Апач Худи — это формат открытых таблиц, который объединяет возможности баз данных и хранилищ данных в озерах данных. Apache Hudi помогает инженерам данных решать сложные задачи, например управлять постоянно развивающимися наборами данных с помощью транзакций, сохраняя при этом производительность запросов. Инженеры по обработке данных используют Apache Hudi для потоковой передачи рабочих нагрузок, а также для создания эффективных дополнительных конвейеров данных. Худи предоставляет Эта таблица, операции, эффективные обновления и удаления, расширенные индексы, сервисы потокового приема, данные кластеризации и уплотнение оптимизации и контроль параллелизма, сохраняя при этом ваши данные в форматах файлов с открытым исходным кодом. Расширенные возможности оптимизации производительности Hudi ускоряют аналитические рабочие нагрузки с помощью любой популярной системы запросов, включая Apache Spark, Presto, Trino, Hive и т. д.
Многие клиенты AWS внедрили Apache Hudi в свои озера данных, построенные на базе Amazon S3 с использованием Клей AWS, бессерверная служба интеграции данных, которая упрощает обнаружение, подготовку, перемещение и интеграцию данных из нескольких источников для аналитики, машинного обучения (ML) и разработки приложений. Сканер клея AWS — это компонент AWS Glue, который позволяет автоматически создавать метаданные таблицы из содержимого данных, не требуя ручного определения метаданных.
Сканеры AWS Glue теперь поддерживают таблицы Apache Hudi, упрощая принятие Каталог данных AWS Glue в качестве каталога столов Hudi. Одним из типичных вариантов использования является регистрация таблиц Hudi, у которых нет определения таблицы каталога. Другой типичный вариант использования — миграция из других каталогов Hudi, таких как метахранилище Hive. При миграции из других каталогов Hudi вы можете создать и запланировать искатель AWS Glue и указать один или несколько путей Amazon S3, по которым расположены файлы таблиц Hudi. У вас есть возможность указать максимальную глубину путей Amazon S3, которые может пройти сканер AWS Glue. При каждом запуске сканеры AWS Glue извлекают информацию о схеме и разделах и обновляют каталог данных AWS Glue с учетом изменений схемы и разделов. Сканеры AWS Glue обновляют местоположение последнего файла метаданных в каталоге данных AWS Glue, который аналитические системы AWS могут использовать напрямую.
Благодаря этому запуску вы сможете создать и запланировать сканер AWS Glue для регистрации таблиц Hudi в каталоге данных AWS Glue. Затем вы можете указать один или несколько путей Amazon S3, где расположены таблицы Hudi. У вас есть возможность указать максимальную глубину путей Amazon S3, которые могут пройти сканеры. При каждом запуске сканера он проверяет каждый из путей S3 и каталогизирует информацию о схеме, такую как новые таблицы, удаления и обновления схем, в каталоге данных AWS Glue. Краулеры проверяют информацию о разделах и добавляют вновь добавленные разделы в каталог данных AWS Glue. Краулеры также обновляют местоположение последнего файла метаданных в каталоге данных AWS Glue, который могут напрямую использовать аналитические системы AWS.
В этом посте показано, как работает новая возможность сканирования таблиц Hudi.
Как сканер AWS Glue работает с таблицами Hudi
Таблицы Hudi имеют две категории, каждая из которых имеет свои особенности:
- Копирование при записи (CoW) – Данные хранятся в столбчатом формате (Parquet), и каждое обновление создает новую версию файлов во время записи.
- Объединение при чтении (MoR) – Данные хранятся с использованием комбинации столбчатого (Parquet) и строкового (Avro) форматов. Обновления записываются в систему на основе строк.
deltaфайлы и сжимаются по мере необходимости для создания новых версий столбчатых файлов.
При использовании наборов данных CoW каждый раз при обновлении записи файл, содержащий запись, перезаписывается с обновленными значениями. В наборе данных MoR при каждом обновлении Худи записывает только строку для измененной записи. MoR лучше подходит для рабочих нагрузок с большим количеством операций записи или изменения с меньшим количеством операций чтения. CoW лучше подходит для рабочих нагрузок с большим объемом чтения данных, которые изменяются реже.
Hudi предоставляет три типа запросов для доступа к данным:
- Снимки запросов – Запросы, которые просматривают последний снимок таблицы на момент данного действия фиксации или сжатия. Для таблиц MoR запросы моментальных снимков раскрывают самое последнее состояние таблицы путем слияния базовых и дельта-файлов последнего среза файла на момент запроса.
- Дополнительные запросы – Запросы видят только новые данные, записанные в таблицу с момента данной фиксации или сжатия. Это эффективно обеспечивает потоки изменений для включения дополнительных конвейеров данных.
- Чтение оптимизированных запросов – Для таблиц MoR запросы просматривают последние сжатые данные. Для таблиц CoW запросы просматривают последние зафиксированные данные.
Для таблиц копирования при записи сканеры создают одну таблицу в каталоге данных AWS Glue с помощью ReadOptimized Serde. org.apache.hudi.hadoop.HoodieParquetInputFormat.
Для таблиц, объединяемых при чтении, сканеры создают две таблицы в каталоге данных AWS Glue для одного и того же местоположения таблицы:
- Таблица с суффиксом
_ro, который использует ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Таблица с суффиксом
_rt, который использует RealTime Serde, позволяющий выполнять запросы к снимкам:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Во время каждого сканирования для каждого предоставленного пути Hudi сканеры выполняют вызов API списка Amazon S3, фильтруют на основе .hoodie папки и найдите самый последний файл метаданных в этой папке метаданных таблицы Hudi.
Сканирование таблицы Hudi CoW с помощью сканера AWS Glue
В этом разделе мы рассмотрим, как сканировать Hudi CoW с помощью сканеров AWS Glue.
Предпосылки
Вот предварительные условия для этого урока:
- Установка и настройка Интерфейс командной строки AWS (AWS CLI).
- Создайте свою корзину S3, если у вас ее нет.
- Создайте свою роль IAM для AWS Glue если у вас его нет. Тебе нужно
s3:GetObjectдляs3://your_s3_bucket/data/sample_hudi_cow_table/. - Выполните следующую команду, чтобы скопировать образец таблицы Hudi в корзину S3. (Заменять
your_s3_bucketс именем корзины S3.)
Эта инструкция поможет вам скопировать образцы данных, но вы можете легко создать любые таблицы Hudi с помощью AWS Glue. Узнайте больше в Введение встроенной поддержки Apache Hudi, Delta Lake и Apache Iceberg в AWS Glue для Apache Spark, часть 2: визуальный редактор AWS Glue Studio.
Создайте сканер Hudi
В этой инструкции создайте обходчик через консоль. Выполните следующие шаги, чтобы создать сканер Hudi:
- На консоли AWS Glue выберите ползунки.
- Выберите Создать сканер.
- Что касается Имя, войти
hudi_cow_crawler. Выберите Следующая. - Под Конфигурация источника данных, выбирать Добавить источник данных.
