Оптическое распознавание символов (OCR), метод преобразования рукописных / печатных текстов в машинно-кодированный текст, всегда было основной областью исследований в области компьютерного зрения из-за его многочисленных приложений в различных областях: банки используют OCR для сравнения утверждений; Правительства используют OCR для сбора отзывов об опросах.

Из-за разнообразия стилей почерка и печатного текста, недавние подходы к OCR включают глубокое обучение для повышения точности. Поскольку для глубокого обучения требуются огромные объемы данных для обучения моделей, такие компании, как Google, получают многообещающие результаты с помощью своих служб OCR.
В этой статье подробно рассказывается о Google Vision OCR, включая простое руководство по python, диапазон приложений, цены и другие альтернативы.
- Что такое Google Cloud Vision OCR?
- Простой учебник
- Почему OCR?
- Примеры использования
- Цены
- Основные особенности Google Cloud Vision OCR
- альтернативы
- Общие вопросы
Что такое Google Cloud Vision?

Google Cloud Vision OCR - это часть API Google Cloud Vision для извлечения текста из изображений. В частности, есть две аннотации, помогающие распознавать символы:
- Текст_Аннотация: Он извлекает и выводит машинно-кодированный текст из любого изображения (например, фотографий уличных пейзажей или пейзажей). Поскольку изначально она была разработана для использования в различных условиях освещения, модель в некотором смысле более устойчива при чтении слов разных стилей, но только на более разреженном уровне. Возвращенный файл JSON включает в себя все строки, а также отдельные слова и соответствующие им ограничивающие рамки.
- Документ_Текст_Аннотация: Это особенно разработано для плотно представленных текстовых документов (например, отсканированных книг). Таким образом, хотя он поддерживает чтение небольших и более сжатых текстов, он менее адаптируется к изображениям в естественных условиях. Такая информация, как абзацы, блоки и разрывы, включается в выходной файл JSON.
Ищете решение OCR, которое преодолевает недостатки Google Cloud Vision или зональное ОКР? Дайте Нанонет™ вращение для более высокой точности, большей гибкости и более широких типов документов!
Простой учебник
В следующем разделе представлено простое руководство по началу работы с Google Vision API, в частности о том, как использовать его для службы Google Cloud Vision OCR.
Простой обзор
Идея, лежащая в основе этого, очень интуитивно понятна и проста.
1) По сути, вы отправляете изображение (удаленное или из локального хранилища) в Google Cloud Vision API.
2) Изображение обрабатывается удаленно в Google Cloud и создает соответствующие форматы JSON в соответствии с вызванной вами функцией.
3) Файл JSON возвращается как результат после вызова функции.
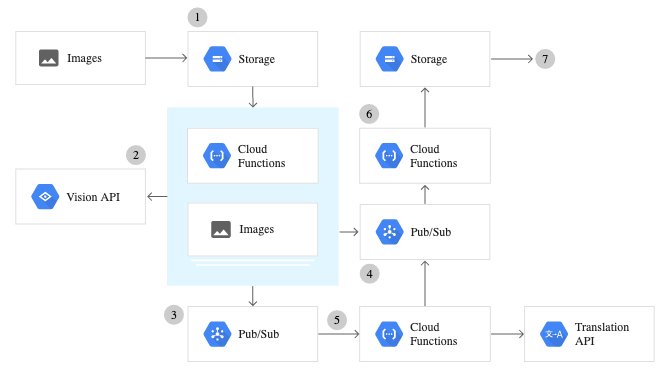
Настройка Google Cloud Vision API
Чтобы использовать любые сервисы, предоставляемые Google Vision API, необходимо настроить Google Cloud Console и выполнить ряд шагов для аутентификации. Ниже приводится пошаговый обзор того, как настроить всю службу Vision API.
- Создайте проект в Google Cloud Console. Чтобы начать использовать любую службу Vision, необходимо создать проект. В проекте организованы такие ресурсы, как сотрудники, API и информация о ценах.
