By Дэвид Вендт и Грегори Кимбалл
Эффективная обработка строковых данных жизненно важна для многих приложений по обработке и анализу данных. Чтобы извлечь ценную информацию из строковых данных, RAPIDS libcudf предоставляет мощные инструменты для ускорения преобразования строковых данных. libcudf — это библиотека C++ GPU DataFrame, используемая для загрузки, объединения, агрегирования и фильтрации данных.
В науке о данных строковые данные представляют речь, текст, генетические последовательности, регистрацию и многие другие типы информации. При работе со строковыми данными для машинного обучения и разработки функций данные часто необходимо нормализовать и преобразовывать, прежде чем их можно будет применить к конкретным вариантам использования. libcudf предоставляет как API общего назначения, так и утилиты на стороне устройства, позволяющие выполнять широкий спектр пользовательских строковых операций.
В этом посте показано, как умело преобразовывать строковые столбцы с помощью API общего назначения libcudf. Вы получите новые знания о том, как разблокировать максимальную производительность с помощью пользовательских ядер и утилит libcudf на стороне устройства. В этом посте также приведены примеры того, как лучше всего управлять памятью графического процессора и эффективно создавать столбцы libcudf для ускорения преобразования строк.
libcudf хранит строковые данные в памяти устройства, используя Формат стрелки, который представляет столбцы строк как два дочерних столбца: chars and offsets (Рис. 1).
Ассоциация chars столбец содержит строковые данные в виде символьных байтов в кодировке UTF-8, которые хранятся непрерывно в памяти.
Ассоциация offsets столбец содержит возрастающую последовательность целых чисел, которые представляют собой позиции байтов, определяющие начало каждой отдельной строки в массиве данных chars. Последний элемент смещения — это общее количество байтов в столбце символов. Это означает размер отдельной строки в строке i определяется как (offsets[i+1]-offsets[i]).
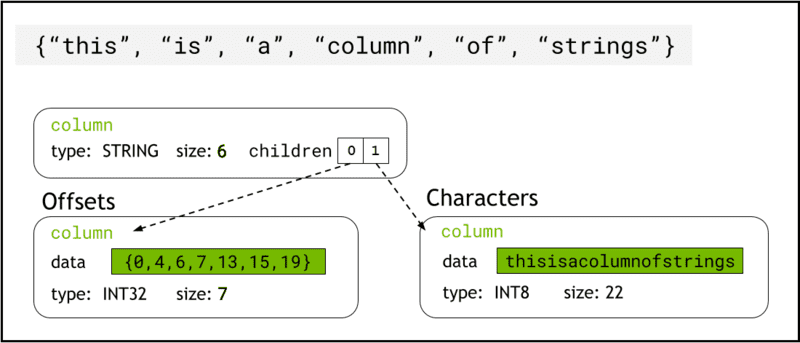 Рис. 1. Схема, показывающая, как формат Arrow представляет столбцы строк с
Рис. 1. Схема, показывающая, как формат Arrow представляет столбцы строк с chars и offsets дочерние столбцы
Чтобы проиллюстрировать пример преобразования строки, рассмотрим функцию, которая получает два столбца входных строк и создает один столбец отредактированных выходных строк.
Входные данные имеют следующий вид: столбец «имена», содержащий имена и фамилии, разделенные пробелом, и столбец «видимости», содержащий статус «общедоступный» или «частный».
Мы предлагаем функцию «редактировать», которая работает с входными данными для создания выходных данных, состоящих из первого инициала фамилии, за которым следует пробел и полное имя. Однако, если соответствующий столбец видимости является «частным», то выходная строка должна быть полностью отредактирована как «X X».
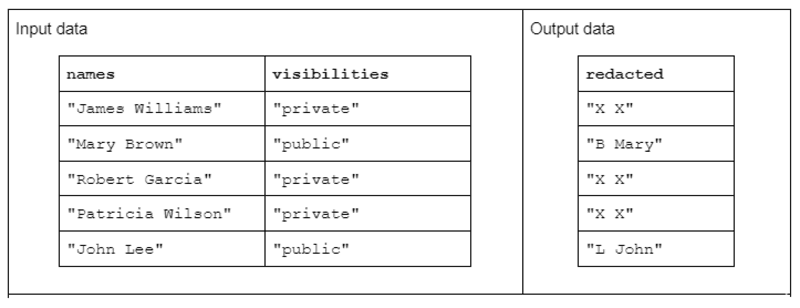 Таблица 1. Пример «редактируемого» преобразования строки, которое получает столбцы строк имен и видимости в качестве входных данных и частично или полностью отредактированные данные в качестве выходных данных.