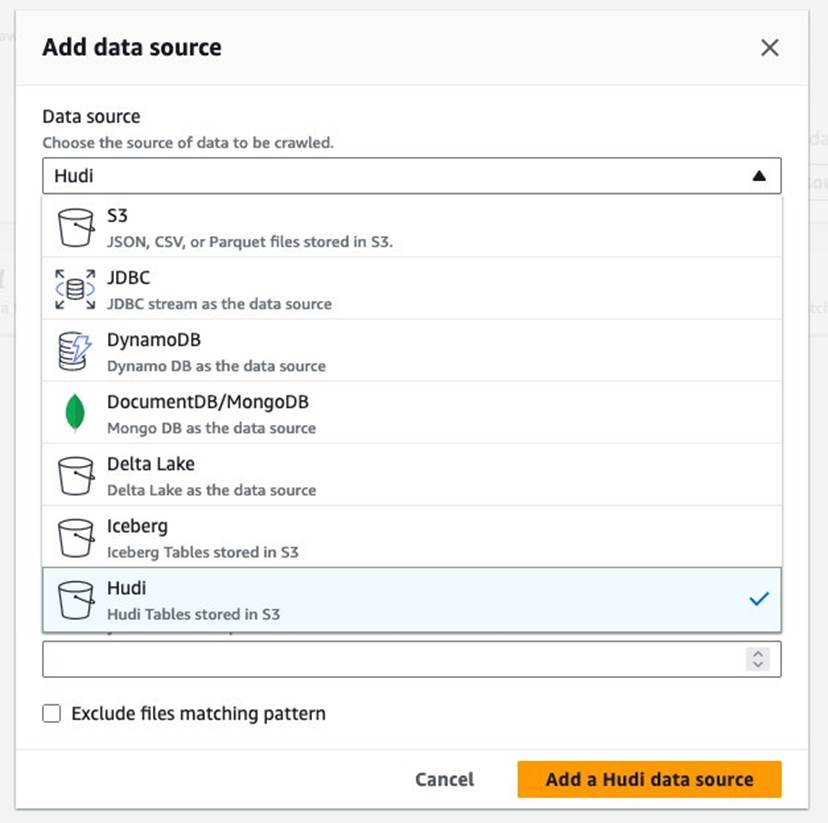
- Что касается Источник данных, выберите Худи.
- Что касается Включить пути к таблицам Hudi, войти
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Заменятьyour_s3_bucketс именем корзины S3.) - Выберите Добавить источник данных Hudi.
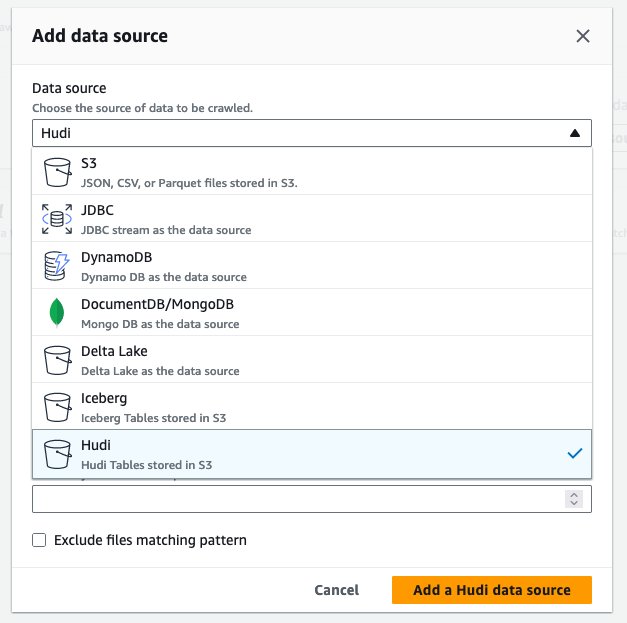
- Выберите Следующая.
- Что касается Существующая роль IAM, выберите роль IAM, затем выберите Следующая.
- Что касается Целевая база данных, выберите Добавить базу данных, то Добавить базу данных появится диалоговое окно. Для Имя базы данных, войти
hudi_crawler_blog, а затем выберите Создавай. Выберите Следующая. - Выберите Создать сканер.
Теперь новый краулер Hudi успешно создан. Сканер можно запустить через консоль, SDK или интерфейс командной строки AWS с помощью команды StartCrawl API. Также через консоль можно запланировать запуск сканеров в определенное время. В этой инструкции запускаем обходчик через консоль.
- Выберите Запустить краулер.
- Подождите, пока сканер завершит работу.
После запуска сканера вы можете увидеть определение таблицы Hudi в консоли AWS Glue:
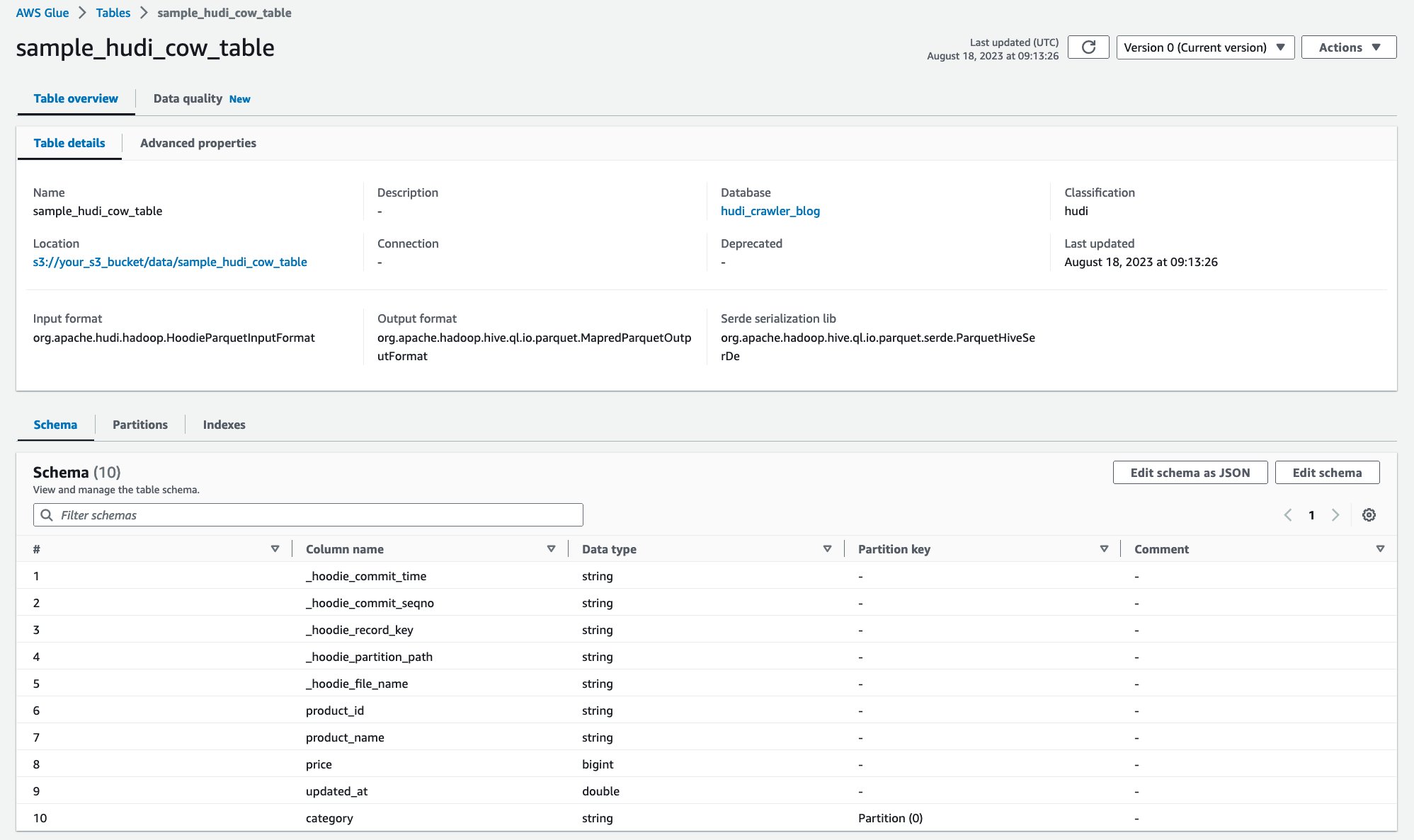
Вы успешно просканировали таблицу Hudi CoR с данными на Amazon S3 и создали таблицу каталога данных AWS Glue с заполненной схемой. После того как вы создадите определение таблицы в каталоге данных AWS Glue, аналитические сервисы AWS, такие как Amazon Athena, смогут запрашивать таблицу Hudi.
