Амазонка Redshift, широко используемое облачное хранилище данных, значительно эволюционировало, чтобы соответствовать требованиям к производительности самых ресурсоемких рабочих нагрузок. В этом посте рассматривается одна такая новая функция — ключ сортировки многомерного макета данных.
Amazon Redshift теперь повышает производительность запросов за счет поддержки ключей сортировки многомерного макета данных — нового типа ключей сортировки, который сортирует данные таблицы по предикатам фильтра, а не по физическим столбцам таблицы. Ключи сортировки многомерного макета данных значительно улучшат производительность сканирования таблиц, особенно если ваша рабочая нагрузка запросов содержит повторяющиеся фильтры сканирования.
Amazon Redshift уже предоставляет возможность автоматическая оптимизация стола (ATO), который автоматически оптимизирует структуру таблиц, применяя ключи сортировки и распределения без необходимости вмешательства администратора. В этом посте мы представляем ключи сортировки многомерного макета данных как дополнительную возможность, предлагаемую ATO и усиленную алгоритмом советника по ключам сортировки Amazon Redshift.
Ключи сортировки многомерного макета данных
Когда вы определяете таблицу с ключом сортировки АВТО, Amazon Redshift ATO проанализирует историю ваших запросов и автоматически выберет для вашей таблицы либо ключ сортировки по одному столбцу, либо ключ сортировки многомерного макета данных, в зависимости от того, какой вариант лучше подходит для вашей рабочей нагрузки. Если выбрано многомерное расположение данных, Amazon Redshift создаст функцию многомерной сортировки, которая совмещает строки, к которым обычно обращаются одни и те же запросы, а функция сортировки впоследствии используется во время выполнения запроса для пропуска блоков данных и даже пропуска сканирования отдельного предиката. столбцы.
Рассмотрим следующий пользовательский запрос, который является доминирующим шаблоном запроса в рабочей нагрузке пользователя:
Amazon Redshift хранит данные для каждого столбца в дисковых блоках размером 1 МБ и сохраняет минимальные и максимальные значения в каждом блоке как часть метаданных таблицы. Если в запросе используется предикат с ограничением диапазонаAmazon Redshift может использовать минимальное и максимальное значения для быстрого пропуска большого количества блоков во время сканирования таблицы. Однако фильтр этого запроса в столбце субрегиона нельзя использовать для определения того, какие блоки следует пропускать на основе минимального и максимального значений, и в результате Amazon Redshift сканирует все строки из таблицы заголовков:
Когда запрос пользователя был запущен с помощью titles с помощью ключа сортировки по одному столбцу subregion, результат предыдущего запроса будет следующим:
Это показывает, что при сканировании таблицы было прочитано 2,164,081,640 XNUMX XNUMX XNUMX строк.
Чтобы улучшить сканирование на titles таблицы, Amazon Redshift может автоматически решить использовать ключ сортировки многомерного макета данных. Все строки, удовлетворяющие lower(subregion) like '%United States%' предикат будет размещен в выделенной области таблицы, поэтому Amazon Redshift будет сканировать только те блоки данных, которые удовлетворяют предикату.
Когда запрос пользователя выполняется с помощью titles используя ключ сортировки многомерного макета данных, который включает в себя lower(subregion) like '%United States%' как предикат, результат sys_query_detail запрос выглядит следующим образом:
Это показывает, что при сканировании таблицы было прочитано 152,324,046 7 XNUMX строк, что составляет всего XNUMX% от исходного значения, и при этом использовался ключ сортировки многомерного макета данных.
Обратите внимание, что в этом примере используется один запрос для демонстрации функции многомерного размещения данных, но Amazon Redshift учтет все запросы, выполняемые к таблице, и может создать несколько регионов для удовлетворения наиболее часто используемых предикатов.
Давайте возьмем другой пример, на этот раз с более сложными предикатами и несколькими запросами.