Таблица 1. Пример «редактируемого» преобразования строки, которое получает столбцы строк имен и видимости в качестве входных данных и частично или полностью отредактированные данные в качестве выходных данных.
Во-первых, преобразование строки может быть выполнено с помощью API строк libcudf. API общего назначения является отличной отправной точкой и хорошей отправной точкой для сравнения производительности.
Функции API работают со всем столбцом строк, запуская как минимум одно ядро для каждой функции и назначая один поток для каждой строки. Каждый поток обрабатывает одну строку данных параллельно через GPU и выводит одну строку как часть нового выходного столбца.
Чтобы выполнить пример функции редактирования с помощью API общего назначения, выполните следующие действия.
- Преобразуйте столбец строк «visibility» в логический столбец, используя
contains - Создайте новый столбец строк из столбца имен, скопировав «XX» всякий раз, когда соответствующая запись строки в логическом столбце имеет значение «false».
- Разделите столбец «отредактировано» на столбцы с именем и фамилией.
- Нарежьте первый символ фамилий как инициалы фамилии
- Создайте выходной столбец, объединив столбец последних инициалов и столбец имен с разделителем пробела ("").
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Этот подход занимает около 3.5 мс на A6000 с 600 тыс. строк данных. В этом примере используется contains, copy_if_else, split, slice_strings и concatenate для выполнения пользовательского преобразования строки. Профилирующий анализ с Энсайт Системы показывает, что split функция занимает наибольшее количество времени, а затем slice_strings и concatenate.
На рис. 2 показаны данные профилирования от Nsight Systems для исправленного примера, демонстрирующие сквозную обработку строк со скоростью до ~600 миллионов элементов в секунду. Области соответствуют диапазонам NVTX, связанным с каждой функцией. Светло-голубые диапазоны соответствуют периодам работы ядер CUDA.
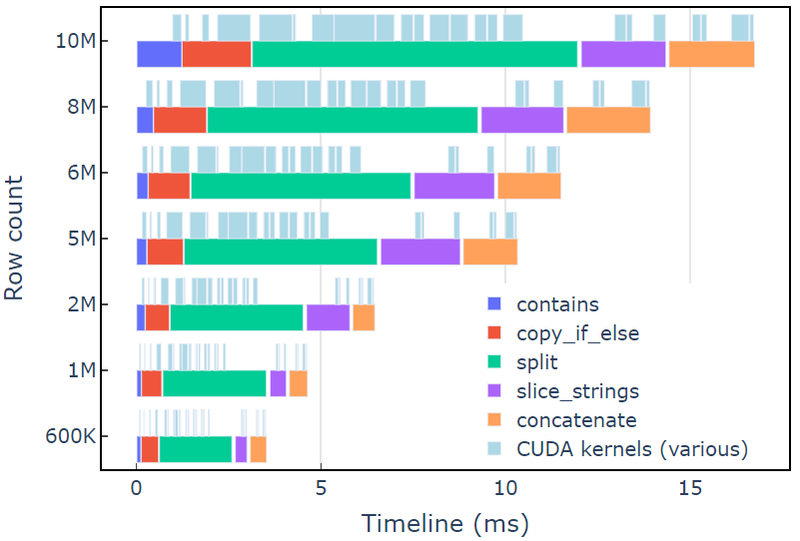 Рис. 2. Данные профилирования от Nsight Systems для примера редактирования
Рис. 2. Данные профилирования от Nsight Systems для примера редактирования
API libcudf strings — это быстрый и эффективный набор инструментов для преобразования строк, но иногда функции, критически важные для производительности, должны работать еще быстрее. Ключевым источником дополнительной работы в API libcudf strings является создание по крайней мере одного нового столбца strings в глобальной памяти устройства для каждого вызова API, что открывает возможность объединить несколько вызовов API в пользовательское ядро.
Ограничения производительности в вызовах malloc ядра
Во-первых, мы создадим собственное ядро для реализации преобразования примера редактирования. При проектировании этого ядра мы должны помнить, что столбцы строк libcudf неизменяемы.
Столбцы строк не могут быть изменены на месте, потому что байты символов хранятся непрерывно, и любые изменения длины строки сделают недействительными данные смещения. Следовательно redact_kernel пользовательское ядро генерирует новый столбец строк, используя фабрику столбцов libcudf для построения обоих offsets и chars дочерние столбцы.
