оценки модели.
Все эти тесты включают набор показателей, которые измеряют эффективность модели при выполнении определенной задачи. Самыми известными и наиболее распространенными показателями являются RED (Дублер, ориентированный на отзыв, для гистологической оценки), СИНИЙ (дублёр двуязычной оценки), или METEOR (Метрика для оценки перевода с явным упорядочением). Эти метрики служат полезным инструментом для автоматизированной оценки, обеспечивая количественные измерения лексического сходства между сгенерированным и ссылочным текстом. Однако они не охватывают всю широту формирования человеческого языка, включая семантическое понимание, контекст или стилистические нюансы. Например, HELM не предоставляет подробные сведения об оценке, относящиеся к конкретным вариантам использования, решения для тестирования пользовательских подсказок и легко интерпретируемые результаты, используемые неспециалистами, поскольку этот процесс может быть дорогостоящим, его нелегко масштабировать и использовать только для конкретных задач.
Более того, достижение генерации языка, подобного человеческому, часто требует включения человеческого фактора в цикл для проведения качественных оценок и человеческого суждения в дополнение к автоматизированным показателям точности. Человеческая оценка является ценным методом оценки результатов LLM, но она также может быть субъективной и склонной к предвзятости, поскольку разные оценщики могут иметь разные мнения и интерпретации качества текста. Более того, человеческая оценка может быть ресурсоемкой и дорогостоящей, а также требовать значительного времени и усилий.
Давайте углубимся в то, как Amazon SageMaker Clarify легко соединяет точки, помогая клиентам проводить тщательную оценку и выбор модели.
Оценка LLM с помощью Amazon SageMaker Clarify
Amazon SageMaker Clarify помогает клиентам автоматизировать показатели, включая, помимо прочего, точность, надежность, токсичность, стереотипы и фактические знания для автоматизированной оценки, а также стиль, согласованность, релевантность для человеческой оценки и методы оценки, предоставляя основу для оценки LLM. и сервисы на основе LLM, такие как Amazon Bedrock. Являясь полностью управляемым сервисом, SageMaker Clarify упрощает использование платформ оценки с открытым исходным кодом в Amazon SageMaker. Клиенты могут выбирать соответствующие наборы данных и показатели оценки для своих сценариев и дополнять их собственными наборами оперативных данных и алгоритмами оценки. SageMaker Clarify предоставляет результаты оценки в нескольких форматах для поддержки различных ролей в рабочем процессе LLM. Ученые, работающие с данными, могут анализировать подробные результаты с помощью визуализаций SageMaker Clarify в блокнотах, карточках моделей SageMaker и отчетах в формате PDF. Тем временем операционные группы могут использовать Amazon SageMaker GroundTruth для проверки и аннотирования элементов высокого риска, которые выявляет SageMaker Clarify. Например, из-за стереотипов, токсичности, ускользания личной информации или низкой точности.
Впоследствии для снижения потенциальных рисков используются аннотации и обучение с подкреплением. Доступные для человека объяснения выявленных рисков ускоряют процесс ручной проверки, тем самым снижая затраты. Сводные отчеты предлагают заинтересованным сторонам бизнеса сравнительные ориентиры между различными моделями и версиями, способствуя принятию обоснованных решений.
На следующем рисунке показана структура оценки LLM и услуг на его основе:

Amazon SageMaker Clarify LLM Assessment — это библиотека Foundation Model Evaluation (FMEval) с открытым исходным кодом, разработанная AWS, чтобы помочь клиентам легко оценивать LLM. Все функции также были включены в Amazon SageMaker Studio, чтобы пользователи могли оценить LLM. В следующих разделах мы представим интеграцию возможностей оценки LLM Amazon SageMaker Clarify с SageMaker Pipelines, чтобы обеспечить масштабную оценку LLM с использованием принципов MLOps.
Жизненный цикл Amazon SageMaker MLOps
Как пост «Дорожная карта основания MLOps для предприятий с Amazon SageMaker», описывает MLOps — это сочетание процессов, людей и технологий для эффективного создания сценариев использования ML.
На следующем рисунке показан сквозной жизненный цикл MLOps:

Типичное путешествие начинается с того, что специалист по данным создает блокнот для проверки концепции (PoC), чтобы доказать, что ML может решить бизнес-задачу. На протяжении всего процесса разработки Proof of Concept (PoC) специалист по данным должен преобразовать ключевые показатели эффективности (KPI) бизнеса в метрики модели машинного обучения, такие как точность или уровень ложноположительных результатов, и использовать ограниченный набор тестовых данных для оценки этих показателей. метрики. Ученые, работающие с данными, сотрудничают с инженерами ML для переноса кода из блокнотов в репозитории, создавая конвейеры ML с помощью Amazon SageMaker Pipelines, которые соединяют различные этапы и задачи обработки, включая предварительную обработку, обучение, оценку и постобработку, при этом постоянно внедряя новые продукты. данные. Развертывание конвейеров Amazon SageMaker зависит от взаимодействия с репозиторием и активации конвейера CI/CD. Конвейер ML сохраняет наиболее эффективные модели, образы контейнеров, результаты оценки и информацию о состоянии в реестре моделей, где участники модели оценивают производительность и принимают решение о переходе к производству на основе результатов производительности и тестов с последующей активацией другого конвейера CI/CD. для промежуточного и производственного развертывания. После запуска в производство потребители ML используют модель посредством вывода, инициируемого приложением, посредством прямого вызова или вызовов API, с циклами обратной связи с владельцами модели для постоянной оценки производительности.
Интеграция Amazon SageMaker Clarify и MLOps
Следуя жизненному циклу MLOps, специалисты по точной настройке или пользователи моделей с открытым исходным кодом создают точно настроенные модели или FM с помощью Amazon SageMaker Jumpstart и сервисов MLOps, как описано в разделе Внедрение практики MLOps с предварительно обученными моделями Amazon SageMaker JumpStart. Это привело к созданию новой области для операций базовой модели (FMOps) и операций LLM (LLMOps). FMOps/LLMOps: внедрение генеративного ИИ и различия с MLOps.