- Включить биллинг - чтобы включить Vision API, вы должны сначала включить биллинг для своего проекта. Детали ценообразования будут рассмотрены в следующих разделах.
- Включить Vision API
- Создать учетную запись службы - создайте учетную запись службы и установите ссылку на созданный проект, затем создайте ключ учетной записи службы. Ключ будет выведен и загружен на ваш компьютер в виде файла JSON.
- Настройка переменной среды GOOGLE_APPLICATION_CREDENTIALS; Чтобы настроить эту переменную среды, запустите ее на Mac/Linux или Windows.
- Блоки кода для Mac / Linux
- Блоки кода для Windows
Более подробную процедуру вышеупомянутых шагов можно найти в официальной документации, предоставленной Google Cloud здесь:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Простая функция распознавания текста Google Vision в Python
API Google Cloud Vision работает с множеством популярных языков, от Java, Node.js, Python до собственного языка Google Go. Для простоты мы вводим простой метод вызова в Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Другими словами, метод последовательно вызывает функцию text_annotation, затем извлеките ответы и распечатайте информацию. document_text_annotation также может быть вызван тем же способом для извлечения плотных текстов. Можно также обнаруживать изображения удаленно, установив изображение через:
image.source.image_uri = uriгде uri — это uri изображения.
Более подробную информацию о кодах можно найти здесь:
https://cloud.google.com/vision
Ищете решение OCR, которое преодолевает недостатки Google Cloud Vision? Даешь нанонеты™ вращение для более высокой точности, большей гибкости и более широких типов документов!
Предлагаемый уровень производительности
Чтобы помочь в дальнейшем анализе данных текста, две функции Google OCR предоставляют пользователям различные уровни вывода: для text_annotation, как целые строки (если Google рассматривает их как одно предложение или фразу), так и отдельные слова внутри; для document_text_annotation, поскольку модель оптимизирована для плотного текста, страница, блок, абзац, слово и разрыв - все это предлагается как часть вывода.
Насколько хорошо это работает?
Насколько надежны модели?
Как упоминалось ранее, Google предлагает две функции для распознавания текста в двух разных ситуациях. Ниже описываются возможности двух функций по извлечению разных типов данных.
Печатные данные
Самый простой тип данных для интерпретации - это печатные текстовые данные, т. Е. Напечатанный и отсканированный компьютерный текст. OCR требуется, когда у нас есть только распечатанная копия этих данных вместо оригинальных машинно-кодированных текстов. Поскольку большинство этих текстов сжато и упаковано в страницы, document_text_annotation будет лучшим вариантом.
Рукописные данные
Контент может содержать рукописный текст, а стили рукописных данных могут сильно различаться. Тем не менее, Google Vision OCR обеспечивает приличную точность, если рукописные заметки не слишком беспорядочные. В зависимости от того, насколько упакован носитель рукописных данных, мы используем одну из двух функций в каждом конкретном случае.
Повернутые / открытые данные
Когда изображения или отсканированные фотографии представлены в нестандартных или невыровненных ракурсах, мы рассматриваем их как данные, полученные в естественных условиях. Тексты потенциально может быть труднее обнаружить в первую очередь, и поэтому мы обычно используем text_annotation функция, которая была разработана, в первую очередь, для обработки данных в естественных условиях. Основываясь на некоторых экспериментах по прохождению вертикальных текстов и дорожных знаков, снятых под разными углами, мы показываем, что Google Vision OCR действительно неплохо работает с данными из различных сред.
Почему OCR?
Многие данные, которые у нас есть сегодня, находятся в неструктурированном формате. Например, при наличии изображения, отсканированного документа или фотографии, в то время как люди могут быстро распознавать тексты и дополнительно интерпретировать значения, все текстовые данные представляют собой просто пиксели с цветами, которые не имеют реального значения для машин.

