Амазонка Redshift — это быстрое, полностью управляемое хранилище данных масштаба в петабайтах, обеспечивающее гибкость использования выделенных или бессерверных вычислений для аналитических рабочих нагрузок. С использованием Amazon Redshift без сервера и Редактор запросов v2, вы можете загружать и запрашивать большие наборы данных всего за несколько кликов и платить только за то, что используете. Разделенная архитектура вычислений и хранения данных Amazon Redshift позволяет создавать масштабируемые, отказоустойчивые и экономичные рабочие нагрузки. Многие клиенты переносят свои рабочие нагрузки по хранению данных в Amazon Redshift и получают выгоду от предлагаемых им богатых возможностей. Ниже приведены лишь некоторые из примечательных возможностей:
- Amazon Redshift легко интегрируется с более широким сервисы аналитики на AWS. Это позволяет выбрать правильный инструмент для правильной работы. Современная аналитика гораздо шире, чем хранилище данных на основе SQL. Amazon Redshift позволяет создавать архитектура дома у озера а затем выполнить любую аналитику, например интерактивная аналитика, операционная аналитика, обработка больших данных, подготовка визуальных данных, предиктивная аналитика, машинное обучение (МЛ) и многое другое.
- Вам не нужно беспокоиться о рабочих нагрузках, таких как ETL, информационные панели, специальные запросы и т. д., которые мешают друг другу. Вы можете изолировать рабочие нагрузки используя совместное использование данных, используя одни и те же базовые наборы данных.
- Когда пользователи выполняют множество запросов в часы пик, вычислительные ресурсы плавно масштабируются в течение нескольких секунд, обеспечивая стабильную производительность при высокой степени параллелизма. Вы получаете один час бесплатного параллельного масштабирования на 24 часа использования. Этот бесплатный кредит удовлетворяет спрос на параллелизм 97 % клиентской базы Amazon Redshift.
- Amazon Redshift прост в использовании благодаря самонастройка и самооптимизация возможности. Вы можете быстрее получать ценные сведения, не тратя драгоценное время на управление хранилищем данных.
- Отказоустойчивость встроен. Все данные, записываемые в Amazon Redshift, автоматически и непрерывно реплицируются в Amazon Simple Storage Service (Amazon S3). Любые аппаратные сбои автоматически заменяются.
- Amazon Redshift это просто взаимодействовать . Вы можете получить доступ к данным с помощью традиционных, облачных, контейнерных и бессерверных веб-служб на основе приложений или приложений, управляемых событиями, и так далее.
- Красное смещение ML позволяет специалистам по обработке и анализу данных создавать, обучать и развертывать модели машинного обучения с использованием знакомого SQL. Они также могут выполнять прогнозы с помощью SQL.
- Amazon Redshift предоставляет комплексная защита данных без дополнительных затрат. Вы можете настроить сквозное шифрование данных, настроить правила брандмауэра, определить детализированные элементы управления безопасностью на уровне строк и столбцов для конфиденциальных данных и т. д.
- Амазонка Redshift легко интегрируется с другими сервисами AWS и сторонними инструментами. Вы можете быстро и надежно перемещать, преобразовывать, загружать и запрашивать большие наборы данных.
В этом посте мы представляем пошаговое руководство по переносу хранилища данных из Google BigQuery в Amazon Redshift с помощью Инструмент преобразования схемы AWS (AWS SCT) и Агенты извлечения данных AWS SCT. AWS SCT — это сервис, который делает миграцию разнородных баз данных предсказуемой за счет автоматического преобразования большей части кода базы данных и объектов хранилища в формат, совместимый с целевой базой данных. Любые объекты, которые не могут быть преобразованы автоматически, четко помечены, чтобы их можно было преобразовать вручную для завершения миграции. Кроме того, AWS SCT может сканировать код вашего приложения на наличие встроенных операторов SQL и преобразовывать их.
Обзор решения
AWS SCT использует сервисный аккаунт для подключения к вашему проекту BigQuery. Сначала мы создаем базу данных Amazon Redshift, в которую переносятся данные BigQuery. Далее мы создаем корзину S3. Затем мы используем AWS SCT для преобразования схем BigQuery и применения их к Amazon Redshift. Наконец, для переноса данных мы используем агенты извлечения данных AWS SCT, которые извлекают данные из BigQuery, загружают их в корзину S3, а затем копируют в Amazon Redshift.