На следующем рисунке показан сквозной жизненный цикл LLMOps:
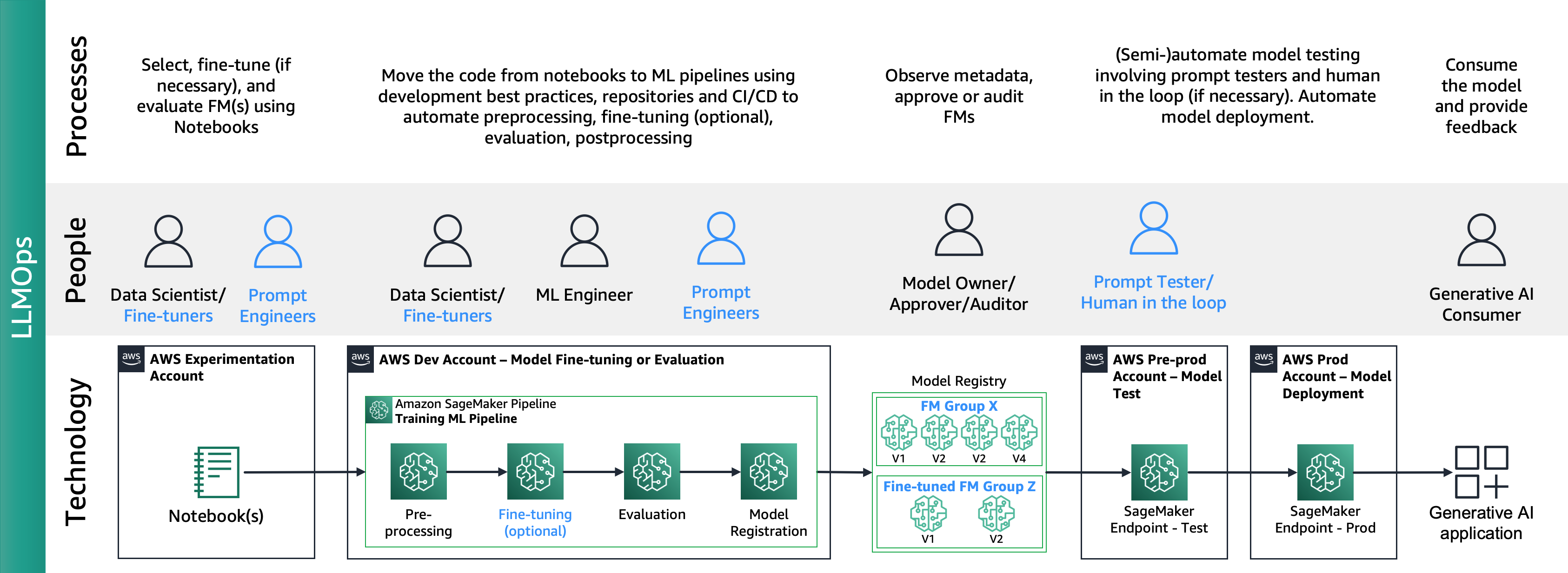
Основными отличиями LLMOps от MLOps являются выбор и оценка модели, включающие разные процессы и показатели. На начальном этапе экспериментирования специалисты по обработке данных (или специалисты по точной настройке) выбирают FM, который будет использоваться для конкретного варианта использования генеративного ИИ.
Это часто приводит к тестированию и точной настройке нескольких FM, некоторые из которых могут дать сопоставимые результаты. После выбора модели(-й) инженеры подсказок несут ответственность за подготовку необходимых входных данных и ожидаемых результатов для оценки (например, подсказки ввода, включающие входные данные и запрос) и определяют такие показатели, как сходство и токсичность. В дополнение к этим метрикам специалисты по обработке данных или специалисты по точной настройке должны проверить результаты и выбрать подходящий FM не только по показателям точности, но и по другим возможностям, таким как задержка и стоимость. Затем они могут развернуть модель на конечной точке SageMaker и протестировать ее производительность в небольшом масштабе. Хотя этап экспериментирования может включать в себя простой процесс, переход к производству требует от клиентов автоматизации процесса и повышения надежности решения. Поэтому нам необходимо углубиться в то, как автоматизировать оценку, позволяя тестировщикам выполнять эффективную оценку в масштабе и реализовывать мониторинг входных и выходных данных модели в режиме реального времени.
Автоматизация оценки FM
Amazon SageMaker Pipelines автоматизирует все этапы предварительной обработки, тонкой настройки FM (опционально) и оценки в масштабе. Учитывая выбранные в ходе экспериментов модели, инженерам подсказок необходимо охватить больший набор случаев, подготавливая множество подсказок и сохраняя их в специально отведенном хранилище, называемом каталогом подсказок. Для получения дополнительной информации см. FMOps/LLMOps: внедрение генеративного ИИ и различия с MLOps. Тогда конвейеры Amazon SageMaker можно структурировать следующим образом:
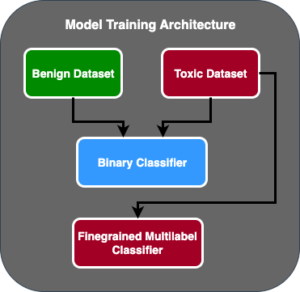
Сценарий 1. Оценка нескольких FM: В этом сценарии FM могут охватить вариант использования в бизнесе без тонкой настройки. Конвейер Amazon SageMaker состоит из следующих этапов: предварительная обработка данных, параллельная оценка нескольких FM, сравнение моделей и выбор на основе точности и других свойств, таких как стоимость или задержка, регистрация выбранных артефактов модели и метаданных.