Когда компании или крупные корпорации имеют дело с огромным объемом бумажной работы, большой объем данных делает невозможным выполнение каких-либо классификаций или обработки данных исключительно человеческими усилиями - это когда машинный кодированный текст становится удобным.
После преобразования OCR информация может быть проанализирована несколькими различными методами в зависимости от характера данных:
- Для числовых данных можно напрямую применить статистические методы для анализа любых корреляций. Мы также могли бы принять традиционные методы машинного обучения (например, KNN, K-Means, линейную регрессию) или подходы глубокого обучения для создания прогнозных моделей для регрессии и / или классификации.
- Для текстовых данных может потребоваться больше этапов обработки. Процесс анализа и интерпретации текстовых данных в значимую статистику часто называют обработкой естественного языка (NLP). В частности, мы могли извлекать числа или даже семантику / атмосферу на основе заданного контента.
Все эти анализы могут позволить компаниям, особенно тем, которые ежедневно собирают огромные объемы новых данных, создавать надежные модели и даже автоматизировать многие процессы и заменить традиционные трудоемкие подходы с множеством ошибок. В следующем разделе рассматриваются некоторые подробные примеры использования OCR.
Ищете решение OCR, которое преодолевает недостатки Google Cloud Vision? Даешь нанонеты™ вращение для более высокой точности, большей гибкости и более широких типов документов!
Примеры использования
Чтение номерного знака

Возможно, одним из наиболее распространенных способов использования OCR в настоящее время является приложение для чтения автомобильных номеров. В развитых странах парковки часто сопровождаются моделями считывания номерных знаков, чтобы определить время въезда, времени выезда и даже точное место припаркованного автомобиля. Некоторые автостоянки даже подключены к государственной сети, чтобы взимать плату за парковку напрямую с семей, что облегчает излишние человеческие усилия.
Модели OCR для номерных знаков также могут быть адаптированы для обнаружения нарушений правил дорожного движения, что позволяет полиции вручную вводить данные об автомобиле-нарушителе.
Сканирование чеков и счетов

Финансовые прогнозы и балансировка активов и пассивов компаний являются важными видами деятельности для любой фирмы. Поскольку крупные компании в течение года совершают крупные закупки в разных секторах, они должны тщательно собирать и обрабатывать все счета-фактуры и квитанции при составлении финансовой отчетности.
С помощью OCR мы можем создавать автоматизированные конвейеры, которые распознавать несколько форматов счетов-фактур и преобразовать их в числа. Трудозатраты требуются только для проверки, а структурированные данные и цифры позволяют компании быстро балансировать приходы и оттоки, создавать финансовые прогнозы, а также следить за любыми злонамеренными манипуляциями с финансами компании.
Электрические медицинские записи

Данные о пациентах часто разбросаны по региону, стране или даже по странам, в зависимости от образа жизни людей. Из-за различий в стилях клиник и больниц (в крупных больницах могут быть организованные базы данных, в то время как врачи в небольших клиниках могут просто записывать записи вручную), возраста пациентов (пожилые пациенты могут быть внесены в конкретную базу данных до обновления и включения компьютеры), а также местонахождение людей (люди могут переехать в другой город или даже за границу), на самом деле поддерживать универсальное медицинское обслуживание может быть очень сложно.
Таким образом, хорошо обученный OCR становится удобным при передаче EMR из одной больницы в другую или преобразовании рукописных данных в машинный текст - и то, и другое может ускорить процесс понимания истории болезни пациентов быстрым и кратким образом.
Формы и опросы

Организации (правительственные или неправительственные) часто могут требовать обратной связи от клиентов или граждан для улучшения своих текущих рекламных планов и продуктов. Поскольку формы обычно пишутся от руки, было бы потенциально сложно выполнить какой-либо прямой статистический анализ. Таким образом, OCR может помочь и ускорить процесс преобразования неструктурированных данных и рукописных опросов в числовые цифры для облегчения вычислений.