Предпосылки
Прежде чем приступить к этому пошаговому руководству, необходимо выполнить следующие предварительные условия:
- Рабочая станция с AWS SCT, Амазонка Корретто 11и драйверы Amazon Redshift.
- Вы можете использовать Облако Amazon Elastic Compute (Amazon EC2)) или ваш локальный рабочий стол в качестве рабочей станции. В этом пошаговом руководстве мы используем Экземпляр Amazon EC2 для Windows. Для его создания используйте этого руководства.
- Чтобы загрузить и установить AWS SCT на ранее созданный инстанс EC2, используйте этого руководства.
- Загрузите драйвер Amazon Redshift JDBC со страницы это место.
- Скачайте и установите Амазонка Корретто 11.
- Сервисный аккаунт GCP, который AWS SCT может использовать для подключения к исходному проекту BigQuery.
- Грант Администратор BigQuery и Администратор хранилища роли в сервисный аккаунт.
- Скопируйте файл ключа учетной записи службы, созданный в консоли управления облаком Google, в экземпляр EC2 с AWS SCT.
- Создайте сегмент облачного хранилища в GCP для хранения исходных данных во время миграции.
В этом пошаговом руководстве рассматриваются следующие шаги:
- Создайте бессерверную рабочую группу и пространство имен Amazon Redshift
- Создайте корзину и папку AWS S3
- Преобразуйте и примените схему BigQuery к Amazon Redshift с помощью AWS SCT.
- Подключение к источнику Google BigQuery
- Подключитесь к цели Amazon Redshift
- Преобразование схемы BigQuery в схему Amazon Redshift
- Проанализируйте отчет об оценке и рассмотрите пункты действий
- Применение преобразованной схемы к целевому Amazon Redshift
- Перенос данных с помощью агентов извлечения данных AWS SCT
- Создание хранилищ доверия и ключей (необязательно)
- Установите и запустите агент извлечения данных
- Зарегистрировать агент извлечения данных
- Добавьте виртуальные разделы для больших таблиц (необязательно)
- Создайте локальную задачу миграции
- Запустите задачу переноса локальных данных
- Просмотр данных в Amazon Redshift
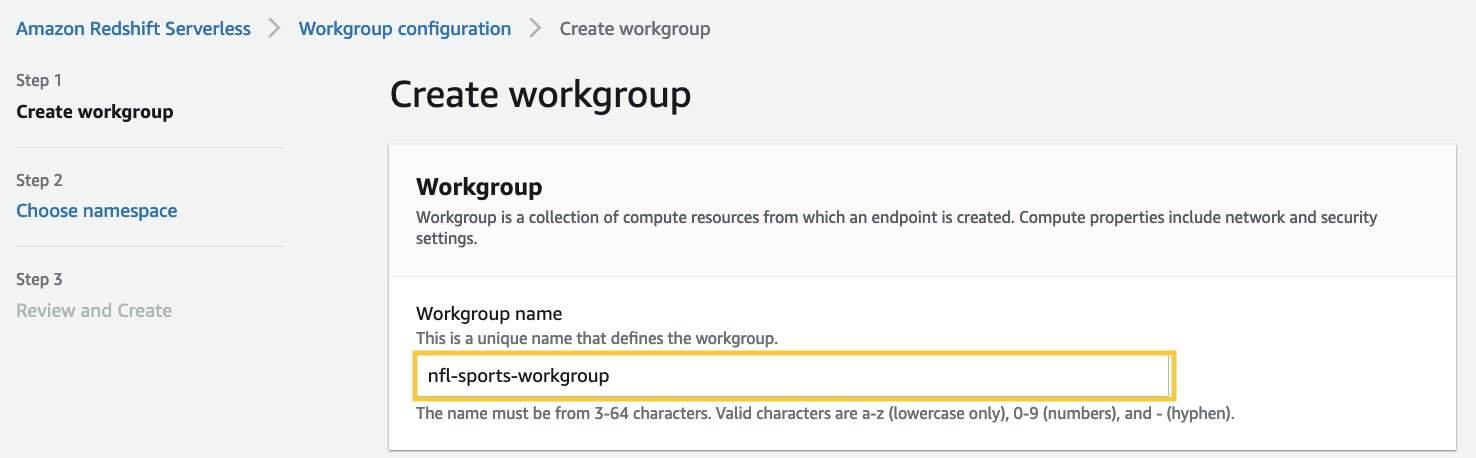
Создайте бессерверную рабочую группу и пространство имен Amazon Redshift
На этом шаге мы создаем рабочую группу и пространство имен Amazon Redshift Serverless. Рабочая группа — это набор вычислительных ресурсов, а пространство имен — это набор объектов базы данных и пользователей. Чтобы изолировать рабочие нагрузки и управлять различными ресурсами в Amazon Redshift Serverless, вы можете создавать пространства имен и рабочие группы и управлять хранилищем и вычислительными ресурсами по отдельности.
Выполните следующие действия, чтобы создать рабочую группу и пространство имен Amazon Redshift Serverless:
- Перейдите в Консоль Amazon Redshift.
- В правом верхнем углу выберите регион AWS, который вы хотите использовать.
- Разверните панель Amazon Redshift слева и выберите Бессерверное Redshift.
- Выберите Создать рабочую группу.
- Что касается Название рабочей группы, введите имя, описывающее вычислительные ресурсы.
- Убедитесь, что VPC совпадает с VPC инстанса EC2 с AWS SCT.
- Выберите Следующая.
- Что касается Имя пространства имен, введите имя, описывающее ваш набор данных.
- In Имя базы данных и пароль раздел, установите флажок Настройка учетных данных администратора.
- Что касается Имя пользователя администратора, введите имя пользователя по вашему выбору, например, awsuser.
- Что касается Пароль пользователя администратора: введите пароль по вашему выбору, например Мой RedShiftPW2022.
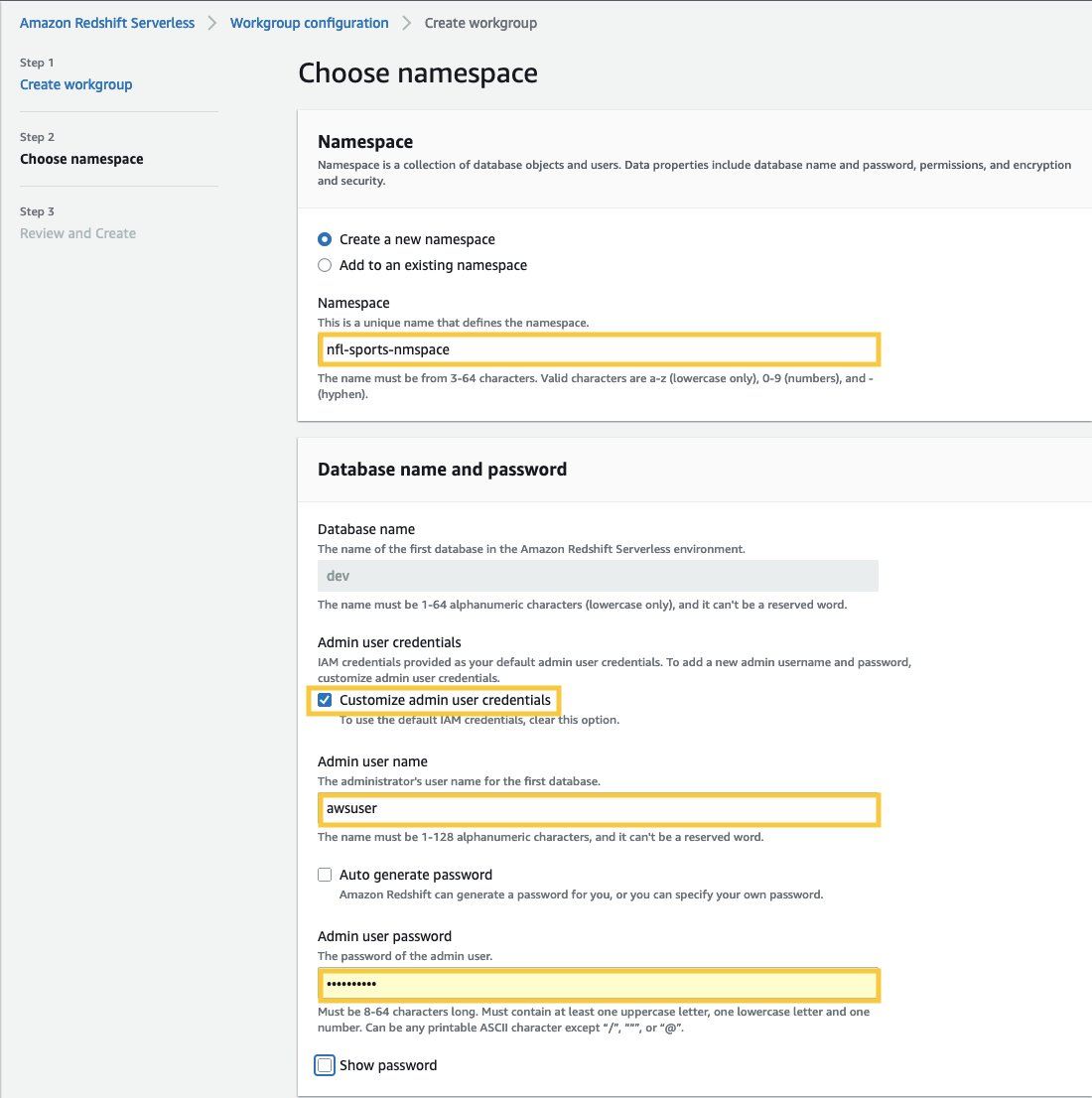
- Выберите Далее. Обратите внимание, что данные в пространстве имен Amazon Redshift Serverless по умолчанию зашифрованы.
- В Просмотр и создание выберите страницу Создавай.
- Создать Управление идентификацией и доступом AWS (IAM) роль и установите ее по умолчанию в вашем пространстве имен, как описано ниже. Обратите внимание, что может быть только одна роль IAM по умолчанию.
- Перейдите в Бессерверная информационная панель Amazon Redshift.
- Под Пространства имен/рабочие группы, выберите пространство имен, которое вы только что создали.
- Перейдите вБезопасность и шифрование.
- Под Разрешения..., выберите Управление ролями IAM.
- Перейдите в Управление ролями IAM. Затем выберите Управление ролями IAM раскрывающийся список и выберите Создать роль IAM.
- Под Укажите корзину Amazon S3 для доступа к роли IAM., выберите один из следующих способов:
- Выберите Без дополнительной корзины Amazon S3 чтобы разрешить созданной роли IAM доступ только к корзинам S3 с именем, начинающимся с красного смещения.
- Выберите Любая корзина Amazon S3 чтобы разрешить созданной роли IAM доступ ко всем корзинам S3.
- Выберите Конкретные корзины Amazon S3 чтобы указать одну или несколько корзин S3 для доступа созданной роли IAM. Затем выберите один или несколько сегментов S3 из таблицы.
- Выберите Создать роль IAM по умолчанию. Amazon Redshift автоматически создает и устанавливает роль IAM по умолчанию.
- Захватите конечную точку для рабочей группы Amazon Redshift Serverless, которую вы только что создали.
Создайте корзину и папку S3
В процессе переноса данных AWS SCT использует Amazon S3 в качестве промежуточной области для извлеченных данных. Выполните следующие действия, чтобы создать корзину S3:
- Перейдите в Консоль Amazon S3
- Выберите Создать ведро, Создать ведро открывается мастер.
- Что касается Название ковша, введите уникальное DNS-совместимое имя для своего сегмента (например, уникальное имя-bq-rs). См. правила именования корзин при выборе имени.
- В качестве региона AWS выберите регион, в котором вы создали рабочую группу Amazon Redshift Serverless.
- Выберите Создать ведро.
- В Консоль Amazon S3, перейдите к только что созданному сегменту S3 (например, уникальное имя-bq-rs).
- Выберите "Создать папку" для создания новой папки.
- Что касается Имя папки, вводить входящий , а затем выбрать Создать папку.
Преобразуйте и примените схему BigQuery к Amazon Redshift с помощью AWS SCT.
Для преобразования схемы BigQuery в формат Amazon Redshift мы используем AWS SCT. Начните с входа в созданный ранее экземпляр EC2, а затем запустите AWS SCT.
Выполните следующие действия с помощью AWS SCT:
Подключиться к источнику BigQuery
- Из издания File Menu укажите Создать новый проект.
- Выберите место для хранения файлов и данных вашего проекта.
- Дайте осмысленное, но запоминающееся имя для вашего проекта, например, BigQuery для Amazon Redshift.
- Чтобы подключиться к исходному хранилищу данных BigQuery, выберите Добавить источник из главного меню.
- Выберите BigQuery , а затем выбрать Следующая. В Добавить источник появится диалоговое окно.
- Что касается Название соединения, введите имя для описания подключения BigQuery. AWS SCT отображает это имя в дереве на левой панели.
- Что касается Ключевой путь, укажите путь к файлу ключа сервисного аккаунта, который был ранее создан в консоли управления облаком Google.
- Выберите Проверить подключение чтобы убедиться, что AWS SCT может подключиться к исходному проекту BigQuery.
- После успешной проверки соединения выберите Свяжитесь.