Следующая диаграмма иллюстрирует эту архитектуру.

Сценарий 2. Точная настройка и оценка нескольких FM.: в этом сценарии конвейер Amazon SageMaker имеет структуру, аналогичную сценарию 1, но в нем параллельно выполняются этапы точной настройки и оценки для каждого FM. Лучшая доработанная модель будет зарегистрирована в Реестре моделей.
Следующая диаграмма иллюстрирует эту архитектуру.
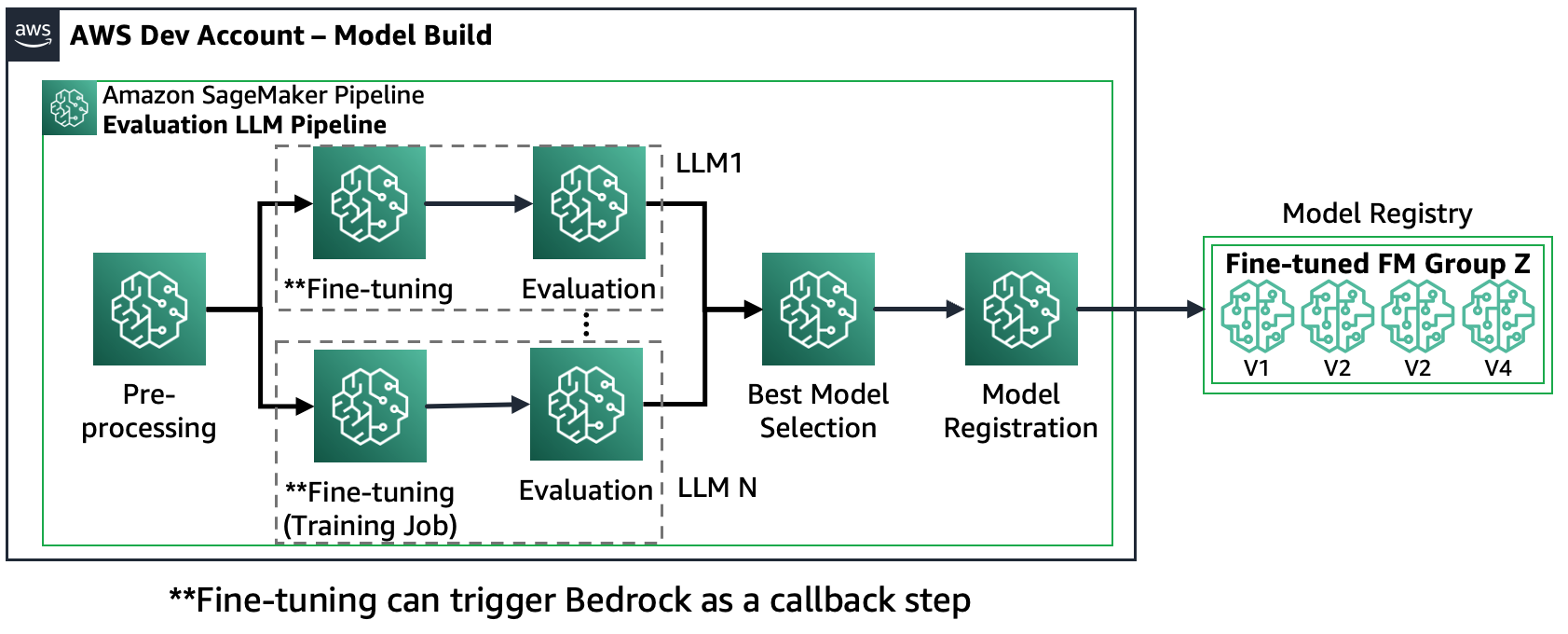
Сценарий 3. Оценка нескольких FM и точно настроенных FM.: Этот сценарий представляет собой комбинацию оценки FM общего назначения и точно настроенных FM. В этом случае клиенты хотят проверить, может ли точно настроенная модель работать лучше, чем FM общего назначения.
На следующем рисунке показаны итоговые шаги конвейера SageMaker.
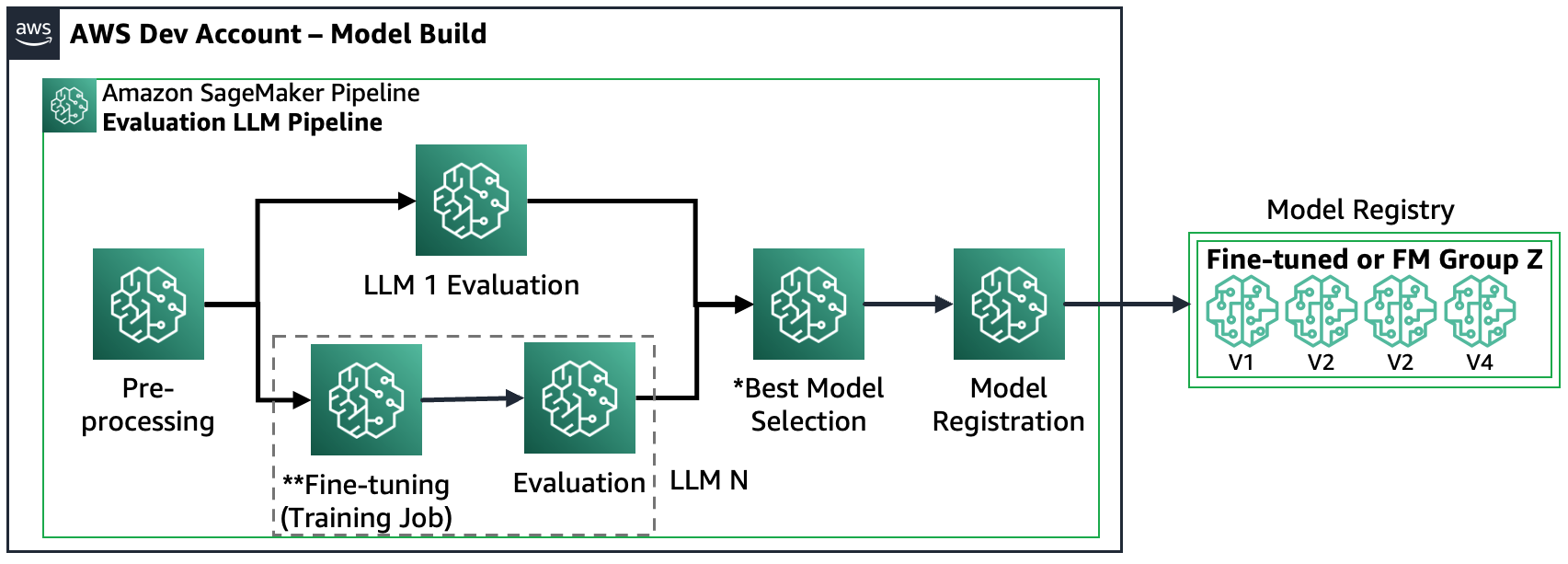
Обратите внимание, что регистрация модели следует двум шаблонам: (а) хранить модель и артефакты с открытым исходным кодом или (б) сохранять ссылку на проприетарный FM. Для получения дополнительной информации см. FMOps/LLMOps: внедрение генеративного ИИ и различия с MLOps.