Ищете решение OCR, которое преодолевает недостатки Google Cloud Vision? Даешь нанонеты™ вращение для более высокой точности, большей гибкости и более широких типов документов!
Цены на Cloud Vision
По данным Google веб-сайт, и то и другое text_annotation и document_text_annotation предлагаются по той же цене, что и следующие:
Каждый месяц первые 1000 единиц выдаются бесплатно, при этом 1000–5000000 единиц оплачиваются из расчета 1.5 доллара за 1000 единиц. После достижения отметки 5000000 цена снижается до 0.6 доллара за 1000 единиц (каждое изображение, отправленное через Google Vision API, считается одной единицей).
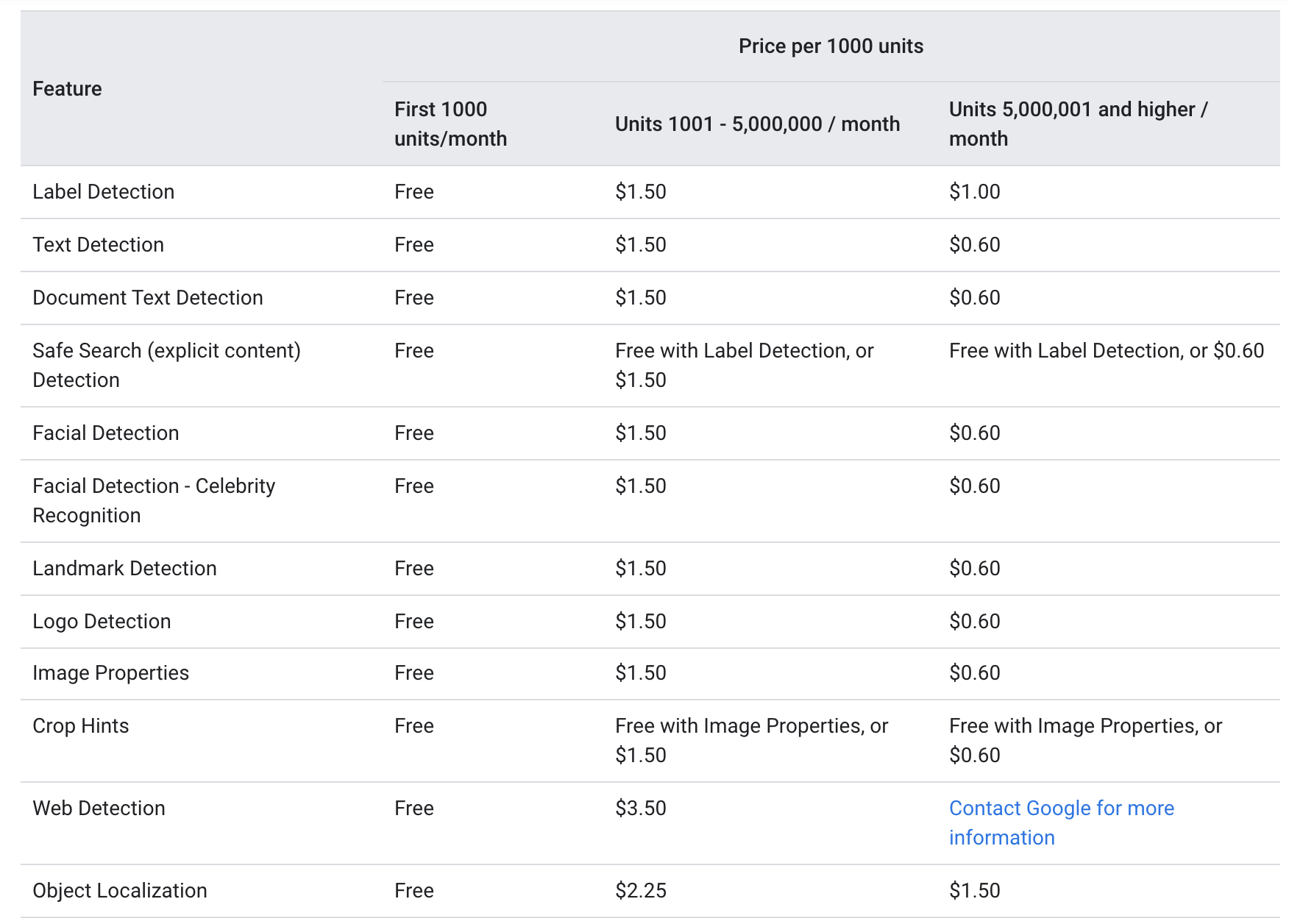
Приведенные выше цены предполагают, что услуга OCR относительно доступна как для небольших компаний с менее частым использованием, так и для крупных корпораций, где услуга требуется более 5000000 раз в месяц.