Подключитесь к цели Amazon Redshift
Выполните следующие действия, чтобы подключиться к Amazon Redshift:
- В AWS SCT выберите Добавить цель из главного меню.
- Выберите Амазонка Redshift, а затем выберите Далее. Ассоциация Добавить цель появится диалоговое окно.
- Что касается Название соединения, введите имя для описания подключения к Amazon Redshift. AWS SCT отображает это имя в дереве на правой панели.
- Что касается Имя сервера, введите захваченную ранее конечную точку рабочей группы Amazon Redshift Serverless.
- Что касается Порт сервера, вводить 5439.
- Что касается База данных, вводить DEV.
- Что касается Имя пользователя, введите имя пользователя, выбранное при создании рабочей группы Amazon Redshift Serverless.
- Что касается Пароль, введите пароль, выбранный при создании рабочей группы Amazon Redshift Serverless.
- Снимите галочку с поле «Использовать клей AWS».
- Выберите Проверить подключение чтобы убедиться, что AWS SCT может подключиться к вашей целевой рабочей группе Amazon Redshift.
- Выберите Свяжитесь для подключения к цели Amazon Redshift.
Обратите внимание, что в качестве альтернативы вы можете использовать значения соединения, которые хранятся в Менеджер секретов AWS.

Преобразование схемы BigQuery в схему Amazon Redshift
После успешного установления исходного и целевого соединений вы увидите исходное дерево объектов BigQuery на левой панели и целевое дерево объектов Amazon Redshift на правой панели.
Выполните следующие действия, чтобы преобразовать схему BigQuery в формат Amazon Redshift:
- На левой панели щелкните правой кнопкой мыши схему, которую вы хотите преобразовать.
- Выберите Преобразовать схему.
- Появится диалоговое окно с вопросом, Объекты могут уже существовать в целевой базе данных. Заменять?. Выберите Да.
После завершения преобразования вы увидите новую схему, созданную на панели Amazon Redshift (правая панель) с тем же именем, что и ваша схема BigQuery.

Примерная схема, которую мы использовали, содержит 16 таблиц, 3 представления и 3 процедуры. Вы можете увидеть эти объекты в формате Amazon Redshift на правой панели. AWS SCT преобразует весь код и объекты данных BigQuery в формат Amazon Redshift. Кроме того, вы можете использовать AWS SCT для преобразования внешних сценариев SQL, кода приложений или дополнительных файлов со встроенным SQL.
Проанализируйте отчет об оценке и рассмотрите пункты действий
AWS SCT создает отчет об оценке сложности миграции. AWS SCT может преобразовывать большую часть кода и объектов базы данных. Однако для некоторых объектов может потребоваться ручное преобразование. AWS SCT выделяет эти объекты синим цветом на диаграмме статистики конверсий и создает элементы действий с привязкой к ним сложности.
Чтобы просмотреть отчет об оценке, переключитесь с Главный вид до Просмотр отчета об оценке следующим образом:
Ассоциация Обзор Вкладка показывает объекты, которые были преобразованы автоматически, и объекты, которые не были преобразованы автоматически. Зеленый представляет автоматически преобразованные или с простыми действиями. Синий цвет обозначает средние и сложные действия, требующие ручного вмешательства.
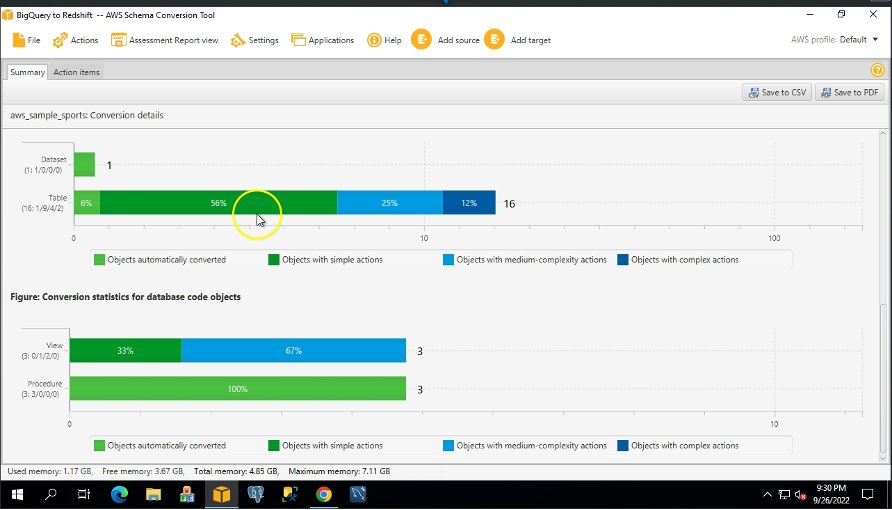
Ассоциация Пункты действий На вкладке показаны рекомендуемые действия для каждой проблемы с конверсией. Если вы выбираете действие из списка, AWS SCT выделяет объект, к которому относится действие.
Отчет также содержит рекомендации по ручному преобразованию элемента схемы. Например, после выполнения оценки подробные отчеты для базы данных/схемы показывают усилия, необходимые для разработки и реализации рекомендаций по преобразованию элементов действий. Дополнительные сведения о том, как решить, как обрабатывать ручные преобразования, см. Обработка ручных преобразований в AWS SCT. Amazon Redshift автоматически выполняет некоторые действия при преобразовании схемы в Amazon Redshift. Объекты с этими действиями отмечены красным предупреждающим знаком.

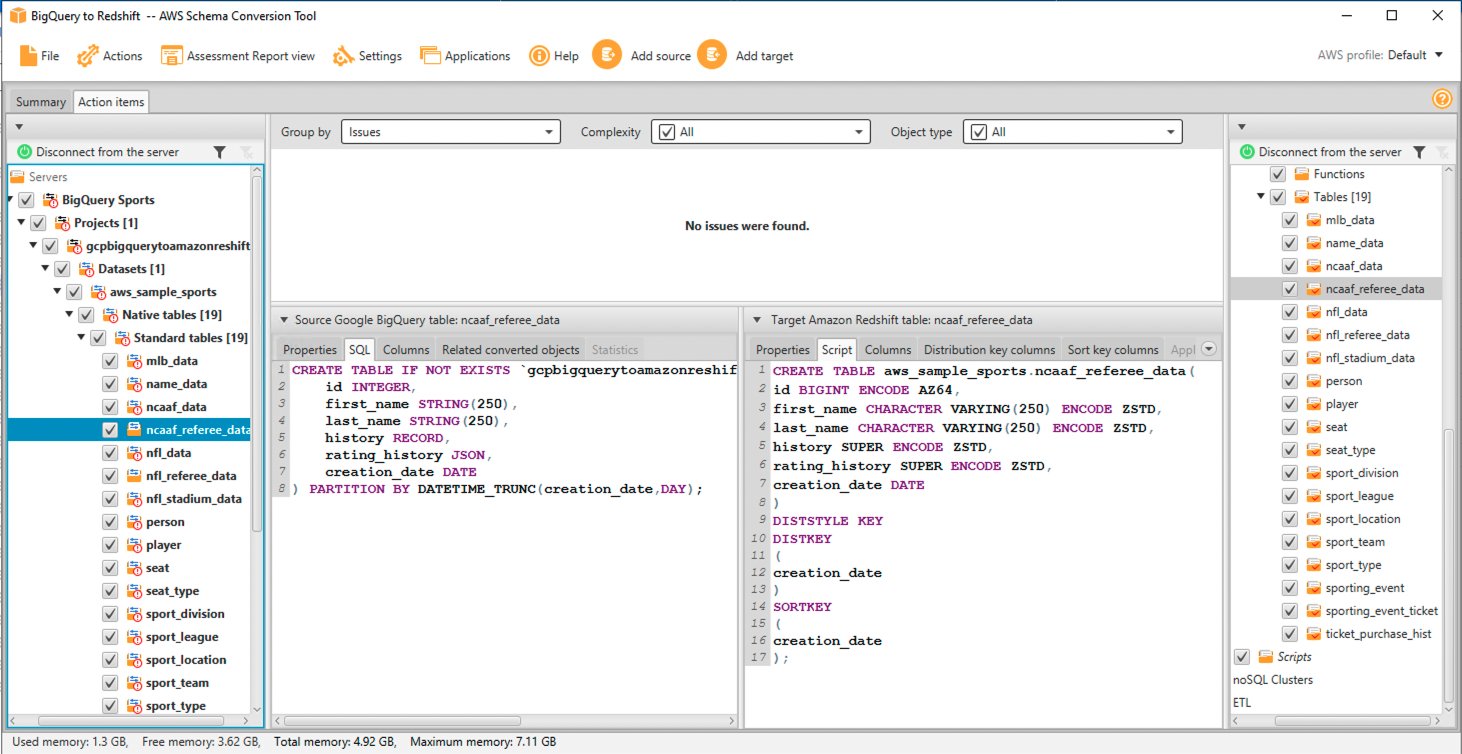
Вы можете оценить и проверить DDL отдельного объекта, выбрав его на правой панели, а также при необходимости отредактировать его. В следующем примере AWS SCT изменяет столбцы типов данных RECORD и JSON в таблице BigQuery ncaaf_referee_data на тип данных SUPER в Amazon Redshift. Ключ раздела в таблице ncaaf_referee_data преобразуется в ключ распределения и ключ сортировки в Amazon Redshift.
Применение преобразованной схемы к целевому Amazon Redshift
Чтобы применить преобразованную схему к Amazon Redshift, выберите преобразованную схему на правой панели, щелкните правой кнопкой мыши и выберите Применить к базе данных.
Перенос данных из BigQuery в Amazon Redshift с помощью агентов извлечения данных AWS SCT.
Агенты извлечения AWS SCT извлекают данные из исходной базы данных и переносят их в облако AWS. В этом пошаговом руководстве мы покажем, как настроить агенты извлечения AWS SCT для извлечения данных из BigQuery и миграции в Amazon Redshift.
Сначала установите агент извлечения AWS SCT на тот же экземпляр Windows, на котором установлен AWS SCT. Для повышения производительности мы рекомендуем использовать отдельный экземпляр Linux для установки агентов извлечения, если это возможно. Для больших наборов данных вы можете использовать несколько агентов извлечения данных, чтобы увеличить скорость переноса данных.
Создание доверия и хранилищ ключей (необязательно)
Вы можете использовать зашифрованную связь Secure Socket Layer (SSL) с экстракторами данных AWS SCT. При использовании SSL все данные, передаваемые между приложениями, остаются конфиденциальными и неотъемлемыми. Чтобы использовать связь SSL, необходимо создать хранилища доверия и ключей с помощью AWS SCT. Вы можете пропустить этот шаг, если не хотите использовать SSL. Мы рекомендуем использовать SSL для рабочих нагрузок.
Выполните следующие действия, чтобы создать хранилище доверия и ключей:
- В AWS SCT перейдите в «Настройки» → «Глобальные настройки» → «Безопасность».
- Выберите Создать доверие и хранилище ключей.