Выполните следующие шаги, чтобы начать запросы к Athena:
- Откройте консоль Amazon Athena.
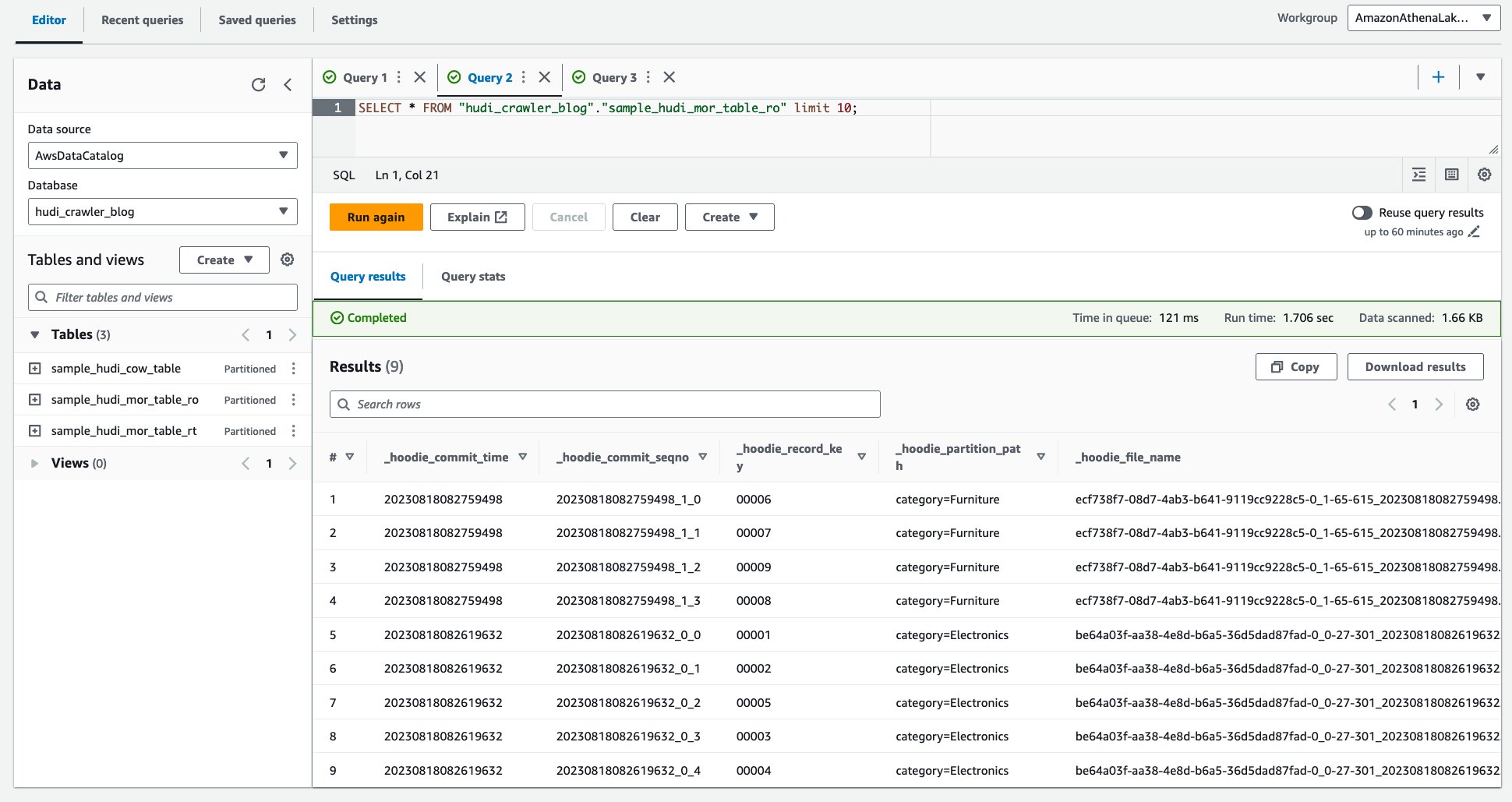
- Выполните следующий запрос.
На следующем снимке экрана показан наш вывод:
Сканирование таблицы Hudi MoR с помощью сканера AWS Glue с разрешениями на данные AWS Lake Formation.
В этом разделе мы рассмотрим, как сканировать таблицу Hudi MoR с помощью AWS Glue. На этот раз вы используете разрешение данных AWS Lake Formation для сканирования источников данных Amazon S3 вместо разрешения IAM и Amazon S3. Это необязательно, но это упрощает настройку разрешений, если ваше озеро данных управляется разрешениями AWS Lake Formation.
Предпосылки
Вот предварительные условия для этого урока:
- Установка и настройка Интерфейс командной строки AWS (AWS CLI).
- Создайте свою корзину S3, если у вас ее нет.
- Создайте свою роль IAM для AWS Glue если у вас его нет. Тебе нужно
lakeformation:GetDataAccess. Но вам не нужноs3:GetObjectдляs3://your_s3_bucket/data/sample_hudi_mor_table/потому что мы используем разрешение данных Lake Formation для доступа к файлам. - Выполните следующую команду, чтобы скопировать образец таблицы Hudi в корзину S3. (Заменять
your_s3_bucketс именем корзины S3.)
В дополнение к этапам обработки выполните следующие действия, чтобы обновить настройки каталога данных AWS Glue, чтобы использовать разрешения Lake Formation для управления ресурсами каталога вместо управления доступом на основе IAM:
- Войдите в консоль Lake Formation как администратор озера данных.
- Если вы впервые получаете доступ к консоли Lake Formation, добавьте себя в качестве администратора озера данных.
- Под Администрация, выберите Настройки каталога данных.
- Что касается Разрешения по умолчанию для вновь создаваемых баз данных и таблиц, отменить выбор Используйте только контроль доступа IAM для новых баз данных и Использовать только управление доступом IAM для новых таблиц в новых базах данных.
- Что касается Настройка версии кросс-аккаунта, выберите Версия 3.
- Выберите Сохранить.
Следующим шагом будет регистрация корзины S3 в расположениях озер данных Lake Formation:
- На консоли Lake Formation выберите Расположение озера данных, и выберите Зарегистрировать местонахождение.
- Что касается Путь к Amazon S3, войти
s3://your_s3_bucket/. (Заменятьyour_s3_bucketс именем корзины S3.) - Выберите Зарегистрировать местонахождение.
