Веб-скрапинг может быть мощным инструментом для извлечения данных с веб-сайтов, но он также может быть сложным и трудоемким процессом. К счастью, Google Sheets предлагает удобное решение для извлечения данных с веб-сайтов без необходимости написания сложного кода. Используя возможности Google Таблиц, вы можете легко извлекать данные с веб-страниц и анализировать их различными способами. В этом блоге я проведу вас через процесс использования Google Таблиц для парсинга веб-страниц и помогу вам раскрыть потенциал парсинга веб-страниц для ваших собственных проектов. Итак, приступим!
Веб-скрейпинг может занимать много времени, быть сложным и включать в себя много кода. Для некодеров. Google Таблицы — отличная альтернатива парсингу веб-страниц. Веб-скрапинг листов Google не требует кодирования и предоставляет множество способов анализа данных веб-сайта.
В этом блоге мы увидим, как легко использовать Google Таблицы для очистки веб-страниц. Итак, приступим!
Зачем использовать Google Таблицы для парсинга веб-страниц?
Есть несколько причин, по которым Google Sheets — отличный инструмент для парсинга веб-страниц:
- Google Таблицы удобны и имеют знакомый интерфейс.
- Он не требует знания языка программирования.
- Google Таблицы доступны из любого места.
- Google Таблицы бесплатны, что делает их доступными для частных лиц и малого бизнеса.
- Google легко интегрируется с другими инструментами Suite.
- Вы можете использовать макросы или сценарии для автоматизации задач парсинга веб-страниц.
- Вы можете легко анализировать очищенные данные, используя формулы Google Sheet.
Извлекайте текст с любой веб-страницы всего одним щелчком мыши. Отправляйтесь в Нанонец парсер веб-сайтов, Добавьте URL-адрес и нажмите «Очистить», чтобы мгновенно загрузить текст веб-страницы в виде файла. Попробуйте бесплатно прямо сейчас.
Какие функции использовать для веб-скрейпинга Google Sheets?
Вот некоторые функции, которые вы можете использовать, когда вам нужно очистить веб-страницы с помощью Google Sheets.
ИМПОРТHTML:
Извлечение таблиц и списков из HTML-страниц.
=IMPORTHTML(url, query, index)- URL: это ссылка на веб-страницу, которую вы хотите очистить.
- запрос: Тип данных – Таблица, Список
- index: если вы хотите извлечь определенную таблицу, вы можете использовать этот
Пример:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)ИМПОРТXML:
Извлечение данных из XML-страниц.
=IMPORTXML(url, xpath_query)- URL: это ссылка на веб-страницу, которую вы хотите очистить.
- xpath_query: выражение XPath, идентифицирующее данные, которые вы хотите извлечь.
Пример:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")ИМПОРТНЫЕ ДАННЫЕ:
Извлечение данных из файлов CSV и TSV.
=IMPORTDATA(url)- URL-адрес: URL-адрес файла CSV или TSV, из которого вы хотите извлечь данные.
Пример:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")РЕГЭКСТРАКТ:
Эта функция может извлекать данные, соответствующие шаблону регулярного выражения.
=REGEXEXTRACT(text, regular_expression)- текст: текст, который вы хотите найти по шаблону
- регулярное_выражение: шаблон, который вы хотите сопоставить
Пример:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")Примечание. Эти функции могут работать не на каждом веб-сайте. Это зависит от макета сайта. Если вам нужно больше данных, вы можете прибегнуть к учебникам по парсингу веб-страниц с использованием Python и Java или использовать инструменты для преобразования веб-сайта в текст, такие как Nanonets.