Обзор решения
Чтобы ускорить ваш путь к масштабной оценке LLM, мы создали решение, реализующее сценарии с использованием Amazon SageMaker Clarify и нового SDK Amazon SageMaker Pipelines. Пример кода, включая наборы данных, исходные блокноты и конвейеры SageMaker (шаги и конвейер машинного обучения), доступен на странице GitHub. Для разработки этого примера решения мы использовали два FM: Llama2 и Falcon-7B. В этой статье мы сосредоточим основное внимание на ключевых элементах решения SageMaker Pipeline, которые относятся к процессу оценки.
Конфигурация оценки: В целях стандартизации процедуры оценки мы создали файл конфигурации YAML (evaluation_config.yaml), который содержит необходимые сведения для процесса оценки, включая набор данных, модель(и) и алгоритмы, которые будут выполняться во время этап оценки конвейера SageMaker. Следующий пример иллюстрирует файл конфигурации:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Шаг оценки: Новый SDK SageMaker Pipeline предоставляет пользователям возможность определять собственные шаги в рабочем процессе машинного обучения с помощью декоратора Python @step. Поэтому пользователям необходимо создать базовый скрипт Python, который будет проводить оценку следующим образом:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultКонвейер SageMaker: После создания необходимых шагов, таких как предварительная обработка данных, развертывание модели и оценка модели, пользователю необходимо связать эти шаги вместе с помощью SageMaker Pipeline SDK. Новый SDK автоматически генерирует рабочий процесс, интерпретируя зависимости между различными этапами при вызове API создания конвейера SageMaker, как показано в следующем примере:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()В примере реализуется оценка одного FM путем предварительной обработки исходного набора данных, развертывания модели и запуска оценки. Сгенерированный конвейерно-направленный ациклический граф (DAG) показан на следующем рисунке.
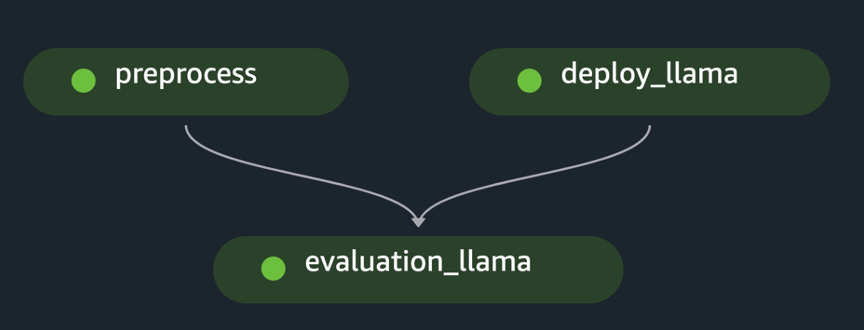
Следуя аналогичному подходу и используя и адаптируя пример из Точная настройка моделей LLaMA 2 в SageMaker JumpStartмы создали конвейер для оценки точно настроенной модели, как показано на следующем рисунке.

Используя предыдущие шаги SageMaker Pipeline в качестве блоков «Лего», мы разработали решение для сценариев 1 и 3, как показано на следующих рисунках. В частности, GitHub Репозиторий позволяет пользователю оценивать несколько FM параллельно или выполнять более сложную оценку, сочетающую оценку как базовой, так и точно настроенных моделей.

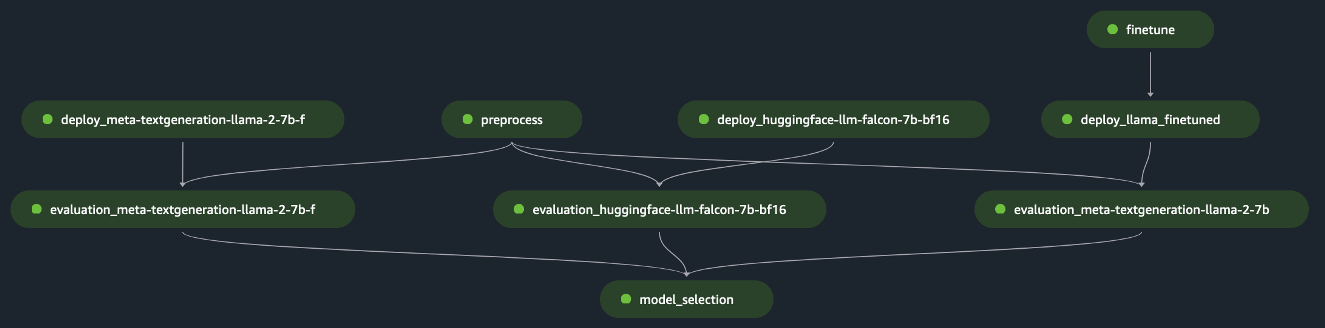
Дополнительные функции, доступные в репозитории, включают следующее:
- Генерация шага динамической оценки: Наше решение динамически генерирует все необходимые шаги оценки на основе файла конфигурации, чтобы пользователи могли оценить любое количество моделей. Мы расширили решение, чтобы обеспечить простую интеграцию новых типов моделей, таких как Hugging Face или Amazon Bedrock.