В этом первом подходе выходная строка для каждой строки создается в динамическая память устройства используя вызов malloc внутри ядра. Пользовательский вывод ядра представляет собой вектор указателей устройств на каждый вывод строки, и этот вектор служит входом для фабрики строковых столбцов.
Пользовательское ядро принимает cudf::column_device_view для доступа к данным столбца строк и использует element метод для возврата cudf::string_view представляющие строковые данные по указанному индексу строки. Выход ядра представляет собой вектор типа cudf::string_view который содержит указатели на память устройства, содержащую выходную строку и размер этой строки в байтах.
Ассоциация cudf::string_view похож на класс std::string_view, но реализован специально для libcudf и переносит символьные данные фиксированной длины в память устройства, закодированные как UTF-8. Он имеет много одинаковых функций (find и substr функции, например) и ограничения (отсутствие нулевого терминатора) в качестве std аналог. А cudf::string_view представляет последовательность символов, хранящуюся в памяти устройства, поэтому мы можем использовать ее здесь для записи памяти, выделенной malloc, для выходного вектора.
Ядро Маллока
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Это может показаться разумным подходом, пока не будет измерена производительность ядра. Этот подход занимает около 108 мс на A6000 с 600 тыс. строк данных — более чем в 30 раз медленнее, чем решение, представленное выше с использованием API строк libcudf.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Основным узким местом является malloc/free вызовы внутри двух ядер здесь. Для динамической памяти устройства CUDA требуется malloc/free вызовы в ядре для синхронизации, в результате чего параллельное выполнение вырождается в последовательное выполнение.
Предварительное выделение рабочей памяти для устранения узких мест
Устранить malloc/free узкое место, заменив malloc/free вызовы ядра с предварительно выделенной рабочей памятью перед запуском ядра.
Для примера редактирования выходной размер каждой строки в этом примере не должен превышать размер самой входной строки, поскольку логика удаляет только символы. Следовательно, можно использовать один буфер памяти устройства того же размера, что и входной буфер. Используйте входные смещения, чтобы найти положение каждой строки.
Доступ к смещениям столбца строк включает перенос cudf::column_view с cudf::strings_column_view и называя его offsets_begin метод. Размер chars дочерний столбец также можно получить с помощью chars_size метод. Затем rmm::device_uvector предварительно выделяется перед вызовом ядра для хранения выходных данных символов.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Предварительно выделенное ядро
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Ядро выводит вектор cudf::string_view объекты, которые передаются cudf::make_strings_column заводская функция. Второй параметр этой функции используется для идентификации нулевых записей в выходном столбце. В примерах в этом посте нет нулевых записей, поэтому заполнитель nullptr cudf::string_view{nullptr,0} используется.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Этот подход занимает около 1.1 мс на A6000 с 600 тыс. строк данных и, следовательно, превосходит базовый уровень более чем в 2 раза. Примерная разбивка показана ниже:
redact_kernel 66us make_strings_column 400us
Остальное время проводится в cudaMalloc, cudaFree, cudaMemcpy, что типично для накладных расходов на управление временными экземплярами rmm::device_uvector. Этот метод работает хорошо, если все выходные строки гарантированно имеют тот же размер или меньше, что и входные строки.
В целом, переход на массовое выделение рабочей памяти с помощью RAPIDS RMM является значительным улучшением и хорошим решением для функции пользовательских строк.
Оптимизация создания столбцов для ускорения вычислений
Есть ли способ улучшить это еще больше? Узким местом в настоящее время является cudf::make_strings_column фабричная функция, которая создает компоненты столбца с двумя строками, offsets и chars, от вектора cudf::string_view объекты.
В libcudf включено множество фабричных функций для построения строковых столбцов. Фабричная функция, использованная в предыдущих примерах, принимает cudf::device_span of cudf::string_view объекты, а затем строит столбец, выполняя gather на базовых символьных данных для построения смещений и дочерних столбцов символов. А rmm::device_uvector автоматически конвертируется в cudf::device_span без копирования каких-либо данных.
Однако если вектор символов и вектор смещений строятся напрямую, то можно использовать другую фабричную функцию, которая просто создает столбец строк, не требуя сбора для копирования данных.