- Введите имя и пароль для хранилищ доверия и ключей и выберите место, где вы хотите их хранить.

- Выберите Порождать.
Установите и настройте агент извлечения данных
В установочном пакете для AWS SCT вы найдете агент подпапки (aws-schema-conversion-tool-1.0.latest.zipagents). Найдите и установите исполняемый файл с именем вроде aws-schema-conversion-tool-extractor-xxxxxxxx.msi.
В процессе установки выполните следующие действия, чтобы настроить AWS SCT Data Extractor:
- Что касается Порт прослушивания, введите номер порта, который прослушивает агент. По умолчанию это 8192.
- Что касается Добавить исходного поставщика, войти нет, так как вам не нужны драйверы для подключения к BigQuery.
- Что касается Добавьте драйвер Amazon Redshift., войти ДА.
- Что касается Введите файл или файлы драйвера Redshift JDBC., введите папку, в которую вы загрузили драйверы Amazon Redshift JDBC.
- Что касается Рабочая папкавведите путь, по которому агент извлечения данных AWS SCT будет хранить извлеченные данные. Рабочая папка может находиться на компьютере, отличном от компьютера агента, и одна рабочая папка может совместно использоваться несколькими агентами на разных компьютерах.
- Что касается Включить SSL-связь, войти Да. Выберите Нет здесь, если вы не хотите использовать SSL.
- Что касается Магазин ключей, введите место хранения, выбранное при создании хранилища доверия и ключей.
- Что касается Пароль хранилища ключей, введите пароль для хранилища ключей.
- Что касается Включить SSL-аутентификацию клиента, войти Да.
- Что касается Трастовый магазин, введите место хранения, выбранное при создании хранилища доверия и ключей.
- Что касается Пароль доверенного хранилища, введите пароль для хранилища доверенных сертификатов.
Запуск агентов извлечения данных
Используйте следующую процедуру для запуска экстрагирующих агентов. Повторите эту процедуру на каждом компьютере, на котором установлен агент извлечения.
Агенты извлечения действуют как слушатели. Когда вы запускаете агент с помощью этой процедуры, агент начинает слушать инструкции. Вы отправляете агентам инструкции по извлечению данных из вашего хранилища данных в следующем разделе.
Чтобы запустить агент извлечения, перейдите в каталог агента извлечения данных AWS SCT. Например, в Microsoft Windows дважды щелкните C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
- На компьютере с установленным агентом извлечения из командной строки или окна терминала выполните команду, указанную после вашей операционной системы.
- Чтобы проверить состояние агента, выполните ту же команду, но замените start на status.
- Чтобы остановить агент, выполните ту же команду, но замените start на stop.
- Чтобы перезапустить агент, запустите тот же файл RestartAgent.bat.
Зарегистрируйте агент извлечения данных
Выполните следующие действия, чтобы зарегистрировать агент извлечения данных:
- В AWS SCT измените представление на Представление переноса данных (другое) , а затем выбрать + Зарегистрироваться.
- Во вкладке подключения:

- Что касается Описание, введите имя для идентификации агента извлечения данных.
- Что касается Имя хоста, если вы установили агент извлечения данных на той же рабочей станции, что и AWS SCT, введите 0.0.0.0, чтобы указать локальный хост. В противном случае введите имя хоста компьютера, на котором установлен агент извлечения данных AWS SCT. Агенты извлечения данных рекомендуется устанавливать в Linux для повышения производительности.
- Что касается порт, введите номер, введенный для Порт прослушивания при установке агента извлечения данных AWS SCT.
- Установите флажок, чтобы использовать SSL (если используется SSL) для шифрования соединения AWS SCT с агентом извлечения данных.
- Если вы используете SSL, то на вкладке SSL:
- Что касается Доверительный магазин, выберите имя хранилища доверия, созданное при создание хранилищ доверия и ключей (при желании вы можете пропустить это, если подключение SSL не требуется).
- Что касается Магазин ключей, выберите имя хранилища ключей, созданное при создание хранилищ доверия и ключей (при желании вы можете пропустить это, если подключение SSL не требуется).

- Выберите Проверить подключение.
- После успешной проверки соединения выберите Зарегистрируйтесь.
Добавьте виртуальные разделы для больших таблиц (необязательно)
Вы можете использовать AWS SCT для создания виртуальных разделов для оптимизации производительности миграции. При создании виртуальных разделов AWS SCT параллельно извлекает данные для разделов. Мы рекомендуем создавать виртуальные разделы для больших таблиц.
Выполните следующие действия, чтобы создать виртуальные разделы:
- Отмените выбор всех объектов в представлении исходной базы данных в AWS SCT.
- Выберите таблицу, для которой вы хотите добавить виртуальное разделение.
- Щелкните правой кнопкой мыши по таблице и выберите Добавить виртуальный раздел.