- Предотвратить перераспределение конечных точек: Если конечная точка уже существует, мы пропускаем процесс развертывания. Это позволяет пользователю повторно использовать конечные точки с FM для оценки, что приводит к экономии средств и сокращению времени развертывания.
- Очистка конечной точки: После завершения оценки SageMaker Pipeline выводит из эксплуатации развернутые конечные точки. Эту функциональность можно расширить, чтобы сохранить лучшую конечную точку модели.
- Шаг выбора модели: Мы добавили заполнитель шага выбора модели, который требует бизнес-логики окончательного выбора модели, включая такие критерии, как стоимость или задержка.
- Этап регистрации модели: лучшую модель можно зарегистрировать в реестре моделей Amazon SageMaker как новую версию определенной группы моделей.
- Теплый бассейн: Теплые пулы, управляемые SageMaker, позволяют сохранять и повторно использовать подготовленную инфраструктуру после завершения задания, чтобы уменьшить задержку при повторяющихся рабочих нагрузках.
На следующем рисунке показаны эти возможности и пример оценки нескольких моделей, который пользователи могут легко и динамично создавать, используя наше решение в этом случае. GitHub репозиторий.

Мы намеренно исключили подготовку данных за рамки, поскольку она будет подробно описана в другом посте, включая дизайн каталога подсказок, шаблоны подсказок, оптимизацию подсказок. Дополнительную информацию и определения соответствующих компонентов см. FMOps/LLMOps: внедрение генеративного ИИ и различия с MLOps.
Заключение
В этом посте мы сосредоточились на том, как автоматизировать и реализовать масштабную оценку LLM с помощью возможностей оценки LLM Amazon SageMaker Clarify и Amazon SageMaker Pipelines. В дополнение к теоретическим проектам архитектуры в этом разделе у нас есть пример кода. GitHub репозиторий (включающий FM-устройства Llama2 и Falcon-7B), позволяющий клиентам разрабатывать собственные масштабируемые механизмы оценки.
На следующем рисунке показана архитектура оценки модели.
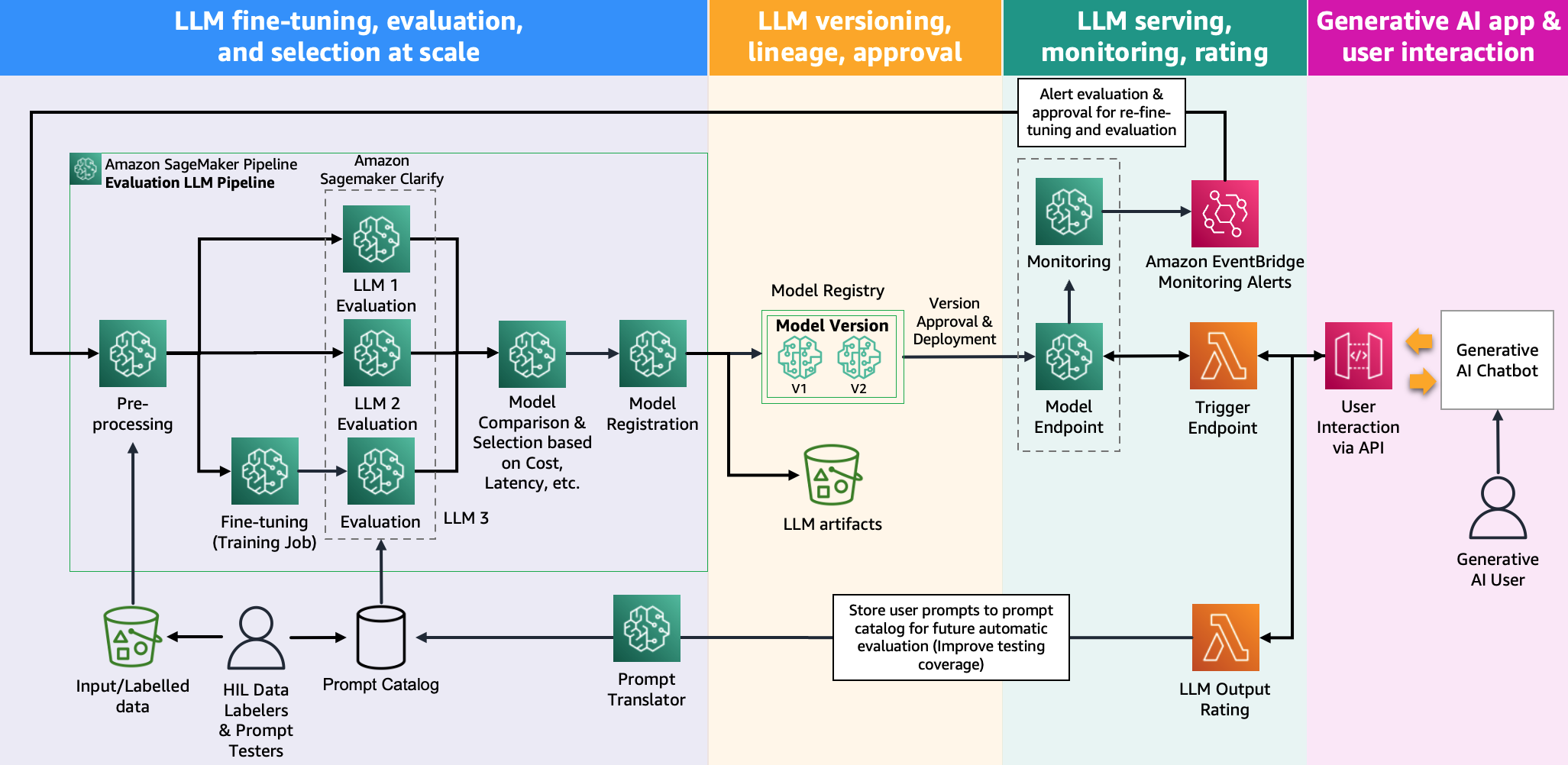
В этом посте мы сосредоточились на внедрении оценки LLM в масштабе, как показано в левой части иллюстрации. В будущем мы сосредоточимся на разработке примеров, реализующих сквозной жизненный цикл FM до производства, следуя рекомендациям, описанным в разделе FMOps/LLMOps: внедрение генеративного ИИ и различия с MLOps. Это включает в себя обслуживание LLM, мониторинг, сохранение выходных рейтингов, которые в конечном итоге вызовут автоматическую переоценку и точную настройку, и, наконец, использование людей в цикле для работы с помеченными данными или каталогом подсказок.