Ассоциация sizes_kernel делает первый проход по входным данным, чтобы вычислить точный выходной размер каждой выходной строки:
Оптимизированное ядро: часть 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Затем выходные размеры преобразуются в смещения путем выполнения операции на месте. exclusive_scan, Обратите внимание, что offsets вектор был создан с names.size()+1 элементы. Последней записью будет общее количество байтов (все размеры суммированы вместе), а первой записью будет 0. Оба они обрабатываются exclusive_scan вызов. Размер chars столбец извлекается из последней записи offsets столбец для построения вектора символов.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
Ассоциация redact_kernel логика почти такая же, за исключением того, что она принимает вывод d_offsets вектор для определения выходного местоположения каждой строки:
Оптимизированное ядро: часть 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Размер вывода d_chars столбец извлекается из последней записи d_offsets столбец для размещения вектора символов. Ядро запускается с предварительно вычисленным вектором смещений и возвращает заполненный вектор символов. Наконец, фабрика столбцов строк libcudf создает столбцы выходных строк.
Эта cudf::make_strings_column фабричная функция строит столбец строк, не создавая копию данных. offsets данные и chars данные уже находятся в правильном ожидаемом формате, и эта фабрика просто перемещает данные из каждого вектора и создает вокруг него структуру столбцов. После завершения rmm::device_uvectors для offsets и chars пусты, их данные были перемещены в выходной столбец.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Этот подход занимает около 300 мкс (0.3 мс) на A6000 с 600 2 строками данных и улучшается по сравнению с предыдущим подходом более чем в XNUMX раза. Вы можете заметить, что sizes_kernel и redact_kernel во многом используют ту же логику: один раз для измерения размера выходных данных, а затем еще раз для заполнения выходных данных.
С точки зрения качества кода полезно реорганизовать преобразование как функцию устройства, вызываемую как размерами, так и ядром редактирования. С точки зрения производительности вы можете быть удивлены, увидев, что вычислительные затраты на преобразование оплачиваются дважды.
Преимущества управления памятью и более эффективного создания столбцов часто перевешивают вычислительные затраты на двукратное выполнение преобразования.
В таблице 2 показано время вычислений, количество ядер и байты, обработанные для четырех решений, обсуждаемых в этом посте. «Общее количество запусков ядра» отражает общее количество запущенных ядер, включая вычислительные и вспомогательные ядра. «Общее количество обработанных байтов» — это совокупная пропускная способность чтения и записи DRAM, а «минимальное количество обработанных байтов» — это в среднем 37.9 байта на строку для наших тестовых входных и выходных данных. Идеальный случай «ограничения пропускной способности памяти» предполагает пропускную способность 768 ГБ/с, теоретическую пиковую пропускную способность A6000.
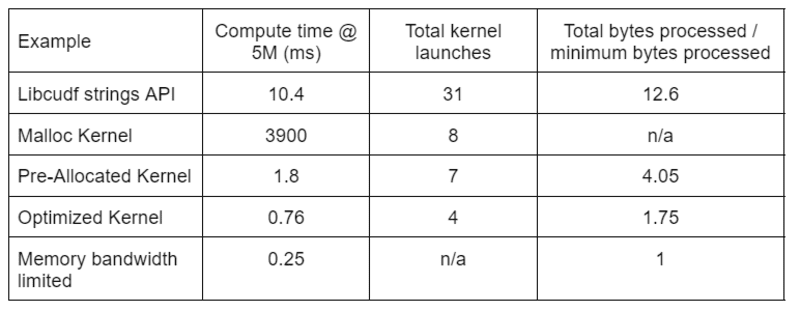 Таблица 2. Время вычислений, количество ядер и байты, обработанные для четырех решений, обсуждаемых в этом посте
Таблица 2. Время вычислений, количество ядер и байты, обработанные для четырех решений, обсуждаемых в этом посте
«Оптимизированное ядро» обеспечивает наибольшую пропускную способность из-за меньшего количества запусков ядра и меньшего количества обрабатываемых байтов. С эффективными пользовательскими ядрами общее количество запусков ядра снижается с 31 до 4, а общее количество обработанных байтов — с 12.6 до 1.75 от размера ввода плюс вывода.
В результате пользовательское ядро обеспечивает более чем в 10 раз более высокую пропускную способность, чем API строк общего назначения для преобразования редактирования.