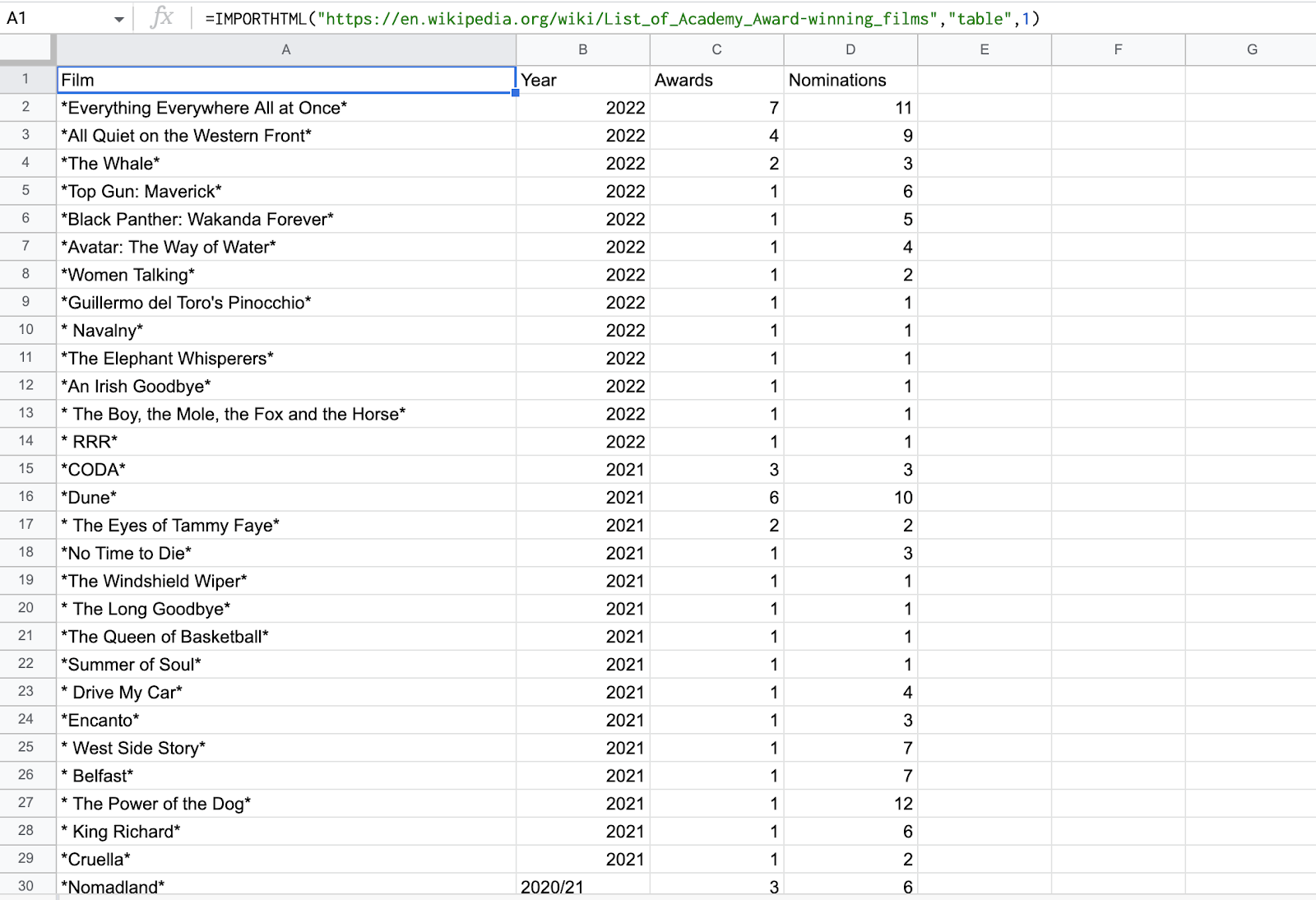
Давайте попробуем извлечь HTML-таблицу в Google Sheets. Мы попробуем очистить таблицу от Список фильмов, отмеченных наградами Академии, страница Википедии.
- Откройте Google Таблицы.
- В новой ячейке введите =IMPORTHTML(url, query, index)
1. Наш код становится,
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =ИМПОРТHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films", "table", 1)
очистит первую таблицу на странице Википедии
3. Проверьте результаты
Как очистить данные с помощью веб-скрейпинга Google Sheets?
Давайте посмотрим, как парсить заголовки, описания, H1 и многое другое с помощью Google Sheets. Чтобы начать парсинг H1 с помощью Google Таблиц, мы будем использовать функцию IMPORTXML для этого конкретного Страница нанонетов. Вот шаги:
- Откройте новую или существующую таблицу Google.
- В ячейке введите следующую формулу:
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- Чтобы извлечь тег H1, используйте следующее выражение XPath: //h1/text()
- Чтобы извлечь тег title, используйте следующее выражение XPath: //title/text()
- Чтобы извлечь метатег описания, используйте следующее выражение XPath: //meta[@name='description']/@content
- Чтобы извлечь все ссылки на страницы, используйте следующее выражение XPath: //a/@href
Нажмите Enter, и Google Таблицы автоматически очистят данные и отобразят их в выбранной ячейке.
Затем вы можете скопировать формулу в другие ячейки, чтобы получить дополнительные данные с тех же или разных веб-страниц.
Извлекайте текст с любой веб-страницы всего одним щелчком мыши. Отправляйтесь в Нанонец парсер веб-сайтов, Добавьте URL-адрес и нажмите «Очистить», чтобы мгновенно загрузить текст веб-страницы в виде файла. Попробуйте бесплатно прямо сейчас.