Затем предоставьте роли искателя Glue доступ к расположению данных, чтобы искатель мог использовать разрешение Lake Formation для доступа к данным и создания таблиц в этом расположении:
- На консоли Lake Formation выберите Расположение данных , а затем выбрать Грант.
- Что касается Пользователи и роли IAM, выберите роль IAM, которую вы использовали для искателя.
- Что касается Место хранения, войти
s3://your_s3_bucket/data/. (Заменятьyour_s3_bucketс именем корзины S3.) - Выберите Грант.
Затем предоставьте роль сканеру для создания таблиц в базе данных. hudi_crawler_blog:
- На консоли Lake Formation выберите Разрешения озера данных.
- Выберите Грант.
- Что касается Принципалы, выберите Пользователи и роли IAMи выберите роль сканера.
- Что касается LF-теги или ресурсы каталога, выберите Именованные ресурсы каталога данных.
- Что касается База данных, выберите базу данных
hudi_crawler_blog. - Под Разрешения базы данных, наведите на Создать таблицу.
- Выберите Грант.
Создайте сканер Hudi с разрешениями на данные Lake Formation.
Выполните следующие шаги, чтобы создать сканер Hudi:
- На консоли AWS Glue выберите ползунки.
- Выберите Создать сканер.
- Что касается Имя, войти
hudi_mor_crawler. Выберите Следующая. - Под Конфигурация источника данных, выбирать Добавить источник данных.
- Что касается Источник данных, выберите Худи.
- Что касается Включить пути к таблицам Hudi, войти
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Заменятьyour_s3_bucketс именем корзины S3.) - Выберите Добавить источник данных Hudi.
- Выберите Следующая.
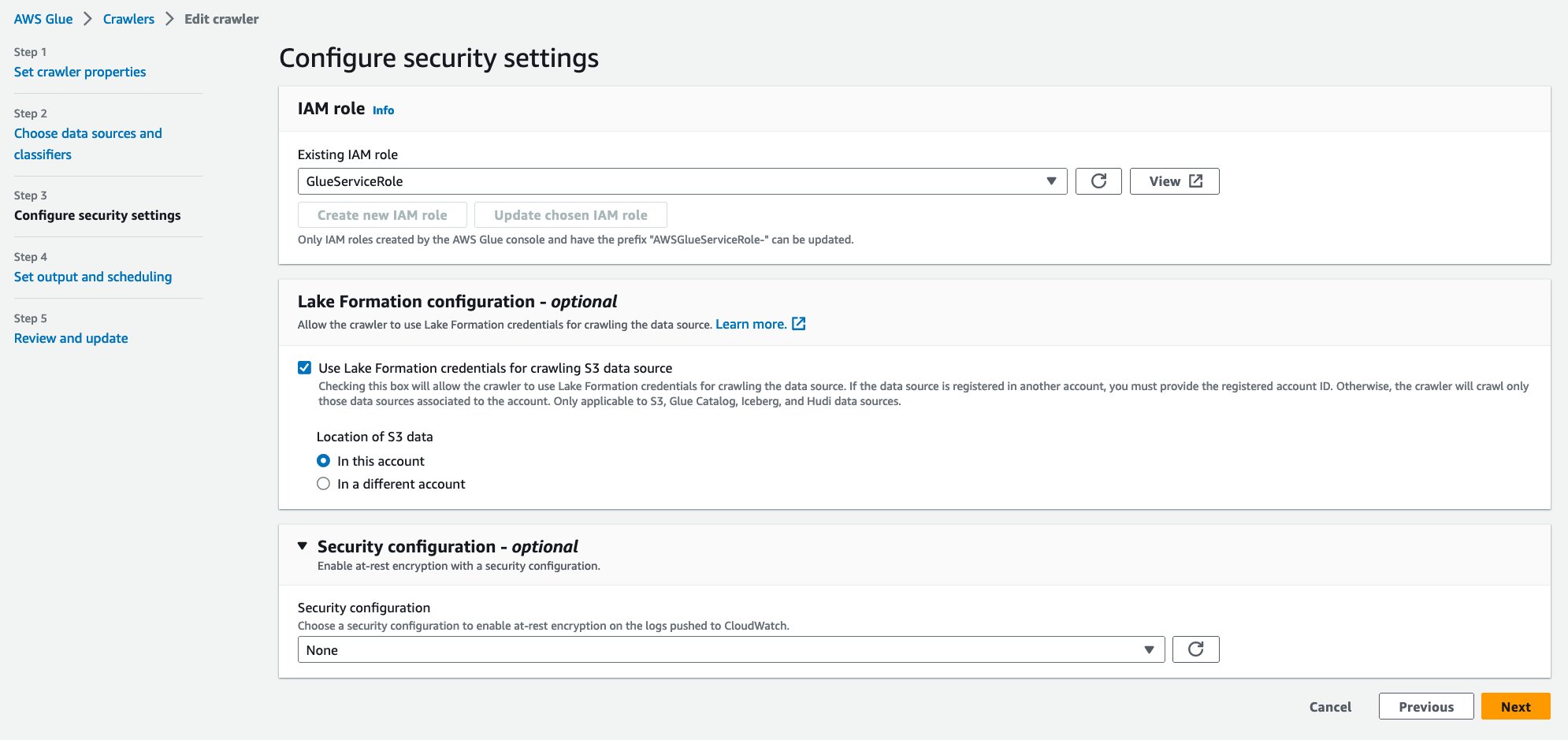
- Что касается Существующая роль IAM, выберите свою роль IAM.
- Под Конфигурация Lake Formation – опционально, наведите на Используйте учетные данные Lake Formation для обхода источника данных S3..
- Выберите Следующая.
- Что касается Целевая база данных, выберите
hudi_crawler_blog. Выберите Следующая. - Выберите Создать сканер.
Теперь новый краулер Hudi успешно создан. Сканер использует учетные данные Lake Formation для сканирования файлов Amazon S3. Давайте запустим новый сканер:
- Выберите Запустить краулер.
- Подождите, пока сканер завершит работу.