Об авторах
 Доктор Сократис Картакис — главный специалист по машинному обучению и эксплуатации, архитектор решений Amazon Web Services. Sokratis стремится предоставить корпоративным клиентам возможность индустриализировать свои решения машинного обучения (ML) и генеративного искусственного интеллекта, используя сервисы AWS и формируя свою операционную модель, то есть основы MLOps/FMOps/LLMOps, а также дорожную карту трансформации с использованием лучших практик разработки. Он потратил более 15 лет на изобретение, проектирование, руководство и внедрение инновационных комплексных решений машинного обучения и искусственного интеллекта на уровне производства в сферах энергетики, розничной торговли, здравоохранения, финансов, автоспорта и т. д.
Доктор Сократис Картакис — главный специалист по машинному обучению и эксплуатации, архитектор решений Amazon Web Services. Sokratis стремится предоставить корпоративным клиентам возможность индустриализировать свои решения машинного обучения (ML) и генеративного искусственного интеллекта, используя сервисы AWS и формируя свою операционную модель, то есть основы MLOps/FMOps/LLMOps, а также дорожную карту трансформации с использованием лучших практик разработки. Он потратил более 15 лет на изобретение, проектирование, руководство и внедрение инновационных комплексных решений машинного обучения и искусственного интеллекта на уровне производства в сферах энергетики, розничной торговли, здравоохранения, финансов, автоспорта и т. д.
 Джагдип Сингх Сони — старший архитектор решений для партнеров в AWS в Нидерландах. Он использует свою страсть к DevOps, GenAI и инструментам для разработчиков, чтобы помочь как системным интеграторам, так и технологическим партнерам. Джагдип применяет свой опыт разработки приложений и архитектуры для внедрения инноваций в своей команде и продвижения новых технологий.
Джагдип Сингх Сони — старший архитектор решений для партнеров в AWS в Нидерландах. Он использует свою страсть к DevOps, GenAI и инструментам для разработчиков, чтобы помочь как системным интеграторам, так и технологическим партнерам. Джагдип применяет свой опыт разработки приложений и архитектуры для внедрения инноваций в своей команде и продвижения новых технологий.
 Доктор Риккардо Гатти — старший архитектор стартап-решений из Италии. Он является техническим консультантом клиентов, помогая им развивать свой бизнес, выбирая правильные инструменты и технологии для внедрения инноваций, быстрого масштабирования и выхода на глобальный уровень за считанные минуты. Он всегда увлекался машинным обучением и генеративным искусственным интеллектом, изучая и применяя эти технологии в различных областях на протяжении всей своей рабочей карьеры. Он ведущий и редактор итальянского подкаста AWS «Casa Startup», посвященного историям основателей стартапов и новым технологическим тенденциям.