Ресурс памяти пула в Диспетчер памяти RAPIDS (RMM) — это еще один инструмент, который вы можете использовать для повышения производительности. В приведенных выше примерах используется «ресурс памяти CUDA» по умолчанию для выделения и освобождения глобальной памяти устройства. Однако время, необходимое для выделения рабочей памяти, увеличивает задержку между этапами преобразования строк. «Ресурс памяти пула» в RMM уменьшает задержку, выделяя большой пул памяти заранее и назначая подраспределения по мере необходимости во время обработки.
С ресурсом памяти CUDA «Оптимизированное ядро» показывает ускорение в 10-15 раз, которое начинает снижаться при увеличении количества строк из-за увеличения размера выделения (рис. 3). Использование ресурса памяти пула смягчает этот эффект и поддерживает ускорение в 15-25 раз по сравнению с подходом API строк libcudf.
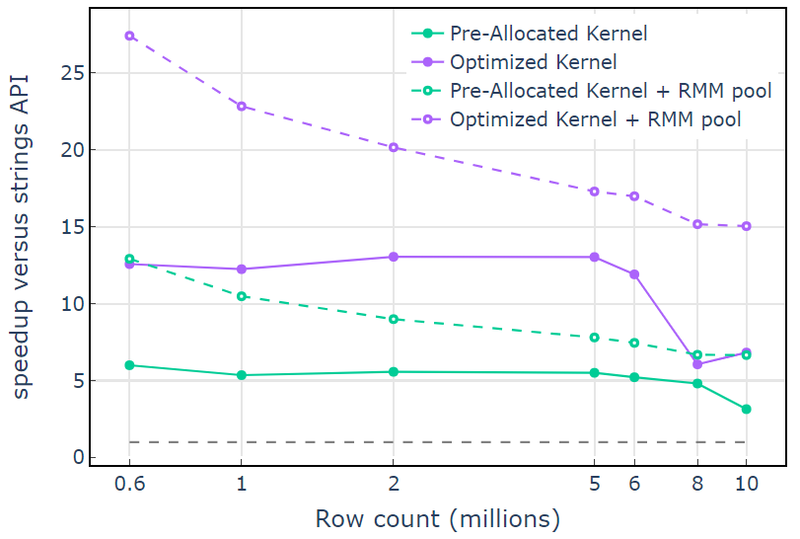 Рис. 3. Ускорение за счет пользовательских ядер «Предварительно выделенное ядро» и «Оптимизированное ядро» с ресурсом памяти CUDA по умолчанию (закрашено) и ресурсом памяти пула (пунктиром) по сравнению со строковым API libcudf, использующим ресурс памяти CUDA по умолчанию
Рис. 3. Ускорение за счет пользовательских ядер «Предварительно выделенное ядро» и «Оптимизированное ядро» с ресурсом памяти CUDA по умолчанию (закрашено) и ресурсом памяти пула (пунктиром) по сравнению со строковым API libcudf, использующим ресурс памяти CUDA по умолчанию
С ресурсом памяти пула демонстрируется сквозная пропускная способность памяти, приближающаяся к теоретическому пределу для двухпроходного алгоритма. «Оптимизированное ядро» достигает пропускной способности 320–340 ГБ/с, измеренной с использованием размера входных данных, размера выходных данных и времени вычислений (рис. 4).
Двухпроходный подход сначала измеряет размеры выходных элементов, выделяет память, а затем устанавливает память с выходами. Учитывая двухпроходный алгоритм обработки, реализация в «Оптимизированном ядре» работает почти на пределе пропускной способности памяти. «Сквозная пропускная способность памяти» определяется как входной плюс выходной размер в ГБ, разделенный на время вычислений. *Пропускная способность памяти RTX A6000 (768 ГБ/с).