После запуска сканера вы увидите две таблицы определения таблицы Hudi в консоли AWS Glue:
sample_hudi_mor_table_ro(читать оптимизированную таблицу)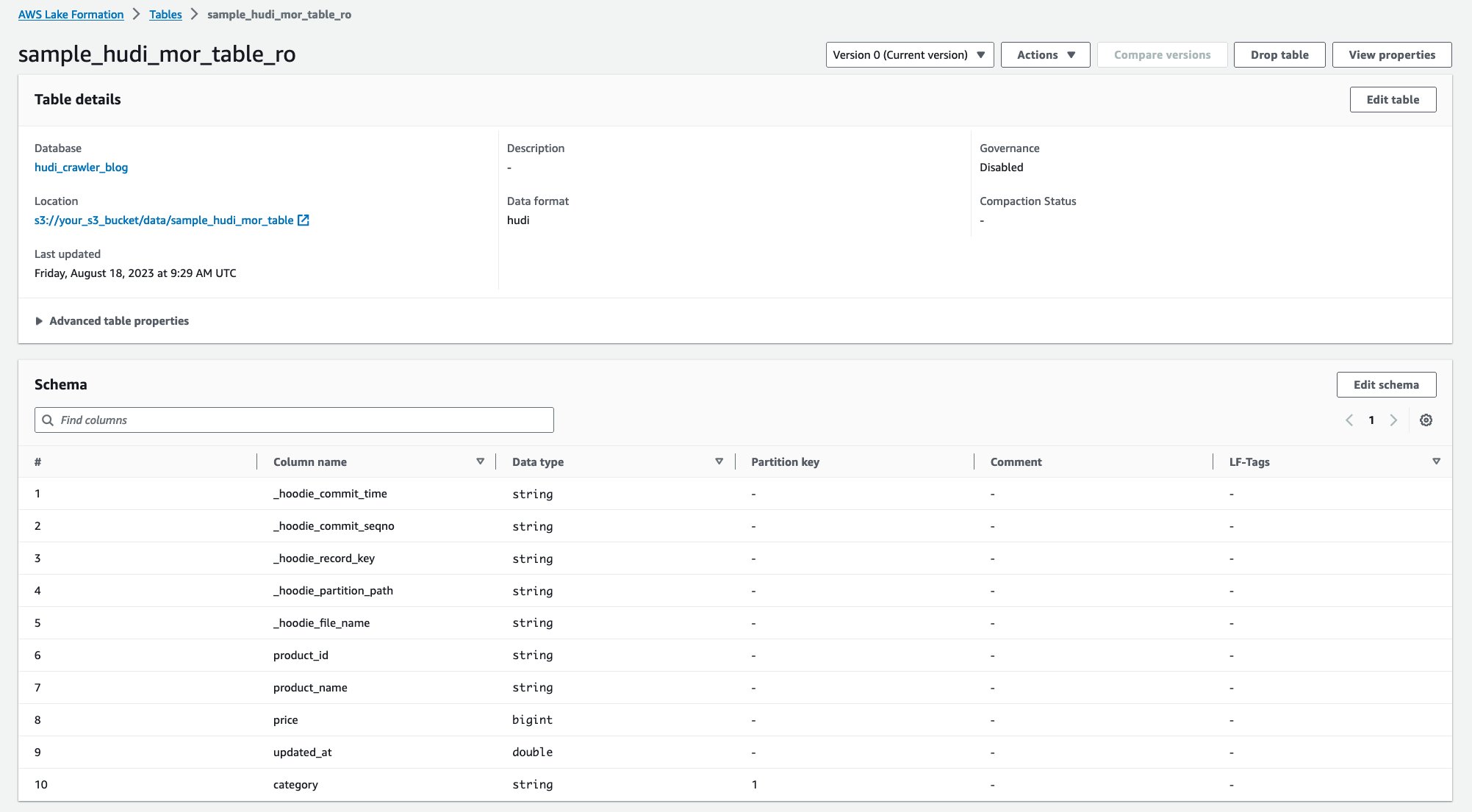
sample_hudi_mor_table_rt(таблица реального времени)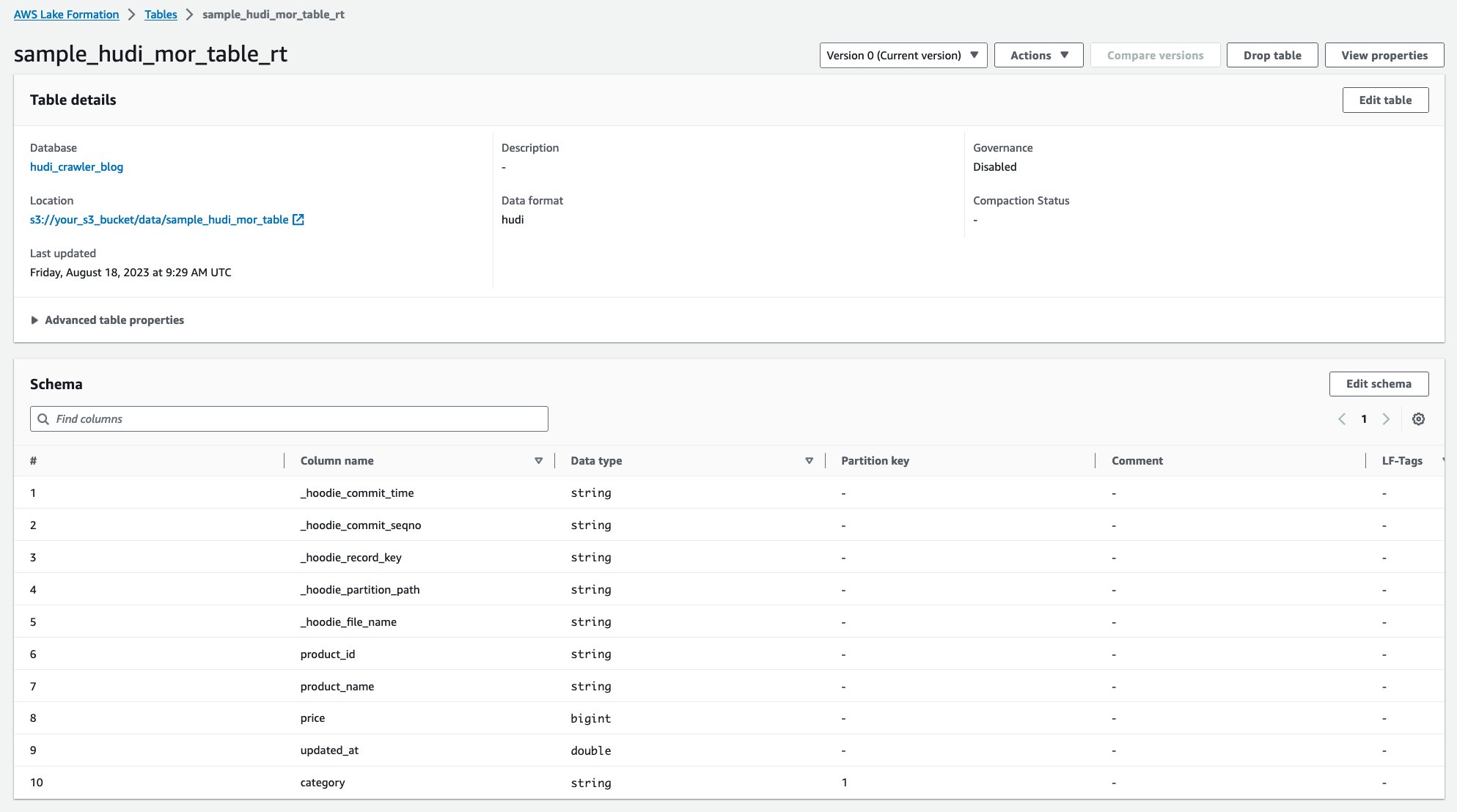
Вы зарегистрировали сегмент озера данных в Lake Formation и включили доступ для сканирования к озеру данных с помощью разрешений Lake Formation. Вы успешно просканировали таблицу Hudi MoR с данными на Amazon S3 и создали таблицу каталога данных AWS Glue с заполненной схемой. После того как вы создадите определения таблиц в каталоге данных AWS Glue, аналитические сервисы AWS, такие как Amazon Athena, смогут запрашивать таблицу Hudi.
Выполните следующие шаги, чтобы начать запросы к Athena:
- Откройте консоль Amazon Athena.
- Выполните следующий запрос.
На следующем снимке экрана показан наш вывод:
- Выполните следующий запрос.