Доктор Риккардо Гатти — старший архитектор стартап-решений из Италии. Он является техническим консультантом клиентов, помогая им развивать свой бизнес, выбирая правильные инструменты и технологии для внедрения инноваций, быстрого масштабирования и выхода на глобальный уровень за считанные минуты. Он всегда увлекался машинным обучением и генеративным искусственным интеллектом, изучая и применяя эти технологии в различных областях на протяжении всей своей рабочей карьеры. Он ведущий и редактор итальянского подкаста AWS «Casa Startup», посвященного историям основателей стартапов и новым технологическим тенденциям.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 100
- 9
- a
- О нас
- ускорять
- доступ
- точность
- точно
- Достигать
- достижение
- через
- Действие (Act):
- Активация
- активный
- ациклический
- добавленный
- дополнение
- Дополнительно
- адрес
- адекватно
- администрация
- Принятие
- Принятие
- достижения
- советник
- После
- против
- агенты
- AI
- Закон об ИИ
- Системы искусственного интеллекта
- цель
- Стремясь
- алгоритм
- алгоритмы
- Выравнивает
- живой
- Все
- позволяет
- уже
- причислены
- всегда
- Amazon
- Создатель мудреца Амазонки
- Amazon SageMaker JumpStart
- Конвейеры Amazon SageMaker
- Студия Amazon SageMaker
- Amazon Web Services
- an
- анализировать
- и
- Другой
- ответ
- любой
- API
- Применение
- Разработка приложения
- Приложения
- прикладной
- применяется
- подхода
- соответствующий
- архитектура
- МЫ
- области
- аргумент
- AS
- оценить
- Оценка
- оценки;
- оценки
- At
- аудит
- автоматизировать
- Автоматизированный
- Автоматический
- автоматически
- автоматизация
- доступен
- AWS
- b
- фон
- основанный
- основной
- BE
- , так как:
- становиться
- было
- поведение
- эталонный тест
- протестированные
- тесты
- Преимущества
- ЛУЧШЕЕ
- Лучшая
- между
- Beyond
- смещение
- пристрастный
- предубеждения
- Блоки
- изоферменты печени
- нарушения
- ширина
- приносить
- строить
- строитель
- бизнес
- но
- by
- под названием
- Объявления
- CAN
- кандидат
- возможности
- способный
- захватить
- Карты
- Карьера
- случаев
- случаев
- каталог
- определенный
- вызов
- характеристика
- более дешевый
- проверка
- Выберите
- выбранный
- классификация
- классифицировать
- чистым
- код
- сплоченной
- сотрудничать
- сочетание
- комбинируя
- Общий
- сообщество
- сравнимый
- сравнить
- сравненный
- сравнение
- комплемент
- завершение
- комплекс
- сложность
- Соответствие закону
- соблюдать
- компонент
- компоненты
- содержащий
- вычислительный
- Вычисление
- сама концепция
- Беспокойство
- Проводить
- проведение
- дирижирует
- Конфигурация
- Свяжитесь
- подключает
- считается
- состоит
- строить
- Потребители
- Container
- содержит
- содержание
- контекст
- беспрестанно
- (CIJ)
- контраст
- диалоговый
- Беседы
- конвертировать
- исправить
- Цена
- экономия на издержках
- дорогостоящий
- Расходы
- чехол для варгана
- Создайте
- создали
- Создающий
- создание
- Критерии
- критической
- решающее значение
- изготовленный на заказ
- Клиенты
- DAG
- данным
- Подготовка данных
- ученый данных
- безопасность данных
- набор данных
- фальсификация данных
- Наборы данных
- Дата и время
- решать
- Принятие решений
- решения
- преданный
- глубоко
- глубокое погружение
- По умолчанию
- определять
- Определения
- обеспечивает
- Спрос
- Зависимости
- зависит
- развертывание
- развернуть
- развертывание
- развертывание
- глубина
- описано
- назначенный
- предназначенный
- проектирование
- конструкций
- желание
- желанный
- подробный
- подробнее
- развивать
- развитый
- развивающийся
- Развитие
- DevOps
- Различия
- различный
- направлять
- направленный
- погружение
- Разное
- do
- не
- домен
- доменов
- управлять
- в течение
- динамично
- e
- каждый
- легко
- легко
- редактор
- Эффективный
- эффективность
- эффективный
- эффективно
- усилие
- или
- элементы
- еще
- занятых
- включить
- позволяет
- позволяет
- впритык
- Конечная точка
- конечные точки
- энергетика
- Инженеры
- повышать
- обеспечивать
- обеспечивает
- обеспечение
- Предприятие
- корпоративные клиенты
- предприятий
- эпоха
- одинаково
- особенно
- существенный
- и т.д
- Эфир (ETH)
- EU
- оценивать
- оценивается
- оценки
- оценка
- Даже
- со временем
- пример
- Примеры
- исполнительный
- существующий
- ожидания
- ожидаемый
- ускорять
- продлить
- расширенная
- и, что лучший способ
- добыча
- f1
- Face
- облегчающий
- факторы
- Фактический
- справедливость
- Водопад
- ложный
- знаменитый
- БЫСТРО
- быстрее
- Особенность
- Показывая
- Обратная связь
- несколько
- поле
- фигура
- цифры
- Файл
- окончательный
- в заключение
- финансы
- финансовый
- Финансовый сектор
- Во-первых,
- Трансформируемость
- Фокус
- внимание
- фокусируется
- следует
- после
- следующим образом
- Что касается
- форма
- Год основания
- Устои
- Учредителями
- Рамки
- каркасы
- часто
- от
- выполнение
- полный
- функциональные возможности
- функциональность
- фундаментальный
- Более того
- будущее
- сбор
- Общие
- общее назначение
- порождать
- генерируется
- генерирует
- порождающий
- поколение
- генеративный
- Генеративный ИИ
- получить
- данный
- Глобальный
- Go
- предоставлять
- график
- группы
- Группы
- Рост
- рука
- вредный
- Освоение
- Есть
- имеющий
- he
- Медицина
- сильно
- помощь
- помощь
- помогает
- High
- высокий риск
- шарниры
- его
- проведение
- кашель
- Как
- How To
- Однако
- HTML
- HTTPS
- человек
- i
- IAM
- идентифицированный
- идентифицирует
- определения
- if
- иллюстрирует
- изображений
- осуществлять
- Осуществляющий
- инвентарь
- Импортировать
- значение
- улучшение
- улучшение
- in
- включают
- включает в себя
- В том числе
- включенный
- включения
- индикаторы
- промышленности
- информация
- сообщил
- Инфраструктура
- начальный
- обновлять
- Инновации
- инновационный
- вход
- затраты
- интегрировать
- интеграции.
- намеренно
- взаимодействие
- в нашей внутренней среде,
- в
- вводить
- вызывается
- включать в себя
- вовлеченный
- включает в себя
- с участием
- ISO
- IT
- Итальянский
- Италии
- пункты
- итерация
- ЕГО
- работа
- путешествие
- JPG
- Сохранить
- хранится
- Основные
- знания
- язык
- большой
- больше
- Фамилия
- наконец
- Задержка
- вести
- лидеров
- ведущий
- изучение
- оставил
- позволять
- Используя
- Библиотека
- Жизненный цикл
- такое как
- Ограниченный
- LINK
- Лама
- расположение
- логика
- Низкий
- машина
- обучение с помощью машины
- Главная
- поддерживать
- поддерживает
- управляемого
- манипуляционная
- манипуляции
- руководство
- многих
- Май..