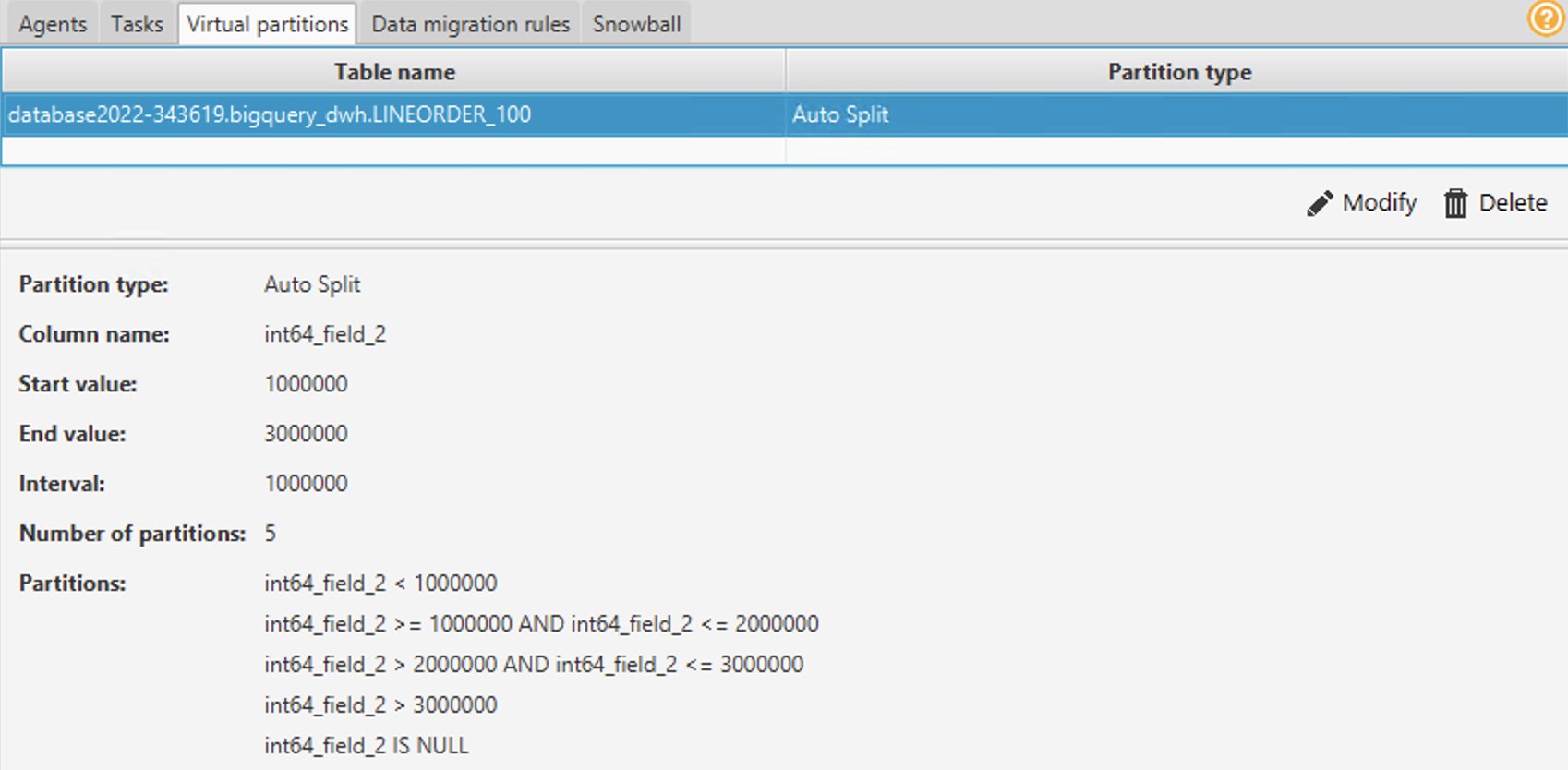
- Вы можете использовать разделы List, Range или Auto Split. Чтобы узнать больше о виртуальном разделении, см. Используйте виртуальное разделение в AWS SCT. В этом примере мы используем автоматическое разбиение на разделы, которое автоматически создает диапазонные разделы. Вы должны указать начальное значение, конечное значение и размер раздела. AWS SCT автоматически определяет разделы. Для демонстрации на столе Lineorder:
- Что касается Начальное значениевведите 1000000.
- Что касается Конечная стоимостьвведите 3000000.
- Что касается Интервал, введите 1000000, чтобы указать размер раздела.
- Выберите Хорошо.

Вы можете увидеть разделы, автоматически сгенерированные под Виртуальные разделы вкладка В этом примере AWS SCT автоматически создал следующие пять разделов для поля:
-
- >=1000000 и <=2000000
- > 2000000 и <= 3000000
- > 3000000
- НУЛЕВОЙ
Создайте локальную задачу миграции
Чтобы перенести данные из BigQuery в Amazon Redshift, создайте, запустите и отслеживайте локальную задачу миграции из AWS SCT. На этом шаге агент извлечения данных используется для переноса данных путем создания задачи.
Выполните следующие действия, чтобы создать локальную задачу миграции:
- В AWS SCT под именем схемы на левой панели щелкните правой кнопкой мыши Стандартные столы.
- Выберите Создать локальную задачу.

- Вы можете выбрать один из трех режимов миграции:
- Извлеките исходные данные и сохраните их на локальном ПК/виртуальной машине (ВМ), где работает агент.
- Извлеките данные и загрузите их в корзину S3.
- Выберите Извлечь загрузку и копирование, чтобы извлечь данные в корзину S3, а затем скопировать их в Amazon Redshift.