Основные особенности Google Cloud Vision OCR
Google OCR имеет различные преимущества, здесь мы описываем некоторые из наиболее значительных преимуществ:
- крепкий - Две функции, обслуживающие два типа текстовых документов в зависимости от решения пользователя, делают Google Vision OCR сравнительно более надежным, чем одномодельные механизмы OCR.
- Языковая поддержка - Имея, пожалуй, самую большую языковую базу данных, Google сообщил, что его OCR применимо к более чем 60 языкам, экспериментируя еще с несколькими десятками, и сопоставляет многие из остальных с другим языковым кодом или общим распознавателем языков.
- Легкость использования - Сама модель является частью встроенной библиотеки Google Vision. После немного более сложного процесса настройки ключа API (который требуется почти для всех механизмов распознавания текста) метод вызова функции может использоваться на многих языках очень простым способом.
- Масштабируемость - Стратегия ценообразования Google поощряет пользователей расширять использование API, поскольку большее использование приводит к более низкой средней цене.
- Скорость - Платформа хранения Google Cloud прекрасно дополняет использование API. При загрузке изображений на диск время отклика API может быть очень быстрым и масштабируемым.

Ищете решение OCR, которое преодолевает недостатки Google Cloud Vision? Даешь нанонеты™ вращение для более высокой точности, большей гибкости и более широких типов документов!
альтернативы
Ниже приведены некоторые альтернативные службы распознавания текста, отличные от Google Vision API, а также преимущества и недостатки каждой службы.
ABBYY
ABBYY FineReader PDF - это программа распознавания текста, разработанная ABBYY и ориентированная, в частности, на чтение PDF-файлов.
- Плюсы: ABBYY намного дешевле для индивидуальных пользователей, поскольку цены сегментированы на более мелкие сегменты (1000, 2000 страниц и т. Д.). Он также ориентирован на клиентов, не являющихся инженерами, поскольку это коммерческое приложение.
- Минусы: Программное обеспечение ориентировано только на формат PDF, и при крупномасштабном распознавании текста цена становится очень высокой.
- Когда использовать: Для отдельных пользователей, которые просто хотят быстро обрабатывать PDF-файлы, ABBYY может быть более жизнеспособным вариантом, чем Google Vision API, который дает большую гибкость, но требует дополнительных кодов.
Microsoft
Microsoft Azure также предлагает Read API для OCR.
- Плюсы: Microsoft предлагает более низкую цену за использование еще большего количества данных. Облачное хранилище Azure предлагает те же услуги, что и Google Cloud.
- Минусы: Нет бесплатного уровня, тогда как другие варианты предоставляют бесплатные вызовы API для небольшого использования.
- Когда использовать: Очень крупномасштабные производственные конвейеры OCR могут выиграть от цен Microsoft.
Кофакс
Подобно ABBYY, Kofax также предлагает чтение PDF-файлов с помощью распознавания текста.
- Плюсы: Цена фиксирована для индивидуального использования, для предприятий предусмотрены скидки. Также предоставляется круглосуточная поддержка клиентов без выходных.
