Рекламные сообщения

Проблемы построения мультимодальных моделей с нуля
Во многих случаях использования машинного обучения организации полагаются исключительно на табличные данные и древовидные модели, такие как XGBoost и LightGBM. Это связано с тем, что глубокое обучение слишком сложно для большинства команд машинного обучения. Общие проблемы включают в себя:
- Отсутствие экспертных знаний, необходимых для разработки сложных моделей глубокого обучения
- Такие фреймворки, как PyTorch и Tensorflow, требуют от команд написания тысяч строк кода, подверженных человеческим ошибкам.
- Для обучения распределенных конвейеров DL требуются глубокие знания инфраструктуры, а на обучение моделей могут уйти недели.
В результате команды упускают ценные сигналы, скрытые в неструктурированных данных, таких как текст и изображения.
Быстрая разработка моделей с помощью декларативных систем
Новые декларативные системы машинного обучения, такие как система с открытым исходным кодом, созданная Людвигом в Uber, обеспечивают подход к автоматизации машинного обучения с минимальным объемом кода, который позволяет специалистам по работе с данными быстрее создавать и развертывать современные модели с помощью простого файла конфигурации. В частности, Predibase — ведущая платформа декларативного машинного обучения с малым объемом кода — вместе с Ludwig упрощают создание мультимодальных моделей глубокого обучения менее чем за 15 строк кода.
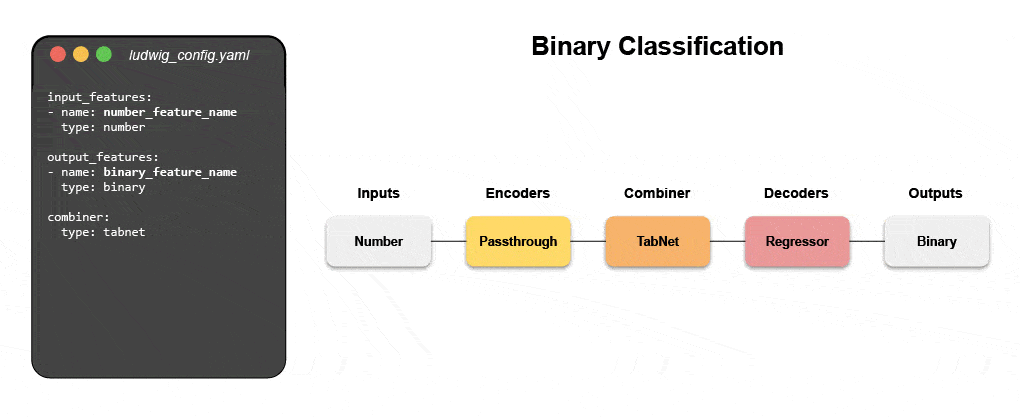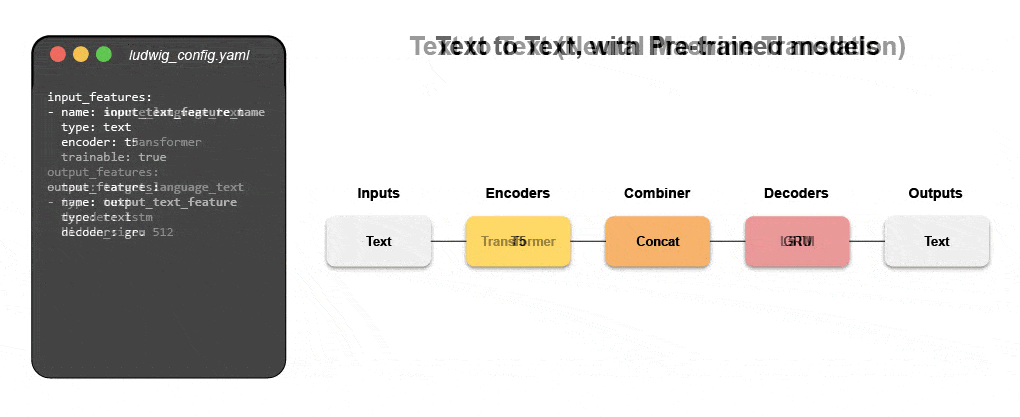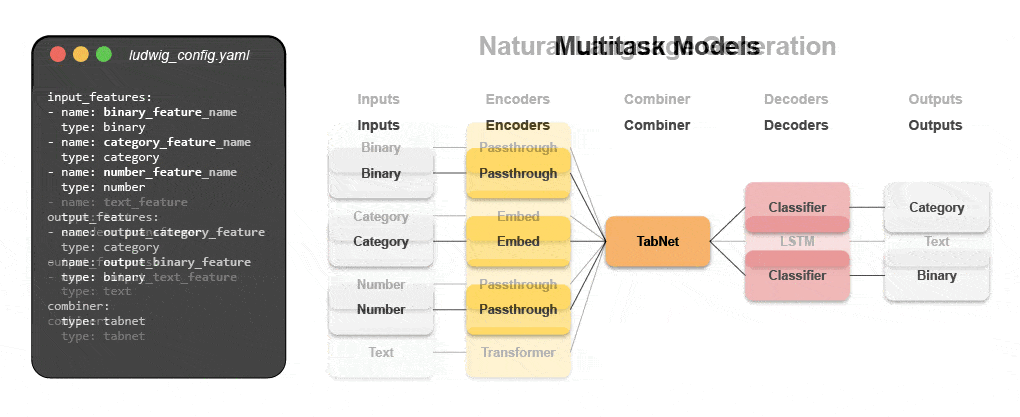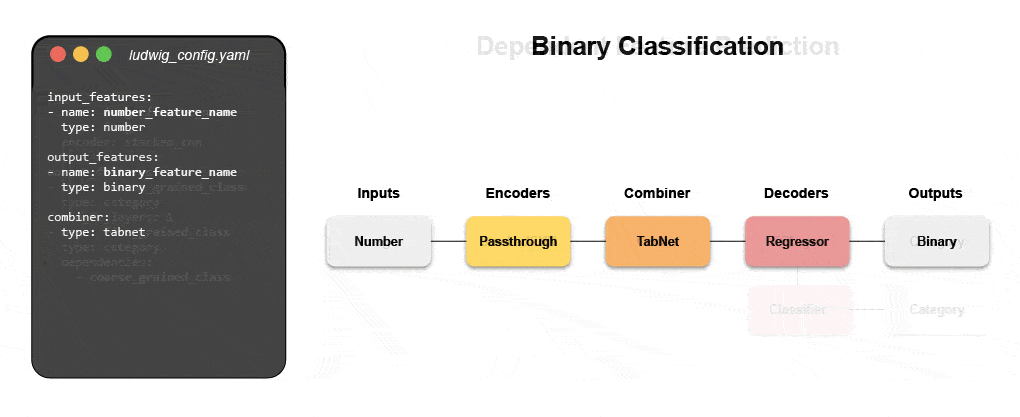
Узнайте, как создать мультимодальную модель с помощью декларативного машинного обучения.
Присоединяйтесь к нашему предстоящему вебинару и интерактивный учебник, чтобы узнать о декларативных системах, таких как Ludwig, и следовать пошаговым инструкциям по созданию мультимодальной модели прогнозирования отзывов клиентов с использованием текстовых и табличных данных.