Представьте, что у вас есть стол items (cost int, available int, demand int) с четырьмя строками, как показано в следующем примере.
| #мне бы | стоят | доступен | спрос |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Ваша основная рабочая нагрузка состоит из двух запросов:
- Шаблон 70% запросов:
- Шаблон 20% запросов:
Используя традиционные методы сортировки, вы можете отсортировать таблицу по столбцу затрат, чтобы оценка cost > 3 выиграет от такого рода. Итак, таблица элементов после сортировки с использованием одного cost столбец будет выглядеть следующим образом.
| #мне бы | стоят | доступен | спрос |
| Регион №1, стоимость <= 3 | |||
| Регион №2, стоимость > 3 | |||
| #мне бы | стоят | доступен | спрос |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Используя эту традиционную сортировку, мы можем сразу исключить две верхние (синие) строки с идентификаторами 4 и 2, поскольку они не удовлетворяют требованиям. cost > 3.
С другой стороны, при использовании ключа сортировки многомерного макета данных таблица будет отсортирована на основе комбинации двух часто встречающихся предикатов в рабочей нагрузке пользователя: cost > 3 и available < demand. В результате строки таблицы сортируются по четырем регионам.
| #мне бы | стоят | доступен | спрос |
| Регион №1, стоимость <= 3 и доступность < спроса. | |||
| Регион №2, стоимость <= 3 и доступность >= спроса. | |||
| Регион №3, стоимость > 3 и доступность < спроса. | |||
| Регион № 4, стоимость > 3 и доступность >= спроса. | |||
| #мне бы | стоят | доступен | спрос |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Эта концепция становится еще более мощной, когда она применяется к целым блокам, а не к отдельным строкам, когда применяется к сложным предикатам, которые используют операторы, не подходящие для традиционных методов сортировки (таких как like), а также при применении к более чем двум предикатам.
Системные таблицы
Следующие системные таблицы Amazon Redshift покажут пользователям, используются ли в их таблицах и запросах многомерные макеты данных:
- Чтобы определить, использует ли конкретная таблица ключ сортировки многомерного макета данных, вы можете проверить, используется ли
sortkey1in svv_table_info равноAUTO(SORTKEY(padb_internal_mddl_key_col)). - Чтобы определить, использует ли конкретный запрос многомерное расположение данных для ускорения сканирования таблицы, вы можете проверить