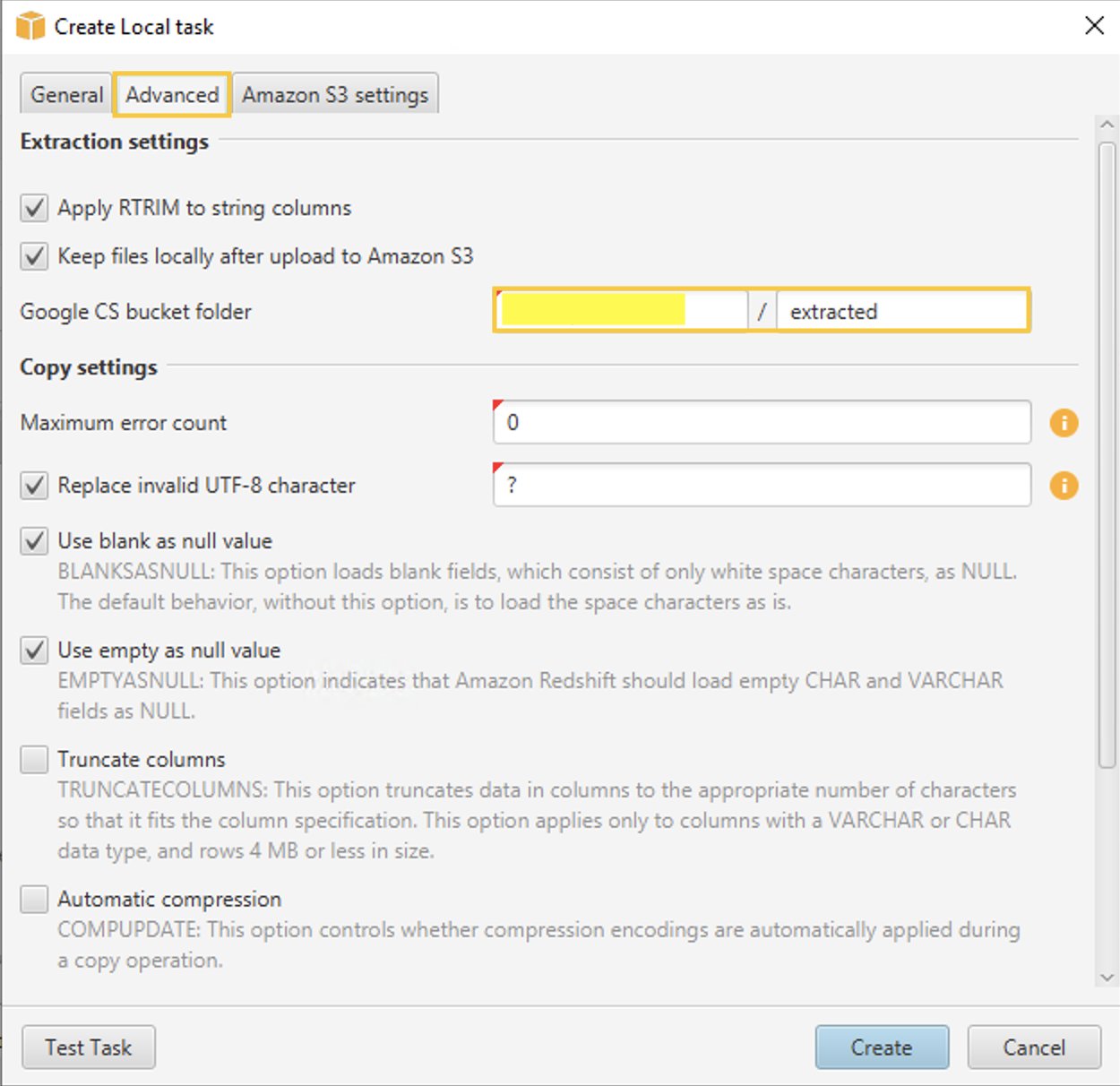
- В Фильтр вкладка, для Папка корзины Google CS войдите в корзину/папку Google Cloud Storage, созданную ранее в консоли управления GCP. AWS SCT хранит извлеченные данные в этом месте.
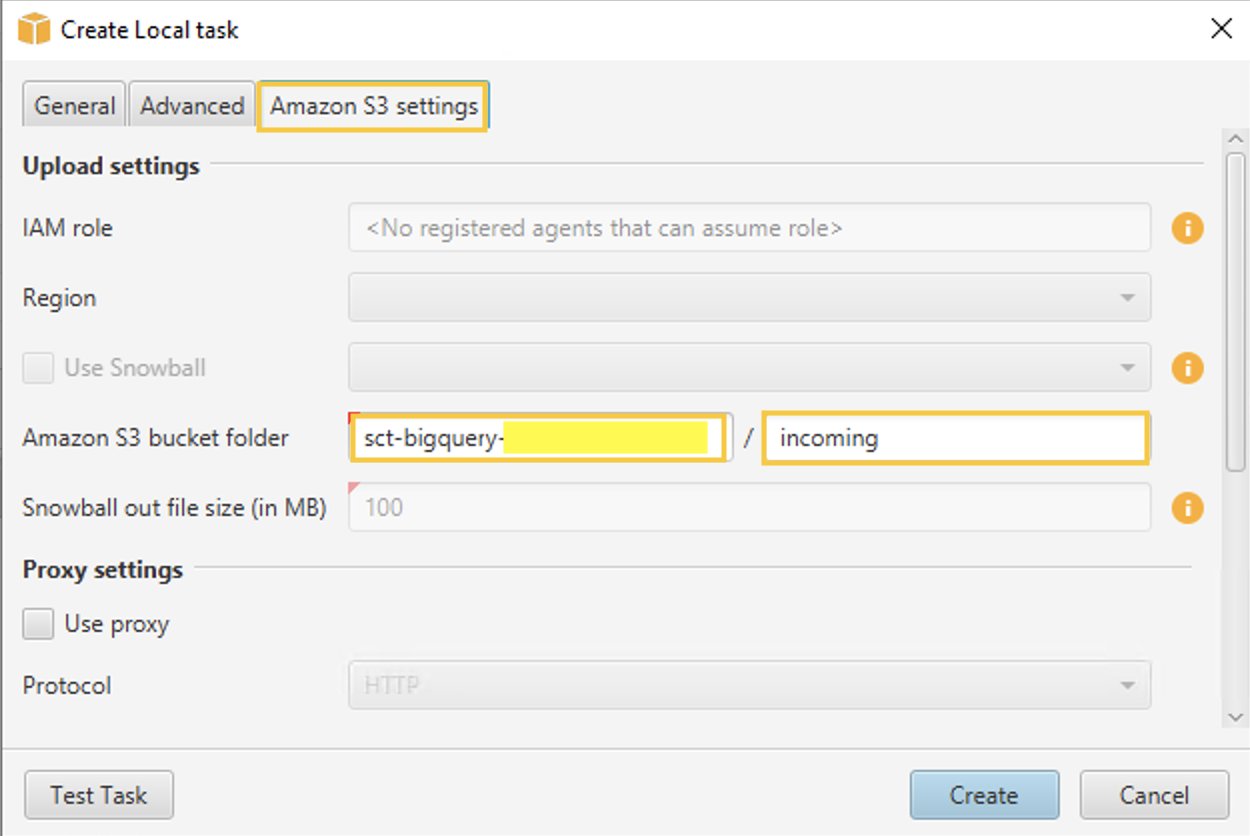
- В Настройки Amazon S3 вкладка, для папка корзины Amazon S3, укажите имена корзины и папки корзины S3, которую вы создали ранее. Агент извлечения данных AWS SCT загружает данные в корзину/папку S3 перед копированием в Amazon Redshift.
- Выберите Тестовое задание.
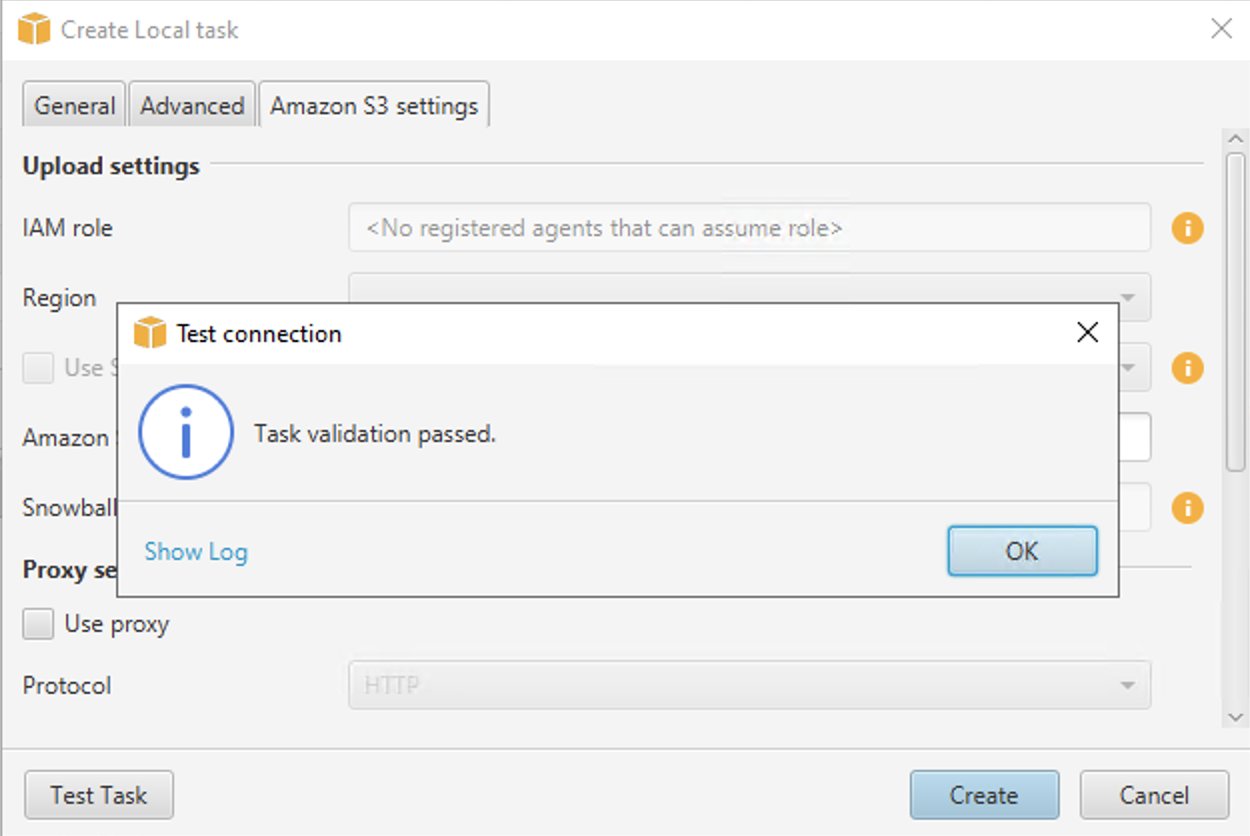
- После успешной проверки задачи выберите Создавай.
Запустите задачу переноса локальных данных
Чтобы начать задание, выберите Start в Задач меню.