На следующем снимке экрана показан наш вывод:
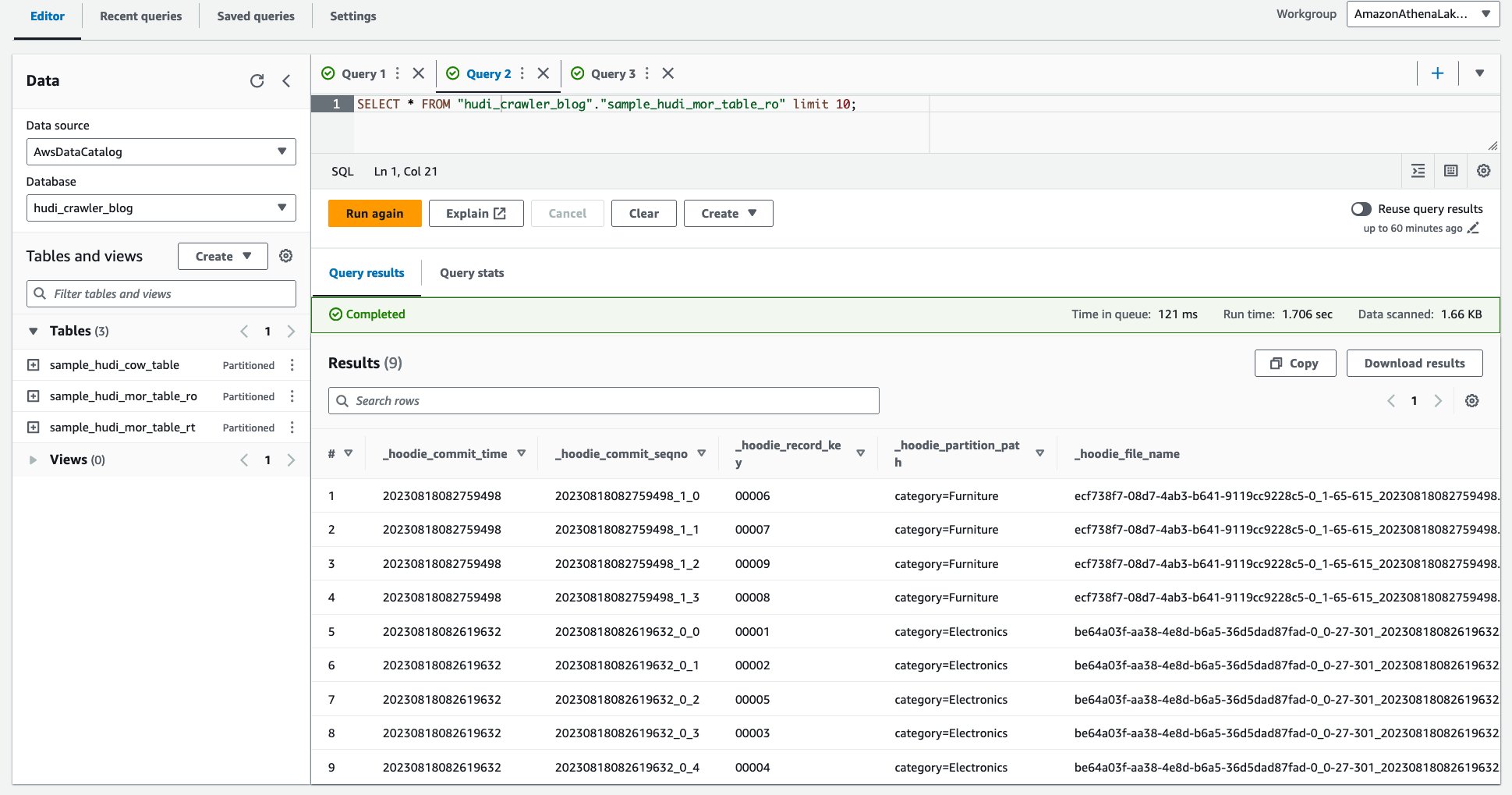
Детальный контроль доступа с использованием разрешений AWS Lake Formation.
Чтобы применить детальный контроль доступа к таблице Hudi, вы можете воспользоваться разрешениями AWS Lake Formation. Разрешения Lake Formation позволяют ограничить доступ к определенным таблицам, столбцам или строкам, а затем запрашивать таблицы Hudi через Amazon Athena с детальным контролем доступа. Давайте настроим разрешение Lake Formation для таблицы Hudi MoR.
Предпосылки
Вот предварительные условия для этого урока:
- Заполните предыдущий раздел Сканирование таблицы Hudi MoR с помощью сканера AWS Glue с разрешениями на данные AWS Lake Formation..
- Создайте пользователя DataAnalyst IAM, у которого есть политика, управляемая AWS. AmazonAthenaПолный доступ.
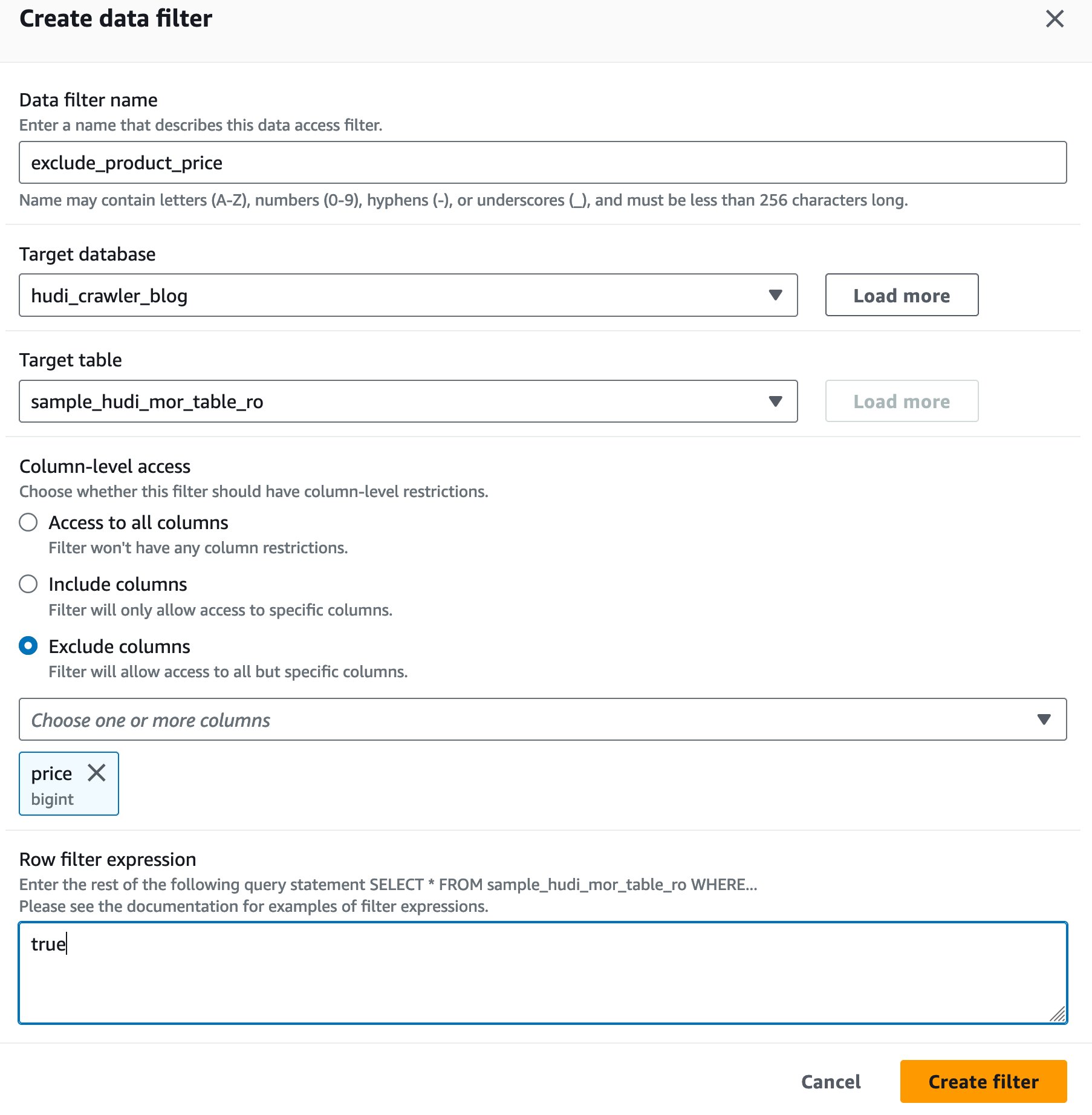
Создайте фильтр ячеек данных Lake Formation.