step_attributeв sys_query_detail вид. Значение будет равноmulti-dimensionalесли во время сканирования использовался ключ сортировки многомерного макета данных таблицы.
Тесты производительности
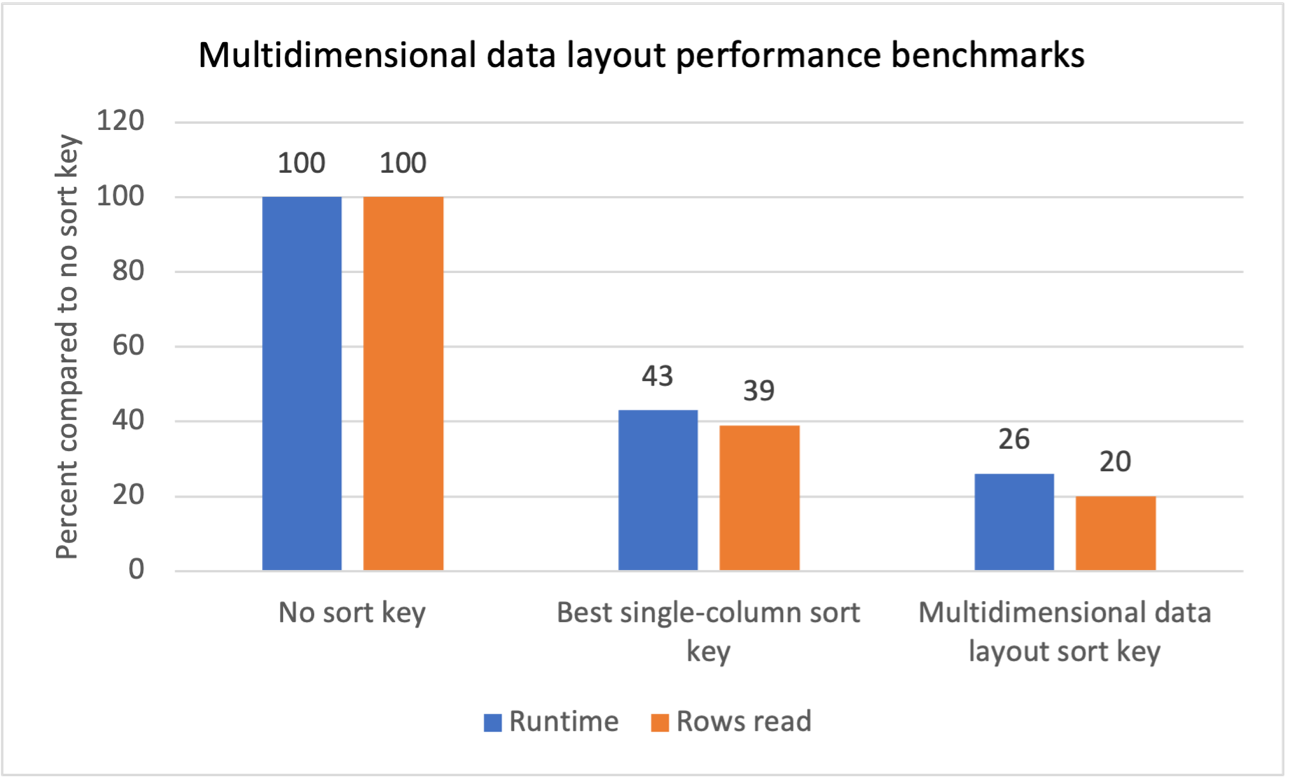
Мы провели внутреннее тестирование производительности для нескольких рабочих нагрузок с фильтрами повторяющегося сканирования и увидели, что введение ключей сортировки многомерного макета данных дало следующие результаты:
- Общее сокращение времени выполнения на 74 % по сравнению с отсутствием ключа сортировки.
- Общее сокращение времени выполнения на 40 % по сравнению с использованием лучшего ключа сортировки по одному столбцу в каждой таблице.
- Сокращение общего количества строк, считываемых из таблиц, на 80 % по сравнению с отсутствием ключа сортировки.
- Сокращение общего количества строк, считываемых из таблиц, на 47 % по сравнению с лучшим ключом сортировки по одному столбцу в каждой таблице.
Сравнение функций
С появлением ключей сортировки многомерного макета данных ваши таблицы теперь можно сортировать по выражениям на основе часто встречающихся предикатов фильтров в вашей рабочей нагрузке. В следующей таблице представлено сравнение функций Amazon Redshift с двумя конкурентами.
| Особенность | Амазонка Redshift | Конкурент А | Конкурент Б |
| Поддержка сортировки по столбцам | Да | Да | Да |
| Поддержка сортировки по выражению | Да | Да | Нет |
| Автоматический выбор столбца для сортировки | Да | Нет | Да |
| Автоматический выбор выражений для сортировки | Да | Нет | Нет |
| Автоматический выбор между сортировкой столбцов или сортировкой выражений | Да | Нет | Нет |
| Автоматическое использование свойств сортировки выражений во время сканирования | Да | Нет | Нет |
Соображения
При использовании многомерного макета данных помните следующее:
- Многомерное расположение данных включается, когда вы устанавливаете для таблицы режим SORTKEY AUTO.
- Amazon Redshift Advisor автоматически выберет либо ключ сортировки по одному столбцу, либо макет многомерных данных для таблицы, анализируя вашу историческую рабочую нагрузку.
- Amazon Redshift ATO корректирует результаты сортировки макета многомерных данных в зависимости от того, как текущие запросы взаимодействуют с рабочей нагрузкой.
- Amazon Redshift ATO поддерживает ключи сортировки многомерного макета данных так же, как в настоящее время это делается для существующих ключей сортировки. Ссылаться на Работа с автоматической оптимизацией таблицы подробнее об АТО.