Каковы недостатки использования Google Sheets Web Scraper?
- Google Таблицы имеют ограниченные возможности. Когда дело доходит до сложных макетов, он не может обрабатывать динамический контент.
- При очистке данных с использованием формул веб-скрейпинга Google Sheets могут возникать расхождения.
- При очистке данных с веб-сайтов вы можете непреднамеренно удалить важную или конфиденциальную информацию. Это может вызвать проблемы с конфиденциальностью и безопасностью, особенно если очищенные данные передаются или хранятся в незащищенном месте.
Совет. Веб-скраппинг Google Таблиц — отличная альтернатива несложным задачам парсинга веб-страниц, таким как мета-заголовки, списки или извлечение таблиц. Для сложных задач следует использовать инструменты веб-скрейпинга.
Часто задаваемые вопросы
Могу ли я парсить веб-страницы с помощью Google Таблиц?
Да, Google Таблицы имеют встроенные функции, такие как IMPORTHTML, IMPORTXML, IMPORTDATA,
и REGEXTRACT, которые позволяют собирать данные с веб-сайтов непосредственно в Google Таблицы. Однако функциональность может быть ограничена, и для более сложных задач веб-скрейпинга может потребоваться использование отдельного веб-скребка или написание пользовательского кода.
Как соскребать данные в таблицу Google?
Вы можете извлечь данные в таблицу Google с помощью одной из встроенных функций, таких как IMPORTHTML, IMPORTXML, IMPORTDATA или REGEXTRACT. Эти функции позволяют извлекать данные с веб-сайтов, файлов CSV или TSV и сопоставлять шаблоны регулярных выражений. Просто укажите URL-адрес, запрос, индекс или шаблон регулярного выражения, и данные будут извлечены и заполнены в вашей таблице Google.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :является
- 1
- 11
- 2023
- 7
- a
- Академия
- доступной
- дополнительный
- доступной
- Все
- альтернатива
- анализировать
- и
- откуда угодно
- МЫ
- AS
- автоматизировать
- автоматически
- наградами
- BE
- становится
- Блог
- встроенный
- бизнес
- by
- CAN
- возможности
- захватить
- случаев
- Клетки
- проверка
- нажмите на
- Закрыть
- код
- Кодирование
- комплекс
- Обеспокоенность
- содержание
- изготовленный на заказ
- данным
- зависит
- описание
- различный
- непосредственно
- Дисплей
- скачать
- динамический
- каждый
- легко
- Enter
- особенно
- Эфир (ETH)
- Каждая
- отлично
- существующий
- извлечение
- добыча
- знакомый
- Особенности
- Файл
- Файлы
- пленки
- First
- после
- Что касается
- формула
- К счастью
- Бесплатно
- от
- функция
- функциональность
- Функции
- получить
- правительство
- большой
- инструкция
- обрабатывать
- помощь
- здесь
- Как
- How To
- Однако
- HTML
- HTTPS
- i
- идентифицирует
- in
- индекс
- лиц
- информация
- Интегрируется
- Интерфейс
- включать в себя
- IT
- Java
- только один
- знания
- язык
- Планировка
- Используя
- такое как
- Ограниченный
- LINK
- связи
- Списки
- расположение
- серия
- Макрос
- Создание
- многих
- Совпадение
- Мета
- может быть
- БОЛЕЕ
- Необходимость
- нуждающихся
- Новые
- of
- Предложения
- on
- ONE
- заказ
- Другое
- собственный
- страница
- особый
- шаблон
- паттеранами
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- населенный
- потенциал
- фунт
- мощностью
- мощный
- политикой конфиденциальности.
- Конфиденциальность и безопасность
- процесс
- Программирование
- проектов
- приводит
- Питон
- повышение
- причины
- регулярный
- требовать
- требуется
- курорт
- s
- то же
- выскабливание
- скрипты
- Поиск
- безопасность
- выбранный
- чувствительный
- отдельный
- несколько
- общие
- должен
- просто
- просто
- небольшой
- малого бизнеса
- So
- Решение
- некоторые
- конкретный
- и политические лидеры
- Статистика
- Шаги
- хранить
- такие
- suite
- ТАБЛИЦЫ
- извлечение таблицы
- TAG
- задачи
- который
- Ассоциация
- Эти
- Через
- кропотливый
- Название
- позиций
- в
- инструментом
- инструменты
- учебные пособия
- отпереть
- необеспеченный
- URL
- использование
- удобно
- разнообразие
- способы
- Web
- соскоб
- Вебсайт
- веб-сайты
- Википедия.
- будете
- без
- Работа
- записывать
- письмо
- XML
- ВАШЕ
- зефирнет