Давайте сначала настроим фильтр для таблицы, оптимизированной для чтения MoR.
- Войдите в консоль Lake Formation как администратор озера данных.
- Выберите Фильтры данных.
- Выберите Создать новый фильтр.
- Что касается Имя фильтра данных, войти
exclude_product_price. - Что касается Целевая база данных, выберите базу данных
hudi_crawler_blog. - Что касается Целевая таблица, выберите стол
sample_hudi_mor_table_ro. - Что касается На уровне столбца доступ, выбор Исключить столбцыи выберите цену столбца.
- Что касается Выражение фильтра строк, войти
true. - Выберите Создать фильтр.
Предоставьте разрешения Lake Formation пользователю DataAnalyst.
Выполните следующие шаги, чтобы предоставить разрешение Lake Formation DataAnalyst пользователь
- На консоли Lake Formation выберите Разрешения озера данных.
- Выберите Грант.
- Что касается Принципалы, выберите Пользователи и роли IAMи выберите пользователя
DataAnalyst. - Что касается LF-теги или ресурсы каталога, выберите Именованные ресурсы каталога данных.
- Что касается База данных, выберите базу данных
hudi_crawler_blog. - Что касается Таблица – опционально, выберите стол
sample_hudi_mor_table_ro. - Что касается Фильтры данных – опционально, Выбрать
exclude_product_price. - Что касается Разрешения фильтра данных, наведите на Выберите.
- Выберите Грант.
Вы предоставили Lake Formation разрешение на доступ к базе данных. hudi_crawler_blog и стол sample_hudi_mor_table_ro, исключая столбец price пользователю DataAnalyst. Теперь давайте проверим доступ пользователей к данным с помощью Athena.
- Войдите в консоль Athena как пользователь DataAnalyst.
- В редакторе запросов выполните следующий запрос:
На следующем снимке экрана показан наш вывод:
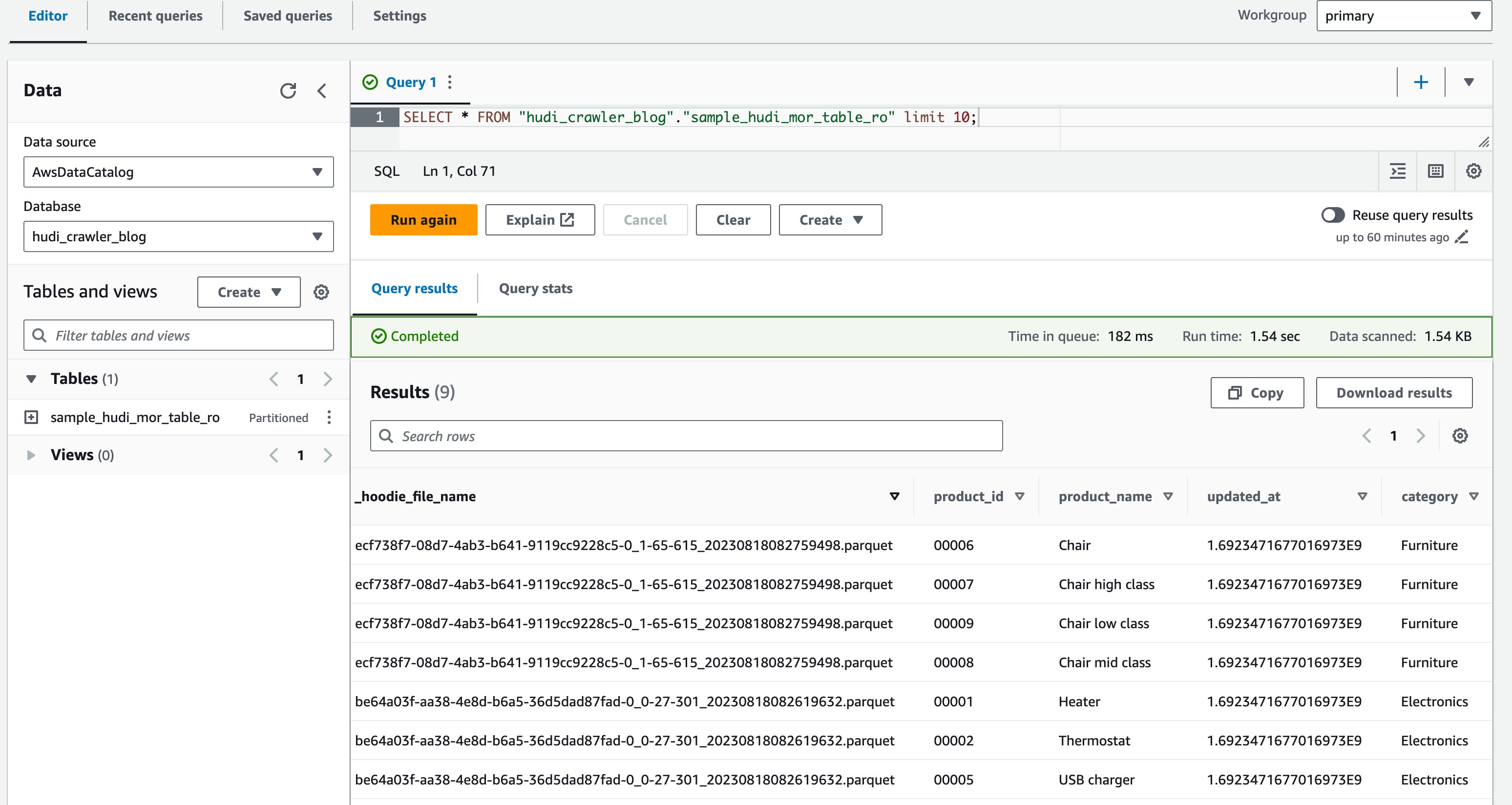
Теперь вы убедились, что столбец price не отображается, но другие столбцы product_id, product_name, update_atи category показаны.
Убирать
Чтобы избежать нежелательных списаний с вашего аккаунта AWS, удалите следующие ресурсы AWS:
- Удалить базу данных AWS Glue
hudi_crawler_blog. - Удаление сканеров AWS Glue
hudi_cow_crawlerиhudi_mor_crawler. - Удалите файлы Amazon S3 в разделе
s3://your_s3_bucket/data/sample_hudi_cow_table/иs3://your_s3_bucket/data/sample_hudi_mor_table/.