- Ключи сортировки многомерного макета данных будут работать как с подготовленными кластерами, так и с бессерверными рабочими группами.
- Ключи сортировки многомерного макета данных будут работать с существующими данными до тех пор, пока в вашей таблице включена функция АВТОСОРТИРОВКИ и обнаружена рабочая нагрузка с фильтрами повторяющегося сканирования. Таблица будет реорганизована на основе результатов функции многомерной сортировки.
- Чтобы отключить ключи сортировки многомерного макета данных для таблицы, используйте alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Это отключает функцию ключа автоматической сортировки в таблице. - Ключи сортировки многомерного макета данных сохраняются при восстановлении или переносе подготовленного кластера в бессерверный кластер и наоборот.
Заключение
В этом посте мы показали, что ключи сортировки многомерного макета данных могут значительно повысить производительность выполнения запросов для рабочих нагрузок, в которых доминирующие запросы имеют повторяющиеся фильтры сканирования.
Чтобы создать кластер предварительного просмотра из консоли Amazon Redshift, перейдите к Кластеры страницу и выберите Создать предварительный кластер. Вы можете создать кластер в регионах Восток США (Огайо), Восток США (Северная Вирджиния), Запад США (Орегон), Азиатско-Тихоокеанский регион (Токио), Европа (Ирландия) и Европа (Стокгольм) и протестировать свои рабочие нагрузки.
Мы хотели бы услышать ваши отзывы об этой новой функции и с нетерпением ждем ваших комментариев к этому посту.
Об авторах
 Милинд Оке является специалистом по хранилищу данных, архитектором решений из Нью-Йорка. Он занимается созданием решений для хранилищ данных более 15 лет и специализируется на Amazon Redshift.
Милинд Оке является специалистом по хранилищу данных, архитектором решений из Нью-Йорка. Он занимается созданием решений для хранилищ данных более 15 лет и специализируется на Amazon Redshift.
 Цзялин Дин — учёный-прикладник в группе Learned Systems, специализирующийся на применении методов машинного обучения и оптимизации для повышения производительности систем обработки данных, таких как Amazon Redshift.
Цзялин Дин — учёный-прикладник в группе Learned Systems, специализирующийся на применении методов машинного обучения и оптимизации для повышения производительности систем обработки данных, таких как Amazon Redshift.
 Янжу Цзи является менеджером по продукту в команде Amazon Redshift. У нее есть опыт работы с концепцией продуктов и стратегией ведущих в отрасли продуктов и платформ данных. Она обладает выдающимися навыками создания существенных программных продуктов с использованием методов веб-разработки, проектирования систем, баз данных и распределенного программирования. В личной жизни Янжу любит рисовать, фотографировать и играть в теннис.