- Минусы: Качество заявлено не такое высокое, как у ABBYY.
- Когда использовать: Малые предприятия с низкими потребностями в использовании.
Текст AWS
AWS Textract выполняет очень похожую роль по сравнению с Google Vision API. Их услуги и цены очень похожи, поэтому выбор полностью зависит от предпочтений клиентов.
Нанонеты
В отличие от ранее обсужденных услуг, OCR Nanonets далее подразделяются на определенные категории с надежными моделями, обученными для каждого типа данных (например, квитанции, счета, водительские права).
- Плюсы: OCR для конкретных категорий, что обеспечивает даже лучшие результаты с точки зрения точности, когда компаниям требуется OCR для целевых приложений.
- Минусы: Nanonets OCR может быть менее применимо к настройкам в дикой природе из-за узкоспециализированных и адаптированных моделей.
- Когда использовать: Если компаниям требуется OCR для определенного типа данных, таких как счета-фактуры, Nanonets может быть экономичным и высокоточным вариантом.
Вы можете попробуйте Nanonets Online OCR здесь.
Распространенные проблемы с Cloud Vision
В этом последнем разделе мы стремимся ответить на некоторые вопросы от Stackoverflow относительно сканирования документов и распознавания текста.
Распознавание документов с помощью нейронных сетей
Это точное использование Google OCR! Выполните указанные выше действия, чтобы сканировать документы и выполнять поиск текста.
Получение наиболее важных деталей после распознавания текста
Идея синтаксического анализа наиболее значимого содержимого внутри любых документов называется обработкой естественного языка. Поскольку каждый документ содержит такую информацию в разных форматах, для этого рекомендуется использовать некоторые подходы к ML. Конечно, если все карточки имеют один и тот же формат, основанные на правилах методы для извлечения текстов с определенными ключевыми символами (например, если он содержит @, это электронное письмо) также должны работать.
Может ли он работать в автономном режиме?
Ссылка: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
К сожалению нет. API вызывает Google Cloud OCR удаленно, и вы не можете работать в автономном режиме, так как API стоит денег.
Может ли он определить, выделен ли текст жирным шрифтом или курсивом?
Нет. Google OCR, скорее всего, обнаружит текстовое содержимое, даже если оно выделено жирным шрифтом или курсивом, но модель OCR не предназначена для понимания типов шрифтов.
Обновление: Добавлено больше информации на основе запросов от читателей.
- &
- a
- ускоренный
- Учетная запись
- точный
- через
- активно
- адрес
- Преимущества
- Все
- альтернатива
- альтернативы
- всегда
- суммы
- анализ
- анализировать
- Другой
- API
- API
- приложение
- отношение
- Применение
- Приложения
- прикладной
- подходы
- ПЛОЩАДЬ
- около
- гайд
- Активы
- Аутентификация
- автоматизировать
- Автоматизированный
- в среднем
- Лазурный
- Лазурное облако
- фон
- Банки
- основа
- до
- польза
- Преимущества
- биллинг
- Заблокировать
- булавка
- Книги
- граница
- брейки
- автомобиль
- Карты
- определенный
- символы
- заряд
- заряженный
- более дешевый
- контроль
- Город
- классификация
- облако
- облачного хранения
- код
- Общий
- Компании
- Компания
- сравненный
- полностью
- компьютер
- компьютеры
- подключенный
- Рассматривать
- Консоли
- содержит
- содержание
- содержание
- Конверсия
- Корпорации
- соответствующий
- Расходы
- может
- страны
- страна
- Создайте
- создали
- Создающий
- Текущий