- Сначала агент извлечения данных извлекает данные из BigQuery в корзину хранилища GCP.
- Затем агент загружает данные в Amazon S3 и запускает команду копирования для перемещения данных в Amazon Redshift.
- На данный момент AWS SCT успешно перенес данные из исходной таблицы BigQuery в таблицу Amazon Redshift.
Просмотр данных в Amazon Redshift
После успешного выполнения задачи переноса данных вы можете подключиться к Amazon Redshift и проверить данные.
Выполните следующие действия, чтобы проверить данные в Amazon Redshift:
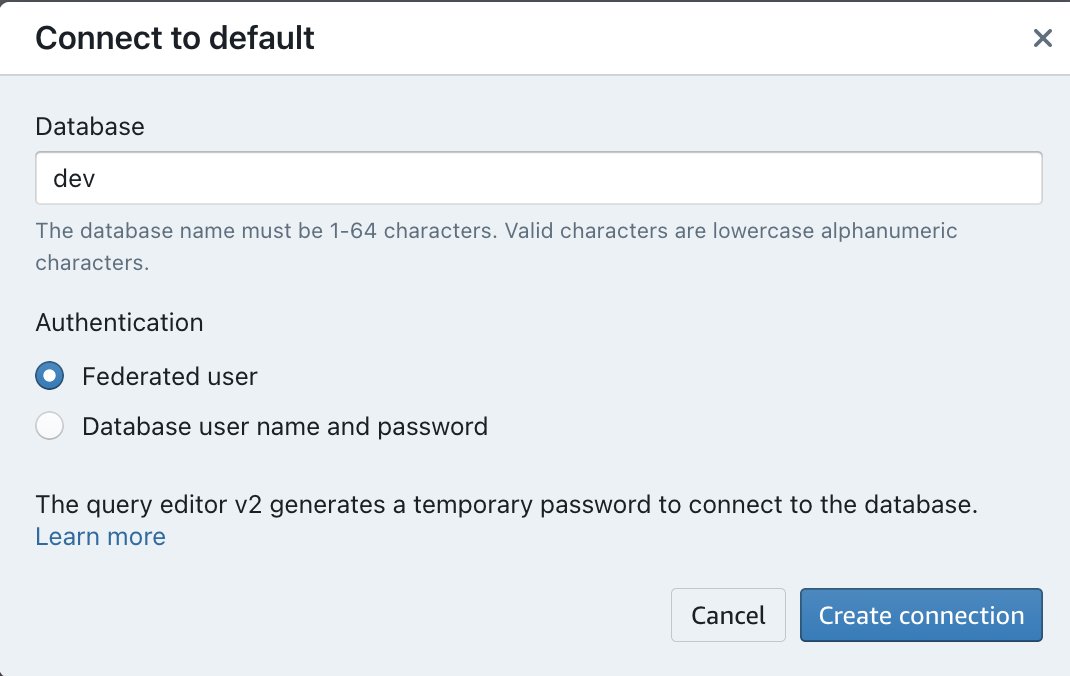
- Перейдите в Редактор запросов Amazon Redshift V2.
- Дважды щелкните имя созданной вами рабочей группы Amazon Redshift Serverless.
- Выберите Федеративный пользователь вариант в разделе «Аутентификация».
- Выберите Создать соединение.
- Создайте новый редактор, выбрав + значку.
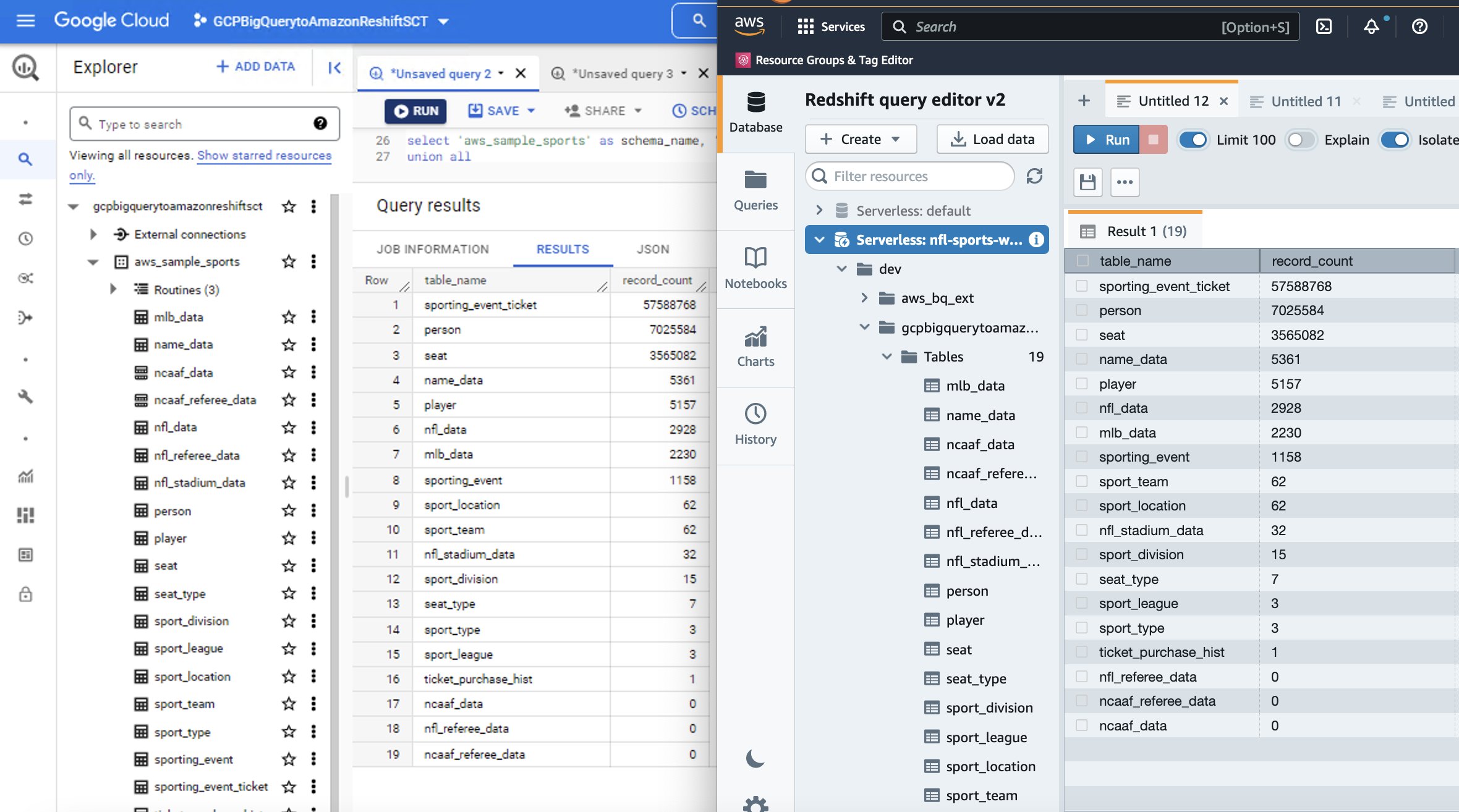
- В редакторе напишите запрос для выбора имени схемы и имени таблицы/представления, которые вы хотите проверить. Исследуйте данные, выполняйте специальные запросы и создавайте визуализации, диаграммы и представления.

Ниже приводится параллельное сравнение исходного BigQuery и целевого Amazon Redshift для набора спортивных данных, который мы использовали в этом пошаговом руководстве.
Очистите все ресурсы AWS, которые вы создали для этого упражнения.
Выполните следующие действия, чтобы завершить работу экземпляра EC2:
- Перейдите в Консоль Amazon EC2.
- На панели навигации выберите Экземпляры.
- Установите флажок для созданного экземпляра EC2.
- Выберите Состояние экземпляра, а затем Завершить экземпляр.
- Выберите прекратить при появлении запроса на подтверждение.
Выполните следующие действия, чтобы удалить рабочую группу и пространство имен Amazon Redshift Serverless.
- Перейдите в Бессерверная информационная панель Amazon Redshift.
- Под Пространства имен/рабочие группы, выберите созданное вами рабочее пространство.
- Под Действия, выберите Удалить рабочую группу.
- Установите флажок Удалите связанное пространство имен.
- Снимите галочку с Создайте окончательный снимок.
- Enter удалять в текстовом поле подтверждения удаления и выберите Удалить.