Янжу Цзи является менеджером по продукту в команде Amazon Redshift. У нее есть опыт работы с концепцией продуктов и стратегией ведущих в отрасли продуктов и платформ данных. Она обладает выдающимися навыками создания существенных программных продуктов с использованием методов веб-разработки, проектирования систем, баз данных и распределенного программирования. В личной жизни Янжу любит рисовать, фотографировать и играть в теннис.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :имеет
- :является
- :нет
- :куда
- 1
- 100
- 15 лет
- 15%
- 152
- 7
- 8
- 9
- a
- ускорять
- Доступ
- дополнительный
- советник
- После
- против
- алгоритм
- Все
- уже
- Amazon
- Amazon Web Services
- an
- анализировать
- анализ
- и
- Другой
- прикладной
- Применение
- МЫ
- AS
- Азия
- Азиатско-Тихоокеанский регион
- автоматический
- Автоматический
- автоматически
- доступен
- AWS
- основанный
- BE
- , так как:
- было
- эталонный тест
- польза
- ЛУЧШЕЕ
- Лучшая
- между
- Заблокировать
- Блоки
- Синии
- изоферменты печени
- Строительство
- но
- by
- CAN
- возможности
- проверка
- Выберите
- облако
- Кластер
- Column
- Колонки
- сочетание
- Комментарии
- обычно
- сравненный
- сравнение
- конкурентов
- комплекс
- сама концепция
- Рассматривать
- состоит
- Консоли
- строить
- содержит
- Цена
- чехлы
- Создайте
- В настоящее время
- данным
- информационное хранилище
- База данных
- решать
- преданный
- определять
- Спрос
- требующий
- Проект
- подробнее
- обнаруженный
- Определять
- Развитие
- распределенный
- распределение
- приносит
- доминирующий
- Dont
- в течение
- каждый
- восток
- или
- включен
- Весь
- равный
- особенно
- Эфир (ETH)
- Европе
- оценка
- Даже
- эволюционировали
- пример
- существующий
- опыт
- выражения
- Особенность
- Обратная связь
- фильтр
- фильтры
- после
- следующим образом
- Что касается
- вперед
- 4
- от
- функция
- группы
- рука
- Есть
- имеющий
- he
- слышать
- ее
- исторический
- история
- Однако
- HTML
- HTTPS
- ID
- if
- немедленно
- улучшать
- улучшается
- in
- включает в себя
- individual
- отрасли
- вместо
- взаимодействовать
- в нашей внутренней среде,
- вмешательство
- в
- вводить
- введение
- Введение
- Ирландия
- IT
- пункты
- Основные
- ключи
- большой
- Планировка
- узнали
- изучение
- ЖИЗНЬЮ
- такое как
- нравится
- Длинное
- посмотреть
- выглядит как
- любят
- машина
- обучение с помощью машины
- поддерживает
- менеджер
- способ
- максимальный
- Встречайте
- Метаданные
- может быть
- мигрирующий
- против
- минимальный
- БОЛЕЕ
- самых
- с разными
- Откройте
- Необходимость
- Новые
- Новая функция
- New York
- нет
- сейчас
- номера
- происходящий
- of
- от
- предложенный
- Огайо
- on
- ONE
- постоянный
- только
- Операторы
- оптимизация
- оптимизирует
- Опция
- or
- заказ
- Орегон
- оригинал
- Другое
- внешний
- выдающийся
- за
- Тихий океан
- Картина
- часть
- особый
- шаблон
- производительность
- выполнены
- личного
- фотография
- физический
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- После
- мощный
- консервированный
- предварительный просмотр
- Произведенный
- Продукт
- Менеджер по продукции
- Продукция
- Программирование
- свойства
- приводит
- Запросы
- быстро
- Читать
- снижение
- относиться
- область
- районы
- повторяющийся
- Требования
- восстановление
- результат
- Итоги
- Run
- Бег
- работает
- то же
- сканирование
- сканирование
- сканирует
- Ученый
- Время года
- посмотреть
- выберите
- выбранный
- выбор
- Serverless
- Услуги
- набор
- она
- показывать
- демонстрации
- показал
- показанный
- Шоу
- существенно
- одинарной
- умение
- So
- Software
- Решения
- специалист
- специализируется
- специализация
- магазины
- Стратегия
- впоследствии
- существенный
- такие
- подходящее
- поддержки
- система
- системы
- ТАБЛИЦЫ
- взять
- команда
- снижения вреда
- теннис
- тестXNUMX
- Тестирование
- чем
- который
- Ассоциация
- их
- следовательно
- они
- этой
- время
- позиций
- в
- Токио
- топ
- Всего
- традиционный
- два
- напишите
- типично
- us
- использование
- используемый
- Информация о пользователе
- пользователей
- использования
- через
- ценностное
- Наши ценности
- вице
- Вид
- Виргиния
- видение
- Склады
- законопроект
- Путь..
- we
- Web
- Веб-разработка
- веб-сервисы
- запад
- когда
- будь то
- который
- широко
- будете
- без
- Работа
- бы
- лет
- йорк
- являетесь
- ВАШЕ
- зефирнет