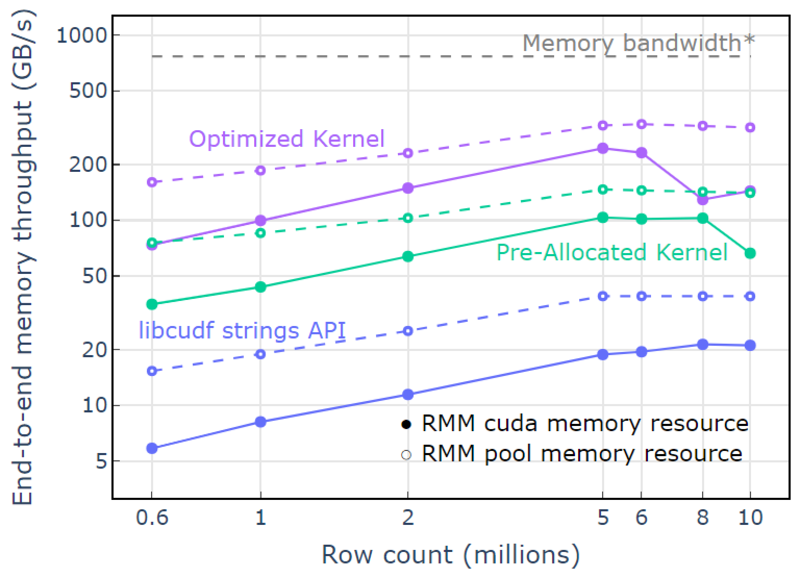 Рисунок 4. Пропускная способность памяти для «Оптимизированного ядра», «Предварительно выделенного ядра» и «API libcudf strings» в зависимости от количества строк ввода/вывода
Рисунок 4. Пропускная способность памяти для «Оптимизированного ядра», «Предварительно выделенного ядра» и «API libcudf strings» в зависимости от количества строк ввода/вывода
Этот пост демонстрирует два подхода к написанию эффективных преобразований строковых данных в libcudf. API общего назначения libcudf является быстрым и простым для разработчиков и обеспечивает хорошую производительность. libcudf также предоставляет утилиты на стороне устройства, предназначенные для использования с пользовательскими ядрами, в этом примере обеспечивающие более чем 10-кратное повышение производительности.
Примените свои знания
Чтобы начать работу с RAPIDS cuDF, посетите рапидсай/кудф Репозиторий GitHub. Если вы еще не пробовали cuDF и libcudf для своих рабочих нагрузок обработки строк, мы рекомендуем вам протестировать последнюю версию. Докерные контейнеры предоставляются как для релизов, так и для ночных сборок. Конда пакеты также доступны для упрощения тестирования и развертывания. Если вы уже используете cuDF, мы рекомендуем вам запустить пример преобразования новых строк, посетив Rapidsai/cudf/дерево/HEAD/cpp/примеры/строки на GitHub.
Дэвид Вендт — старший системный инженер-программист в NVIDIA, разрабатывающий код C++/CUDA для RAPIDS. Дэвид имеет степень магистра электротехники Университета Джона Хопкинса.
Грегори Кимбалл — менеджер по разработке программного обеспечения в NVIDIA, работающий в команде RAPIDS. Грегори возглавляет разработку libcudf, библиотеки CUDA/C++ для обработки столбцовых данных, на основе которой работает RAPIDS cuDF. Грегори имеет докторскую степень по прикладной физике Калифорнийского технологического института.
Оригинал, Перемещено с разрешения.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- О нас
- выше
- ускоряющий
- Принимает
- доступ
- Доступ
- выполнено
- через
- добавленный
- Добавляет
- алгоритм
- Все
- выделяет
- распределение
- уже
- количество
- анализ
- и
- Другой
- апаш
- API
- API
- Приложения
- прикладной
- подхода
- подходы
- приближается
- около
- массив
- связанный
- автоматический
- автоматически
- доступен
- в среднем
- Пропускная способность
- Базовая линия
- , так как:
- до
- не являетесь
- ниже
- полезный
- Преимущества
- ЛУЧШЕЕ
- между
- Синии
- Breakdown
- буфер
- строить
- Строительство
- строит
- построенный
- C + +
- Калифорния
- призывают
- под названием
- вызова
- Объявления
- не могу
- случаев
- случаев
- Причинение
- изменения
- персонаж
- символы
- ребенок
- класс
- Закрыть
- код
- Column
- Колонки
- объединять
- сравнив
- полный
- Заполненная
- компоненты
- вычисление
- Вычисление
- Рассматривать
- Состоящий из
- строить
- содержит
- конвертировать
- переделанный
- копирование
- соответствующий
- Цена
- Создайте
- создали
- создает
- создание
- изготовленный на заказ
- данным
- обработка данных
- наука о данных
- Давид
- По умолчанию
- Степень
- обеспечивает
- убивают
- развертывание
- предназначенный
- проектирование
- застройщиков
- развивающийся
- Развитие
- устройство
- различный
- непосредственно
- обсуждается
- Разделенный
- Docker
- Падение
- в течение
- динамический
- каждый
- легче
- эффект
- эффективный
- эффективно
- электротехника
- элементы
- ликвидировать
- включить
- поощрять
- впритык
- инженер
- Проект и
- Весь
- запись
- Эфир (ETH)
- Даже
- многое
- пример
- Примеры
- отлично
- Кроме
- выполнение
- ожидаемый