Выполните следующие действия, чтобы удалить корзину S3.
- Перейдите в Консоль Amazon S3.
- Выберите корзину, которую вы создали.
- Выберите Удалить.
- Для подтверждения удаления введите название корзины в поле ввода текста.
- Выберите Удалить сегмент.
Заключение
Миграция хранилища данных может быть трудным, сложным и, тем не менее, полезным проектом. AWS SCT упрощает миграцию хранилища данных. Следуя этому пошаговому руководству, вы сможете понять, как задача переноса данных извлекает, загружает, а затем переносит данные из BigQuery в Amazon Redshift. Решение, которое мы представили в этом посте, выполняет однократную миграцию объектов и данных базы данных. Изменения данных, сделанные в BigQuery во время переноса, не будут отражены в Amazon Redshift. Во время переноса данных приостановите свои задания ETL в BigQuery или повторно запустите ETL, указав Amazon Redshift после переноса. Рассмотрите возможность использования лучшие практики для AWS SCT.
У AWS SCT есть некоторые ограничения при использовании BigQuery в качестве источника. Например, AWS SCT не может преобразовывать подзапросы в аналитические функции, географические функции, статистические агрегатные функции и т. д. Полный список ограничений смотрите в Руководство пользователя AWS SCT. Мы планируем устранить эти ограничения в будущих выпусках. Несмотря на эти ограничения, вы можете использовать AWS SCT для автоматического преобразования большей части кода BigQuery и объектов хранилища.
Скачайте и установите AWS SCT, войдите в Консоль AWS, оформите заказ на Amazon Redshift Serverless и приступайте к миграции!
Об авторах
 Седрик Худи является архитектором решений, специализирующимся на миграции баз данных с использованием службы миграции базы данных AWS (DMS) и инструмента преобразования схемы AWS (SCT) в AWS.. Он работает над проблемами, связанными с миграцией БД. Он тесно сотрудничает с клиентами бизнес-сектора EdTech, Energy и ISV, чтобы помочь им реализовать истинный потенциал службы DMS. Он помог перенести сотни баз данных в облако AWS с помощью DMS и SCT.
Седрик Худи является архитектором решений, специализирующимся на миграции баз данных с использованием службы миграции базы данных AWS (DMS) и инструмента преобразования схемы AWS (SCT) в AWS.. Он работает над проблемами, связанными с миграцией БД. Он тесно сотрудничает с клиентами бизнес-сектора EdTech, Energy и ISV, чтобы помочь им реализовать истинный потенциал службы DMS. Он помог перенести сотни баз данных в облако AWS с помощью DMS и SCT.
 Амит Арора является архитектором решений, специализирующимся на базах данных и аналитике в AWS. Он работает с нашими клиентами в области финансовых технологий и глобальной энергетики, а также с сертифицированными партнерами AWS, предоставляя техническую помощь и разрабатывая клиентские решения по проектам миграции в облако, помогая клиентам перенести и модернизировать свои существующие базы данных в облако AWS.
Амит Арора является архитектором решений, специализирующимся на базах данных и аналитике в AWS. Он работает с нашими клиентами в области финансовых технологий и глобальной энергетики, а также с сертифицированными партнерами AWS, предоставляя техническую помощь и разрабатывая клиентские решения по проектам миграции в облако, помогая клиентам перенести и модернизировать свои существующие базы данных в облако AWS.
 Джагадиш Кумар является специалистом по аналитике, архитектором решений в AWS, специализирующимся на Amazon Redshift. Он глубоко увлечен архитектурой данных и помогает клиентам создавать масштабные аналитические решения на AWS.
Джагадиш Кумар является специалистом по аналитике, архитектором решений в AWS, специализирующимся на Amazon Redshift. Он глубоко увлечен архитектурой данных и помогает клиентам создавать масштабные аналитические решения на AWS.
 Ануша Чалла — старший специалист по аналитике, архитектор решений в AWS, специализирующийся на Amazon Redshift. Она помогла многим клиентам создать крупномасштабные решения для хранения данных в облаке и локально. Ануша увлечена аналитикой данных и наукой о данных и позволяет клиентам добиваться успеха в своих крупномасштабных проектах по работе с данными.
Ануша Чалла — старший специалист по аналитике, архитектор решений в AWS, специализирующийся на Amazon Redshift. Она помогла многим клиентам создать крупномасштабные решения для хранения данных в облаке и локально. Ануша увлечена аналитикой данных и наукой о данных и позволяет клиентам добиваться успеха в своих крупномасштабных проектах по работе с данными.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/migrate-google-bigquery-to-amazon-redshift-using-aws-schema-conversion-tool-sct/
- 1
- 10
- 100
- 9
- a
- О нас
- доступ
- Учетная запись
- Достигать
- Действие (Act):
- Действие
- действия
- дополнительный
- адрес
- Администратор
- После
- Агент
- агенты
- Все
- уже
- Amazon
- аналитический
- Аналитические фармацевтические услуги
- аналитика
- и
- Применение
- Приложения
- Применить
- архитектура
- ПЛОЩАДЬ
- оценки;
- Помощь
- связанный
- Аутентификация
- автоматический
- автоматически
- AWS
- Использование темпера с изогнутым основанием
- НИМ
- до
- польза
- Лучшая
- между
- большой
- Синии
- Коробка
- строить
- бизнес
- кнопка
- Может получить
- не могу
- возможности
- Пропускная способность
- Сертифицированные
- проблемы
- сложные
- изменение
- изменения
- Графики
- проверка
- Оформить заказ
- выбор
- Выберите
- Выбирая
- выбранный
- явно
- клиент
- тесно
- облако
- облачного хранения
- код
- лыжных шлемов
- Column
- Колонки
- Связь
- сравнение
- совместим
- полный
- комплекс
- сложность
- Вычисление
- компьютер
- компьютеры
- Конфигурация
- подтвердить
- Свяжитесь
- связи
- Коммутация
- связь
- Рассматривать
- последовательный
- Консоли
- содержит
- контрольная
- Конверсия
- конверсий
- конвертировать
- переделанный
- копирование
- Цена
- рентабельным
- Создайте
- создали
- создает
- Создающий
- кредит
- клиент
- Решения для клиентов
- Клиенты
- данным
- Анализ данных
- наука о данных
- обмен данными
- База данных
- базы данных
- Наборы данных
- Решение
- По умолчанию
- Спрос
- развертывание
- описывать
- описано
- Проект
- компьютера
- Несмотря на
- подробный
- определяет
- Диалог
- различный
- дисплеев
- распределение
- Dont
- скачать
- загрузок
- водитель
- драйверы
- в течение
- каждый
- Ранее
- Простой в использовании
- редактор
- усилие
- встроенный
- включить
- позволяет
- позволяет
- зашифрованный
- шифрование
- впритык
- Конечная точка
- энергетика
- Enter
- вошел
- Окружающая среда
- Эфир (ETH)
- оценивать
- пример
- Выполняет
- существующий
- Больше
- и, что лучший способ
- дополнительно
- извлечение
- Экстракты
- знакомый
- БЫСТРО
- быстрее
- несколько
- поле
- Файл
- Файлы
- окончательный
- в заключение
- финансовый
- финансовые технологии
- Найдите
- брандмауэр
- First
- Трансформируемость
- Фокус
- внимание
- следовать
- после
- следующим образом
- формат
- Бесплатно
- от
- полный
- Функции
- Более того
- будущее
- порождать
- генерируется
- генерирует
- география
- получить
- Глобальный
- Google Cloud
- Зелёная
- обрабатывать
- Аппаратные средства
- помощь
- помог
- помощь
- помогает
- здесь
- High
- основной момент
- очень
- держать
- Главная
- кашель
- ЧАСЫ
- Вилла / Бунгало
- Как
- How To
- Однако
- HTML
- HTTPS
- ICON
- определения
- Личность
- осуществлять
- in
- Увеличение
- указывать
- individual
- информация
- вход
- размышления
- устанавливать
- Установка
- пример
- инструкции
- рефлексологии
- Интегрируется
- взаимодействовать
- вмешивающийся
- вмешательство
- вопрос
- IT
- пункты
- работа
- Джобс
- JSON
- Основные
- Вид
- большой
- крупномасштабный
- последний
- запуск
- запускает
- слой
- УЧИТЬСЯ
- Lets
- уровень
- недостатки
- Linux
- Список
- Включенный в список
- Listening
- загрузка
- локальным
- расположение
- машина
- сделанный
- Главная
- Большинство
- сделать
- ДЕЛАЕТ
- управлять
- управление
- менеджер
- управления
- руководство
- вручную
- многих
- значимым
- средний
- Соответствует
- Меню
- методы
- Microsoft
- Microsoft Windows,
- может быть
- мигрировать
- миграция
- ML
- Модели
- Модерн
- модернизировать
- монитор
- БОЛЕЕ
- самых
- двигаться
- MSI
- с разными
- имя
- имена
- именования
- Откройте
- Навигация
- Необходимость
- Новые
- следующий
- примечательный
- номер
- объект
- объекты
- Предложения
- ONE
- Откроется
- операционный
- операционная система
- Оптимизировать
- Другое
- в противном случае
- пакет
- хлеб
- панель
- Параллельные
- партнеры
- Прошло
- страстный
- Пароль
- путь
- ОПЛАТИТЬ
- Вершина горы
- выполнять
- производительность
- выполняет
- план
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Точка
- возможное
- После
- потенциал
- практиками
- предсказуемый
- Predictions
- предпосылки
- представлены
- предварительно
- частная
- Процедуры
- процесс
- Производство
- FitPartner™
- Прогресс
- Проект
- проектов
- обеспечивать
- приводит
- положил
- вопрос
- быстро
- ассортимент
- реализовать
- рекомендовать
- рекомендаций
- Управление по борьбе с наркотиками (DEA)
- запись
- Red
- снижает
- отметила
- область
- зарегистрироваться
- Связанный
- публикации
- остатки
- повторять
- замещать
- заменить
- реплицируются
- отчету
- Отчеты
- представляет
- Запросы
- требовать
- обязательный
- упругий
- Полезные ресурсы
- награждение
- Богатые
- Щелкните правой кнопкой мыши
- Роли
- роли
- РЯД
- условиями,
- Run
- то же
- масштабируемые
- Шкала
- Весы
- масштабирование
- сканирование
- Наука
- Ученые
- скрипты
- легко
- секунды
- Раздел
- сектор
- безопасный
- безопасность
- выбор
- чувствительный
- Serverless
- обслуживание
- Услуги
- набор
- Наборы
- установка
- настройки
- несколько
- общие
- разделение
- должен
- показывать
- Шоу
- подпись
- просто
- одинарной
- Размер
- Снимок
- So
- Решение
- Решения
- некоторые
- Источник
- специалист
- скорость
- Расходы
- раскол
- Спорт
- SSL
- инсценировка
- Начало
- Начало
- начинается
- отчетность
- статистический
- статистика
- Статус:
- Шаг
- Шаги
- Stop
- диск
- магазин
- хранить
- магазины
- успех
- Успешно
- такие
- супер
- Коммутатор
- система
- ТАБЛИЦЫ
- взять
- принимает
- цель
- Сложность задачи
- Технический
- Технологии
- Терминал
- Ассоциация
- Источник
- их
- сторонние
- три
- время
- раз
- в
- терпимость
- инструментом
- инструменты
- традиционный
- Train
- Transform
- правда
- Доверие
- под
- лежащий в основе
- понимать
- созданного
- Применение
- использование
- Информация о пользователе
- пользователей
- VALIDATE
- подтверждено
- ценный
- ценностное
- Наши ценности
- продавец
- поставщики
- проверить
- версия
- Вид
- Просмотры
- Виртуальный
- прохождение
- предупреждение
- Web
- Что
- который
- в то время как
- Шире
- будете
- окна
- в
- без
- Рабочая группа
- работает
- работает
- рабочая станция
- бы
- записывать
- письменный
- ВАШЕ
- зефирнет