Заключение
В этом посте показано, как сканеры AWS Glue работают с таблицами Hudi. Благодаря поддержке сканера Hudi вы можете быстро перейти к использованию каталога данных AWS Glue в качестве основного каталога таблиц Hudi. Вы можете начать создавать бессерверное озеро транзакционных данных с помощью Hudi на AWS, используя AWS Glue, каталог данных AWS Glue и детальные элементы управления доступом Lake Formation для таблиц и форматов, поддерживаемых аналитическими механизмами AWS.
Об авторах
 Норитака Сэкияма является главным архитектором больших данных в команде AWS Glue. Он работает в Токио, Япония. Он отвечает за создание артефактов программного обеспечения, чтобы помочь клиентам. В свободное время он любит кататься на велосипеде.
Норитака Сэкияма является главным архитектором больших данных в команде AWS Glue. Он работает в Токио, Япония. Он отвечает за создание артефактов программного обеспечения, чтобы помочь клиентам. В свободное время он любит кататься на велосипеде.
 Кайл Дуонг — инженер-разработчик программного обеспечения в команде AWS Glue и Lake Formation. Он увлечен созданием технологий больших данных и распределенных систем.
Кайл Дуонг — инженер-разработчик программного обеспечения в команде AWS Glue и Lake Formation. Он увлечен созданием технологий больших данных и распределенных систем.
 Сандип Адванкар является старшим менеджером по техническим продуктам в AWS. Находясь в районе Калифорнийского залива, он работает с клиентами по всему миру, чтобы преобразовать деловые и технические требования в продукты, которые позволяют клиентам улучшить управление, защиту и доступ к данным.
Сандип Адванкар является старшим менеджером по техническим продуктам в AWS. Находясь в районе Калифорнийского залива, он работает с клиентами по всему миру, чтобы преобразовать деловые и технические требования в продукты, которые позволяют клиентам улучшить управление, защиту и доступ к данным.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :имеет
- :является
- :нет
- :куда
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- в состоянии
- О нас
- доступ
- Доступ к данным
- доступа
- Учетная запись
- Действие
- Добавить
- добавленный
- дополнение
- принял
- Принятие
- продвинутый
- После
- Все
- позволять
- Позволяющий
- позволяет
- причислены
- Amazon
- Амазонка Афина
- Amazon Web Services
- an
- Аналитические фармацевтические услуги
- аналитика
- и
- Другой
- любой
- апаш
- Apache Spark
- API
- появляется
- Применение
- Разработка приложения
- Применить
- МЫ
- ПЛОЩАДЬ
- около
- AS
- At
- автоматически
- избежать
- AWS
- Клей AWS
- Формирование озера AWS
- Использование темпера с изогнутым основанием
- основанный
- залив
- BE
- , так как:
- было
- польза
- Лучшая
- большой
- Big Data
- Приносит
- Строительство
- построенный
- бизнес
- но
- by
- Калифорния
- призывают
- CAN
- возможности
- возможности
- случаев
- каталог
- каталоги
- категории
- ячейка
- проблемы
- изменение
- менялась
- изменения
- расходы
- Выберите
- Column
- Колонки
- сочетание
- совершать
- привержен
- полный
- комплекс
- компонент
- Конфигурация
- Консоли
- содержит
- содержание
- непрерывно
- контроль
- контрольная
- может
- гусеничный
- Создайте
- создали
- создает
- Полномочия
- Клиенты
- данным
- Интеграция данных
- Озеро данных
- информационное хранилище
- База данных
- базы данных
- Наборы данных
- определение
- Определения
- Delta
- убивают
- демонстрирует
- глубина
- Развитие
- непосредственно
- обнаружить
- распределенный
- распределенные системы
- do
- приносит
- в течение
- каждый
- легче
- легко
- редактор
- фактически
- эффективный
- включить
- включен
- инженер
- Инженеры
- Двигатели
- Enter
- Эфир (ETH)
- развивается
- без учета
- извлечение
- быстрее
- меньше
- Файл
- Файлы
- фильтр
- фильтры
- Найдите
- Во-первых,
- Впервые
- после
- Что касается
- формат
- образование
- часто
- от
- данный
- земной шар
- Go
- предоставлять
- предоставленный
- Гиды
- Hadoop
- Есть
- he
- помощь
- помогает
- его
- Hive
- Как
- How To
- HTML
- HTTPS
- IAM
- if
- последствия
- улучшать
- in
- В том числе
- дополнительный
- информация
- вместо
- интегрировать
- интеграции.
- Интерфейс
- в
- введение
- IT
- Япония
- JPG
- хранение
- озеро
- озера
- последний
- запуск
- УЧИТЬСЯ
- изучение
- Меньше
- ОГРАНИЧЕНИЯ
- линия
- Список
- расположенный
- расположение
- места
- Войти
- машина
- обучение с помощью машины
- сохранение
- сделать
- ДЕЛАЕТ
- управлять
- управляемого
- менеджер
- управления
- руководство
- максимальный
- объединение
- Метаданные
- мигрирующий
- миграция
- ML
- БОЛЕЕ
- самых
- двигаться
- с разными
- имя
- родной
- Необходимость
- необходимый
- Новые
- вновь
- следующий
- сейчас
- of
- on
- ONE
- только
- открытый
- с открытым исходным кодом
- оптимизированный
- Опция
- or
- Другое
- наши
- выходной
- часть
- страстный
- путь
- пути
- производительность
- разрешение
- Разрешения
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Популярное
- населенный
- После
- Подготовить
- предпосылки
- предыдущий
- цена
- первичный
- Основной
- обработка
- Продукт
- Менеджер по продукции
- Продукция
- обеспечивать
- при условии
- приводит
- Запросы
- быстро
- Читать
- реальные
- реального времени
- реальном времени
- последний
- запись
- зарегистрироваться
- зарегистрированный
- замещать
- Требования
- Полезные ресурсы
- ответственный
- ограничивать
- Дорога
- Роли
- РЯД
- Run
- то же
- график
- считаться
- SDK
- Раздел
- безопасный
- посмотреть
- выберите
- старший
- Serverless
- обслуживание
- Услуги
- набор
- настройки
- показанный
- Шоу
- упрощает
- с
- одинарной
- Ломтик
- Снимок
- So
- Software
- разработка программного обеспечения
- Источник
- Источники
- Искриться
- конкретный
- Начало
- Область
- Шаг
- Шаги
- хранить
- потоковый
- потоки
- студия
- Успешно
- такие
- поддержка
- Поддержанный
- синхронизации.
- системы
- ТАБЛИЦЫ
- команда
- Технический
- технологии
- который
- Ассоциация
- их
- тогда
- Там.
- они
- этой
- три
- Через
- время
- раз
- в
- Токио
- топ
- транзакционный
- Сделки
- переведите
- траверс
- вызвать
- срабатывает
- учебник
- два
- Типы
- типичный
- под
- нежелательный
- Обновление ПО
- обновление
- Updates
- использование
- прецедент
- используемый
- Информация о пользователе
- пользователей
- использования
- через
- VALIDATE
- подтверждено
- Наши ценности
- версия
- визуальный
- Склады
- we
- Web
- веб-сервисы
- ЧТО Ж
- когда
- который
- в то время как
- КТО
- будете
- без
- Работа
- работает
- записывать
- письменный
- являетесь
- ВАШЕ
- себя
- зефирнет