На этом занятии вы узнаете, как:
- Быстро обучайте, итерируйте и развертывайте мультимодальную модель для прогнозирования отзывов клиентов,
- Используйте инструменты декларативного машинного обучения с малым кодом, чтобы значительно сократить время, необходимое для создания нескольких моделей машинного обучения.
- Используйте неструктурированные данные так же легко, как и структурированные, с помощью Ludwig и Predibase с открытым исходным кодом.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- О нас
- и
- подхода
- Автоматизация
- , так как:
- строить
- Строительство
- проблемы
- код
- Общий
- комплекс
- Конфигурация
- клиент
- данным
- глубоко
- глубокое обучение
- развертывание
- развивать
- Развитие
- распределенный
- драматично
- легко
- позволяет
- ошибка
- эксперту
- быстрее
- Файл
- следовать
- от
- GIF
- Жесткий
- Скрытый
- Как
- How To
- HTML
- HTTPS
- человек
- изображений
- in
- включают
- Инфраструктура
- инструкции
- IT
- КДнаггетс
- знания
- ведущий
- УЧИТЬСЯ
- изучение
- Используя
- линий
- жить
- машина
- обучение с помощью машины
- сделать
- многих
- ML
- модель
- Модели
- самых
- с разными
- необходимый
- с открытым исходным кодом
- организации
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- прогноз
- Predictions
- pytorch
- уменьшить
- требовать
- требуется
- результат
- обзоре
- Сессия
- сигналы
- просто
- просто
- конкретно
- и политические лидеры
- современное состояние
- Шаг
- структурированный
- системы
- взять
- принимает
- команды
- tensorflow
- Ассоциация
- тысячи
- время
- в
- слишком
- инструменты
- Train
- учебник
- Предстоящие
- случаи использования
- ценный
- Недели
- будете
- в
- записывать
- XGBoost
- ВАШЕ
- зефирнет