- клиент
- служба поддержки
- Клиенты
- данным
- анализ данных
- обработка данных
- База данных
- базы данных
- день
- занимавшийся
- решение
- глубоко
- зависимый
- в зависимости
- описывать
- предназначенный
- подробный
- подробнее
- обнаруженный
- Определять
- развитый
- различный
- трудный
- направлять
- непосредственно
- Разнообразие
- Врачи
- Документация
- доменов
- вниз
- управлять
- вождение
- каждый
- ослабление
- Edge
- усилие
- усилия
- появившийся
- включить
- призывает
- предприятий
- Окружающая среда
- особенно
- по существу
- и т.д
- Примеры
- Выход
- Экстракты
- семей
- БЫСТРО
- Особенности
- Обратная связь
- Сборы
- Финансы
- финансовый
- Фирма
- First
- фиксированной
- Трансформируемость
- фокусируется
- следовать
- после
- формат
- формы
- найденный
- Бесплатно
- от
- функция
- Функции
- далее
- Общие
- получающий
- правительственный
- Правительства
- большой
- обрабатывать
- помощь
- здесь
- High
- высший
- очень
- история
- больницы
- Как
- How To
- HTTPS
- человек
- Людей
- идея
- изображение
- изображений
- важную
- что она
- улучшать
- включены
- включает в себя
- В том числе
- individual
- лиц
- info
- информация
- пример
- интуитивный
- вопросы
- IT
- саму трезвость
- Java
- хранение
- Основные
- труд
- язык
- Языки
- большой
- больше
- крупнейших
- Лиды
- изучение
- уровень
- уровни
- Библиотека
- Лицензия
- лицензии
- стиль жизни
- Вероятно
- LINK
- локальным
- расположение
- места
- Длинное
- машина
- обучение с помощью машины
- Продукция
- основной
- сделать
- способ
- вручную
- Карты
- отметка
- массивный
- смысл
- значимым
- основным медицинским
- средний
- упомянутый
- методы
- Microsoft
- ML
- модель
- Модели
- деньги
- Месяц
- БОЛЕЕ
- самых
- двигаться
- с разными
- натуральный
- природа
- потребности
- сеть
- Тем не менее
- Заметки
- номер
- номера
- многочисленный
- предложенный
- Предложения
- Официальный представитель в Грузии
- оффлайн
- онлайн
- оптимизированный
- Опция
- Опции
- заказ
- Организованный
- Другое
- собственный
- упакованный
- parking
- часть
- особый
- особенно
- Прохождение
- Люди
- возможно
- Планы
- Платформа
- Полиция
- Популярное
- мощный
- цена
- цены
- процесс
- Процессы
- обработка
- Производство
- Продукция
- Проект
- Прогнозы
- многообещающий
- рекламный
- обеспечивать
- при условии
- приводит
- обеспечение
- Покупка
- быстро
- ассортимент
- ранжирование
- RE
- читатели
- Reading
- последний
- признавать
- учет
- по
- область
- удаленные
- требовать
- обязательный
- Требования
- требуется
- исследованиям
- Полезные ресурсы
- ответ
- ОТДЫХ
- Итоги
- Дорога
- Роли
- Run
- то же
- масштабируемые
- Шкала
- сканирование
- сканирование
- Сектора юридического права
- смысл
- Серии
- обслуживание
- Услуги
- выступающей
- набор
- установка
- значительный
- Признаки
- аналогичный
- просто
- с
- небольшой
- So
- Software
- твердый
- Решение
- некоторые
- конкретный
- конкретно
- Вращение
- этапы
- и политические лидеры
- отчетность
- статистический
- статистика
- диск
- Стратегия
- улица
- структурированный
- поддержка
- Поддержка
- Опрос
- terms
- Ассоциация
- следовательно
- Через
- по всему
- время
- раз
- сегодня
- к
- традиционный
- трафик
- Обучение
- Передающий
- превращение
- Типы
- под
- понимать
- понимание
- единиц
- Universal
- использование
- пользователей
- обычно
- различный
- видение
- объем
- Смотреть
- будь то
- в то время как
- КТО
- Шире
- окна
- в
- слова
- Работа
- работает
- бы
- X
- год
- ВАШЕ