- Между тем
- проводить измерение
- меры
- механизмы
- Метаданные
- метод
- методы
- метрический
- Метрика
- минимизировать
- минут
- дезинформация
- смягчать
- смягчающим
- ML
- млн операций в секунду
- модель
- Модели
- модуль
- монитор
- Мониторинг
- БОЛЕЕ
- самых
- мотивированные
- Автоспорт
- много
- с разными
- должен
- имя
- необходимо
- Необходимость
- потребности
- Нидерланды
- Новые
- Новые технологии
- следующий
- неспециалисты
- в своих размышлениях
- ноутбук
- ноутбуки
- нюансы
- номер
- of
- предлагают
- .
- on
- консолидировать
- ONE
- постоянный
- только
- с открытым исходным кодом
- операционный
- операция
- Операционный отдел
- Мнения
- оптимизация
- or
- OS
- Другое
- наши
- внешний
- Результат
- Результаты
- выходной
- выходы
- выдающийся
- за
- общий
- собственный
- Владельцы
- Параллельные
- параметры
- особый
- особенно
- партнер
- партнеры
- страсть
- страстный
- путь
- паттеранами
- Люди
- выполнять
- производительность
- выступления
- выполняет
- фаза
- PII
- трубопровод
- Часть
- заполнитель
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- PoC
- Подкаст
- Точка
- бассейн
- Пулы
- После
- Постобработка
- потенциал
- мощностью
- Питание
- практиками
- Точность
- подготовка
- подготовка
- присутствие
- предотвращать
- предыдущий
- первичный
- Основной
- Принципы
- политикой конфиденциальности.
- частная
- Проблема
- процедуры
- процесс
- Процессы
- обработка
- Производство
- прогрессия
- протуберанец
- обещание
- продвижении
- наводящие
- доказательство
- доказательство концепции
- распространение
- свойства
- ( изучите наши патенты),
- для защиты
- Доказывать
- обеспечивать
- поставщики
- приводит
- обеспечение
- что такое варган?
- публично
- цель
- Питон
- качественный
- количественный
- вопрос
- ассортимент
- Обменный курс
- рейтинг
- реальные
- реальный мир
- реального времени
- уменьшить
- Цена снижена
- снижение
- относиться
- ссылка
- зарегистрированный
- Регистрация
- реестра
- регресс
- регулярный
- регулируемых брокеров
- регулируемые отрасли
- правила
- усиление обучения
- Связанный
- актуальность
- соответствующие
- надежность
- повторяющийся
- отчету
- Reporting
- Отчеты
- хранилище
- представитель
- обязательный
- требуется
- исследованиям
- исследователи
- ресурсоемкий
- Полезные ресурсы
- ответственность
- ответственный
- в результате
- Итоги
- розничный
- сохранять
- возвращают
- снова использовать
- обзоре
- Революционные
- правую
- тщательный
- Risen
- Снижение
- рисках,
- Дорожная карта
- надежный
- прочность
- Роли
- роли
- Run
- Бег
- работает
- s
- безопасный
- защитные меры
- sagemaker
- Конвейеры SageMaker
- экономия
- Масштабируемость
- масштабируемые
- Шкала
- сценарий
- Сценарии
- Ученый
- Ученые
- сфера
- Гол
- скрипт
- SDK
- легко
- разделах
- сектор
- безопасный
- безопасность
- риски безопасности
- выберите
- выбранный
- выбор
- выбор
- старший
- настроение
- служить
- обслуживание
- Услуги
- выступающей
- Сессия
- набор
- формирование
- Поделиться
- показывать
- показанный
- Шоу
- сторона
- значительный
- аналогичный
- упрощает
- просто
- с
- одинарной
- небольшой
- Решение
- Решения
- РЕШАТЬ
- некоторые
- Источник
- пролет
- специалист
- конкретный
- конкретно
- потраченный
- инсценировка
- заинтересованных сторон
- стандартизации
- стандартов
- Стэнфорд
- Начало
- начинается
- ввод в эксплуатацию
- Статус:
- Шаг
- Шаги
- По-прежнему
- диск
- магазин
- Истории
- простой
- структурированный
- учился
- студия
- стиль
- впоследствии
- такие
- РЕЗЮМЕ
- поддержка
- система
- системы
- портняжное дело
- Сложность задачи
- задачи
- команда
- команды
- Технический
- снижения вреда
- технологический
- технологии
- Технологии
- шаблоны
- тестXNUMX
- Тестеры
- Тестирование
- тестов
- текст
- чем
- который
- Ассоциация
- Будущее
- их
- Их
- тогда
- теоретический
- тем самым
- следовательно
- Эти
- они
- этой
- те
- три
- Через
- по всему
- время
- в
- вместе
- инструментом
- инструменты
- трек
- Train
- специалистов
- Обучение
- поезда
- трансформация
- переход
- Переход
- Переводы
- Тенденции
- вызвать
- правда
- заслуживающий доверия
- два
- Типы
- типичный
- В конечном счете
- неразрешенный
- понимать
- понимание
- беспрецедентный
- Предстоящие
- использование
- прецедент
- используемый
- Информация о пользователе
- пользователей
- использования
- через
- обычно
- использовать
- VALIDATE
- ценный
- различный
- версия
- с помощью
- жизненный
- Уязвимости
- хотеть
- теплый
- we
- Web
- веб-сервисы
- ЧТО Ж
- были
- Что
- когда
- , которые
- в то время как
- КТО
- широкий
- Широкий диапазон
- Википедия.
- будете
- в
- без
- Работа
- рабочий
- работает
- Мир
- YAML
- лет
- Уступать
- являетесь
- ВАШЕ
- зефирнет