- и, что лучший способ
- дополнительно
- извлечение
- завод
- БЫСТРО
- быстрее
- Особенность
- Особенности
- фигура
- фильтрация
- окончательный
- в заключение
- First
- фиксированной
- следовать
- следует
- после
- форма
- формат
- Бесплатно
- часто
- от
- передний
- полностью
- функция
- Функции
- далее
- Gain
- Общие
- генерирует
- получить
- GitHub
- данный
- Глобальный
- хорошо
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- гарантированный
- Ручки
- имеющий
- здесь
- высший
- наивысший
- имеет
- Как
- How To
- Однако
- HTML
- HTTPS
- идеальный
- идентифицирующий
- неизменный
- осуществлять
- реализация
- в XNUMX году
- улучшать
- улучшение
- улучшается
- in
- включены
- В том числе
- Увеличение
- повышение
- индекс
- individual
- информация
- начальный
- вход
- Институт
- в нашей внутренней среде,
- IT
- саму трезвость
- Johns Hopkins
- Университет Джонса Хопкинса
- присоединение
- КДнаггетс
- Сохранить
- Основные
- знания
- этикетка
- большой
- больше
- Фамилия
- Задержка
- последний
- последний релиз
- запустили
- запускает
- запуск
- Лиды
- изучение
- Длина
- Библиотека
- легкий
- ОГРАНИЧЕНИЯ
- недостатки
- погрузка
- расположение
- машина
- обучение с помощью машины
- Главная
- поддерживает
- сделать
- ДЕЛАЕТ
- Создание
- управлять
- управление
- менеджер
- управления
- многих
- мастер
- Освоение
- Совпадение
- означает
- проводить измерение
- меры
- Память
- метод
- может быть
- миллиона
- против
- БОЛЕЕ
- более эффективным
- движется
- MS
- с разными
- имя
- имена
- Необходимость
- необходимый
- Новые
- номер
- Nvidia
- объекты
- смещение
- ONE
- открытие
- работать
- работает
- Операционный отдел
- Возможность
- Другое
- выплачен
- Параллельные
- параметр
- часть
- Прошло
- Вершина горы
- производительность
- выполнения
- выполняет
- периодов
- разрешение
- перспектива
- Физика
- Часть
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плюс
- Точка
- бассейн
- населенный
- должность
- позиции
- После
- мощный
- полномочия
- предыдущий
- обработка
- производит
- профилирование
- предлагает
- при условии
- приводит
- что такое варган?
- цель
- ассортимент
- доходит до
- Читать
- разумный
- получает
- запись
- Цена снижена
- снижает
- Рефакторинг
- отражает
- районы
- освободить
- публикации
- осталось
- представляющий
- представляет
- ресурс
- результат
- возвращают
- Возвращает
- РЯД
- Run
- Бег
- то же
- Наука
- Во-вторых
- старший
- Последовательность
- служит
- Наборы
- Поделиться
- должен
- показанный
- Шоу
- значительный
- аналогичный
- просто
- с
- одинарной
- Размер
- Размеры
- меньше
- So
- Software
- Инженер-программист
- разработка программного обеспечения
- твердый
- Решение
- Решения
- Источник
- Space
- конкретный
- конкретно
- указанный
- речь
- скорость
- потраченный
- раскол
- Начало
- и политические лидеры
- Начало
- Статус:
- Шаги
- По-прежнему
- магазин
- хранить
- магазины
- простой
- поток
- Структура
- удивлен
- системы
- принимает
- команда
- Технологии
- временный
- тестXNUMX
- Тестирование
- Ассоциация
- их
- теоретический
- следовательно
- Через
- пропускная способность
- время
- в
- вместе
- инструментом
- Инструментарий
- инструменты
- Всего
- Transform
- трансформация
- преобразований
- преобразован
- превращение
- tv
- Типы
- типичный
- лежащий в основе
- Университет
- отпереть
- отпирающий
- us
- использование
- коммунальные услуги
- ценный
- Ценная информация
- Против
- видимость
- видимый
- жизненный
- который
- в то время как
- широкий
- Широкий диапазон
- будете
- в
- без
- Работа
- работает
- работает
- бы
- записывать
- письмо
- X
- ВАШЕ
- зефирнет










